はじめに
「購入可能なビルディングブロックの一覧を入手してRDKitで処理したいなー」と思い、
以下の記事を参考に某試薬会社からデータを入手してみました。
製品名とCAS番号だけ取得するようコードを簡略化して実行してみたところ、
多くの製品では問題なく情報が取得できていたものの、
"title"を取得してからCAS番号と製品名に分割する方法が一部製品でうまくいきませんでした。
(CAS番号のない製品だと製品名の一部がCAS番号扱いされてしまう等)
今回、上記サイトのコードを改良して挙動を改善したので紹介します。
環境
- Windows 11
- python 3.8.8
- beatutifulsoup4 4.11.1
改良点
- タイトルを取得してCAS番号と製品名に分割するのがうまくいかない問題に関して
CAS番号はproductValクラス、製品名はnameクラスの情報を取得するようにしました。
name = soup.find('h1', class_ = 'name') #試薬名
CAS = soup.find('span', class_ = 'cas productVal') #CAS番号
- 製品情報取得を途中で打ち切る仕様の追加
(アルファベット名)+0000~9999の4桁の数字により製品コードをつくり、
順番にアクセスすることで情報を取得していましたが、
アルファベットの種類によっては製品数が少なく、9999までアクセスしても
殆どがPage Not Foundとなってしまう場合があります。
「大体100個くらい連続で製品がなかったらその先はアクセスしなくてもいいかな」と思い、
指定したマージン数だけPage Not Foundとなった場合に取得を打ち切るようにしてみました。
実際のコード
上記2点以外にも細かな修正が入っていますが、以下が実際のコードになります。
URLの部分は実際の試薬会社のURLに書き換えてください。
import pandas as pd
from tqdm import tqdm
import urllib.request
from bs4 import BeautifulSoup
import time
#パッケージの読み込み
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
#スクレイピングではなく、ブラウザからアクセスしていると見なされるようにするためのコード
#以下、データを取得してExcelファイルに保存する関数を定義
def collect_data(alphabet, start, end, margin):
df = pd.DataFrame(columns = ["ProductNumber", "Name", "CAS"]) #空のデータフレームつくる
code_number = [str(s).zfill(4) for s in range(start, end)] #4桁の数字の並びを作る
counter = 0
for code_ in tqdm(code_number):
code = alphabet + code_ #アルファベット+数字4桁を組み合わせて製品コードをつくる
#打ち切りの仕組み。counterの値がmarginで指定した値より小さいとき取得を続行する。
if counter < margin:
time.sleep(3) #サーバーに負荷をかけないように3秒間隔を空ける。
url = 'https://www.XXXX.com/JP/ja/p/{}'.format(code)
request = urllib.request.Request(url = url, headers = headers)
html = urllib.request.urlopen(request)
html.encoding = "EUC-JP"
soup = BeautifulSoup(html, "html.parser")
title = soup.find("title").text.split('|')[0].strip()
#製品がないかどうか判定し、なかったらcounterの値を+1する。
if "Page Not Found" in title:
print('{}:Not Found'.format(code))
counter += 1
pass
#製品がある場合、counterの値を0に戻し、情報取得を行う。
else:
print('{}:OK'.format(code))
counter = 0
name = soup.find('h1', class_ = 'name')
CAS = soup.find('span', class_ = 'cas productVal')
info = [code, name.text, CAS.text]
df.loc[code_] = info #取得した情報をデータフレームに格納
else:
pass
df.to_excel('compoundlist_{}.xlsx'.format(alphabet), index = False)
#データフレームをExcelファイルに保存
print("compounds_{} finished".format(alphabet)) #終了メッセージの表示
使用例
J0001からJ9999までアクセスし、20個連続で製品ページがない場合に打ち切る場合は
collect_data("J", 1, 10000, 20)
と書いて実行すればデータの取得が開始されます。
実行中は以下のように進捗が表示され、終了するとメッセージとともにファイルが保存されます。
0%| | 1/9999 [00:03<9:53:12, 3.56s/it]J0001:Not Found
0%| | 2/9999 [00:08<12:03:36, 4.34s/it]J0002:OK
0%| | 3/9999 [00:12<11:12:35, 4.04s/it]J0003:OK
0%| | 4/9999 [00:15<11:01:52, 3.97s/it]J0004:OK
0%| | 5/9999 [00:19<10:51:47, 3.91s/it]J0005:OK
0%| | 6/9999 [00:23<10:28:17, 3.77s/it]J0006:Not Found
0%| | 7/9999 [00:27<10:31:01, 3.79s/it]J0007:OK
0%| | 8/9999 [00:30<10:30:09, 3.78s/it]J0008:OK
0%| | 9/9999 [00:34<10:24:39, 3.75s/it]J0009:OK
0%| | 10/9999 [00:38<10:24:09, 3.75s/it]J0010:OK
0%| | 11/9999 [00:41<10:16:33, 3.70s/it]J0011:Not Found
0%| | 12/9999 [00:45<10:23:04, 3.74s/it]J0012:OK
0%| | 13/9999 [00:49<10:12:46, 3.68s/it]J0013:Not Found
0%| | 14/9999 [00:52<10:07:57, 3.65s/it]J0014:Not Found
0%| | 15/9999 [00:56<10:04:50, 3.63s/it]J0015:Not Found
0%| | 16/9999 [00:59<9:57:29, 3.59s/it] J0016:Not Found
0%| | 17/9999 [01:03<9:53:40, 3.57s/it]J0017:Not Found
0%| | 18/9999 [01:07<9:52:53, 3.56s/it]J0018:Not Found
0%| | 19/9999 [01:11<10:40:25, 3.85s/it]J0019:Not Found
0%| | 20/9999 [01:16<11:17:08, 4.07s/it]J0020:Not Found
0%| | 21/9999 [01:20<11:39:34, 4.21s/it]J0021:Not Found
0%| | 22/9999 [01:24<11:39:29, 4.21s/it]J0022:Not Found
0%| | 23/9999 [01:28<11:07:03, 4.01s/it]J0023:Not Found
0%| | 24/9999 [01:33<11:36:34, 4.19s/it]J0024:Not Found
0%| | 25/9999 [01:37<11:48:25, 4.26s/it]J0025:Not Found
0%| | 26/9999 [01:40<11:10:01, 4.03s/it]J0026:Not Found
0%| | 27/9999 [01:45<11:36:05, 4.19s/it]J0027:Not Found
0%| | 28/9999 [01:50<11:54:19, 4.30s/it]J0028:Not Found
0%| | 29/9999 [01:54<12:25:24, 4.49s/it]J0029:Not Found
0%| | 30/9999 [01:58<11:36:26, 4.19s/it]J0030:Not Found
0%| | 31/9999 [02:02<11:07:43, 4.02s/it]J0031:Not Found
100%|██████████| 9999/9999 [02:05<00:00, 79.54it/s] J0032:Not Found
compounds_J finished
もっと製品数が多いアルファベットの場合はプログレスバーも伸びてきます。
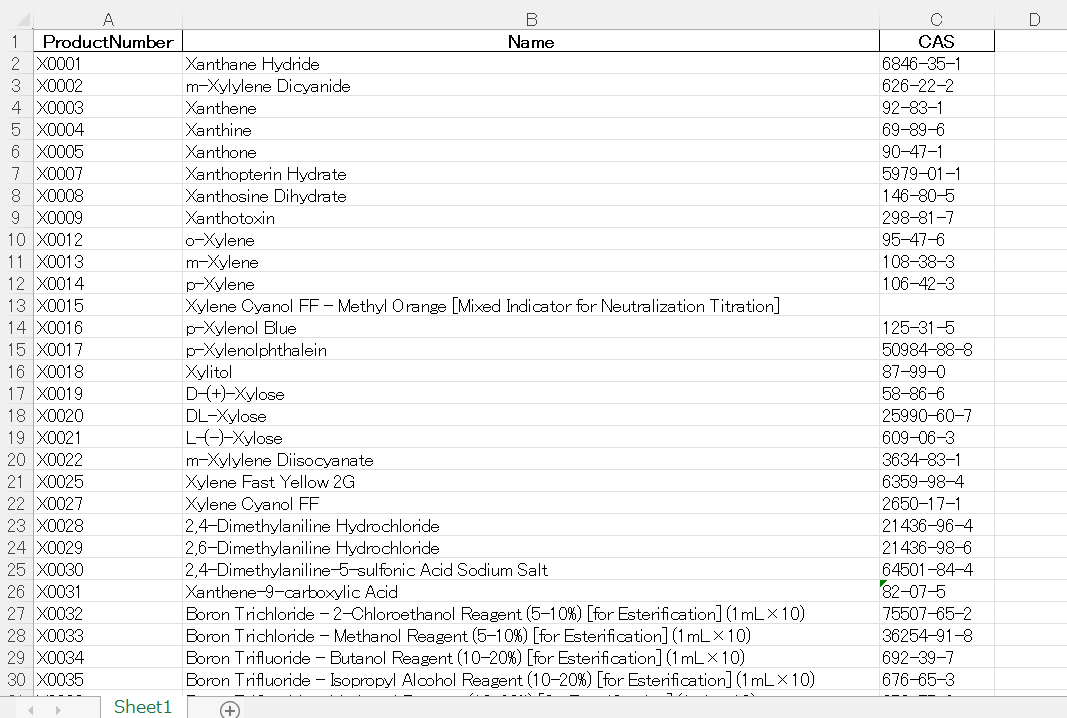
保存されたExcelファイルは以下のようになっています。

上の例では全ての製品にCAS番号がありましたが、ない場合は以下のように空欄になります。
(X0015のC列)
備考
今回の改良で開始番号や打ち切りマージンを指定できるようにしましたが、
打ち切りマージンの値をいくつにするかは結構難しいところで、
あまりにも大きな値を入れるとJのような製品数の少ないアルファベットで時間を浪費し、
逆に小さな値を入れてしまうとまだ製品があるのに打ち切ってしまうことになります。
今回情報を取得した試薬会社は製品名の頭文字がコード番号のアルファベットとなっており、
「製品名がBisで始まるものが全て入っているBは数多いかも」とざっくり推測が可能です。
数の多そうなアルファベットの場合は打ち切りマージンを大きく、
逆に数の少なそうなものについては打ち切りマージンを小さく設定するとよいでしょう。
(ちなみにAでは1,500弱番号が飛んでる部分がありました)
おわりに
某試薬会社から製品名とCAS番号を取得するコードを作成しました。
ケモインフォマティクス・マテリアルズインフォマティクスの世界ではしばしば
「インフォマティクスをやるためのデータが手元にない!」といった事態に直面しますが、
ひとまず試薬会社からデータを取得できると解析の足がかりになりそうです。
次回は取得した情報からSMILES構造式を取得する方法を紹介する予定です。
これまでの記事のシリーズ
RDKit入門①:まずは環境構築
RDKit入門②:1分子の読み込みと部分構造検索
RDKit入門③:複数分子の読み込み (前編)と分子群の描画
RDKit入門④:複数分子の読み込み (後編)とデータフレームの加工
RDKit入門⑤:データフレーム内の分子群に対する部分構造検索
RDKit入門⑥:Morganフィンガープリントの作成とそれを用いたタニモト係数の計算による分子類似性評価
RDKit入門⑦:反応式の取り扱い(前編)
RDKitで化学反応を扱った際の生成物群を整理し図示する方法
RDKit入門⑧:反応式の取り扱い(後編)
RDKitで化学反応を繰り返しつつ分子の重複数をカウント・記載する
RDKit入門⑨:データフレーム内の分子群に対する化学反応の適用とExcelファイルへの出力
RDKit入門⑩:データフレーム内の分子群に対する完全一致検索
指定した回数だけ化学反応を実施する関数の作成
BRICSフラグメントを利用した分子構造生成関数の簡略化
Butinaモジュールによる類似化合物のクラスタリング