(その3)では、下記ランド研究所のレポートにある1次元問題のシミュレータを実装します。(レポートには細部が全く書かれていないので、止むを得ず、ほとんど独断で実装します)。
Air Dominance Through Machine Learning: A Preliminary Exploration of Artificial Intelligence–Assisted Mission Planning, 2020
ここで実装するのは GAN (Generative Adversarial Networks) のトレーニング用のシミュレータで、強化学習用のシミュレータは別途実装することにしました。
また、GAN のトレーニング用のデータを生成するために、ランダム・プランナーも実装します。ランダム・プランナーは、GANプランナーの性能を比較するためのベースラインにもなります。
作成した Codes は下記 GitHub にあります。
GAN は(その4)で実装します。
過去記事へのリンクは最下段にあります。
1. ミッション・プランニング問題再考
いろいろな考え方があるとは思いますが、ここでは、戦闘が、作戦レベルのプランニングと、実際に現地で兵刀を交える戦闘レベルの戦術から成るものと考えます。
作戦とは、いつ、どこに、どういった構成と規模の戦闘パッケージを送り込むかといった、比較的大きな時空間ベースのマクロなプランニングと定義します。ランド研究所のレポートが取り扱っているのはこちらです。
一方、戦術は、自軍のどのユニットが相手のどのユニットを、どういった方向や距離から、どういった武器で攻撃し、相手の攻撃をどういった動きでかわすのかといった、どちらかと言えば短い時空間でのプランニングと定義します。具体的な例としては、DARPAのACEProgramが挙げられるます。
実際には、マクロなプランの結果が、ミクロなプランに影響を及ぼし、翻ってミクロなプランの結果がマクロなプランに影響を与えるため、複雑系で言うマクロ/ミクロ・ループを形成します。したがって、両方を統合的に取り扱って、作戦と戦術を同時に創発するよう AI をトレーニングすることが、望ましい姿です。しかしながら、現在の AI 技術でマクロ/ミクロ・ループを処理出来るのは、AlphaStar クラスの RTS (Real Time Simulation) ゲームまでで、それとてもコーディングと学習には Google レベルのリソースが必要です。私+ビンテージマシンでは無理です。
そこで、本記事では、ランド研究所と同じように、ミッション・プランニング問題をマクロな作戦レベルのプランニング問題と捉え、ミクロな戦術は取り扱わないこととしました。つまり、Fighter 搭載ウェポンや SAM のミサイル速度は無限大で一瞬で(厳密には、シミュレーションのステップ幅の中で)決着がつくレベルの時空間を前提とします。加えて、問題を簡単にするために、これらの性能は完璧であると仮定します。ランド研究所のレポートでも、プランニングの内容は、Fighter, Jammer の進出距離と進出タイミングとなっていて、ウェポンの速度や確実性はモデリングした形跡がないので、同じように仮定しているはずです。作戦レベルの標準シミュレータである AFSIM の方では、結果としてその影響が出るシミュレーションになっているとは思いますが、すくなくとも AI の学習を行った AFGYM の方では、そこまでやった形跡はありません。
以上を踏まえて、トレーニング済みの GAN で生成したプランを使って、シミュレーションを行う全体イメージを下図に示します。実際に運用するとしたら、シミュレータ部分が現実世界に置き換わります。
GAN は、Generator と Discriminator (Critic) で構成されますが、ミッション・プランの生成は Generator で行います。Discriminatorは、GAN のトレーニングの時にしか使いませんが、これは普通の GAN と同じ使い方です。
シミュレータは、ミッション条件とミッション・プランが与えられた時に、Blue Team と Red Team の交戦をシミュレーションし、ミッションの成否を返します。
図1

2. GAN トレーニングのための 1D シミュレータの実装
シミュレータは、強化学習でいうところの環境に対応するもので、図1の 1D Simulator For GAN になります。
GitHubの実装コードではsimple_1D_simulator_for_gan.pyになります。
2.1 ミッション成功の定義
はじめに、ミッション成功 の定義が必要です。ここでは、ランド研究所のレポートに従って、Fighter 1機, Jammer 1機 のパッケージから成る Blue Team を考えます。Red Team は SAM 1基 のみです。
ここで、Blue Teamが「ミッションに成功したプラン」とは、与えられたミッション条件の下で、ミッション・プランに従って行動した時に、SAM を撃破でき、且つ、Fighter と Jammer がともに生き残ったプランと定義しました。それ以外のプランは、すべて「ミッションに成功しなかったプラン」としました。したがって、「ミッションに成功しなかったプラン」には、Fighter、Jammer のいずれかが撃墜されたプランのみならず、Fighter, Jammer, SAM のすべてが生き残ったプランや、すべてが破壊されたプランのような引き分けプランも含みます。この辺りは、「ミッション成功」をどう定義するかに依存します。レポートでどう定義しているのかは判りませんでした。
2.2 ミッション・プランナーとのインタラクション
ミッション条件は、ランド研究所のレポートに従って、
Fighter の射程(fighter.firing_range)
SAM の位置(sam.offset)
SAM の射程(sam.firing_range)
ジャミングを受けた時の SAM の射程(sam.jammed_firing_range)
の4つとしました。数値は、(その2)記載の Table 2.2 の範囲でランダムに(一様分布で)生成します。SAMに対して、Jammer のジャミングが有効となる距離は一定値(30km)なので、条件からは除外しています。Fighter, Jammer のスピードも一定値としているため条件に入れていません。これらは、POC (Proof of Concept) のレポートなので問題を簡素にしている故だと思われます。
ミッション・プランナーは、これらの量を受け取って、プランを出力します。プランは、これもランド研究所のレポートに従って、
Fighter の進出距離(fighter.ingress)
Jammer の進出距離(jammer.ingress)
の2つとします。(その2)記載のTable 2.3 の Lead Distance は、レポートと同様に省略します。プランの数値範囲は、(その2)の Table2.4 に従うものとしました。シミュレータは、これらのプランをプランナーから受け取って、ミッション条件に従ってシミュレーションを行います。
2.3 シミュレータの仕様
シミュレータですが、step_by_step で交戦を模擬する AFGYM っぽいものを実装しても良いのですが、それは強化学習を実装するときに行うことにしました。ここでは極限まで簡素にしたものを実装して、手っ取り早くトレーニング・データを作って、GAN でどこまでできるのか確認してみます。ランド研究所のレポートでも、Fighter と Jammer の進出タイミング(Jammer Lead Distance)が GAN の実装では省略されていること、「step_by_stepのシミュレーションではない」などとさり気なく記載してあるあることから、同じように進めたのではないかと感じています。
シミュレータの仕様は以下となります。(あくまで原理検証用なので、かなり乱暴です)。
<GANのトレーニング用に実装した簡素なシミュレータの仕様>
AFGYM の設定に合わせた仕様:
- レーダ方程式等の計算は一切しない
- エージェントは、あらかじめ決められた範囲内に相手がいれば自動的に攻撃する
- EW(Electorical Warfare, 電子戦)の計算は一切せず、単純に SAM の射程のパーセント減少として計算する。
追加で明記した仕様:
- SAM と Fighter 搭載ウェポンの速度は非常に早く、射程内に入った瞬間(シミュレーションの1ステップ以内)に相手を撃破できる。
- SAM ミサイル と Fighter 搭載ウェポン の攻撃能力は 100%、つまり SAM も Fighter も射程内に入った相手を 100% 確実に撃破できる。
- Jammer は、jammer.jam_range(30km)内に SAM が入った瞬間に、SAM の射程を一挙に 70% 縮退させる(70% は、Figure 2.1、Figure 2.2で、100km →70km となっていることから設定したものです。)
ここまで問題を簡単にすると、step_by_step のシミュレーションをしなくても、(つまり、強化学習のように MDP (Markov Decision Problem) として問題を定式化しなくても)、ミッションの成否が計算できるので、成否を計算するシミュレータをコーディングしました。
※ やがて実装する強化学習は、step-by-step であるマルコフ決定過程(MDP: Markov Decision Process)を前提としているので、これから実装するGAN を使ったプランニングに比べると、step-by-step の意思決定が要求される戦闘レベルのプランニングにより親和性があるように思います。
2.4 Blue Team が成功できるミッション条件と成功できないミッション条件
ここでシミュレータの実装に行きたいところなのですが、実装する前に、実装するシミュレーション環境(つまり、Blue team と Red team の交戦の様子)がどういうものなのかを調べて把握しておきます。これは、メンドーではあるのですが、一方で実装の方向性を決める上で大いに助けになる作業でもあります。
はじめに、ミッション条件について考えます。
(その2)記載の Table 2.2 のミッション条件は、いろいろな考え方で分類できると思いますが、私は Blue チームにミッション成功の可能性があるのか、無いのかに従って、次の表に示すように5つに分類しました。
表2.1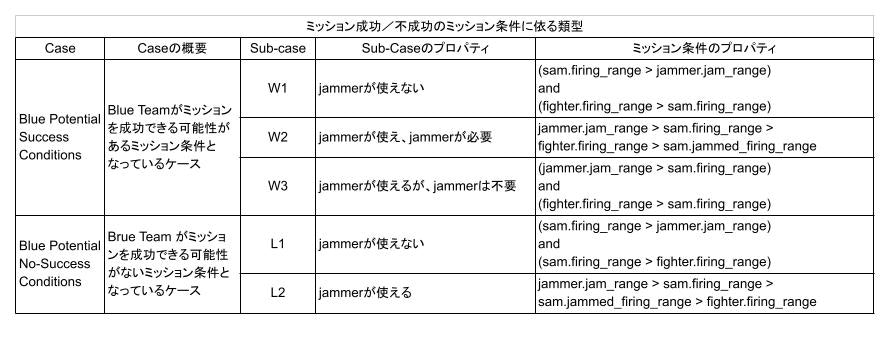
Blue Potential Success Condition とあるのは、適切なプランさえあれば、Blue Team がミッションを成功できるようなミッション条件となっているケースです。これは、さらに w1、 w2、 w3 の3つに分類できます。
ケース w1 は、Jammer のジャミングが SAM に対して有効とできるレンジ(jammer.jam_range)よりも、SAM の射程(sam.firing_range)が長いため、Jammer は使えないのですが、実は Fighter 搭載ウェポンの射程(fighter.firing_range)が SAM の射程よりも長いために、Jammer を使わなくても、Blue Team は SAM を撃破できるケースです。つまり、下図のような交戦状況です。ここで、濃紺の丸が Fighter 進出距離 (fighter.ingress)、半透明で濃紺の大きな円が Fighter の射程 (fighter.firing_range)、水色の丸が Jammer 進出距離 (jammer.ingress)、半透明で水色の大きな円が Jammer の有効レンジ (jammer.jam_range)、赤の丸が SAM 配備位置 (sam.offset)、半透明で赤色の外側の大きな円が、クリーンな状態での SAM の射程 (sam.firing_range)、内側の大きな円がジャミングを受けた時の SAM の射程 (sam.jammed_firing_range) になります。この内、ミッション・プランは、fighter.ingress と jammer.ingress で、これを生成するのが GAN プランナーの役割です。fighter.firing_range 等、その他の量は、ミッション条件としてランダムに与えられます。
図2.1

ケース w2 は、Fighter 搭載ウェポンの射程(fighter.firing_range)が SAM のクリーンな射程(sam.firing_range)よりは短いものの、ジャミングを受けた時の SAM の射程(sam.jammed_firing_range)よりは長いケースです。加えて、Jammer のジャミングが SAM に対して有効とできるレンジ(jammer.jam_range)が、SAM の射程よりも長いため、Jammer を適切に配置することで、Blue Team は SAM を撃破することが可能になります。つまり、下図のような交戦状況です。
図2.2

ケース w3 は、w1 と似ていて、Fighter 搭載ウェポンの射程(fighter.firing_range)が SAM の射程(sam.firing_range)よりも長いために、Jammer を使わなくても、Blue Team は SAM を撃破できるケースです。ただし、w1と異なり、Jammer のジャミングが SAM に対して有効とできるレンジ(jammer.jam_range)がSAM の射程よりも長いため、(Jammer の前進は不要ですが)、Jammer を前進させることが可能なケースです。つまり、下図のような交戦状況です。
図2.3

一方、表2.1で Blue Potential No-Success Conditions とあるのは、どんなプランを用意しても Blue team がミッションを成功できない条件です。この条件は、Jammerが使える場合(ケース l1)と使えない場合(ケース l2)に分けることができます。
数学に強い人なら、先の表2.1から各ケースの割合(確率)をさくっと計算できるのでしょうが、私は考えても判らなかったので、モンテカルロ法で計算しました。下の表がそれです。
表2.2

この表から、ミッション条件を一様分布からランダムにサンプルした場合、そのミッション条件が Blue Team がミッションに成功できる可能性がある条件となっている割合(あるいは確率)は最大でも 58.44% 、成功できない(引き分けを含む)条件となっている割合は 41.56% あることが判ります。したがって、ミッション・プランナーがうまく学習できたか否かは、様々な(一様分布からサンプルした)ミッション条件が与えられた時に、Blue Team の平均勝率が理論上の上限値である 58.44% にどれだけ近いかで測ることができます。
この数値は、この後、何度も使うので、すぐに探せるようにグラフ化しておきましょう。
図2.4

また、w1, w2, w3 の割合は、W1 が 3.13%, w2 が 8.44%、w3 が 46.88%になっています。したがって、プランナーのプランに従った場合にミッションに成功したケースの割合とこれらの数値と比較すれば、どのケースが学習しやすく、どのケースが学習しにくいのか判断できます。
これも、すぐに探せるようにグラフ化しておきます。
図2.5
![Breakdown of Potential Success [%] .png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2Fda602698-9614-f72f-058d-7cbfa0864ba1.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=5a578c2b2587a15a60eb1c965ce011f9)
この部分の実装は、実装コードでは、以下になっています。
if (sam.firing_range > jammer.jam_range) and (fighter.firing_range > sam.firing_range):
mission = 'w1'
self.w1.setter(mission, fighter, jammer, sam)
if jammer.jam_range > sam.firing_range > fighter.firing_range > sam.jammed_firing_range:
mission = 'w2'
self.w2.setter(mission, fighter, jammer, sam)
if (jammer.jam_range > sam.firing_range) and (fighter.firing_range > sam.firing_range):
mission = 'w3'
self.w3.setter(mission, fighter, jammer, sam)
if (sam.firing_range > jammer.jam_range) and (sam.firing_range > fighter.firing_range):
mission = 'l1'
self.l1.setter(mission, fighter, jammer, sam)
if jammer.jam_range > sam.firing_range > sam.jammed_firing_range > fighter.firing_range:
mission = 'l2'
self.l2.setter(mission, fighter, jammer, sam)
2.5 ランダム・ミッション・プランナーによる Blue Team の勝率
ミッション・プランナーの性能を比較するためのベースラインとして、ランダムにミッション・プランを生成するランダム・プランナーを作ります。
Blue Team がミッションに成功する条件は、以下の2通りになります。blue_win_condition_1 は、Jammer を使用せずにミッションに成功する条件、blue_win_condition_2 は、Jammer を使用してミッションに成功する条件です。
# Blue team win without using jammer
blue_win_condition_1 = (fighter.ingress < sam.offset - sam.firing_range) and \
(jammer.ingress < sam.offset - sam.firing_range) and \
(fighter.firing_range > sam.offset - fighter.ingress)
# Blue team wins with using jammer
blue_win_condition_2 = (jammer.jam_range > sam.firing_range) and \
(fighter.ingress < sam.offset - sam.jammed_firing_range) and \
(jammer.ingress + jammer.jam_range > sam.offset) and \
(jammer.ingress < sam.offset - sam.jammed_firing_range) and \
(fighter.firing_range > sam.offset - fighter.ingress)
モンテカルロ・シミュレーションにより、この条件に従って、ランダム・プランナーの性能を計算したのが下の表です。ランド研究所のレポートでは、ランダムに生成した(ミッション条件、プラン)の内 36%(私のシミュレータでは 10.54%)が成功したとのことなので、ランド研究所のプロジェクトでは、もっと成功し易い問題設定、或いはプラン設定になっているようです(やはり、先の表の通りに設定しているわけではなさそうです)。
表2.3

この表を見ると、ランダム・プランでは、成功できる可能性がある条件なのに成功できなかったプランが 47.86% あります。GAN プランナーには、この値を 0% に近づけ、勝率 10.54% を理論上の上限値である 58.44% に近づけるよう学習することが期待されます。全体の41.61% をしめる l1 と l2 については、プランナーがどうがんばってもミッションは成功しないミッション条件です。
ランダム・プランナーは、比較のためのベースラインとなるので、比較しやすくするためにミッション条件 w1, w2, w3 の成功率をグラフ化しておきましょう。
図2.6

ランダム・プランナーによるプランで実際に成功した割合(図2.6 の Success 部分)を、図2.5 と並べて書くと下図になります。ランダム・プランでは、特に w1, w2 のケースに成功することが難しいですね。
図2.7
![Breakdown of Succeeded Missions [%] (1).png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2Faddbaa6c-4f95-32ba-b891-6fd9fc801853.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=276194dd7e314bb923fb7c3f4439e0e8)
3. トレーニング、評価、テスト用データの生成
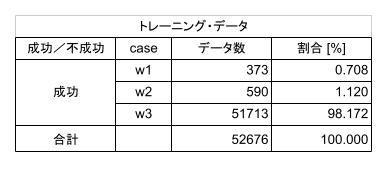
GAN のトレーニング用のデータは、ランダム・プランナーで生成したプランを使ってシミュレーションした結果から、成功した正例 52,676 個を選択して使用します。正例のみを使う理由は GAN の実装の際に述べます。52,676 個という数は、レポートの Table 2.6 にトレーニングデータ 50,000 個とあったことから決めました。ただ、実際に走らせてみた感じでは、こんなに要らないのではないかと感じました。内訳は、次の表のようになっています。
表3.1
ところで、AI の教師有り学習ではトレーニング・データは非常に重要です。良いミッション・プランナーを作るためには、良いトレーニング・データが必要です。今回のように、ランダムに生成したプランでは、例えミッションに成功したとしても、良いプランとは限りません。例えば、Fighter 搭載ウェポンの射程が SAM の射程よりも長く Jammer 無しでも SAM を撃破できるにもかかわらず、無意味に Jammer や Fighter を前進させて危険に晒すようなプランが含まれます。もちろん、今回のような簡単な問題では、プランの生成アルゴリズムを工夫して幾つか if-then ルールを入れれば、良いプランだけを生成できるのですが、それでは、if-then ルールでミッション・プランナーを作っているのか、AI を学習させているのか、だんだんわからなくなってしまいます。そこで、今回は、(レポートではどうしているのか判りませんでしたので)、悪いプランであっても、正例(成功したプラン)であればトレーニング・データとすることにして進めました。したがって、出来上がるミッション・プランナーも、良いプランを生成するプランナーというよりは、勝てはするプランを生成するプランナーになるはずです。
とは言え、そもそも良いプランの究極である最適なプランを生成するのであれば、GAN を使う必要はないはずです。この問題では、ミッション条件が決まれば、(最適の意味にもよりますが、たぶん)最適解が1つ計算できるはずです。一方、GAN は、確率的にプランを生成します。最適な1つのプランを見つけるのには向きません。では、「なぜランド研究所は敢えて GAN を使ったのか?」という疑問がわいてきます。おそらく、彼らが GAN を使った目的は、最適プランを生成するのが目的ではなく、「成功しそうなプランをたくさん生成して、それらから背後にある重要な何かを人が読み取って、シミュレータにはモデル化していないミッション・リスク等も考慮して、最終的には人がプランを作る」ことを想定しているのではないでしょうか。プロジェクトの目的が AI assisted ですし、現状のAIでは、なぜそのプランなのかまでは説明してくれませんから。
プランナーの性能を確認するための評価、テスト用のミッション条件も、一様分布からランダムにサンプリングして生成します。データ数は、それぞれ 100,000 ポイントとしました。評価とテストには、ミッション成功の可能性がある条件、ミッション成功の可能性がない条件の両方を使用しました。したがって、学習が上手く行っていれば、評価時もテスト時もミッションの成功率が、上限値である 58.44% に近づくはずです。
これらのミッション条件に対するランダム・プランナーに依るミッション実行結果は以下のとおりで、表2.3とほぼ同様の分布となっています。
表3.2

表3.3

(その4)へ続く
必要なシミュレータの実装とデータの準備ができましたので、(その4)では GAN を実装し、トレーニングを行います。