本記事は、ランド研究所の「機械学習による航空支配」を実装する(その9)です。
実装したコードは、GitHub にあります。今回使用する環境は 'myenv_v1', 'myenv_v2' フォルダ、トレーニング用のファイルは 'stable_baselines' フォルダ内の 'training_actor_critic-v1.py', 'training_actor_critic-v2.py' です。
過去の記事へのリンクは最下段にあります。
1. 少しだけ複雑な環境
(その8)では、ミッションに成功できるミッション条件だけで学習を行いました。しかしながら、実際には、SAM の射程が非常に長い等の理由で、どう頑張ってもミッションに成功できないケースがあるはずです。このような時には、無理に進出せずに安全な場所で滞空するよう学習させる必要があります。このため、下表にある、どう頑張ってもミッションに成功できないミッション条件 l1, l2 を追加して学習させてみます。
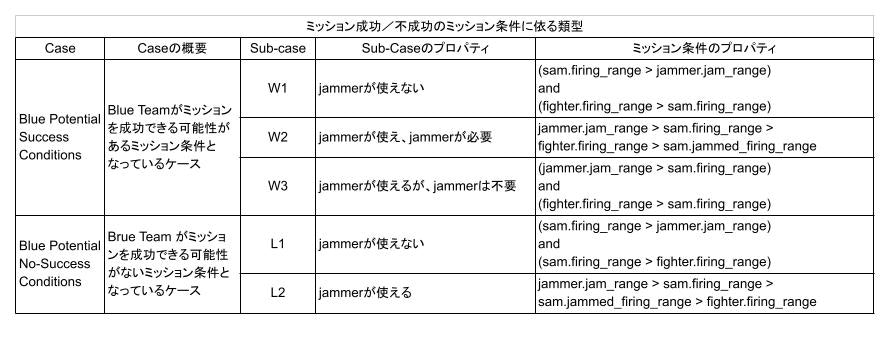
ミッションに成功できないミッション条件の時の報酬をどう与えるのかは重要です。ここでは、ミッション条件が l1、又は l2 の時には、シミュレーションの最大ステップ終了時点で Fighter と Jammer が共に生き残っていれば報酬+1が得られるようにしました。これにより、Blue Team は成功する可能性がなければ SAM の要撃範囲に侵入しなくなるはずです。(これにより、学習時のシミュレーション時間が増大し、結果として学習時間が増大します)。
また、w1, w3 のミッション条件では、敢えて Jammer を進出させる必要がないので、シミュレーション終了時点で、 Fighter と Jammer が共に生き残り、SAM が破壊されているのみならず、Jammer がオフになっている(つまり、Jammer が SAM から十分に離隔している)ことを成功の条件とし、この時のみ報酬+1を与えることとしました。これにより、w1 や w3 のミッション条件の時は、Jammer は前進しなくなるはずです。これは、制約を増やす方向なので、強化学習問題としては難しくなるはずです。
以上のために、コードでは、報酬函数を以下のように変更しています。
def get_reward_4(self, done):
reward = 0
# For done
if done:
if (self.mission_condition == 'w1') and (self.fighter.alive > .5) and \
(self.jammer.alive > .5) and (self.jammer.on < .5) and (self.sam.alive < .5):
reward = 1
elif (self.mission_condition == 'w2') and (self.fighter.alive > .5) and \
(self.jammer.alive > .5) and (self.jammer.on > .5) and (self.sam.alive < .5):
reward = 1
elif (self.mission_condition == 'w3') and (self.fighter.alive > .5) and \
(self.jammer.alive > .5) and (self.jammer.on < .5) and (self.sam.alive < .5):
reward = 1
elif (self.mission_condition == 'l1') and (self.fighter.alive > .5) and (self.jammer.alive > .5):
reward = 1
elif (self.mission_condition == 'l2') and (self.fighter.alive > .5) and (self.jammer.alive > .5):
reward = 1
else:
reward = -1
return reward
※ Agent には、観測として陽に w1, w2, w3, l1, l2 の条件は与えていません。トレーニング用のプログラムが使うだけです。Agent は観測から、自分が置かれた状況を分類し、適切なアクションを起こすことを学習する必要があります。
2. Agent
(その8)で一番性能が良かったPPO2+並列環境数=8で学習させました。ネット・アーキテクチャやハイパー・パラメータは(その8)と同じくデフォルトのままです。
3. 学習履歴
3.1 Fighter, Jammerの初期位置が固定の場合
環境は 'myenv_v1' フォルダ、トレーニング用のファイルは 'stable_baselines' フォルダ内の 'training_actor_critic-v1.py'です。
fighter.ingress, jammer.ingress の初期値をそれぞれ 0 km で固定して学習させた場合の学習履歴を下図に示します。縦軸は1000エピソードでテストした時の平均リターン [-1, 1] です。横軸は、学習ステップ数です。薄い紫又は赤ラインが平均リターンの生値、濃い紫又は赤ラインが α=0.9 の指数移動平均(EMA: Exponential Moving Average)です。(途中まで紫色になっているのは、一度そこで学習を中断したためです。最初に思ったよりも、長い学習時間が必要でした。深い意味はありません。)
図3.1

3.2 Fighter, Jammerの初期位置がランダムな場合
環境は 'myenv_v2' フォルダ、トレーニング用のファイルは 'stable_baselines' フォルダ内の 'training_actor_critic-v2.py'です。
fighter.ingress, jammer.ingress の初期値をそれぞれ [-10, 0] km の範囲内でランダムに設定して学習させた場合の学習履歴を下図に示します。1回しか試行していないので正確ではありませんが、初期値が0固定の場合に比べると、少し学習は難しそうですが、ベストの獲得性能は同等レベルに見えます。
図3.2

4. 獲得性能
4.1. Fighter, Jammerの初期位置が固定の場合
ミッション条件 l1 の性能が少し悪いのですが、他は 98% 以上のミッション成功率となり、ベースラインであるランダム・プランナーよりはずっと高い性能を達成しました。
表4.1

図4.1
![Success Ratio [%] (1).png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2F15245f5d-d2a4-de3d-619f-ca843ac36cf2.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=9f9dc53783facaae142c049d3f15c481)
4.2. Fighter, Jammerの初期位置がランダムな場合
初期位置固定の場合と、同等の性能が達成できました。ミッション条件 l1 の場合は、初期位置固定の場合よりも性能が改善しています。ただ、乱数系列を変えて調べてみないと、毎回こういった結果となるのかは判りません。条件の振れ幅がある中で上手く学習できるのであれば、そのほうが汎化能力は高くなる気はします。
表4.2

図4.2
![Success ratio [%] (1).png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F366937%2Fbb807955-40b9-39e5-dc2f-cb8e3551e939.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=177ad407a6d3404d437264aaaf42882c)
5. ミッション・プランの例
以下の動画では、濃紺の丸が Fighter、半透明で濃紺の大きな円が Fighter の射程、緑色の丸が Jammer、半透明で緑色の大きな円が Jammer の有効レンジ、赤の丸が SAM 配備位置 、半透明で赤色の大きな円が SAM の射程を表しています。SAMの射程を表す円は、ジャミングを受けると、それに対応した大きさの円に変わります。また、Fighter, Jammer, SAM が一直線上に並んでいませんが、これは単に見やすくするために Fighter と Jammer 位置を少しだけオフセットさせて表示しているためです。計算は、1次元上の交戦となっています。
Fighter, Jammerの初期位置がランダムな場合の生成プランの例を示します。
ミッション条件が w1, w3 の時は、Agent が、Jammerを前進させないことに対してインセンティブを持つように報酬を与えてので、(その9)で学習させたAgentに比べ、必要が無い時には Jammer を前進させないようにプランが生成されています。
5.1. w1
Jammer を前進させることなく、FighterでSAMを攻撃するプランを生成する必要がある条件です。下に示すように、必要なプランが生成できています。(その8)と違って、Jammerを前進させないことにインセンティブを持つように報酬を与えているので、Jammerは前進していません。
{
"Mission": "Success without using Jammer",
"mission_condition": "w1",
"fighter": {
"alive": 1,
"initial_ingress": -3.0,
"ingress": 61.0,
"firing_range": 38.0
},
"jammer": {
"alive": 1,
"initial_ingress": -6.0,
"ingress": -6.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 99.0,
"firing_range": 31.0,
"jammed_firing_range": 21.7
}
}

5.2. w2
まず SAM の射程を縮退できるところまで Jammer を前進せた後に、そこで Jammer を滞空させます。次に、Fighter を前進させて SAM を撃破するプランを生成します。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 75.0,
"firing_range": 19.0
},
"jammer": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 64.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 94.0,
"firing_range": 23.0,
"jammed_firing_range": 16.099999999999998
}
}

別の例を示しておきます。
{
"Mission": "Success with using Jammer",
"mission_condition": "w2",
"fighter": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 51.0,
"firing_range": 18.0
},
"jammer": {
"alive": 1,
"initial_ingress": -2.0,
"ingress": 40.0,
"jamming": 1
},
"sam": {
"alive": 0,
"offset": 69.0,
"firing_range": 24.0,
"jammed_firing_range": 16.799999999999997
}
}

5.3. w3
Jammer を前進させることなく、Fighter のみを前進させて SAM を撃破するプランを生成しています。Jammerを前進させないことにインセンティブを持つように報酬を与えているので、Jammerは前進していません。
{
"Mission": "Success without using Jammer",
"mission_condition": "w3",
"fighter": {
"alive": 1,
"initial_ingress": -4.0,
"ingress": 51.0,
"firing_range": 26.0
},
"jammer": {
"alive": 1,
"initial_ingress": -7.0,
"ingress": -7.0,
"jamming": 0
},
"sam": {
"alive": 0,
"offset": 77.0,
"firing_range": 21.0,
"jammed_firing_range": 14.7
}
}

数は少ないのですが、Jammerを前進させてSAMの射程を(不必要なのですが)縮退させたのちにFighterを前進させるプランを生成することもありました。

5.4. l1
Jammer を前進させはするのですが、Jammer が SAM の射程に入る前に滞空状態で維持するプランを生成します。Fighter は前進させません。
{
"Mission": "Success without using Jammer",
"mission_condition": "l1",
"fighter": {
"alive": 1,
"initial_ingress": -4.0,
"ingress": 0.0,
"firing_range": 37.0
},
"jammer": {
"alive": 1,
"initial_ingress": -9.0,
"ingress": 39.0,
"jamming": 0
},
"sam": {
"alive": 1,
"offset": 84.0,
"firing_range": 39.0,
"jammed_firing_range": 27.299999999999997
}
}

これは、珍しくミッションに失敗した例です。Jammerの進出を止めきれなかったことが判ります。
{
"Mission": "Failed",
"mission_condition": "l1",
"fighter": {
"alive": 1,
"initial_ingress": -9.0,
"ingress": -9.0,
"firing_range": 29.0
},
"jammer": {
"alive": 0,
"initial_ingress": -3.0,
"ingress": 18.0,
"jamming": 0
},
"sam": {
"alive": 1,
"offset": 52.0,
"firing_range": 34.0,
"jammed_firing_range": 23.799999999999997
}
}

5.5. l2
こちらも、Jammer を前進させますが、SAMの射程に入らないように滞空させています。
{
"Mission": "Success with using Jammer",
"mission_condition": "l2",
"fighter": {
"alive": 1,
"initial_ingress": -3.0,
"ingress": 9.0,
"firing_range": 11.0
},
"jammer": {
"alive": 1,
"initial_ingress": -8.0,
"ingress": 33.0,
"jamming": 1
},
"sam": {
"alive": 1,
"offset": 63.0,
"firing_range": 20.0,
"jammed_firing_range": 14.0
}
}

6. まとめ
報酬を工夫することで、意図したプランを生成できるように、Agentを強化学習できることが判りました。
7. 感想
1D 問題を通して感じたことをまとめます。
GAN プランナーを上手く学習させるのに重要なことは、学習したいミッション全体をカバーしているデータを、バランスよく使うことだと痛感しました。データが沢山あるだけではダメです。データが、ドメインをカバーしているのかどうか見極めるのは、それを使う人間側のミッション(ドメイン)知識の問題です。AI はツールにしかすぎません。
強化学習プランナーについても、同じように、ミッション全体をバランスよくカバーするように、Agent を環境とインタラクトさせることが重要だと感じました。ここでもやはり重要なのはドメイン知識です。End to end で AI が全てやってくれるわけではありません。AI は Stable baselines のようなツールを使えばなんとかなります。今後、もっと多くの便利で使いやすいツールが出てくるでしょう。しかし、その AI をラップするドメイン知識は、今のところ、AI を使う人間が持っている知識です。
やがては、これらの領域も AI がカバーしてくれる時代が来るのかもしれませんが、現時点では無理です。おそらく、ランド研究所は、これらのことが十分に分かっているので、`AI Mission Planning' ではなく、 'AI Assisted Mission Planning'という副題のレポートとしたのでしょう。
また、GAN プランナーの場合は、プランの分布をみることで GAN プランナーがどういったプランを生成しようとしているのか理解することができました。これは強化学習プランナーには無い特徴です。強化学習プランナーでは、細部のタイミング制御までプランニングしてくれる代わりに、なぜそのプランを生成したのかは全く判りません。この分野は、Explainable RL として現在盛んに研究されている分野ですので、今後の発展に期待したいと思います。興味がある方は、以下のサーベイ・ペーパなどを参考にしてください。
(その10へ続く)
これまで、GAN プランナーと強化学習プランナーという2種類のプランナーを学習させてきました。
Rand 研究所のレポートでは、この2つは全く別々に扱われていて、連携までは考慮されていません。レポートは、ここで唐突に 2D 問題に移っています。しかしながら、せっかくプランナーを2種類作ったので、(その10)では、それぞれの特徴を活かして、2つのプランナーを連携させることを試みたいと思います。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上
- ランド研究所の「機械学習による航空支配」を実装する(その7):1D simulator for RL の実装
- ランド研究所の「機械学習による航空支配」を実装する(その8): Stable Baselines による強化学習