はじめに
「深層生成モデルを巡る旅」シリーズ第3回はみなさんお待ちかねの(?)GANのまとめです.
GANは綺麗な画像を生成することに長けており, その人気はFlowやVAEと比べても圧倒的です. その一方で, 世にはGANの研究があふれていて, 画像生成に限っても把握するのが困難な状態になっています. 本記事では, 元祖から最新の研究に至る歴史の中で重要と思われるものをジャンル別に紹介したいと思います.
今回も画像生成のみを扱います.
GANの基本
GANそのものについての解説は日本語のものに限っても既に多数あるので, ここでは簡単に触れることとし, 後に続く各手法の紹介に集中したいと思います. ご存じの方は飛ばしてください.
全体像
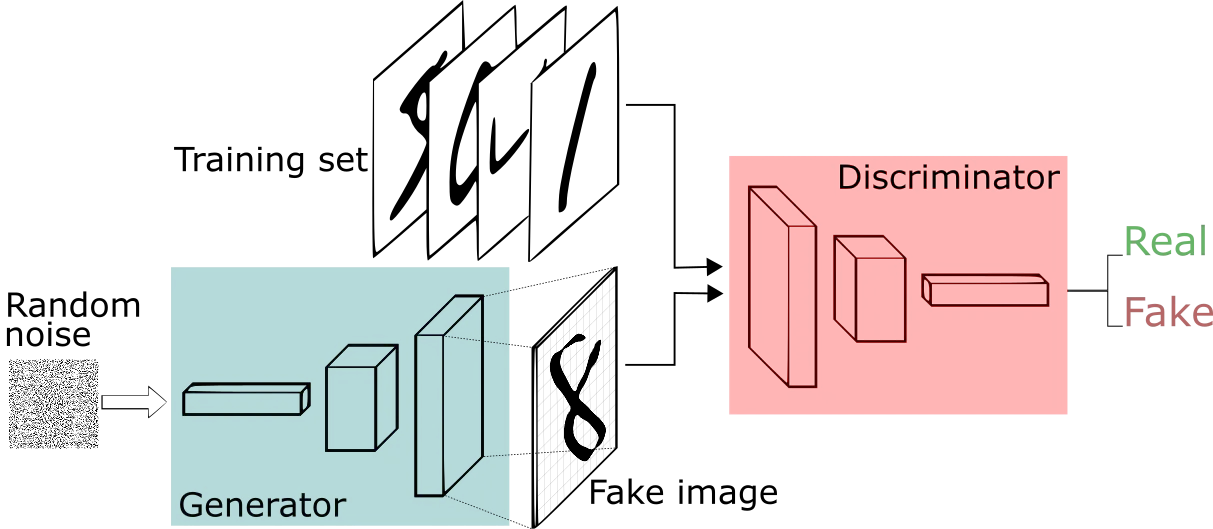
A Beginner's Guide to Generative Adversarial Networks (GANs) | Skymind
GANは生成器$G$(Generator)と識別器$D$(Discriminator)という2つのニューラルネットからなります.
生成器はランダムなノイズ画像から偽物の画像を生成し, 識別器は画像が教師データに含まれる「本物」か否かを判定します.
式で表すなら, 生成器は識別器の正解率を最小化するように, 識別器は正解率を最大化するように学習していきます.
\min_{G}\max_{D} \mathbb{E}[\log{D(x)}] + \mathbb{E}[\log{(1-D(G(z)))}]
ここで, $x$は教師データからサンプルしたデータ, $z$はランダムノイズ, $G(z)$は$z$から生成したデータです. $D(x)$は$x$が本物(教師データからのサンプル)であると判断する確率で, $1-D(G(z))$は$G(z)$が本物でないと判断する確率です.
目的関数を, $D$について最大化, ($D$を固定して)$G$について最小化, と交互に繰り返して両者の性能を高めていきます. 「切磋琢磨」のイメージです.
以上のように, イメージするのはそれほど難しくありませんが, 2つのニューラルネットを交互に訓練して最適解に至るのが難しそうですよね.
実際, 一方のモデルが悪いままもう一方が強化されてうまくいかないというような問題が起きやすいそうです.
VAE・Flowとの比較
ここで, 第1回の図をもう一度見てみましょう.
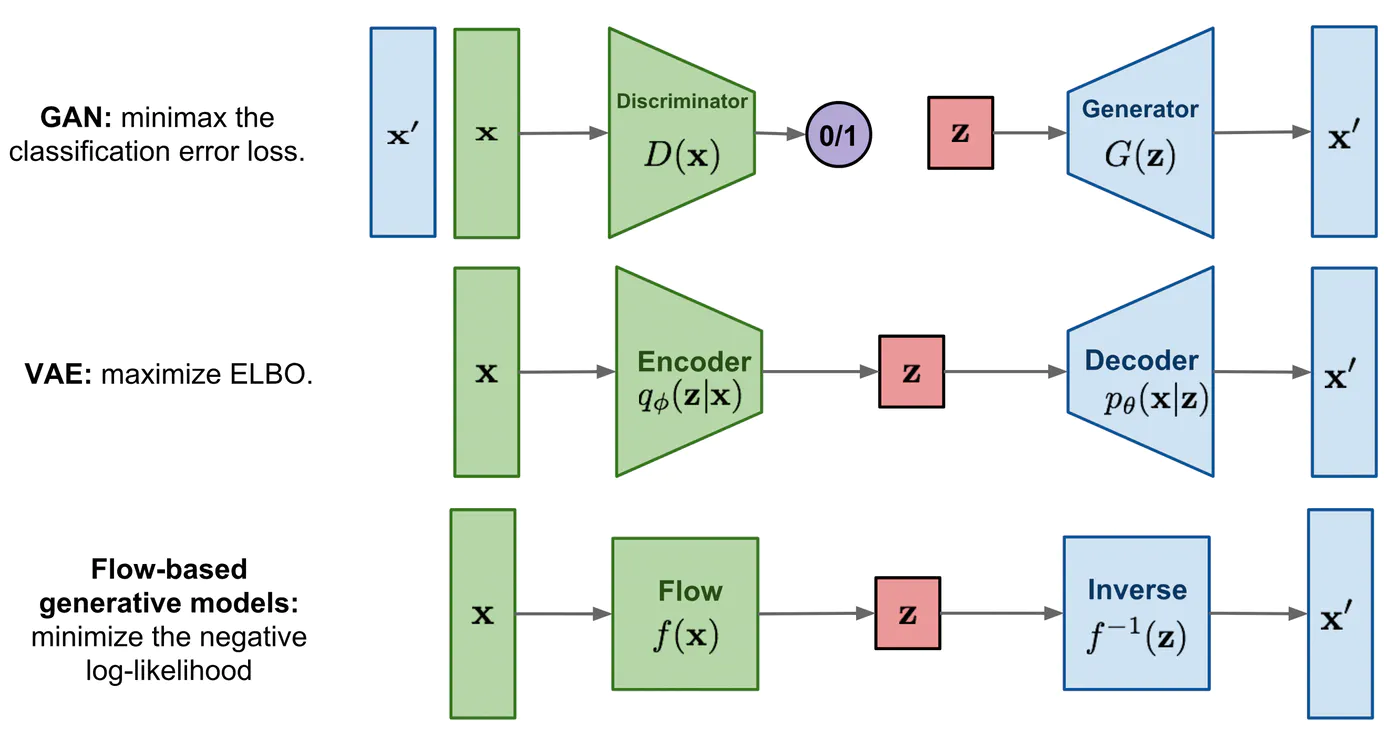
Flow-based Deep Generative Models.
VAEやFlowと比較した時のGANの最大の特徴は, Encoderを持たないことです.
代わりに, 識別器を設けて生成器の教師信号に使っています. Encoder-Decoderによる再構成ではなく, このような形である種の官能評価を実現することで, GANは「実際にありそうな画像」を生成することに非常に長けています.
一方, 密度推定を行わないためデータセットに含まれる一部のモードが無視されてしまうモード崩壊が起きやすいです(極端な例だと, MNISTで特定の数字ばかり生成するなど). また, 識別器が強くなりすぎて生成器が学習できないなど, 学習の安定性にも課題があります.
様々なGAN
20種類の重要なGANたちを, 「画像品質」「学習方法」「生成画像の操作」「画像変換」「その他の応用」という軸で分けてみました(独断と偏見です).
画像品質
最初は, 花型とも言える画像品質を向上させる研究を見ていきましょう.
もう1年前になってしまいますが, GANの父であるGoodfellowがこの節で書きたいことをだいたいまとめてくれています.
4.5 years of GAN progress on face generation. https://t.co/kiQkuYULMC https://t.co/S4aBsU536b https://t.co/8di6K6BxVC https://t.co/UEFhewds2M https://t.co/s6hKQz9gLz pic.twitter.com/F9Dkcfrq8l
— Ian Goodfellow (@goodfellow_ian) January 15, 2019
画像は左から順にGAN, DCGAN, Coupled GAN, PGGAN, StyleGANです.
"Vanilla" GAN [Goodfellow+, 2014]
元祖GANは先に説明した通りなので, 生成結果のみを示します.

それぞれの画像において, 一番右の列は隣の列から最も近い教師画像です.
c), d)はともにCIFAR-10の画像ですが, c)は全結合, d)はCNNのモデルで生成した結果です. CIFA-10になるとなかなか苦しそうですね.
Deep Convolutional GAN [Radford+, 2015]
先ほどのGANをfully-convolutionalにするなどのテクニックを加えてより高品質な画像を生成できるようにしたものがdeep convolutional GAN (DCGAN) です.
生成器は4層の転置畳込み(逆畳み込み)というシンプルな構造になっています.

このシンプルな構造ゆえ, TensorFlow, PyTorch, Chainerなどの主要フレームワークでチュートリアルとして使われています. 小さい画像なら普通のGPU1枚で動くということもあって, 個人レベルでは最も人気のGANという印象があります. いろいろな方がいろいろな画像を生成していておもしろいので, 興味のある方は調べてみてください. 私も過去にChainerのサンプルコードを少しいじって寿司の画像を生成したことがあります(SushiGAN).
こちらはLSUNの寝室の画像で学習したものです. 64x64くらいの画像は結構綺麗に生成できます.

また, DCGANに限られた機能ではありませんが, 潜在空間上でzどうしを足し引きすることで, 画像空間上で意味のある演算をすることも可能です.

Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Self-Attention GAN [Zhang+, 2018]
単純な畳込みは局所的な演算しかできないので, 層をとても深くしないと画像上の離れた点間で一貫性を保つのが難しいのですが, self-attention GAN (SAGAN) は, 特徴マップの変換に自己注意機構 (self-attention mechanism) を加えたことで画像の大域的な情報を表現することに成功しました.

今度はImageNetの128x128の画像を綺麗に生成しています(クラス指定あり).

なお, 自己注意機構の他にも, ヒンジ損失の導入, スペクトル正規化(後述), two-timescale update rule (TTUR; 生成器と識別器で異なる学習率を使うこと)といった工夫があり, これらはすべて後のBigGANに継承されています.
ちなみに, この論文の第二著者にはGoodfellowがいます.
Self-Attention Generative Adversarial Networks
Progressive GAN [Karras+, 2018]
GANの学習を動かしてみた方は実感があると思いますが, 単純に画像の解像度を上げようとすると, 学習が不安定になったり, モード崩壊が起きやすくなったりします. そこで, 学習初期は4x4の低解像度で始めて, 徐々に層を追加しながら1024x1024の高解像度画像を生成できるようにするのがprogressive growing GAN (PGGAN) です.

層を追加するときには下図の(a), (b), (c)の順に, αの値を大きくしながら「ソフトに」追加します.

この他にも, 識別器にミニバッチ内の標準偏差を入れて多様性を向上させるなどの工夫を入れて, 1024x1024の画像を生成した結果がこちらです!

CelebAの顔が芸能人らしくなっているのもわかりますね. なお, この学習に使われているCelebA-HQというデータセットは, この研究のために新たに作られたものです.
Progressive Growing of GANs for Improved Quality, Stability, and Variation
StyleGAN [Karras+, 2019]
StyleGANはPGGANの著者陣による最新作で, 生成器にスタイル変換由来のAdaIN (adaptive instance normalization) というモジュールを採用し, 高画質でリアルな画像を生成することに成功しました.

PGGAN (a)と比べると, StyleGAN (b)は次のような特徴があります.
- マッピングネットワークと合成ネットワークからなる
- マッピングネットワークで正規分布に従う潜在変数$z$を学習可能な分布に従う中間潜在変数$w$に変換する
- 合成ネットワークの最初の入力はすべての要素が1のテンソルで固定する
- 合成ネットワークの途中のAdaIN層で, 中間潜在変数$w$をアフィン変換してからスタイルとして取り込む
- 髪の毛先の動きのような確率的な要素を反映させるため, 合成ネットワークの随所でノイズを足す
AdaIN層では元の特徴マップ$x$の平均と分散をスタイル特徴マップ$y$に合わせるような操作を行います.
$$
\mathrm{AdaIN}(x,y) = \sigma(y)\frac{x-\mu(x)}{\sigma(x)}+\mu(y)
$$
生成結果は驚くべきクオリティです. ぜひ動画でご覧ください.

顔のリアルさもさることながら, 顔を変化させていく過程のどこを切り取っても極めて自然な画像になっているところが, これまでのGANとは一線を画しています.
潜在変数を$z_1, z_2$と2つ用意して, 合成ネットワークのある層で入力を$w_1$から$w_2$に切り替えることで, 顔のスタイルを混ぜることもできます.

また, StyleGANの訓練データとして, CelebA-HQよりも年齢や人種の多様性に富んだFFHQというデータセットを作成しました.
A Style-Based Generator Architecture for Generative Adversarial Networks
BigGAN [Brock+, 2019]
本節の最後に紹介するBigGANは, 基本的にはSAGANをより大きなスケールでやってみたというものです.
まず, ImageNetの512x512の画像でSAGANのベースラインに対してバッチサイズを8倍, チャンネル数を1.5倍にしたところ, これだけでFrechet Inception Distance(低いほうが良い)とInception Score(高いほうが良い)が大幅に改善しました.
さらに, クラス変数に対する埋め込み共有, 重みの直交性による正則化, 潜在変数の分割などのテクニックを加えて性能を改善しています.

生成結果はこちらです.

Large Scale GAN Training for High Fidelity Natural Image Synthesis
学習方法
ここまで, GANによる美しい生成結果を載せてきましたが, 実際は鴨の水掻きよろしく丹念なチューニングが必要です. 次は, 学習の安定化やモード崩壊の防止に向けた, 学習方法に注目した研究を紹介していきます.
ここからは短めに書きます. 詳細は元論文をご参照ください.
Unrolled GAN [Metz+, 2017]
Unrolled GANは先に識別器のパラメータ更新を$K$回行い, その損失で生成器のパラーメータ更新をしてから, 識別器のパラメータを1回更新時に戻す(unroll)というものです. これは賢い識別器で生成器を導くイメージで, モード崩壊を起きにくくする効果があるそうです.
次の図で, 上段がUnrolled GAN, 下段が通常のGANです. Unrolled GANではターゲットのすべてのモード(クラスタ)を再現できています.

Unrolled Generative Adversarial Networks
Wasserstein GAN [Arjovsky+, 2017]
通常のGANの目的関数は, 最適な識別器の下ではJensen-Shannonダイバージェンスと捉えることができます. しかし, JSダイバージェンスは2つの分布(訓練画像と生成画像)が重ならない部分では発散してしまい, 勾配消失が起きやすくなります. そこで, 分布に重なりがないところでも滑らかな(Lipschitz連続な)Wasserstein距離を目的関数に使ったのがWasserstein GAN (WGAN) です. WGANの訓練では, 識別器はW距離を推定し, 生成器が推定されたW距離を最小化します. また, W距離で要請されるLipschitz制約を満たすため, 識別器の重みをクリッピングします. 詳しくは論文のほか, [10-12]も参考になるかもしれません.
通常のGANとWGANの学習曲線を比較してみます. このように, JSダイバージェンスは途中でスパイクが入って不安定ですが,

W距離は学習初期からずっと滑らかになっています.

識別器の損失に勾配に関する正則化(gradient penalty)を入れたWGAN-GPという改良版もあります.
Spectrally Normalized GAN [Miyato+, 2018]
GANの登場以来進められてきた学習の安定性のための研究(WGANなど)の中で, 識別器のLipschitz連続性が重要であるということが指摘されていました. そこで, 識別器の各層のスペクトルノルムを正規化してLipschitz連続性を保証したのがSpectrally Normalized GAN (SNGAN) です.
具体的には, 重み行列$W$を最大特異値$\rho(W)$で割るという操作をしています.
\tilde{W} = \frac{W}{\rho(W)}
これで各層がLipschitz連続になり, 全体としてもLipschitz連続性が保たれます.
実験では, バッチ正規化やWGAN-GPなど他の正規化・正則化手法と比較しても高性能でハイパーパラメータに頑健であることが示されました.

また, 調節すべきパラメータもスケーリングファクターのみと使いやすいところも特徴です. 執筆時点で被引用数690で, BigGANにも採用されるなど, かなり人気で効果の実証された手法です.
Spectral Normalization for Generative Adversarial Networks
HoloGAN [Nguyen-Phuoc+, 2019]
HoloGANは, StyleGANの生成器を元に, 3次元構造を考慮した画像生成を可能にしました. HoloGANの合成ネットワークは図のように, 3次元畳込み, 3次元の回転, 3次元畳込み, 2次元への写像, 通常の2次元畳込み, という構造になっています.

画像生成の背後に3D表現を陽に設けることで, 潜在変数で角度を調節できるようになります. ただし, 識別器に与えるのは2次元画像なので, 訓練データに3Dモデルは必要ありません.
このようにCelebAの顔画像を並べて回転させることができます.

車の360度回転もこの通りです.

HoloGAN: Unsupervised learning of 3D representations from natural images
Prescribed GAN [Dieng+, 2019]
Prescribed GAN (PresGAN) は, 事前分布だけでなく尤度もモデル化するという, GANとVAEのいいとこ取りとも言えるアプローチでモード崩壊を防ぎました.
p_\theta(\boldsymbol{x}|\boldsymbol{z})=\mathcal{N}(\boldsymbol{x}|\mu_\theta(\boldsymbol{z}),\Sigma_\theta(\boldsymbol{z}))

モード崩壊の対策はシンプルで, 損失関数にエントロピー正則化の項を入れるだけです. $\lambda$は正則化の度合いを決めるハイパーパラメータです.
\mathcal{L}_\text{PresGAN}=\mathcal{L}_\text{GAN}-\lambda \mathbb{E}_{p_\theta(\boldsymbol{x})}[\log p_\theta(\boldsymbol{x})]
画像を$p_\theta(\boldsymbol{x}|\boldsymbol{z})$をサンプリングするところでは, 前回登場したreprametrization trickを使います.
FFHQでの生成結果によると, StyleGANのような質を維持したまま多様性を増すことができたそうです(左: StyleGAN, 右: PresGAN). 論文には量的評価もあります.

Prescribed Generative Adversarial Networks
生成画像の操作
次は生成画像を操作する方法, あるいはdisentanglementについてこれまで紹介していなかったものを見ていきます. SAGANやBigGANはクラス指定をしていますし, StyleGANやHoloGANはdisentanglementを含んでいるので, 既に登場しているアプローチではあります.
Conditional GAN [Mirza+, 2014]
Conditional GAN (CGAN) は, 生成器と識別器をクラス変数$y$で条件付けたモデルとして設計します. Conditional VAEのアナロジーで考えて問題ないと思います.

Conditional Generative Adversarial Nets
Information Maximizing GAN [Chen+, 2016]
CGANのように, 属性を指定する変数$c$を使って特徴のdisentanglementを行ったのがInformation Maximizing GAN (InfoGAN) です.
MNISTの例で例えると, InfoGANでは, $c$は数字の種類や線の太さなどの属性を表現し, $z$はノイズ(画像の確率的な要素)とします. CGANとは異なり, 識別器に$c$を入力することはしません. その代わり, $c$と画像$x$の相互情報量が高くなるように目的関数を設計します. 相互情報量を直接計算するのは難しいので, VAEでやったように近似事後分布$Q(c|x)$を導入して変分下限$\mathcal{L}_I(G,Q)$を使います.
\mathcal{L}_\text{InfoGAN}=\mathcal{L}_\text{GAN}-\lambda \mathcal{L}_I(G,Q)
このような目的関数で学習をさせると, 図のように$c$に意味のある情報を持たせることができます.
 [InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets](https://arxiv.org/abs/1606.03657)
[InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets](https://arxiv.org/abs/1606.03657)
画像変換
続いて紹介するのは, 画像変換のためのGANです. これらのGANは, ラフな線画を写真のように変換するなど, 楽しい応用をいろいろと考えることができます.
pix2pix [Isola+, 2017]
pix2pixは, 「線画と写真」, 「航空写真と地図」のような画像ペアに対して, 片方をCGANの条件として入力し, もう片方を生成するという枠組みで画像変換を行うGANです. 生成器は入力を画像とするためU-Netで実装されます.

損失関数には, 生成画像と実画像のL1損失も加えます.
\mathcal{L}_\text{pix2pix}(G,D)=\mathcal{L}_\text{CGAN}(G,D)+\lambda \mathcal{L}_{L1}(G)
また, pix2pixなどの画像変換系のモデルには, 識別器側にPatchGANと呼ばれる画像の局所領域を切り出して識別する手法が使われています. 詳しくは[14]などをご参照ください.
変換の結果がこちらです.
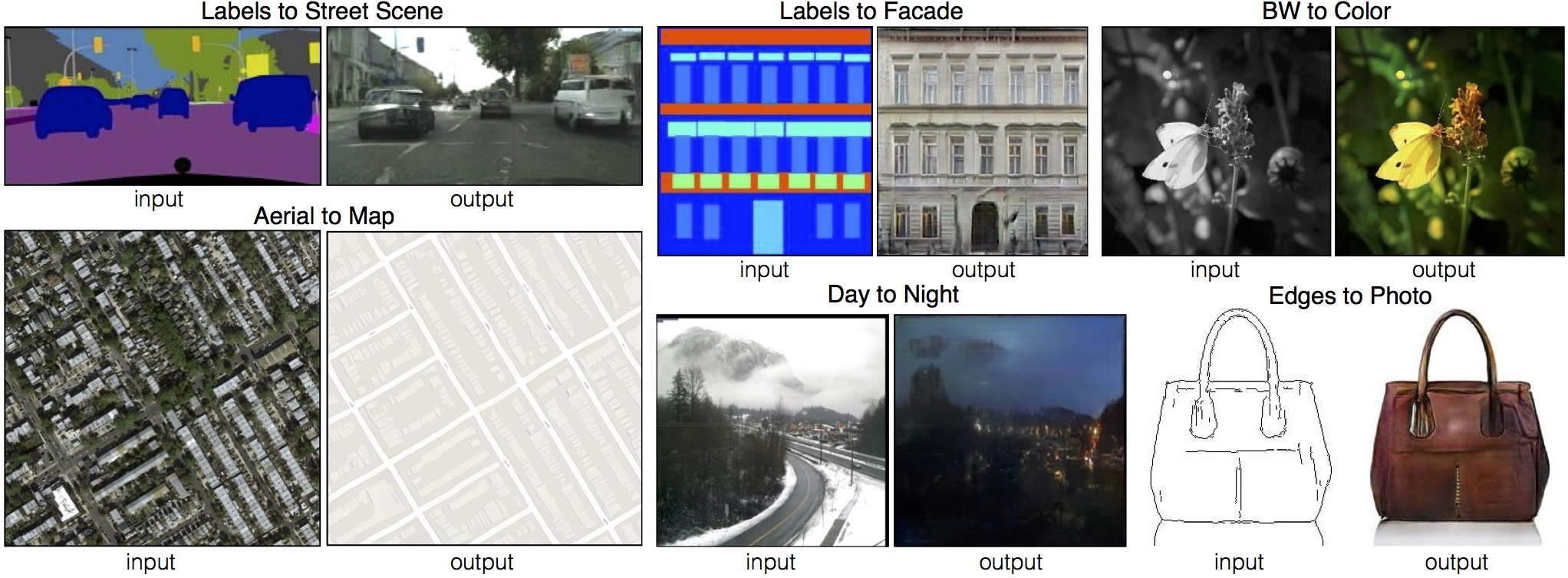
この結果は非常にセンセーショナルで, 後にアーティストを含む多くの人がpix2pixを使ったプロジェクトを公開しました. その一部は更新版の論文にも掲載されています.

興味のある方は公式サイトなどで調べてみてください. また, 最近はvid2vidのように動画への適用も進んでいます.
Image-to-Image Translation with Conditional Adversarial Networks
CycleGAN [Zhu+, 2017]
pix2pixでは「航空写真と地図」のようにペアの画像が必要ですが, 実際には画像がペアになっているケースは多くありません. そこで, ペア画像がなくても変換できるように改良を加えたのがCycleGANです. ちなみに, この論文はpix2pixと同じチームによってpix2pixの4ヶ月後に書かれたものです. この分野の発展は本当に速いですね.
さて, CycleGANでは, 画像のドメイン$X$と$Y$(例えばシマウマとウマ)を考え, 生成器$G:X\rightarrow Y, F:Y\rightarrow X$とそれぞれのドメインに属するかを判定する識別器$D_X, D_Y$を用意します.
すると, 後はpix2pixと同じように考えて, $G$と$D_Y$, $F$と$D_X$をセットにして学習させます. また, 「$F(G(x))$は$D_Y$によって$Y$と判定されるべき」というようなcycle consistency loss も損失関数に加えます.

このような工夫により, 「モネの絵と写真」や「シマウマとウマ」のようなペア画像が手に入らない変換も可能になりました.

CycleGANも多くの方が応用を試しており, その一部が公式サイトで紹介されています.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
SPADE [Park+, 2019]
SPADE (spatially-adaptive (de)normalization) は, セグメンテーションからの画像生成に特化したモデルで, これまでにない写実的な画像を生成するとともに, スタイル転写を可能にしました.
根幹となるSPADE層では, バッチ正規化のスケールγとバイアスβを, セグメンテーションを畳み込んで得られる(空間適応的な)テンソルに置き換えています. これにより, 同じラベルの領域でも繊細な違いを生み出しリアリティの向上に貢献しています.

また, 入力するノイズ$z$として, スタイル画像をエンコードしたものを与えることで, 下図のようなスタイル転写が可能になりました.

Semantic Image Synthesis with Spatially-Adaptive Normalization
その他の応用
最後は, 分類できなかった応用例を簡単に見ていきます. 「GANでこんなこともできるのか!」という気持ちで読んでいただければ幸いです.
StackGAN [Zhang+, 2017]
画像→画像の変換ができるなら文章→画像の変換もできます. StackGANは, LSTMで入力文をエンコードし, そのベクトルから文の意味に合った画像を生成することができます. このような「文章からの画像生成」に興味を持った方は, [16,17]が参考になるかもしれません.

StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Super Resolution GAN [Lediig+, 2017]
Super Resolution GAN (SRGAN) は名前の通り超解像のためのGANです. 図のように, 生成器はskip connection付きの残差ブロックを何段も重ねた構造になっています.

ご覧の通り, エッジの鮮明な超解像画像が得られます.

Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Conditional Analogy GAN [Jetchev+, 2017]
Conditional Analogy GAN (CAGAN) はデータの入れ方を工夫して, 服の仮想試着 (virtual try-on) を可能にしました. 生成器は着用画像$x_i$, 商品画像$y_i$, 試着したい商品画像$y_j$の3つ組を入力とし, 試着画像$x_j$を出力します. 識別器は$x$が実画像で$(x,y)$の組が正しい組み合わせになっているかを判定します.

こちらが生成結果です(右から2列目).

最新の研究では動画への適用も進んでいます(FW-GAN).
The Conditional Analogy GAN: Swapping Fashion Articles on People Images
SinGAN [Shaham+, 2019]
SinGANは1枚の画像で学習し, そこから同じような要素を持つ任意のサイズ・アスペクト比の画像を生成するという少し変わったGANです.
モデルは図のような階層型のネットワークになっており, 畳込みのみで実装されているため, アップサンプルのスケール$r$を変えることで任意のサイズの画像を生成できます.

$z$の入れ方を工夫することでpaint to image, 画像編集, harmonization, 超解像, 動画化など幅広い応用ができるというところが強みです. 実用上役に立つ場面がたくさんありそうですね.
 [SinGAN: Learning a Generative Model from a Single Natural Image](https://arxiv.org/abs/1905.01164)
[SinGAN: Learning a Generative Model from a Single Natural Image](https://arxiv.org/abs/1905.01164)
おわりに
最後までお読みいただきありがとうございました!
本記事では, 20種類のGANを「画像品質」「学習方法」「生成画像の操作」「画像変換」「その他の応用」という軸で分けて紹介しました.
GANの発展は凄まじく, ときどき整理しないと全体像を把握するのが難しいので, 記事を執筆していく中で大いに自分の勉強になりました. 読んでくださった方のためにもなれば幸いです.
気が向いたら続編を書くかもしれません.
参考文献
[1] Shion Honda. "画像認識 第9章 さらなる話題." 2019.
xpaperchallengeの勉強会で発表したときの資料です.
[2] Zhaoqing Pan et al. "Recent Progress on Generative Adversarial Networks (GANs): A Survey." IEEE Access. 2019.
私の知る限り最新のGANサーベイ論文なのですが, PGGANなどNVIDIAの研究に触れられていないのが気になります.
[3] 高橋智洋. "SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~." 2019.
[4] ⽚岡裕雄. "敵対的生成ネットワーク(GAN)." 2019.
[5] Masahiro Suzuki. "GAN(と強化学習との関係)." 2017.
[6] Mario Lucic et al. "Are GANs Created Equal? A Large-Scale Study." NIPS. 2018.
Google BrainによるGANのメタ分析. 各手法を公平な条件で比較し直しました. 論文で報告される値は選択バイアスなどがかかっていることが多いので, Googleの計算資源でこのようなメタ分析をするのは分野の発展に重要ですね.
[7] Karol Kurach et al. "A Large-Scale Study on Regularization and Normalization in GANs." ICML. 2019.
同じく, Google BrainによるGANのメタ分析. こちらは正則化・正規化手法に注目しています.
[8] Kento Doi. "StyleGAN解説 CVPR2019読み会@DeNA." 2019.
[9] Jason Brownlee. "A Gentle Introduction to BigGAN the Big Generative Adversarial Network." 2019.
[10] Lilian Weng. "From GAN to WGAN." 2017.
[11] Wasserstein GAN [arXiv:1701.07875] – ご注文は機械学習ですか?
[12] 織姫と彦星の遠距離恋愛で学ぶいろいろな距離 - Qiita
[13] Kento Doi. "[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images." 2019.
[14] 【DeepLearning】Patch GANのPatchとは? - 0.5から始める機械学習
[15] Shion Honda. "思い描いた画像を簡単に生成!セグメンテーションを写実的な画像に変換するGauGANとは | AI-SCHOLAR.", 2019.
[16] Shion Honda, Seitaro Shinagawa, Keito Ishihara, and Hiroyuki Osone. "Bridging between Vision and Language." 2019.