はじめに
KDDI エンジニア&デザイナー Advent Calendar 2025 で、1日目の記事を担当します豊田陽介(@youtoy)です。
「エンジニア・デザイナーでなくても(社内の担務によらず)参加OK、仕事絡みの話でなくても可」という自社のアドベントカレンダーに、また今年も記事を書いてみます。
(ちなみに、「普段の Qiita の記事も、仕事絡みの話でなくても可」ということで、Qiita では自分が個人でやっている様々な技術系の内容の「ガジェット・モノづくり・Web・ローカルLLM・生成AI や、その他いろいろ」について記事を書いています)
今回の記事の内容
今回、個人で買って普段使っている、3種の PC とローカルLLM という話に関して記事を書いてみます。ちなみに、かなり雑多な感じの内容になりました。
ローカルLLM に用いている PC(概要)
今回の記事で登場する、ローカルLLM を試している 3種の個人所有の PCは以下があります。
ざっくりと、種類・スペックなどの一部を以下に書いてみます。
- ミニPC「GMKtec EVO-X2」
- Ryzen AI Max+ 395
- メモリ 128GB
- MacBook Air(13インチ、2025)
- Apple M4チップ
- 16GB ユニファイドメモリ
- Mac mini(2024)
- Apple M4チップ
- 24GB ユニファイドメモリ
これら 3種の PC は、ローカルLLM に関して個人的に便利だと思う特徴を備えています(詳細はこの後に)。
この後の話
今回の記事は、ローカルLLM の話題を扱っています。
これまでローカルLLM に関する記事は、既にちょっとした記事をたくさん書いている状況でもあり、この記事では全体のざっくりなところ(+ 自分が試した内容をベースに、雑多な感じの内容)を書いています。
個人的には、それらのたくさん書いた記事にばらけているローカルLLM関連の情報を、(一部だけですが)集約する感じでまとめたい、というモチベーションもあって書いた内容です。
各PC とローカルLLM で利用可能なモデル
まずは、ローカルLLM で 1つ重要なポイントになる「利用可能なモデルのサイズ」という話を書いてみます。
各PC で利用可能なモデルのサイズ
各PC で利用可能なローカルLLM用のモデルのサイズは、今回の 3台は、搭載しているメモリのサイズがダイレクトに効いてくるものになります。
Apple Silicon搭載の Mac の場合
それについて少し補足すると、Apple Silicon搭載の Mac では、ユニファイドメモリによって CPU と GPU などがメモリを共有する仕組みになっています。
自分が持っている MacBook Air(16GB ユニファイドメモリ)と Mac mini(24GB ユニファイドメモリ)では、とある実行環境(自分が過去に試したもので、例えば MLX LM や MLX-VLM)では、デフォルトの状態で OS用に約8GB のメモリが使われ、残りをローカルLLM用に活用可能になったりします。
ちなみに、GUI搭載の実行環境では、設定画面でこの情報を簡単に確認できたりもします。
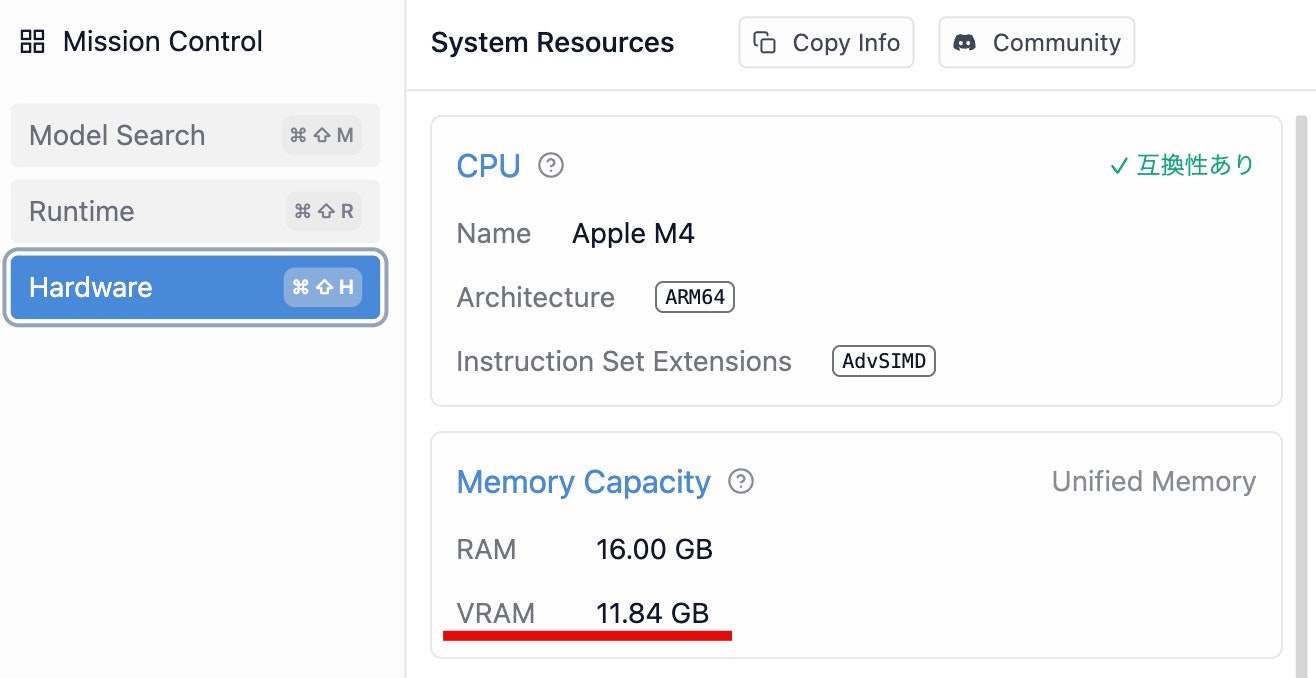
例えば「LM Studio」を用いた場合、ローカルLLM のモデル用に割り当て可能な VRAM がデフォルトで以下のようになります(デフォルト設定で、VRAM に 11.84GB利用可能、という感じです ← 上で書いていた 8GBほど、というものより多く利用できる状態になるようです)。
Ryzen AI Max+ 395搭載の EVO-X2 の場合
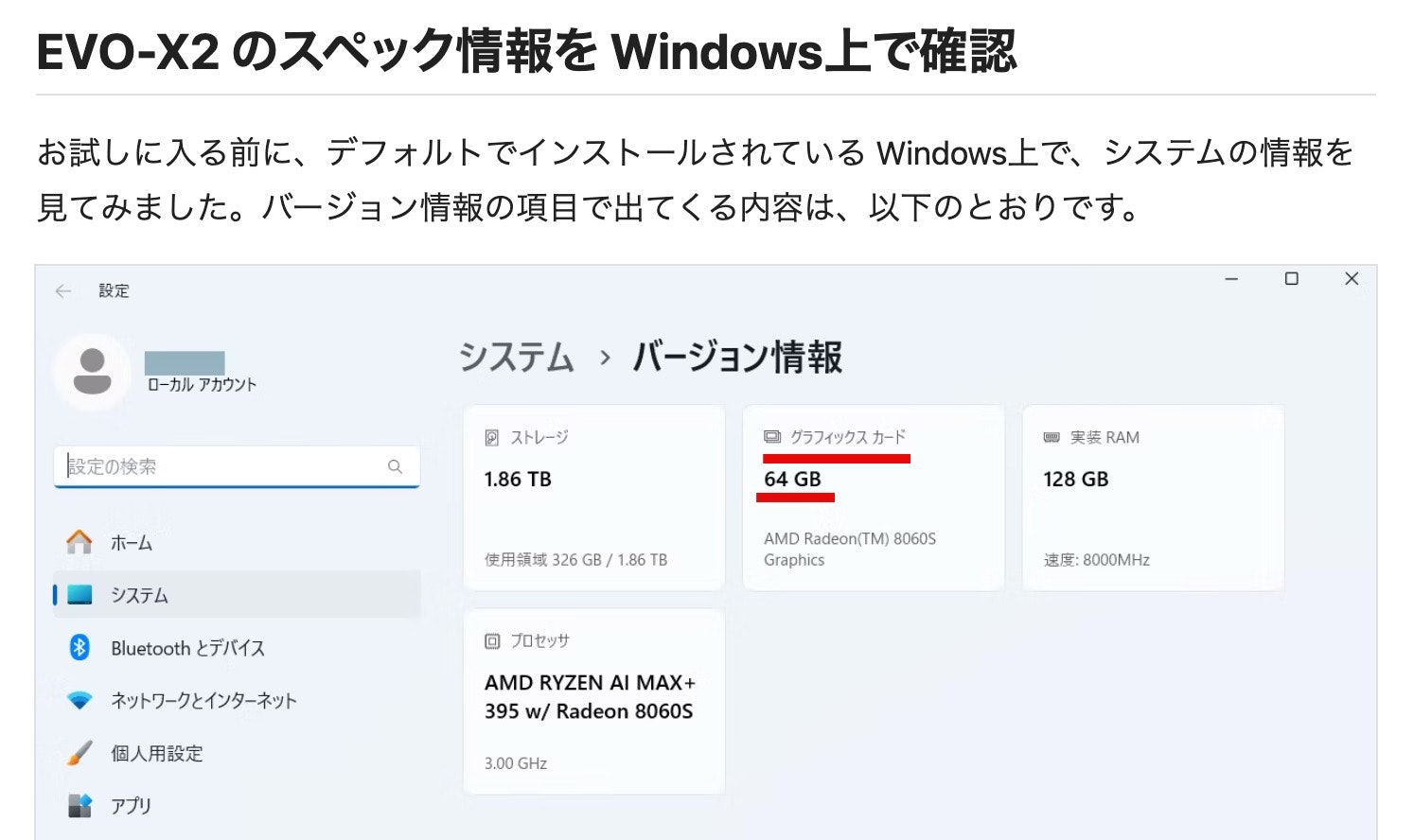
また、Ryzen AI Max+ 395 を搭載したミニPC「GMKtec EVO-X2」も、メモリ 128GB を上記と似た感じで共用という形で VRAM に利用可能です。こちらは、デフォルト設定で 64GB が VRAM用に割り当てられる設定になっているようでした。
このデフォルト設定を変えて、もっと VRAM用に割り当てても問題ないようで、96GB の割り当てに増やす、というのはよく行われています。
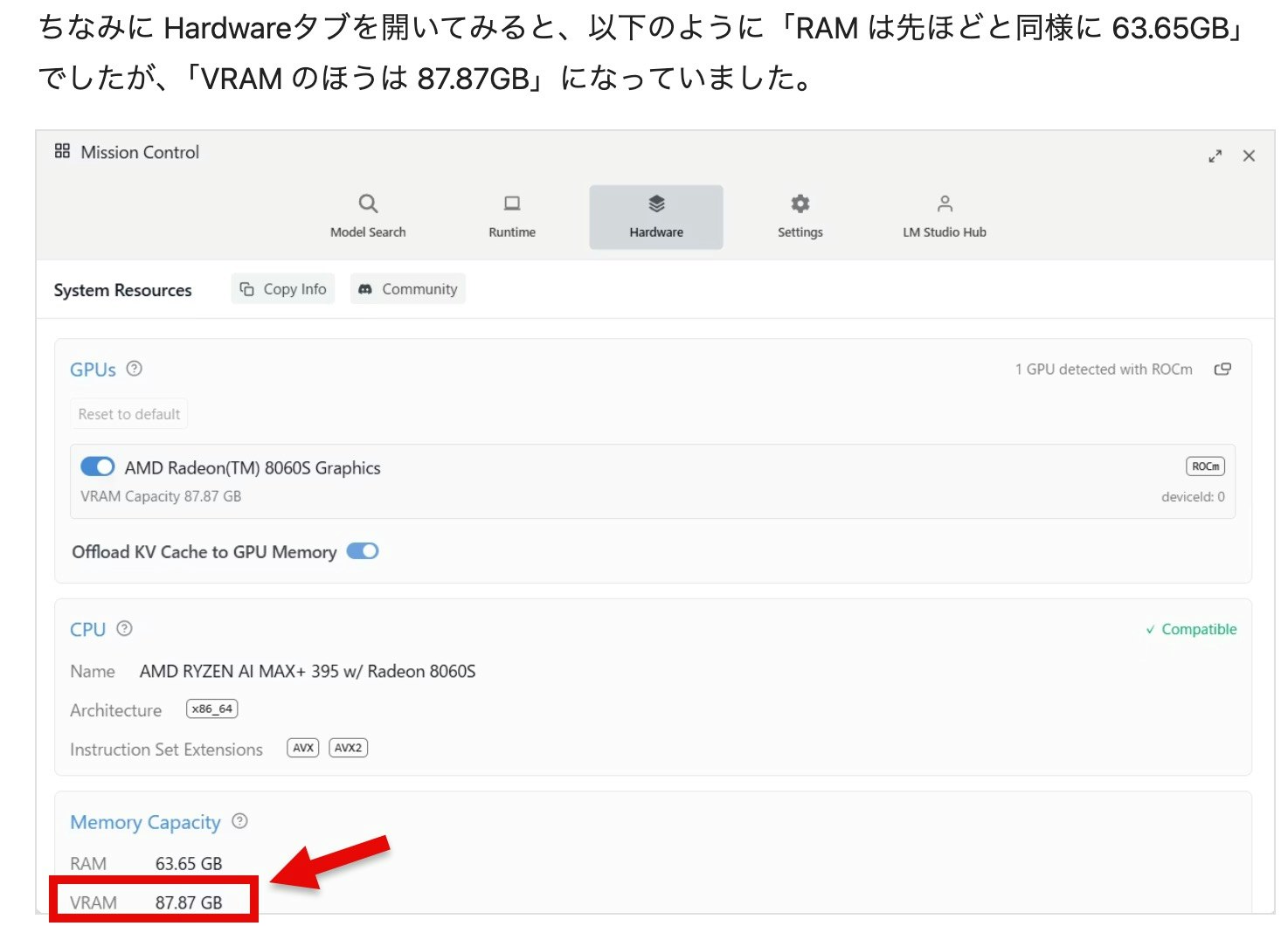
それと自分が試した中では、LM Studio・EVO-X2 をどちらもデフォルトのままで使って、なおかつ、ランタイムを「ROCm llama.cpp」に変えた場合は VRAM への割り当て可能なサイズが OS で出ているサイズよりも大きくなっているようでした(これについて、どうしてこのようになるのかを、きちんと調べてないのですが...)。
●ミニPC「GMKtec EVO-X2」でローカルLLM: LM Studio で ROCm llama.cpp(Windows)+ gpt-oss-120b を利用【Ryzen AI Max+ 395・メモリ128GB搭載の PC】 - Qiita
https://qiita.com/youtoy/items/b6b376cae88b11e11100
別途、このあたりは詳細を調べてみようと思っています。
ローカルLLM用のモデルのサイズ
上で書いたように、それぞれの PC でローカルLLM用に利用可能な VRAM のサイズが異なります。それに合わせてローカルLLM用のモデルがおさまるようにモデル選定を行う場合、おおまかには以下の記事に書かれたような計算で、必要な VRAM のサイズが分かるようです。
●ローカル環境でLLMを動かすには?必要メモリを簡単計算!
https://zenn.dev/chro96/articles/04efc3803d3882
モデル自体のサイズは、自分の場合は Hugging Face や LM Studio・Ollama のサイトなどに掲載された情報を見て確認しています。
(Hugging Face だと各モデルの Files and versions のページ、LM Studio は Model Catalog、Ollama は library のページなどです)
それで、サイズ的に動きそうなものをあれこれ試しています(ぎりぎり動かなそうなサイズ感のものも「とりあえず試してみる」ということをやってみたりもしつつ)。
gpt-oss-20b での例
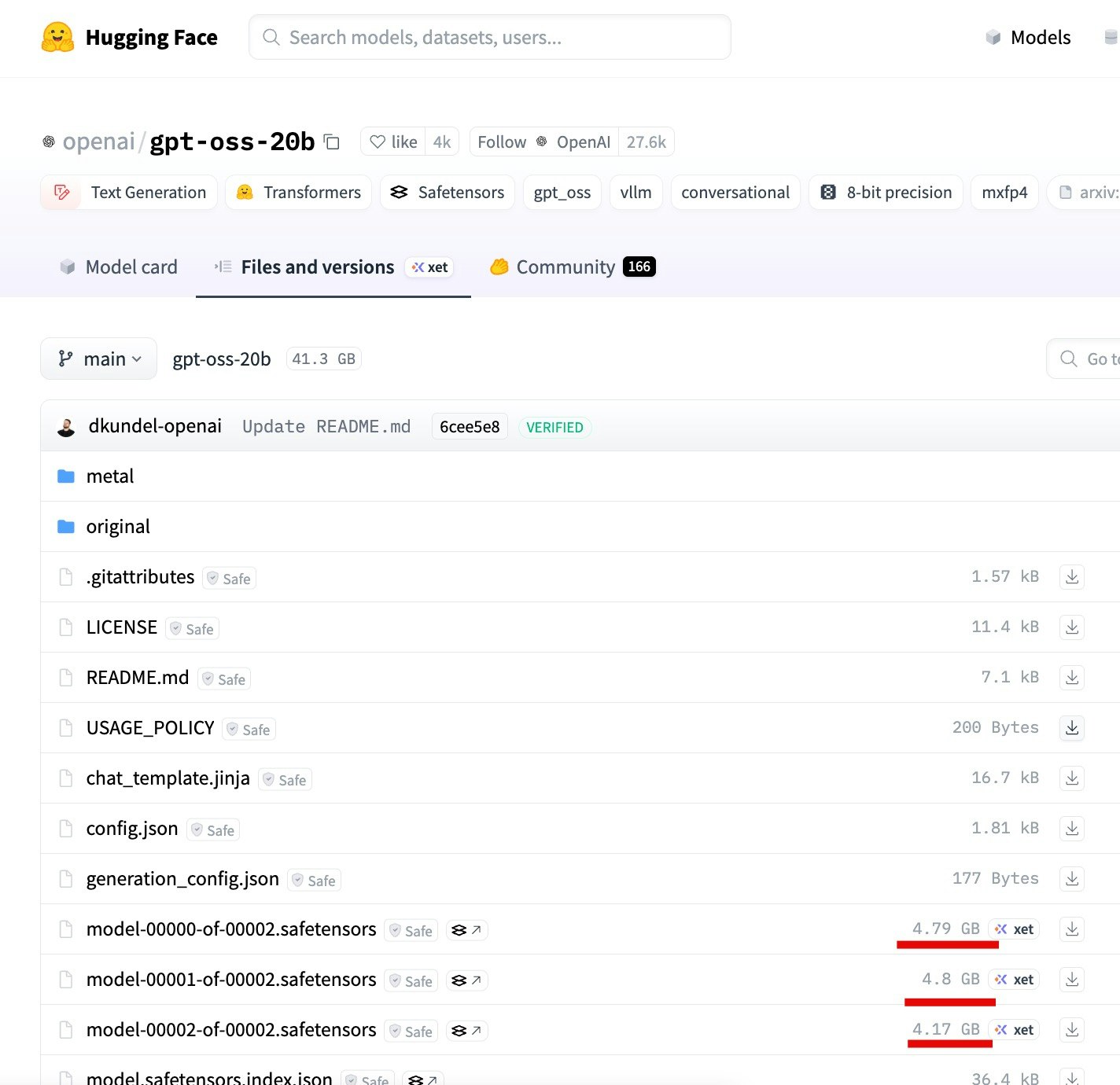
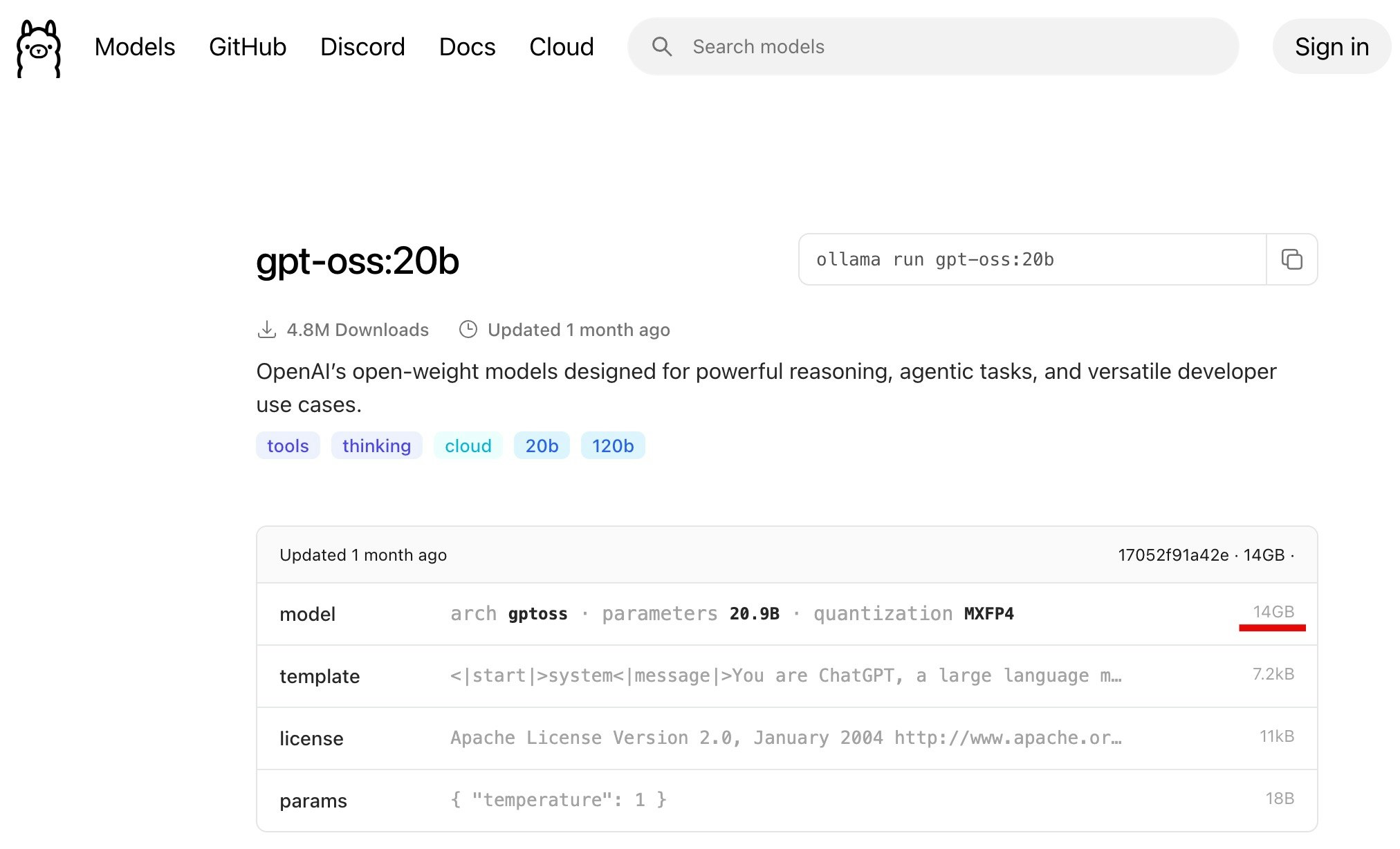
モデルのサイズを Webサイト上で確認できるという内容について、gpt-oss-20b を例にして見てみます。
●openai/gpt-oss-20b at main
https://huggingface.co/openai/gpt-oss-20b/tree/main
※ 以下の合計値
●gpt-oss:20b
https://ollama.com/library/gpt-oss:20b
●gpt-oss
https://lmstudio.ai/models/gpt-oss
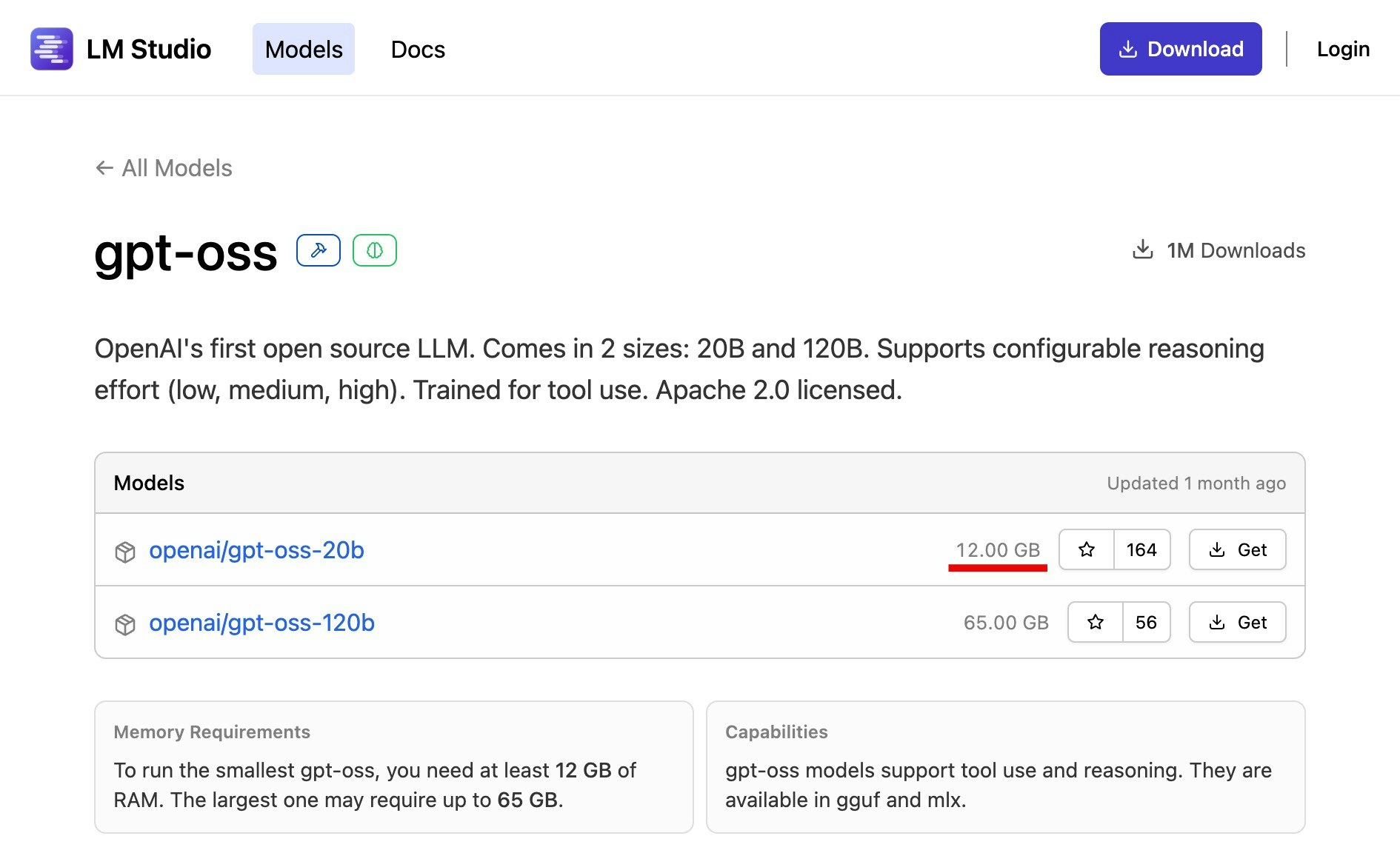
あと LM Studio の場合だと、アプリ上からモデルを検索する仕組みがあるのですが、そこでも上記のサイト上に出ているような情報を確認可能です。
ローカルLLM を API で扱う
API経由ではなく GUI・コマンドでの利用
上で書いていた実行環境でローカルLLM を使う場合、インターフェースの部分は LM Studio・Ollama は以下のような GUI でも扱えます。
また、MLX LM や MLX-VLM はコマンドベースで使う形になります。
それ以外に、自分が書いたコードで扱いたい場合などは、API でも扱うことができます。
API で扱う
API を使ったローカルLLM について、試した内容をいろいろ記事に書いたものがあります。その一部を以下に列挙してみます。
- LM Studio のサーバーに対してローカルネットワーク上の別PC から API でアクセス(ローカルネットワーク内でローカルLLM)【Node.js + Vercel AI SDK】 - Qiita
- ミニPC「GMKtec EVO-X2」でローカルLLM: LM Studio の OpenAI互換のAPI + gpt-oss-120b を利用【Node.js】 - Qiita
- LM Studio の Python SDK「lmstudio-python」でローカルLLM の軽いお試し(M4 MacBook Air を利用) - Qiita
- LM Studio の TypeScript SDK「lmstudio-js」でローカルLLM の軽いお試し(M4 MacBook Air を利用)【Node.js】 - Qiita
- ベータ版機能「LM Studio REST API」を使ってみる(curl でのお試し): M4 MacBook Air でのローカルLLM - Qiita
- M4 の Mac mini で ローカルLLM: Ollama v0.8 の新機能(ストリーミング + ツール)を試す - Qiita
- Mac mini で ローカルLLM: Ollama で「REST API」とライブラリ「ollama-js」を試す(モデルは Gemma 3) - Qiita
ローカルLLM と API の話(過去に書いた記事の情報をベースにしたもの)
上の記事では、以下の内容を扱っています。
- OpenAI互換の API
- 独自の仕様の API
- 独自仕様の REST API
- 公式SDK(Javascript/TypeScript、Python)
- 独自仕様の REST API
OpenAI互換の API を使うパターンだと、OpenAI公式の SDK・ライブラリで API を直接扱えたりします。また、AIエージェント開発用の SDK・ライブラリで、API経由でローカルLLM を簡単に扱えるようにしているものもあります。
それに関連して、以下は Vercel の AI SDK のページで、LM Studio + OpenAI互換API を使う場合のプロバイダーについて書かれたページです。
●OpenAI Compatible Providers: LM Studio
https://ai-sdk.dev/providers/openai-compatible-providers/lmstudio
以下の npmパッケージを使う形のものですが、OpenAI互換の API を広く扱えるものになります。
●@ai-sdk/openai-compatible - npm
https://www.npmjs.com/package/%40ai-sdk/openai-compatible
ローカルLLM を API経由で扱う際、HTTPリクエストを直接扱う形でも使えますが、上記のような仕組みなどもあるので SDK・ライブラリと組み合わせて使うと色々便利です。
ローカルLLM で試したモデル
最後に、過去のローカルLLM に関する記事で扱ったことのあるモデルを書いていこうとしたのですが、わりと大量にあったので(※ ちょこちょこ試してみては、ちょっとしたメモ的な記事を高頻度に書いていたため)、過去5ヶ月以内で記事を書いたものだけをピックアップして紹介してみます。
- gpt-oss-120b
- 「LFM2-VL-1.6B」「LFM2-VL-450M」
- InternVL3.5
- qwen3-4b系の 2507
- Gemma 3 270M
- Jan-v1-4B
- Qwen3-Coder-30B-A3B-Instruct
- Gemma 3n
- DiffuCoder
- LLM-jp-3.1