目次
はじめに
「LSTMによるサザエさんのじゃんけん予想」という記事を書いたばかりなのですが、早速違うモデルでも試してみたのでその結果を書き留めておきます。
ソースコード
import numpy as np
import pandas as pd
from keras.layers import Activation, Dense
from keras.models import Sequential
data_file = 'サザエさんじゃんけん.tsv'
res_file = 'small_neural'
def shuffle_lists(list1, list2):
'''リストをまとめてシャッフル'''
seed = np.random.randint(0, 1000)
np.random.seed(seed)
np.random.shuffle(list1)
np.random.seed(seed)
np.random.shuffle(list2)
def get_data():
'''データ作成'''
df = pd.read_csv(data_file, sep='\t',
usecols=['rock', 'scissors', 'paper'])
X_data = [[0, 0, 0]]
for row in df.values:
data = [d + 1 for d in X_data[-1]]
data[row.argmax()] = 0
X_data.append(data)
# numpy.array型に変換
# X_data = np.array(X_data[:-1])
# y_data = np.array(df.values)
X_data = np.array(X_data[-501:-1])
y_data = np.array(df.values[-500:])
last_data = np.array(X_data[-1:])
# 正規化
X_data = X_data.astype(np.float32)
last_data = last_data.astype(np.float32)
X_data /= 255.0
last_data /= 255.0
# シャッフル
shuffle_lists(X_data, y_data)
return X_data, y_data, last_data
def get_model():
'''モデルを構築'''
model = Sequential()
model.add(Dense(32, input_shape=(3,)))
model.add(Activation('relu'))
model.add(Dense(32))
model.add(Activation('relu'))
model.add(Dense(32))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def pred(model, X, Y, label):
'''正解率 出力'''
predictX = model.predict(X)
correct = 0
for real, predict in zip(Y, predictX):
if real.argmax() == predict.argmax():
correct += 1
correct = correct / len(Y)
print(label + '正解率 : %02.2f ' % correct)
def main():
X_data, y_data, last_data = get_data()
# データ分割
mid = int(len(y_data) * 0.7)
train_X, train_y = X_data[:mid], y_data[:mid]
test_X, test_y = X_data[mid:], y_data[mid:]
# 学習
model = get_model()
hist = model.fit(train_X, train_y, epochs=1000, batch_size=8,
validation_data=(test_X, test_y))
# 正解率出力
pred(model, train_X, train_y, 'train')
pred(model, test_X, test_y, 'test')
# 来週の手
next_hand = model.predict(last_data)
print(next_hand[0])
hands = ['グー', 'チョキ', 'パー']
print('来週の手 : ' + hands[next_hand[0].argmax()])
if __name__ == '__main__':
main()
簡単に解説
今回は簡単なニューラルモデルで学習してみました。
データは、それぞれの手が出てない回数にしました。
サザエさんじゃんけん.tsv には以下の形式でデータをまとめてあります。
サザエさんじゃんけん.tsv
year month day rock scissors paper
1991 11 10 0 1 0
1991 11 17 1 0 0
1991 11 24 1 0 0
...
そこから, データを以下のように整形
[[0 0 0] <- 最初はすべて0
[1 0 1] <- チョキが出たので1番目を0に。ほかは+1
[0 1 2] <- グーが出たので0番目を0に。ほかは+1
...
データをすべて使うとなぜか精度が精度が落ちるので、ここでは直近の100回分のみ使用しています。
結果
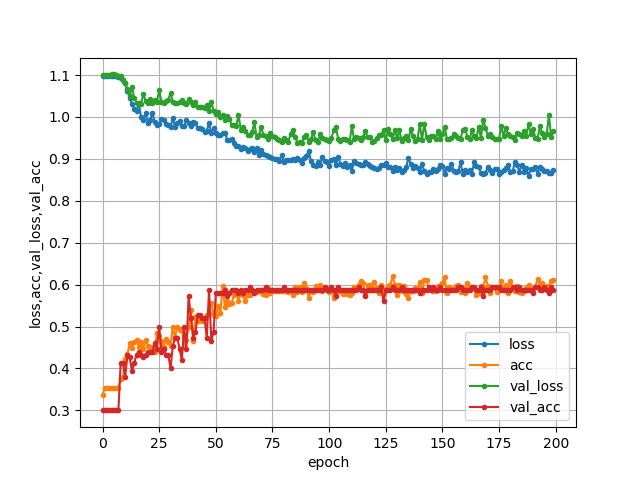
パラメータや層数を変えてみて一番良かった結果がこちらです。
- 出力
train正解率 : 0.61
test正解率 : 0.58
[0.17965864 0.07733747 0.7430039 ]
来週の手 : パー
- グラフ
最後に
精度はLSTMのときとたいして変りませんでしたが、来週の手が「パー」になりました。ただ、パラメータをいじっているとちょいちょい「グー」も出ます。(どちらを信じたらいいんだorz)
使用する素性次第でまだまだ改善の余地があるかと思いますので、皆さんも是非チャレンジしてみてください。
とりあえず、今週のサザエさんを楽しみにしてます。
追記
(18/08/19)
残念ながら今回は外れてしまいました。(正解はグーでした)