本記事は、ランド研究所の「機械学習による航空支配」を実装する(その5)です。
(その4)で、conditional GAN を使ったミッション・プランナーを実装し、トレーニングしました。
(その5)では、トレーニング結果を分析し、GAN が生成しようとしているプランを読み解きます。また、GAN の性能向上のための方策を考えます。
過去記事へのリンクは最下段にあります。
作成した Codes の GitHub のリンクは下記です。
1. トレーニング結果の概要
(その4)で、トレーニンしたGANプランナーは、全ミッションに対するミッション成功率が、理論上の達成可能な上限値 58.44%に対し 40% 強でした。
この結果は、(その3)で示したランダム・プランナーの成功率(10%)よりはずっと良いものの、まだまだ取りこぼしが多いという感じです。この原因を探るために、分析を行います。以下の分析では、学習がより安定していた Generator 最終層の活性化函数に "sigmoid" 函数を使ったものを使用しました。トレーニング・エポックは、せっかくビンテージ・マシンが丸1日学習のために働いてくれたので、最終エポック(2k epoch)のものを使用しました。
テスト・データ(テスト用のミッション条件)を使って、トレーニング中にミッション条件w1, w2, w3 に対する成功率がどのように変遷したのか見てみます。w1, w2, w3の定義は(その3)と同じですが、以下に示しておきます。
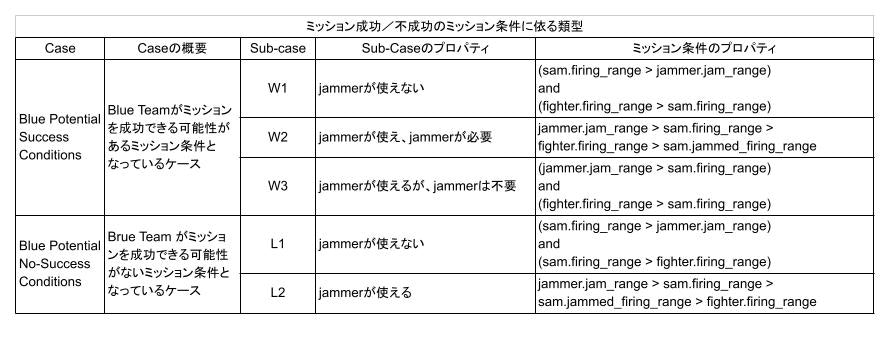
成功できる条件の下で、実際にも成功したミッション・プランにおける w1, w2, w3 の割合と、成功できなかったプランにおける w1, w2, w3 の割合を調べたのが下図です。全割合の合計は、成功率の理論的上限である 58.44% になります。w1、w2 (特にw1)では、ミッションが成功する(win)よりも、成功しない(not_win)割合のほうが高くなっているように見えます。
図1.1
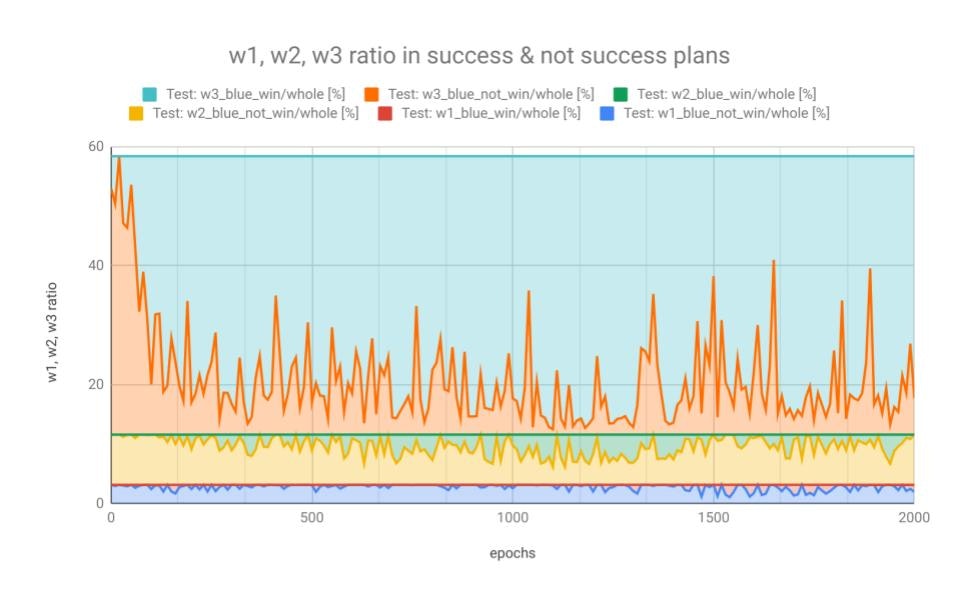
このままでは「見えます」としか言えないので、1000エポック以降は学習が飽和したと仮定して、1000から2000エポックの間の履歴を使って、w1, w2, w3 それぞれの成功率の平均を計算したのが下図になります。ミッション成功率は、上限58.44%に対して42.29%です。成功できる条件なのに、成功できるプランを生成できなかった割合は16.12%です。
図1.2
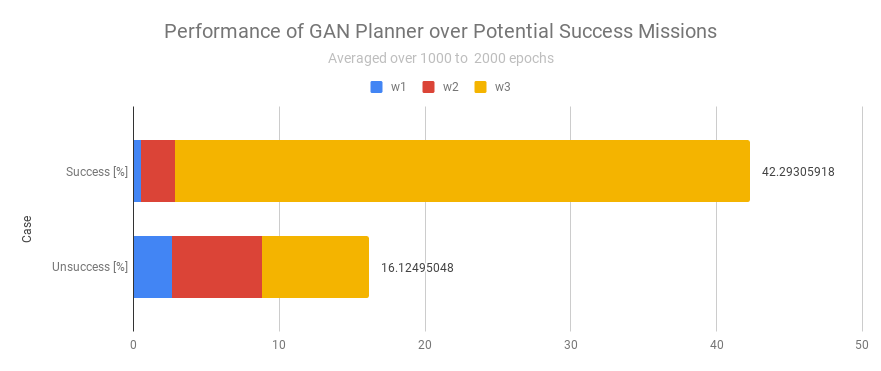
ランダム・プランナーの場合のこれに対応する図は下図でしたので、成功できるミッション・プランを生成できる割合はずっと高く(10.54% → 42.29%)なっています。
図1.3
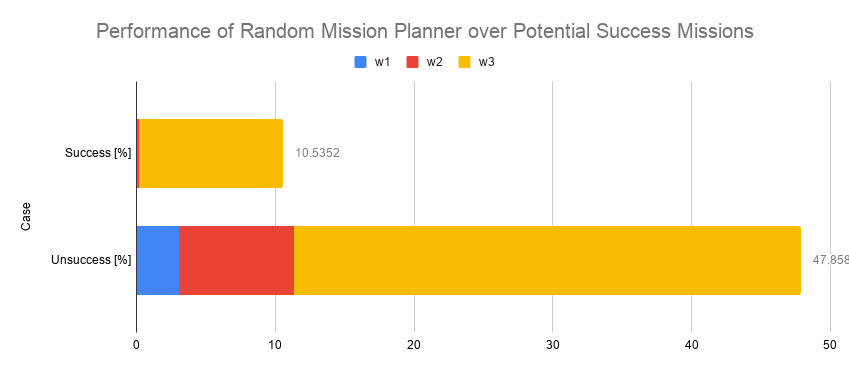
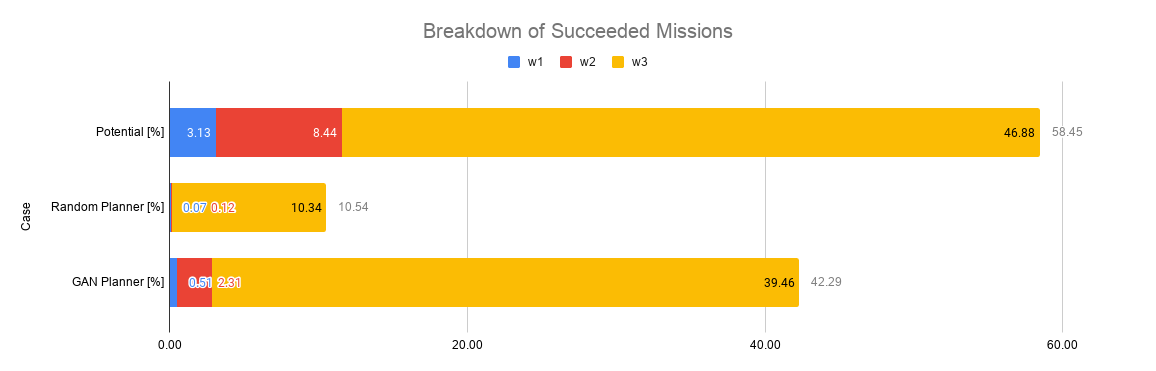
実際に成功したプラン42.29%(図 1.2 の Success 部分)だけを抜き出して、その内訳をランダム・プランナーの場合と比較したのが下図になります。Potential successとあるのは、理論上の上限値です。ランダム:プランナーに比べると、だいぶん上限値に近づきました。
図1.4
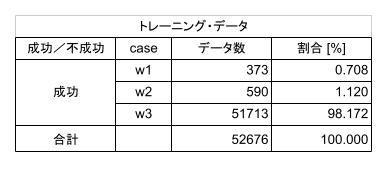
これらの図を見ると、w1 や w2 のケースがうまく学習できないようです。この原因は、トレーニングに使ったデータにあると考えられます。下表((その3)の表2.5)に示したように、トレーニング・データ 52,676 個の内訳は、w1 は僅か 373個(0.708%)、w2 は 590個(1.12%)、w3 は残りの 51713個(98.172%) となっていて、w1 や w2 のケースは、極端にデータ数が少なくアンバランスです。これでは、全体が w3 のデータに引っ張られるように学習してしまうはずです。
表1.1
2. GAN は、どのようなプランを生成しようとしているのか?
GAN プランナーが、どういったプランを生成しようとしているのか調べてみます。
このため、エポック=2000 のモデルを使用して、ランダムに選択した1つのミッション条件に対し、1000 ポイントのプランを生成し、統計を取って調べてみます。これは、GitHubのコードの"Run GAN Mission Generator and Check the performance.ipynb"になります。
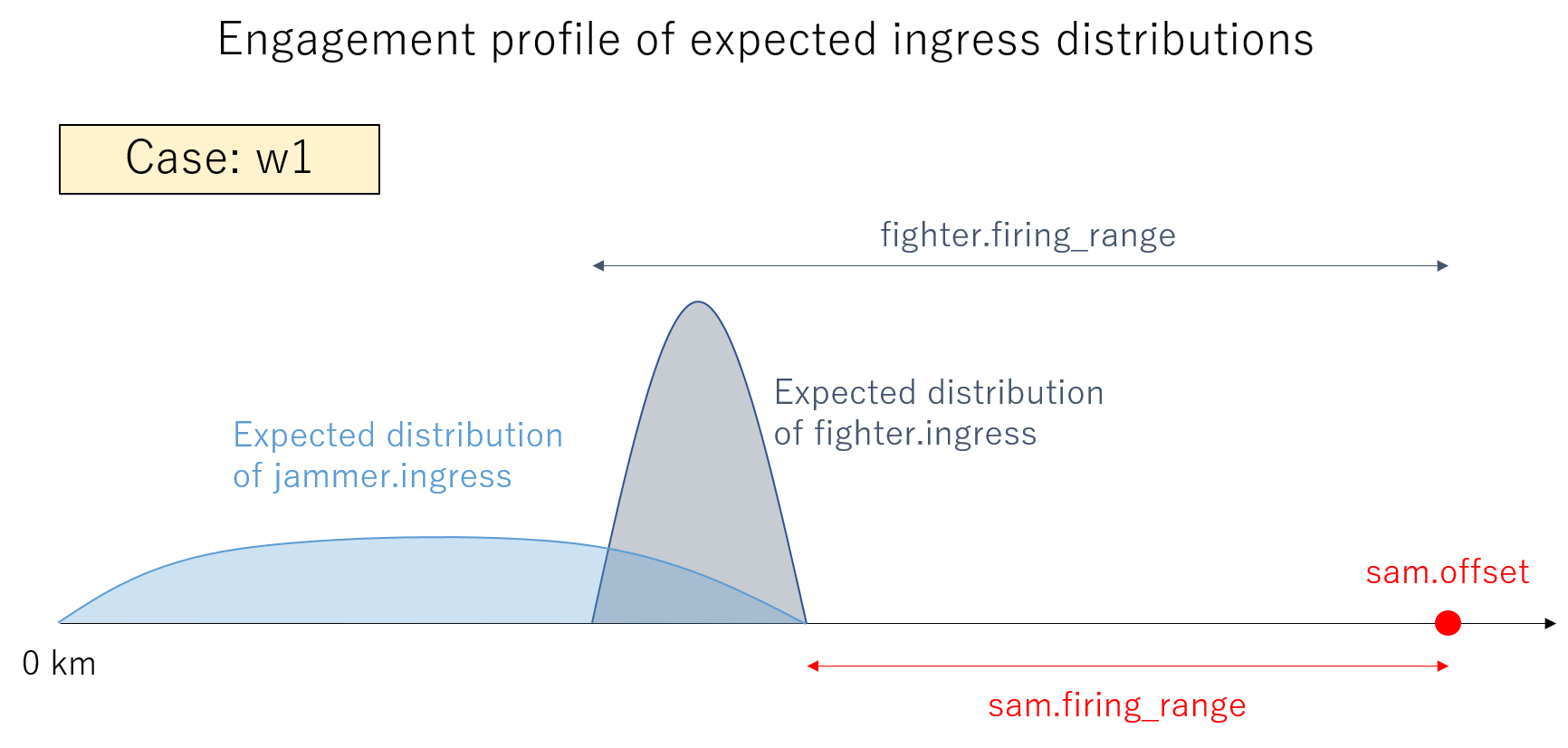
2.1 ケース w1 に対するプラン
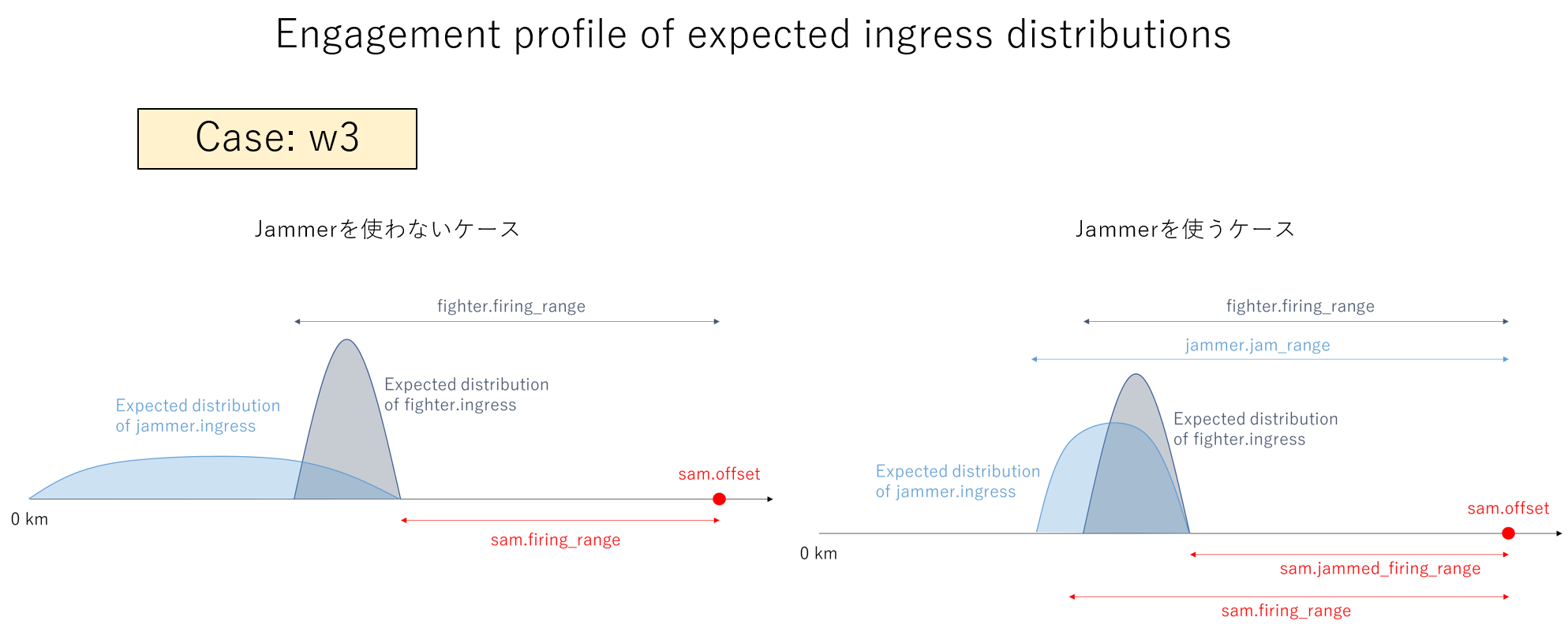
以下では、濃紺の丸が Fighter 進出距離 (fighter.ingress)、半透明で濃紺の大きな円が Fighter の射程 (fighter.firing_range)、水色の丸が Jammer 進出距離 (jammer.ingress)、半透明で水色の大きな円が Jammer の有効レンジ (jammer.jam_range)、赤の丸が SAM 配備位置 (sam.offset)、半透明で赤色の外側の大きな円が、クリーンな状態での SAM の射程 (sam.firing_range)、内側の大きな円がジャミングを受けた時の SAM の射程 (sam.jammed_firing_range) になります。
w1 のミッション条件に対して、生成したプラン例を以下に示します。w1は、Fighter 搭載ウェポンの長い射程を活かして、SAM を撃破するプランです。
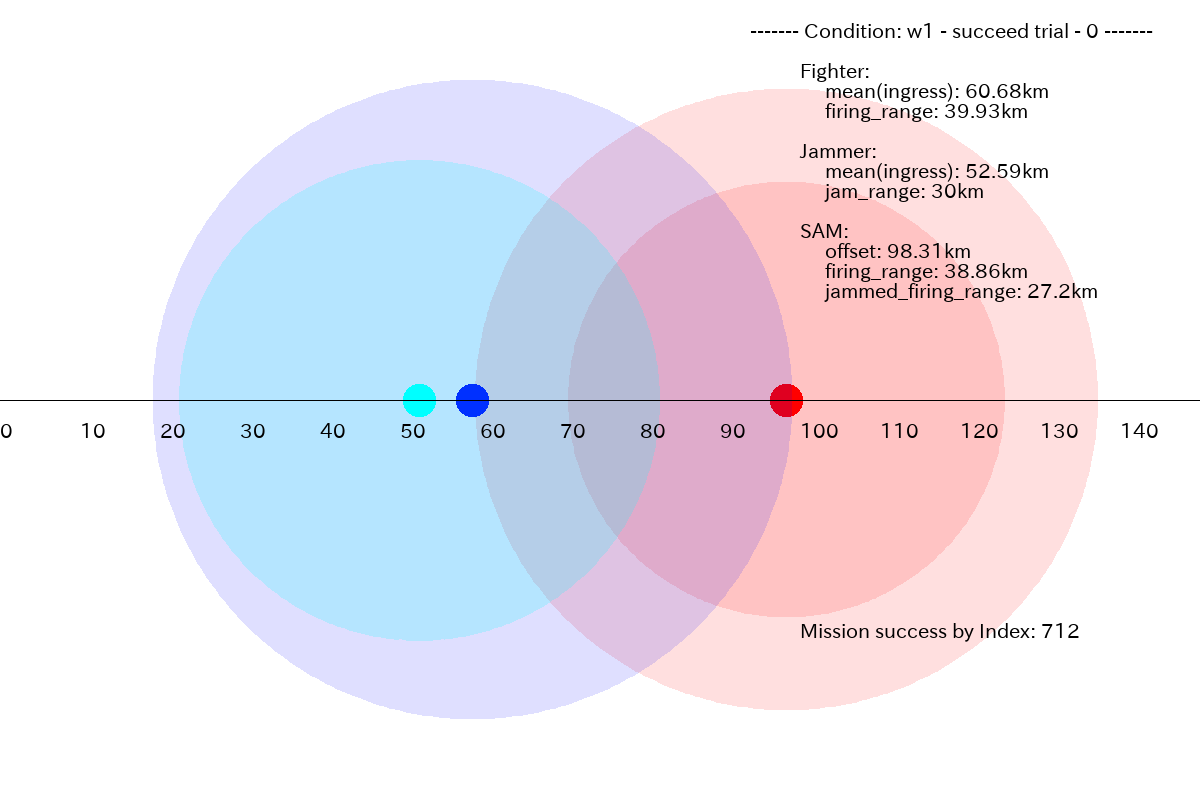
まず、ミッションに成功したプランの例です。Fighter 搭載ウェポンの射程(39.93km)が、SAM の射程(38.86km)より僅かに長いだけですが、Fghter をギリギリまで前進させて、SAM を撃破するプランを生成しています。
図2.1.1
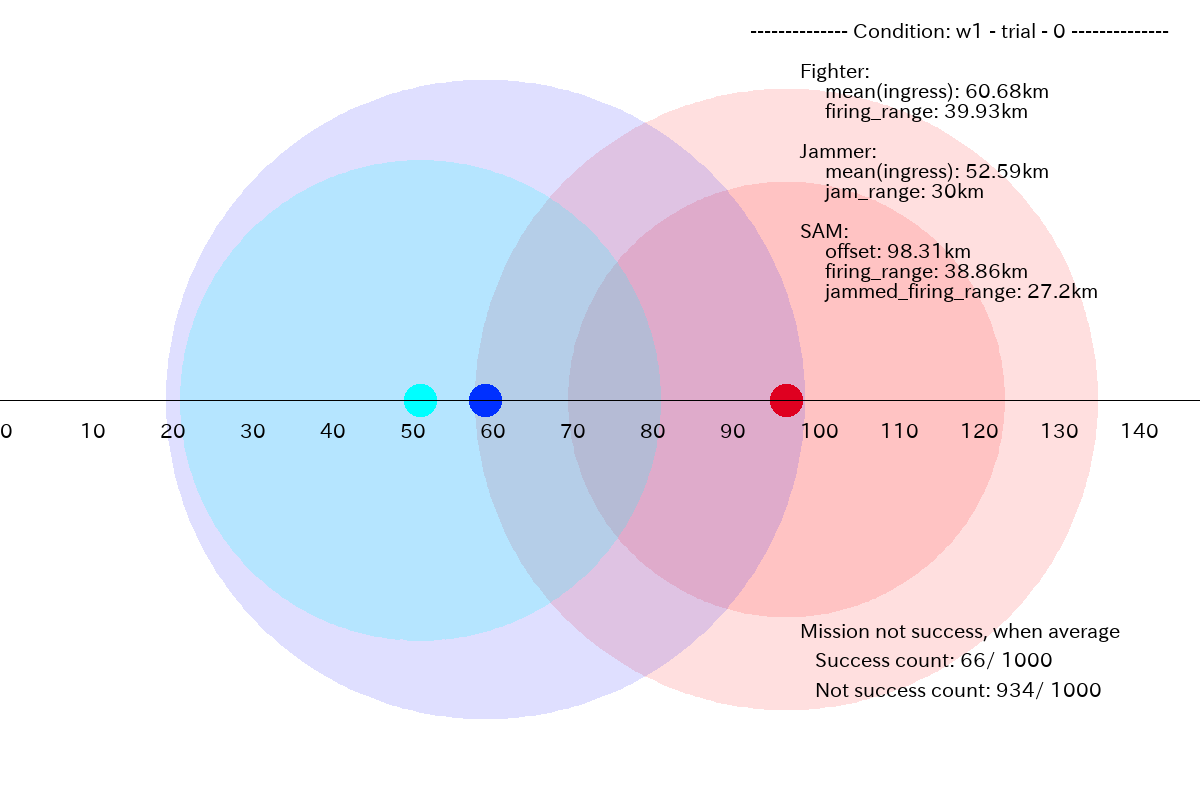
下図は、このミッション条件に対して GAN プランナーが生成した fighter.ingress と jammer.ingress の 1000 プランの平均を取って表示したものです。僅かなのですが、平均的には Fighter を前進させすぎて、SAM に撃墜され、ミッションはドローとなっています。(SAM は Fighter の射程内なので、SAM も撃破されます)。また、このミッション条件で、成功したのは図の右下にあるように 6.6 % (= 66/1000) のみでした。
図2.1.2
ここで、GAN の学習が上手く行った場合、どのようなプランが生成されるべきか考えてみます。w1のケースでは、Fighter搭載ウェポンの射程(fighter.firing_range)が、SAM の射程(sam.firing_range)よりも長いため、ミッションが成功するための Fighter 進出距離の分布は下図のようでなければなりません。また、Jammer は、Jamming が有効となる距離よりも SAM の射程が長いため、SAM の射程外にとどまる必要があります。したがって、ミッションが成功するための Jammer の進出距離の分布は下図のようになっている必要があります。
図2.1.3
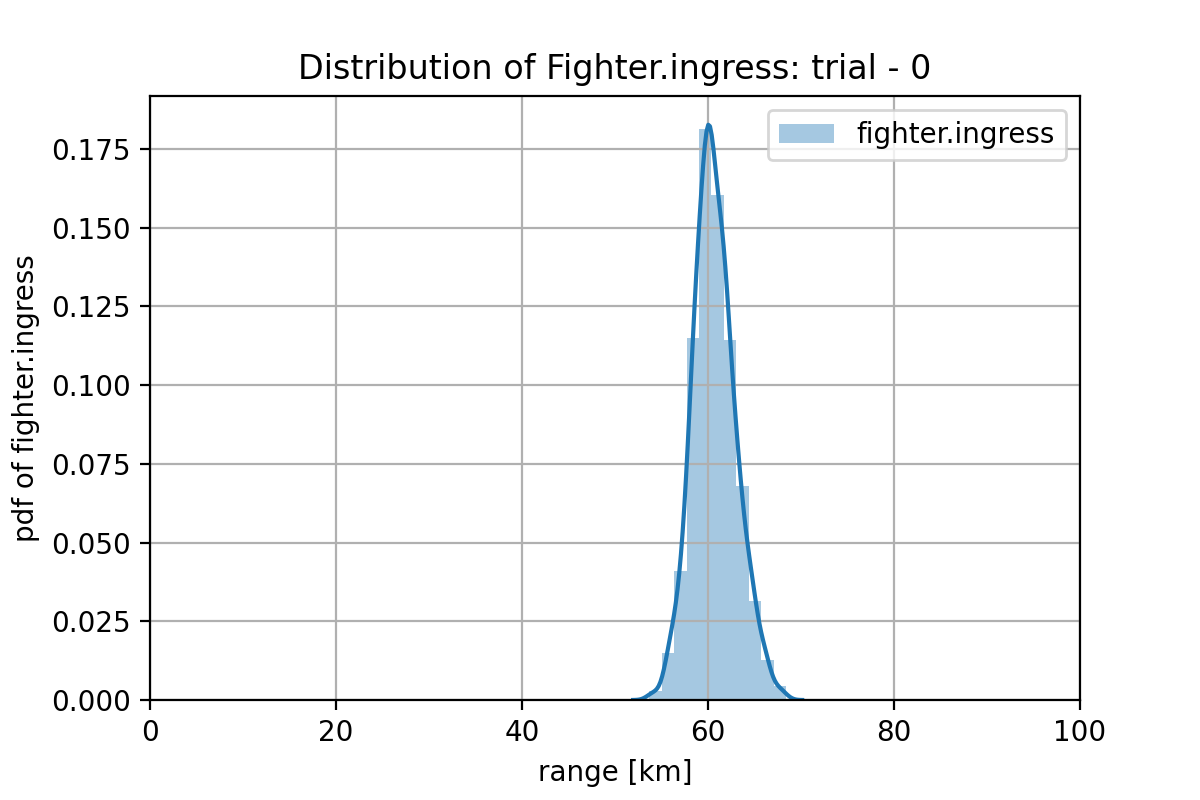
実際に GAN が生成した1,000プランの分布を計算してみます。このミッション条件では、sam.offset - sam.firing_range = 98.31 - 38.86 = 59.45 km です。また、SAM の射程(38.8)と Fighter 搭載ウェポンの射程(39.93 km)の差は、1.13km しかないので、ミッション・プランにおける Fighter の進出分布は、(58.32, 59.45)km の間に押し込める必要があります。
学習した、GAN プランナーによる、Fighter の進出プランの分布は下図のようになっていて、平均は60.68 km で、分布はシャープです。これをみると、(学習は十分ではありませんが、)成功するプランが持つ特徴を捉え始めています。もっと多くの w1 データで学習する、ネットの隠れユニット数を増やすか層を深くする、最新の GAN のアルゴリズムを使用する 等の対策で改善する可能性があります。
図2.1.4
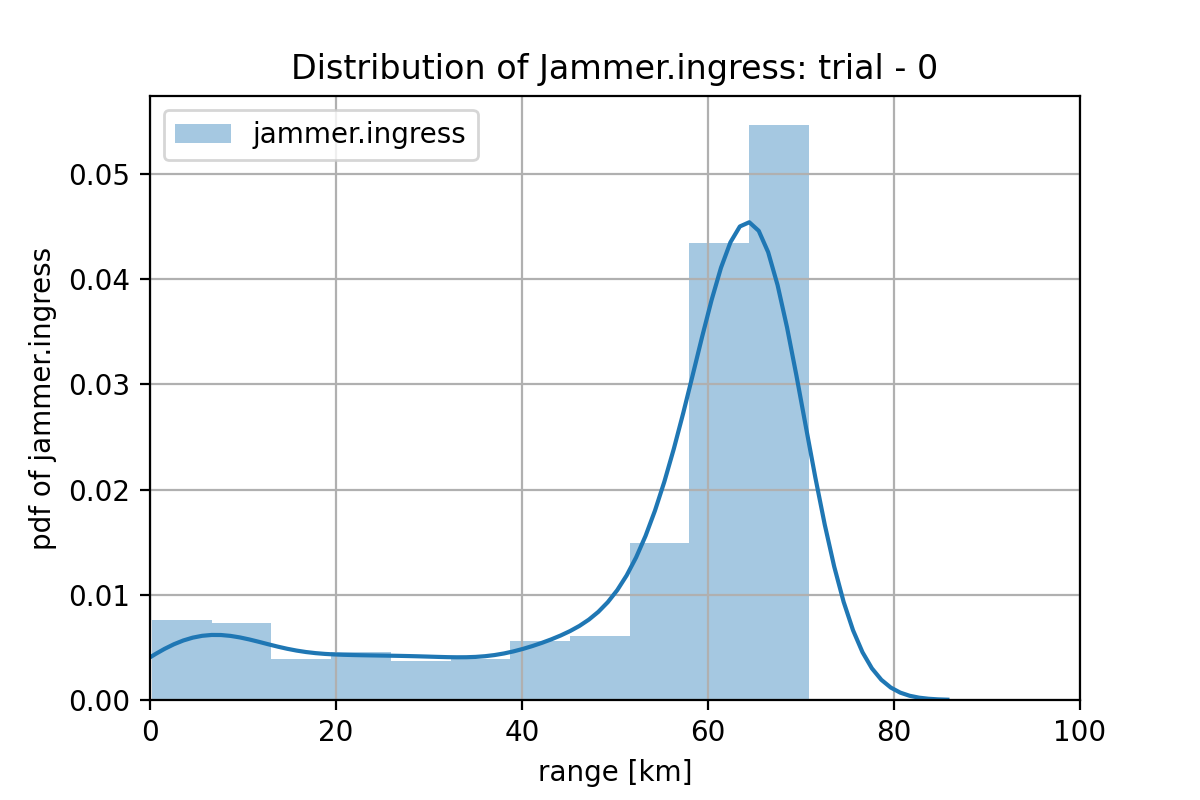
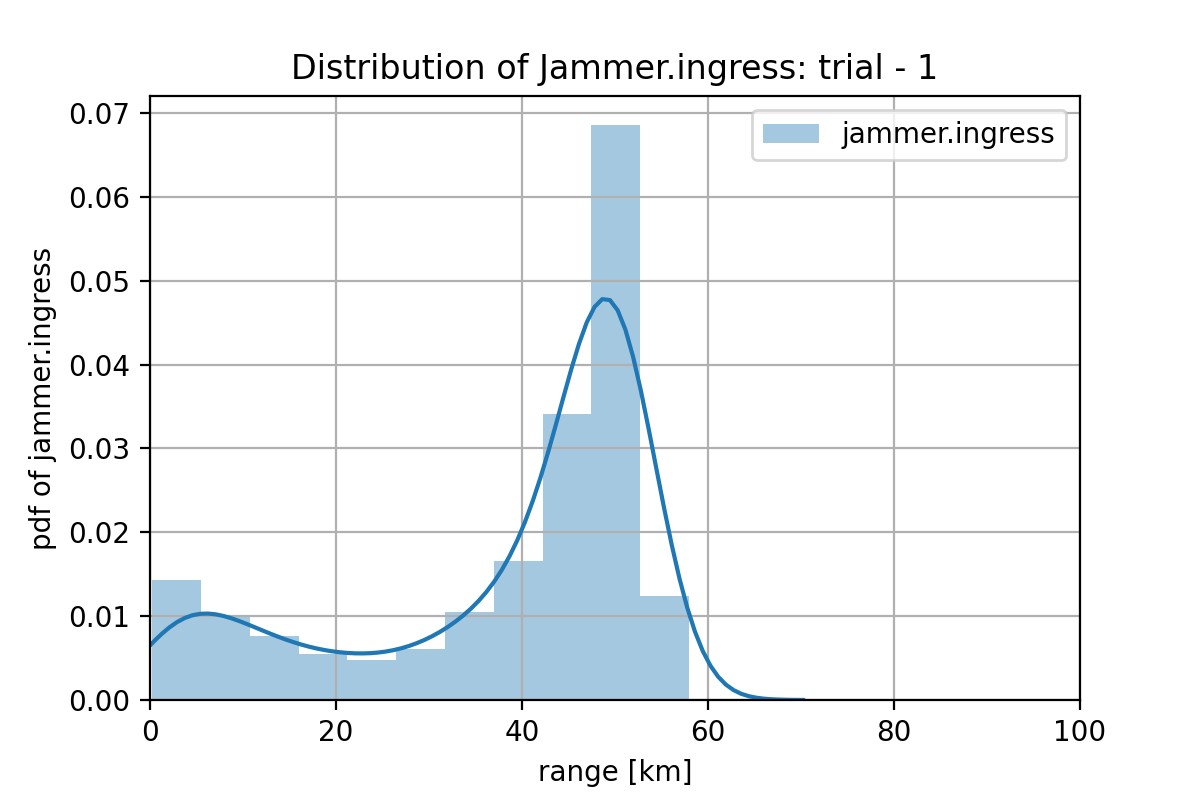
一方、Jammer については、SAM の射程でカバーできない 59.45km 以下の領域に配置できていればよいことになります。このミッション条件に対する Jammer の進出レンジの分布は下図のようになっています。(学習は不十分ですが)、これも成功するプランの特徴を捉え始めていると言えなくもない気がします。60km を超えた辺りにあるピークですが、これは、Jammer を前進させる必要があるケースの学習か、fighter.ingress の予測に引っ張られている可能性が有ります。やはり w1 のデータ数を増やす必要が有りそうです。(このケースでは、Jammer は不要なのは明らかなので、Jammer の進出距離を強制的に 0km したデータを作って学習させることも考えられます)。
図2.1.5
以下に、w1 条件でミッションに成功した別のミッション例を示します。
図2.1.6
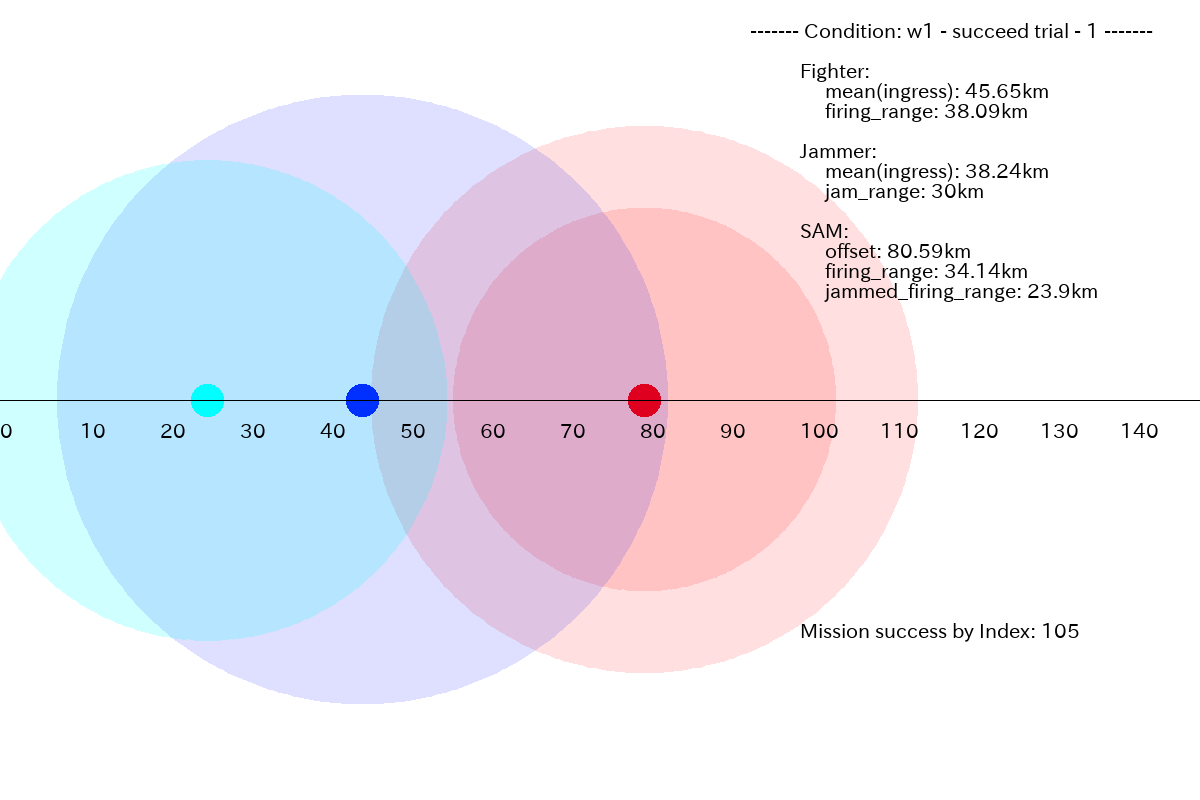
この場合は、SAM の射程(34.14 km)に比べ、Fighter 搭載ウェポンの射程(38.09 km)に少し余裕がある(3.95 km)ので、Fighter 進出距離の分布がシャープでなくとも、下図のように、平均としても成功できる結果となっています。また、全体の 34.9% (=349/1000) がミッションに成功しています。Jammer 進出距離の分布は、やはり前進させるほうに引っ張られていますが、成功のための特徴はとらえ始めています。
図2.1.7
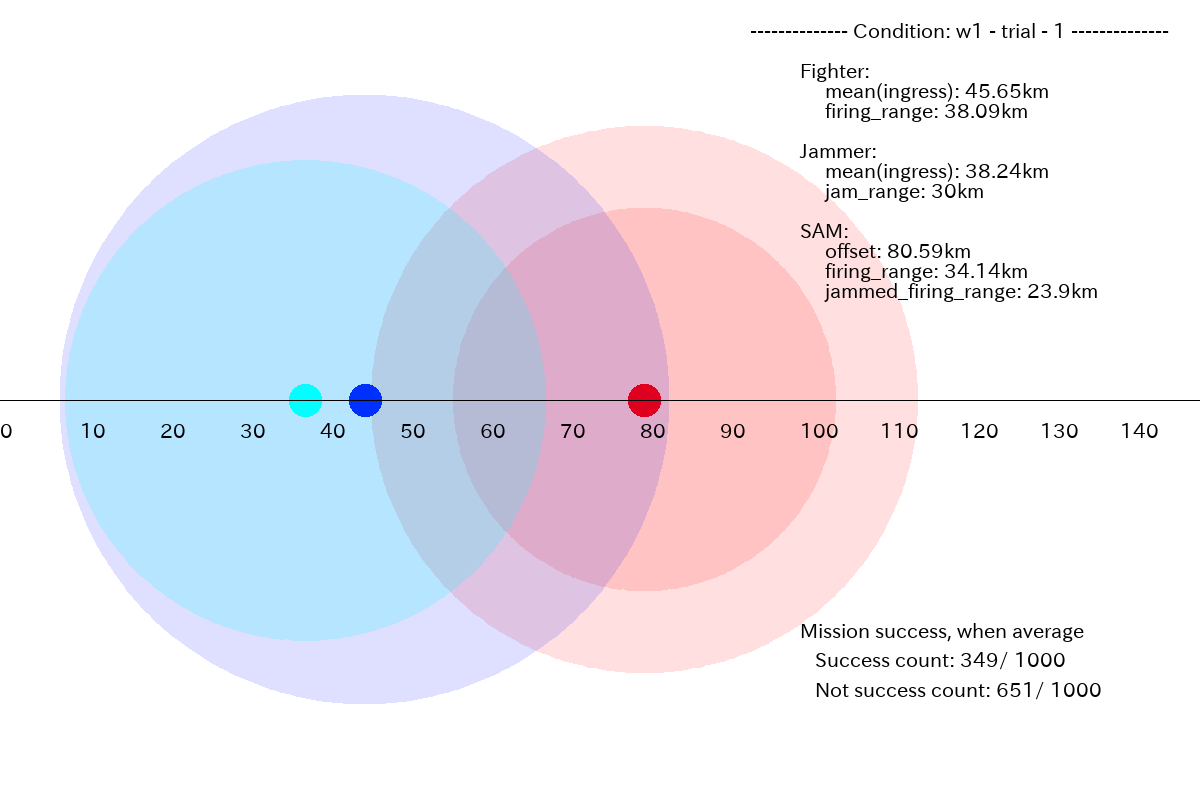
図2.1.8
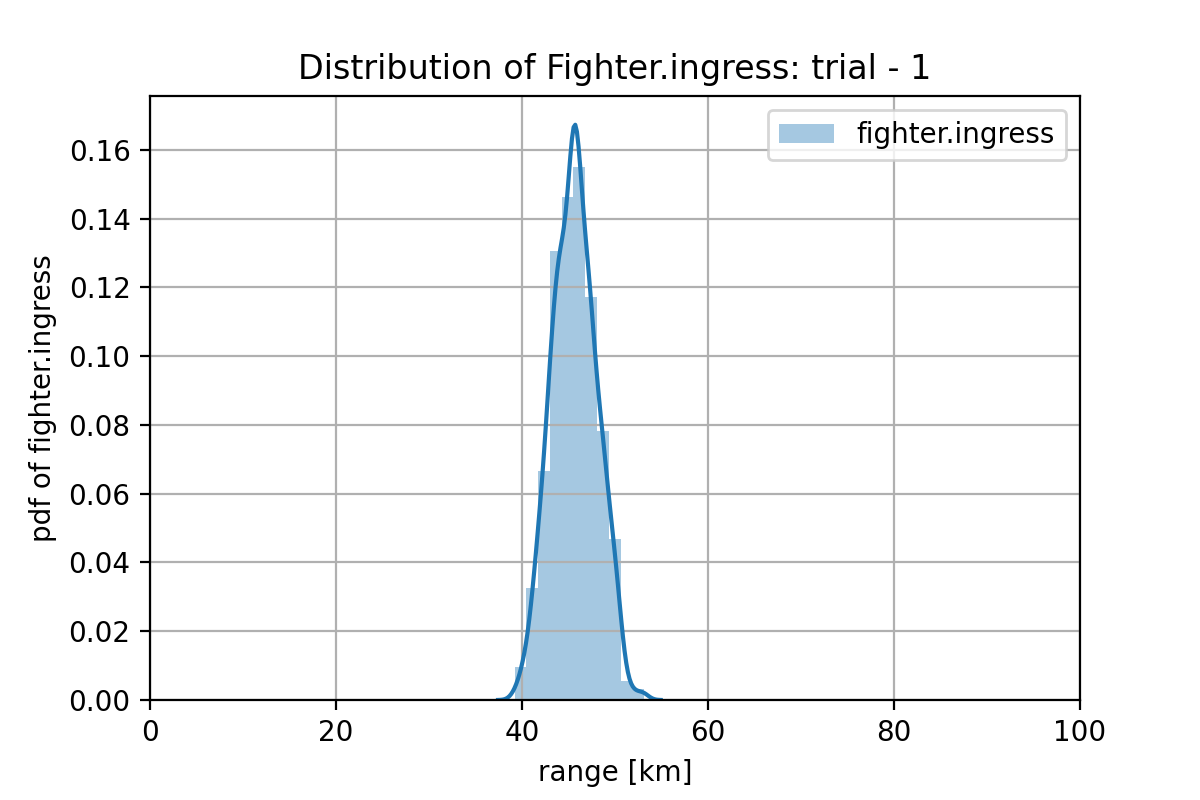
図2.1.9
以上の結果を踏まえて考えると、図2.1.3 が予め示されていなくとも、GANプランナーが生成したプランの分布をみることにより、ミッションに成功するためのプラン要件となぜそれが必要なのかが見えて来ませんか?これが GAN プランナーを使う一番のメリットだと思います。
2.2 ケース w2 に対するプラン
これは、Jammer を適切な位置に配置し、SAM の射程を縮退させた上で、Fighter を適切な位置に進出させる必要があるケースです。
ミッションに成功したプランの例としては、以下が挙げられます。Jammer を前進させることにより、SAM の射程を縮退させ、そこに Fighter を前進させることでミッションを成功させています。
図2.2.1
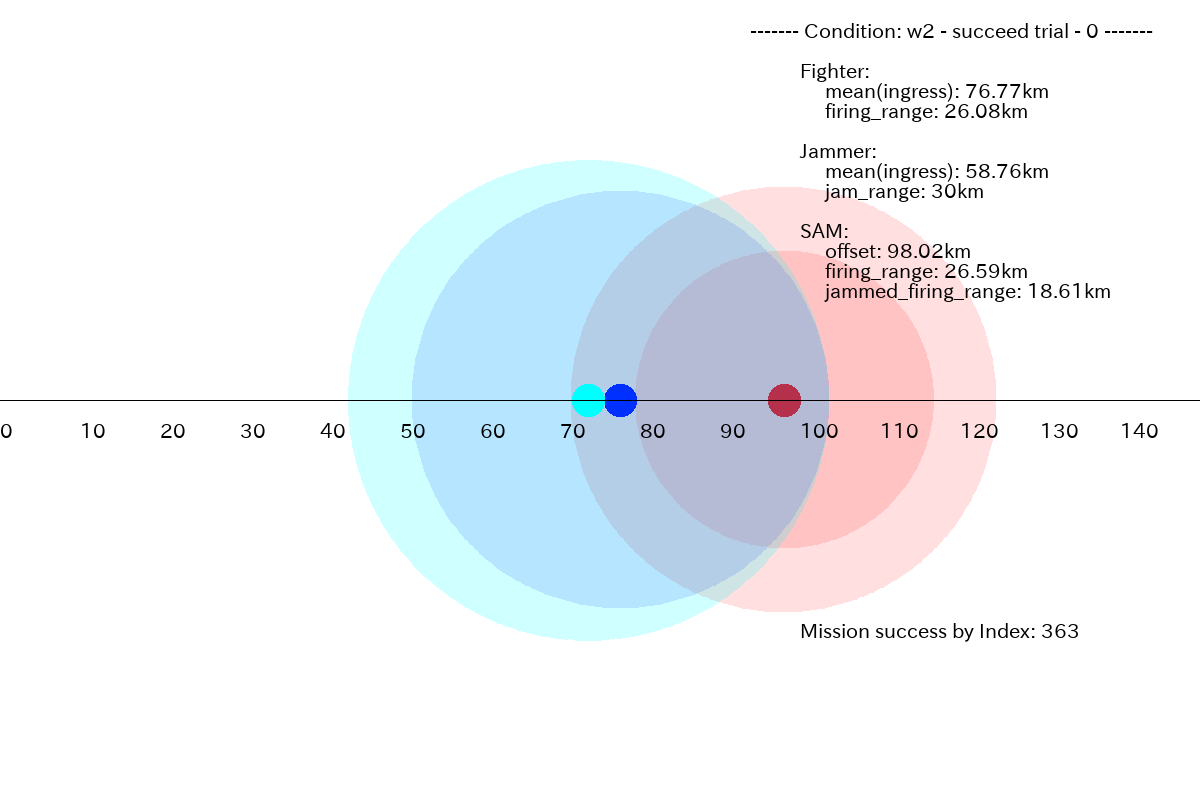
このミッション条件の場合も、後に示すように、Jammer の進出分布が 0km 方向にも長く伸びていて、平均的には、Jammer を前方に進出させきれず、ミッションに成功したのは、50.6 % (506/1000) です。全体として Jammer について学習不足な感じですが、これはトレーニングデータが、Jammer が無くても良いケース(w1 と w3)に偏りすぎていて、適切な位置に Jammer を進出させる学習が困難になっている可能性があります。
図2.2.2
w2 のケースでも、GAN の学習が上手く行った場合、どのようなプランが生成されるべきか考えてみます。まず、SAM に対しジャミングを有効にするために、Jammer は、jammer.jam_range と sam.jammed_firing_range の間の位置に進出させる必要があります。その上で、Fighter は、fighter.firing_range と sam.jammed_firing_range の間に前進させなければなりません。したがって、成功するプランの分布は下図のようになっている必要があります。
図2.2.3
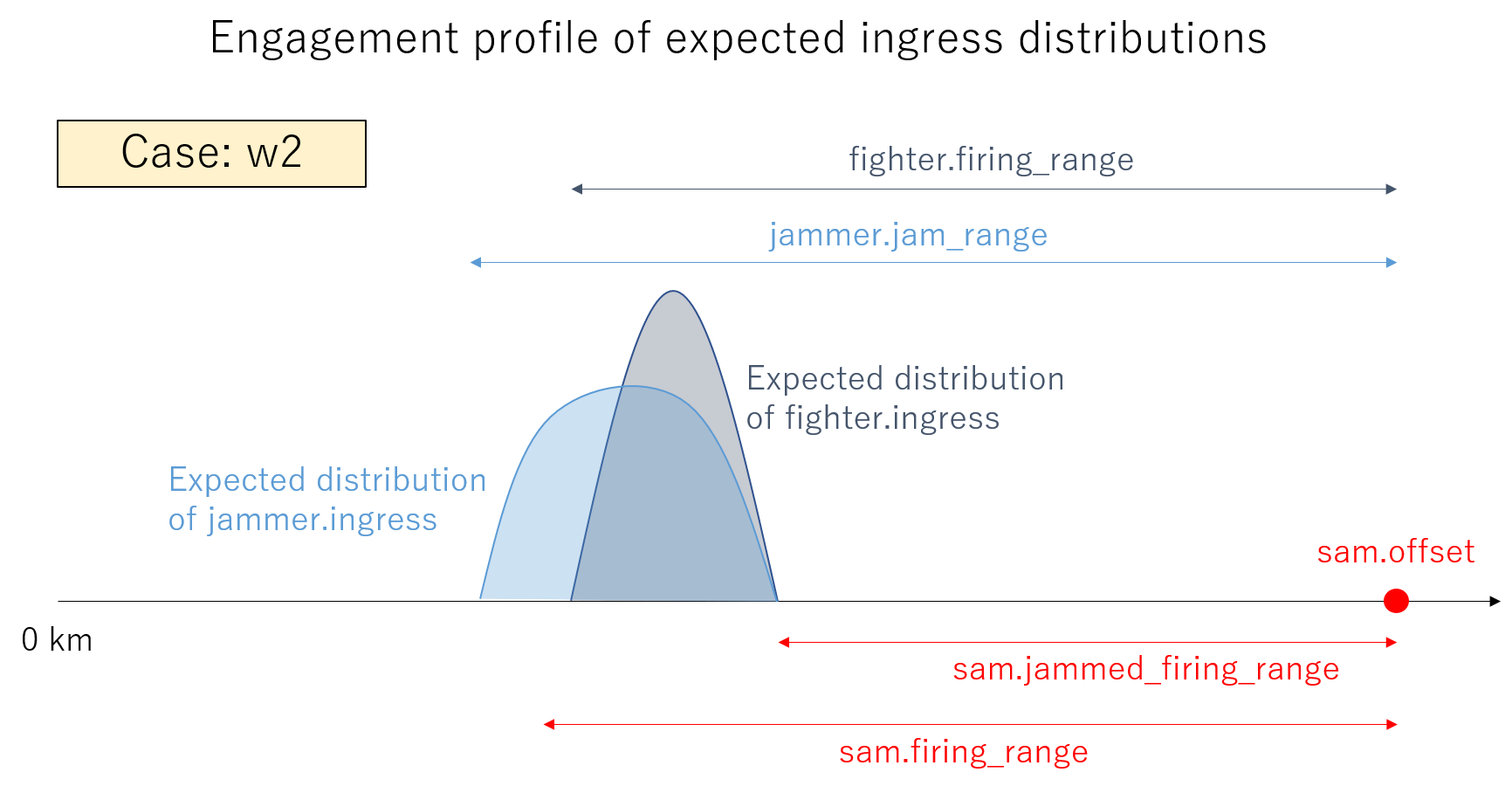
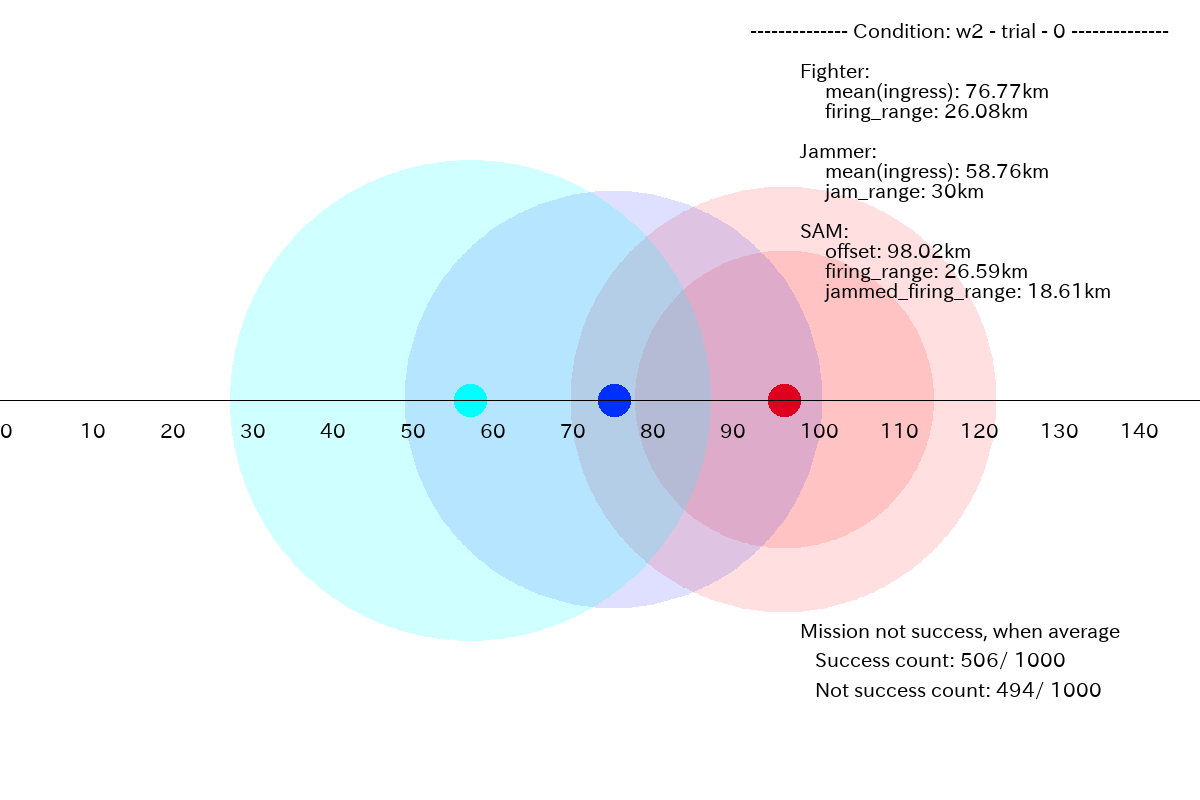
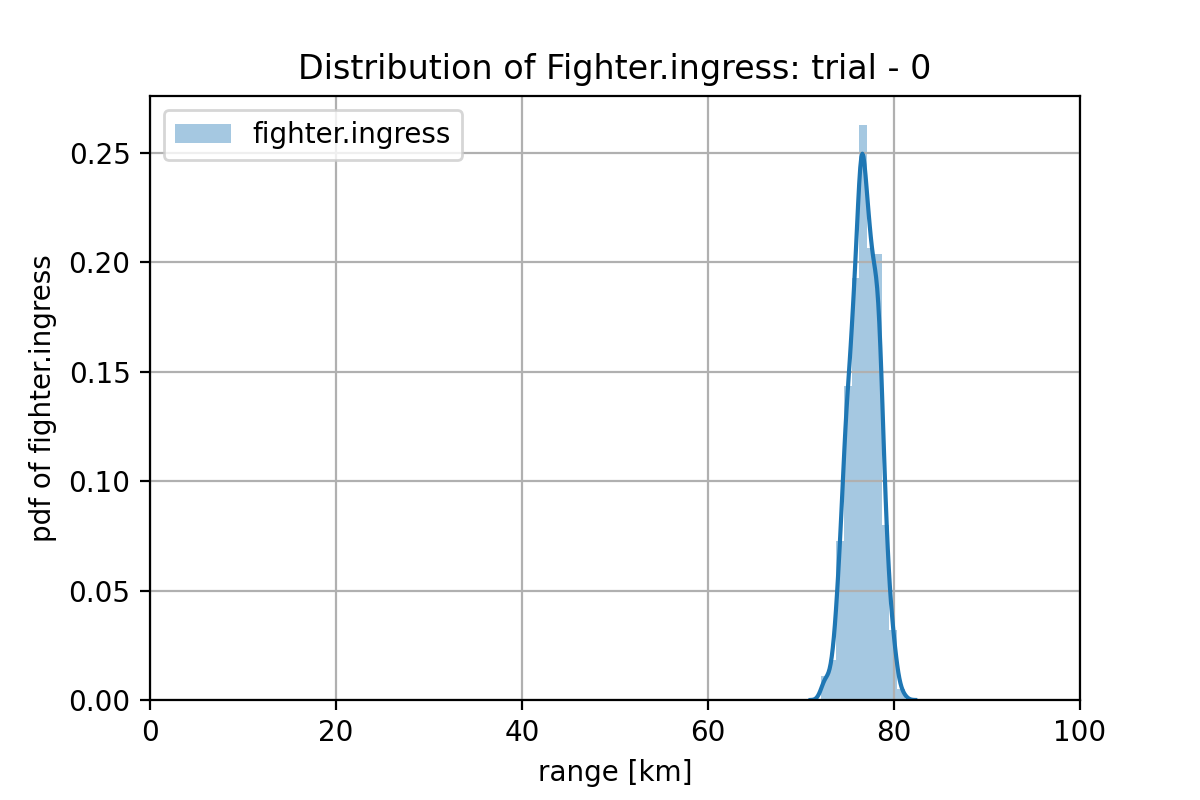
図2.2.1 のミッション条件で、GAN プランナーにより、1000プラン生成してプランの分布を計算します。Fighter は、sam.offset-sam.jammed_firing_range(98.02 - 18.61 = 79.41 km)とsam.offset-fighter.firing_range(98.02 - 26.08 = 71.94 km)の間に進出させる必要があります。下図に示すように、GAN プランナーは、この条件の特徴をかなり捉えています。
図2.2.4
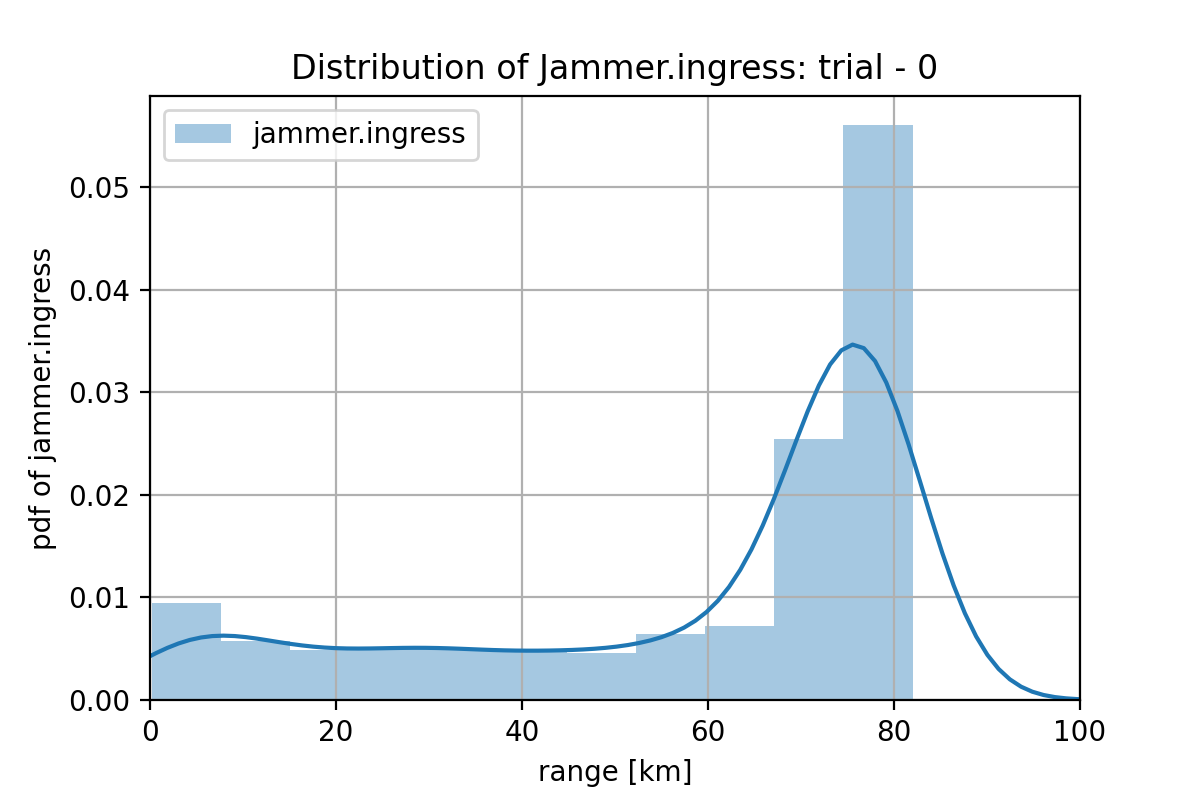
また、Jammerは、sam.offset-sam.jammed_firing_range(98.02 - 18.61 = 79.41 km)とsam.offset-jammer.jam_range(98.02 - 30.0 = 68.02 km)の間に進出させる必要があります。尾は長く引いていますが、ピークは正しい所に持ってきています。トレーニング・データ数が多ければ、もう少し正確に特徴を捉えてくれそうな気がします。
図2.2.5
別の w2 ケースを以下に示します。このミッション条件の場合、成功する割合は 37.4% (=374/1000) でした。この条件では、Fighter を(51.43, 55.15)km の間に、Jammer を(42.9, 55.15)km の間に選出させる必要があります。図から、成功するプランの要件を捉えかかっているのが見てとれますが、学習は十分ではありません。
図2.2.7
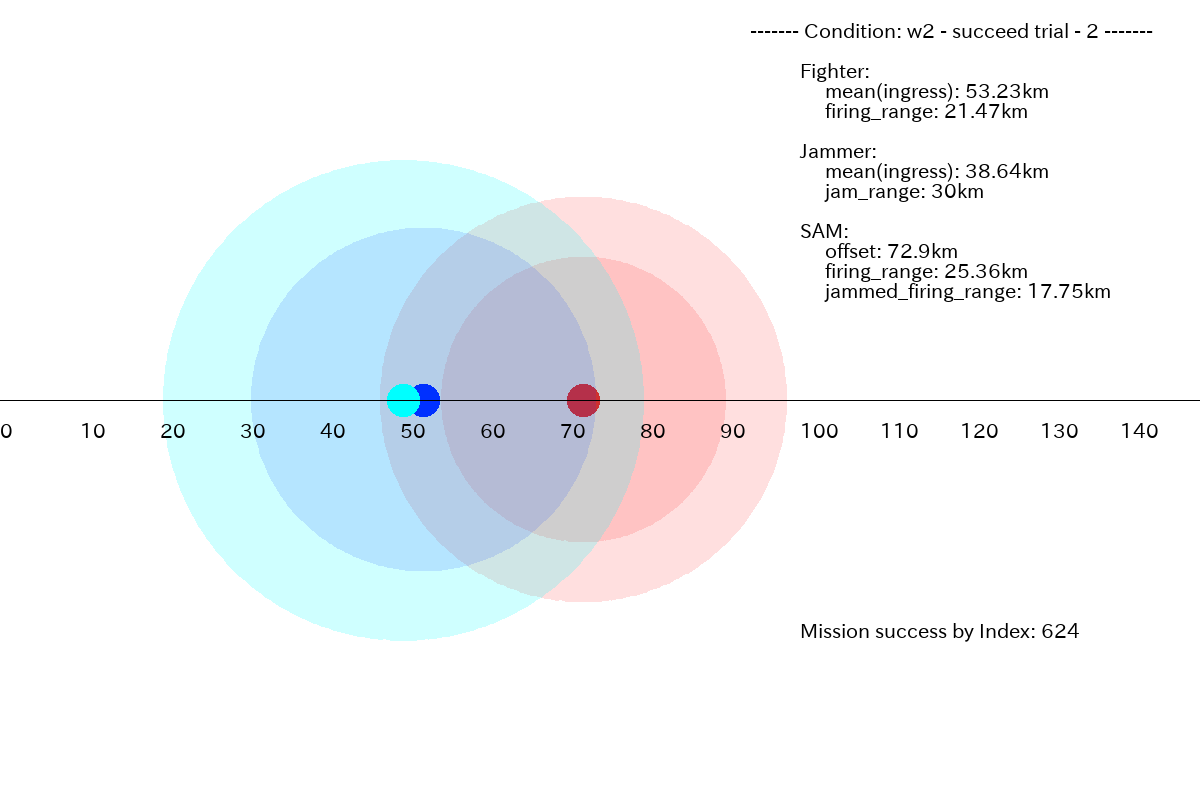
図2.2.8
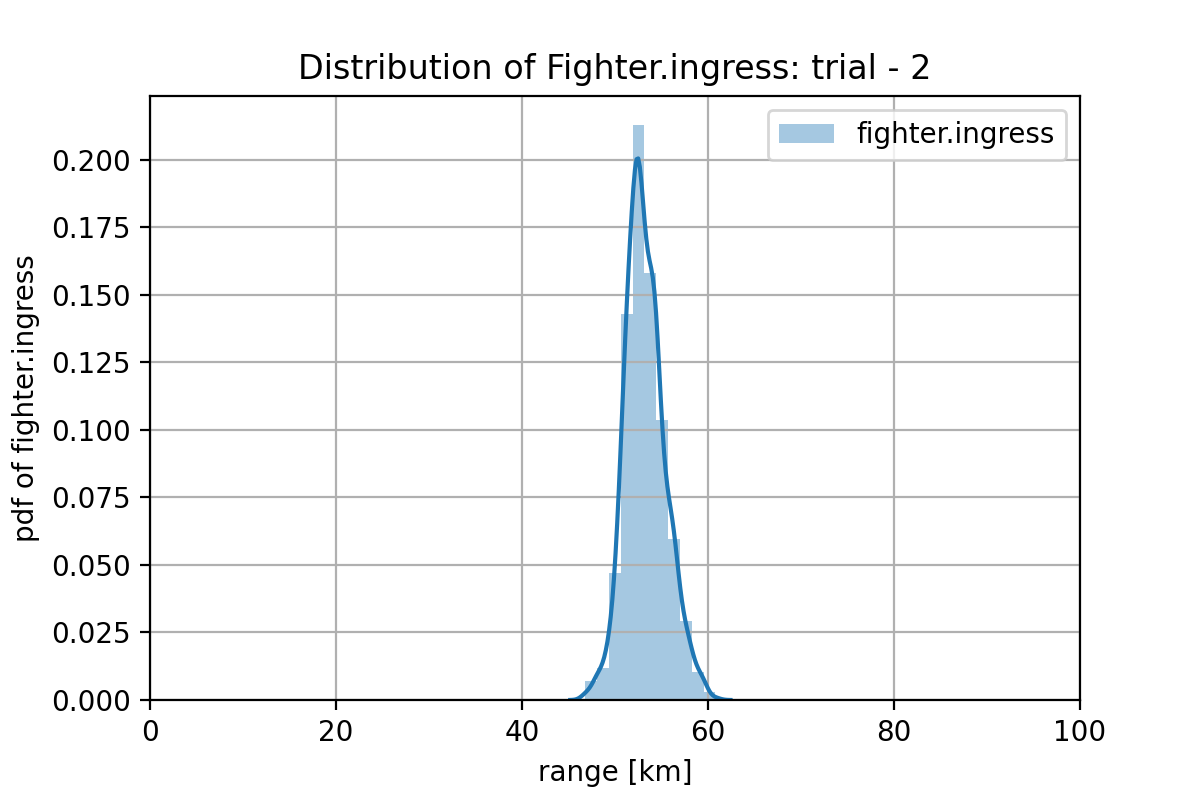
図2.2.9
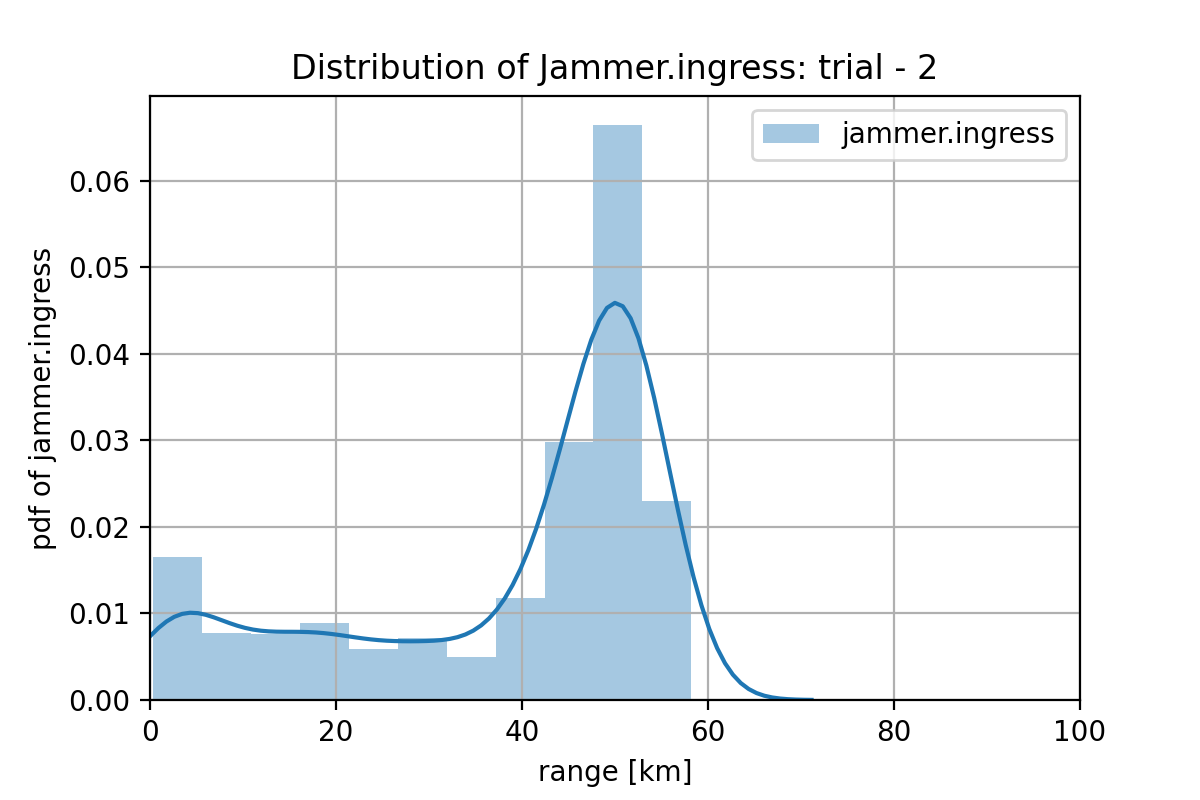
2.3 ケースw3に対するプラン
このケースでは、Jammer は不要なのですが、Jammer を前進させたがります。下図に例を示します。
図2.3.1
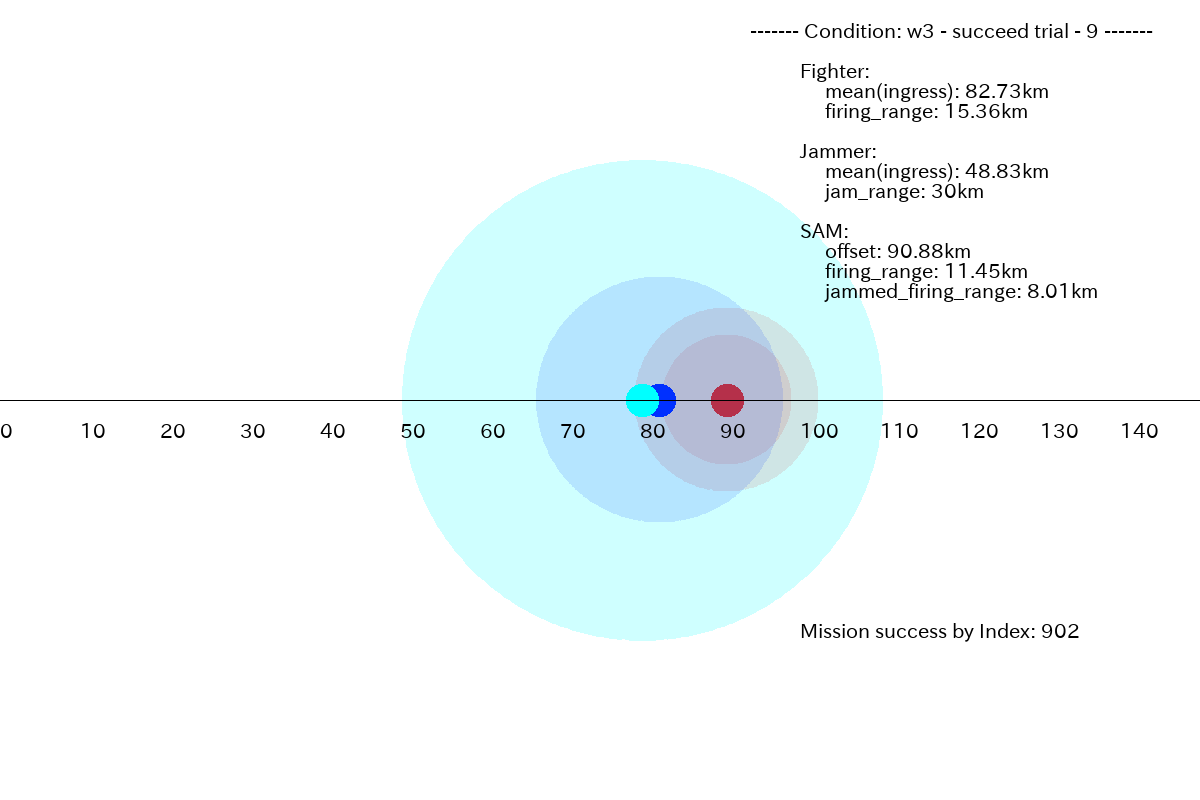
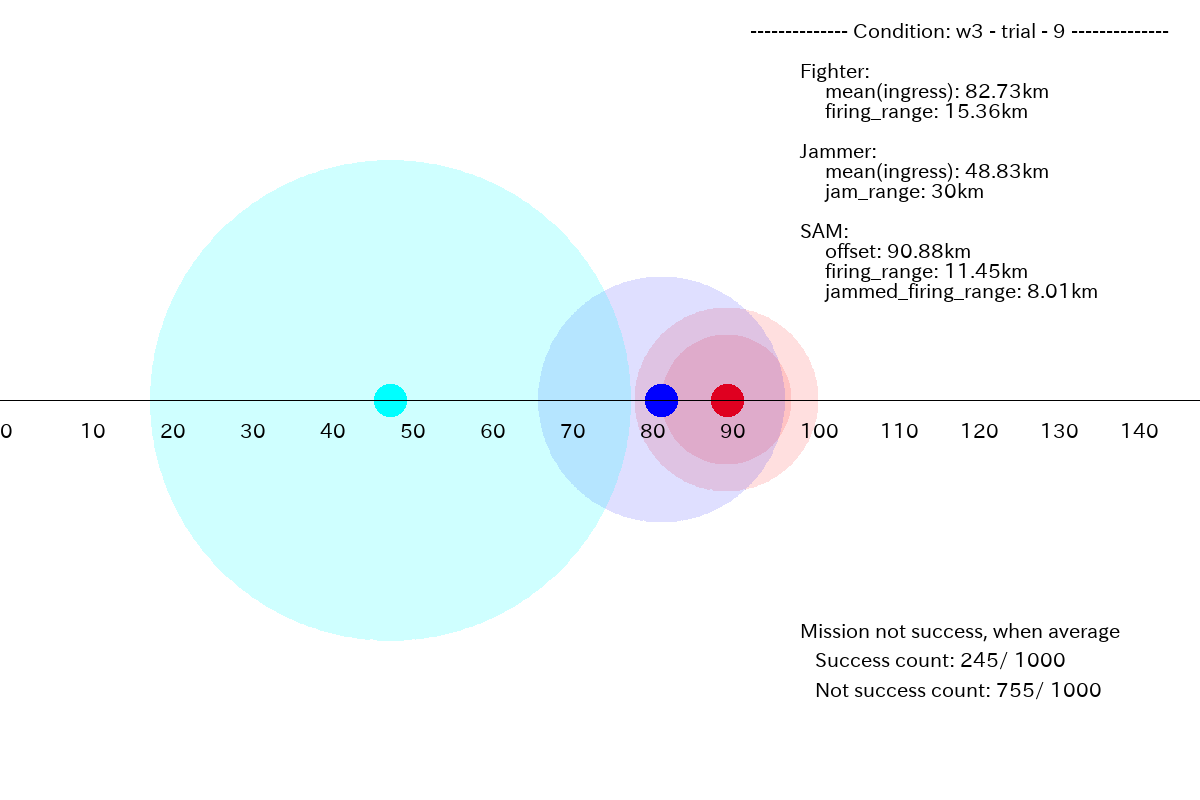
下図が、プランの平均値で書いたものになります。
図2.3.2
下図は、w3 のケースで、ミッションに成功するプランのあるべき分布です。このケースは、Jammerは使わなくてもミッションは成功できるのですが、敢えて Jammer を使ってもミッションに成功できます。したがって、成功のための要件は、Jammer を使わないプラン要件(w1 と同じ)、または、Jammer を使うプラン要件(w2 と同じ)の2つの要件の 'OR' で構成されることになります。
図2.3.3
このような場合に、GAN プランナーは、Jammer を使わないプランを生成するよう学習するのか、Jammer を必要とするプランを生成するよう学習するのかは興味があるところです。できれば、どちらのプランも生成するように学習してくれると、プランの全体をカバーするという意味で一番良いのですが。ただ、これをちゃんと調べるには、乱数系列を変えて十分な統計になるよう学習を繰り返す必要があるので、とてもビンテージ・マシンではできません。したがって、いくつかの例で調べるにとどめました。
図 2.3.2 の条件の場合、それぞれの分布は下図になります。
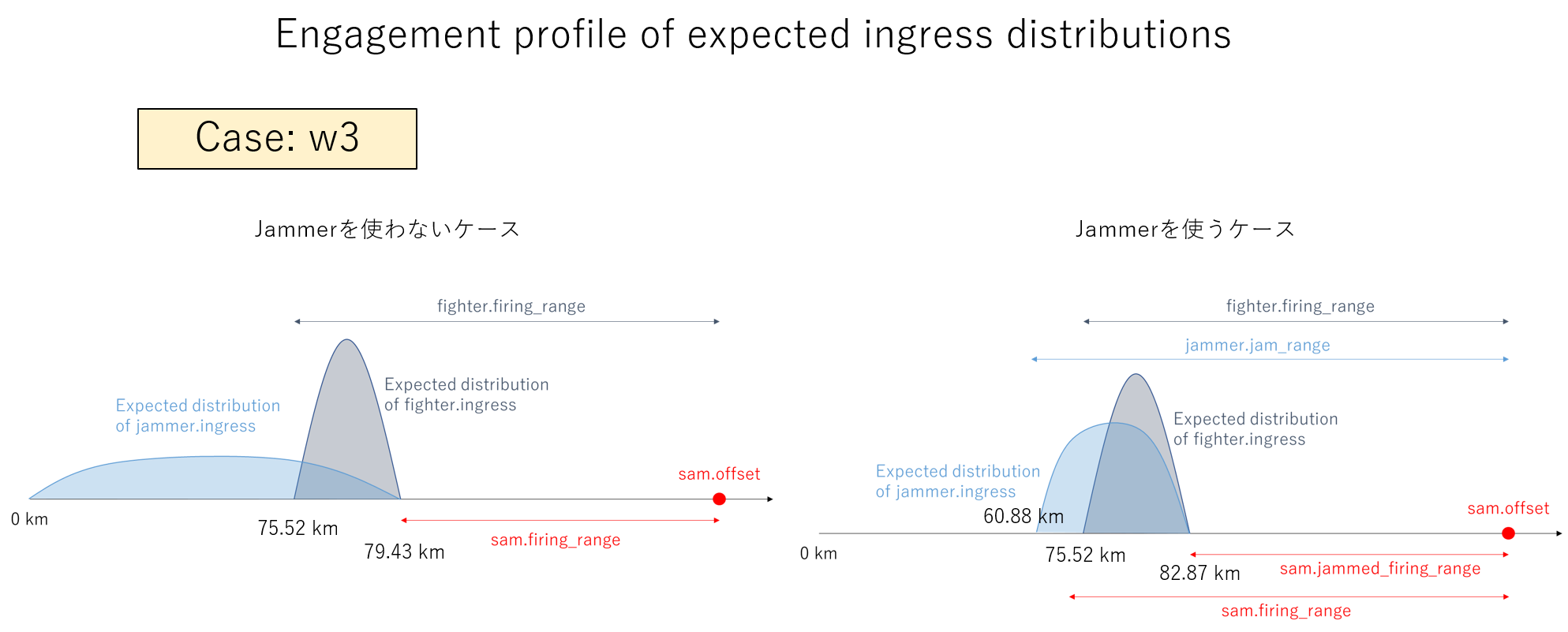
GANプランナーが生成したプランの分布は、下図ですので、この条件では、Jammerを使うプランを生成するよう学習しているように見えます。
図2.3.4
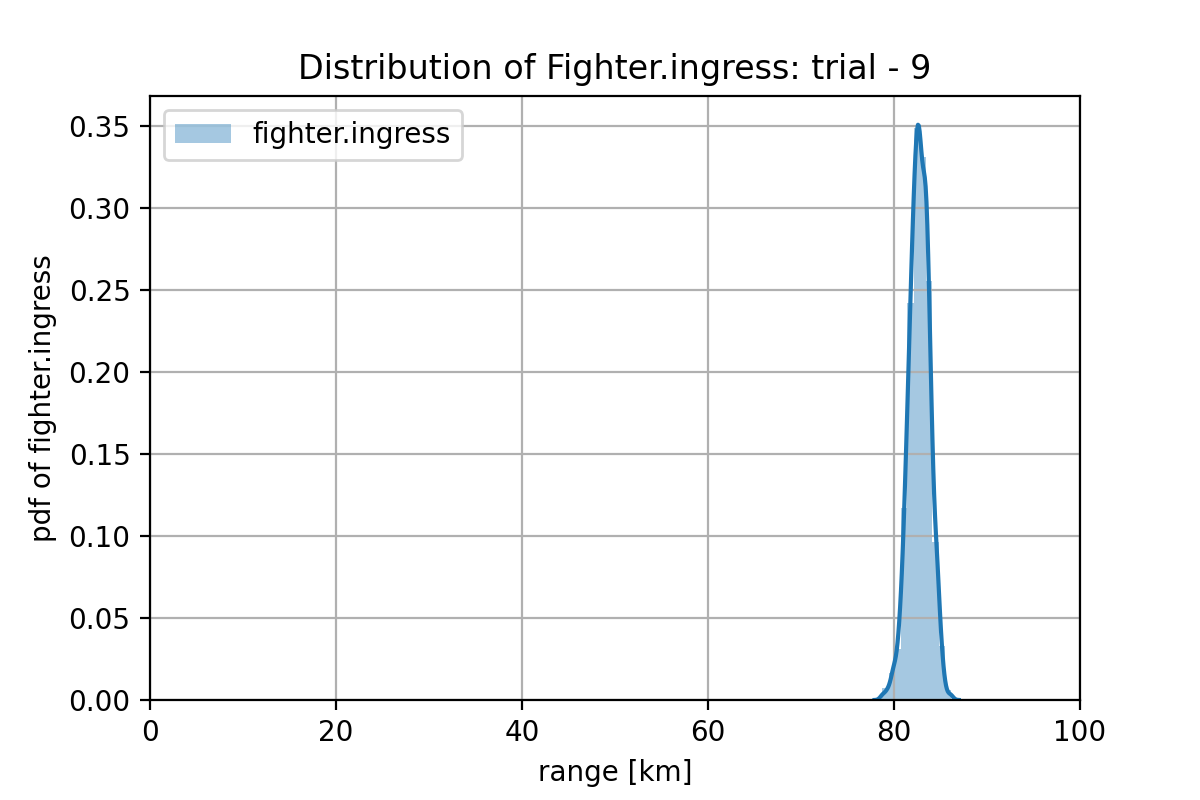
図2.3.5
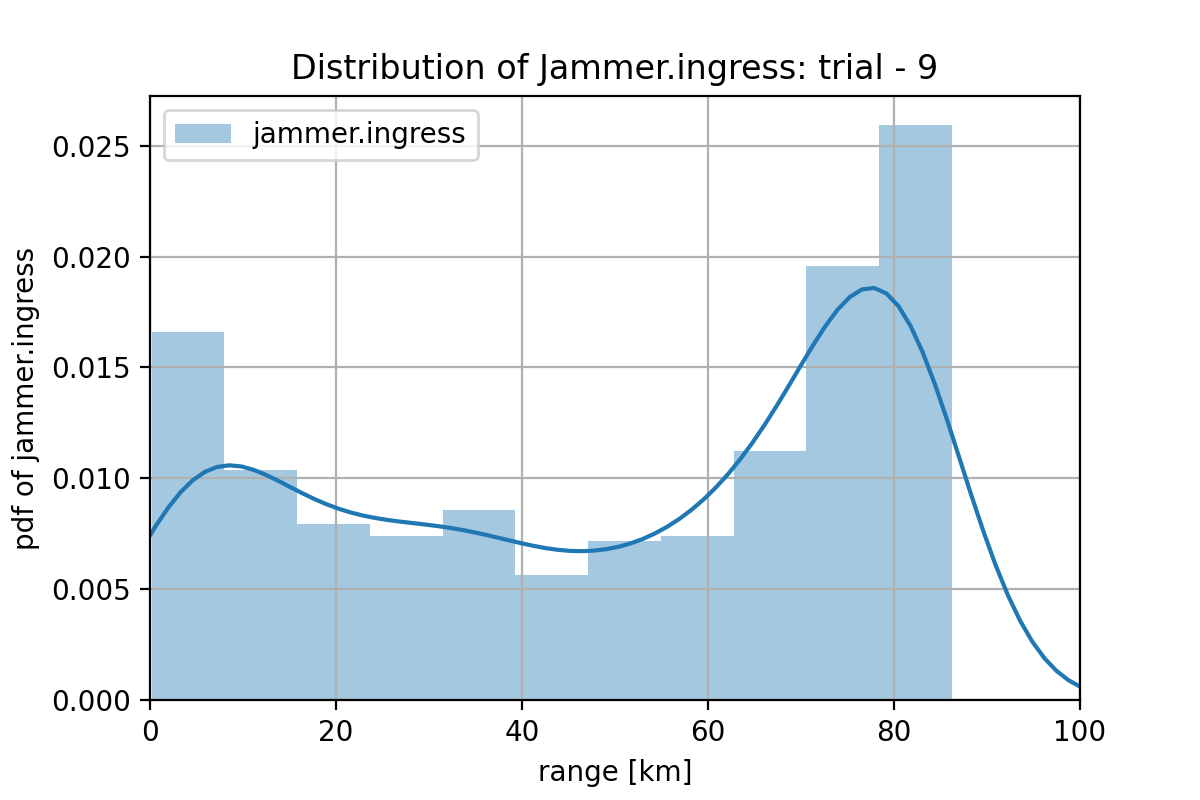
成功する割合が比較的高く96.6% (=966/1000)となった、別のケースはこんな感じでした。
図2.3.6
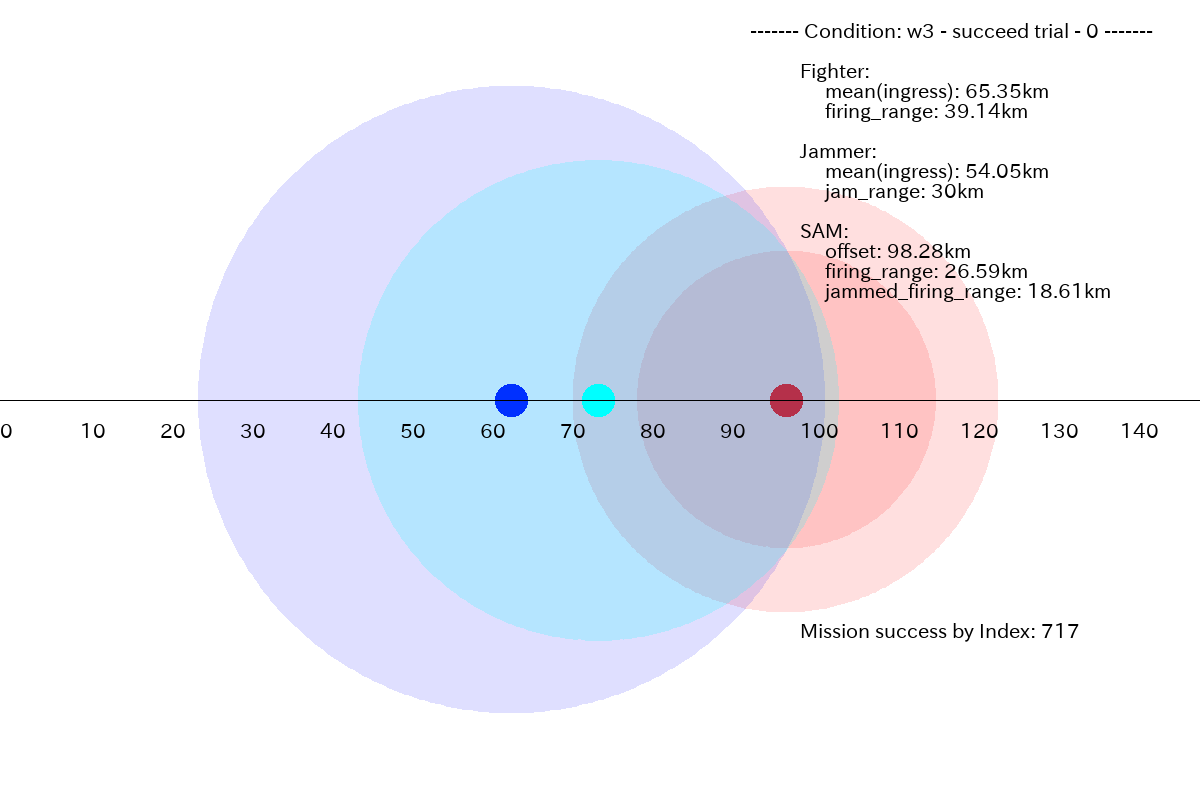
図2.3.7
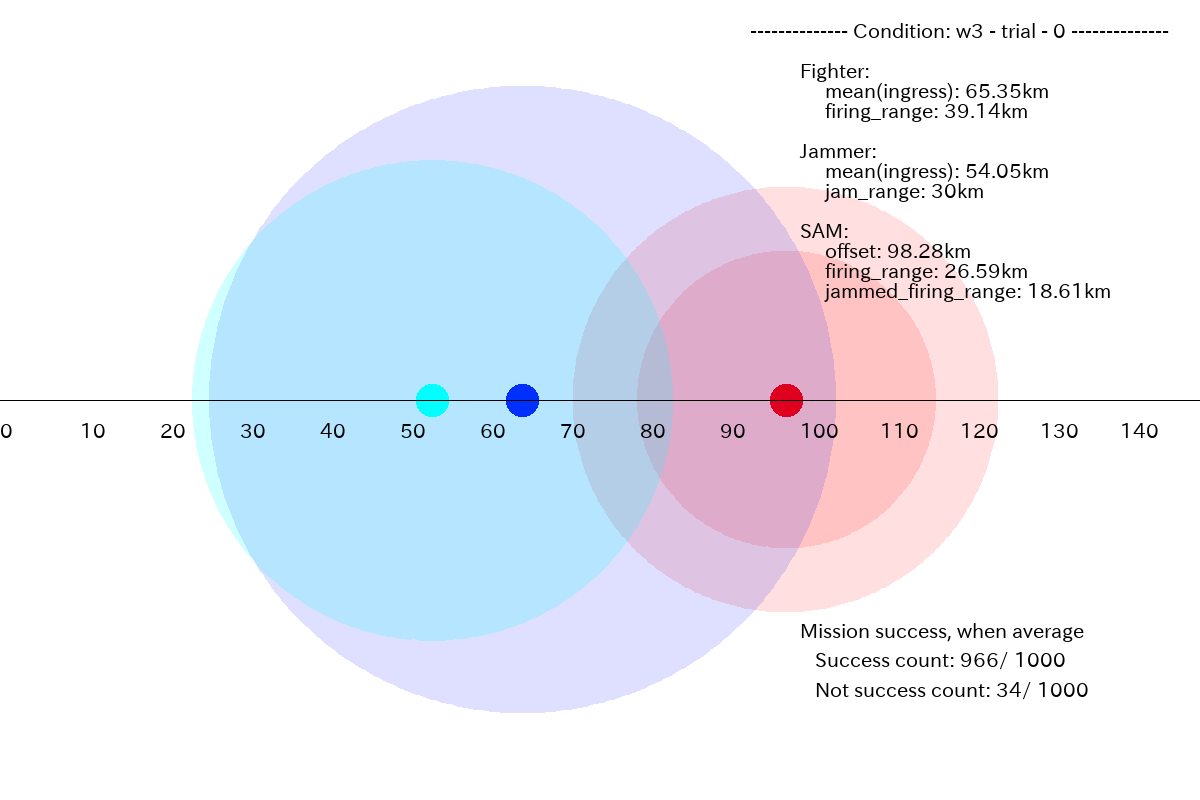
このミッション条件の場合、望ましい分布は下図になります。
図2.3.8
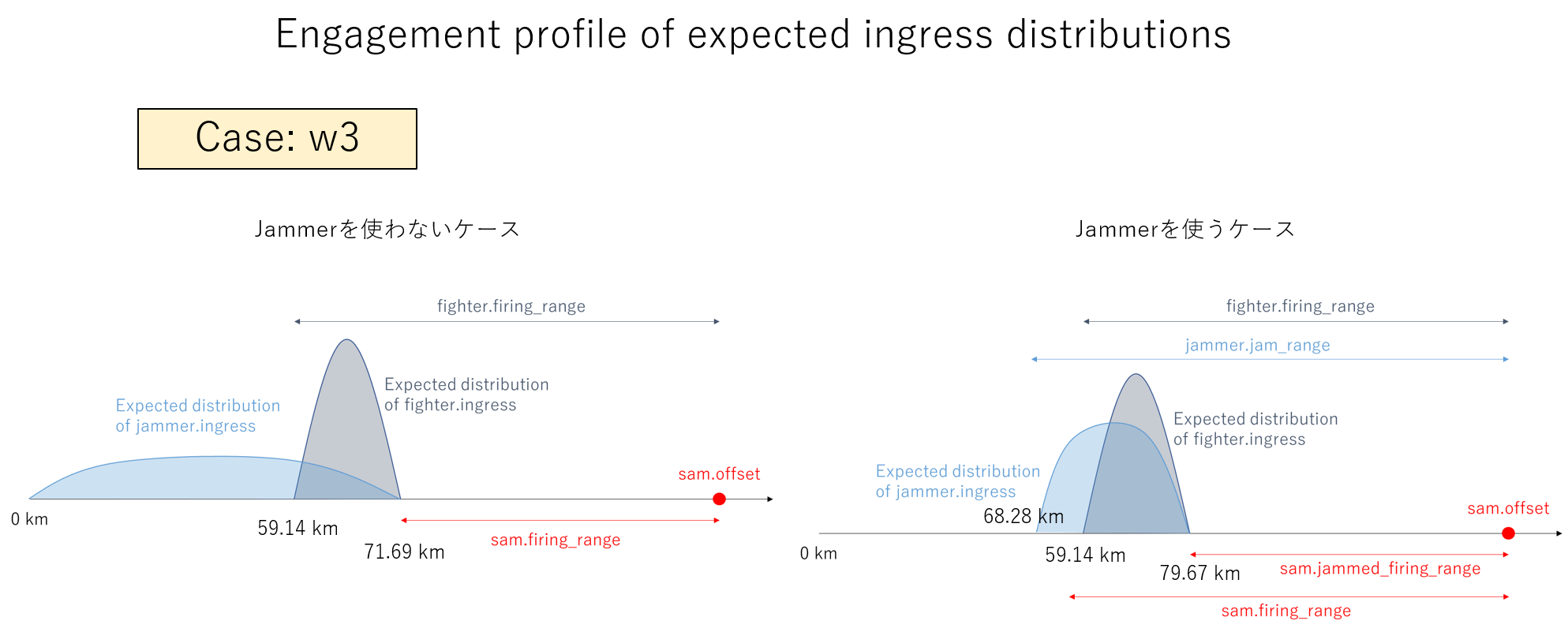
GAN プランナーが生成したプランの分布は下図になります。Fighterのプランが混合分布のようになっていて、両方のプランを学習しているような気もしますが、学習が進むと、どちらかに収斂するかもしれませんし、何とも言えませんね。この辺りは、面白そうなので、ビンテージ・マシンでできるアイデアを思いついたら分析してみようと思います。
また、未だ思い付きだけですが、異なる分布を学習するために混合分布をネットに組み込んで、MDN(Mixture of Density Network)化したら面白いかもしれません。
いずれにせよ、まず GAN の性能向上をしたほうが良いと思います。
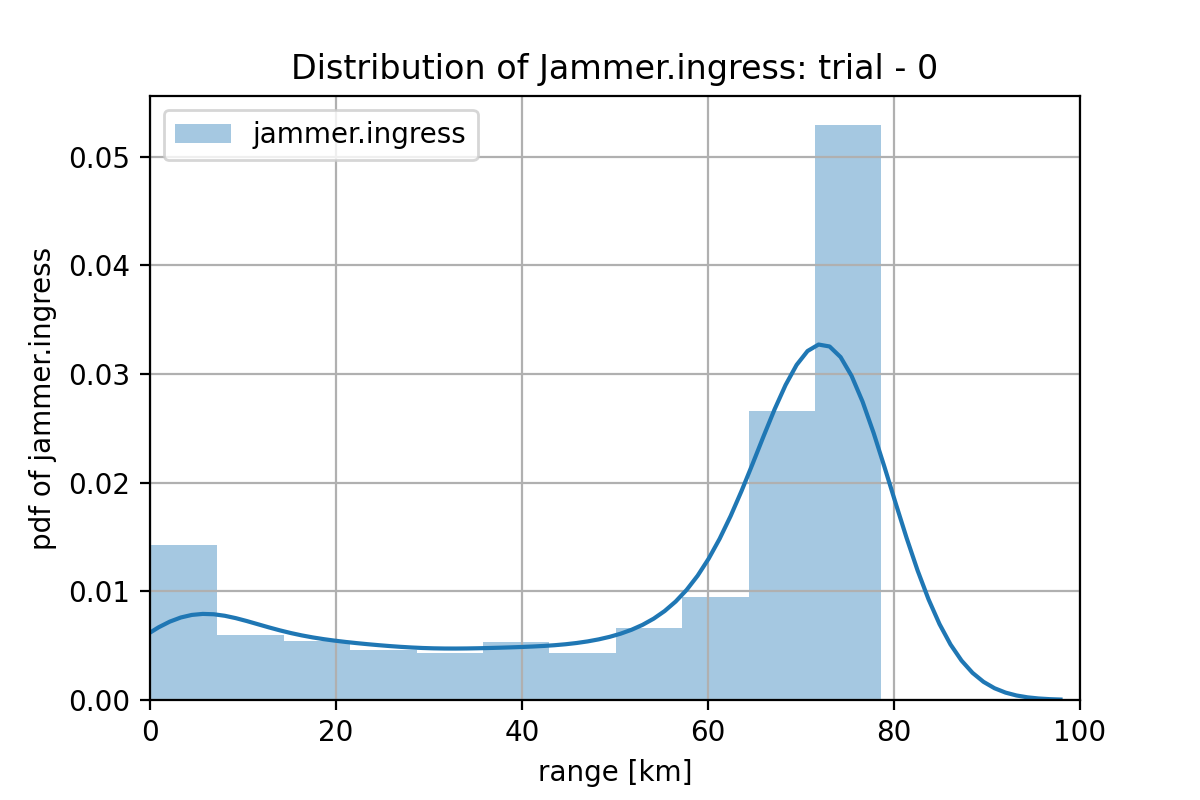
図2.3.9
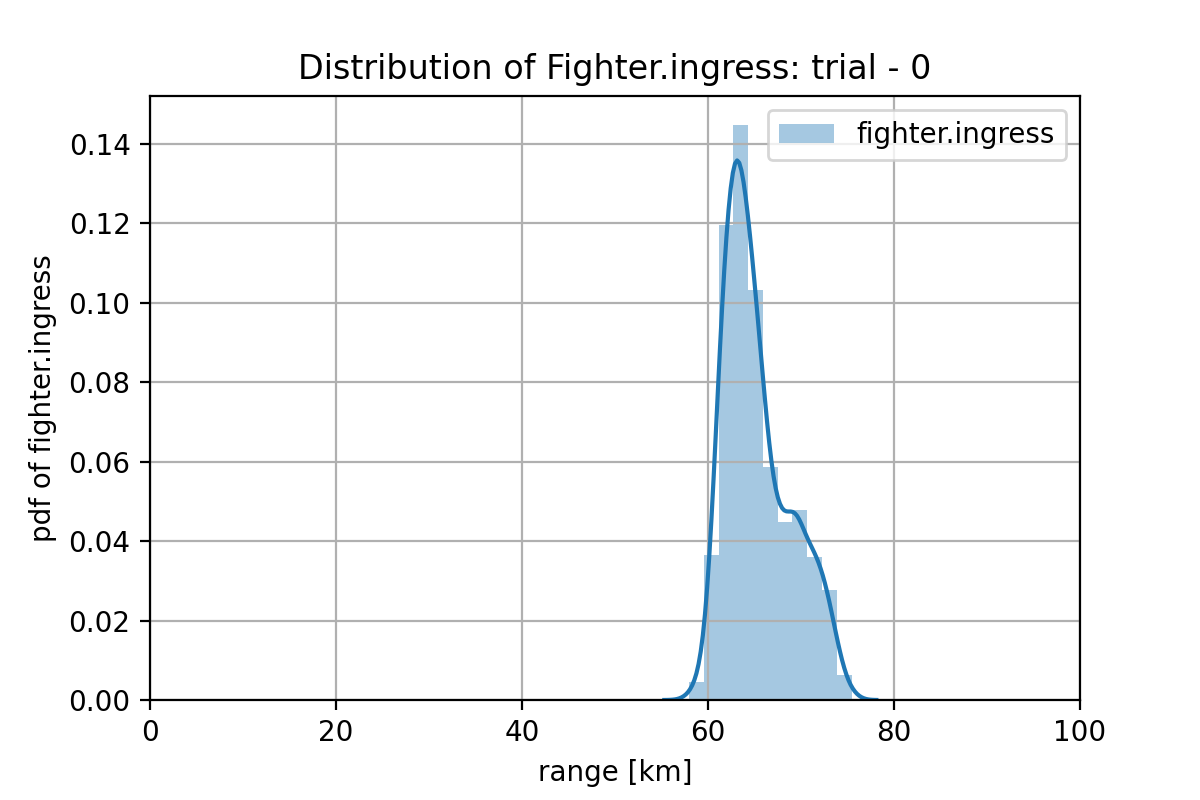
図2.3.10
(その6へ続く)
トレーニング・データの重要性と GAN プランナーの改善
上記から、問題の1つは、トレーニング・データの内訳として、w1, w2, w3 のトレーニング・データ数が極端にアンバランス(w1 : w2 : w3 = 373 : 590 : 51713)なことが考えられました。
(その6)では、トレーニング・データの重要性を示すために、トレーニング・データを少し作為して、w1 : w2 : w3 = 15000 : 15000 : 15000 となるようにトレーニング・データ数をバランスさせて学習してみます。15000 は、これまでのデータ数と合わせるために、全体のデータ数が 50000程度 になるよう決めたものです。GAN の性能が、どの程度向上するのでしょうか?