ラビットチャレンジの提出レポートです。

<科目一覧>
深層学習:Day1 (NN)
深層学習:Day2 (CNN)
深層学習:Day3 (RNN)
深層学習:Day4 (Tensorflow & 強化学習)
1.要点まとめ
Section 1 : 再帰型ニューラルネットワークの概念
【RNN全体像】
■ RNNとは:時系列データに対応可能な、ニューラルネットワークである。
■ 時系列データとは:時間的順序を追って一定間隔ごとに観察され,しかも相互に統計的依存関係が認められるようなデータの系列
● 音声データ
● テキストデータなど
■ RNNについて
● RNNの中間層は、ある時刻の中間層からの出力を次の時刻の中間層に伝えるためのパスをもつ。それによって時刻 $t$ の中間層は、同じ時刻 $t$ の入力層からのインプットに加えて、前の時刻 $t-1$ の中間層からのインプットも受け取ることになる。
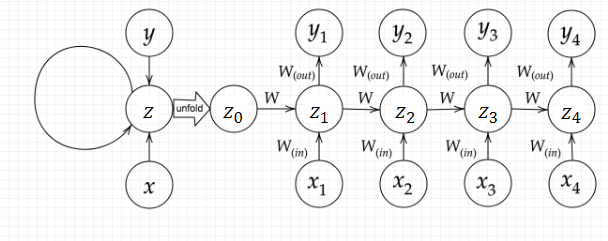
● 数式で表すと以下のようになる。そこで、$f , g$ は活性化関数とする。
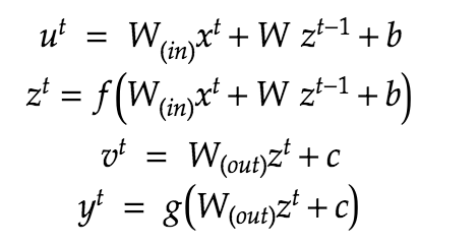
【BPTT- Backpropagation Through Time】
■ BPTTとは:RNNにおいてのパラメータ調整方法の一種
【BPTTの数学的記述】
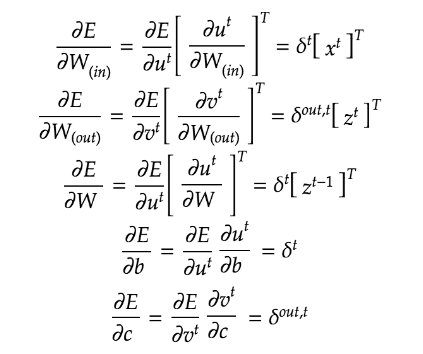
【パラメータの更新式】
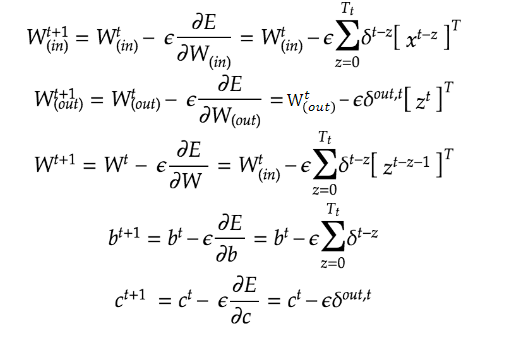
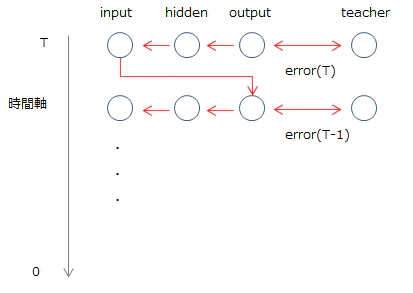
■ BPTTのイメージ
RNNは展開すると長いNNとみなすことができるので、通常通りbackpropagationが適用できるはず、というのが基本的な考え方です。イメージ的には以下のようになります。
誤差は最後の時刻であるTから最初の0に向かって伝播していきます。よって、ある時刻tにおけるoutput layerの誤差は「時刻tにおけるteacher(教師データ)とoutput(出力)の差異」と「t+1から伝播してきた誤差」の和になります。
図からも明らかなとおり、BPTTは最後のTまでのデータ、つまりすべての時系列データがなければ学習を行うことができません。そのため、長いデータは最新の分のみ切り取るなどといった対応が必要です。
Section 2 : LSTM(Long short term memory)
LSTM(Long short-term memory)は、RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データ(sequential data)に対するモデル、あるいは構造(architecture)の1種です。その名は、Long term memory(長期記憶)とShort term memory(短期記憶)という神経科学における用語から取られています。LSTMはRNNの中間層のユニットをLSTM blockと呼ばれるメモリと3つのゲートを持つブロックに置き換えることで実現されています。
(参考)わかるLSTM ~ 最近の動向と共に
【LSTMモデルの定式化】
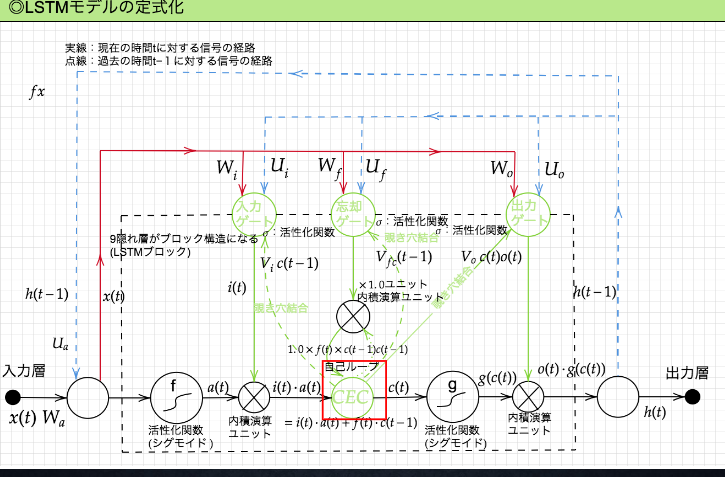
【Constant Error Carousel (CEC)】
■ 勾配消失および勾配爆発の解決方法として、勾配が、$1$ であれば解決できる。
■ **課題:**入力データについて、時間依存度に関係なく重みが一律である。
➡ ニューラルネットワークの学習特性が無いということ。
【入力ゲートと出力ゲート】
■ 入力・出力ゲートの役割とは:
入力・出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列 $W,U$ で可変可能とする。
➡ CECの課題を解決できる。
【忘却ゲート】
■ CECは、過去の情報が全て保管されているが、過去の情報が要らなくなった場合、削除することはできず、保管され続けるという問題点だある。
➡ 忘却ゲートは過去の情報が要らなくなった場合、そのタイミングで情報を忘却する機能がある。
【覗き穴結合】
■ **課題:**CECの保存されている過去の情報を、任意のタイミングで他のノードに伝播させたり、 あるいは任意のタイミングで忘却させたい。
➡ CEC自身の値は、ゲート制御に影響を与えていない。
■ 覗き穴結合とは?
CEC自身の値に、重み行列を介して伝播可能にした構造。
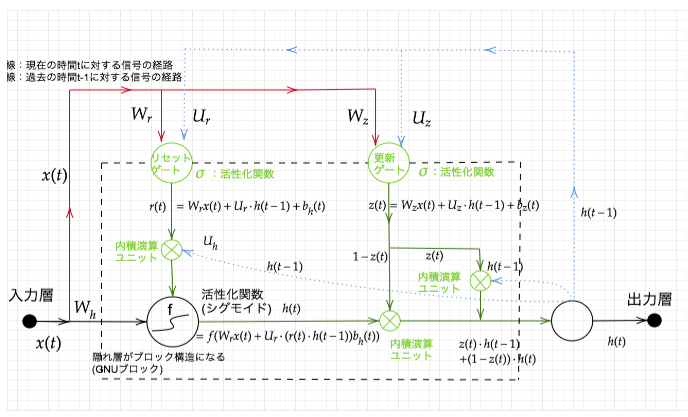
Section 3 : GRU
■ LSTMでは、パラメータ数が多く、計算負荷が高くなる問題があるため、GRUで解決する、
■ GRUとは?
LSTMのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった構造。
■ GRU全体図
Section 4 : 双方向RNN
■ 過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデル
■ 実用例:文章の推敲や、機械翻訳等
Section 5 : Seq2Seq
■ Seq2seqとは: Encoder-Decoderモデルの一種を指す。
■ 実用例:機械対話や、機械翻訳など
【Encoder RNN】
■ ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造
● Taking : 文章を単語等のトークン毎に分割し、トークンごとのIDに分割する。
● Embedding : IDから、そのトークンを表す分散表現ベクトルに変換。
● Encoder RNN : ベクトルを順番にRNNに入力していく。
■ Encoder RNN処理手順
● vec1をRNNに入力し、hidden stateを出力する。このhidden stateと次の入力vec2をまたRNNに入力してきたhidden stateを出力という流れを繰り返す。
● 最後のvecを入れたときのhidden stateをfinalstateとしてとっておく。このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる
【Decoder RNN】
■ システムがアウトプットデータを、単語等のトークンごとに生成する構造。
■ Decoder RNNの処理
● ①Decoder RNN : Encoder RNN のfinal state (thought vector) から、各token の生成確率を出力していくfinal state をDecoder RNN のinitial state として設定し、Embedding を入力。
● ➁Sampling : 生成確率にもとづいてtoken をランダムに選ぶ。
● ③Embedding: ➁で選ばれたtoken をEmbedding してDecoder RNN への次の入力とする。
● ④Detokenize: ①-③を繰り返し、➁で得られたtoken を文字列に直す。
【HRED】
■ HREDとは:過去 $n-1$ 個の発話から次の発話を生成する。
Seq2seqでは、会話の文脈無視で、応答がなされたが、HREDでは、前の単語の流れに即して応答されるため、より人間らしい文章が生成される。
■ HREDの構造は Seq2Seq + Context RNN
● Context RNN:Encoder のまとめた各文章の系列をまとめて、これ までの会話コンテキスト全体を表すベクトルに変換する構造。
➡ 過去の発話の履歴を加味した返答をできる。
■ HREDの課題:
● 会話の「流れ」のような多様性が無い
● 短く情報量に乏しい答えをしがちである。
【VHRED】
■ VHREDとは:⇒ HREDに、VAE(バエと呼ばれている)の潜在変数の概念を追加したもの。
■ HREDの課題を、VAEの潜在変数の概念を追加することで解決した構造。
【VAE】
■ オートエンコーダについて
● 教師なし学習の一つ
● 具体例:MNISTの場合、28x28の数字の画像を入れて、同じ画像を出力するニューラルネットワークということになる。
● オートエンコーダ構造:入力データから潜在変数 $z$ に変換するニューラルネットワークをEncoder、逆に潜在変数 $z$ をインプットとして元画像を復元するニューラルネットワークをDecoder。
● オートエンコーダのメリット:次元削減が行えること
■ VAEについて
● データを潜在変数 $z$ の確率分布という構造に押し込めることを可能にする。
Section 6 : Word2vec
■ 定義:
Word2Vecは、テキスト処理を行うためのニューラルネットワークのこと。膨大なテキストデータを解析し、単語の意味をベクトル化することでその意味の類似性を計算したり、単語同士の意味を足し引きしたりできるようになる。
■ Word2vecでは下記2つのモデルが使用されています。
● CBOW
● skip-gram
それぞれのモデルについては、以下のリンク先をご参照頂ける。
(参考)Word2Vecを理解する
(参考)絵で理解するWord2vecの仕組み
■ word2vecのメリット:
大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能にした。
Section 7 : Attention Mechanism
■ seq2seq の問題は長い文章への対応が難しいです。seq2seq では、2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならない
⇒ 解決案:文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく、仕組みが必要になる。これを「入力と出力のどの単語が関連しているのか」を学習する仕組みの Attention Mechanismが挙げられる。
■ Attention Mechanism の原理
以下のリンク先にてご参照頂ける。
seq2seq で長い文の学習をうまくやるための Attention Mechanism について
2.確認テスト
【P11】
**Q:**サイズ5×5の入力画像を、サイズ3×3のフィルタで 畳み込んだ時の出力画像のサイズを答えよ。 なおストライドは2、パディングは1とする。
**A:**以下の通りに、出力画像サイズは 3×3となる
{ OH =\frac{H+2P-FH}{S}+1} \\
{ OW =\frac{W+2P-FW}{S}+1}
【P23】
**Q:**RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。 残り1つの重みについて説明せよ。
**A:**中間層から次の中間層へ渡される重みとする。
【P36】
**Q:**連鎖律の原理を使い、dz/dxを求めよ。
z = t^2 \\
t = x + y
A:
$$\dfrac{\partial z}{\partial x}=\dfrac{\partial z}{\partial t}\dfrac{\partial t}{\partial x} =2t = 2(x +y)$$
【P45】
**Q:**下図の$y_1をx・s_0・s_1・w_{in}・w・w_{out}$を用いて数式で表せ。
A:
Z_1=sigmoid(S_0W+x_1W_{(in)}+b)\\
y_{1} = sigmoid ( z_{1} W_{(out)} + C )
【P62】
**Q:**シグモイド関数を微分した時、入力値が0の時に最大値をとる。その値 として正しいものを選択肢から選べ。
(1)0.15 (2)0.25 (3)0.35 (4)0.45
A:
f(z) = Sigmoid(z) ➡ f(0) = 1/2 \\
{f(z)' = (1 - f(z)) \cdot f(z) =1/4
}
【P78】
**Q:**以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。 文中の「とても」という言葉は空欄の予測において なくなっても影響を及ぼさないと考えられる。 このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か_____。」
**A:**忘却ゲート
【P88】
**Q:**LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
A:
● LSTMでは、パラメータ数が多く、計算負荷が高い
● CECでは、ニューラルネットワークの学習特性がない
【P92】
**Q:**LSTMとGRUの違いを簡潔に述べよ
**A:**LSTMでは、パラメータ数が多く、計算負荷が高いことに対して、GRUではそのパラメータを大幅に削減するので、計算負荷が低い。
【P109】
**Q:**下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用 するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再 帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を 導入することで解決したものである。
A:(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
【P119】
**Q:**seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ。
A:
● seq2seqとHREDの違い:Seq2seqでは、会話の文脈無視で、応答がなされたが、HREDでは、前の単語の流れに即して応答されるため、より人間らしい文章が生成される。
● HREDとVHREDの違い:HREDでは、同じコンテキストを与えられても、答えの内容が毎回会話の流れとしては同じものしか出れない問題に対して、VHREDでは、VAEの潜在変数の概念を追加することで解決できる。
【P128】
**Q:**VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
自己符号化器の潜 在変数に____を導入したもの。
**A:**確率分布
【P137】
**Q:**RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
A:
● RNNとword2vecの違い:RNNでは、単語のような可変長の文字列をNNに与えることはできない問題に対し、word2vecでは、膨大なテキストデータを解析し、単語の意味をベクトル化することができる。
● seq2seqとAttentionの違い:seq2seqでは、長い文章への対応が難しいが、Attentionでは、「入力と出力のどの単語が関連しているのか」 の関連度を学習する仕組みであり、seq2seqの問題を解決できる。
3.実装演習
【実装演習結果】
【考察】
■ weight_init_std = 1、learning_rate = 0.1で、hidden_layer_sizeの値を変更すると、以下の結果になる。
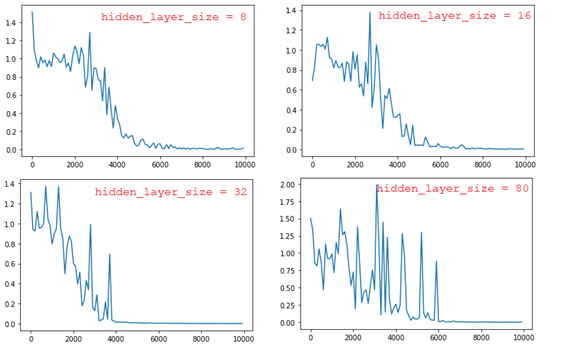
➡ hidden_layer_sizeの値が大きいほど、学習後のモデル評価(精度)が良くなるが、最初のepochでは、誤差が大きい。
■ learning_rate = 0.1、hidden_layer_size = 16で、weight_init_stdの値を変更すると、以下の結果になる。
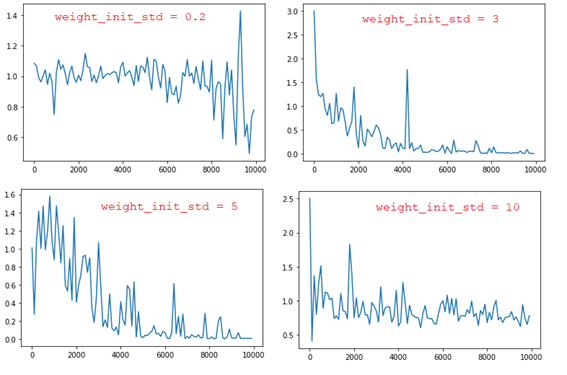
➡ weight_init_stdの値が大きいほど、勾配爆発問題が起こりやすくなる。また、小さいな値に対しても同様な勾配爆発問題が起こる。
(weight_init_stdの値は1~3の範囲内に良い結果が得られる)
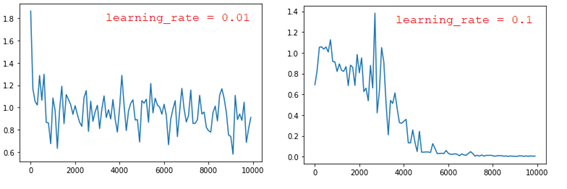
■ weight_init_std = 1、hidden_layer_size = 16で、learning_rateの値を変更すると、以下のように、learning_rateが小さくすれば、勾配爆発が起こる。
■ 重みの初期化方法を変更すると、以下の結果になる。
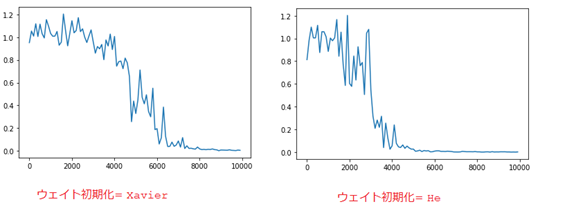
➡ モデルの精度がほぼ同じである。
■ 中間層の活性化関数を変更すると、活性化関数がReLUの場合は勾配爆発問題が発生する。
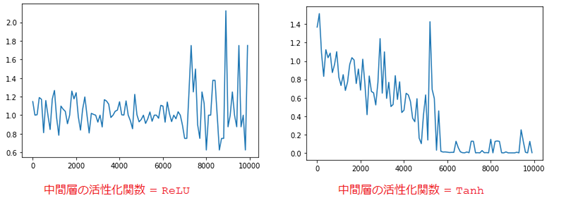
■ ハイパーパラメータのチューニング、重みの初期化方法や活性化関数などの選択は様々な組み合わせで最適化する必要があるが、難しいと感じました。
4.JDLA_Eシラバス_2020版より学習
本章では、E資格の試験に向けて、JDLA_Eシラバス_2020版よりある項目が本講義では学習内容範囲外とするので、自分で調べて学習内容をまとめていきます。
JDLA_Eシラバス_2020版
【識別モデルと生成モデル】
機械学習の分類問題は、識別モデルと生成モデルに大別される。
識別モデル(Discriminative model)
■ サンプルデータ $x$ がクラス $y$ に分類する条件付き確率 $P(y|x)$ を直接モデル化する。分類時は、$\hat{y}=argmax_yP(y|x)$を選択する。
分類問題で求めたいのは、個々のデータ $x$ がどのクラスに所属するかであり、識別モデルは所属確率を直接求めるモデルである。
生成モデル(Generative models)
■ 観測データを生成する確率分布を想定し、観測データからその確率分布を推定する方法。識別モデルと同様に条件付き確率 $P(y|x)$ をモデル化するがその方法が異なる。
(生成モデルでは直接これをモデル化しない。)
■ ベイズの定理:
$$\begin{eqnarray}P(y|x)=\frac{P(x|y)P(y)}{P(x)}\end{eqnarray}$$
分母の $P(x)$ はクラスに依存しないので、分類時には不要であるため、$\hat{y}=\arg \max _{ y }{P(x|y)P(y)}$ のクラスに分類する。
● $P(y)$ :クラスの割合である。
● $P(x|y)$ :観測されたデータ $x$ は、無作為に生成されるのではなく、何らかの分布に基づいて生成されると考える。この分布が、$y$ のクラスごとに異なっており、各クラスが観測データ $x$ を生成する確率(尤度)がどのくらいあるか、という値である。
■ $P(y|x)$ を直接求めるのではなく、$P(x|y)P(y)$を求めるということ。
(参考)機械学習・自然言語処理の勉強メモ
【GAN(Generative Adversarial Network)について】
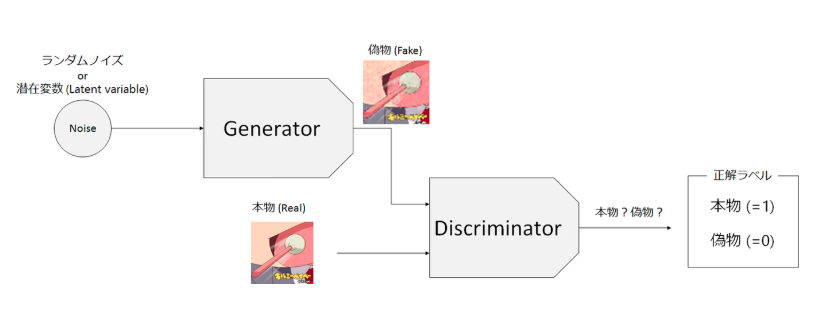
■ GANは生成モデルの一種である。
■ GANの全体仕組み:
GANは生成器$G$(Generator)と識別器$D$(Discriminator)という2つのニューラルネットからなる。生成器はランダムなノイズ画像から偽物の画像を生成し, 識別器は画像が教師データに含まれる「本物」か否かを判定する。
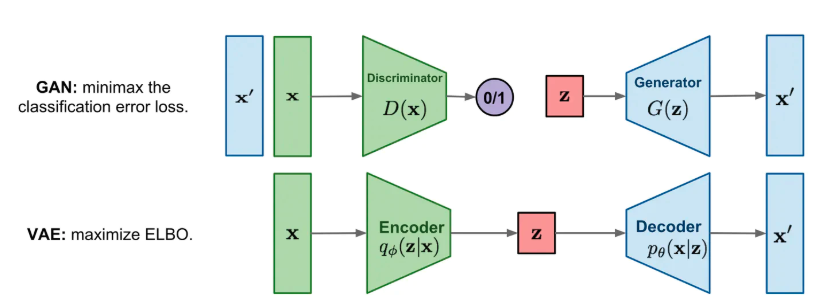
■ 生成モデルVAE(Variational Autoencoder)と比較すると、GANの最大の特徴は, Encoderを持たないことである。
(参考)深層生成モデルを巡る旅(3): GAN
(参考)GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
DCGAN(Deep Convolutional GAN)
■ Radford et al. (2015)によって提案されたDCGANはCNN(convolutional neural network)を使ったモデルになっている。
■ Radford et al. (2015)論文の要点を以下にまとめる。
● プーリングをやめる:CNNでは最大プーリングを使ってダウンサンプリングするのが一般的ですが、discriminatorではこれをストライド2の畳み込みに置き換えます。
● バッチノルムを使用する
● 深い構成では全結合層を除去する
● Generatorでは活性化関数に出力層だけTanhを使うが、それ以外の層では全てReLUを使います。一方、discriminatorの方では全ての層でLeaky ReLUを使います。
(参考)はじめてのGAN
CGAN(Conditionnal GAN)
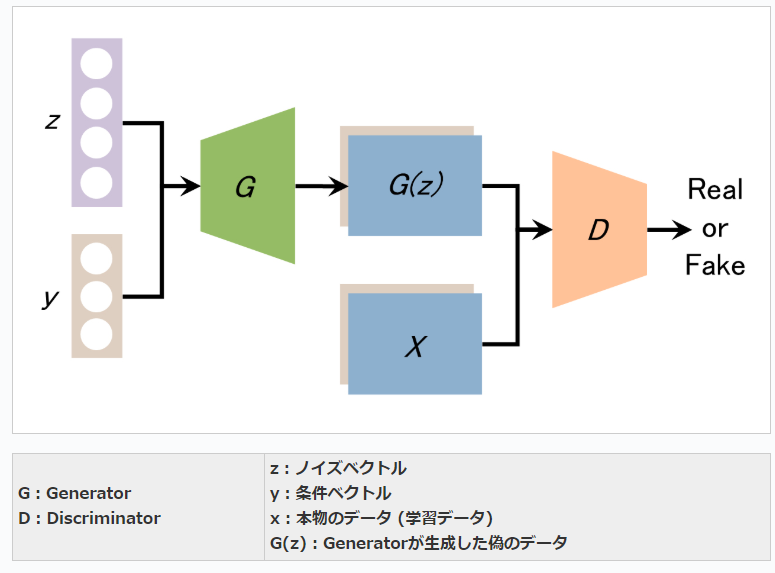
■ CGAN (Conditional GAN)は2014年にarXivで公開された論文 Conditional Generative Adversarial Netsで提案された生成手法。
■ CGANの構造:
● Generatorの入力にノイズベクトルだけでなく、条件ベクトルも与えている点。それに伴い、Discriminatorも条件ベクトルに相当する条件データを入力できるよう改良されている。
(参考)CGAN (Conditional GAN):条件付き敵対的生成ネットワーク
(参考)今さら聞けないGAN(6) Conditional GANの実装