はじめに
SUSHI食べたい!ということで,DCGANで寿司の画像を生成してみました.
やったことは,Chainerのサンプルコードを少し変えて実行しただけです.予めご了承ください.
原理の紹介
今回使用したGANについて, 簡単に原理を解説します.
GAN
**敵対的生成ネットワーク(generative adversarial networks; GAN)**は, 2014年にMontreal大学(当時)のIan Goodfellowが考案したネットワークで, ノイズからこのような「本物らしい」画像を生成することができます.

それぞれの画像において, 一番右の列は隣の列から最も近い教師画像です.
すなわち, 左5列の画像は教師データとは異なり, かつ本物らしい画像ということになります.
では, どのようにして画像を生成するのでしょうか?
GANはこのような構成になっています.
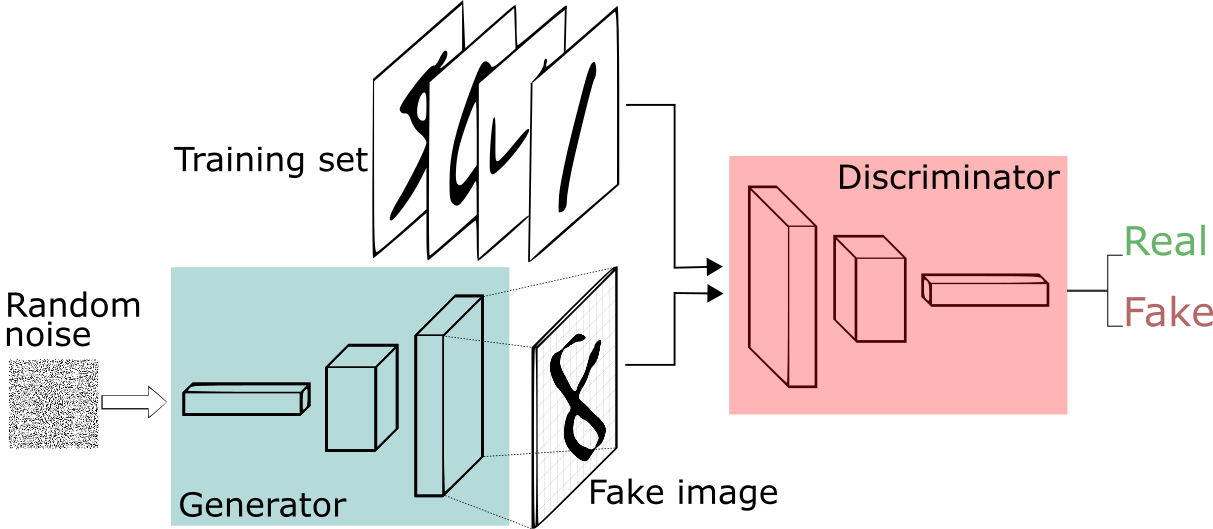
A Beginner's Guide to Generative Adversarial Networks (GANs) | Skymind より引用
GANは生成器$G$(Generator)と識別器$D$(Discriminator)という2つのニューラルネットからなります.
生成器はランダムなノイズ画像から偽物の画像を生成し, 識別器は画像が教師データに含まれる「本物」か偽物かを判定します.
次の式のように, 生成器は識別器の正解率を下げるように, 識別器は正解率を上げるようにパラメータを最適化していきます.
\min_{G}\max_{D} V(D,G) = \textrm{E}[\log{D(x)}] + \textrm{E}[\log{(1-D(G(z)))}]
ここで, $x$は教師データからサンプルしたデータ, $z$はランダムノイズ, $G(z)$は$z$から生成したデータです.
$D(x)$は$x$が本物(教師データからのサンプル)であると判断する確率で, $1-D(G(z))$は$G(z)$が本物でないと判断する確率です.
この$V(G,D)$を目的関数(通常のディープラーニングでいう損失関数)を, $D$について最大化, ($D$を固定して)$G$について最小化, と交互に繰り返していきます.
なお, VAEのような誤差最小化だと, 出力が複数の画像を平均したようなぼやけた画像になる傾向がありますが, GANは識別器を騙すように学習しているのでエッジが綺麗な「本物らしい」画像になるそうです.
以上のように, イメージするのはそれほど難しくありませんが, 2つのニューラルネットを交互に訓練して最適解に至るのが難しそうですよね.
実際, 一方のモデルが悪いままもう一方が強化されてうまくいかないというような問題が起きやすいそうです.
DCGAN
このGANに, プーリングをストライドに変える, 全結合層をなくす, 活性化関数としてLeakyReLUを用いる, といった改良を加えたものが**deep convolutional GAN (DCGAN)**です.
DCGANの生成器では, 潜在変数(本記事では10次元)から逆畳込みを繰り返して画像を生成します.
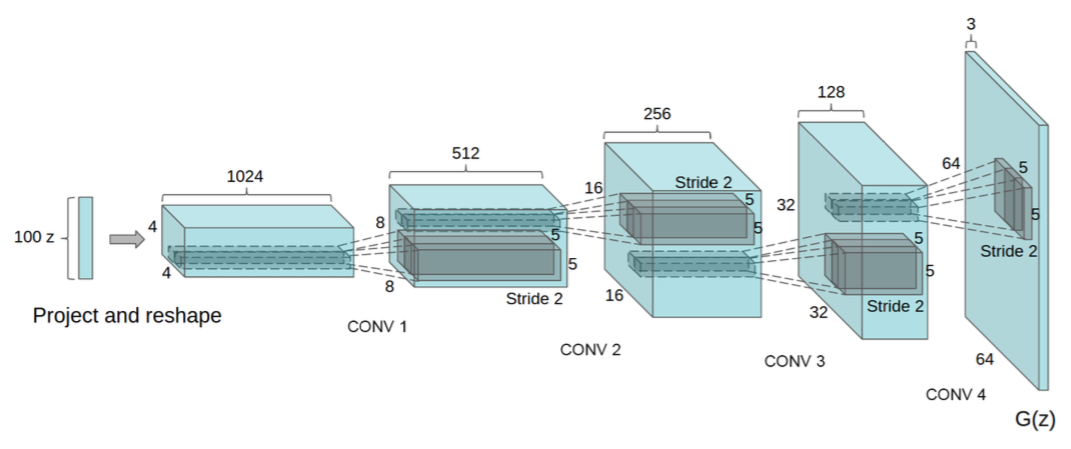
DCGANはGANに比べて高解像度の画像を生成できます.
すべて生成されたベッドルームの画像です. 本物と見分けがつきません.

また, 教師データにラベルが付いていると, Word2Vecの要領で元となる潜在変数とラベルを対応させることで, このような画像を得ることができます.

データセット
データ取得
本記事の本当の動機は,「DCGANを試してみたいけど,MNISTやCIFAR10でサンプルコードを実行するだけではつまらない!どうせなら他に誰も試していないデータでやりたい!」と思ったことでした.
そのため,寿司の画像を以下のサイトからお借りしました.
選定基準は,サイズ200x200程度の大きさで,2個セットかつ皿が写っていないことです.「握りのほかに寿司なし」ということで軍艦などは含めませんでした.
・はま寿司

・回転すし北海道

・かっぱ寿司

・くら寿司

・スシロー

5つのチェーンの力を借りて,253枚のデータを集めることができました.
本当は1万枚くらい欲しいのですが,データが比較的似通っているので大丈夫な気がします.
データにラベルがついていると学習後にいろいろ遊べるのですが,これを自分でやる気力はありませんでした…
さて,これらはサイズや背景色がバラバラなので,前処理をしないと使えません.
前処理
画像を黒背景でサイズが96x96x3のPNGファイルに直します.
リサイズは簡単にできるとして,くら寿司以外の画像の背景を黒くするのにはこのコードを使いました.
import numpy as np
import glob
from PIL import Image
files = glob.glob('./sushiro_resize/*.png')
cnt = 0
for f in files:
with Image.open(f) as img:
rgba_img = np.asarray(img.convert('RGBA'))
mask = rgba_img[:,:,3]>0 # 透明度が0より大きい部分が0,それ以外が1の行列
rgb_img = rgba_img[:,:,:3]*np.stack([mask,mask,mask], axis=2)
img = Image.fromarray(np.uint8(rgb_img))
img.save('./sushiro_resize/' + str(cnt) + '.png' )
cnt += 1
処理後の画像はこのようになります.

学習
Chainerのサンプルコードを動かします.
chainer/examples/dcgan at master · chainer/chainerから,net.py, train_dcgan.py, updater.py, visualize.pyをダウンロードしてきてください.
net.pyはサイズ32x32の画像を想定しているので,96x96の場合は少しだけパラメータを変える必要があります.
結論を先に言うと,GeneratorとDiscriminatorを定義するところでbottom_width=12とすればコードが動きます.
この12がどこから来るのか,少しコードを観察してみましょう.
class Discriminator(chainer.Chain):
def __init__(self, bottom_width=4, ch=512, wscale=0.02):
w = chainer.initializers.Normal(wscale)
super(Discriminator, self).__init__()
with self.init_scope():
self.c0_0 = L.Convolution2D(3, ch // 8, 3, 1, 1, initialW=w)
self.c0_1 = L.Convolution2D(ch // 8, ch // 4, 4, 2, 1, initialW=w)
self.c1_0 = L.Convolution2D(ch // 4, ch // 4, 3, 1, 1, initialW=w)
self.c1_1 = L.Convolution2D(ch // 4, ch // 2, 4, 2, 1, initialW=w)
self.c2_0 = L.Convolution2D(ch // 2, ch // 2, 3, 1, 1, initialW=w)
self.c2_1 = L.Convolution2D(ch // 2, ch // 1, 4, 2, 1, initialW=w)
self.c3_0 = L.Convolution2D(ch // 1, ch // 1, 3, 1, 1, initialW=w)
self.l4 = L.Linear(bottom_width * bottom_width * ch, 1, initialW=w)
self.bn0_1 = L.BatchNormalization(ch // 4, use_gamma=False)
self.bn1_0 = L.BatchNormalization(ch // 4, use_gamma=False)
self.bn1_1 = L.BatchNormalization(ch // 2, use_gamma=False)
self.bn2_0 = L.BatchNormalization(ch // 2, use_gamma=False)
self.bn2_1 = L.BatchNormalization(ch // 1, use_gamma=False)
self.bn3_0 = L.BatchNormalization(ch // 1, use_gamma=False)
bottom_widthというのは,畳込み層c3_0を通過した後の特徴マップのサイズだということがわかります.
サイズ$(In,In)$の画像にカーネルサイズ$k$, ストライド$s$, パディング$p$で畳込みをした後の特徴マップのサイズ$(Out,Out)$は次の式で表されます.
Out = \frac{In+2p-k}{s}+1
この式に従って繰り返し計算をすると,サイズ32x32の画像ではbottom_width=4, 96x96の画像ではbottom_width=12であることがわかりますね.
バッチサイズは10にして実行しました.
$ python train_dcgan.py --gpu=0 --dataset=./data --batchsize=10
結果
100組のランダムノイズ(値が[-1,1]に収まる100次元のベクトル)から生成した画像を並べてみました.
・1000イテレーション後
形は寿司っぽいですね.

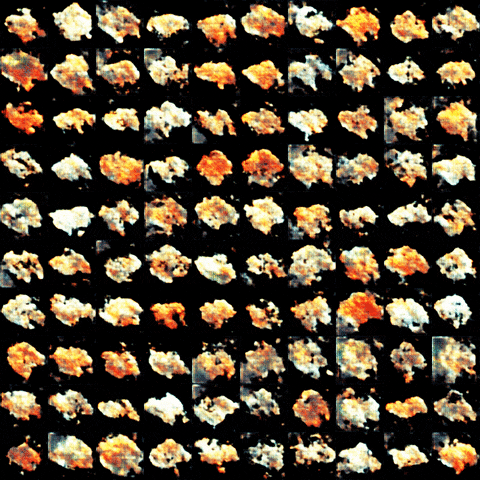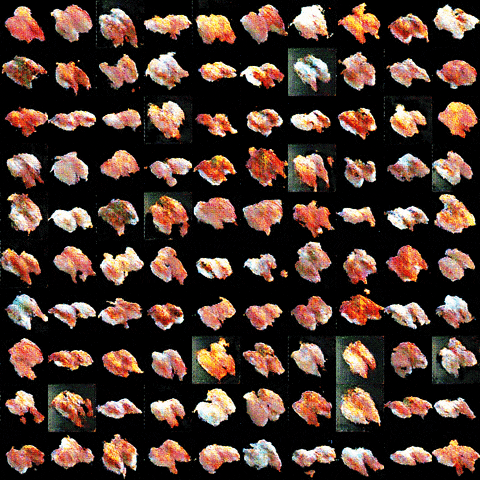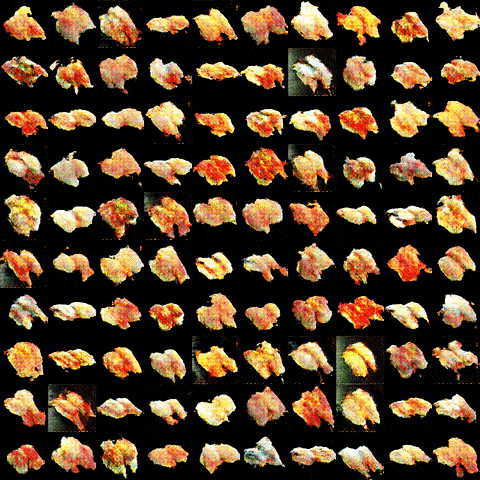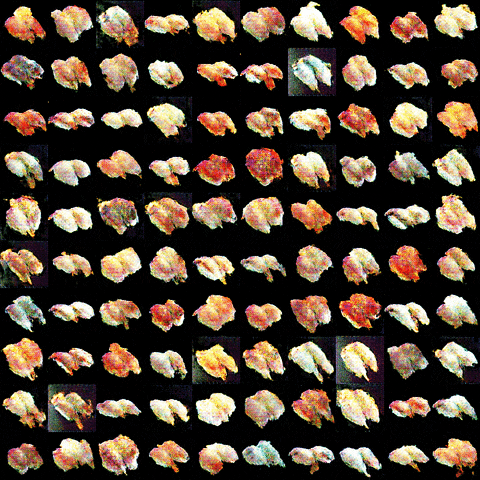
・25000イテレーション後
![]()
![]()
![]() !!!寿司!!!
!!!寿司!!!![]()
![]()
![]()

・学習経過のgif動画
次に,潜在空間上の2点とその間にある内分点を入力にして,連続的に変化するアニメーションを作ってみます.
このようなコードでpng画像を50枚生成し,Free Online Animated GIF Maker - Make GIF Images Easilyでgif動画に変換しました.
gen = Generator(n_hidden=100)
chainer.backends.cuda.get_device_from_id(0).use()
serializers.load_npz("./result/gen_iter_25000.npz", gen)
gen.to_gpu() # Copy the model to the GPU
start = np.random.uniform(-1, 1, (100, 1, 1)).astype(np.float32)
end = np.random.uniform(-1, 1, (100, 1, 1)).astype(np.float32)
diff = end - start
for i in range(50):
arr = start + i*diff/50
z = Variable(chainer.backends.cuda.to_gpu(arr.reshape(1,100,1,1)))
with chainer.using_config('train', False):
x = gen(z)
x = chainer.backends.cuda.to_cpu(x.data)
x = np.asarray(np.clip(x * 255, 0.0, 255.0), dtype=np.uint8)
x = x.reshape(3,96,96).transpose(1,2,0)
Image.fromarray(x).save("./continuous/" + str(i) + ".png")
連続的に変化する寿司です.最高ですね.
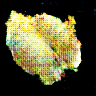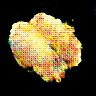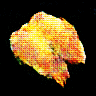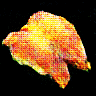
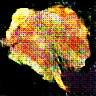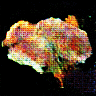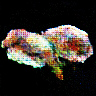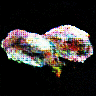
画像にラベルがあれば,潜在空間上でベクトル値を調節することで「マグロっぽくする」「玉子っぽくする」という操作ができたのですが,面倒なので今回は見送りました.
次回はもっと鮮明な画像を作りたいので,どなたか寿司データセットを公開してください…!
参考文献
[1] Goodfellow et al., Generative Adversarial Nets, arXiv, 2014.
GANの元祖.
[2] Radford et al.,Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, arXiv, 2016.
DCGANの元祖.
[3] はじめてのGAN
GANの様々なバリエーションについて外観できる素晴らしいまとめです.