はじめに
文章の感情分析に挑戦したのでその内容をまとめます。
今回は公開されているニュースコーパスを材料にし、各記事のネガポジ度合いのスコア化に試みます。
参考
感情分析の実装に当たって下記を使用、参考にさせていただきました。
感情分析とは何か
感情分析概要
感情分析とは様々なテキスト情報をテキストマイニングや機械学習の技術を用いて、その記述内容の感情を分析する手法です。ポジティブorネガティブの1軸の分析が最もオーソドックスな印象ですが、より細かい感情の分析に踏み込んでいるものもあります。
感情分析の方法
感情分析において最も一般的なのは文章に含まれる単語に着目する方法で、ポジティブ(ネガティブ)な文面にはそれ特有の単語が含まれるはずという考えに基づいています。そのような特定の単語を集めたリストを極性辞書と呼び、今回の感情分析ではこの極性辞書を用います。
極性辞書
極性辞書について
極性辞書とは、単語や用語毎に「ポジティブ」「ネガティブ」といった意味上のフラグ立てがなされた辞書のことを言います。単に「ポジティブ」「ネガティブ」といったフラグだけのものもあればポジティブ度合いやネガティブ度合いが離散的なスコア数値として与えられているものもあります。
今回使用する極性辞書
今回は極性辞書として公開されている「単語感情極性対応表」を使用させていただきます。
こちらの極性辞書はその語が一般的に良い印象を持つか(positive) 悪い印象を持つか(negative)を表した二値属性を離散的な値でスコア化した辞書になっています。こちらは東工大研究室の高村さんという方が公開している辞書になります。
研究目的に限り使用可能で、商用利用は不可なのでご注意ください。
商用利用できる極性辞書が欲しい方は「日本語評価極性辞書」をご利用ください。こちらは東北大の研究室が公開している極性辞書でクレジットの明記すれば商用利用可能です。
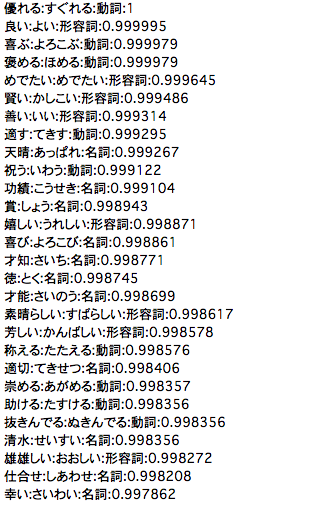
「単語感情極性対応表」の中身はこんな感じです。
感情分析の実装
以下で感情分析を実装していきます。極性辞書を読み込んでデータフレーム化した表とスコア化したい文章を形態素解析した表をマージさせ、その文章内形態素それぞれにスコアを付与してその合計値を求めるという手順で進めます。
極性辞書を読み込んでデータフレーム化する
まず極性辞書を読み込んでデータフレーム化します。
後の工程で、janomeの形態素解析結果と平仄を合わせるために読み仮名を全てカタカナにする処理を入れています。その処理のためにjaconvというライブラリを使用させていただいています。こちらはpipでイントール可能です。
今回使用する極性辞書は同じ漢字でも読みによって異なるスコアが割り当てられているので注意です。
import pandas as pd
import numpy as np
import os
import glob
import pathlib
import re
import janome
import jaconv
# dicというディレクトリにダウンロードしてきた極性辞書を入れておく
p_dic = pathlib.Path('dic')
# 極性辞書はテキスト形式でダウンロードしてきている想定
for i in p_dic.glob('*.txt'):
with open (i, 'r', encoding = 'cp932') as f:
#単語・読み仮名・品詞・スコアに分割してリストとして格納
x = [ii.replace('\n', '').split(':') for ii in f.readlines()]
posi_nega_df = pd.DataFrame(x, columns = ['基本形', '読み', '品詞', 'スコア'])
# jaconvを使って読み仮名を全てカタカナに変換
posi_nega_df['読み'] = posi_nega_df['読み'].apply(lambda x : jaconv.hira2kata(x))
# なぜか読みや品詞まで同じなのに、異なるスコアが割り当てられていたものがあったので重複を削除
posi_nega_df = posi_nega_df[~posi_nega_df[['基本形', '読み', '品詞']].duplicated()]
ニュース記事を読み込む
データセットは「livedoor ニュースコーパス」を使用させていただきます。データのフォーマットは各記事ごとに下記のようになっており、テキストデータとしてダウンロードして使用できます。
1行目:記事のURL
2行目:記事の日付
3行目:記事のタイトル
4行目以降:記事の本文
まずサイトからフォルダをダウンロードして解凍します。
そのフォルダがカレントディレクトリに存在するとして、下記を実行してデータフレームに落とし込みます。
p_temp = pathlib.Path('text')
article_list = []
# フォルダ内のテキストファイルを全てサーチ
for p in p_temp.glob('**/*.txt'):
#第二階層フォルダ名がニュースサイトの名前になっているので、それを取得
media = str(p).split('/')[1]
file_name = str(p).split('/')[2]
if file_name != 'LICENSE.txt':
#テキストファイルを読み込む
with open(p, 'r') as f:
#テキストファイルの中身を一行ずつ読み込み、リスト形式で格納
article = f.readlines()
#不要な改行等を置換処理
article = [re.sub(r'[\n \u3000]', '', i) for i in article]
#ニュースサイト名・記事URL・日付・記事タイトル・本文の並びでリスト化
article_list.append([media, article[0], article[1], article[2], ''.join(article[3:])])
else:
continue
article_df = pd.DataFrame(article_list)
article_df.head()
するとこのような形で出力されます。

こちらのデータを利用して感情分析を行います。
ニュース記事を形態素解析する
今回はニュース記事の中からスポーツ関連の記事に絞って形態素解析を行います。
形態素解析にはjanomeを使用します。単語を形態素に分割し、その単語の「基本形」「読み」「品詞」を取得します。極性辞書には単語が「基本形」で記載されているので、基本形の取得が必須になります。
# スポーツ関連の記事に絞る
news_df = article_df[article_df[0] == 'sports-watch'].reset_index(drop = True)
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.charfilter import *
t = Tokenizer()
char_filters = [UnicodeNormalizeCharFilter()]
analyzer = Analyzer(char_filters, t)
word_lists = []
for i, row in news_df.iterrows():
for t in analyzer.analyze(row[4]):
#形態素
surf = t.surface
#基本形
base = t.base_form
#品詞
pos = t.part_of_speech
#読み
reading = t.reading
word_lists.append([i, surf, base, pos, reading])
word_df = pd.DataFrame(word_lists, columns = ['ニュースNo.', '単語', '基本形', '品詞', '読み'])
word_df['品詞'] = word_df['品詞'].apply(lambda x : x.split(',')[0])
各記事のネガポジスコアを算出する
極性辞書をデータフレーム化したものと、ニュース記事を形態素解析データフレーム化したものをマージします。
score_result = pd.merge(word_df, posi_nega_df, on = ['基本形', '品詞', '読み'], how = 'left')
するとこのような感じで出力されます。なぜこの単語がこのスコアなの...?と思う単語も多々あったりするのですが、それぞれの単語についてスコアが割り振られているがわかると思います。
各ニュース記事のネガポジ度合いを算出します。
基本的には各文章内単語に付与されているスコアを全て足し上げたものをその文章のスコアとします。
文章の文字数にばらつきがある場合はスコアが文字数に左右されてしまうので、それを補正した標準化スコアも算出します。
result = []
for i in range(len(score_result['ニュースNo.'].unique())):
temp_df = score_result[score_result['ニュースNo.'] == i]
text = ''.join(list(temp_df['単語']))
score = temp_df['スコア'].astype(float).sum()
#スコアをスコアが付与されている単語数で割った値を算出
score_r = score/temp_df['スコア'].astype(float).count()
result.append([i, text, score,score_r])
pd.DataFrame(result, columns = ['ニュースNo.', 'テキスト', '累計スコア', '標準化スコア']).sort_values(by = '標準化スコア').reset_index(drop = True)
出力はこのような感じになります。

それではスコア上位の記事(ポジティブな記事)とスコア下位の記事(ネガティブな記事)を比べてみましょう。
ポジティブな記事
今シーズンは、最多勝、最優秀防御率、最多奪三振と22歳の史上最年少で投手三冠を達成し、
沢村賞を獲得した広島東洋カープ・前田健太が、17日深夜放送のフジテレビ「すぽると!」に生出演を果たした。
契約更改には、「そうですね。楽しみですね。いい成績だったので、気持ちよく一発でいきたいなと思います」と笑顔を見せた前田。
「あんまり自分では実感がなくて、周りの人が喜んでくれて、やっと実感できるかな」と今シーズンの活躍を振り返った。
また、大きく成績を向上させた要因については、「ピッチングのレベルも上がったんですけど、(昨シーズンの)14敗も本当に悔しかったし、何か変えたいなと思って。
あと、ストレートが今年よくなったので、勝てるようになりました」と語る。
そのストレートについては、「投げるコツみたいなものを掴んで、はやい球を投げれるようになって、投球に幅が出るようになりました。投げ方のコツですね。
(3回目の先発でコツを掴んだと言われているが?)本当にその試合の一球だけで掴みました」と断言するのだった。
ネガティブな記事
現在、日本中に大きな驚きと怒りをもたらしてる大相撲の野球賭博問題。
旧態依然とした体質に加え、暴力団との繋がりも根が深く、4日、大関・琴光喜と大嶽親方には解雇処分が下された。
TBS系「サンデー・ジャポン」(4日放送)では、テリー伊藤が本問題について言及、
「博打ってこの程度の罪で済むのかと素人の人が思ってしまうのが危険」と警笛を鳴らすと、
「本来ならば相撲協会がNHKに今回の名古屋場所は放送しないで下さいと言わなくてはいけないし、
協会が体制を維持しようとする姿勢に違和感を感じる」と苦言を呈したばかりだった。
そんな言葉を象徴するかのように、琴光喜は最も重い処分=除名ではないため、退職金が支給され、5日には一部のメディアが「満額なら5500万円」と伝えている。
どこまでも、ぬるま湯体質が抜けきらず、進歩のない角界には、今度も多くの批判が寄せられそうだ。
ポジティブな記事は前田健太が沢村賞を取ったという記事、ネガティブな記事は大相撲の野球賭博問題の記事です。こう見るとなんとなく一定レベルでは判定できているのかなという気がします。ただ、もとの極性辞書自体がマイナスの値を付与されている単語の方が多く、今回最も高いスコアがついた記事の標準化スコアも-0.146246とマイナス判定でした。実際の判定に用いるためには閾値の検討が必要だなと感じました。
Next
今回感情分析を行うに当たって極性辞書を探したのですが殆ど公開されているものはなく、この記事で記載した2つくらいでした。また、商用利用できるものに限ると日本語評価極性辞書くらいしかありませんでした。実際何かの目的に沿った分析を行うためには、それに合致した極性辞書の自作が必要な感じがします。極性辞書を自作するメソッドがあるならばそれも勉強できればよいなと考えています。またその他の色々な文章に対しても感情分析をやっていきたいです。