はじめに
この記事は、過去にも色々と試してきているローカルLLM関連の話です。
技術情報のチェックと合わせて、ほぼ毎日に近いくらい確認している Hugging Face の MLX版モデル(主に「mlx-community (MLX Community)」のもの)を見ていたら、直近で加わっていたモデルの 1つを試してみます。
Jan-v1-4B について
MLX Community のモデルで、一番最近、作成されていたのが Jan-v1-4B のシリーズでした。元のモデルに関する情報は、以下の公式アカウントのポストなどに書いてあります。
上記の公式のポストを見てみると、公式が出した GGUF版もあるようです。

実際に試したもの
ここで、今回試した 2つの内容を書いてみます。ざっくり書くと、以下の実行環境・モデルの組み合わせです。
LM Studio で「janhq/Jan-v1-4B-GGUF」
まずは以下の「janhq/Jan-v1-4B-GGUF」を、LM Studio で試してみます。
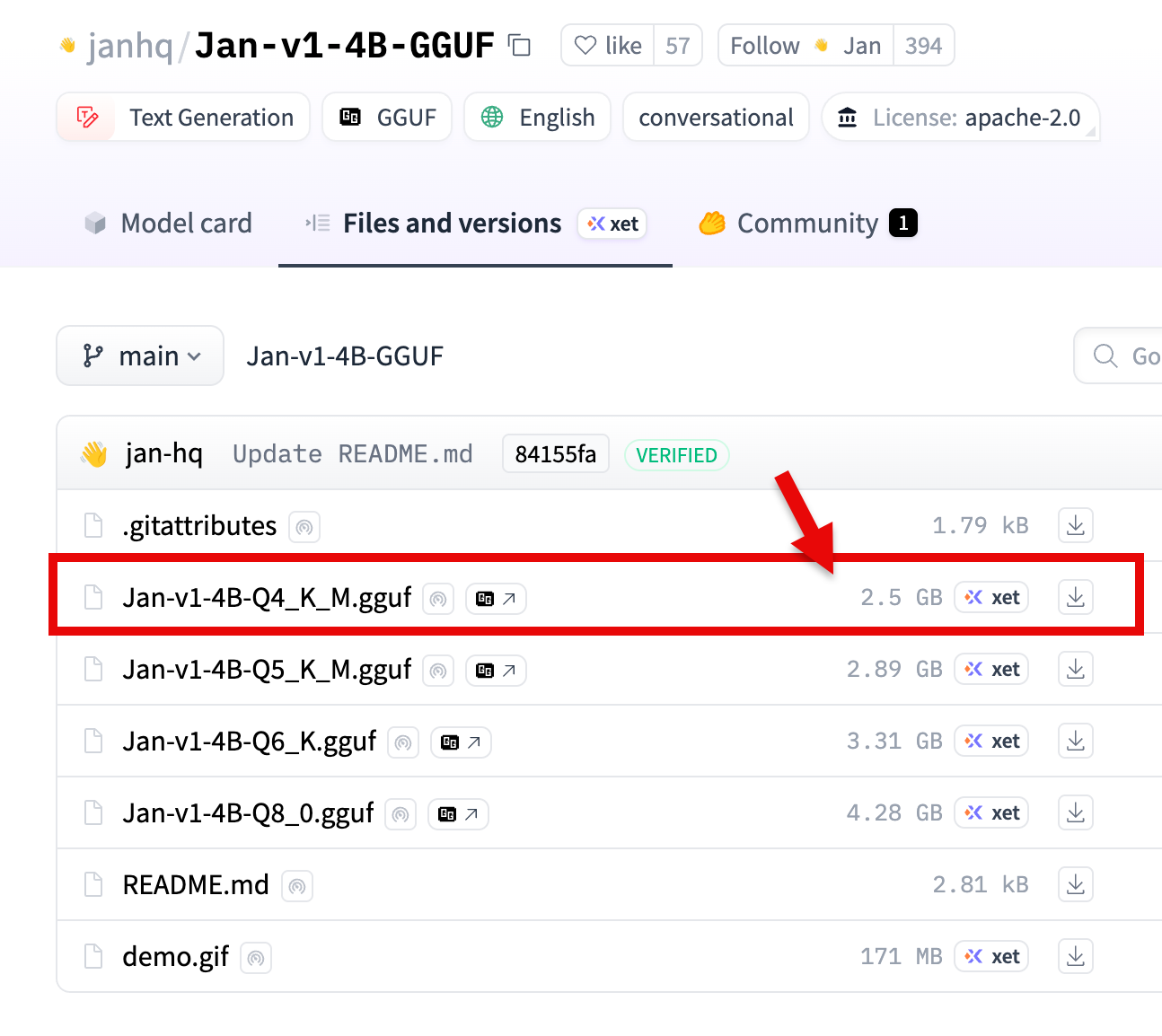
●janhq/Jan-v1-4B-GGUF · Hugging Face
https://huggingface.co/janhq/Jan-v1-4B-GGUF
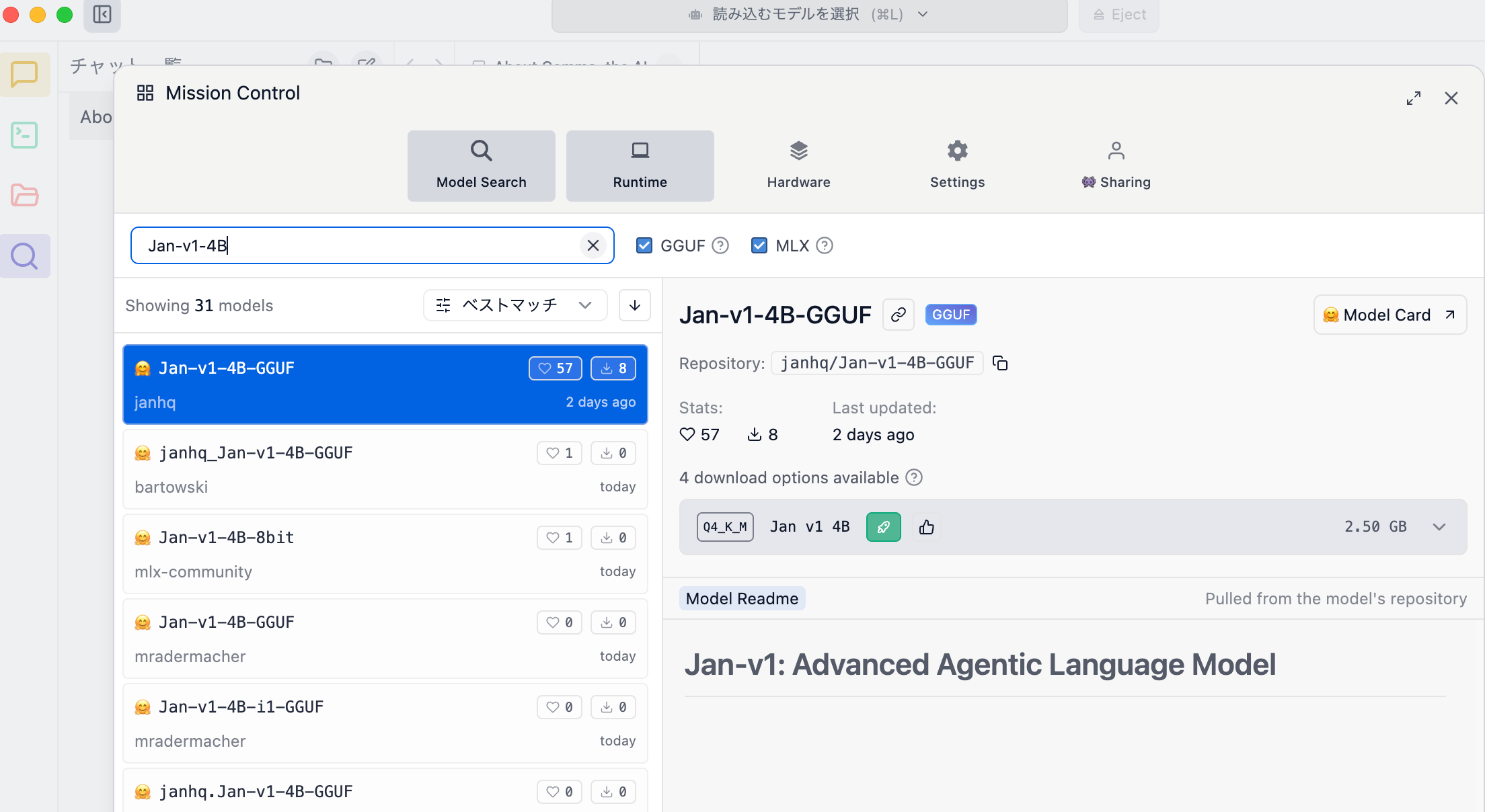
モデルサイズは 2.5GB のようなので、自分が持ち運んで使っている M4 の MacBook Air(ユニファイドメモリ 16GB)でも余裕で動くサイズです。
Hugging Face上で GGUF版のモデルの情報を見てみると、上で動作を確認したものは量子化が 4bit のもののようです(他に、もっとモデルサイズが大きい 5bit、 6bit、 8bit があるようでした)。
実行結果:LM Studio で「janhq/Jan-v1-4B-GGUF」
以下に実行中の様子の動画を掲載します。プロンプトは「日本語で、生成AIについて8歳に分かるような内容で短く説明して」というものにしています。
最初に「Thinking...」という内容が出て、最終的には『生成AIは、あなたの言葉で新しい絵や物語をつくる「魔法のツール」です。例えば、「笑ってる猫」と言うと、かわいい絵ができます!』という応答を得られました。
以下の部分を見ると、推論の処理が 26.68秒だったようです。
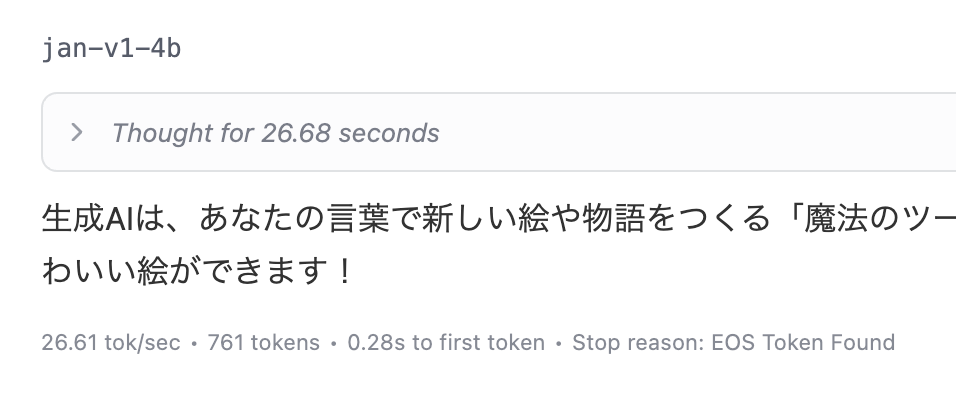
また出力スピード・トータルの出力の情報は、以下となっていました。
- 26.61 tok/sec
- 761 tokens
MLX LM で「mlx-community/Jan-v1-4B-4bit」
次に、過去にもよく使っている MLX LM を使ったお試しです。
環境構築の話は、過去の自分の記事で何度も書いているので省略します。
利用するモデルは以下で、モデルサイズは 2.26GB です。
●mlx-community/Jan-v1-4B-4bit · Hugging Face
https://huggingface.co/mlx-community/Jan-v1-4B-4bit
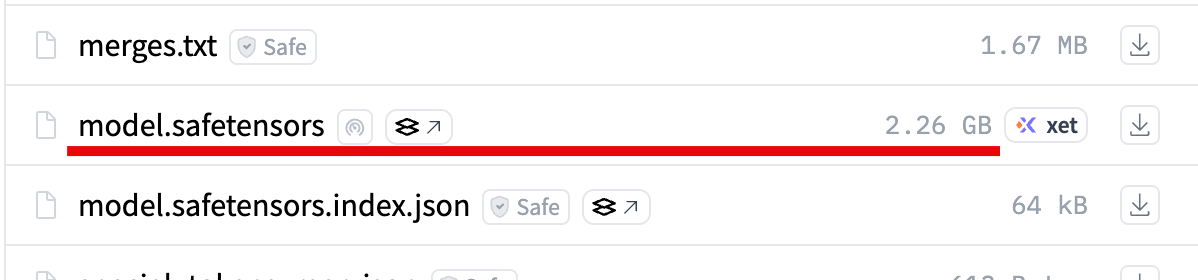
ちなみに 8bit のものでも、モデルサイズが 4.27GB のようなので、今回使っている M4 の MacBook Air(メモリ 16GB)でも余裕で動きそうです。
●mlx-community/Jan-v1-4B-8bit · Hugging Face
https://huggingface.co/mlx-community/Jan-v1-4B-8bit
実行用のコマンド
今回試した実行用のコマンドは、以下のとおりです。
mlx_lm.generate --model mlx-community/Jan-v1-4B-4bit --prompt "日本語で、生成AIについて8歳に分かるような内容で短く説明して" --max-tokens 2048
実行結果:MLX LM で「mlx-community/Jan-v1-4B-4bit」
実行結果は以下のとおりです。
こちらは、出力スピード・トータルの出力の情報などは、以下となっていました。
- Prompt: 28 tokens, 162.942 tokens-per-sec
- Generation: 552 tokens, 34.880 tokens-per-sec
- Peak memory: 2.434 GB