はじめに
ローカルLLMまわりの情報を追いかけている方は、高確率で目にすることもあると思われるミニPC「GMKtec EVO-X2」で、LM Studio を使ったローカルLLM を試した手順のメモ、という感じの記事になります。
試す環境について、今回使うランタイムは「ROCm llama.cpp(Windows) v1.52.1」で、利用するモデルは OpenAI の「gpt-oss-120b」です。また、基本的にデフォルト設定で使ってみます(最適な設定になってはいないかも...)。
↓ゲットした EVO-X2
EVO-X2 をゲットしたのは、上記のポストをしたタイミングです。その後、すぐに外出して遠出をして、翌日の夜に帰宅という状況だったので、この記事を書いたタイミングくらいでセットアップやお試しを行いました。
EVO-X2 に関する情報
EVO-X2 については、日本語の紹介記事もいくつか出ていたりするので、詳細はそちらをご参照ください。例えば、以下の記事などがあります。
●【西川和久の不定期コラム】Ryzen AI Max+ 395とメモリ128GBを搭載したミニPC「GMKtec EVO-X2」がついにやってきた! - PC Watch
https://pc.watch.impress.co.jp/docs/column/nishikawa/2050714.html
●【西川和久の不定期コラム】Ryzen AI MaxのLLMとAI画像生成の性能は?OCuLinkでどちらも快適に♪「GMKtec EVO-X2」(後編) - PC Watch
https://pc.watch.impress.co.jp/docs/column/nishikawa/2053153.html
EVO-X2 のスペック情報を Windows上で確認
お試しに入る前に、デフォルトでインストールされている Windows上で、システムの情報を見てみました。バージョン情報の項目で出てくる内容は、以下のとおりです。

さっそく試してみる
とりあえず、EVO-X2 の初期セットアップを終えて、ネット接続ができるようにした状態から、サクッとローカルLLM を動かしてみます。
なお、標準でローカルLLM を試すための環境が入っているようなのですが、この記事では LM Studio を使ってローカルLLM を試します。
1)LM Studio のダウンロード・インストール
まずは、以下の公式サイトから LM Studio のインストーラーをダウンロードして、インストールします。
●LM Studio - Local AI on your computer
https://lmstudio.ai/
記事執筆時点だと「0.3.30」が最新版で、EVO-X2 へのインストールは特に問題なく進められました。
2)LM Studio の起動とモデルのインストール
LM Studio を起動して、初期セットアップを行います。途中で「Choose your level」という選択肢が出るところは「Power User」を選択しました。
また、最初のモデルとして gpt-oss-20b のインストールを促す画面が出てきましたが、ここはスキップしました。モデルは、この後に LM Studio の Model Catalog にも掲載されている他のモデル(今回は「gpt-oss-120b」)を自分で検索してダウンロードします。
モデルのダウンロード
その後、LM Studio の以下の画面が出るところまで進めました。
ここから、左メニューの虫眼鏡アイコン(モデルを検索する画面を出すためのアイコン)をクリックして、そこで「openai/gpt-oss-120b」を検索します。自分の場合、「gpt-」などキーワードを途中まで入力した段階で gpt-oss-120b が出てきました。
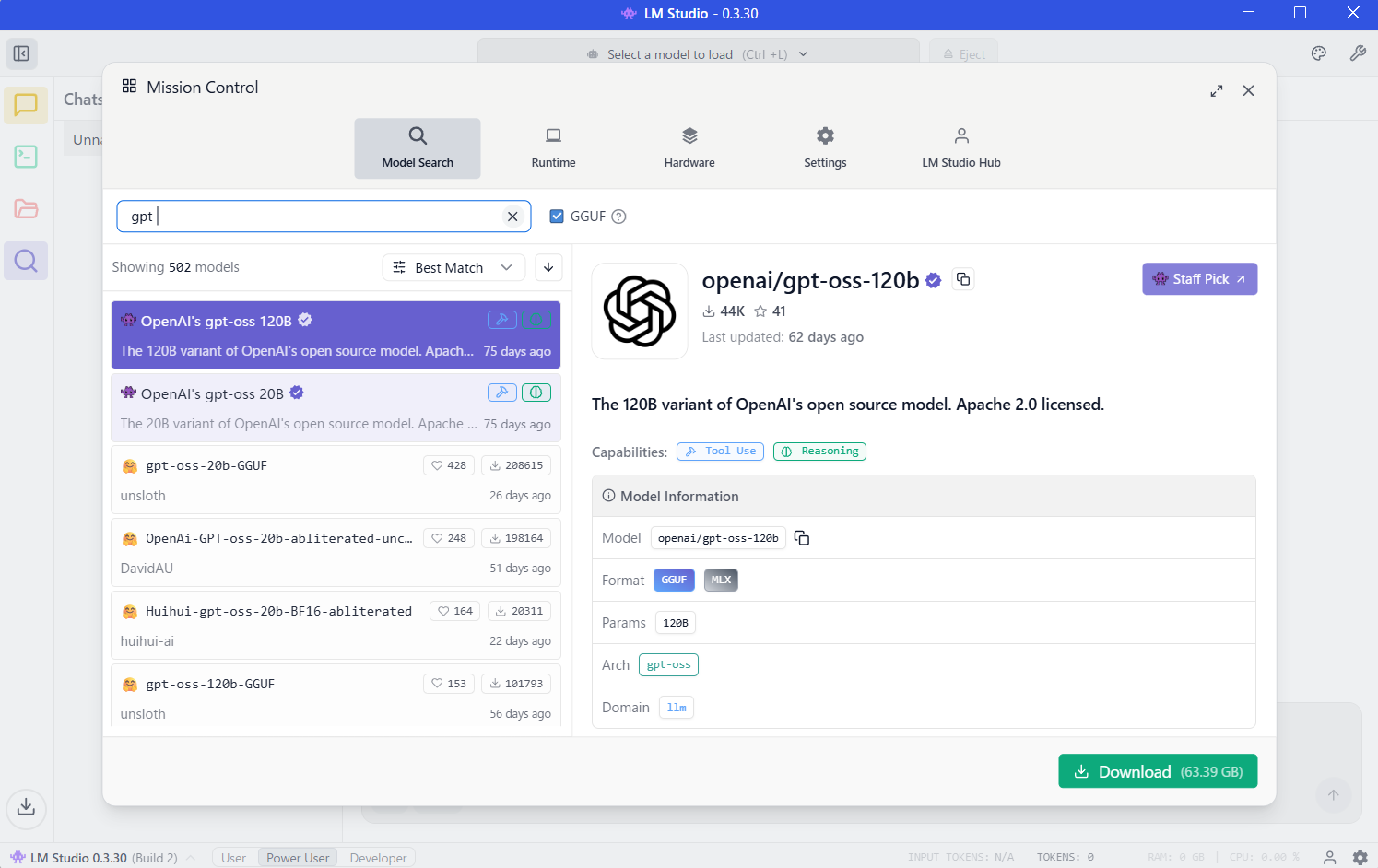
このモデルをダウンロードします(※ そのままダウンロードすると「GGUF」のモデルになります)。ダウンロードが完了したら次へ進みます。
3)設定を確認してみてランタイムを変更
設定について、最初はデフォルトのままで進めてみました。
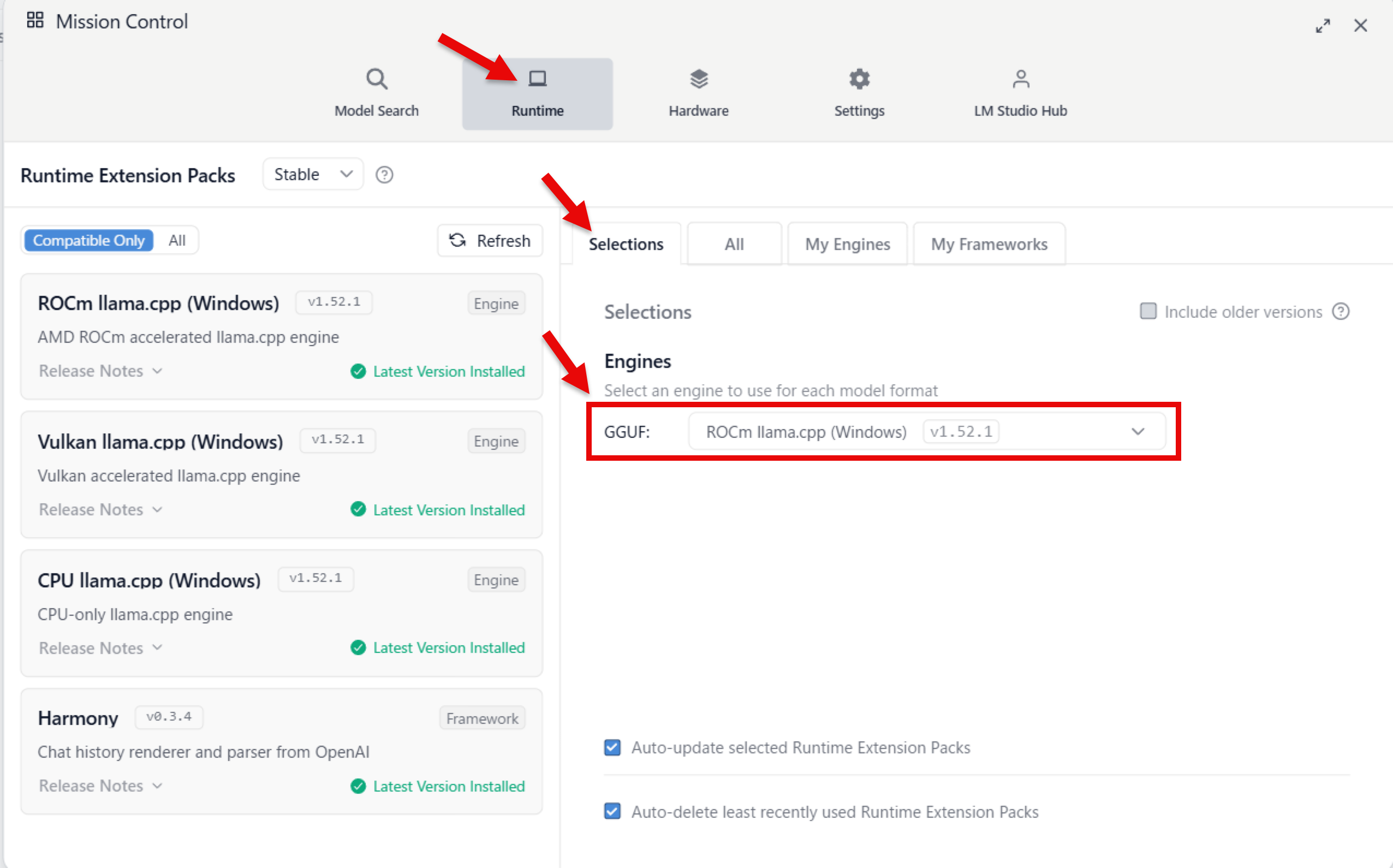
ちなみに、この時点でランタイムの情報を見てみた時の内容が、以下になります。4つのランタイムがあり、左メニューを見ると「ROCm llama.cpp(Windows)」が未ダウンロードの状態のようです。
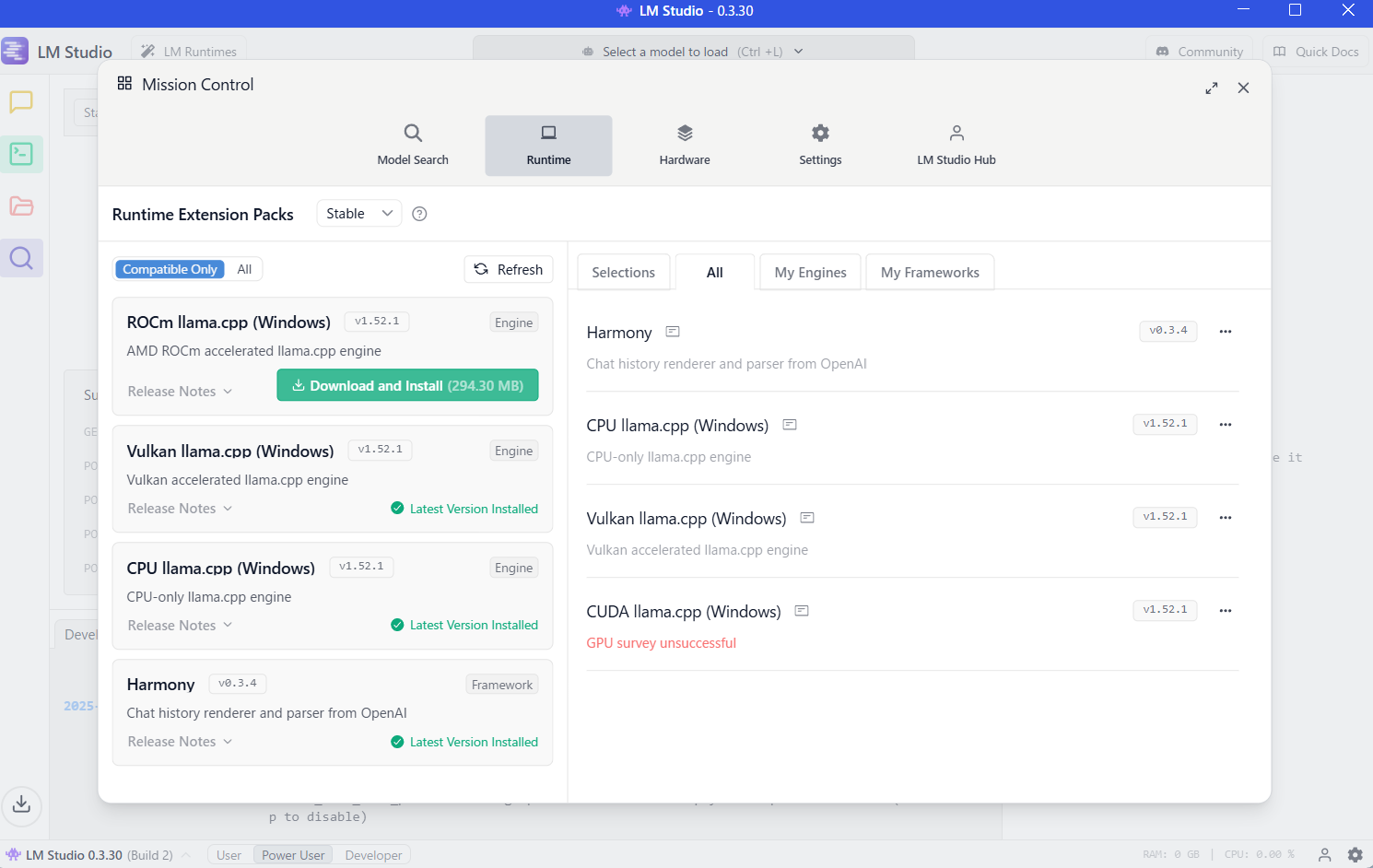
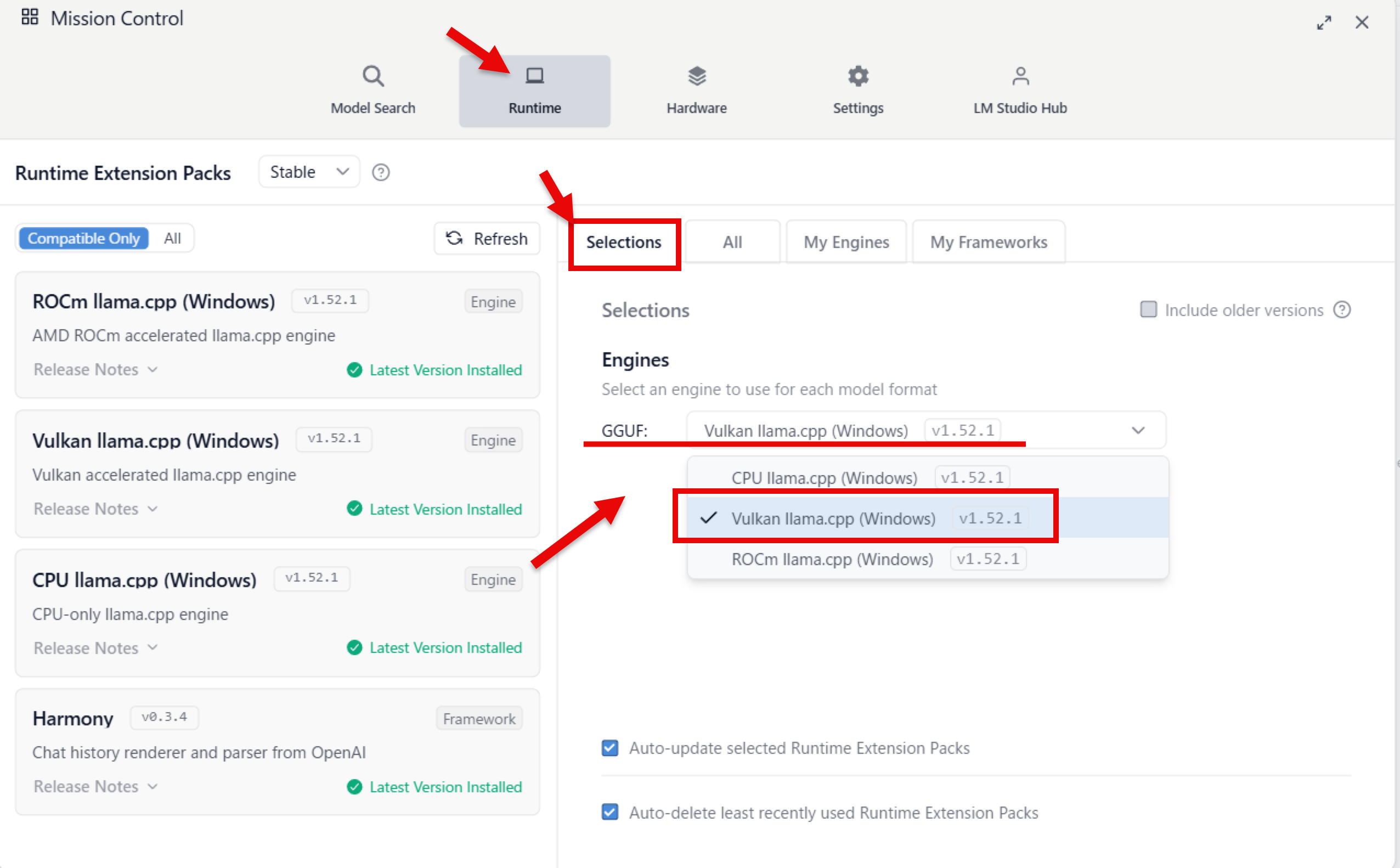
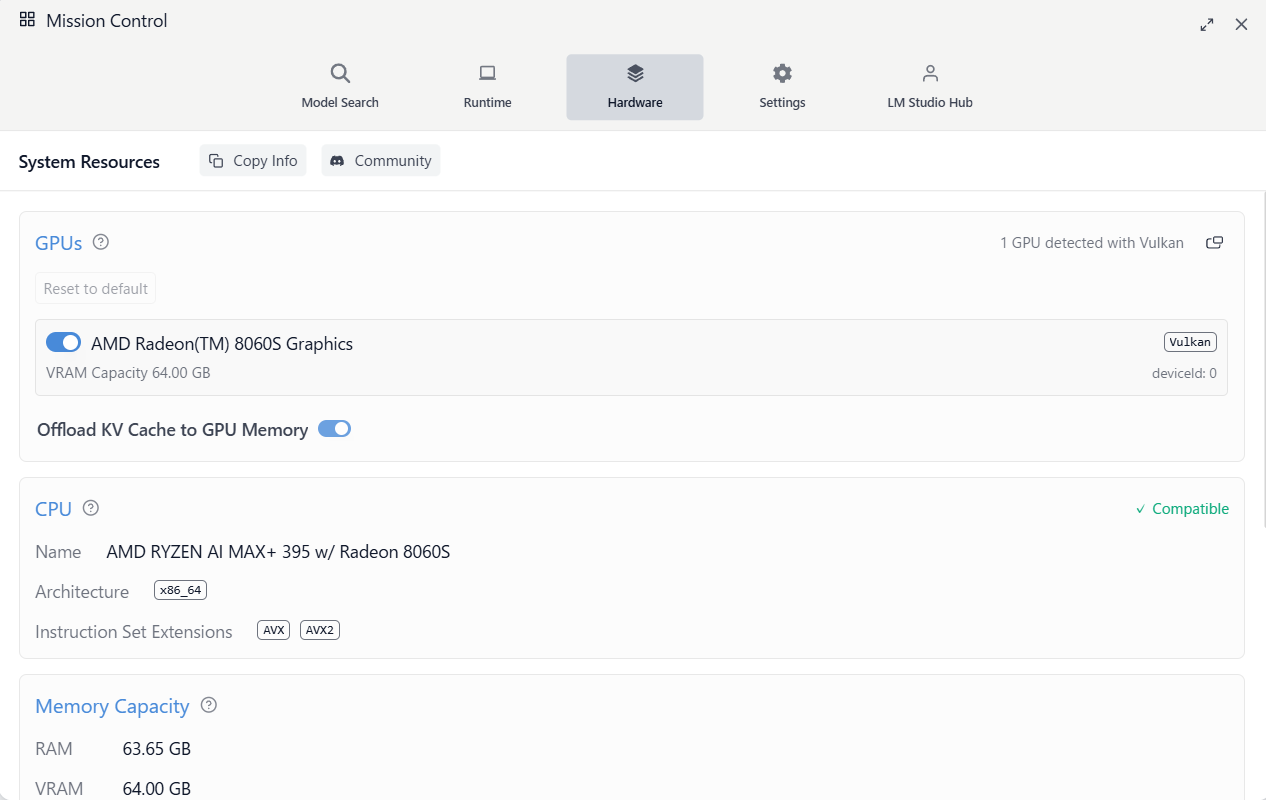
デフォルトのランタイム設定を見てみると、GGUF のモデルのランタイムは以下の Vulkan llama.cpp(Windows)の v1.52.1 が選ばれていました。
ちなみに Hardwareタブを開いてみると、以下のように「RAM 63.65GB、 VRAM 64GB」になっていました。
ランタイムの変更
この状態で進めると、モデル(gpt-oss120b)のロードで以下のエラーが発生する状況でした。
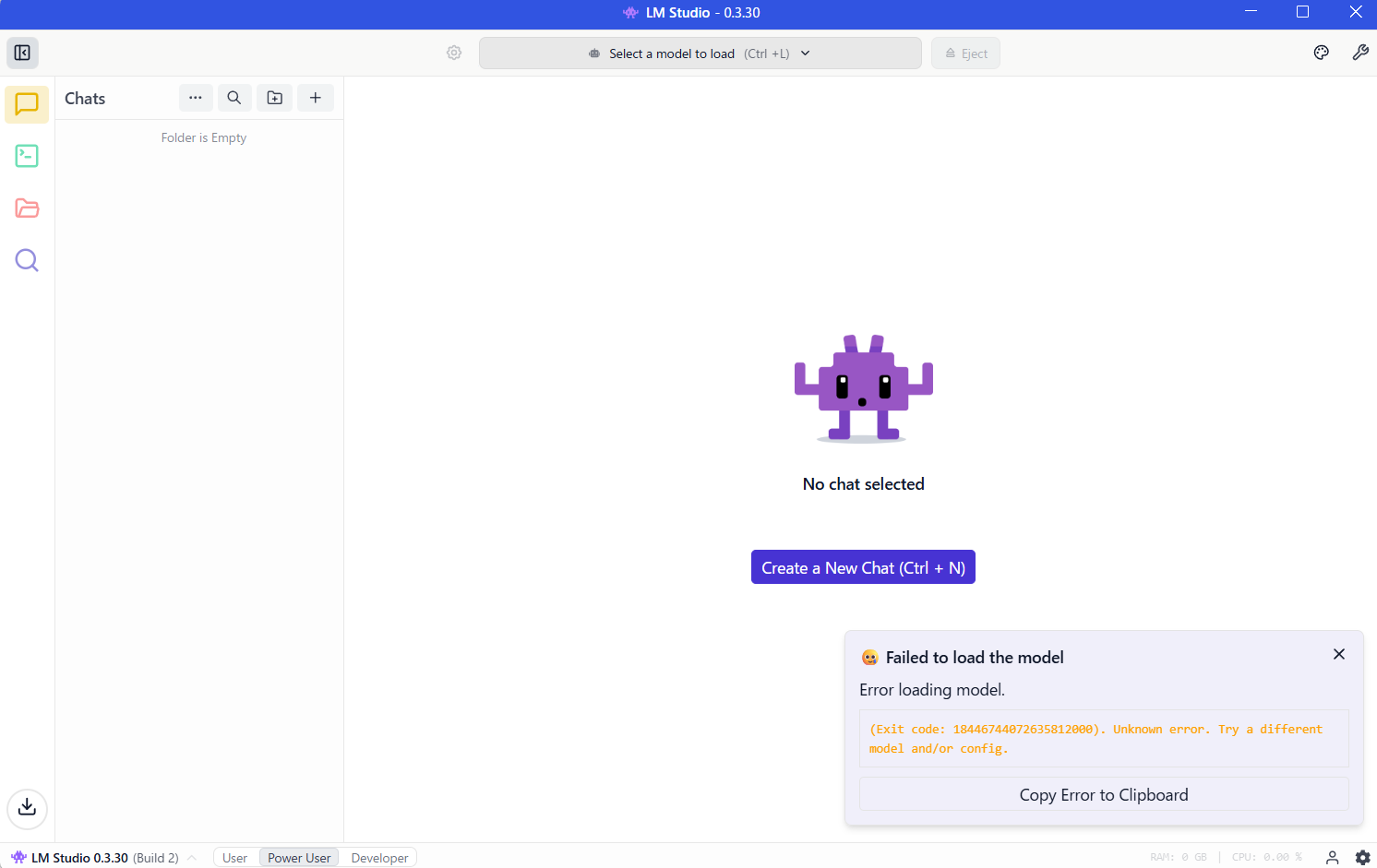
それで先ほどの画面で、追加ダウンロードできるようになっていた「ROCm llama.cpp(Windows)の v1.52.1」を試してみることにしました。以下の画面は、ROCm llama.cpp(Windows)をダウンロード後、GGUF用のランタイムとして選んだ状態です。
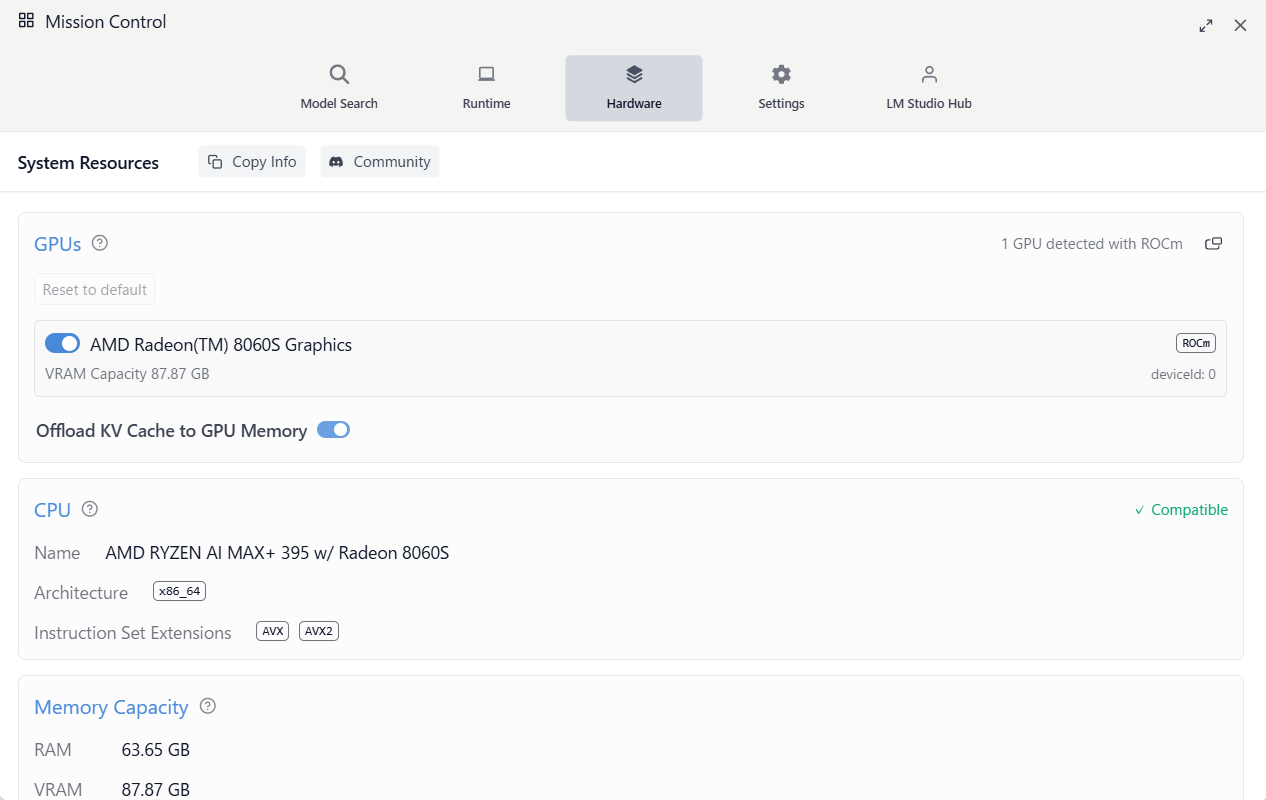
ちなみに Hardwareタブを開いてみると、以下のように「RAM は先ほどと同様に 63.65GB」でしたが、「VRAM のほうは 87.87GB」になっていました。
4)簡単なお試し
ランタイムを変えた後だと、モデルのロードでエラーが出なくなっていました。
最後に、とりあえずの簡単なお試しをシンプルなプロンプトでやってみたところ、無事に動作させることができました。
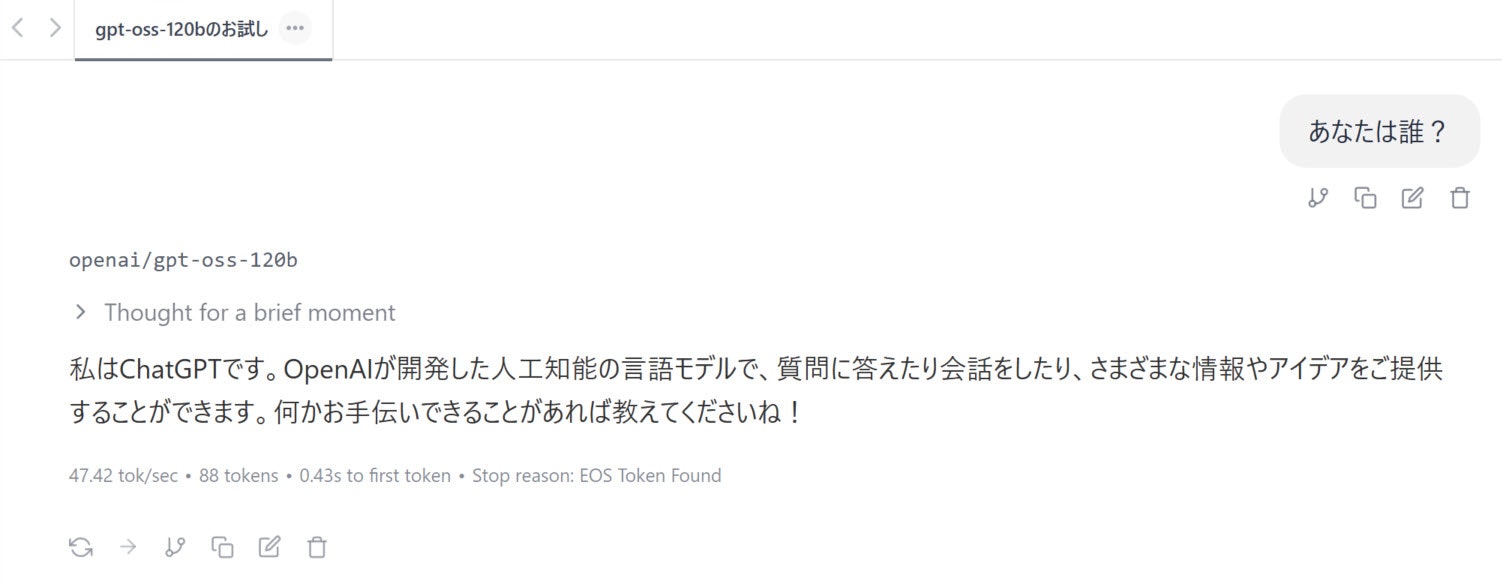
お試し1
以下は、「あなたは誰?」というプロンプトで実行してみた時の結果です。
最終結果のキャプチャ画像は、以下のとおりです。
お試し2
さらに試してみます。
以下は、「なぜ空は青い?」というプロンプトで実行してみた時の結果です。
最終結果のキャプチャ画像は、以下のとおりです。
おわりに
とりあえず、ミニPC「GMKtec EVO-X2」と LM Studio を使ったローカルLLM を試せました。その際、ランタイムを「ROCm llama.cpp(Windows) v1.52.1」にすれば、特に問題なく gpt-oss-120b を利用することができました。
また今後も、GMKtec EVO-X2 を使ったローカルLLM を試していければと思います。
【追記】 LINE Bot に組み込んでみた
その後、上記で試したローカルLLM を LINE Botサーバーに組み込んで使ってみました。
以下のように、スマホの LINEアプリの入力に対して、GMKtec EVO-X2上の gpt-oss-120b を使った回答が行われるものを試せました。
※ 以前、登壇用に試作した LINE Bot の設定を再利用したので、Bot名に「202508」(2025年8月)という内容が入っています
ちなみに、 ↓こちらでポストしている、LT登壇用に進めた内容です。