Courseraの機械学習コースの11週目です。最終週ということで、写真OCRでの実例です。実例を通じて機械学習のパイプライン処理と天井分析について学びます。
記事「Coursera機械学習入門オンライン講座虎の巻(文系社会人にオススメ)」を最初に読むことをお勧めします。
サマリ
実績時間:約2.5時間
目安時間:約1時間(正確には1時間14分)
※コースに各章の時間目安が書かれていて、それを足しただけです。
一覧
| No. | 章 | 目安時間 | 内容 |
|---|---|---|---|
| 1.1 | Photo OCR | 50分 | 写真OCR |
| 1.2 | Review | 20分 | スライドPDFとクイズ |
| 1.3 | Conclusion | 4分 | 全講義の総括 |
講義内容
1. Application Example: Photo OCR
1.1. Photo OCR
1.1.1. Problem Description and Pipeline
Video:7分
Photo OCRと機械学習パイプライン。
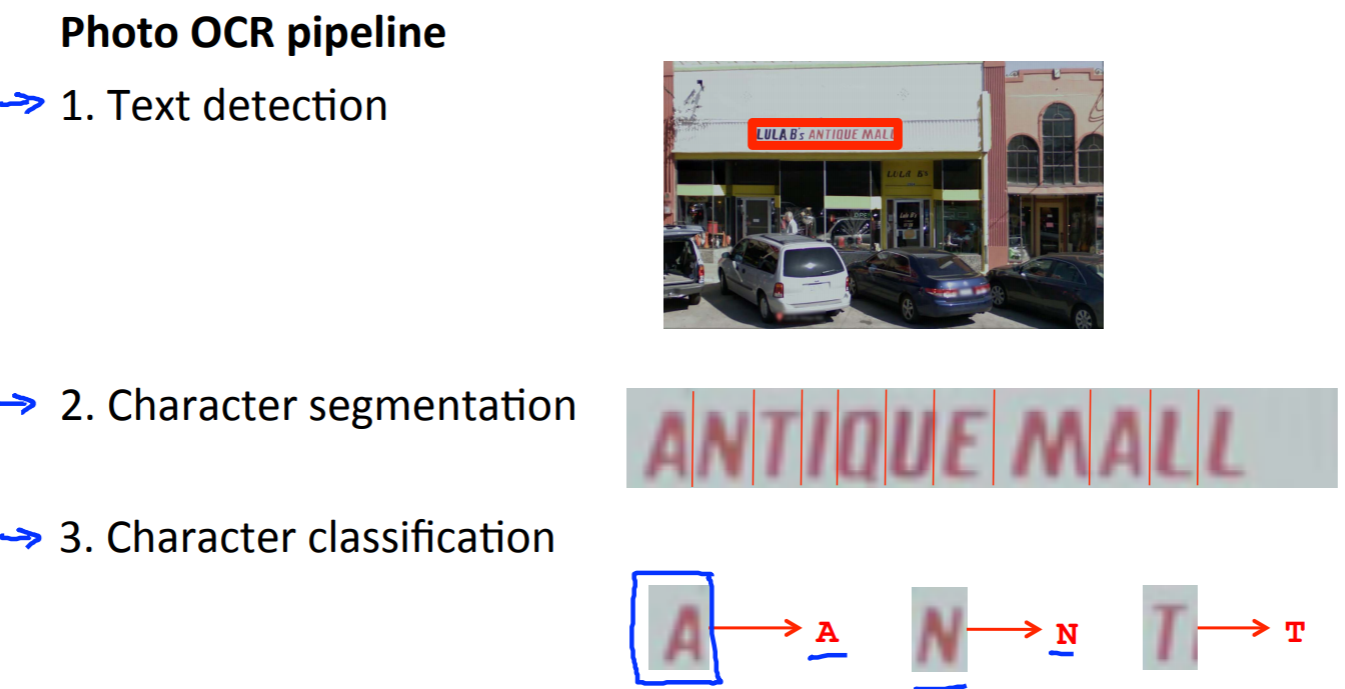
Photo OCRは、以下の3ステップに分けることができる。
※最後に誤字修正を含むことがあるが今回は割愛(例: C1earing -> Cliearing)
- テキスト検知
- 文字のセグメンテーション
- 文字分類

このように機能分割された処理群をパイプラインと呼びます。
パイプラインの各機能ごとに異なるエンジニアが担当することも多いです。
1.1.2. Sliding Windows
Video:14分
スライディングウィンドウ(Sliding Windows)。
OCRのパイプラインの最初は「1. テキスト検知」で、そこではスライディングウィンドウという方法を使います。
以下の例では歩行者検知で、82×36サイズの矩形ウィンドウを少しずつスライドさせていき、分類器を使って歩行者かどうかを判定していきます。スライドする幅をStep-sizeやStrideと呼びます。

OCRでは画像内からテキストを見つけると白で塗りつぶし、「膨張」処理を行います。そして、アスペクト比が文字らしく箇所は除外します。ここまでの処理がスライディングウィンドウです。
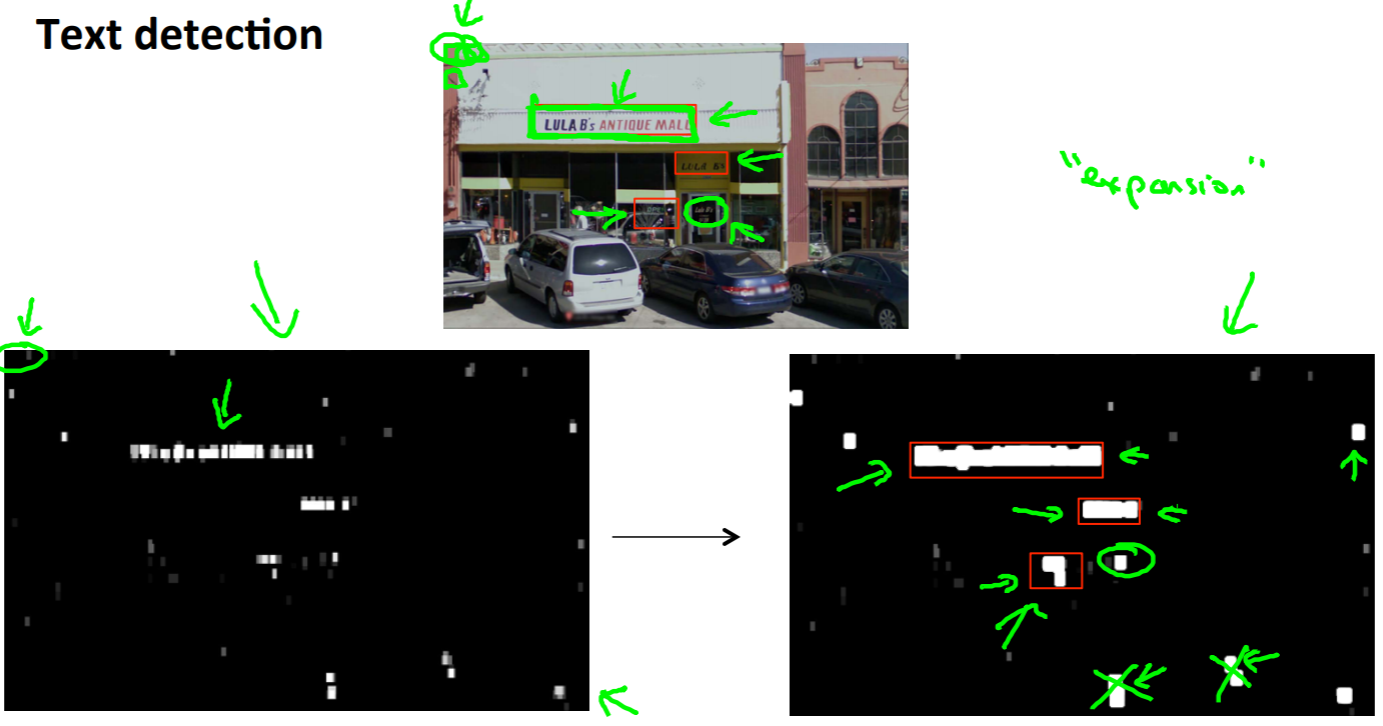
その後に「2. 文字のセグメンテーション」をします。真ん中で文字を2つに分けたい場合を陽性として分類をします。この分類器により個々の文字を分割します。

そして、最後が文字分類です。以上がOCRのパイプラインでした。
1.1.3. Getting Lots of Data and Artificial Data
Video:16分
大量データの取得とデータ合成。
精度の高い機械学習モデルを作るためにデータは多いほうがいいです。大量データを得るために以下の2つの方法があります。
- 人工的にデータ生成
- 少量データからデータ水増し(Data Augmentation)
OCRの例で「1. 人工的にデータ生成」は様々なフォントの文字といろいろな背景を組み合わせることです。「2. 少量データからデータ水増し(Data Augmentation)」は画像を歪ませたりして水増しすることです。
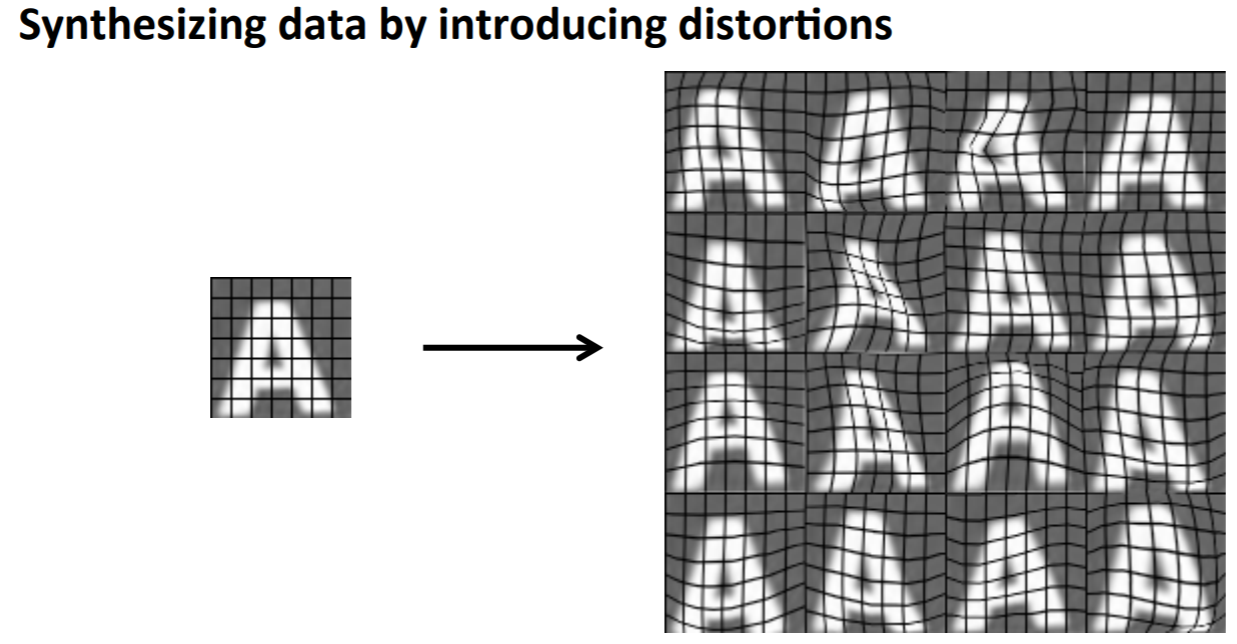
ただ、ランダムなノイズでは意味がない場合もあり注意が必要です。下図の例では画像に輝度をランダムにノイズとして加えることは意味がないらしいです。ただ、時にはうまくいくこともあるらしく、試してみることが重要らしいです。

いずれにせよ、データを増やす前に低バイアス状態であることを確認することが重要です。そして、データを増やすコストがどれだけかかるかを確認することも重要です。データを増やすために、クラウドソーシング(Amazon Mechanical Turk)のようなサービスを使うことも選択肢としてあります。
1.1.4. Ceiling Analysis: What Part of the Pipeline to Work on Next
Video:13分
天井分析(Ceiling Analysis)について。
天井分析で機械処理パイプラインのどこを改善すると全体のパフォーマンスに対して最も効果があるのかを分析します。パフォーマンス向上の上限(天井)がわかることから天井分析と呼ばれています。
下図のOCRの例では、全体の正答率が72%だったとします。そして、もし「1. テキスト検知」が100%正しかった場合に全体の正答率が何%になるかを出します。ここでは、89%と17%向上します。そしてさらに「2. 文字セグメーンテーション」が仮に100%正しかった場合、全体の正答率が何%になるかを出します。
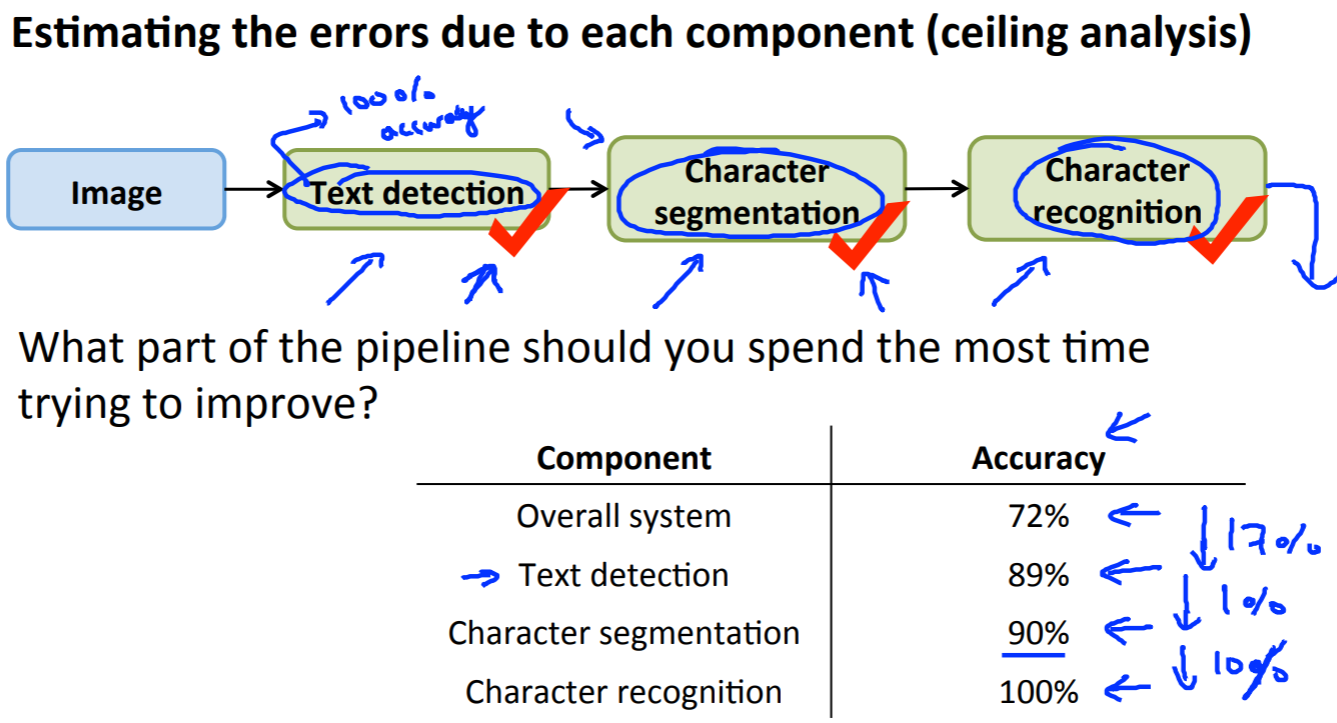
このように仮定の値を算出して、どこに注力するのが最も効果的かを判断します。
機械学習の問題を見た時に、直感がこう言う事がある: このコンポーネントにもっと時間を注ぎ込んだらいいんじゃないか。だが何年もかかって、 自分自身の直感すら信じてはいけない、むしろ自分の直感をそれほどは信じない、という事を学習した。
講義の中で上記のように解説しています。経験豊かなエキスパートでさえ直感を信じずに、天井分析のような体系だった手法を使うらしいです。
1.2. Review
1.2.1. Lecture Slides
Reading:10分
スライドPDF。
1.2.2. Application: Photo OCR
Reading:10分
数式もなく簡単でした(四則演算程度の計算問題はあり)。一発で100%合格。
1.3. Conclusion
1.3.1. Summary and Thank You
Video:4分
全講義の総括と先生からのお礼。
総括としては以下のスライドがまとまっています。

感想
最終週は数式など難しい点がないため、パイプライン処理や天井分析については、容易に理解ができました。プログラミング演習もないため、相対的に少ない時間で終わらせています。
関連記事
私より詳しくまとめてくれています。
他の週のリンクです。
- Coursera機械学習入門コース(1週目 - 線形回帰と線形代数)
- Coursera機械学習入門コース(2週目 - 重回帰、多項式回帰、正規方程式)
- Coursera機械学習入門コース(3週目 - ロジスティック回帰、正則化)
- Coursera機械学習入門コース(4週目 - ニューラルネットワーク)
- Coursera機械学習入門コース(5週目 - ニューラルネットワークと誤差逆伝播法)
- Coursera機械学習入門コース(6週目 - 様々なアドバイス)
- Coursera機械学習入門コース(7週目 - SVM)
- Coursera機械学習入門コース(8週目 - 教師なし学習(K-MeansとPCA))
- Coursera機械学習入門コース(9週目 - 異常検知、レコメンデーション)
- Coursera機械学習入門コース(10週目 - ビッグデータ対応)
- Coursera機械学習入門コース(11週目 - 写真OCR) <- 本記事