本記事は、ランド研究所の「機械学習による航空支配」を実装する(その19)です。(今回の記事が最後です)。
ランド研究所のレポートに記載されている1次元プランニング問題、2次元プランニング問題に対し、GAN と強化学習を適用し実装した感想、反省点、疑問点を中心にまとめ、今後に活かしたいと思います。
これまでの強化学習で、使用したコードは、下記 GitHub にあります。
1次元問題(GAN)
1次元問題(強化学習)
2次元問題(強化学習)
感想:GAN によるプランニングの将来性
- 成功例(や失敗例)が、山ほどあるような問題で、成功例と似た静的なプランを生成するには結構使えるのではないか、と感じました。ただし、例がないような突飛なプランは生成できません。
- 2次元問題のような時系列のプランニングができるのかどうかは、もっと GAN の勉強をしないと判りません。何らかの工夫が必要だろうと思います。
感想:現在の強化学習の有効性と限界
- 今回は、アクション空間が連続だったので、評判が良い SAC(Soft Actor Critic)を使用しました。このアルゴリズムは、思ったよりもパワフルで、今回ぐらいの問題なら有用性が高いと感じました。時間があれば、PPO と比較したかったところです。
- 空間的なプランニングに比べ、時間的なプランニングは、遥かに難しかったです。スパースな終端報酬だけでは学習は進まず、報酬シェーピングが必要でした。これは、SACに限らず、強化学習全体に言えるような気がします。
- 空間的なプランニングでは、射程のギリギリのところをきちんと見極めることができました。これは、予想以上の性能でした。
- 一方、時間的なプランニングでは、数タイムステップのタイミングを合わせるために報酬シェーピングに頼らざるを得ませんでした。原因は探索時に時間的なタイミングが合うケースが稀にしか発生しないことに問題があると考えました。このため、報酬シェーピングで、タイミングが合う方向に探索をさせることで無事に学習ができました。報酬シェーピングでは、どういう方向に学習させるべきかをよく考えることが重要だと思いました。
感想:観測を相対量だけで行うことの有用性
- 観測を、慣性空間の座標値ではなく、相対的な距離と角度に変更することで、並行移動や回転に対して不変な観測量を得ることができます。その結果、探索空間をかなり小さくできるので非常に有効です。最初は、ランド研究所のレポートに従って、慣性空間の(x, y)座標値で学習させようとしましたが、問題を少し難しくするとすぐに学習が進まなくなってしまいました。同じ問題でも、観測空間が小さくなるように観測量を工夫することは非常に重要だと感じました。
感想:学習した解のロバストネス(汎化能力)
- 距離やイニシャル・ヘディングエラーに対し、想像以上の十分な汎化能力(ロバストネス)を示しました。特に、イニシャル・ヘディングエラーに対しては、360度の汎化能力を達成しました。
- 相対量でない観測量を用いた場合、ほとんど汎化能力はありませんでした。明記されていませんが、ランド研究所のレポートでも、汎化能力は貧弱だった感じでした。相対的な観測量にすることで、360度の全周空間を小さな観測空間に変換できるので、汎化能力が向上したものと思われます。
疑問:各プランの統一的な取り扱い
- 今回は、4種類のプランニング問題に対し、別々のニューラルネットをトレーニングしました。理論的には、もっと大きくて深いネットを用いれば、統一的に4種類の問題を扱うことができるはずです。つまり、1つのニューラルネットで4種類のプランニング問題すべてに対応できるはずです。この場合、扱える範囲が広くなるので、有用性はずっと高くなります。ただし、SACも含め、現在の強化学習アルゴリズムにそこまでの能力があるのか、と感じます。
疑問:存在しないエンティティの取り扱い
- 実装した Mission 4 や、上記のように各プランを統一的に取り扱う場合、存在しないエンティティ(最初から存在しなかったり、途中で撃破されて存在しなくなったりしたエンティティ)を取り扱う必要があります。今回は、存在しなくなった段階で。観測量をすべて 0 にすることで対応しました。結果的には問題はありませんでしたが、実態とは違った取り扱いになっているので、もっと良い方法はないのだろうか、と思います。
感想:強化学習によるプランニングの将来性
- 今回のようなプランニングを、現実問題でどう使うのかについては、ランド研究所のレポートでは何も述べられていません。これについては、University College of London のグループが行った、複数(数隻)USV(Unmanned Surface Vehicle)のプランニング研究が参考になると思います。具体的には、下図のような3階層アーキテクチャで、USV のプランニングからコントロールまでを行うシステムが提案されています。
Path planning algorithm for unmanned surface vehicle
formations in a practical maritime environment
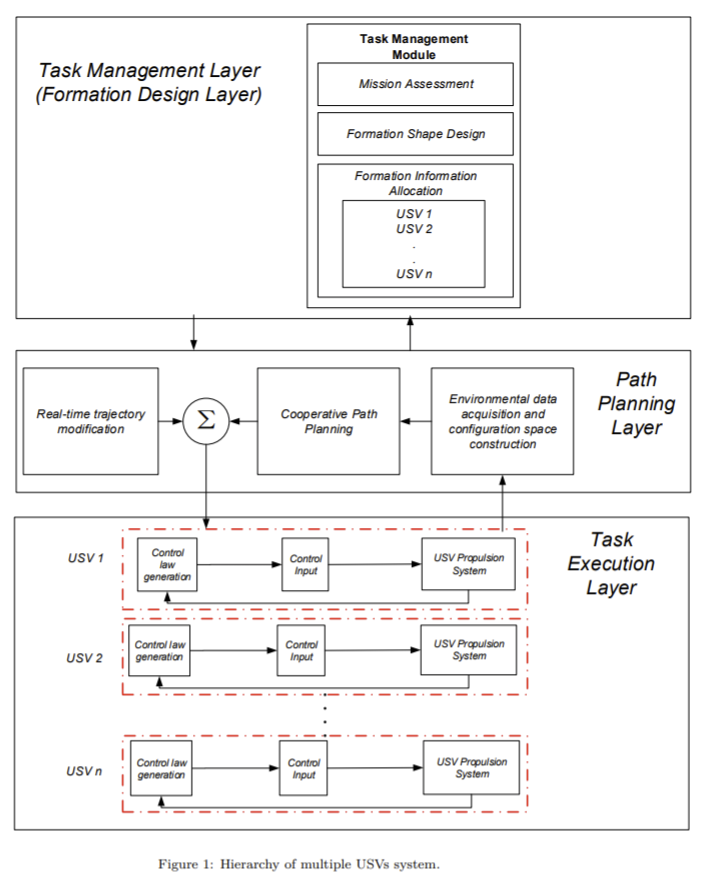
感想:拡張性
- ランド研究所のレポートの結論でも述べられてましたが、この方法では、あらかじめ設定したエンティティ数以上のエンティティには対応できません。このためレポートでは、戦場をグリッド化して対応する案が提案されています。この場合、扱える敵のエンティティ数は任意にできるのですが、味方のエンティティ数はやはりあらかじめ最大値を決めておく必要があると思われます。
- この制約を取り払うには、例えば、各エンティティを自律エージェントとみなして、マルチエージェント強化学習を適用することが考えられます。ただし、マルチエージェント強化学習は、学習が強化学習よりもさらに困難で Long way to go なレベルです。
感想:自律分散システム(Autonomous)というアプローチ
- 今回のアプローチは、AlphaStar 等と同じく、中央集権的なプランニングでした。これとは別のアプローチとして、Hide & Seek 等のように、自律エージェントによる分散自律的なアプローチが考えられます。上記のマルチエージェント強化学習はその一例です。実際に戦闘を行う現場の箱物の視点からは、自律システムの方が有用だと考えられます。一方、C4I(Command, Control, Communication, Computer and Intelligence, 指揮統制系)という視点からは、今回のようなアプローチも有用だと思います。現実問題としては、この2つの両極にあるアプローチの中間点が取られることになるものと想像できますが、今後どこでどうバランスがとられた全体システムの研究につながっていくのか楽しみです。
感想:実世界の問題に強化学習は使えるのだろうか?
- 今回の問題設定は、実際の問題を極限までシンプルにした設定です。にもかかわらず、(少なくとも、私のビンテージマシンでは)、数日の学習が必要でした。囲碁やAtariのゲームも現実世界の問題に比べると極めてシンプルです。
- DeepMind, OpenAI, UC Berkeleyといった先端研究機関の研究でも、現実世界の問題は未だ遥か彼方な感じがします。かなりのBreak through が無い限り、現実世界の問題に対して使うのはなかなか難しいのではないかという気がします。
- 或いは、深層強化学習も、かつての Optimal Control や Robust Control と同じような道をたどるのでしょうか?
反省:巨大化するCodeの取り扱い
- 必要なものをその都度追加していったので、いつの間にかコードが巨大化してしまいました。やはり、モジュールに分割して作った方が、デバッグが楽です。
追記:別の題材で、マルチエージェント強化学習の応用を取り扱った記事を書き始めました。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上
- ランド研究所の「機械学習による航空支配」を実装する(その7):1D simulator for RL の実装
- ランド研究所の「機械学習による航空支配」を実装する(その8): Stable Baselines による強化学習
- ランド研究所の「機械学習による航空支配」を実装する(その9): 少し複雑な環境
- ランド研究所の「機械学習による航空支配」を実装する(その10):GAN / 強化学習プランナーの連携を考える
- ランド研究所の「機械学習による航空支配」を実装する(その11): 2次元問題の概要
- ランド研究所の「機械学習による航空支配」を実装する(その12): 2D simulator for mission_1 の実装
- ランド研究所の「機械学習による航空支配」を実装する(その13): 2D 問題 mission_1 を強化学習する
- ランド研究所の「機械学習による航空支配」を実装する(その14): Relative Observation による mission planner の能力アップ
- ランド研究所の「機械学習による航空支配」を実装する(その15): 2D問題 mission_2
- ランド研究所の「機械学習による航空支配」を実装する(その16): 2D問題 mission_3
- ランド研究所の「機械学習による航空支配」を実装する(その17): 2D問題 mission_4
- ランド研究所の「機械学習による航空支配」を実装する(その18): 2D問題 mission_4 Reward shaping による改良