本記事は、ランド研究所の「機械学習による航空支配」を実装する(その7)です。
(その6)までで、1D 問題に対する GAN によるミッション・プランニングの実装は終了しました。過去の記事へのリンクは、最下段に有ります。
今回からは、1D 問題に対する 強化学習(RL: Reinforcement Learning)を使ったミッション・プランニングを実装します。GAN はサンプル・データから学習するアルゴリズムでしたが、強化学習は環境との step-by-step のインタラクションを通して学習するアルゴリズムです。
実装した codes は、GitHubにあります。シミュレータは、アップデートした順に、'myenv', 'myenv_1', 'myenv_2'のフォルダになっています。これらは、ミッション条件が異なる(順に難しくなる)だけです。今回は、'myenv'を使用します。またフォルダ構成になっているのは、OpenAi Gym のカスタム環境として登録するためです。
1. 深層強化学習
強化学習は、価値反復法(Value iterations)や方策反復法(Policy Iterations)を確率近似することで、最適ポリシーや最適価値函数をオンライン学習していくアルゴリズムの総称です。
強化学習の枠組みは下図で表されます。(この図は、下記の有名な著作からの引用です)。
Reinforcement Learning: An Introduction (2nd edition), Sutton & Barto, 2018
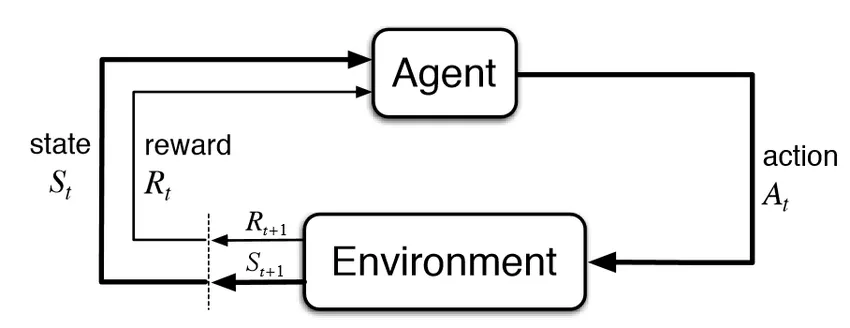
全体の枠組みは、エージェント(Agent)と環境(Environment)で構成します。Agent が強化学習の対象である AI で、ここに(deep な)ニューラルネットを使うのが深層強化学習です。Agent は、環境から状態 St(又は観測Ot) と報酬 Rt を受取り、それらの函数であるポリシー(Policy)にしたがってアクション At を決定し、環境に働きかけます。
ポリシーは、多くの場合、確率的にアクションを生成します。環境は、アクションを受けることによって、状態 St から、次のタイム・ステップにおける状態 St+1 に遷移します。環境も多くの場合、確率的(Stochastic)なものです。ただし、今回の実装は確定的(Deterministic)なものとなっています。
例えば、レーダや電子戦をちゃんと計算すると状態遷移は確率的になります。また、Fighter 搭載ウェポンや SAM の性能が完璧でないものとして定式化ししても、遷移は確率的になります。これらについては、将来実装したいと思っていますが、今回は扱いません。(ランド研究所のレポートでも扱っていません)。
Agent は環境から得られる報酬和が最大になるように、データを収集しながら(つまりオンラインで)ポリシー等を学習してゆきます。
また、図にあるように、全体の枠組みは離散時間です。したがって、step-by-stepでシミュレーションは進みます。
実装するシミュレータは、図の Environment に該当します。具体的には、Blue Team と Red Team の交戦をシミュレーションします。交戦は、ミッションが成功または失敗するか、予め決めておいた終了タイム・ステップに達するまで続けられます。ミッションの成功、失敗の定義は GAN を使ったミッション・プランニングの時と同じとしました。したがって、シミュレーション終了時点で Fighter と Jammer が生き残り、SAMが撃破されている時のみミッション成功で、それ以外の時はミッション失敗です。
2.強化学習問題としての 1D ミッション・プランニング問題
1D 問題ですので、GAN の時と同様に、全てのイベントは1次元、つまり直線上で起こります。
ミッション・プランとして欲しいのは、Fighter と Jammer の進出距離とタイミングです。(今回は、タイミングもちゃんとプランニングします)。ミッション・プランは、各タイム・ステップでのアクションと、その結果として起きる状態遷移がつくる軌跡(trajectory)と見做すことができます。そこで、(GAN の時とは異なり)、強化学習で普通に行われているように、1タイム・ステップ毎にシミュレーションを進行させることとし、各タイムステップで適切なアクションを起こすように Agent を学習させます。これにより、学習した Agent がミッション・プランナーとして機能することになります。やっていることは、普通の強化学習の枠組みであり、ミッション・プランニングだからと言って特別なことは何もありませんので、サクサク作っていきます。
この枠組みは、GAN を使ったミッション・プランナーとは考え方が違います。GAN プランナーは、ミッション条件が与えられると、一気にFighter と Jammer の進出距離をプランニングします。また、進出のタイミングまではプランニングしません。一方、強化学習プランナーは、タイムステップ毎に、その時点の観測に基づいてどういったアクションをとるのかを決定して行きます。その結果として、Fighter と Jammer を、いつ、どこに進出させたら良いのかがプランニングされます。つまり、経路プランニングとタイミング・プランニングを行います。プランニングというよりは、逐次的な意思決定といったほうが良いかもしれません。したがって、シミュレーションのタイムステップを小さくして、対象としている時空間サイズを小さくし、フィデリティを上げていくことにより、そのまま戦闘レベルの戦術を生成することも可能です(今回は、そこまではやっていません)。
2.1 状態(state)と観測(observation):
強化学習は、マルコフ決定過程(MDP: Markov Decision Process)を前提としています。MDP となるように、状態(観測)、アクション、報酬を定義します。
ランド研究所のレポートを参考にして、状態(state)は以下としました。Noneとあるものは、エピソード毎に乱数で初期化します。
Fighter:
def __init__(self):
# Specifications
self.alive = 1
self.speed = 740. # km/h
self.ingress = None # km
self.previous_ingress = None # km
self.min_firing_range = self.FIGHTER_MIN_FIRING_RANGE
self.max_firing_range = self.FIGHTER_MAX_FIRING_RANGE
self.firing_range = None
Jammer:
def __init__(self):
# Specifications
self.alive = 1
self.jam_range = 30. # km
self.speed = 740. # km/h
self.ingress = None # km
self.previous_ingress = None # km
self.jam_effectiveness = 0.7 # Reduce ratio to the adversarial SAM range
SAM:
def __init__(self):
self.alive = 1
self.min_firing_range = self.SAM_MIN_FIRING_RANGE
self.max_firing_range = self.SAM_MAX_FIRING_RANGE
self.firing_range = None
self.jammed_firing_range = None
self.max_offset = self.SAM_MAX_OFFSET # km
self.offset = None
観測(observation)は、ダイナミクスが MDP となるように、以下としました。(ニューラルネット入力用に正規化しています)。
obs = []
obs.append(self.fighter.ingress / self.sam.max_offset)
obs.append(self.fighter.firing_range / self.fighter.max_firing_range)
obs.append(self.jammer.ingress / self.sam.max_offset)
obs.append(self.sam.offset / self.sam.max_offset)
obs.append(self.sam.firing_range / self.sam.max_firing_range)
obs.append(self.sam.jammed_firing_range /
(self.sam.max_firing_range * self.jammer.jam_effectiveness))
obs.append(self.sam.alive)
obs.append(self.jammer.on)
observation = np.array(obs) # (8,)
2.2 アクション(action):
アクションは、ランド研究所のレポートでも後退は入れていないようだったので、以下としました。(後退を入れるとアクション空間が広くなる分、学習が難しくなります)。
- Fighter のアクション:前進 (740km/h) 又は停止 (0km/h) の2値
- Jammer のアクション:前進 (740km/h) 又は停止 (0km/h) の2値
もちろん、Fighter も Jammer も固定翼機なので実際には停止できません。これは、便宜的な表現で、旋回でもしているものと考えてください。今回は、そこまでの Fidelity を持つシミュレータを実装するわけではありません。
このアクションをどう表現するかですが、OpenAi Gym 自身は、Multi-discrete に対応しているので、Fighter と Jammer のアクションを別々に実装することができます。しかしながら、強化学習ツールは、Multi-discrete には対応していないことがあるので工夫が必要です。ここでは、各タイムステップで Agent がとることができるアクションは、以下の4つのうちの一つとして実装しました。dt はシミュレーションのステップ幅です。
- action_0 = [Fighter 停止、Jammer 停止] = [0, 0] * 740 km/h * dt
- action_1 = [Fighter 前進、Jammer 停止] = [1, 0] * 740 km/h * dt
- action_2 = [Fighter 停止、Jammer 前進] = [0, 1] * 740 km/h * dt
- action_3 = [Fighter 前進、Jammer 前進] = [1, 1] * 740 km/h * dt
コードとしては、以下で表せます。
ACTION_DIM = 4
ACTION_LIST = [[0, 0], [0, 1], [1, 0], [1, 1]]
Agent は、このアクションを n_action タイムステップ毎に更新します。つまり、n_action タイム・ステップ同じアクションが続きます。n_action を大きくするほど、報酬を得るまでのアクション数が少なくなるため、強化学習が容易になりますが、後述するシミュレーションの解像度(resolution)というか、粒度のようなものが粗くなるので、以下の実験は n_action=1 で行いました。
2.3 報酬(reward):
強化学習では、報酬の与え方が非常に重要です。報酬の与え方が、学習してほしいポリシーに対応していないと、意図するような学習をしてくれません。
ランド研究所のレポートでは、交戦終了時に、Fighter が生き残っていれば +2、Jammer が生き残っていれば +1、SAM が生き残っていれば -4(負の報酬)としてします。ただ、この設定の意味が書いてないので、分かったような、腑に落ちないような感じです。このため、実装では単純に、ミッションに成功すれば(Fighter と Jammer が生き残り、SAM が破壊されていれば)+1、成功しなければ(それ以外の時は) -1としました。
def get_reward_2(self, done):
reward = 0
# For done
if done:
if (self.fighter.alive > .5) and (self.jammer.alive > .5) and (self.sam.alive < .5):
reward = 1
else:
reward = -1
return reward
一般的に言って、このようにミッション終了時点でのみ報酬が与えられるような環境は、強化学習アルゴリズムにとって厳しいものとなります。人間でも同じですが、あるアクションをずっとやっていかないと報酬に結びつかない環境では、そこにたどり着く前に挫折したり、どのアクションが報酬につながったのか判り難いため、なかなか学習が進みません。
幸いこの問題では、SAM の位置(sam.offset)がエピソード毎に乱数で変わるので、Figter や Jammer に近い場所に、偶々 SAM が配備されるケースが生じます。これにより、比較的短いタイム・ステップで 1 又は −1 の報酬が得られるエピソードが生じます。このように、問題設定自体にある種のカリキュラム学習が組み込まれているため、ビンテージ・マシンでも比較的容易に強化学習できることが期待できます。
3."1D simulator for RL" の仕様
シミュレータの実装に当たっては、現実の連続時間空間を離散時間空間で模擬するので若干の注意が必要です。
例として、Fighter.ingress が現時刻で 8km で、これが 9km を超えると SAM が Fighter 搭載ウェポンの射程に入り SAM を撃破でき、10km を超えると逆に自分が SAM の射程に入り SAM に撃破されるものとします。また、ウェポンや SAM の能力は完璧で速度は ∞ とします。この場合、連続時間空間であれば、イベントは順繰りに発生するので、Fighter は SAM を撃破でき、SAM が Fighter に撃破されることはありません。(Fighter 搭載ウェポンと SAM のミサイル速度は ∞ としています)。しかし、1回のタイムステップで Fighter が 2km 以上進んでしまうような離散時間空間では、Fighter, SAM がともに撃破される判定になり、結果はドローとなってしまいます。このように実際と異なる状況が発生するのを避けるように、シミュレーションのタイム・ステップに注意してコーディングする必要があります。以下の仕様で、resolution とあるのが、これに対応するシミュレーションの解像度で、シミュレーションで使用するいろいろな数値の最小単位になります。
- resolution = fighter.speed * dt * n_actions
以下の実験では、resolution=1km となる(1タイムステップで Fighter, Jammer が 1km進む)よう、dt=1/fighter.speed=1/740[h]=4.86[s], n_actions=1と設定しています。
以上を踏まえ、シミュレータの仕様は、ランド研究所のレポートを参考にして以下としました。
AFGYM の設定に合わせた仕様:
- レーダ方程式等の計算は一切しない
- エージェントは、あらかじめ決められた範囲内に相手がいれば自動的に攻撃する
- EW(Electorical Warfare, 電子戦)の計算は一切せず、単純に SAM の射程のパーセント減少として計算する。
追加で明記した仕様:
- SAM と Fighter 搭載ウェポンの速度は非常に早く、射程内に入った瞬間(シミュレーションの1ステップ以内)に相手を撃破できる。
- SAM ミサイル と Fighter 搭載ウェポン の攻撃能力は 100%、つまり SAM も Fighter も射程内に入った相手を 100% 確実に撃破できる。
- Jammer は、jammer.jam_range(30km)内に SAM が入った瞬間に、SAM の射程を一挙に 70% 縮退させる(70% は、Figure 2.1、Figure 2.2で、100km →70km となっていることから設定したものです。)
- resolution = 1km
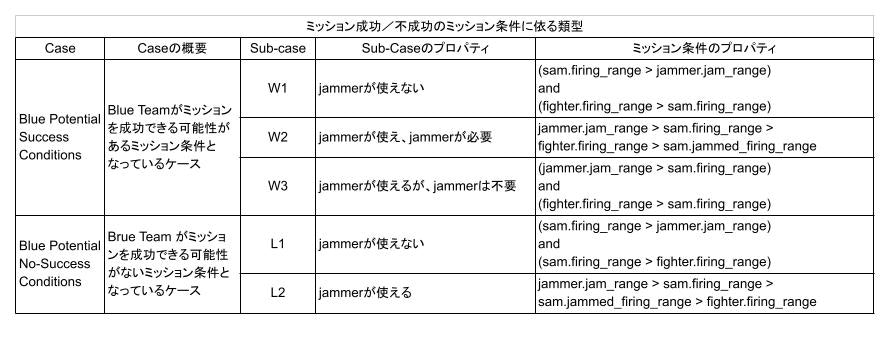
強化学習のフィージビリティを測るために、簡単な環境から始めます。このため、ミッション条件としては、GAN の結果を踏まえ、成功の可能性がある条件 w1, w2, w3 のみとします。(ミッション条件 l1, l2 を加えたケースは、次の段階の問題として別途実施します。)w1, w2, w3 の定義は GAN と同様に、下表としています。
表3.1
また、Fighter と Jammer の初期位置は、[0, -10] km の間でランダムに設定しました。ランド研究所と同様に、初期位置を固定して実験したのですが、これでは問題が簡単すぎて、Agent はあっという間に学習してしまいました。ランド研究所のレポートでも、DQN で学習は瞬時に終わっています。これでは、さすがに面白くないので、少し問題を難しくしています。(初期位置をランダムにすることによって、ミッション条件に応じて Fighter と Jammer を進出させるタイミングをうまくコントロールしなければならなくなるので、学習は難しくなります)。
4.Random action planner による性能
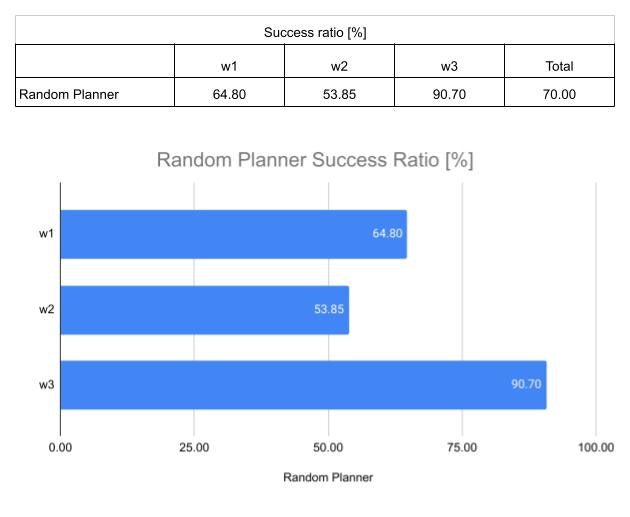
性能比較のベースラインとして、ランダム(一様分布)にアクションを選択するランダム・エージェントにより、シミュレーションを 10,000回 行って、プランの性能を見ました。
全体としてのミッション成功率は 70% でした。また、w1, w2, w3 の各ミッション条件での成功率は夫々 64.80, 53.85, 90.70 % でした。w1, w2 は少し難しく、w3 は割と簡単なミッションとなるようです。これは、今後ベースラインとして使うので、見やすく図表にしておきます。
※ この問題がランダム・アクションでも割と上手く行くのは、アクションが前進とストップの2通りであるためです。後に示しますが、アクションが、前進、ストップ、後退の3アクションになると、それだけで性能はずっと劣化します。
図表4.1
(その8)に続く
(その8)では、ミッション・プランを Agent に強化学習させます。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上