はじめに
どうも。スクレイピング歴2日の初心者です。
本日もスクレイピングを勉強したので学習内容をQiitaにまとめます。
この続き 学習教材や開発環境は前頁と被るので省略致します。
本記事の趣旨
今回も動画通りに行っても2022年度のseleniumの記法変化によりエラーが発生する箇所を中心として進めていきます。その部分以外はさらっと。動画の方を確認して頂いて。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- 初学者が勉強するBeautiful Soup②
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
学習
前回の復習
#ブラウザの起動
browser = webdriver.Chrome("C:/****/****/Desktop/****/****/スクレイピング/chromedriver.exe")
#お好きなURLを指定してアクセス
url = "https://scraping-for-beginner.herokuapp.com/login_page"
browser.get(url)
sleep(4) #ここでスリープ位入れときますか。
#1 どの場所に 2 どんな操作を行いたいか。
elem_username = browser.find_element('id',"username") #この場所に
elem_username.send_keys('imanishi') #このようなキーを送る。
elem_pass = browser.find_element('id',"password") #この場所に
elem_pass.send_keys('kohei') #このようなキーを送る。
elem_click = browser.find_element('id',"login-btn") #この場所に
elem_click.click() #このような操作を行う。クリック。
閉じるときはこう。
browser.quit()
今回の内容
- テキスト情報を取得する。
- テキスト情報を効率よく取得する。
- それらをCSVにて出力する。
テキスト情報を取得する。
elem_name = browser.find_element('id',"name") #この場所に
elem_name.text
elem_company = browser.find_element('id',"company") #この場所に
elem_company.text
elem_birthday = browser.find_element('id',"birthday") #この場所に
elem_birthday.text
elem_hobby = browser.find_element('id',"hobby") #この場所に
動画とは記法が異なりますが、前qiita記事にて扱った訂正箇所を応用してこのように情報を取得する事ができます。 動画の41分50秒辺り。
print(elem_name.text ,elem_company.text ,elem_birthday.text ,elem_hobby.text)
#結果
#今西 航平 株式会社キカガク 1994年7月15日 バスケットボール
#読書
#ガジェット集め
この調子で手作業でコード入力すると、テキスト情報を取得することができますが、もう少し効率の良いやり方はないのでしょうか?
テキスト情報を効率よく取得する。
因みに複数形にすると一気に情報を取得する事が出来ます。
検証を用いて観察すると、「th」というTagに欲しい情報がありそう。

elem_keys = browser.find_elements(by="tag name", value="th")
elem_keys
#結果
[<selenium.webdriver.remote.webelement.WebElement (session="cfc3f9b32dc24af2a07271c3fe294899", element="3f9d5d34-6a6e-4683-9fe4-b38393c19fdb")>,
<selenium.webdriver.remote.webelement.WebElement (session="cfc3f9b32dc24af2a07271c3fe294899", element="6177635c-b770-41cc-9ab9-2a1a336b8ec1")>,
<selenium.webdriver.remote.webelement.WebElement (session="cfc3f9b32dc24af2a07271c3fe294899", element="04f2b519-ec5e-424c-8a13-28eb9fb7f8b2")>,
<selenium.webdriver.remote.webelement.WebElement (session="cfc3f9b32dc24af2a07271c3fe294899", element="e79cf174-6f91-408e-a07c-04f3820ac85c")>,
<selenium.webdriver.remote.webelement.WebElement (session="cfc3f9b32dc24af2a07271c3fe294899", element="0cf82e55-1021-42bf-836e-59093f2dcfcc")>]
こうすると取得する事が出来る。⇒動画の48分辺り。
これは2022年度で記法が変更したやり方。動画の通りに行うとエラーになります。
これで各々取得した情報を確認する事が出来ます。.find_elements。複数系ですからね。
取得した情報を確認するには.textでテキスト化する必要があります。
elem_keys[2].text
#'生年月日'
thでkeyが取れたので今度はtdで同じことを行いましょう。
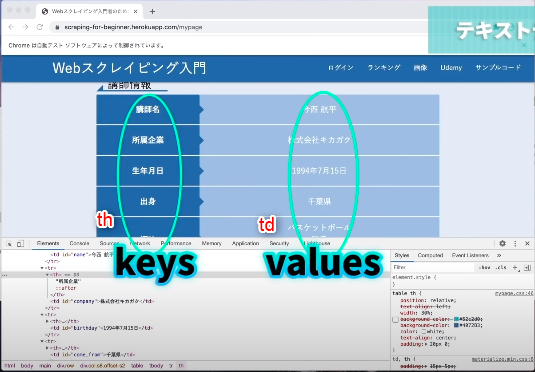
elem_values = browser.find_elements(by="tag name", value="td")
#結果
elem_values[2].text
#'1994年7月15日'
なるほど、このようにして値を確認するのですね。ちまちま。
…察しがいい方なら気づくと思いますが、サイトが同じような構造なら、for分で取ってくることもできるはずです。実装を試みましょう。
for e in elements:
print(e.text)
for v in elem_values:
print(v.text)
#結果
講師名
所属企業
生年月日
出身
趣味
今西 航平
株式会社キカガク
1994年7月15日
千葉県
バスケットボール
読書
ガジェット集め
リスト型にして情報を一括テキスト化しました。
しかしこれでは少し見にくい。なので辞書型にして確認してみましょう。
#別パターン
keys =[]
for e in elements:
key = e.text
keys.append(key)
print(keys)
values = []
for elem_td in elem_values:
value = elem_td.text
values.append(value)
print(values)
['講師名', '所属企業', '生年月日', '出身', '趣味']
['今西 航平', '株式会社キカガク', '1994年7月15日', '千葉県', 'バスケットボール\n読書\nガジェット集め']
それでは一括取得した情報をcsvに出力してみましょう。
それらをCSVにて出力する。
空のdfを作成。
import pandas as pd
df = pd.DataFrame()#この空のデータに入れてあげる。
情報の格納。
dfに["項目"]というカラムを作成し、その中に要素を格納する。
valuesも同様。
df["項目"] =keys
df["値"] =values
df

最後にcsv出力
df.to_csv("C:/Users/****/Downloads/imanyu.csv",index=False)
csvに出力。
場所に指定⇒C:/Users/****/Downloads
名前の指定⇒imanyu.csv
index=False⇒ 手前のindexを削除。 詳しくは動画の59分に。
総まとめ
#モジュールのインポート
!pip install selenium
from selenium import webdriver
from time import sleep
import pandas as pd
#ブラウザの起動⇒成功
browser = webdriver.Chrome("C:/****/****/Desktop/****/****/スクレイピング/chromedriver.exe")
#お好きなURLを指定してアクセス
url = "https://scraping-for-beginner.herokuapp.com/login_page"
browser.get(url)
sleep(2) #ここでスリープ位入れときますか。
#1 どの場所に 2 どんな操作を行いたいか。 #このパートは動画とは記法が異なるので注意して。
elem_username = browser.find_element('id',"username") #この場所に
elem_username.send_keys('imanishi') #このようなキーを送る。
elem_pass = browser.find_element('id',"password") #この場所に
elem_pass.send_keys('kohei') #このようなキーを送る。
elem_click = browser.find_element('id',"login-btn") #この場所に
elem_click.click() #このような操作を行う。クリック。
sleep(2)
#この場所の情報を取得する #このパートは動画とは記法が異なるので注意して。
elem_keys = browser.find_elements(by="tag name", value="th")
elem_values = browser.find_elements(by="tag name", value="td")
#取得した情報を可視化。つまり各々に.textを付与する。 for分を用いて一括処理を行うと効率的。
keys =[]
for e in elem_keys:
key = e.text
keys.append(key)
print(keys)
values = []
for elem_td in elem_values:
value = elem_td.text
values.append(value)
print(values)
#csvへの出力パート。
df = pd.DataFrame()
df["項目"] =keys
df["値"] =values
print(df)
#csv出力。ここは動画とは記法が異なる。私が普段使用している記法。
df.to_csv("C:/****/****/Downloads/imanyu.csv",index=False)
感想。
少しついてこれなかった部分も時間をおいて復習したら少し理解に近づいたと思う。
記法の変更点を修正するのは大変だが、少しでも他の型にお役に立てれば。