なんとなく知っている気になっているけど。。。
ディープラーニング関連技術の中でも、GANに関するニュースは良く取り上げられていますね。警察と貨幣偽造者といったコンセプトは理解しやすく、学習したモデルから新たに絵や文章などを作り出せることは「これぞ人工知能」感を醸し出しています。
知ったかぶって、「それ、GANでできたら面白いですね」とか言ってしまうくせに、ソースコードレベルでの動作については実は良くわかっていない。チュートリアルを実行してなんとなく、「この行は〜をしているのだなぁ」ということはわかるのですが、そもそも「GANの基本思想を理解した上でなぜこのコーディングになっているのか」が掴めないため、
- 自分の適用させたい問題に対して、どこを修正すれば良いのかわからない
- 新しいGANのアルゴリズムが出てきたときに、どこを修正すれば良いのかわからない
はい、全て私の経験です。この記事では、自分自身の経験のもと、GANの概念をどうコーディングに落とし込むかを解説したいと思います。理論についてはあえて深入りせず、GAN の考え方とコードの対応関係を解説できたらと思います。
目的
GANの実装面での基本コンセプトを理解し、一から実装できるようになる
内容
GANのネットワーク構造と、入力データ&正解ラベル、loss関数について
対象としている人
前提知識
- MLP, CNNを用いた識別モデルをKerasで理解、実装できる
- numpy.ndarrayの知識
GANについてなんとなく分かっていること
- 生成モデルである(絵を描いたりできる)
- 生成者と識別者を競わせる
- パラメータチューニングが難しい
- 数字を書いたりベッドルームを生成したりできる
- 線画に着色したり、単語から画像を生成したりできる
- 様々なGAN亜種があり、現在進行形で増えている
- とりあえずチュートリアルを実行している
GANについてよく分からないこと
- 生成者と識別者のネットワークの繋ぎ方
- 生成させるデータの元となるデータ
- loss関数の中身の解釈
- GAN の種類と使い分け
- 学習した生成モデルのコントロール
- mnistを学習したが、どうやって"1"と"5"を書き分ける?
- exampleを実行できたが、各行の表す意味
- 意味は理解できるが、その記述に至った思考過程
参考にした記事
GANについての大まかな知識は知っているものとします。参考になった記事はたくさんあるのでそちらを参照してください。また、Generator、Discriminatorのネットワーク構造についてや、Batch NormalizationなどについてのTipsなどについては、以下が参考になりました。
Generative Adversarial Networks(GAN)を勉強して、kerasで手書き文字生成する
はじめてのGAN
実行環境
Python 2.7.14
Keras 2.1.3
backend:tensorflow 1.4.1
使用データ
MNIST データセット(shape = datasize, 28, 28, 1)
基本構造(データフロー)
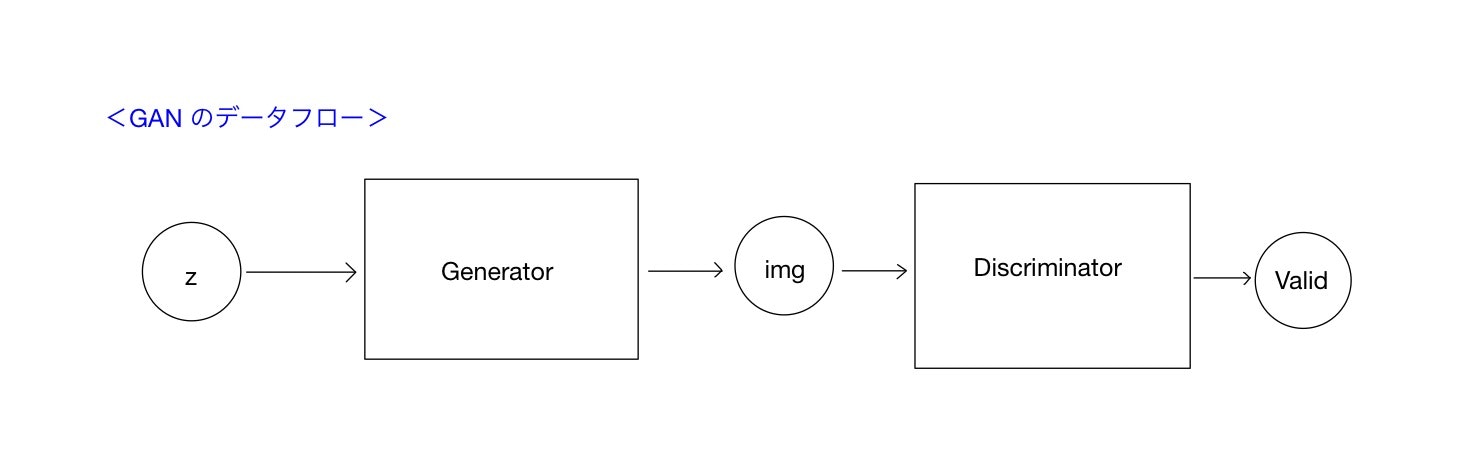
GANの基本構造を図に示します。四角で囲んだモジュールが生成器(Generator)および識別器(Discriminator)です。丸で囲んだ変数が各モジュールの入出力となる変数を示しています。
まずGeneratorは、潜在変数と言われる値(z)を入力値として受け取り、画像データ(img)を出力します。通常zは(mnistの場合)100次元ほどの各要素が0から1までの値をとる変数で、一様分布や正規分布からランダムサンプリングされます。つまり、この潜在変数zが生成モデルから画像を生成するための「種」となります。
Discriminatorは画像データ(img)を入力値として取り、そのデータが本物のデータか、それともGeneratorから生成(捏造)されたデータかを出力値(Valid)として識別します。出力値は、本物である場合1、偽物である場合0として、その確率を連続値として返します。
データを示す丸は、データの実体ではなく、データを流し込むための窓口だと思ってください。(TensorflowでいうPlaceholder)。
Discriminator(識別器)の学習
Discriminator(識別器)の学習から説明します。
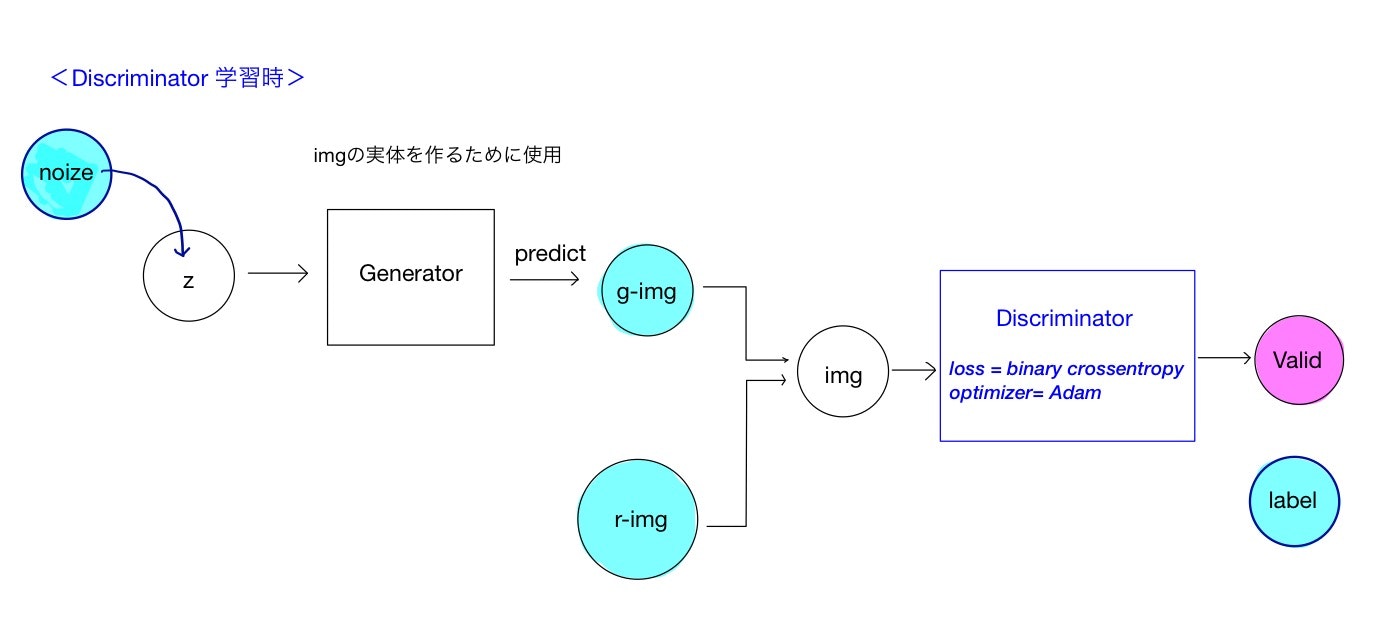
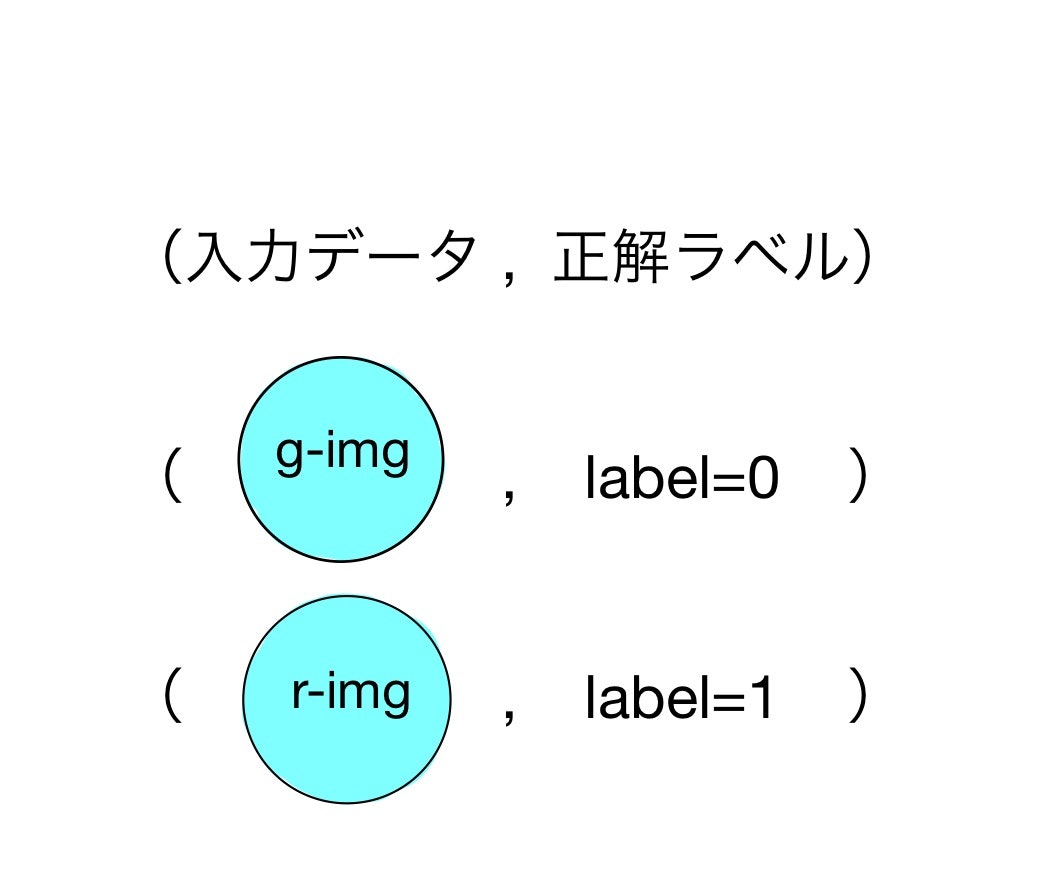
識別器は画像(img)を入力データとして、予想結果(偽物か本物か)を出力するので、教師データはその画像が偽物か本物かのラベルになります。すなわち、本物の画像(r-img)をimgに入力した時には1の正解ラベルを、偽物(g-img)をimgに入力した時には0の正解ラベルを与えます。
偽物の画像(g-img)を生成するためには生成器の入力値zに乱数から発生させたデータ(noise)を与えます。Generatorから生成画像を実際に発生させ(predictメソッドを使います)、生成された偽物画像をimgに流し込みます。ここで、Generatorは画像を生成させるために用いただけで、学習対象のDiscriminatorとは完全に分離されていることに注意してください。。生成された画像は、numpy.arrayの形で完全に確定しているため、generatorはこの場合Discriminatorの学習とは無関係です。
データセットにある本物の画像(r-img)の場合は、単純に識別器の入力imgに実データr-imgを流し込めばOKです。
generatorの学習
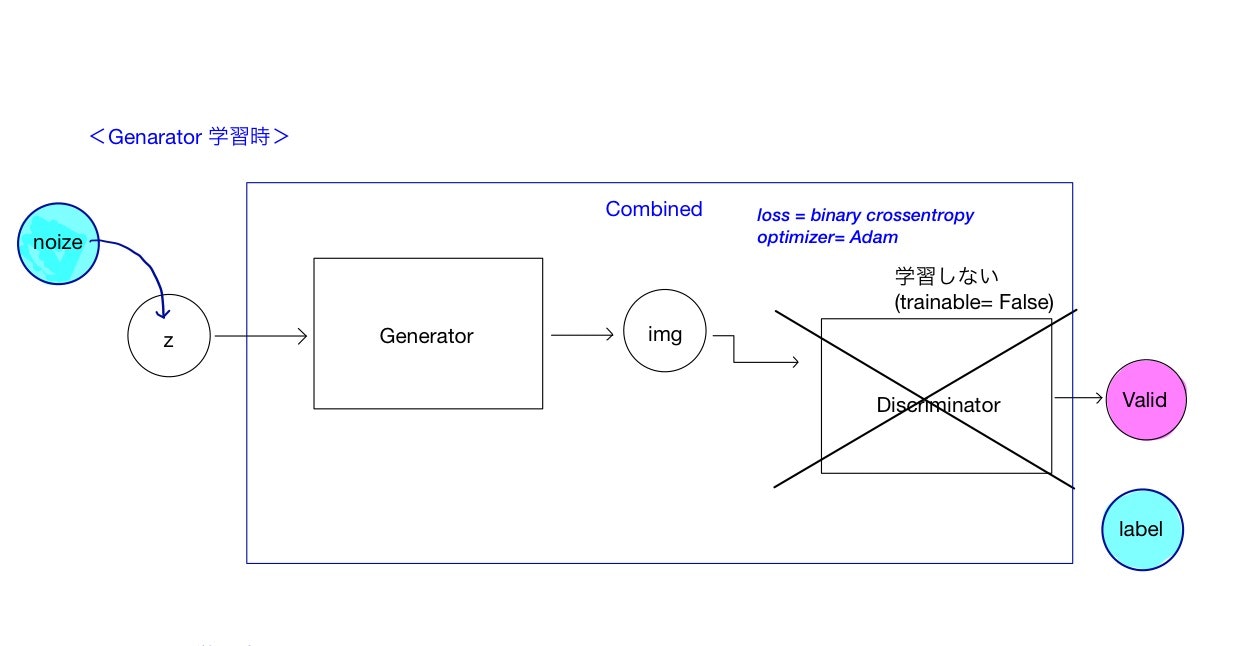
GANの最終出力は、画像が本物であるかどうか(の確率)を表す変数Validであるため、Generatorの学習時にもValidを目的変数にとります。このあたりが、同じ生成モデルではありますが、目的変数に自分自身の入力データをとるVAE(Valiational Auto Encoder)との違いになります。従って、Genaratorの学習時にはDiscriminatorまでを含めたネットワークを用います。これを図中ではCombinedネットワークとして表しています。
ただし、ここではあくまでGenaratorのみを学習させたいため、Discriminatorの重みを固定させる必要があります。これは、Discrminatorのオプションをtrainable = Falseにすることで達成されます。入力データは乱数によって生成された値noiseです。
これでCombinedネットワークを学習させることで、Genaratorだけをうまく学習させることができます。
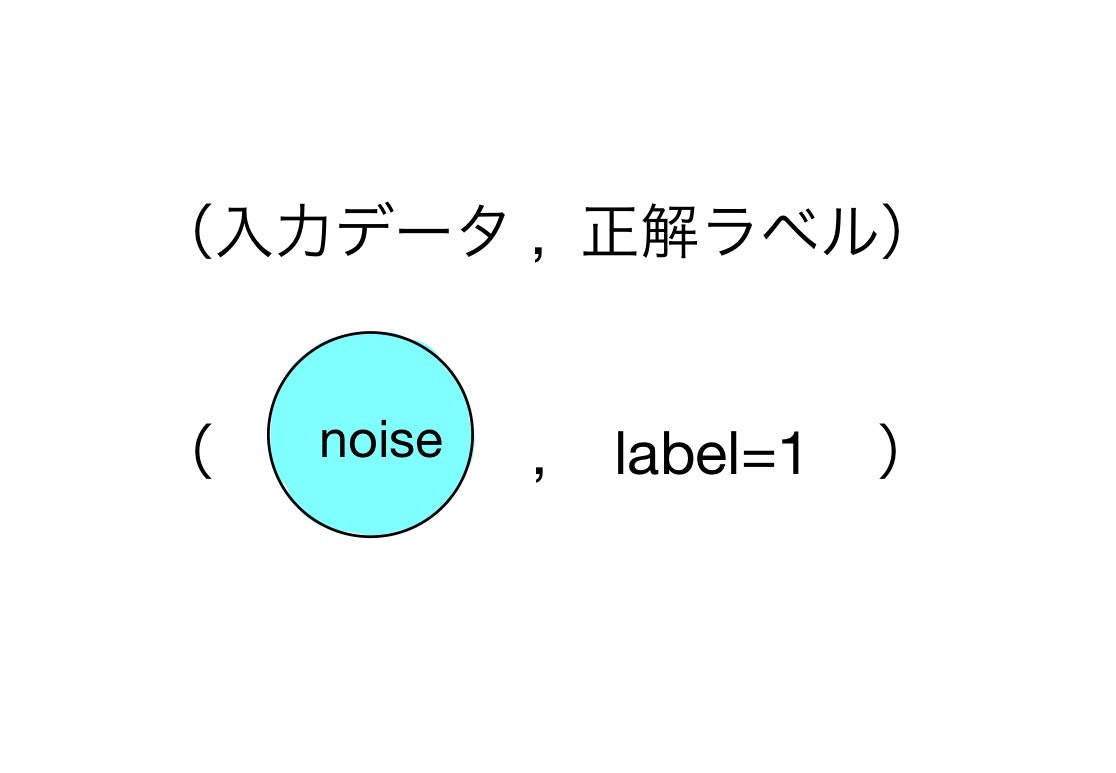
ここで一つだけトリックを使います。noiseからGenaratorを用いて生成された画像は当然偽物なので、本来正解ラベルは0なのですが、ここでは本物(1)のラベルを使います。なぜならGeneratorの目的はDiscriminatorを騙すことなので、識別結果が本物と判定されるほうが(Generatorにとっての)loss関数が小さくなる方向に進むからです。
Discriminator、Generatorの学習ともに、予想と正解が一致するときに値が小さくなるようなloss関数を用いて、その関数を最小化するように学習します。ラベルは0,1の二値分類ですので、loss関数としてbinary crossentropyを用いることができます。
基本構造のKerasコード
class GAN():
def __init__(self):
#mnistデータ用の入力データサイズ
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# 潜在変数の次元数
self.z_dim = 100
optimizer = Adam(0.0002, 0.5)
# discriminatorモデル
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Generatorモデル
self.generator = self.build_generator()
# generatorは単体で学習しないのでコンパイルは必要ない
#self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
self.combined = self.build_combined1()
#self.combined = self.build_combined2()
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (self.z_dim,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
return model
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
return model
def build_combined1(self):
self.discriminator.trainable = False
model = Sequential([self.generator, self.discriminator])
return model
def build_combined2(self):
z = Input(shape=(self.z_dim,))
img = self.generator(z)
self.discriminator.trainable = False
valid = self.discriminator(img)
model = Model(z, valid)
model.summary()
return model
コードはこちらを基に一部改編したものを用います。githubに上げています。
まず、GAN クラスを定義し、コンストラクタにGAN の基本構造を構築していきます。まず、入力画像のshapeを定義します。mnist なので高さ28、幅28、1チャンネル(白黒)ですね。
学習に用いるoptimizer を定義したあとに、基本構造を書きます。メンバ変数discriminator変数を宣言し、build_discriminatorメソッドの返り値を格納します。build_discriminatorは、入力データに先ほど定義したmnistデータシェイプをとり、シグモイド関数により最終的にvalidity=[0,1]を出力するモデルです。
同様にbuild_generatorメソッドによりgenerator 変数を宣言しています。オリジナルでは、これもコンパイルしていますが、generator単体では学習しないので、ここでのコンパイルは必要ありません。実際にコメントアウトで無効化しても学習はうまくいきます。
さて、generatorの学習時には、generator単体ではなく、あくまでdiscriminatorを連結したcombinedネットワークを用いることを説明しました。combinedネットワークを作っていきましょう。generatorとdiscriminatorを直列に繋ぎます。ここでは、多少冗長ですが二通りの方法を紹介します。
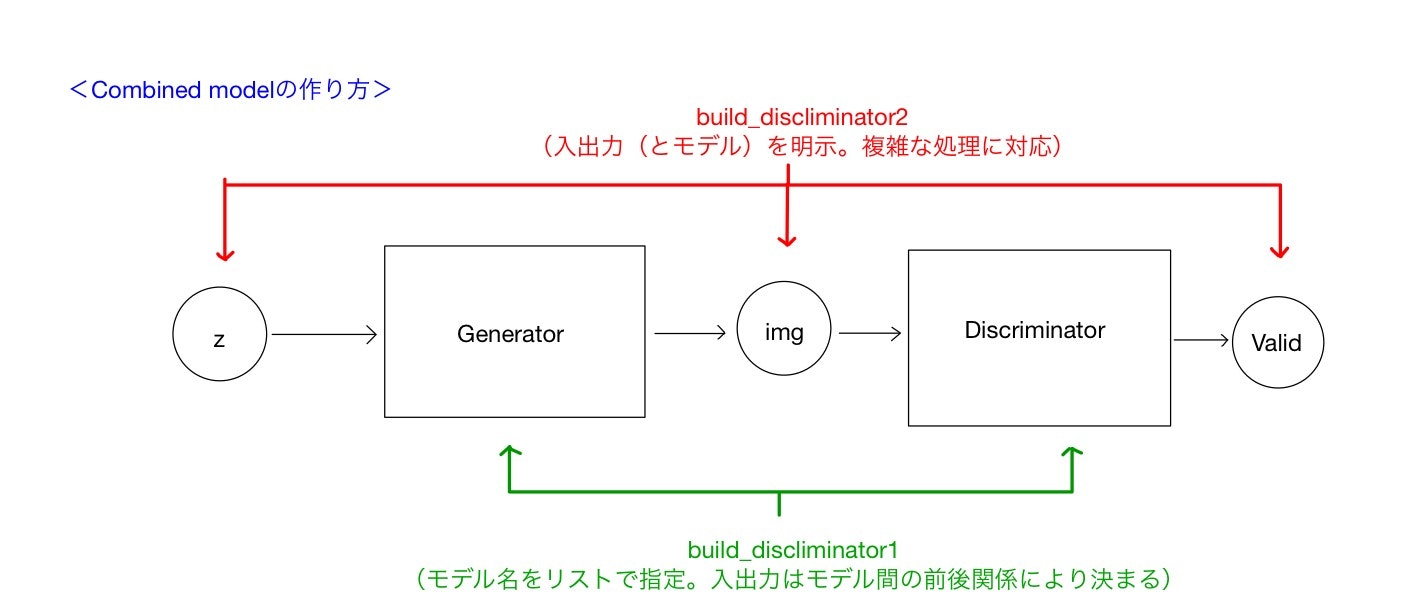
1つ目は、定義したmodel名を用いて新しいcombined modelを定義する方法です。コードのbuild_combined1メソッドがこれに対応します。Sequential[self.generator, self.discriminator]のように、sequentialモデルをリスト形式で書くことで、モデルを直列につなぐことができます。モデルを指定することで、そのモデルの入出力が決まりますから、あるモデルの出力が次のリストのモデルの入力に引き渡されていきます。この際、前段の出力シェイプと入力シェイプは当然一致している必要があります。
2つめは、モデルの入出力変数を用いて新しいcombined modelを定義する方法です。これはbuild_combined2メソッドに対応しています。generatorの入力zをInputメソッドを用いて宣言し、generatorからの出力をimgに代入します。さらに生成画像imgをdiscriminatorに渡した出力をvalidとして、データの通り道を作ってやります。最終的なモデルの宣言はModelメソッドに最初の入力と最後の出力を指定することで達成されます。
記述がシンプルなのは1つ目の方法ですが、実際のモデル構造を入出力を意識しながら記述しているのは2つめ目の方法です。モデルの分岐、合流など複雑なモデルを扱う場合は後者の方が適しています。kerasに慣れていない場合はSequential モデルとFunctional APIの説明を参照するとよいと思います。
loss関数
GAN 論文で用いられてるloss 関数を以下に示します。
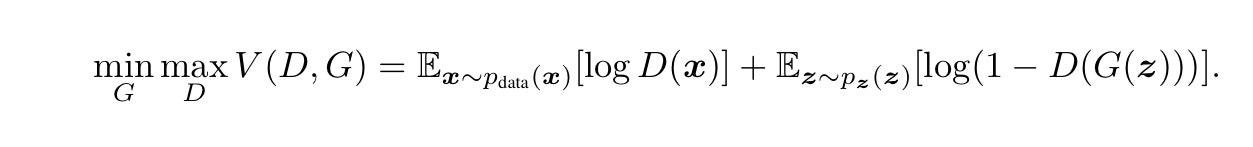
Descriminator、Generatorの学習で触れた入力データ、正解ラベルの関係と、それに対応するloss関数について見ていきます。上式はGAN論文に記載されているloss関数です。
まずはDiscriminatorからですが、Generatorを固定した上で上式を最大化します。右辺第1項は本物データを用いるケースです。この項を最大化するにはlogの内部を最大化、すなわちDiscriminatorの識別結果として1を出力させるよう学習させます。
右辺第2項は、Generatorにより生成されたデータを示します。log内部を最大化するためにはDiscriminatoの出力を最小化、つまり0を出力するようにすれば良いです。これはDiscriminatorの学習のところで触れた入力データの組み合わせと正解ラベルの組み合わせに一致します。
次にGeneratorについてです。Discriminatorは固定でGeneratorのみに依存するので第2項のみを考えます。Gについて最小化をするので対数項の中身が1になるように学習させたいことがわかります。これは、Generatorの学習の所で、Generatorから生成した偽物の画像に、本物のラベル(1)をつけて学習させることに対応します。
やや観念的な説明になりましたが、GANのロス関数の定義と、実装で用いた各ネットワークのloss関数の対応がわかると思います。
学習
def train(self, epochs, batch_size=128, save_interval=50):
# mnistデータの読み込み
(X_train, _), (_, _) = mnist.load_data()
# 値を-1 to 1に規格化
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Discriminatorの学習
# ---------------------
# バッチサイズの半数をGeneratorから生成
noise = np.random.normal(0, 1, (half_batch, self.z_dim))
gen_imgs = self.generator.predict(noise)
# バッチサイズの半数を教師データからピックアップ
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
# discriminatorを学習
# 本物データと偽物データは別々に学習させる
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
# それぞれの損失関数を平均
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Generatorの学習
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.z_dim))
# 生成データの正解ラベルは本物(1)
valid_y = np.array([1] * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# 進捗の表示
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 指定した間隔で生成画像を保存
if epoch % save_interval == 0:
self.save_imgs(epoch)
論文のアルゴリズム通りに実装しています。論文と少し違うところはdiscriminatorの学習時に教師データ(本物データ)とgeneratorから生成した偽物データを別々に学習させているところです。
今回の実装では、実はあまり影響はないですが、GANを効率よく学習させるための手法としてBatch Normalizationという手法があります。入力データをミニバッチ単位で正規化する手法で、本物データと(特に学習初期のほとんど乱数のような)生成データを混ぜて正規化することは好ましくないため、分けて処理していると考えられます。
結果
生成した画像を示します。
400 iteration後

1000 iteration後

5000 itration後

15000 iteration後

段々と文字が生成されています。
まとめ
GANの基本的なネットワーク構造の解説と、kerasを用いた実装方法について解説し、実際に文字が生成されることを確認しました。この記事では、discriminator, generatorのネットワークの中身については解説せず、二つのネットワークの連結方法と損失関数、学習の方法について解説しました。
さて、より良い生成モデルを作ったり、より効率的な学習をさせるためにはどのようなテクニックがあるでしょうか。実は、今回の基本構造に対して、ネットワークの中身やその連結方法、用いる損失関数を変えることで、GANをさらにブラッシュアップすることができます。
例えば、今回の生成画像は文字のない部分にも微妙に白いピクセルが見え、何か砂絵のように見えますね。これはネットワーク構造に(単純な)多層ニューラルネットワークを使っているためです。通常のニューラルネットワークは、隣接するノード間(今回でいうピクセル間)の関係については全く考慮しません。ですので、このような砂絵状の画像になります。ピクセル間の関係性を考慮するネットワークを用いることで、さらに良い画像を生成させることができます。すなわち畳み込みニューラルネットワークを用いたdcganです。
また、乱数から文字を生成させることに成功しましたが、現状では生成させる文字(1とか8とか)を指定することができません。生成データをコントロールするためには、学習時に文字の正解ラベルを取り込む必要があります(conditional-GAN)。
これらについても、今回の基本構造をベースに今後解説していきたいと思います。