Courseraの機械学習コースの6週目です。
「様々なアドバイス」と副題をつけましたが、データ分割と交差検証、バイアスとバリアンス、不均衡データと分類評価、大量データの有効性などについて学びます。アルゴリズムそのものの学習というより機械学習を使って設計・実装・検証していく上での注意点といったことろです。数学的な難解さはありません。
記事「Coursera機械学習入門オンライン講座虎の巻(文系社会人にオススメ)」を最初に読むことをお勧めします。
サマリ
実績時間:約5.5時間
目安時間:約6時間(正確には6時間2分)
※コースに各章の時間目安が書かれていて、それを足しただけです。
一覧
| No. | 章 | 目安時間 | 内容 |
|---|---|---|---|
| 1 | Advice for Applying Machine Learning | 278分 | 機械学習のモデル検討時のアドバイス |
| 1.1 | Evaluating a Learning Algorithm | 31分 | モデルを評価するためのデータ分割方法 |
| 1.2 | Bias vs. Variance | 47分 | バイアスとバリアンス |
| 1.3 | Review | 200分 | ここまでのクイズとプログラム演習 |
| 2 | Machine Learning System Design | 84分 | 機械学習システムの設計 |
| 2.1 | Building a Spam Classifier | 28分 | スパム分類を例にした機械学習実装の注意点 |
| 2.2 | Handling Skewed Data | 25分 | 不均衡データ分類への対応として評価指標の考え方 |
| 2.3 | Using Large Data Sets | 11分 | 大量データを扱った場合のメリットと注意点 |
| 2.4 | Review | 20分 | 2章のクイズ(演習なし) |
1. Advice for Applying Machine Learning
1.1. Evaluating a Learning Algorithm
1.1.1. Deciding What to Try Next
Video:5分
機械学習でモデルを作って結果が芳しくない場合にどうするか。
対応方法として下記のスライドで書いてあるように訓練データス数を増やすなど。

1.1.2. Evaluating a Hypothesis
Video:7分, Reading:4分
データ分割とテストデータに対する評価方法についてです。
過学習を考慮して、データ全体を訓練データとテストデータに分割します。一般的には訓練データを全体の70%、テストデータを30%にするそうです(最近は訓練データをもっと多くする傾向があるような気がします)。
テストセットに対する評価として、コスト関数は以下の通りです。
- 線形回帰のコスト関数(訓練時と変わらず)
J_{test}(\Theta) = \dfrac{1}{2m_{test}} \sum_{i=1}^{m_{test}}(h_\Theta(x^{(i)}_{test}) - y^{(i)}_{test})^2
- 分類のコスト関数(訓練時よりシンプルで、0/1で誤差を積み上げていきます)
err(h_\Theta(x),y) = \begin{matrix} 1 & \mbox{if } h_\Theta(x) \geq 0.5\ and\ y = 0\ or\ h_\Theta(x) < 0.5\ and\ y = 1\newline 0 & \mbox otherwise \end{matrix} \\
\text{Test Error} = \dfrac{1}{m_{test}} \sum^{m_{test}}_{i=1} err(h_\Theta(x^{(i)}_{test}), y^{(i)}_{test})
1.1.3. Model Selection and Train/Validation/Test Sets
Video:12分, Reading:3分
今度はデータ全体を訓練・交差検証(Cross Validation)・テストに分ける方法です。一般的に訓練=60%, 交差検証(Cross Validation)=20%, テスト=20%のデータ量で分割します。
この場合、交差検証(Cross Validation)データセットに対して、訓練時にパラメータを最適化し、最終評価をテストデータセットに対して行います。
訓練とテストの2分割の場合、テストデータセットでの評価をして最適なモデルを選択します。その場合、未知のデータに対してモデル精度がよくなく過学習となってしまうことがあります。なので、3種類に分割をして訓練時の評価にも使っていないテストデータセットに対して最終評価を下します。
※わかりなくいですが、交差検証(Cross Validation)データを使ってモデルを生成しているわけではなく、交差検証(Cross Validation)データはモデル生成後の評価に使用しています。
1.2. Bias vs. Variance
1.2.1. Diagnosing Bias vs. Variance
Video:7分, Reading:3分
バイアスとバリアンスについて。
予測精度が悪い場合、バイアスとバリアンスのどちらが原因かを特定します。バイアスが高いと未学習(Underfitting)で、バリアンスが高いと過学習(Overfitting)です。その両者の中間を探す必要があります。下図がそのサマリです。
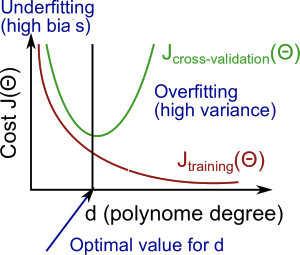
1.2.2. Regularization and Bias/Variance
Video:11分, Reading:3分
正則化(Regularization)とバイアス・バリアンスについて。
正則化のパラメータである$\lambda$の大きさと学習状態について図で示しています。
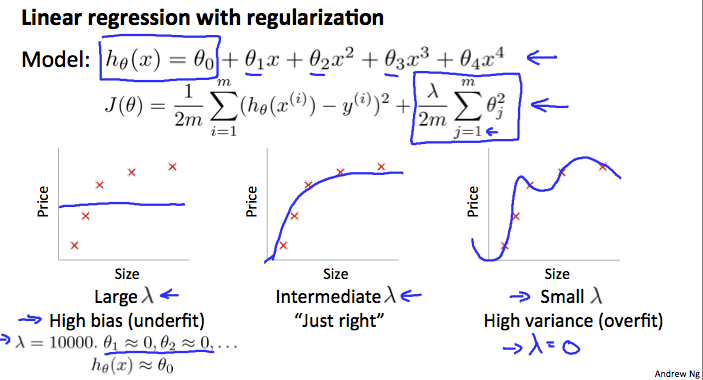
$\lambda$の値を最適にしたモデルを探索するために以下の手順を踏みます。
- 値が異なる$\lambda$の一覧を作成
- 複数モデルを作成
- 全モデルに対して$\lambda$ をすべて試し、最適なパラメータ $\theta$を学習する
- 学習したパラメータ$\theta$と$\lambda$を使ってクロスバリデーション(交差検証)誤差($J_{CV}(\theta)$)を計算
- クロスバリデーション(交差検証)誤差が最も低くなっった組み合わせを選択
- テストセットに対しての誤差を計算し、未知のデータに対応できるかを確認
1.2.3. Learning Curves
Video:11分, Reading:3分
データ数と誤差の学習曲線についてです。
ハイバイアス(High Bias)の状態 -> 誤差が大きくてもデータ数を増やすことは解決策にならない
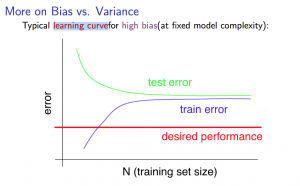
ハイバリアンス(High Variance)の状態 -> 誤差が大きい場合にデータ数を増やすことは解決策になりえる
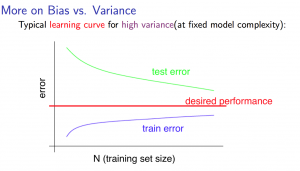
1.2.4. Deciding What to Do Next Revisited
Video:6分, Reading:3分
ハイバイアス(High Bias)とハイバリアンス(High Variance)のどちらの場合にどんな手段が精度向上に有効か。
| 手段 | 有効な状況 |
|---|---|
| データ数を増やす | ハイバリアンス(High Variance) |
| 特徴量を減らす | ハイバリアンス(High Variance) |
| 特徴量を増やす | ハイバイアス(High Bias) |
| 多項変数($x_1^2, x_2^2, x_1x_2$など)を増やす | ハイバイアス(High Bias) |
| $\lambda$の値を減らす | ハイバイアス(High Bias) |
| $\lambda$の値を増やす | ハイバリアンス(High Variance) |
ニューラルネットワークについて。
パラメータが少ないと未学習(Underfitting)しやすく、多いと過学習(Overfitting)しやすい。隠れ層を1つから始めていくことが推奨らしい。
1.3. Review
1.3.1. Lecture Slides
Reading:10分
ここまでのスライドPDF。
1.3.2. Advice for Applying Machine Learning
Quiz:5問, Reading:10分
難しくないです。ですが、ケアレスミスで80%でした・・・
1.3.3. Regularized Linear Regression and Bias/Variance
Programming Assignment:180分
正則化された線形回帰および多項式回帰を使ったハイバイアスとハイバリアンスの確認のプログラム演習です。いつも通り、GitHubでカンニングしたので、40分程度で終わらせています。
2. Machine Learning System Design
2.1. Building a Spam Classifier
2.1.1. Prioritizing What to Work On
Video:9分, Reading:3分
機械学習を使ったシステムの例としてスパムメール分類の説明です。
簡単にスパムメール分類をする機械学習アルゴリズムの一例を紹介しています。そして、精度向上させるために以下のアプローチがあるらしいです。
- 大量データを集める
- 洗練された特徴を開発する
- 入力データを複数の方法で処理するアルゴリズムの開発
2.1.2. Error Analysis
Video:13分, Reading:3分
エラー分析についてです。
以下が機械学習の課題に対する推奨アプローチらしいです。
- シンプルなアルゴリズムを素早く実装し、クロスバリデーションデータに対してテストする
- 学習曲線を出力して、何が(多くのデータ、特徴量など)必要かを判断する
- 手でエラーとなった例を確認してエラーに対する傾向を確認する
エラーを確認するためにひとつの指標に統一することが大事。
またQuick and Dirtyで実装・確認することが大事。
2.2. Handling Skewed Data
不均衡データに対する注意点です。
評価指標に関して、私が以前投稿した記事「【入門者向け】機械学習の分類問題評価指標解説(正解率・適合率・再現率など)」に詳しく書いています。
2.2.1. Error Metrics for Skewed Classes
Video:11分
不均衡データに対する注意点と分類問題における評価指標についてです。
不均衡データ(Skewed data)を扱う場合、正答率(Accuracy)や類似の評価指標に対する注意が必要です。例えば、がんの陽性・陰性を分類する場合、がんの陰性データが全体の99.5%だった場合、すべてを陰性と予測すればそれだけで正答率が99.5%になってしまうからです。
分類指標として適合率(Precision)と再現率(Recall)についても混合行列を通じて学習します。
2.2.2. Trading Off Precision and Recall
Video:14分
適合率(Precision)と再現率(Recall)の関係と平均について。
適合率(Precision)と再現率(Recall)はトレードオフの関係で一方を高くするともう一方が低くなります。また、両者を統合した指標は、F値(F Score)という調和平均(相加平均ではない)を使います。
※調和平均は$2\frac{Presicion \times Recall}{ Presicion + Recall }$で相加平均は$\frac{ Presicion + Recall }{2}$です。
2.3. Using Large Data Sets
2.3.1. Data For Machine Learning
Video:11分
大量データを扱った場合のメリットと注意点について。
もしデータの中に予測に必要な情報を含んでいるのであれば大量データは精度向上にとって大きく貢献します。
複数のアルゴリズムで機械学習モデルを作った場合、アルゴリズムの優越よりもデータ量の多さが重要になる場合もあった例を示しています。

2.4. Review
2.4.1. Lecture Slides
Reading:10分
2章「Machine Learning System Design」のスライドPDF。
2.4.2. Machine Learning System Design
Quiz:5問, Reading:10分
久々に100%で一発合格。簡単でした。
感想
前章「Coursera機械学習入門コース(5週目 - ニューラルネットワークと誤差逆伝播法)」に比べると複雑な数式もなく難易度は下がります。小休止のようなものをつくってくれているのでしょうか。しかし、内容は非常に重要で例えば混合行列や分類評価指標などは基本であり実務上役に立ちます。
事前に知っている内容も多かったため、短時間で終わらせることができました。
関連記事
私より詳しくまとめてくれています。
他の週のリンクです。
- Coursera機械学習入門コース(1週目 - 線形回帰と線形代数)
- Coursera機械学習入門コース(2週目 - 重回帰、多項式回帰、正規方程式)
- Coursera機械学習入門コース(3週目 - ロジスティック回帰、正則化)
- Coursera機械学習入門コース(4週目 - ニューラルネットワーク)
- Coursera機械学習入門コース(5週目 - ニューラルネットワークと誤差逆伝播法)
- Coursera機械学習入門コース(6週目 - 様々なアドバイス) <- 本記事
- Coursera機械学習入門コース(7週目 - SVM)
- Coursera機械学習入門コース(8週目 - 教師なし学習(K-MeansとPCA))
- Coursera機械学習入門コース(9週目 - 異常検知、レコメンデーション)
- Coursera機械学習入門コース(10週目 - ビッグデータ対応)
- Coursera機械学習入門コース(11週目 - 写真OCR)