目次
はじめに
数日前に、サザエさんじゃんけん研究所様が過去のサザエさんのじゃんけんの手をまとめたPDFを公開したことが話題になっていました。さらに同研究所がそのデータを解析し、通算で7割以上の勝率を誇っていると知り、まだ未熟ではありますが機械学習をかじる者としてじっとしてはいられなかったわけです。
ということで、まずはLSTMを使って簡単に予測モデルを作ることにしました。
ソースコード
別記事「Kerasで多変量LSTM」を参考にしています。
import numpy as np
import pandas as pd
from keras.layers import LSTM, Activation, Dense
from keras.models import Sequential
data_file = 'サザエさんじゃんけん.tsv'
look_back = 13 # 遡る時間
res_file = 'lstm'
def shuffle_lists(list1, list2):
'''リストをまとめてシャッフル'''
seed = np.random.randint(0, 1000)
np.random.seed(seed)
np.random.shuffle(list1)
np.random.seed(seed)
np.random.shuffle(list2)
def get_data():
'''データ作成'''
df = pd.read_csv(data_file, sep='\t',
usecols=['rock', 'scissors', 'paper'])
dataset = df.values.astype(np.float32)
X_data, y_data = [], []
for i in range(len(dataset) - look_back - 1):
x = dataset[i:(i + look_back)]
X_data.append(x)
y_data.append(dataset[i + look_back])
# X_data = np.array(X_data)
# y_data = np.array(y_data)
X_data = np.array(X_data[-500:])
y_data = np.array(y_data[-500:])
last_data = np.array([dataset[-look_back:]])
# シャッフル
shuffle_lists(X_data, y_data)
return X_data, y_data, last_data
def get_model():
model = Sequential()
model.add(LSTM(16, input_shape=(look_back, 3)))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def pred(model, X, Y, label):
'''正解率 出力'''
predictX = model.predict(X)
correct = 0
for real, predict in zip(Y, predictX):
if real.argmax() == predict.argmax():
correct += 1
correct = correct / len(Y)
print(label + '正解率 : %02.2f ' % correct)
def main():
# データ取得
X_data, y_data, last_data = get_data()
# データ分割
mid = int(len(X_data) * 0.7)
train_X, train_y = X_data[:mid], y_data[:mid]
test_X, test_y = X_data[mid:], y_data[mid:]
# 学習
model = get_model()
hist = model.fit(train_X, train_y, epochs=50, batch_size=16,
validation_data=(test_X, test_y))
# 正解率出力
pred(model, train_X, train_y, 'train')
pred(model, test_X, test_y, 'test')
# 来週の手
next_hand = model.predict(last_data)
print(next_hand[0])
hands = ['グー', 'チョキ', 'パー']
print('来週の手 : ' + hands[next_hand[0].argmax()])
if __name__ == '__main__':
main()
簡単に解説
データはあらかじめtsvファイルにまとめておきました。
year month day rock scissors paper
1991 11 10 0 1 0
1991 11 17 1 0 0
1991 11 24 1 0 0
1991 12 1 0 0 1
...
そこから, データを以下のように整形(look_back=2 のとき)
[[[0. 0. 1.]
[0. 1. 0.]]
[[1. 0. 0.]
[0. 1. 0.]]
[[1. 0. 0.]
[1. 0. 0.]]
...
結果
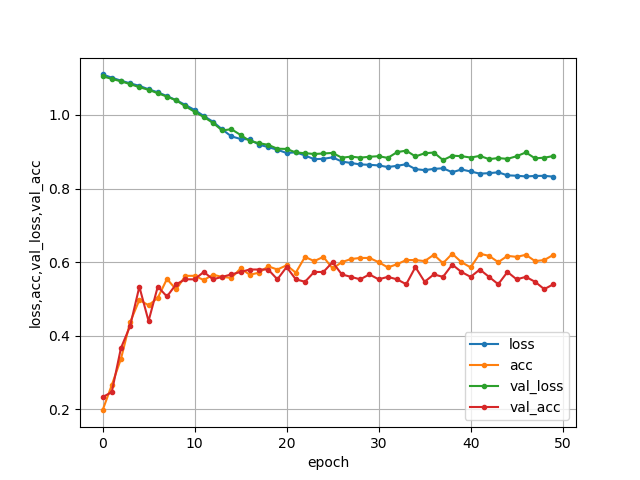
パラメータを変えてみて一番良かった結果はこのようになりました。
- 出力
train正解率 : 0.60
test正解率 : 0.59
[0.6323466 0.12851575 0.23913768]
来週の手 : グー
- グラフ
最後に
残念ながら今回はサザエさんじゃんけん研究所様の勝率には及びませんでしたが、使用する素性やモデル次第でまだまだ改善の余地があるかと思います。また時間があるときに挑戦したいと思います。皆さんもぜひチャレンジしてみてください。
今週のサザエさんを楽しみにしてます。
追記
(18/08/18)
コードが汚すぎたので整理しました。
別のモデルでも挑戦してみました。
→ ニューラルネットによるサザエさんのじゃんけん予想
(18/08/19)
見事(運良く)正解できました!