はじめに
GANの基本を理解して、自分の思うような動作をさせたいために改良をしてきました。これまでの経緯はこちら
-
GANの基本構造
今さら聞けないGAN(1) 基本構造の理解 -
CNNを用いて生成画像の表現力を上げたい
今さら聞けないGAN (2) DCGANによる画像生成 -
学習を安定化し、モード崩壊を避けたい
[今さら聞けないGAN(4) WGAN] (https://qiita.com/triwave33/items/5c95db572b0e4d0df4f0)
潜在変数空間上のカテゴリの分布
GANの生成画像を見たときに思ったことは、「いろいろな数字(画像)が生成されるけど、どうやって書き分けるの?」でした。
(通常の)GANは教師あり学習に分類されると思いますが、これはあくまで画像が本物か偽物かに対する教師あり学習で、例えばmnistでは、画像がどの数字に対応するかの教師あり学習は行なっていません。
そのため、生成器(generator)が明示的に数字を書き分けることはできません。訓練画像のラベルを知らされていないので当然です。generatorにとっては1も4も6も(知ら)なく、ただひたすら訓練データの分布に近づけるように学習を繰り返します。
結果として、generator自体にはわからないけれども「何か1らしいもの」、つまり「1を1たらしめている特徴」はgeneratorの潜在変数に取り込まれます。

generatorの潜在変数空間zから画像を生成した場合のイメージが上図です。潜在変数zがとる空間の分布に対して異なる数字が生成されます。
しかし、例えば数字の1を1たらしめる特徴が空間zのある特定の領域に集まっている保証はありません。
1を書くにもいろいろな流儀がありますよね。縦線一本引く人とか、上側を折り返す人とか、下に線を引く人とか。そのため、z空間を指定して文字を書き分けることは現実的ではありません。
というよりも、(少なくとも私が)潜在空間zにもとめる性能は数字を書き分けることではないと思っています。
どの数字を書くかに関係なく様々な字体の訓練データを学習して、その背後にある字の特徴を潜在空間にマッピングしてほしいわけです。そうすることで、丸文字や草書体をかき分けたり、ある人の字体を真似たり、筆圧を変えたり、とかを実現したいわけです。
そのためには、generatorの潜在変数とカテゴリ情報を切り離して考え、代わりにカテゴリ情報の条件化での生成モデル、識別モデルを生成する必要があります。
それがConditional(条件付き)GANになります。
Conditional GAN
生成する画像を明示的に書き分けるために、訓練時に教師データのカテゴリ(ラベル)情報を用いてやろう、というのがconditional GANです。
要は
discriminatorに「今は、6について本物か偽物かを判定してるんですよー」とか
generatorに「今は、3を書くという条件のもとに画像を生成してるんですよー」ということを
教えてやるわけです。
論文は以下
Conditional Generative Adversarial Nets
アイデアは非常に簡単で、generatorとdiscriminatorの各入力にラベル情報を混ぜてあげるだけです。他は一緒。ここが大事なところで、カテゴリ情報を用いるからといって、数値自体の識別モデルを作るわけではなく、あくまで本物か偽物かの識別をするだけです。シリーズを通して言ってきていますが、各GANの派生系において基本構造は変わりません。
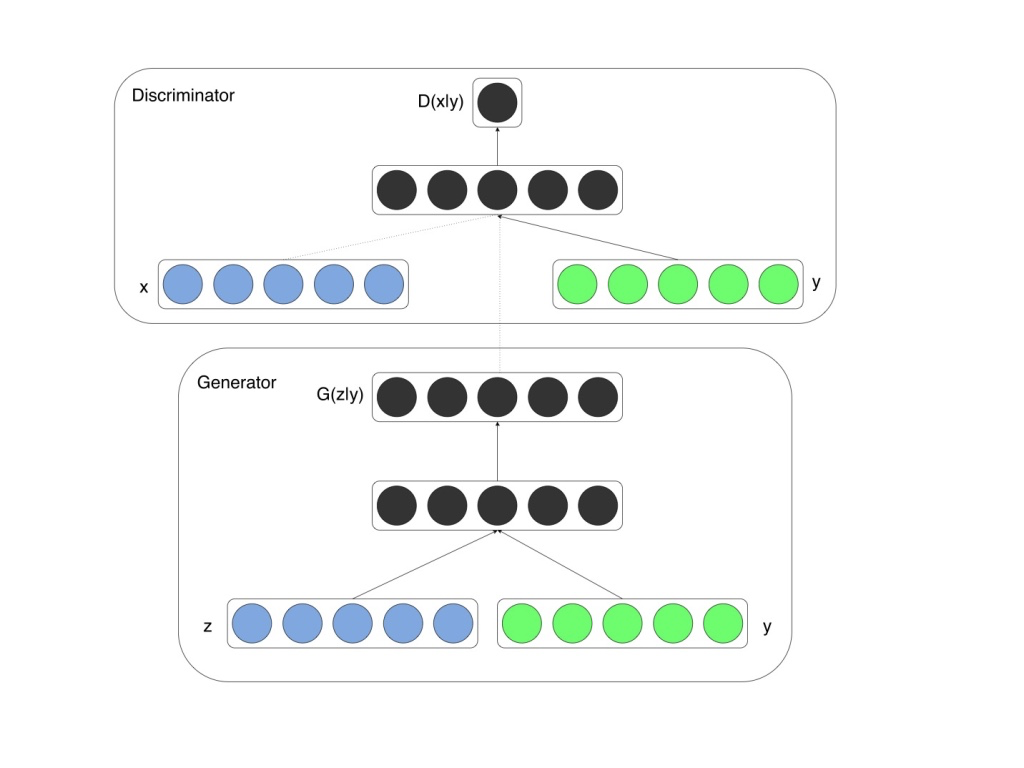
上記論文より引用
Conditional GANの構造
Generatorの学習時
generatorの学習時に用いる構造を以下に示します。generator単体では学習できないので、generatorとdiscriminatorを繋げたcombinedモデルを用います。
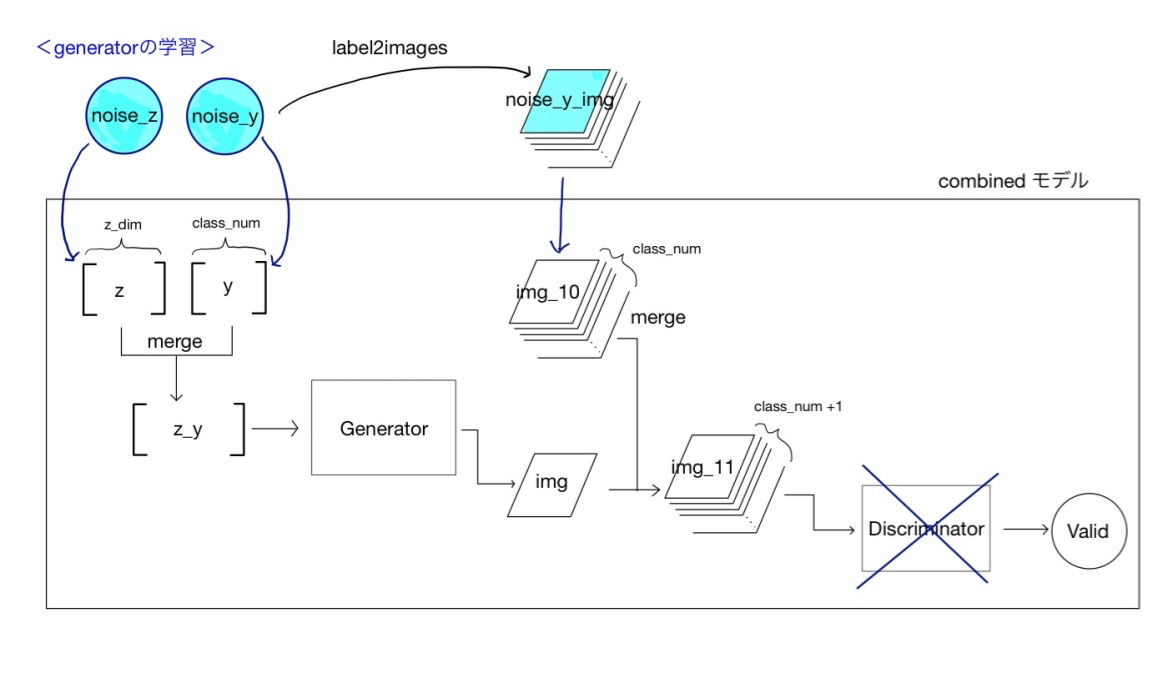
generatorへの数値ラベルの入力
generatorへの入力は次元数z_dimの潜在変数zですが、それにラベル情報を結合させます。mnistの場合はラベル情報は手書き文字の数値を示す0から9までの数値です。これをzに結合させます。実際にはラベルyは0-9のスカラー値ではなく、class_num=10の次元を持つ(俗にいうone-hot)ベクトルです。これを潜在変数と結合します。
zとyの結合の仕方としては、
- 入力データはバラバラに流し込んで、generatorモデル内で結合する
- generatorモデル内の入力変数は結合したサイズにして、あらかじめ結合した(1つの)入力データを流し込む
の2通りが考えられます。今回の実装では、2つが混在しているので注意してください。
モデルの最小単位であるgeneratorとdiscriminatorに関しては結合した1つのデータが流し込まれる構造としています。
なぜなら、構造設計の基本思想として、データフォーマットを基本構造から変えたくないからです。
しかし、結合した入力データを作ってばかりいると変数の数が増えますので、generatorの学習時に使うcombinedモデルでは、入力データはばらばらにいれ(上記の1)、combined_model内でマージしてから、内部のgeneraorモデルには一つの入力データとして引き継ぐ、という形をとっています。combinedモデルがデータフォーマットのバッファとしての役割を担っているわけですね。
この方法でしかできないというわけではないので、自分の好みで何を優先させたいかで決めれば良いと思います。
generatorのコードは以下
def build_generator(self):
model = Sequential()
model.add(Dense(input_dim=(self.z_dim + CLASS_NUM), output_dim=1024)) # z=100, y=10
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((7,7,128), input_shape=(128*7*7,)))
model.add(UpSampling2D((2,2)))
model.add(Convolution2D(64,5,5,border_mode='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2,2)))
model.add(Convolution2D(1,5,5,border_mode='same'))
model.add(Activation('tanh'))
return model
通常のDCGANとの相違点は、inputの次元(サイズ)だけです。潜在変数の次元数z_dimにCLASS_NUMを足しています。クラス数の情報が増えるのでinputの間口を広げておきます。これだけ。
discriminatorへの数値ラベルの入力
次にdiscriminatorへの数値ラベル情報の入力のさせ方について説明します。discriminatorの入力は画像データでmnistの場合は(batch_num, 28, 28, 1)の行列です。(backend=tensorflow表記で)
画像データに、数値ラベル情報を持たせる方法として非常に単純な方法を用います。画像データは1チャンネル(白黒)の画像ですが、そこにclass_num=10種類の白黒画像を重ねて11チャンネルにしてしまいます。ただし、正解となるチャンネルのデータは各ピクセル値がオール1の白い画像、その他はオール0の黒い画像にします。強引ですね。
例えばラベルが3である画像に関しては、インデックス番号3(すなわち4枚目)だけ白い10枚の画像を重ねて11チャンネルにします。

このやり方を知った時の正直な感想は「もったいねぇ」ですね。大した情報もないのに画像のデータ量が11倍に増える所業。
高解像度データや、もっと大きなカテゴリ問題に対してスケールしないのは明らかですね。
対処法としてラベル情報をdiscriminatorの中間層に入れる手もあり有効なようです。
大変参考になるブログがこちら
conditional DRAGANでのラベルの与え方 緑茶思考ブログ
ただし、中間層にラベル情報を入れるテクニックはWGAN-gpでは使えないような気がします(discriminatorの入力値の平均をとるので)。GANの多カテゴリへの適用は研究されていると思いますし、きっとうまい方法があるのだと思います。(調査不足ですので、ご存知の方いたら教えてください)
discriminatorの実装は以下
def build_discriminator(self):
model = Sequential()
model.add(Convolution2D(64,5,5,\
subsample=(2,2),\
border_mode='same',\
input_shape=(self.img_rows,self.img_cols,(1+CLASS_NUM))))
model.add(LeakyReLU(0.2))
model.add(Convolution2D(128,5,5,subsample=(2,2)))
model.add(LeakyReLU(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
これもgeneratorの時と同じでinputを1チャンネルから1+class_num(=11)にするだけです。
combinedモデルの作成
generatorでは、上述の通りz,y二つのインプットを定義します。それをモデル内部でマージしています(z_y)。
マージした変数z_yをgeneratorに通して偽物画像を生成させるデータの流れを作ります(img)。
ラベル情報から10チャンネル画像の変換はlabel2images関数を使います。
生成した偽物データと、ラベル情報を10ch画像にしたもの(img_10)をマージします(img_11)。
それをdiscriminatorに通したものが最終出力です。
モデルの入力変数はz,y, img_10です。
def build_combined(self):
z = Input(shape=(self.z_dim,))
y = Input(shape=(CLASS_NUM,))
img_10 = Input(shape=(self.img_rows,self.img_cols,CLASS_NUM,))
z_y = merge([z, y],mode='concat',concat_axis=-1)
img = self.generator(z_y) # [batch, WIDTH, HEIGHT, channel=1]
img_11 = merge([img, img_10],mode='concat', concat_axis=3)
self.discriminator.trainable= False
valid = self.discriminator(img_11)
model = Model(input = [z, y, img_10], output = valid)
return model
Discriminatorの学習時
discriminatorの学習時の構造を以下に示します。
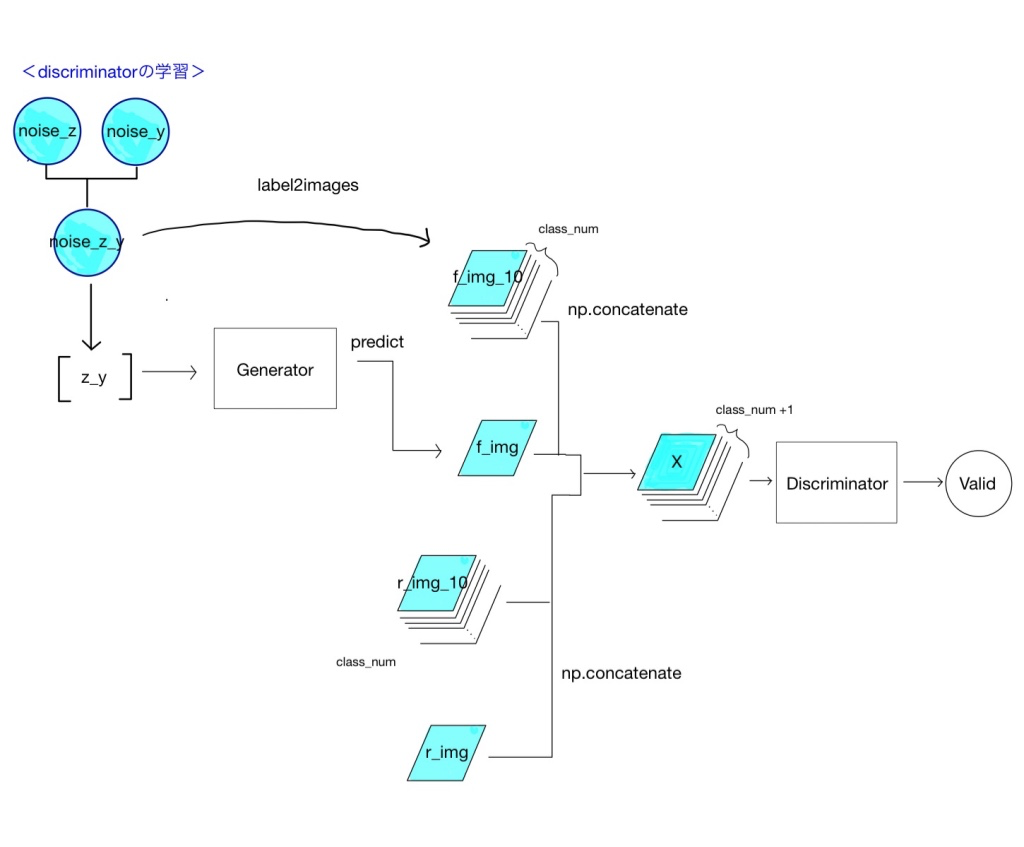
シリーズ1で通常のGANを説明したときと変わりません。generatorは画像を生成するための下準備にのみ用います。実データをあらかじめ結合(np.ndarrayの結合ですからnp.concatenateを用います)してから、discriminatorに突っ込みます。
今回も、偽物の生成データと本物データを同時に入力させています。
生成結果
生成結果を示します。0,1,2,3...とラベルを指定して画像を生成させています。潜在変数の値は各マスで異なります。
ラベルを与えて数字を書き分けることに成功しています。

まとめ
- Conditional GANを用いることで、ラベル情報を与えながらGANを学習させた。
- Generatorにラベル情報を与えながら生成させることで文字を書き分けることができた。
実装はこちら (https://github.com/triwave33/GAN/blob/master/GAN/cgan/cgan_mnist.py)
180317追記
コードが間違っていてうまくいきませんでしたが,fixしています.
(使っていない変数があるので,もう少しすっきりさせたいです)
ラベルを与えることで文字を書き分けることができましたので、次回はいろいろ実験してみたいと思います。
特に、generatorに与えるラベルにちょっとイジワルをしてみて、どのような画像が生成されるか試してみたいと思います。
思いついてはいるのですがまだ試していないので、ちょっと楽しみです。