はじめに
oneWEXを使ってみた時のメモです。
これまでは、"検索/探索"辺りにフォーカスしてきましたが、ここからは、oneWEXの"分析"という機能に着目し、ContentMinerを使ってどのようなことができるのかを見ていきたいと思います。今回は、"分析"関連の機能の中でも手っ取り早く使えそうな、"ガイド付きモード"の"原因または特性の分析"という項目をとりあえず試してみます。
関連記事
インストール関連
oneWEX導入メモ / Ubuntu編
oneWEX導入メモ / RHEL7.6 オフライン編
検索関連
oneWEX検証メモ - (0) 概要理解
oneWEX検証メモ - (1)ファイルシステムクローラーによるデータの取り込み / データセット、コレクションの作成
oneWEX検証メモ - (2)Windowsファイルシステムクローラーによるデータの取り込み
oneWEX検証メモ - (3)ContentMinerによる文書の検索
oneWEX検証メモ - (4)ApplicationBuilderによるWebアプリの作成と文書の検索
分析関連
oneWEX検証メモ - (5)ContentMinerによる分析 / ガイド付きモード
oneWEX検証メモ - (6)ContentMinerによる分析 / 各種"ID情報"をベースとした分析
API関連
oneWEX検証メモ - (7)REST API
利用するデータセット/コレクション
テスト用ファイル
今回のテストで取り込むファイル群は以下です。
https://github.com/tomotagwork/WEXTest01/tree/master/SampleFiles2
これまで作成してきたファイル群をベースに、1つWord文書を追加しています。
以下の2つは、全く同じWordの文書です(ディレクトリだけ異なる)。
WEXTest01/SampleFiles2/TroubleReport/チーム02/障害報告書サンプル20190724.doc
WEXTest01/SampleFiles2/TroubleReport/チーム03/障害報告書サンプル20190724.doc
上の2つの文書には、被害状況として以下の文言が含まれています。
「領域01 のトランザクションTRAN0002がA002で異常終了。」
もう1つ、追加で以下のようなWord文書を用意しました。
WEXTest01/SampleFiles2/TroubleReport/チーム01/障害報告書サンプル20190826.doc
この文書には、被害状況として「領域01 のトランザクションTRAN0001がA001でアベンド。」という文言が含まれています。一方、別の欄に、「TRAN0002には影響なし」、「(A002アベンドの対応と同様)」という文言が含まれます。
上の2つとは全く違う内容の障害報告書ですが、TRAN0002とA002というキーワードを含んでいる文書をあえて用意してみました。
コレクション
先の記事で、annotator_ITWord01.csvという用語リストを取り込んで、ITWord01という辞書を追加しました。同様に、上のトランザクションコード"TRAN0002"やアベンドコード"A002"を認識させるために、annotator_ITWord02.csvというファイルを取り込んで、ITWord02という辞書を追加し、コレクションに適用します。
※このように全コードをリストにしておいて取り込むのはあまり現実的ではないと思われます。恐らく、こういったコードを認識させるためには、"文字パターンアノテーター"というものを使うことで正規表現で認識させられると思われます。これは別途試してみたいと思うので、今回は一旦ベタでコードのリストを辞書として取り込んでテストしてみます。
ContentMinerによる分析 / 原因または特性の分析
さて、上のデータを取り込んだコレクションを、ContentMinerで見てみましょう。
ITWord02で、コード類の辞書を登録しておいたので、ファセット"ITWord02"の欄で、アベンドコードやトランザクションコードが認識され、それらを含む文書のカウントが確認できます。ここから"A002"を選択して検索してみます。
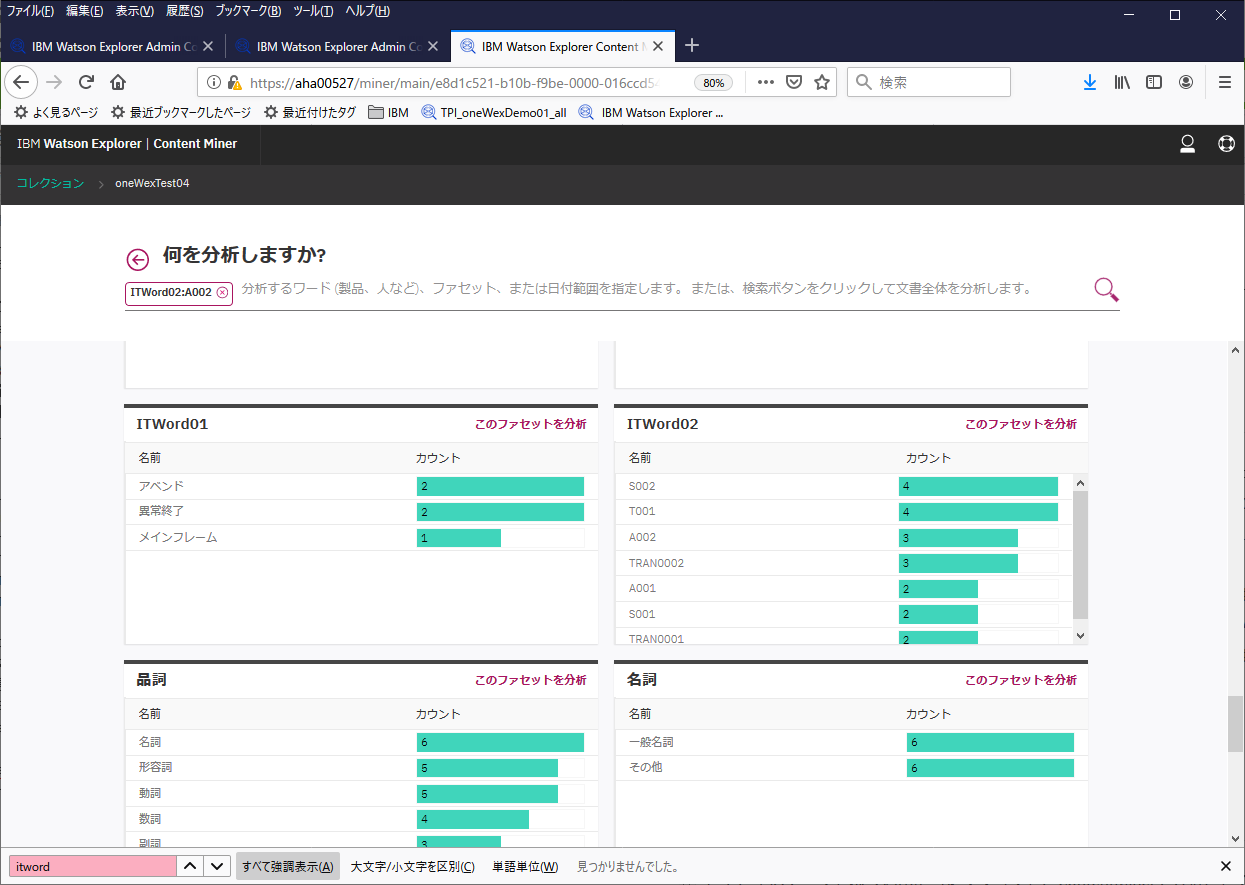
以下のグラフで、右上の「原因または特性の分析」を選択してみます。
以下のような画面が表示されます。
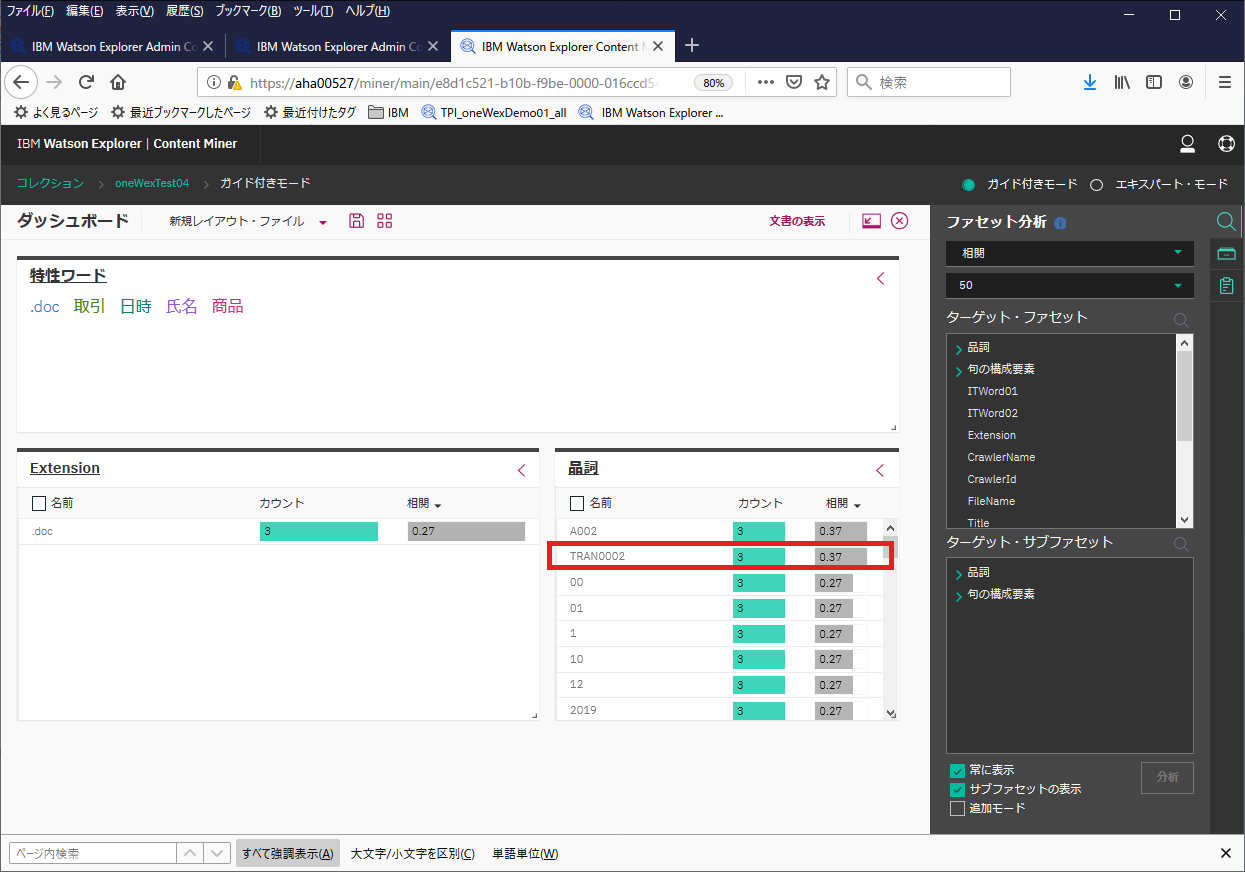
ダッシュボードには、分析によって提案された特性ワードに加え、さらに分析可能な 1 つ以上のファセットが表示されます。
ここで示される"特性ワード"や"ファセット"が何を示すのか明確な説明が見つからず詳細が不明なのですが、WEXさんが何らかの分析をして、さらなる分析のヒントとなるキーワードやファセットを提案してくれているらしいです。恐らく、関係の深いキーワードや相関が高いキーワードを含むファセットなどを表示してくれているのではないかと推察します。
さて、ここで、"品詞"ファセットを見てみます。ここには、相関値の高い順にファセット値が並んでいるようです。
"相関値"について調べてみると、この辺の記述が参考になりそうです。
参考: 頻度値と相関値が高いファセット値の識別
「ファセット」ビューには、選択されたファセットの値のリストが表示されます。 ファセット値とは、分析されるエンティティーのことで、ワード、テキストのパターン、フィールド値などがあります。 各ファセット値には、対応する頻度カウントと相関値があります。
- 頻度 とは、照会された文書セット中の、特定のファセット値を含む文書の数のことです。 棒グラフの棒の長さの違いにより、検索結果内のさまざまなファセット値のカウントを一目で比較できます。
- 相関 とは、あるファセット値が、検索条件に一致する文書とどの程度関連性があるかを示します。 相関値は、照会に一致する他の文書と比較して、 高い頻度の固有性のレベルを測定します。 1.0 より高い相関値は異常を表し、さらに調査が必要です。
頻度値は有用ですが、常に相関値ほど役に立つとは限りません。 例えば、特定の自動車モデルの頻度カウントが高い場合、それは 全体的な自動車人気に起因していて、結果的にそのモデルの自動車が 他のモデルよりも多く売れたという可能性があります。 一方、高い相関値は、何らかの異常があることを示しているため、さらに調査および分析が必要です。 相関値による結果のソートは、ファセット値とサブファセット間の異常を識別するのに役立ちます。 特にコレクション内で何を探すか明確ではなく、予期しない異常を発見したい場合に役立ちます。
平たく言えば、"A002"と関連性の高いキーワードを上位に挙げてくれていると考えて良さそうです。"A002"は最初に検索したワードなのでそれは置いておいて、次に表示されているのは"TRAN0002"です(上の図の赤枠で囲った部分)。これを選択して、「さらに分析」ボタンをクリックしてみます。
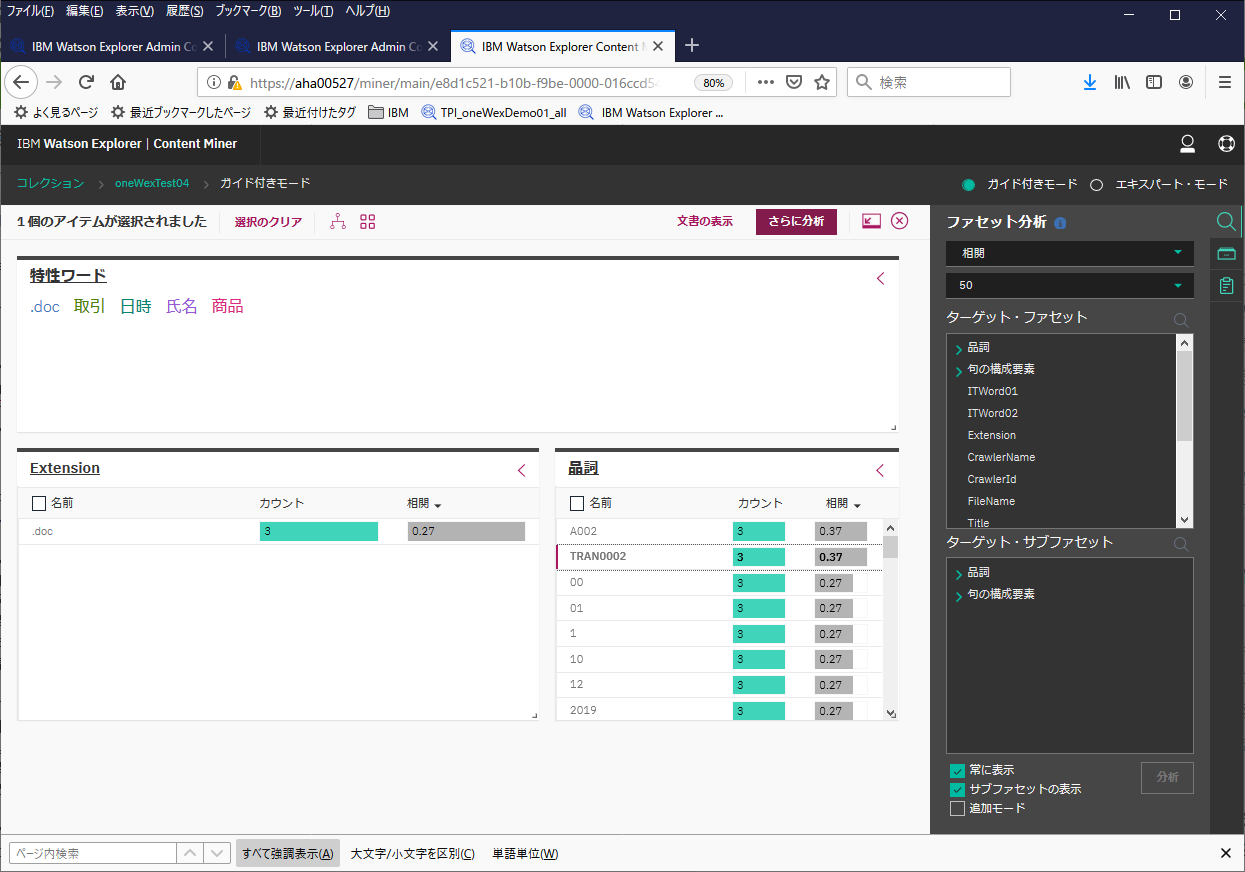
こんな感じで、検索条件が付与されて絞り込みが行えました。ここで文書の表示を選択してみます。

以下の3つの文書が抽出されました。
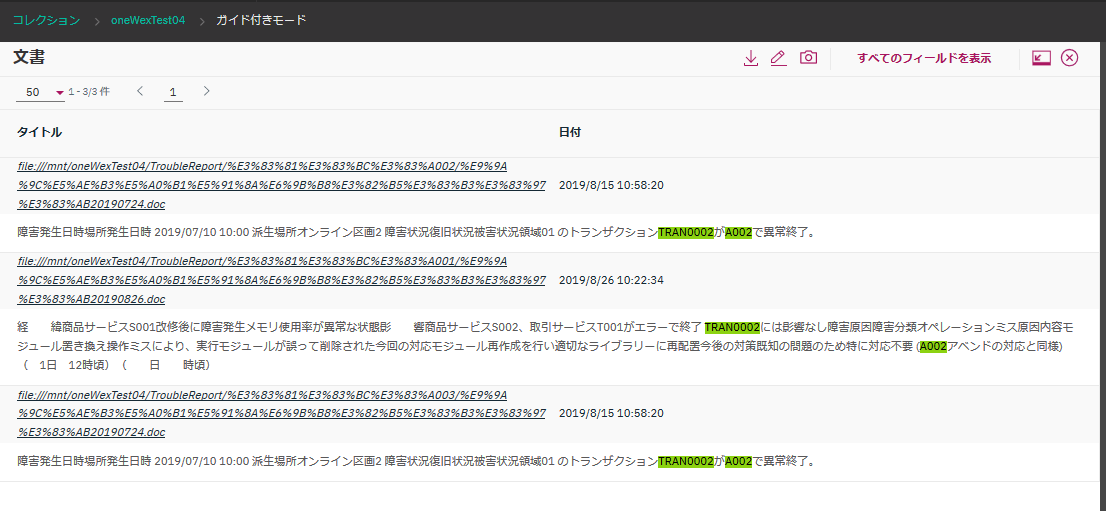
最初に挙げた、Word文書3つがヒットしているようです。
これはすなわち、文脈とか関係なく、"A002"と"TRAN0002"が同一文書上にあるものを3つ検出してくれている、ということになると思います。
考察
最初に挙げたように、今回着目したのは2つの同一のWord文書と、文脈が異なるが同じようなキーワードを含むWord文書です。
少なくとも素のままでは、各文書に含まれる"文脈"を解釈するということまでは行ってくれず、単に1ファイルの中にどういうキーワードが含まれるか、ということしか判断してくれないようです。
"相関値"についても、結局、同一文書に含まれているかどうかしか判定してくれていないように見えます(3つのWord文書は文脈上は明らかに別の意味合いですが、同列に扱われてしまう)。
Wordでは表形式になっているので、人が見れば、この部分が発生事象だなとか、この部分が原因だな、というのは分かりますが、そういう表形式のものから勝手に分類をしてくれるということもありません。
また、このWord文書の雛形は、どこぞやからテンプレをダウンロードして使っているのですが、「経緯」や「影響」という文言の部分は表示を意識して、間にブランクが入ったりしているので、「経」「緯」それぞれ別の単語で認識してしまっているようです。この手のゆらぎも補正はしてくれていません(実際の既存文書の中にはこういうモノも多数紛れていると思われます)。
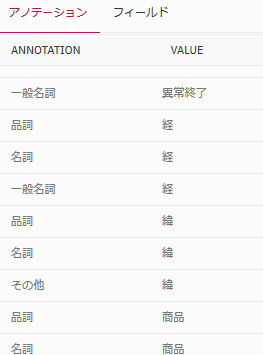
設計書とか手順書とかを想定すると本文の量が膨大になるため、一緒に含まれるキーワードの量も膨大になり、それらの相関(同じ文書に含まれるかどうか)にどれだけ意味があるのか、というのは甚だ疑問です。
恐らく"分析"のベースになるのは"ファセット"になると思われ、"非構造化データ"に対して、どの程度"分析"に役立つ"ファセット"を割り当てられるか、というのが肝になりそうな気がします。
とりあえず素のままだとあまり有用なファセットが付かないので、"非構造化データ"としてWord,Excel,PDFを取り込んだデータをベースにした場合、どういうファセットを適用してどういう分析ができるのか??? ということを考えないといけないと思います。
つまり、"分析"とか"洞察"を導き出すには、ある程度"構造化された状態"(≒意味のあるファセットが適用された状態)を作ってあげないといけないんじゃないかと思うわけですが、どうしたものか、なかなかそこが難しそうです...。
ファセットの制御
文書(ファイル)の外部の観点
とりあえず、各文書の外部の観点から付与できるファセットとしては、メタデータファセット(ファイル名やファイルサイズなど)があります。このうち、コントロールできそうなものとしては、ディレクトリ名、および、クローラー名、の辺りだと思います。
例えば、各ファイルを意味のあるカテゴリごとに分類して、そのカテゴリに応じたディレクトリを作成してファイルを配置する、あるいは、カテゴリ単位でクラーラーを分けてWEXに取り込む、ということをすると、その分類したカテゴリ単位の情報がディレクトリ名やクローラー名のファセットとして付与されることになります。
また、もう一つ重要な要素として、ファイルの更新日時というのがあります。oneWexの分析では、時系列に基づく分析が行えますが、この時刻情報の元になるのがファイルの最終更新日時です。例えば、"障害報告書"というようなものを想定した場合、ファイルの最終更新日は、実際の障害が発生したタイミングからはだいぶ時間が経過したものになるはずです。しかも、oneWEXに取り込むためにファイルの配置場所を変えたりすると、操作方法によっては最終更新日がさらに上書きされてしまう可能性もあります。この情報が意味のあるものとして扱えるのかどうかは注意を払っておく必要があります。
文書(ファイル)の中身の観点
コレクションに"アノテーター"を適用することで、各文書にタグ付けのようなものをすることができます。前に例で挙げた辞書がその1つですが、例えば特定のカテゴリの用語辞書を作って適用すれば、特定の用語が含まれる文書かどうか、という分類が行えます。IT用語辞書を作って適用すれば、IT用語ファセットとして"トランザクション"というキーワードを含む文書かどうか、という分類ができるということになります。
それ以外に、ID情報(メッセージIDやアベンドコードなど)は文字パターンアノテーターというもので認識させることができそうなので、その辺りは使えそうです。これについては別の記事で取り上げます。
補足 (SDU)
IBMのPublic Cloud上で提供されているWatson Discoveryという非構造化データ探索のためのサービスがあるのですが、そちらでは、SDU(Smart Document Understanding)という機能が提供されています。
参考: Smart Document Understanding
この機能を使うと、例えばファイルの中身に表形式のレイアウトで情報を保持しているようなPDFがあったとして、その位置情報から、この部分に記載されているのはタイトルだよ、とか、この部分に記載されているのが障害原因だよ、とか、そういうことをトレーニングさせるができるようです。教師データを使ってある程度トレーニングさせてモデルを作成すると、それをベースにして、他の文書もアノテーション付けを行ってくれるようです。
なかなかステキな機能なのですが、残念ながらoneWEXでは提供されていないようです...。