1. はじめに
本記事は、ランド研究所の「機械学習による航空支配」を実装する(その12)です。
(その11)では、ランド研究所のレポートから2次元問題についてまとめました。今回は、1次元問題のための環境を生成するシミュレータを拡張して、2次元問題のための環境を生成するシミュレータを実装します。これは下図の Environment に該当します。(この図は、下記の有名な著作からの引用です)。
Reinforcement Learning: An Introduction (2nd edition), Sutton & Barto, 2018
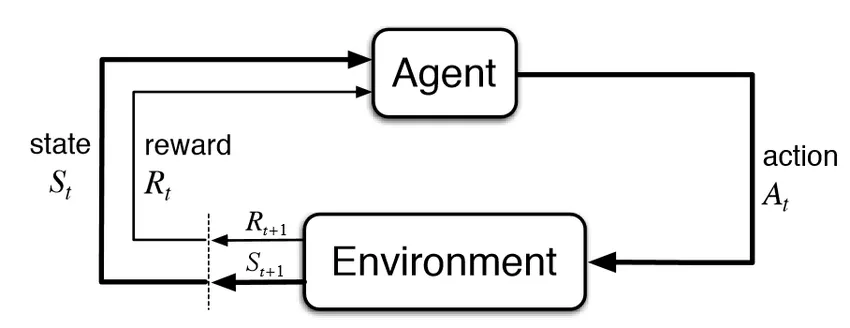
また、Agent が、ミッション・プランナーに該当します。これらの関係は、1D 問題と同じです。
今回以降の記事では、順番に、以下の各ミッションについて、強化学習エージェントのトレーニングを行って、どれくらいまで強化学習が対応できるのか探りながら進めていきます。ランド研究所のレポートには、ミッションの明確な定義や検討内容がきちんと記載されておらず、全体に曖昧模糊としているので、各ミッションの内容や設定はレポート記載内容から推定しました。
- Mission 1: Blue Team:{Fighter (x 1), Jammer (x 1)} vs Red Team:{SAM (x 1)}
- Mission 2: Blue Team:{Fighter (x 1)} vs Red Team:{SAM (x1), Target (x 1)}
- Mission 3: Blue Team:{fighter (x 3)} vs Red Team:{SAM (x1)}
- Mission 4: Blue Team:{fighter (x3), Decoy (x 1)} vs Red Team:{SAM (x1)}
また、今回は原理検証(PoC: Proof of Concept)が目的ですし、私のビンテージ・マシンの能力もありますので、全ミッションに対応できる汎用プランナーではなく、各ミッション毎に専用のプランナー(エージェント)を作ることにしました。理論的には、(つまり、十分速いマシンが用意できて、強化学習アルゴリズムがちゃんと働くようにいろいろと調整できれば)、汎用プランナーにそのまま拡張できる作りになっています。
今回の記事では、Mission 1 のためのシミュレータを作成します。といっても、やったことは 1D 問題用のシミュレータを二次元に拡張するだけのことです。Mission 2 以降では、各ミッションに対応するようにシミュレータの一部を修正して用います。
なお、画像の rendering には PyGame を使いましたので、PyGame のインストールが必要です。
作成したコードは下記 GitHub にあります。
過去記事へのリンクは、最下段にあります。
2. Mission 1
シミュレータを作る前に、ミッション1を定義します。ミッション1は、1D 問題を二次元に拡張したミッションです。Blue Team, Red Team の構成は夫々以下とします。
Blue Team
- Fighter 1機
- Jammer 1機
Red Team
- SAM 1基
ミッション条件は、以下とします。
Fighter は、Jammer 無しでは SAM を撃破できないが、Jammer を適切なタイミングと場所に進出させれば、Fighter は Jammerを撃破できる。
これは、1D 問題の時のミッション条件 w2 に相当します。
今回は、原理検証(PoC: Proof of Concept)なので、学習の成否判断がしやすいように、学習が上手くできればミッション成功率が 100% になるよう、1D 問題で一番難しかったミッション条件 w2 のみを使用しました。
したがって、不等式で各エンティティの射程、ジャムが有効な距離(jammer.jam_range)の間の関係を記述すると以下となります。
jammer.jam_range > sam.firing_range > fighter.firing_range > sam.jammed_firing_range
3. 2D simulator の基本仕様
2D 問題における Fighter と SAM の性能は、ランド研究所のレポートでは下の Table3.1 となっています。Fighter や SAM の射程が、1D 問題の時の約半分となっていますが、理由の記載はありません。また、Jammer 性能については記載が無く判りません。

実装では、1D 問題の時とある程度同じ性能値にしたかったのと、Table 3.1 の値だと絵にした時に射程が小さすぎて見難かったので、各射程(fighter.firing_range, jammer.jam_range)は一律2倍にしました。また、Jammer の有効レンジ(jammer.jam_range)は、1D 問題と同様 30km 固定、Jammer よる SAM の射程(sam.firing_range)の縮退は 70% (sam.jammed_firing_range = sam.firing_range x .7)としました。
以上から、シミュレータの仕様は、1D 問題の時のシミュレータの仕様を 2D に拡張にして、以下としました。シミュレーションの解像度を 1D 問題の時の半分 (0.5km) にした以外は変更はありません。解像度を半分にした理由は、単に強化学習の問題として少し難しくしようと思ったからです。
AFGYM の設定に合わせた仕様:
- レーダ方程式等の計算は一切しない
- エージェントは、あらかじめ決められた範囲内に相手がいれば自動的に攻撃する
- EW(Electorical Warfare, 電子戦)の計算は一切せず、単純に SAM の射程のパーセント減少として計算する。
追加で明記した仕様:
- SAM と Fighter 搭載ウェポンの速度は非常に早く、射程内に入った瞬間(シミュレーションの1ステップ以内)に相手を撃破できる。
- SAM ミサイル と Fighter 搭載ウェポン の攻撃能力は 100%、つまり SAM も Fighter も射程内に入った相手を 100% 確実に撃破できる。
- Jammer は、jammer.jam_range(30km)内に SAM が入った瞬間に、SAM の射程を一挙に 70% 縮退させる。
- Fighter, SAM の Firing range は Table 3.1 の2倍
- Fighter firing range = [7, 21] km random
- SAM firing range = [10, 21] km random
- resolution = 0.5km
4. 2D simulator for mission 1
マルコフ決定過程(MDP)を規定する状態、観測、アクション、報酬は以下の通りとしました。
4.1 State(状態)
状態変数については、1次元問題で使った simulator の状態変数を、2次元にしただけで大きな違いはありません。
Fighter に関連する状態は、以下の None となっている変数です。
def __init__(self):
# Observations
self.heading_sin = None
self.heading_cos = None
self.x = None # km
self.y = None # km
self.previous_x = None # km
self.previous_y = None # km
self.firing_range = None # km
self.weapon_count = None
self.alive = None
# Additional states
self.heading = None
エンティティのヘディングについては、レポートでは角度をそのまま [-1,1] で正規化したものを状態や観測として用いていましたが、360 度のところで不連続になるのを避けるために、heading に加えて(冗長表現にはなるのですが)、sin(heading_angle), cos(heading_angle) を追加しました。これらは、それぞれ正規化した速度ベクトルの x、y 成分に対応します。
previous_x, previous_y とあるのは、前のタイムステップでの、x, y 座標位置です。
ランド研究所のレポートに従って、weapon_count という状態量を追加していますが、これは将来の拡張用で今回は使っていません。
Jammer に関連する状態は、以下の None となっている変数です。
def __init__(self):
# Observations
self.heading_sin = None
self.heading_cos = None
self.x = None # km
self.y = None # km
self.previous_x = None # km
self.previous_y = None # km
self.on = None
self.alive = None
# Additional states
self.heading = None
SAM に関連する状態は、以下の None となっている変数です。heading については、状態(観測)量に入れていますが、これも将来の拡張用で、今回は使っていません。
def __init__(self):
# Observations
self.heading_sin = None
self.heading_cos = None
self.x = None # km
self.y = None # km
self.firing_range = None
self.jammed_firing_range = None
self.weapon_count = None
self.alive = None
self.previous_alive = None
self.jammed = None
# Additional states
self.heading = None
4.2 Observation(観測)
観測も、1次元問題で使った simulator の観測量を、2次元にするのが基本です。エンティティのヘディングについては、観測量としては1つ増えてしまうのですが、360度 で不連続に変化するのを避けるために、sin(heading_angle), cos(heading_angle) としました。その他は、基本的に 1D 問題の時と同じです。
したがって、Fighter に関連する観測は7つ、Jammer に関連する観測は6つ、SAM に関連する観測は8つになります。これらは、それぞれ、[0, 1] の範囲になるように正規化して用います。
def get_observation_mission_1(self):
obs = []
obs.append(self.fighter_1.heading_sin)
obs.append(self.fighter_1.heading_cos)
obs.append(self.fighter_1.x / self.space_x)
obs.append(self.fighter_1.y / self.space_y)
obs.append(self.fighter_1.firing_range / self.fighter_1.max_firing_range)
obs.append(self.fighter_1.weapon_count)
obs.append(self.fighter_1.alive)
obs.append(self.jammer_1.heading_sin)
obs.append(self.jammer_1.heading_cos)
obs.append(self.jammer_1.x / self.space_x)
obs.append(self.jammer_1.y / self.space_y)
obs.append(self.jammer_1.alive)
obs.append(self.jammer_1.on)
obs.append(self.sam_1.heading_sin)
obs.append(self.sam_1.heading_cos)
obs.append(self.sam_1.x / self.space_x)
obs.append(self.sam_1.y / self.space_y)
obs.append(self.sam_1.firing_range / self.sam_1.max_firing_range)
obs.append(
self.sam_1.jammed_firing_range / (self.sam_1.max_firing_range * self.jammer_1.jam_effectiveness))
obs.append(self.sam_1.weapon_count)
obs.append(self.sam_1.alive)
return obs
4.3 Action(アクション)
アクションについては、1D 問題が、前進、停止、(後退)の離散アクションだったのに対し、2D 問題ではエンティティ(Fighter と Jammer)の進行方向、すなわち、連続量であるヘディング角度がアクションになります(速度は、一定値としています)。したがって、アクション空間が連続(continuous action space)に対応できる強化学習アルゴリズムを使う必要があります。(例えば、Actor-Critic 系のアルゴリズムである PPO や A3C は連続アクション空間に対応しているので使えますが、DQN は離散アクション空間のみの対応ですので使えません)。
なお、レポートでは、ヘディング角そのものをアクション(プラン)としていましたが、角度変化の要求が、Fighter や Jammer の旋回性能を上回ってしまうので、ヘディング角の変化量(の正規化値)としました。Fighter, Jammer の旋回性能の上限値はレポートには書いてないので、ここでは 3 [deg/sec] とかなり小さく設定しました。これは、これ以上大きくすると学習が上手く進まなかったためです。(常識的な値にする工夫は後でやります)。
以上から、アクションは以下で与えています。
if self.mission_id == 'mission_1':
self.fighter_1.action = actions[0] * self.fighter_1.max_heading_change_step
self.jammer_1.action = actions[1] * self.jammer_1.max_heading_change_step
4.4 Reward(報酬)
報酬は、1D 問題の時と同じように、SAM を撃破したら 1、それ以外の時は -1 を与えました。コードでは下記になります。1D 問題用のシミュレータがベースになっているので、w2 以外のミッション条件についてもコードに記載がありますが、今回は、self.mission_condition == 'w2' のミッション条件だけが対象です。
def get_reward_mission_1(self, done, fighter, jammer, sam):
reward = 0
# For done
if done:
if (self.mission_condition == 'w1') and (fighter.alive > .5) and \
(jammer.alive > .5) and (jammer.on < .5) and (sam.alive < .5):
reward = 1
elif (self.mission_condition == 'w2') and (fighter.alive > .5) and \
(jammer.alive > .5) and (jammer.on > .5) and (sam.alive < .5):
reward = 1
elif (self.mission_condition == 'w3') and (fighter.alive > .5) and \
(jammer.alive > .5) and (jammer.on < .5) and (sam.alive < .5):
reward = 1
elif (self.mission_condition == 'l1') and (fighter.alive > .5) and (jammer.alive > .5):
reward = 1
elif (self.mission_condition == 'l2') and (fighter.alive > .5) and (jammer.alive > .5):
reward = 1
else:
reward = -1
return reward
(その13)へ続く
以上で 2D 問題用のシミュレータが作成できたので、(その13)では、Stable Baselines を使ってエージェントを強化学習し、ランド研究所のレポートの手法をそのまま適用した場合の限界と原因を探ります。
過去記事へのリンク
- ランド研究所の「機械学習による航空支配」を実装する(その1):レポートのまとめ
- ランド研究所の「機械学習による航空支配」を実装する(その2):1次元問題について
- ランド研究所の「機械学習による航空支配」を実装する(その3): 1D simulator for GAN と Random mission planner の実装)
- ランド研究所の「機械学習による航空支配」を実装する(その4): conditional GAN の実装とトレーニング
- ランド研究所の「機械学習による航空支配」を実装する(その5):トレーニング結果の分析
- ランド研究所の「機械学習による航空支配」を実装する(その6):トレーニング・データの重要性と GAN の性能向上
- ランド研究所の「機械学習による航空支配」を実装する(その7):1D simulator for RL の実装
- ランド研究所の「機械学習による航空支配」を実装する(その8): Stable Baselines による強化学習
- ランド研究所の「機械学習による航空支配」を実装する(その9): 少し複雑な環境
- ランド研究所の「機械学習による航空支配」を実装する(その10):GAN / 強化学習プランナーの連携を考える
- ランド研究所の「機械学習による航空支配」を実装する(その11): 2次元問題の概要