はじめに
今や自然言語処理の定番手法となっているWord2Vecについて勉強したことをまとめました。
そのアルゴリズムの概要を整理しライブラリを用いてモデルを作成しています。
参考
Word2Vecを理解するに当たって下記を参考にさせていただきました。
- ゼロから作るDeep Learning ❷ ―自然言語処理編 斎藤 康毅 (著)
- 絵で理解するWord2vecの仕組み
- Efficient Estimation of Word Representations in Vector Space
(元論文) - gensimのAPIリファレンス
Word2Vec概要
下記ではWord2Vecの前提となっている自然言語処理の考え方について記載しています。
単語の分散表現
単語を固定長のベクトルで表現することを「単語の分散表現」と呼びます。単語をベクトルで表現することができれば単語の意味を定量的に把握することができるため、様々な処理に応用することができます。Word2Vecも単語の分散表現の獲得を目指した手法です。
分布仮説
自然言語処理の世界では様々なベクトル化手法が研究されていますが、主要な手法は**「単語の意味は周囲の単語によって形成される」というアイデアに基づいており分布仮説と呼ばれています。本記事でご紹介するWord2Vecも分布仮説に基づいています。**
カウントベースと推論ベース
単語の分散表現を獲得する手法としては、大きく分けてカウントベースの手法と推論ベースの手法の二つがあります。カウントベースの手法は周囲の単語の頻度によって単語を表現する方法で、コーパス全体の統計データから単語の分散表現を獲得します。一方で、推論ベースの手法はニューラルネットワークを用いて少量の学習サンプルをみながら重みを繰り返し更新する手法です。Word2Vecは後者に該当します。
Word2vecのアルゴリズム
以下ではWord2Vecのアルゴリズムの中身を説明していきます。
Word2vecで使用するニューラルネットワークのモデル
Word2vecでは下記2つのモデルが使用されています。
- CBOW(continuous bag-of-words)
- skip-gram
それぞれのモデルの仕組みについて説明していきます。
CBOWモデル
概要
CBOWモデルはコンテクストからターゲットを推測することを目的としたニューラルネットワークです。このCBOWモデルをできるだけ正確な推測ができるように訓練することで単語の分散表現を獲得することができます。
前後のコンテクストをどの程度利用するかはモデル作成ごとに判断しますが、前後1単語をコンテクストとする場合、例えば下記だと「毎朝」「を」から「?」の単語を推測することになります。
|私|は|毎朝|?|を|飲み|ます|。|
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
CBOWのモデル構造を図示すると下記のようになります。入力層が二つあり、中間層を経て出力層へとたどり着きます。
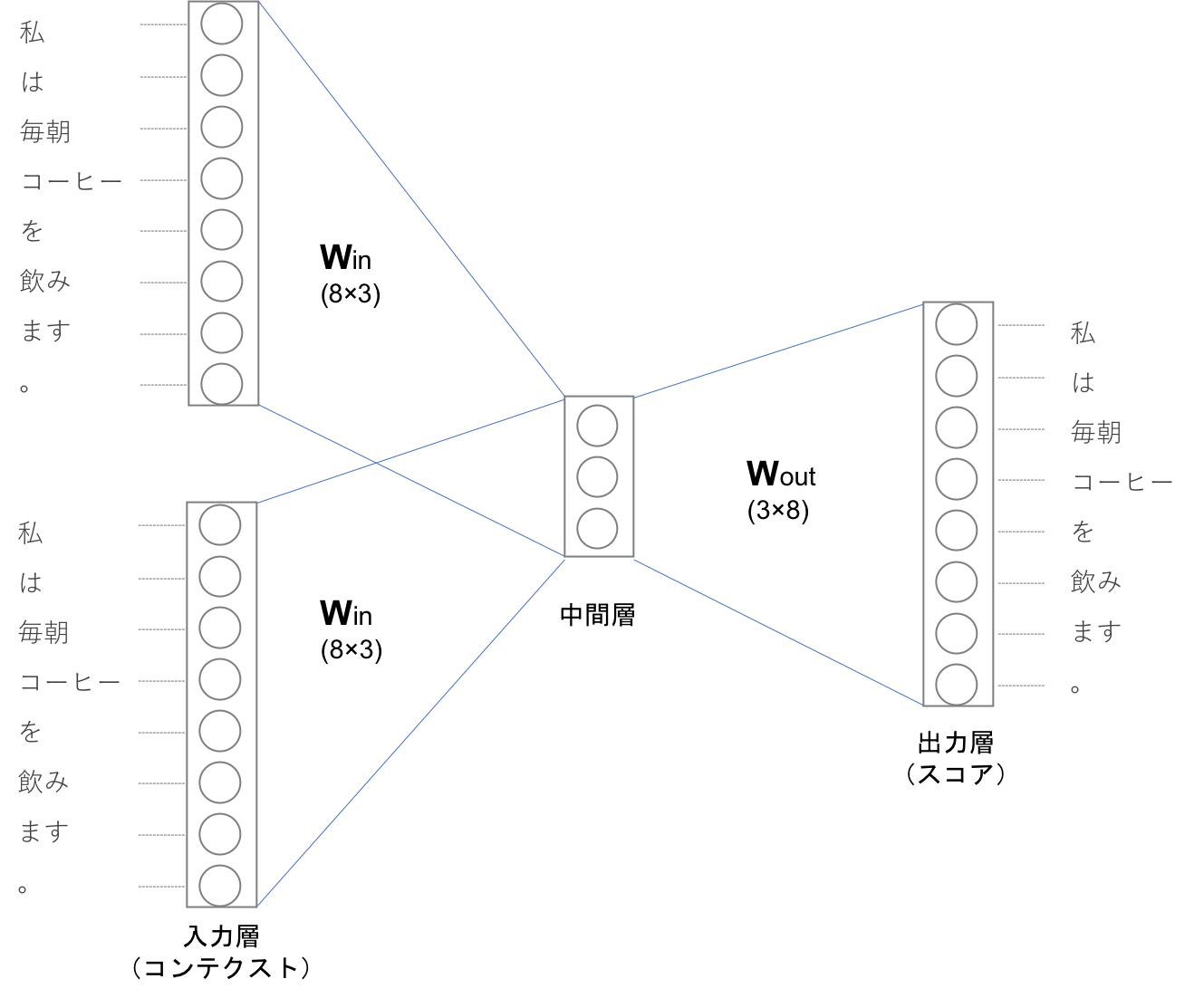
上記図の中間層は各入力層の全結合による変換後の値が「平均」されたものになります。一つ目のの入力層が$h_1$二つ目の入力層が$h_2$に変換されたとすると中間層のニューロンは$\frac{1}{2}(h_1+h_2)$になります。
入力層から中間層への変換は、全結合層(重みは$W_{in}$)によって行われます。この時は全結合層の重み$W_{in}$は$8×3$の形状の行列になっていますが、この重みこそがCBOWを用いて作る単語の分散表現になります。
CBOWモデルの学習
CBOWモデルは出力層において各単語のスコアを出力しますが、そのスコアに対してSoftmax関数を適応することで「確率」を得ることができます。この確率は前後の単語を与えた時にその中央にどの単語が出現するのかを表します。
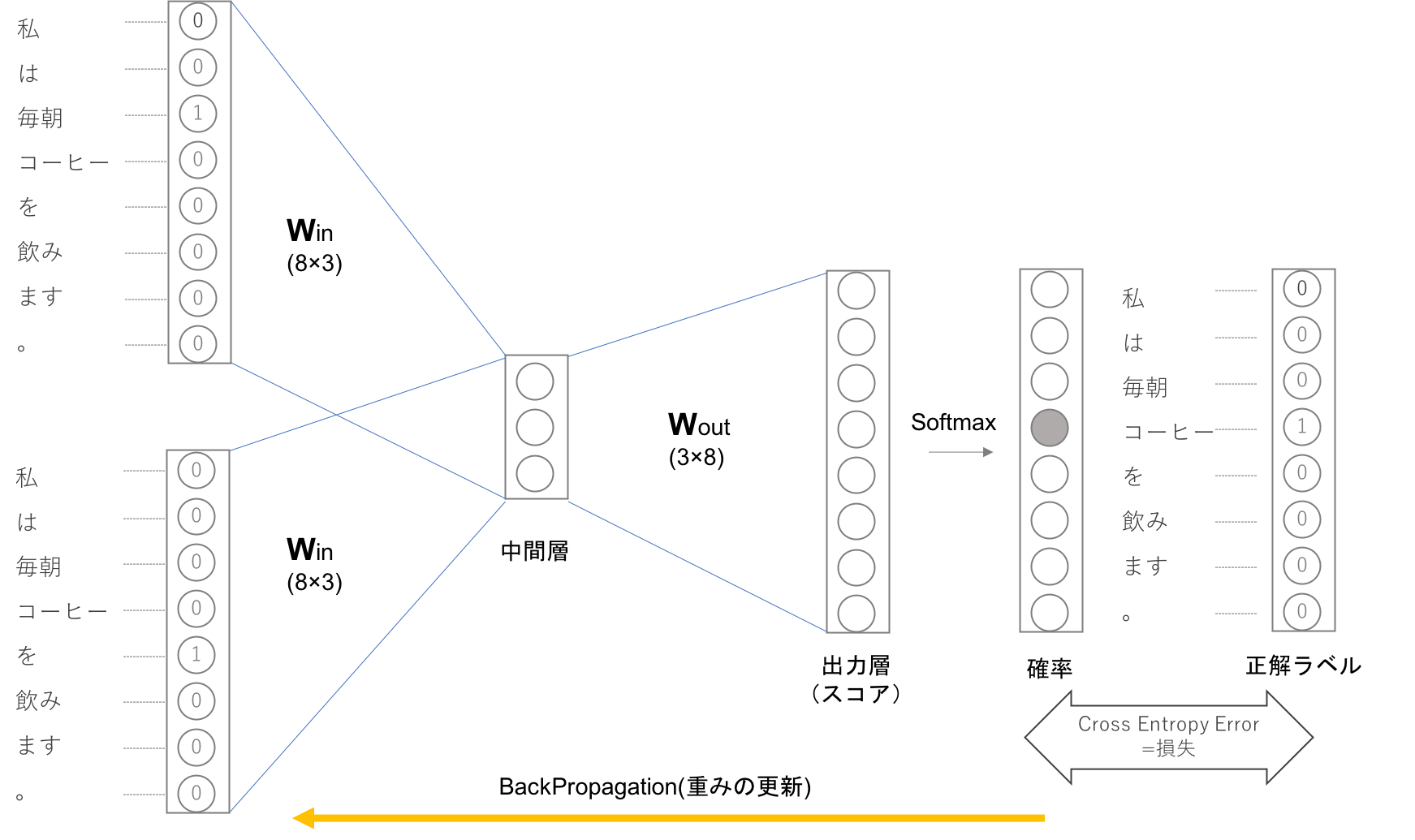
上記の例ではコンテクストは「毎朝」「を」、ニューラルネットワークが予想したい単語が「コーヒー」である例です。この時適切な重みを持ったニューラルネットワークでは「確率」を表すニューロンにおいて正解ニューロンが高くなっていることが期待できます。CBOWの学習では正解ラベルとニューラルネットワークが出力した確率の交差エントロピー誤差を求め、それを損失としてその損失を少なくしていく方向に学習を進めます。
CBOWモデルの損失関数は下記のように表されます。
(モデルを作成するに当たって用いるコンテクストを前後1単語とした場合)
L = -\frac{1}{T}\sum_{t=1}^{T}logP(w_{t}|w_{t-1},w_{t+1})
上記損失関数をできるだけ小さくしていく方向で学習していくことで、その時の重みを単語の分散表現として獲得することができます。
skip-gramモデル
skip-gramモデルはCBOWで扱うコンテクストとターゲットを逆転させたようなモデルになります。下記のように中央の単語から前後の複数のコンテクストを予測するモデルです。
|私|は|?|コーヒー|?|飲み|ます|。|
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
skip-Gramのモデルのイメージは下記のようになります。
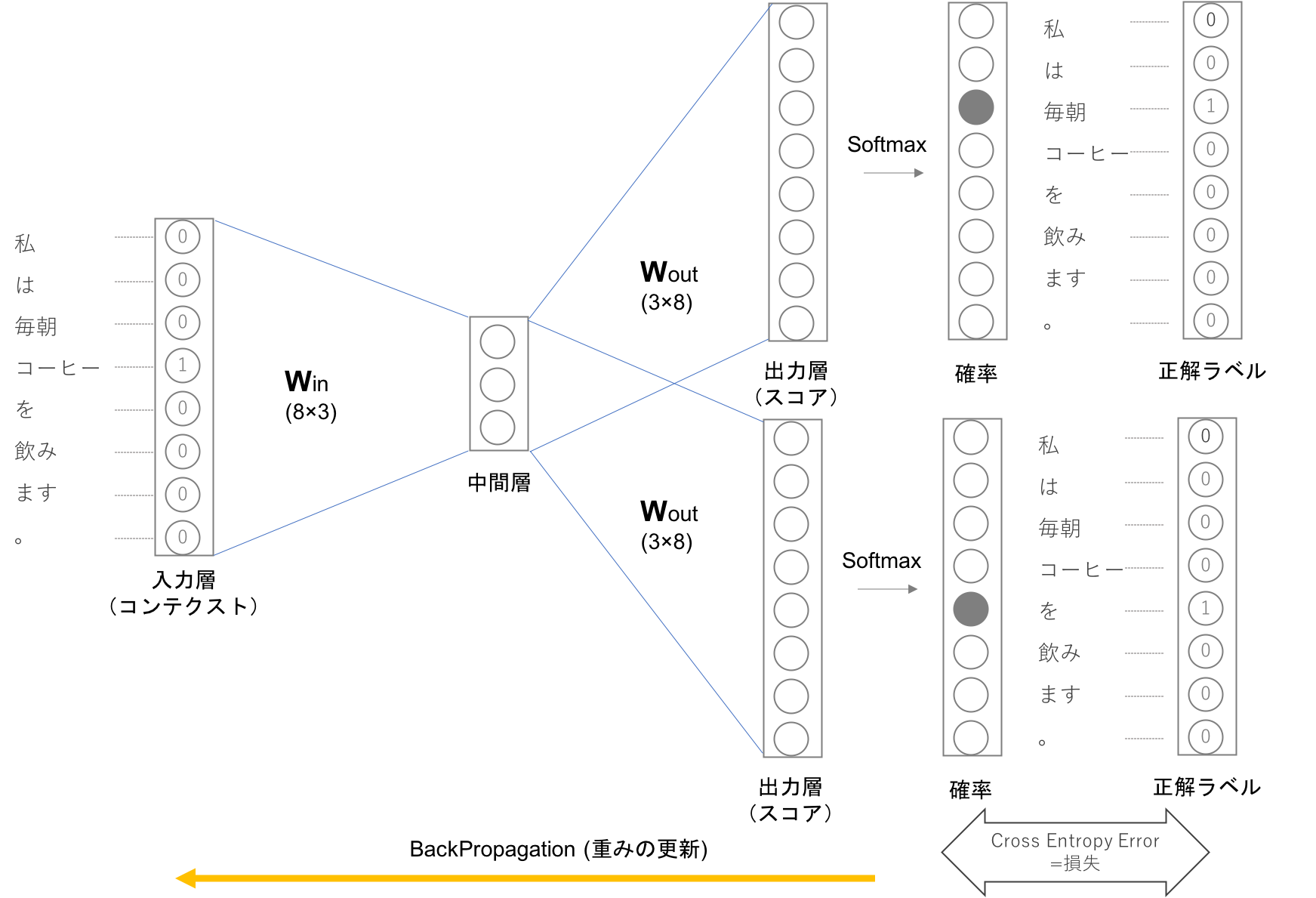
skip-gramの入力層はひとつで出力層はコンテクストの数だけ存在します。それぞれの出力層で個別に損失を求め、それらを足し合わせたものを最終的な損失とします。
また、skip-gramモデルの損失関数は下記の式で表されます。
(モデルを作成するに当たって用いるコンテクストを前後1単語とした場合)
L = -\frac{1}{T}\sum_{t=1}^{T}(logP(w_{t-1}|w_{t}) + logP(w_{t+1}|w_{t}))
skip-gramモデルはコンテクストの数だけ推測を行うためその損失関数は各コンテクストで求めた損失の総和を求める必要があります。
CBOWとskip-gram
CBOWとskip-gramではskip-gramモデルの方が良い結果が得られるとされており、コーパスが大規模になるにつれて程頻出の単語や類推問題の性能の点において優れた結果が得らるとのことです。一方でskip-gramはコンテクストの数だけ損失を求める必要があるため学習コストが大きく、CBOWの方が学習は高速です。
ライブラリを用いたWord2vecモデルの作成
以下ではライブラリを用いて実際にWord2Vecのモデルを作成していきます。
データセット
pythonのライブラリであるgensimを用いて簡単にWord2Vecのモデルを簡単に作成することが可能です。今回データセットは「livedoor ニュースコーパス」を使用させていただきます。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿しているの気になる方そちらをご参照いただければと思います。
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
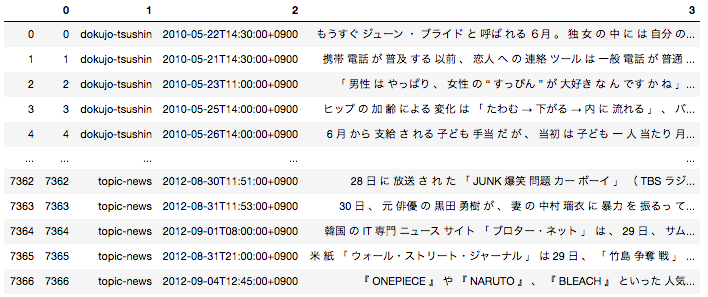
一番右のカラムが文章を全て形態素解析して半角スペースごとに区切ったものになります。こちらを用いてWord2Vecモデルを作成します。
モデルの学習
gensimを用いてWord2vecのモデルの作成を行います。下記がモデルを作成するに当たっての主要なパラメータになります。
| パラメーター名 | パラメータの意味 |
|---|---|
| sg | 1ならskip-gramで0ならCBOWで学習する |
| size | 何次元の分散表現を獲得するかを指定 |
| window | コンテクストとして認識する前後の単語数を指定 |
| min_count | 指定の数以下の出現回数の単語は無視する |
下記がWord2Vecのモデルを作成するコードになります。投入するテキストさえ作成できていれば一行でモデルの作成が可能です。
sentences = []
for text in df[3]:
text_list = text.split(' ')
sentences.append(text_list)
from gensim.models import Word2Vec
model = Word2Vec(sentences, sg=1, size=100, window=5, min_count=1)
Word2Vecでできること
Word2Vecのモデルによって単語の分散表現を獲得することができました。単語の分散表現を用いると単語間の意味的な距離を定量的に表したり、単語同士で意味の足し算や引き算ができたりします。
先ほど作成したモデルを用いて「家族」に近い単語を確認してみます。
for i in model.most_similar('家族'):
print(i)
('親子', 0.7739133834838867)
('恋人', 0.7615703344345093)
('絆', 0.7321233749389648)
('友人', 0.7270181179046631)
('団らん', 0.724891185760498)
('友だち', 0.7237613201141357)
('ふたり', 0.7198089361190796)
('夫婦', 0.6997368931770325)
('同士', 0.6886075735092163)
('深める', 0.6761922240257263)
「親子」や「恋人」など何となく「家族」と意味合いの近そうな単語が上位に上がってきました。
次は単語同士で算術計算をしていみます。「人生」ー「幸福」を計算してみたのが下記になります。
for i in model.most_similar(positive='人生',negative='幸福'):
print(i)
('現金', 0.31968846917152405)
('おら', 0.29543358087539673)
('修理', 0.29313164949417114)
('募金', 0.2858077883720398)
('ユーザー', 0.2797638177871704)
('頻度', 0.27897265553474426)
('適正', 0.2780274450778961)
('税金', 0.27565300464630127)
('かから', 0.273759663105011)
('予算', 0.2734326720237732)
今回は学習させたコーパス自体がそこまで大きなものではないため、微妙な感じにはなっていますが「現金」という単語が最も上位に来ています。単語の分散表現がどのようなものになるかは投入するコーパスに依存するため、Word2Vecを使用したい局面に応じて投入するコーパスをどういったものにするかの検討が必要だと思います。
Next
Word2Vecについて概要をざっくりと理解することができました。Word2Vecの発展であるDoc2vecについても次回以降でまとめることができたらと思っています。最後までご覧いただきありがとうございました。