本記事は、ランド研究所の「機械学習による航空支配」を実装する(その10)です。
作成したコードは GitHub にあります。今回使用する環境は、'rllib' フォルダにある 'myenv.py'、トレーニング用のコードは、'training_actor_critic-v0.py' です。
過去の記事へのリンクは最下段にあります。
1. はじめに
ランド研究所のレポートでは、1D 問題に対し GAN と強化学習という2種類のアプローチをとっています。そして、1D 問題に対するレポートはそこで唐突に終わっています。また、1D 問題に続く 2D 問題では、理由の記載はなく、強化学習のみが使われています。
GAN と強化学習夫々に対する何らかのコメントぐらい書いてもらえれば、多少は彼らの考えが想像できるのですが、記載は0です。せっかくやったのにもったいないと思ったので、1D 問題を通して感じたことを元に、GAN と強化学習の連携を試みました。
2. GAN プランナー と RL(強化学習)プランナー の特徴を活かした連携
1D 問題を通して感じたことは、GAN プランナーは、比較的大きな時空間で、ざっくりとしたプランを生成するのに適し、RLプランナーは、もっとリアルタイムよりの比較的小さな時空間で、タイムステップ毎のプランを生成するのに適しているということでした。
また、強化学習は一般的に言って学習が難しいのですが、これまでの記事のように、ミッション成功時点でのみ報酬が得られるようなプランでは、特に学習が困難になります。
こういった経験を元に、GAN プランナーと RL プランナーを連携させる方法を考えます。思いついた方法としては、
(1) RL プランナーの学習時に、GAN プランナーを利用して学習し易くする。実行時(テスト時)は、RL プランナーのみを利用する。
(2) if - then rule のようなものを使って、SAM に近づくまでは GAN プランナーを利用し、SAMに近づいたら RL プランナーに切り替える。したがって、実行時(テスト時)も、GAN プランナーと RL プランナーの両方を利用する。
(2) のアプローチについては、少なくとも 1D 問題では、やれば上手く行くと思ったのでやりませんでした。
今回は、(1) のアプローチをとります。やっていることは難しいことではありません。単なる報酬シェーピング(reward shaping)です。Blue team である fighter や jammer が、SAM から遠方にいる時に、GAN プランナーのプランに近づくことに対しインセンティブを与えるように、各タイムステップで小さな報酬を与えているだけです。また、GAN プランナーは事前にトレーニングしておいて、強化学習中は GAN プランナーは固定で使用します。
GAN プランナーで生成したプランを利用しているのは、コードでは以下の報酬を定義している部分です。Fighter, Jammer 夫々が、GAN プランナーの提示したプランよりも一定距離以遠にいる場合、アクションの結果 GAN プランナーのプランに近づいた場合には、近づいた距離に応じた正の報酬、遠ざかった場合には遠ざかった距離に応じた負の報酬を与えています。一定距離以遠としている理由は、以下の通りです。
- GAN プランナーのプランが 100% 正確という訳ではない。
- Jammer, Fighter の進出タイミングの制御は強化学習だけに任しているので、強化学習でタイミングをうまく制御するには、ある程度 SAM から遠い所から制御し始める必要がある。
- SAMまでの距離が近ければ、ピュアな強化学習でも学習できる可能性が高い。
一定距離(変数名は、plan_margin)としては、プランの 1/2 の距離としてみました(Fighter と Jammer が SAM にある程度近づけば、あとは報酬シェーピング無しの強化学習で学習できるはずなので、全く適当に決めただけです)。また、(self.fighter_speed * self.dt)=1, step_reward_coef=0.1としています。したがって、各タイムステップでの報酬は、[-0.1, 0.1]の範囲で、GANプランナーのプランに接近又は離隔に応じて与えられることになります。
def get_reward_1(self, done):
"""
Reward for GAN + RL planner architecture
"""
reward = 0
step_reward_coef = STEP_REWARD_COEF
plan_margin = PLAN_MARGIN
# For each time step
fighter_x = self.fighter.plan * plan_margin - self.fighter.ingress
fighter_previous_x = self.fighter.plan * plan_margin - self.fighter.previous_ingress
fighter_dx = fighter_previous_x - fighter_x
if fighter_x > 0:
reward += fighter_dx / (self.fighter.speed * self.dt) * step_reward_coef
jammer_x = self.jammer.plan * plan_margin - self.jammer.ingress
jammer_previous_x = self.jammer.plan * plan_margin - self.jammer.previous_ingress
jammer_dx = jammer_previous_x - jammer_x
if jammer_x > 0:
reward += jammer_dx / (self.fighter.speed * self.dt) * step_reward_coef
# For done
if done:
if (self.fighter.alive > .5) and (self.jammer.alive > .5) and (self.sam.alive < .5):
reward += 1
else:
reward += -1
return reward
また、問題を少し難しくするために、エージェントが採ることが出来るプラン(アクション)を、Fighter, Jammer の前進と停止だけではなく、後退も可能にしました。Fighter, Jammer の前進を+1,停止を0,後退を−1で夫々表すこととすると、Agent は、以下の9つのアクションから、一つアクションを選択することになります。
ACTION_DIM = 9
ACTION_LIST = [[-1, -1], [-1, 0], [-1, 1],
[0, -1], [0, 0], [0, 1],
[1, -1], [1, 0], [1, 1]]
3. 強化学習ツールについて
ここで一つ小さな問題があります。
GAN プランナーは、Tensorflow 2 で作りました。一方、これまで強化学習のツールとしては、Stable Baselines を使用してきましたが、Stable Baselines は Tensorflow 1 にしか対応していません。今更、もう一度、GAN を tensorflow 1 で作って学習し直すエネルギーは私にはありません。
このため、ここでの強化学習ツールは RLLIB を使用しました。ランド研究所のレポートが OpenAI Baselines を使っているようだったので、それの改良版である Stable Baselines を使って来ましたが、最初から RLLIB を使えばよかったですね。(そこまでのビジョンはありませんでした)。
RLLIB は、分散処理用フレームワークである ray の上で走る強化学習用ライブラリです。Stable Baselines と同様、SAC や PPO 等の各種の強化学習アルゴリズムが用意されています。使い勝手も Stable Baselines と似ています。ただ、オリジナルコード(GitHub で見られます)の解読が、Stable Baselines よりもずっと難しいのが難点です。
幸い、学習用のコードは、最小限の変更だけで大丈夫です。(OpenAI Gymに登録して使う方法が判らなかったので、登録せずに使うよう変更しています)。
4. 学習履歴
4.1 Baseline environment
ベースライン環境では、Fighter, Jammerの初期位置を 0 に固定して学習ました。
GAN プランナーを用いたほうが、少し学習は早くなるようですが、問題自体が簡単なので大差はありません。
図4.1

4.2 Hard Environment
Fighter, Jammer の初期位置を [-100, 0] km の間でランダムに変えて学習しました。初期位置が、マイナス方向に振れるほど、SAM との初期相対距離が広くなってゆくので、SAM に到達するまで、右移動を数十回継続しなければなりません。これは、強化学習にとっては、厳しい条件です。
この場合、GAN プランナーを用いる効果は絶大です。GAN プランナーを用いない場合、成功率は 70% 以下となってしまいます。
図4.2

下図表で結果の内訳を見ると、RL のみを使った場合は w2 の条件で成功できるプランを全く生成できない(成功率 = 0%)ことが判ります。後で生成プランを示しますが、RL のみでは、w2 に対しては、Jammer も Fighter もほとんど動かすことができず、タイムアウトとなるプランしか生成できていません。GAN プランナーを補助的に使って学習することで、成功するプランを生成できるように学習できるようになりました。
表4.1
![Success ratio [%] of RL agent vs RL+GAN agent___ _w1_w2_w3 RL_99.4_0_98.5 RL+ GAN_99.8_98.5_100.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2F68cc2bf6-4230-e58a-2f6d-db576a2007f3.jpeg?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=2320523e9a273276f627c9d01e80909e)
図4.3
![Success ratio [%].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2Fcc03eca4-bc1a-4bf8-1daf-a36ad85a780e.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=b2f1364659ee6a49ee070b9c381afa8c)
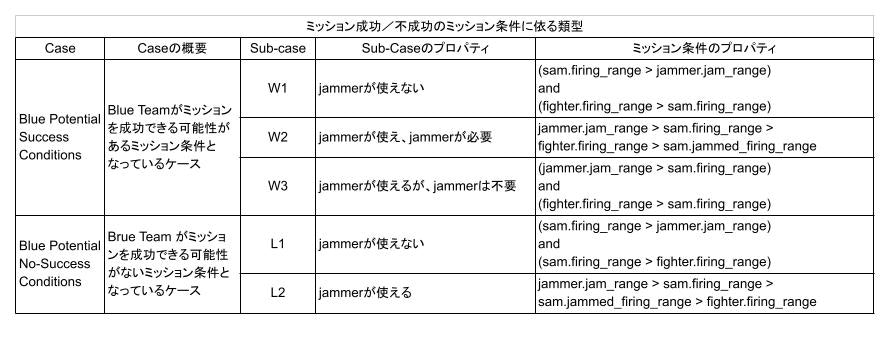
なお、再録ですが、ミッション条件 w1, w2, w3 は以下の通りです。
表4.2
5. 生成プランの例
以下の動画で、青の小さい丸がGANプランナーが示したFighterの進出プラン位置、水色の小さい丸がGANプランナーが示したJammerの進出プラン位置です。その他は、(その9)までと同じで以下のとおりです。
濃紺の丸が Fighter、半透明で濃紺の大きな円が Fighter の射程、緑色の丸が Jammer、半透明で緑色の大きな円が Jammer の有効レンジ、赤の丸が SAM 配備位置 、半透明で赤色の大きな円が SAM の射程を表しています。SAM の射程を表す円は、ジャミングを受けると、それに対応した大きさの円に変わります。また、Fighter, Jammer, SAM が一直線上に並んでいませんが、これは単に見やすくするために Fighter と Jammer 位置を少しだけオフセットさせて表示しているためです。計算は、1次元上の交戦となっています。
5.1. w1
5.1.1. RL
Jammer は前進させずに Fighter のみ前進させるプランを生成します。
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -92.0,
"ingress": 13.0,
"firing_range": 37.0
},
"jammer": {
"alive": 1,
"initial_ingress": -24.0,
"ingress": -42.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 50.0,
"firing_range": 35.0,
"jammed_firing_range": 24.5
}
}

5.1.2. RL + GAN
(1) Fighter が先行するミッション条件
Fighter, Jammer ともに、GAN プランナーのプランに近づくようインセンティブが与えられているので、両者とも SAM に接近します。先行した Fighter には、(不要なのですが) Jammer の進出を待つ傾向がみられます。
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -25.0,
"ingress": 59.0,
"firing_range": 34.0
},
"jammer": {
"alive": 1,
"initial_ingress": -91.0,
"ingress": 49.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 93.0,
"firing_range": 32.0,
"jammed_firing_range": 22.4
}
}

(2) Jammer が先行するミッション条件
Jammer が先行するミッション条件の場合は、Jammer は GAN プランナーのプラン辺りの SAM の射程外で待機し、Fighter だけを前進させるプランを生成します。
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -77.0,
"ingress": 9.0,
"firing_range": 37.0
},
"jammer": {
"alive": 1,
"initial_ingress": -53.0,
"ingress": 2.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 46.0,
"firing_range": 31.0,
"jammed_firing_range": 21.7
}
}

5.2. w2
5.2.1. RL
Fighter, Jammer ともに進出しきれずに滞空してしまうプランしか生成できず、タイムアウトでミッションに失敗します。
{
"Mission": "Failed",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -57.0,
"ingress": 20.0,
"firing_range": 21.0
},
"jammer": {
"alive": 1,
"initial_ingress": -70.0,
"ingress": -36.0,
"jamming": 0
},
"sam": {
"alive": 1,
"offset": 87.0,
"firing_range": 24.0,
"jammed_firing_range": 16.799999999999997
}
}

{
"Mission": "Failed",
"mission_condition": "w2",
"fighter": {
"alive": 0,
"initial_ingress": -49.0,
"ingress": 14.0,
"firing_range": 21.0
},
"jammer": {
"alive": 1,
"initial_ingress": -63.0,
"ingress": -26.0,
"jamming": 0
},
"sam": {
"alive": 1,
"offset": 36.0,
"firing_range": 22.0,
"jammed_firing_range": 15.399999999999999
}
}

5.2.2. RL + GAN
(1) Jammer が先行するミッション条件
先行して進出した Jammer は、GAN プランナーのプラン位置辺りで滞空し、Fighter が近づくのを待ちます。Fighter が接近すると、SAM に妨害をかけることが出来る位置まで進出し SAM に妨害をかけて SAM の射程を縮退させます。そこへ Fighter を進出させるプランを生成します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -95.0,
"ingress": 30.0,
"firing_range": 24.0
},
"jammer": {
"alive": 1,
"initial_ingress": -6.0,
"ingress": 21.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 54.0,
"firing_range": 27.0,
"jammed_firing_range": 18.9
}
}

(2) Fighter が先行するミッション条件
Fighter は SAM に接近したところで待機し、その間に Jammer を進出、先行させて SAM に妨害をかけさせます。そして、SAM の射程が縮退したところで Fighter を進出させるプランを生成します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -34.0,
"ingress": 13.0,
"firing_range": 23.0
},
"jammer": {
"alive": 1,
"initial_ingress": -87.0,
"ingress": 7.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 36.0,
"firing_range": 26.0,
"jammed_firing_range": 18.2
}
}

(3) Fighter, Jammer が同程度の距離からミッションが始まる時
Fighter, Jammer は一緒に進出しますが、SAM に接近したところで Fighter が待機して Jammer が先行し、SAM に妨害をかけます。そして SAM の射程が縮退したら Fighter を前進させるプランを生成します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -57.0,
"ingress": 58.0,
"firing_range": 17.0
},
"jammer": {
"alive": 1,
"initial_ingress": -67.0,
"ingress": 53.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 75.0,
"firing_range": 19.0,
"jammed_firing_range": 13.299999999999999
}
}

5.3. w3
5.3.1. RL
Jammer は使わずに SAM だけで対処するプランを生成します。
{
"Mission": "Success without using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -32.0,
"ingress": 5.0,
"firing_range": 29.0
},
"jammer": {
"alive": 1,
"initial_ingress": -5.0,
"ingress": -33.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 34.0,
"firing_range": 28.0,
"jammed_firing_range": 19.599999999999998
}
}

{
"Mission": "Success without using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -92.0,
"ingress": 56.0,
"firing_range": 24.0
},
"jammer": {
"alive": 1,
"initial_ingress": -81.0,
"ingress": -4.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 80.0,
"firing_range": 23.0,
"jammed_firing_range": 16.099999999999998
}
}

5.3.2. RL + GAN
Fighterが先行するミッション条件でも、Jammer が先行するミッション条件でも、Fighter, Jammer は、インセンティブに従って GAN プランナーのプラン近傍まで進出します。しかしながら、Jammer を進出させすぎることはありませんでした。Jammer を使用するか否かは、その時のタイミング次第のようです。
(1) Fighterが先行するミッション条件
(不要なのですが)、Jammerの進出を待つ傾向が見られます。
{
"Mission": "Success with using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -10.0,
"ingress": 57.0,
"firing_range": 23.0
},
"jammer": {
"alive": 1,
"initial_ingress": -42.0,
"ingress": 53.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 80.0,
"firing_range": 17.0,
"jammed_firing_range": 11.899999999999999
}
}

(2) Jammer が先行するミッション条件
Jammer は進出後に待機し、Fighterが進出するプランを生成します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -89.0,
"ingress": 36.0,
"firing_range": 24.0
},
"jammer": {
"alive": 1,
"initial_ingress": -23.0,
"ingress": 28.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 60.0,
"firing_range": 23.0,
"jammed_firing_range": 16.099999999999998
}
}

6. まとめ
GAN Planner が提示するプランに近づくようインセンティブを与えて強化学習する、つまり、GAN Planner が提示したプランに近づくか遠ざかるかによって正又は負の報酬を与えるように報酬シェーピングして強化学習することで、ピュアに強化学習だけ使うよりも、良い結果が得られることが判りました。
当然ですが、報酬シェーピングした場合に生成されるプランは、報酬シェーピングしない時に生成されるプランとは異なる特性を持ちます。欲しい特性を持ったプランを生成するプランナーをトレーニングするには、ドメイン知識を活かして報酬シェーピングする必要があることが判りました。
(その11)へ続く
1D 問題は今回で終了です。(その11)からは、ランド研究所のレポートに従って 2D 問題を取り扱います。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上
- ランド研究所の「機械学習による航空支配」を実装する(その7):1D simulator for RL の実装
- ランド研究所の「機械学習による航空支配」を実装する(その8): Stable Baselines による強化学習
- ランド研究所の「機械学習による航空支配」を実装する(その9): 少し複雑な環境