はじめに
oneWEXを使ってみた時のメモです。
まずはファイルシステムクローラーによるデータの取り込み、データセット、コレクション作成の辺りです。
関連記事
インストール関連
oneWEX導入メモ / Ubuntu編
oneWEX導入メモ / RHEL7.6 オフライン編
検索関連
oneWEX検証メモ - (0) 概要理解
oneWEX検証メモ - (1)ファイルシステムクローラーによるデータの取り込み / データセット、コレクションの作成
oneWEX検証メモ - (2)Windowsファイルシステムクローラーによるデータの取り込み
oneWEX検証メモ - (3)ContentMinerによる文書の検索
oneWEX検証メモ - (4)ApplicationBuilderによるWebアプリの作成と文書の検索
分析関連
oneWEX検証メモ - (5)ContentMinerによる分析 / ガイド付きモード
oneWEX検証メモ - (6)ContentMinerによる分析 / 各種"ID情報"をベースとした分析
API関連
oneWEX検証メモ - (7)REST API
全体像
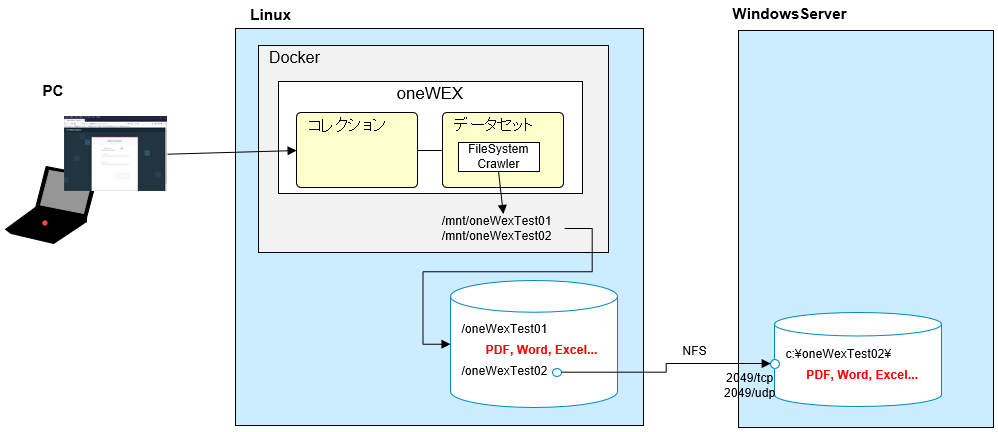
PDF,Excel,Wordなどの文書をoneWEXに取り込んで分析するってことをやりたい。
今回は、その取り込み部分に着目してやってみます。
今回は、ファイルシステムクローラーをを使う想定です。
対象となるファイルは、oneWEXが稼働するLinuxと同じディスク上に配置するケースと、別のWindowsServer上に配置するケースの2パターンを想定してみます。
いずれにしても、oneWEXはDockerコンテナとして実装されているので、Linuxファイルシステムをコンテナ上から参照できるようにする必要があります。
また、リモートのWindowsServer上のファイルはNFSマウントしてLinuxから参照できるようにすることを想定します。
データの取り込み
事前準備
対象のファイル配置
PDFとかExcelとか適当なファイルを作成して、Linux, WindowsServerそれぞれに配置します。
WindowsServer側では対象のディレクトリをNFSで公開し、Linuxからはその公開されたディレクトリをNFSマウントしておきます。
当然、WindowsServer側はNFSサーバーが必要になりますし、Linux側はNFSクライアント(nfs-utils)が必要になります。
(Linux-WindowsServer間のNFSマウントについてはここでは本質ではないので詳細は割愛しますが、NFSv4の場合、NFSサーバー側ではTCP,UDPの2049ポートが使われるのでFirewallの設定などにはご注意を。)
ローカルファイルシステムのマウント
oneWEXのDockerコンテナからローカルのファイルシステムにアクセスできるようにマウントを行います。
これは、ibmwatsonexplorerコマンドで起動されるGUIのツールを使うか、もしくは、/root/ibm/wex/config/wex.jsonという構成ファイルを直接編集します。(GUIでの変更も最終的にはwex.jsonが書き換えられることになります)
参考: Providing access to the local filesystem from Watson Explorer oneWEX installed on Docker
ibmwatsonexplorerでの操作をしてみます。
[root@test11 ~]# /root/ibm/wex/bin/ibmwatsonexplorer
/root/ibm/wex/bin/ibmwatsonexplorer: error while loading shared libraries: libXss.so.1: cannot open shared object file: No such file or directory
起動しようとしたらおこられた。
https://www.ibm.com/support/knowledgecenter/ja/SS8NLW_12.0.0/com.ibm.watson.wex.ee.doc/c_onewex_install_docker.html
「libXScrnSaver」こいつが必要らしい。
ここからダウンロードしてインストール。
https://centos.pkgs.org/7/centos-x86_64/libXScrnSaver-1.2.2-6.1.el7.x86_64.rpm.html
libXScrnSaver-1.2.2-6.1.el7.x86_64.rpm
(あ、しまった、後から気づいたが、これOSのDVDに含まれてたかも...)
[root@test11 /Host_Inst_Image/oneWEX]# yum install ./libXScrnSaver-1.2.2-6.1.el7.x86_64.rpm
読み込んだプラグイン:langpacks, product-id, search-disabled-repos, subscription-manager
This system is not registered with an entitlement server. You can use subscription-manager to register.
./libXScrnSaver-1.2.2-6.1.el7.x86_64.rpm を調べています: libXScrnSaver-1.2.2-6.1.el7.x86_64
./libXScrnSaver-1.2.2-6.1.el7.x86_64.rpm をインストール済みとして設定しています
依存性の解決をしています
--> トランザクションの確認を実行しています。
---> パッケージ libXScrnSaver.x86_64 0:1.2.2-6.1.el7 を インストール
--> 依存性解決を終了しました。
依存性を解決しました
===============================================================================================================================================================================================
Package アーキテクチャー バージョン リポジトリー 容量
===============================================================================================================================================================================================
インストール中:
libXScrnSaver x86_64 1.2.2-6.1.el7 /libXScrnSaver-1.2.2-6.1.el7.x86_64 40 k
トランザクションの要約
===============================================================================================================================================================================================
インストール 1 パッケージ
合計容量: 40 k
インストール容量: 40 k
Is this ok [y/d/N]: y
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
インストール中 : libXScrnSaver-1.2.2-6.1.el7.x86_64 1/1
検証中 : libXScrnSaver-1.2.2-6.1.el7.x86_64 1/1
インストール:
libXScrnSaver.x86_64 0:1.2.2-6.1.el7
完了しました!
リトライ
[root@test11 ~]# /root/ibm/wex/bin/ibmwatsonexplorer
上がってきました。
右上のメニューからMountを選択
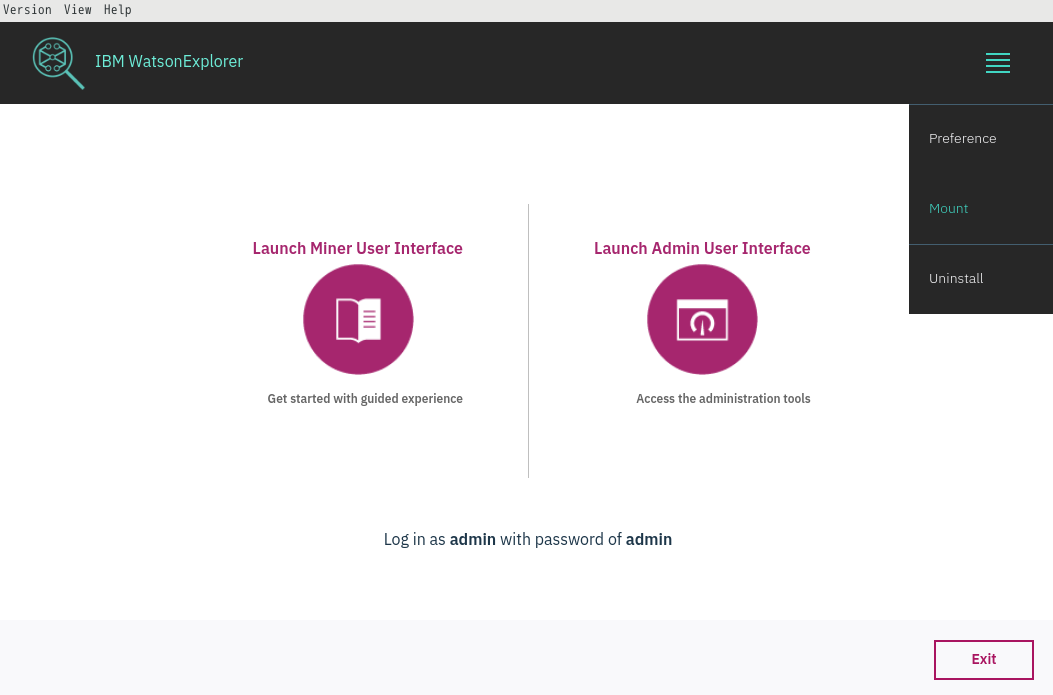
ローカルの/oneWexTest01, /oneWexTest02をそれぞれ、/mnt/oneWexTest01, /mnt/oneWexTest02にマウントします。
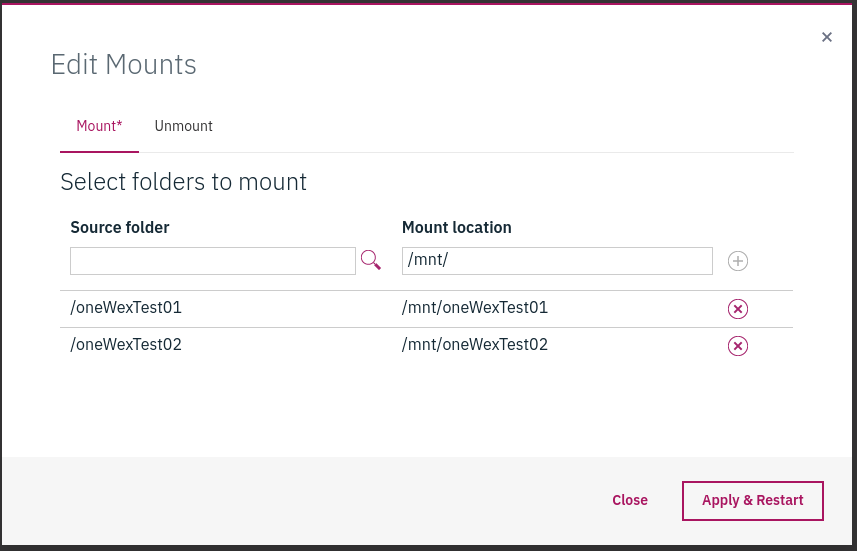
Apply&Restartボタンを押すと、変更が反映されて(wex.jsonが変更されて)、oneWEXが再起動されます。
{
"env": {
"SOLR_MAX_HEAP": "4g",
"DOCPROC_WORKER_NUM": "2",
"SOLR_PER_NODE": "1",
"DOCPROC_MAX_MEMORY": "2g",
"WKSML_HOST": "wksml-service",
"ZK_MAX_HEAPSIZE": "1g",
"ZK_MIN_HEAPSIZE": "512m",
"WLP_JVM_MAX_MEMORY": "1g"
},
"port": 443,
"name": "wex12dae",
"wexDataVolume": "wex12dae",
"dockerImage": "ibm-wex-ee:12.0.3.935",
"wksmlImage": "ibm-wex-wksml:12.0.3.935",
"wksmlContainerName": "wksml-service",
"restart": "unless-stopped",
"mounts": {
"oneWexTest01": "/oneWexTest01",
"oneWexTest02": "/oneWexTest02"
}
}
末尾の"mounts"の所を手で編集して追加してもOKです。
編集後はoneWEXの再起動が必要です。
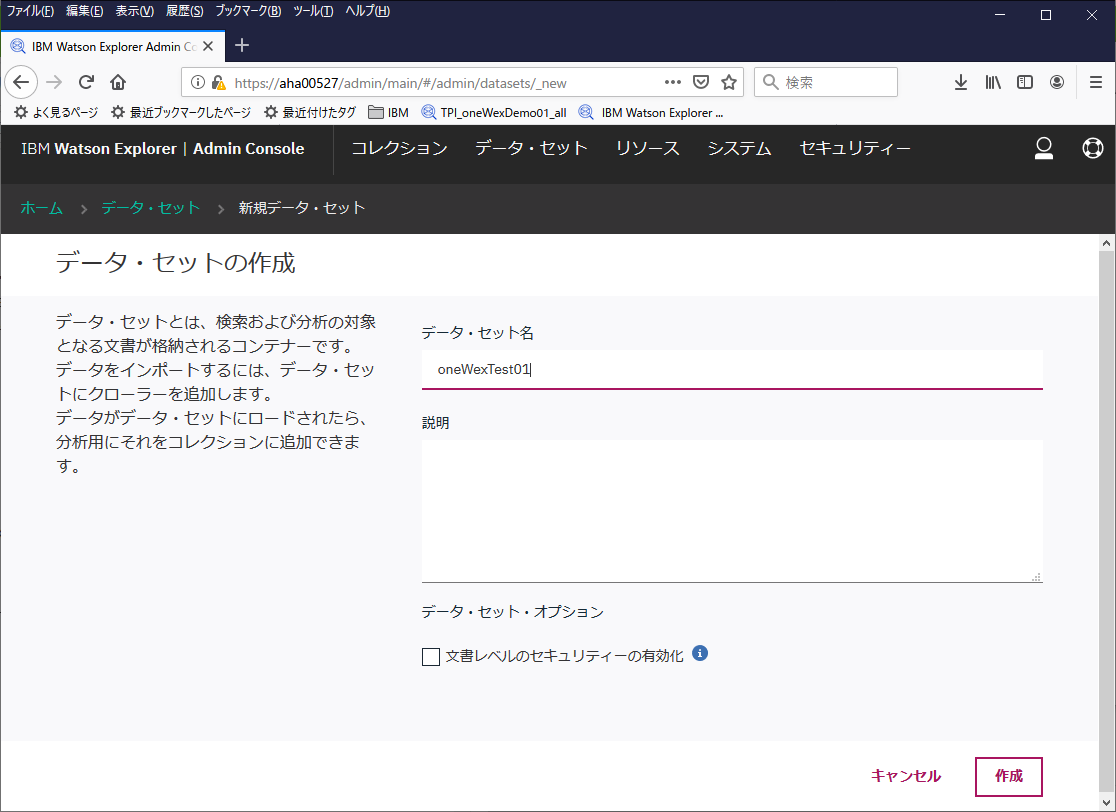
データセットの作成
Admin Consoleにてデータセットの作成を行います。
データセット - データセットの追加
クローラーの追加
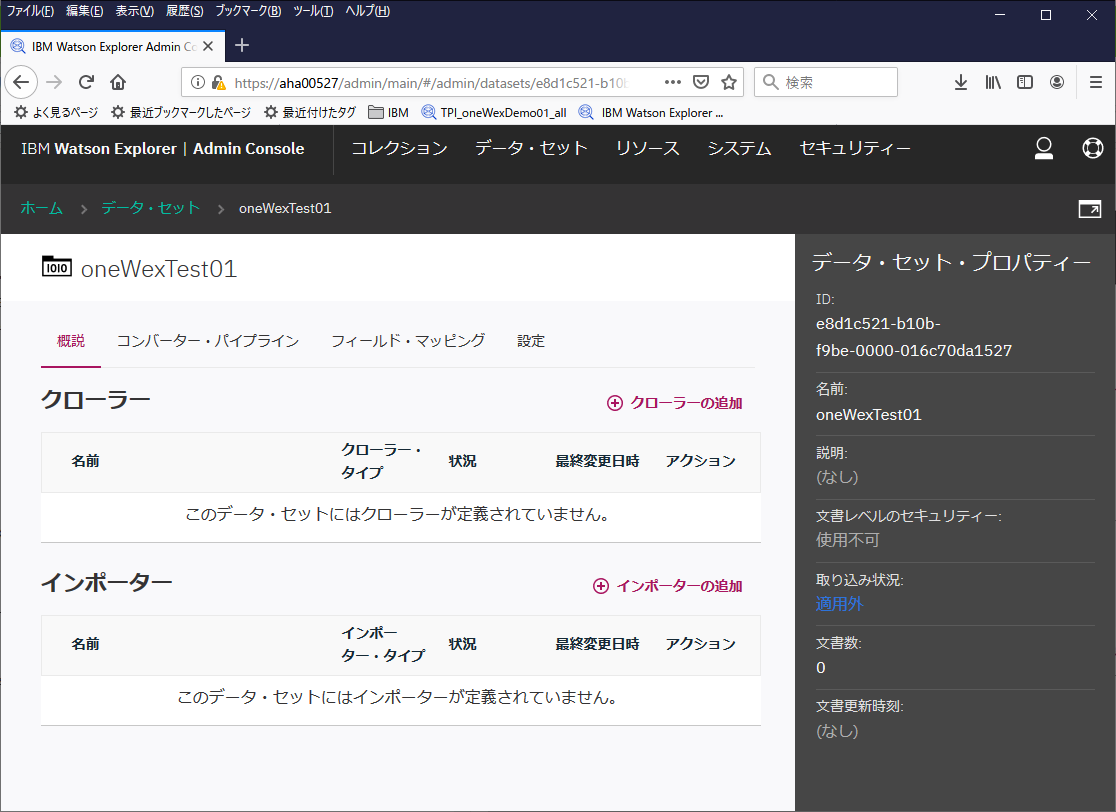
各種クローラーの設定を行う。拡張オプションあたりはとりあえずデフォルト。
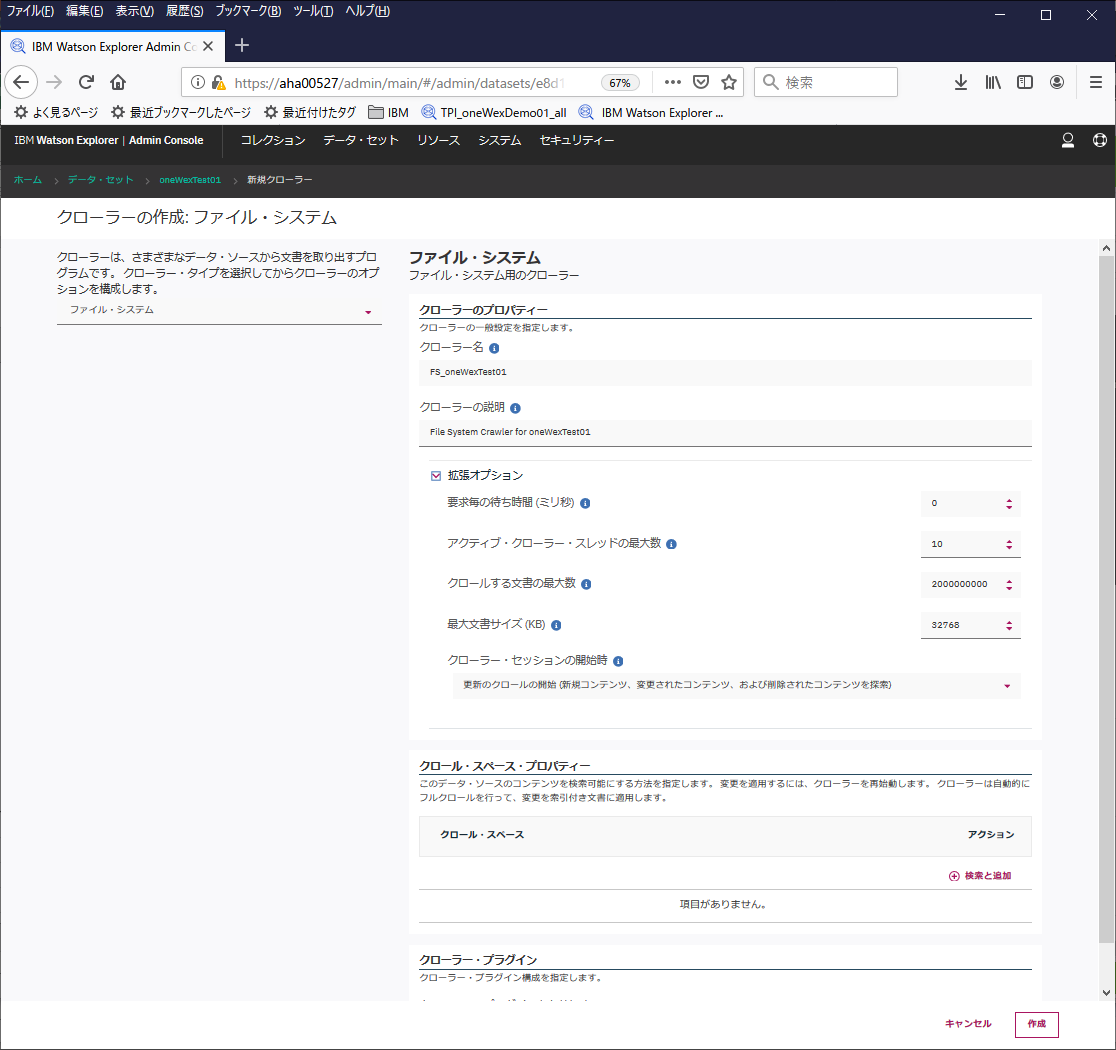
上の画面のクロールスペースのアクションの所の"検索と追加"をクリック
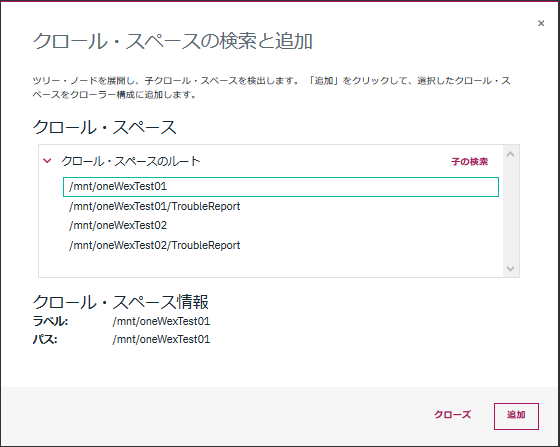
事前準備でマウントしたディレクトリが表示されるので、ここでは/mnt/oneWexTest01を選択。
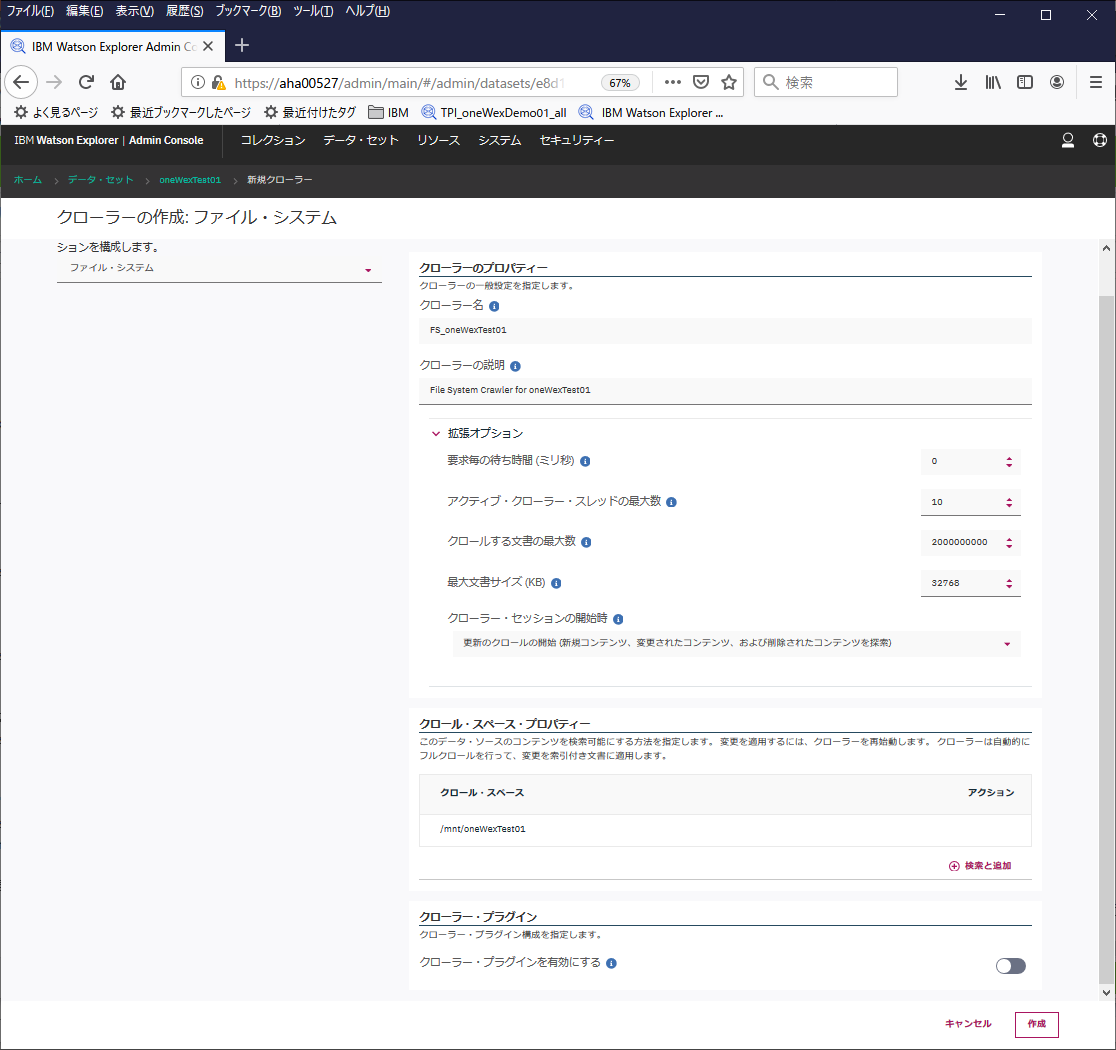
最後の"作成"ボタンを押せばデータセットが作成されます。
次の画面で、"クロールの開始"ボタンを押すと、指定したディレクトリ以下のファイルをクロールしてデータの取り込みが行われます。
ちなみに、今回クロール対象にしているディレクトリ下には、以下のようなディレクトリ構成で、3つだけダミーのファイルを置いています。
[root@test11 /oneWexTest01]# ls -laR
.:
合計 4
drwxr-xr-x. 3 root root 27 8月 8 19:30 .
dr-xr-xr-x. 22 root root 4096 8月 8 18:35 ..
drwxr-xr-x. 5 root root 63 8月 8 19:31 TroubleReport
./TroubleReport:
合計 0
drwxr-xr-x. 5 root root 63 8月 8 19:31 .
drwxr-xr-x. 3 root root 27 8月 8 19:30 ..
drwxr-xr-x. 2 root root 53 8月 8 19:31 チーム01
drwxr-xr-x. 2 root root 53 8月 8 19:31 チーム02
drwxr-xr-x. 2 root root 53 8月 8 19:31 チーム03
./TroubleReport/チーム01:
合計 56
drwxr-xr-x. 2 root root 53 8月 8 19:31 .
drwxr-xr-x. 5 root root 63 8月 8 19:31 ..
-rwxr-xr-x. 1 root root 56832 8月 8 19:31 障害報告書サンプル20190711.doc
./TroubleReport/チーム02:
合計 56
drwxr-xr-x. 2 root root 53 8月 8 19:31 .
drwxr-xr-x. 5 root root 63 8月 8 19:31 ..
-rwxr-xr-x. 1 root root 56320 8月 8 19:31 障害報告書サンプル20190724.doc
./TroubleReport/チーム03:
合計 56
drwxr-xr-x. 2 root root 53 8月 8 19:31 .
drwxr-xr-x. 5 root root 63 8月 8 19:31 ..
-rwxr-xr-x. 1 root root 56320 8月 8 19:31 障害報告書サンプル20190724.doc
クロールが完了するとこんな感じになります。
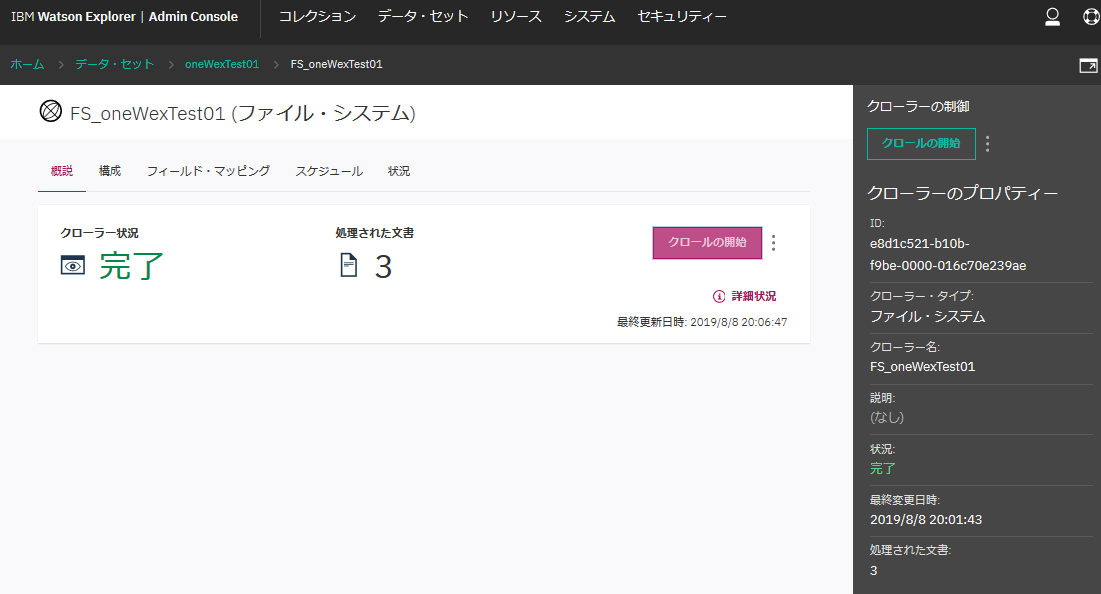
きちんと3件の文書が取り込まれたことが分かります。
作成されたデータセットの、"フィールドマッピング"のタブを見てみます。
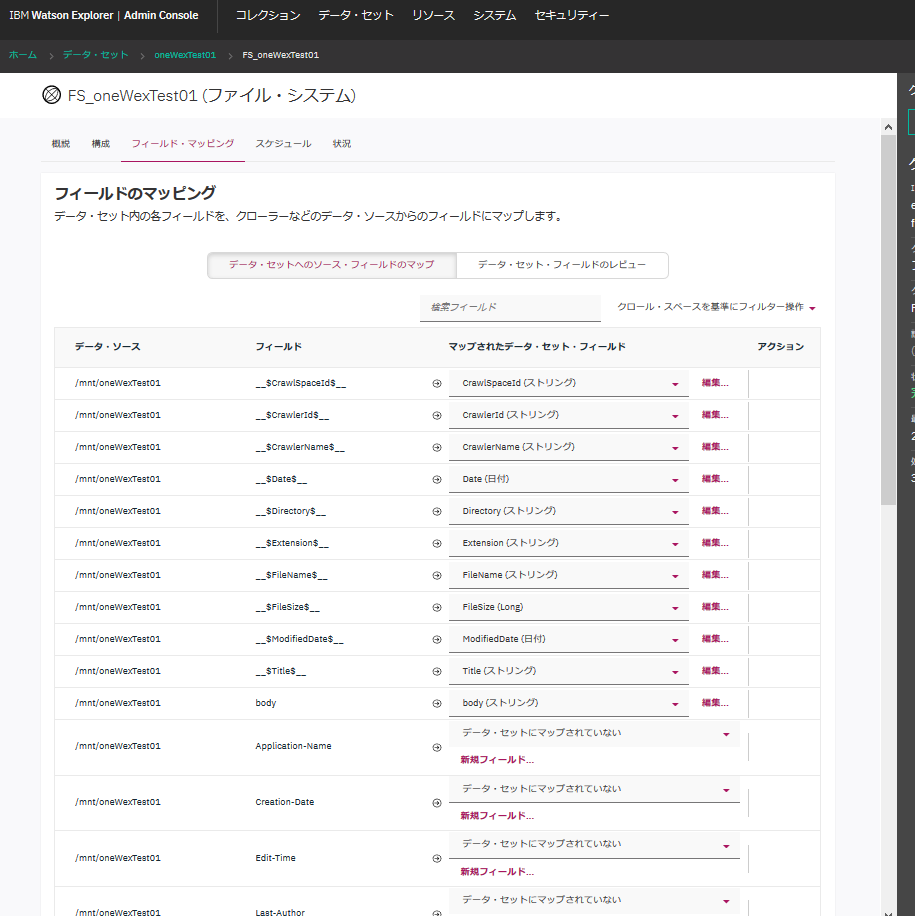
FileName, FileSize, ModifiedDateといったフィールドが自動で認識されて、データが取り込まれるようです。文書の中身はbodyというフィールドに取り込まれます。
何の情報が何のフィールド名として取り込まれるのかは、クローラーの種類によって微妙に違うようです。この辺りの細かい情報はマニュアルに記載が無さそうなので、色々とやってみるしかなさそうです。(どこかに情報あるならだれか教えてください!)
同様に、oneWexTest02についてもデータセットを作成します。
WindowsServer上のディレクトリにも同じ構造で同じファイルを配置しています。
作成されたデータセットのリストを見るとこんな感じになります。
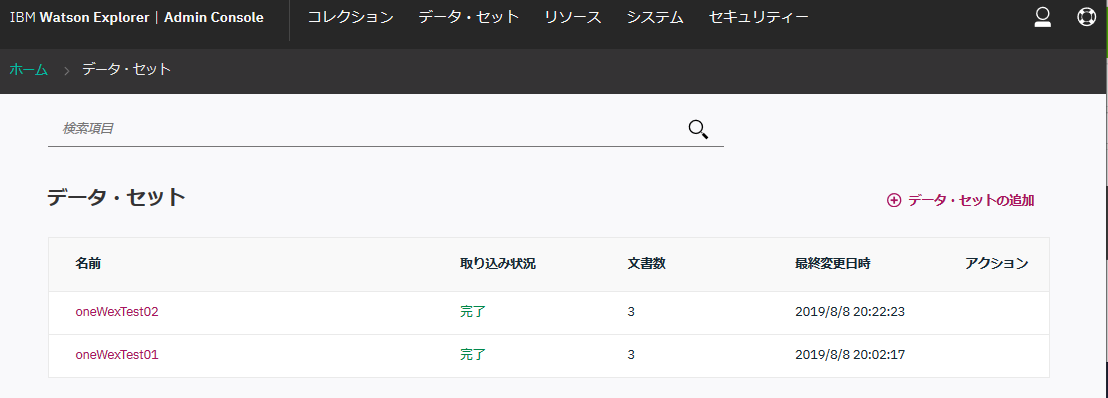
データの解析/加工(コレクションの作成)
取り込んだデータを分析するために、コレクションを作成します。
コレクション - コレクションの追加
とりあえずそのまま"次へ"
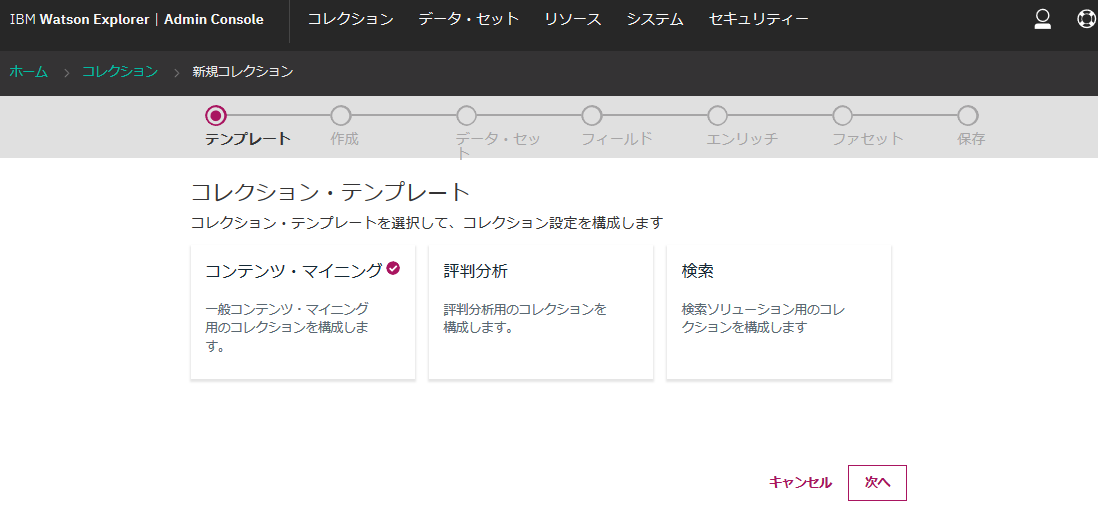
コレクションはデータセットと1:1でマッピングされるので、分かりやすいようにデータセットと同じ名前を付けることにします。
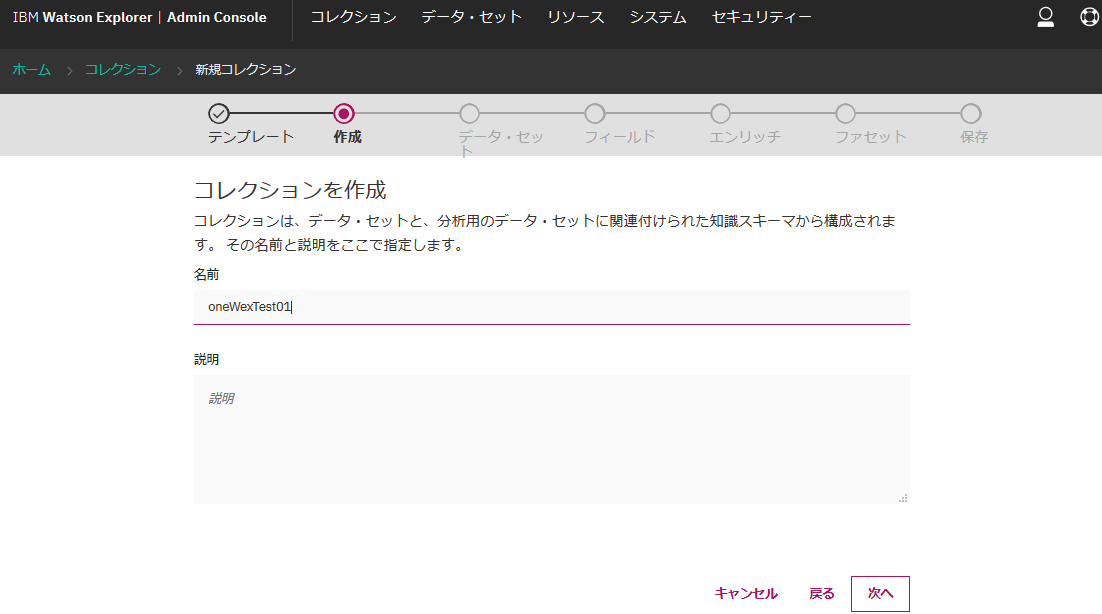
作成済みのデータセットがリストに表示されるので、そこからoneWexTest01を選択します。
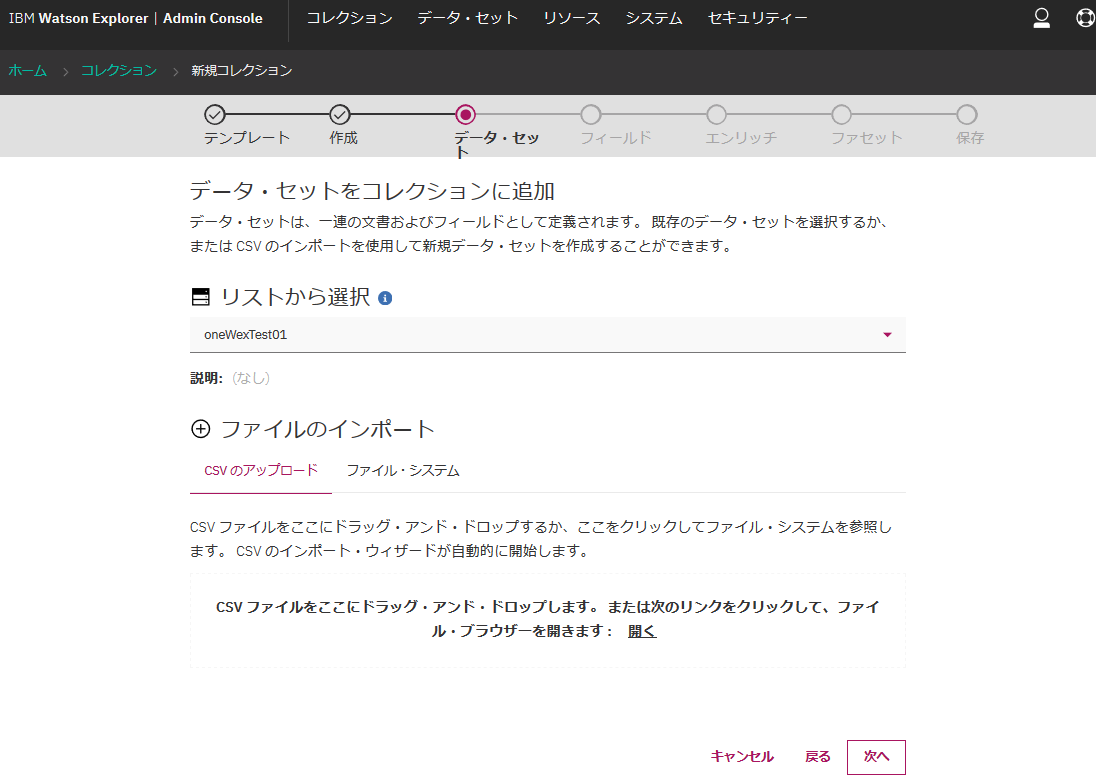
認識されているフィールドの情報のサンプルなどが確認できます。とりあえずそのまま"次へ"
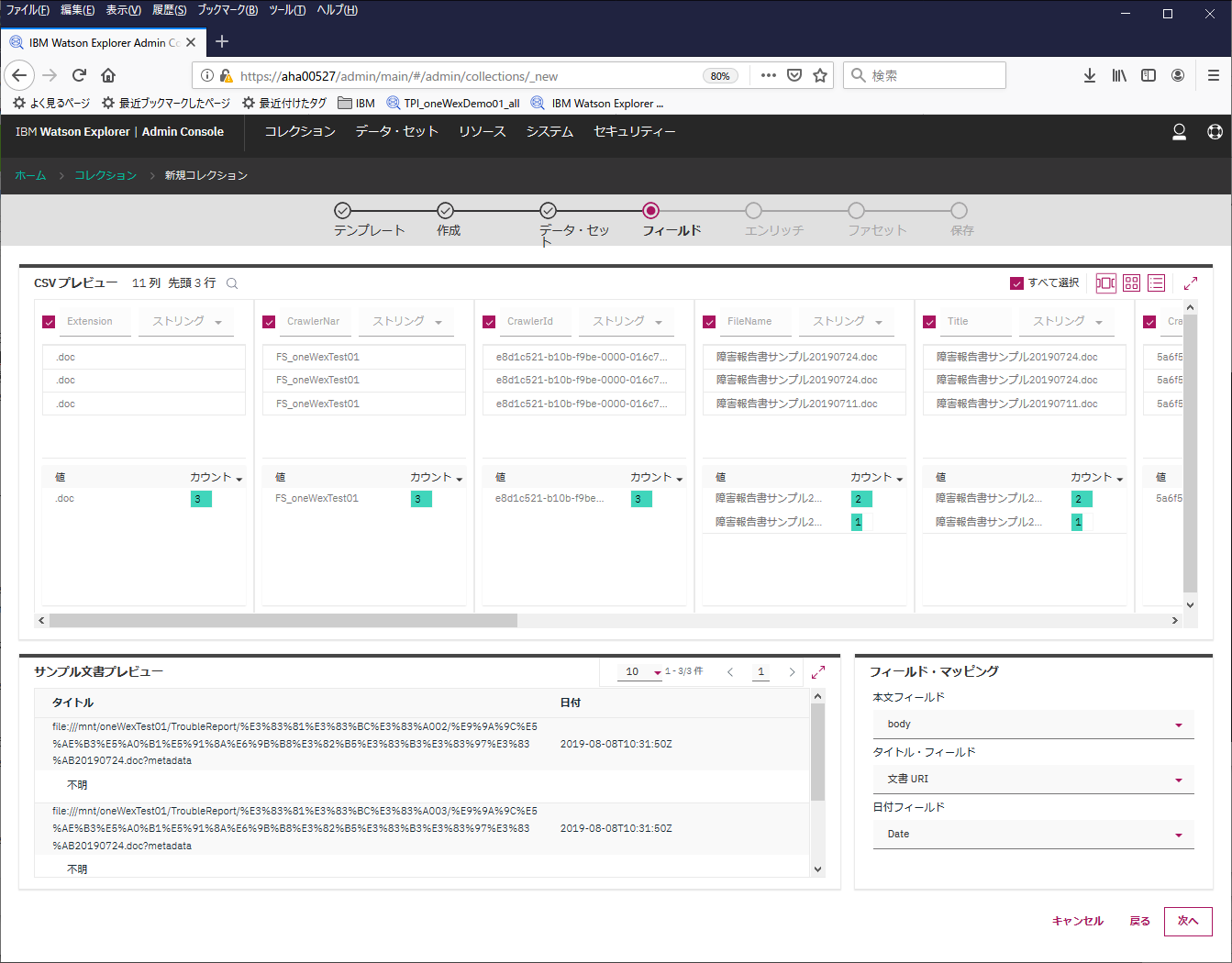
ここでは分析のサポートをする各種設定が行えますが、とりあえず一番下の"言語の識別"に"日本語"を指定して、あとはそのままにします。
※"言語の識別"はデフォルトでは自動検出になっています。自動検出のままだと同義語での検索がうまくできないようなので、"日本語"を明示指定しています。ちなみに、V12.0.3からはここに複数の言語指定ができるようになっています。日本語と英語の文書が混在している場合を想定して、両方を指定してみたら、それでもやっぱり同義語検索がうまく動きませんでした。なので、ここは日本語1択とします。こういう細かい隠された制約(不具合???)がたくさんありそうなので、言語の混在とか複雑なケースは要注意と思います。
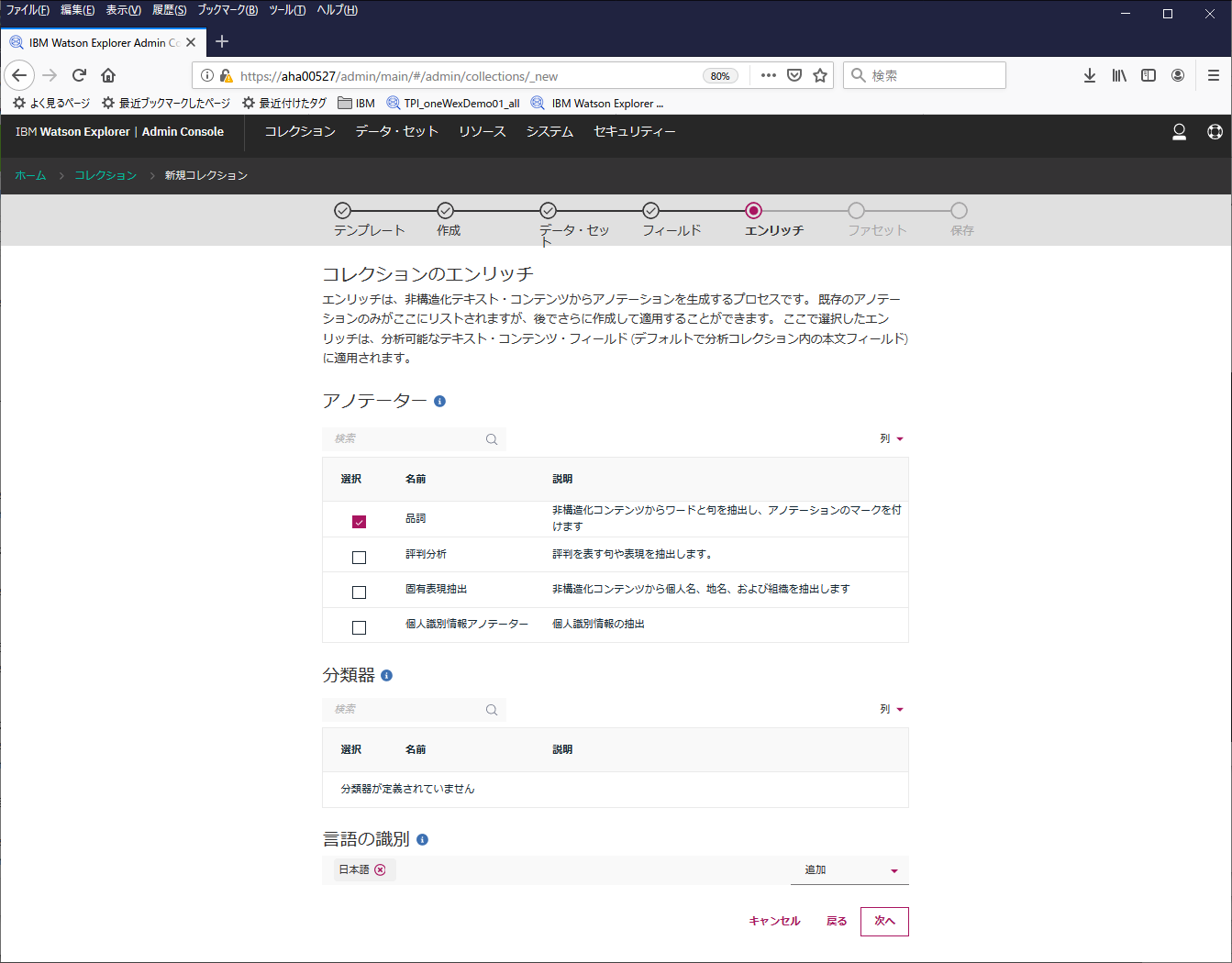
ファセットというものに対する設定です。ここもとりあえずそのまま"次へ"
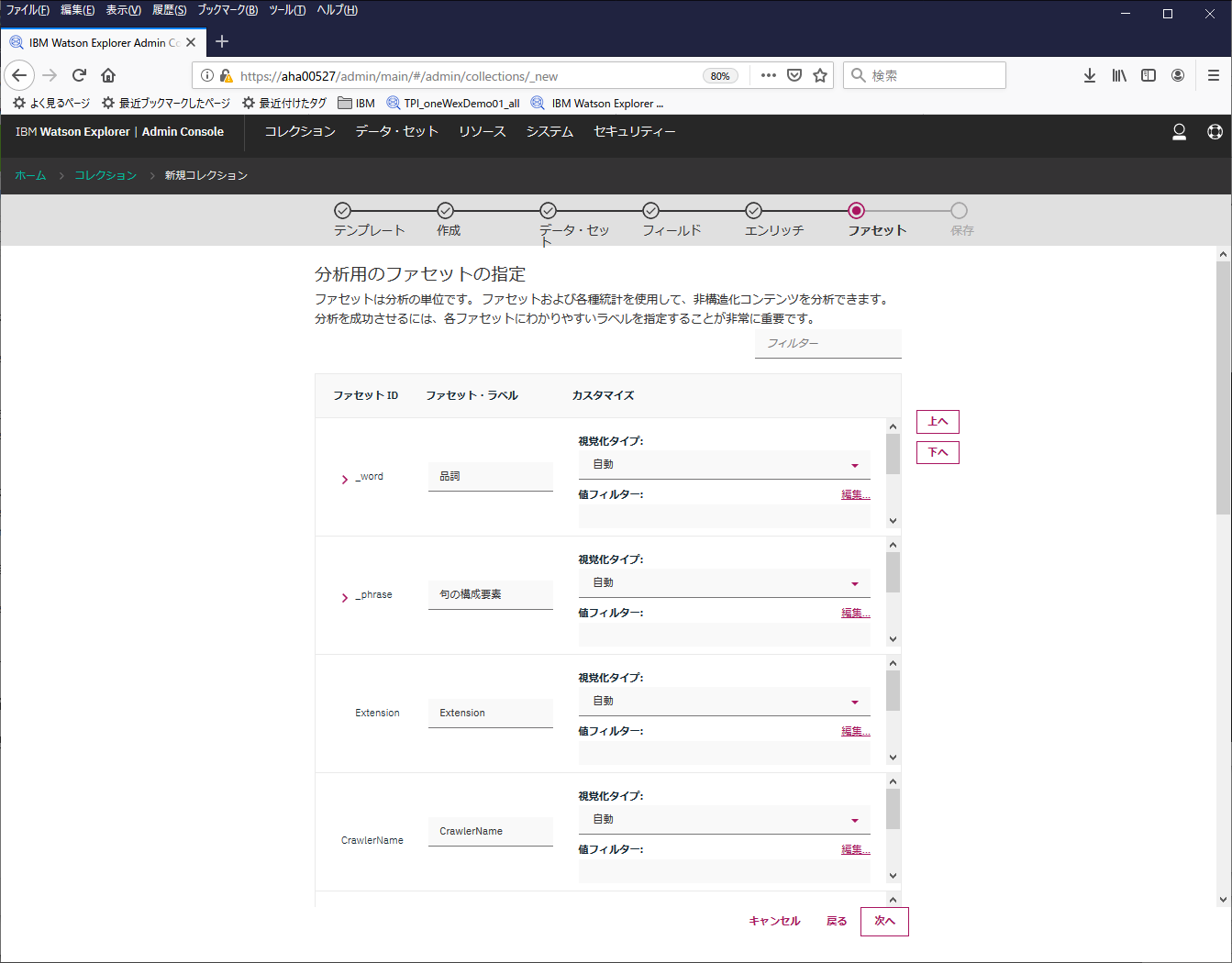
※WEXではファセットという概念が結構重要なようです。ファセットというのはダイヤモンドのカットの切子面という意味で使われるらしく、分析対象のデータをダイヤモンドの原石と見立てて、そのデータを見る時の観点を表すようです。ファセットを変えてみると、すなわち様々な角度からみると、見え方が変わってくる、というイメージのようです。その辺はおいおい...
デフォルトでいくつかのファセットが自動で付いているようです。
最後に、"今すぐ索引付けを実行"にチェックして保存すると、コレクションが作成されて、設定内容に従って分析の下準備となるデータの加工処理が行われます。
索引付けが開始されます。データ量が多かったり、コレクションの設定内容によっては、ここで非常に時間がかかる場合があります。
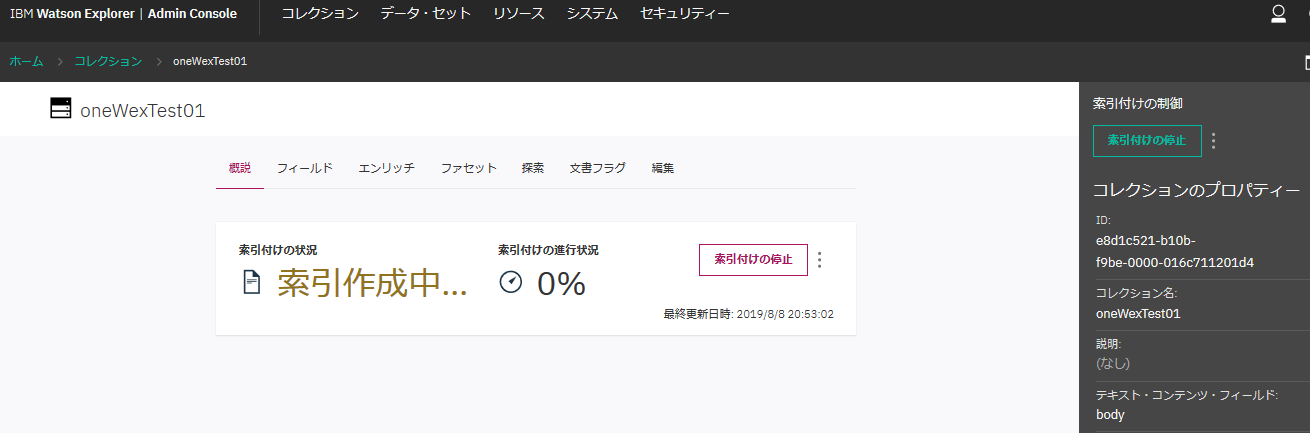
完了!
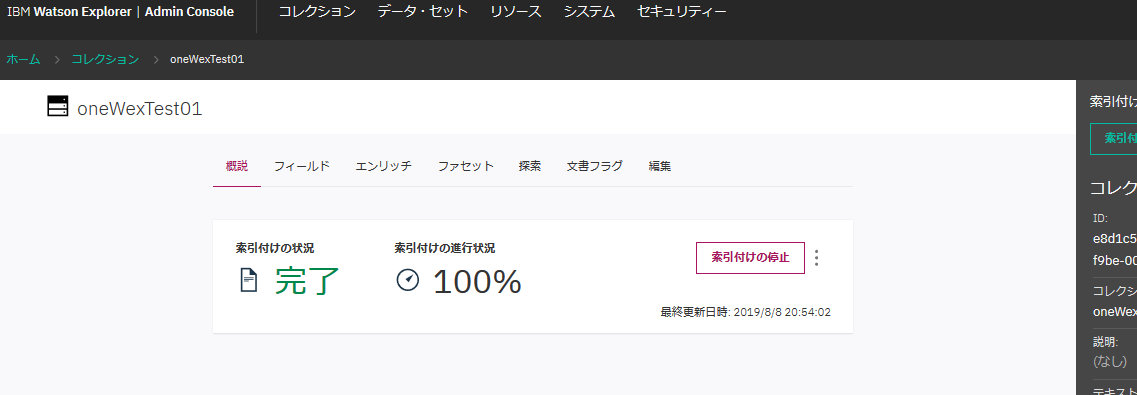
同じように、oneWexTest02もコレクション作ります。
一覧で見るとこんな感じ。
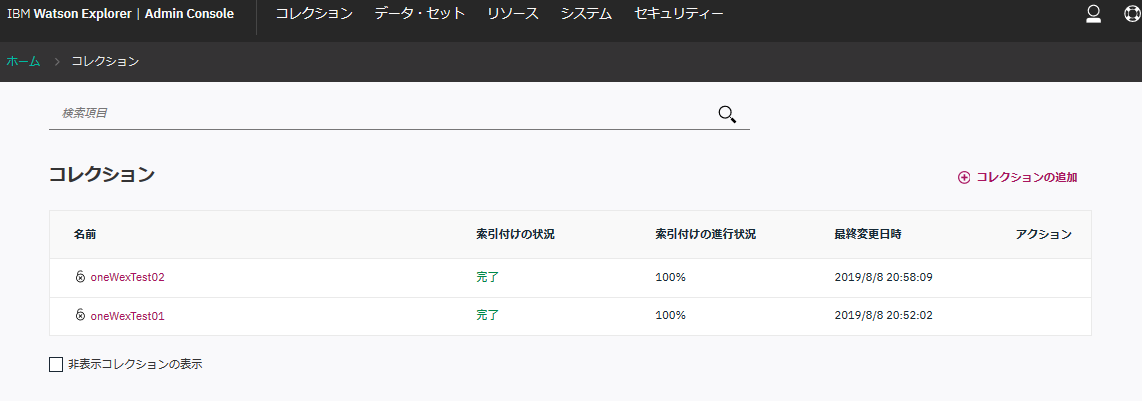
これで、データの検索や分析のための最低限の下準備が整いました。
データの検索/分析操作
ここから、対象データの検索や分析操作をやってみます。
ContentMinerという機能を使います。(https://hostname:443/miner)
索引付けまで完了したコレクションが2つあるのがわかります。分析準備完了となってますね。
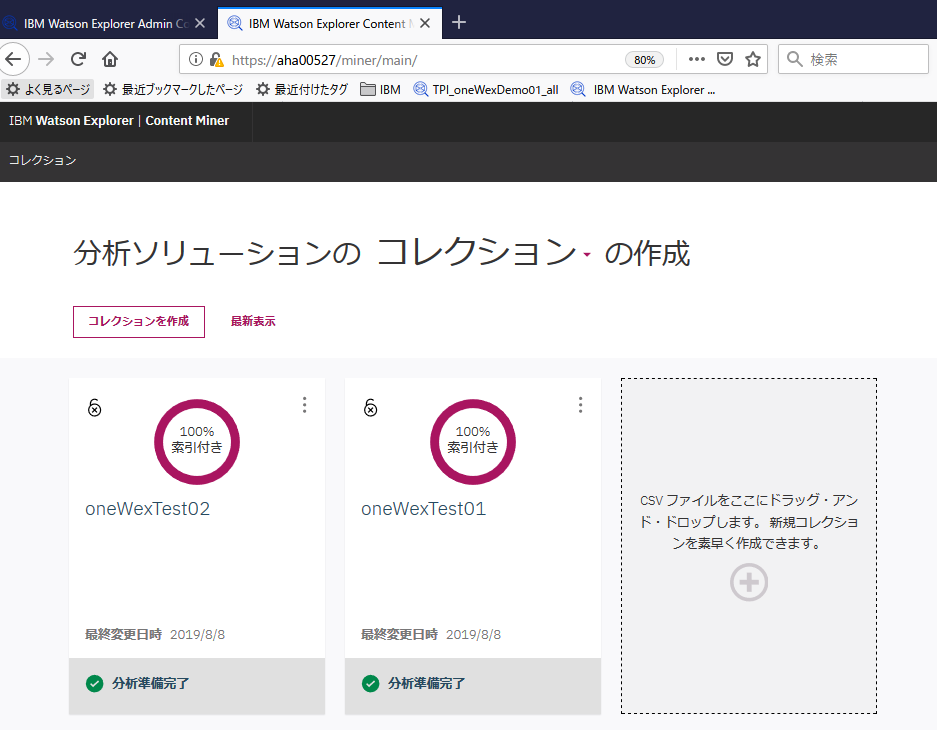
検索/分析操作は"コレクション"の単位で行いますので、oneWexTest01のコレクションを選択してみます。
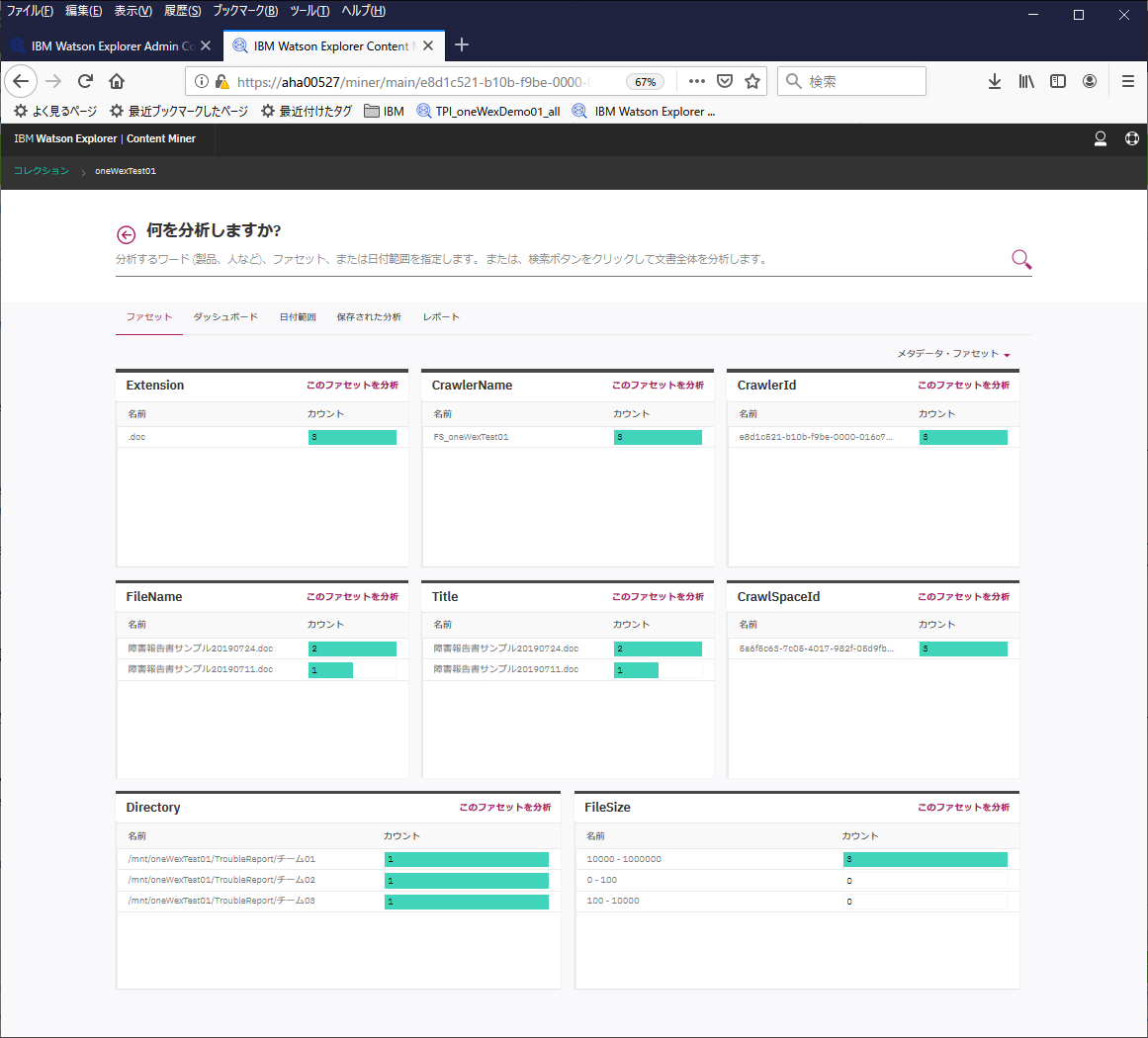
データを取り込むときに自動で認識されたもの(メタデータ: ファイル名やファイルサイズ、更新日付など)がコレクション作成時にファセットとして付与されているので、その辺の軸で集計された情報がならんでいます。
ファイル数が少ないので面白みが無いですが、このディレクトリに配置されているファイルは何件ありますよとか、この範囲のファイルサイズのものは何件ありますよとか。
メタデータファセット => ファセットに切り替えるとこんな感じになります。
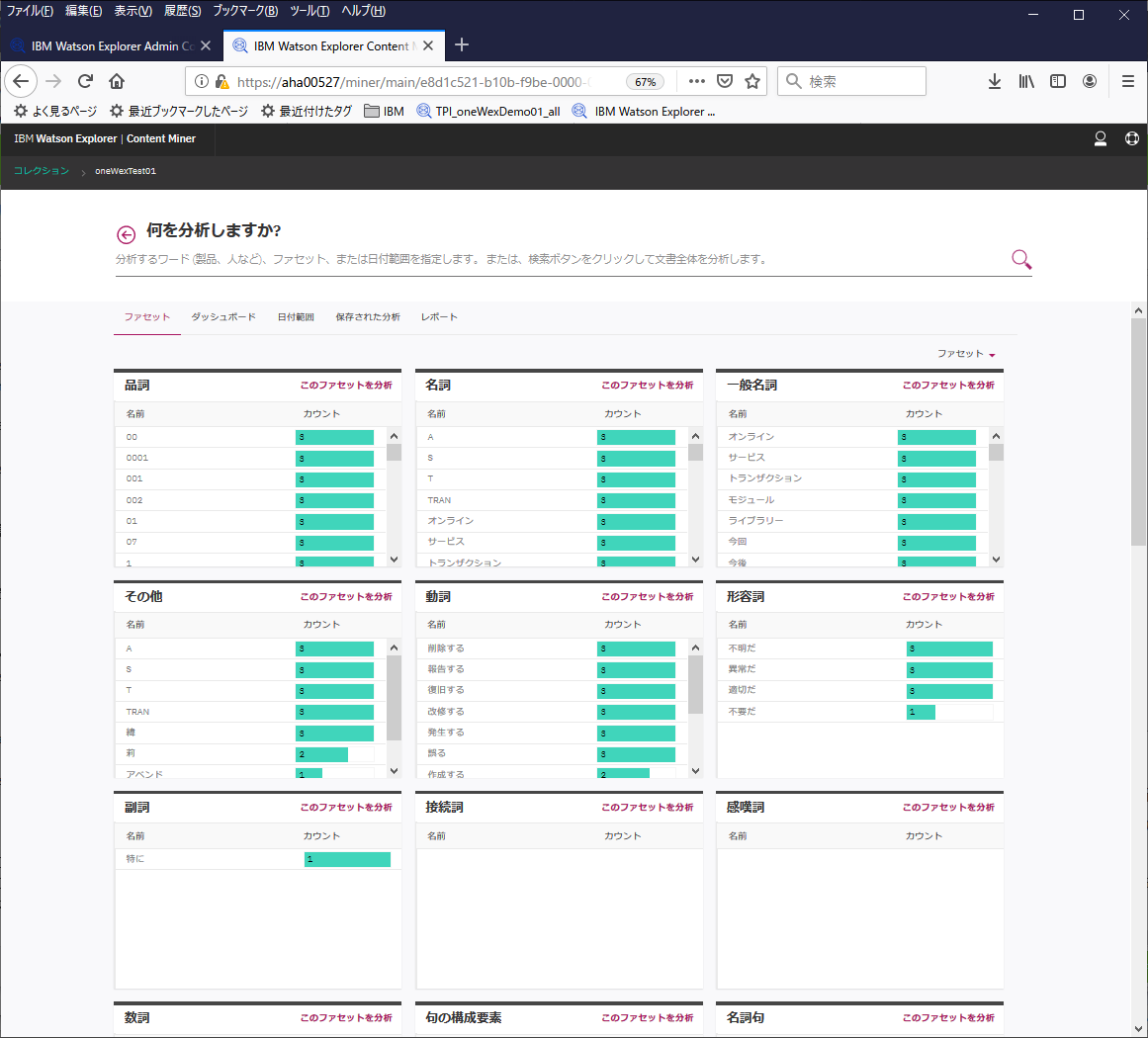
品詞もデフォルトで付いているファセットなので、文章を形態素解析して分析した情報から、こういう名詞が含まれている文書が何件ありますよとか、こういう動詞が含まれている文書が何件ありますよとか、という情報が確認できます。
一番上の検索欄に"アベンド"というキーワードを入れて、検索ボタン(虫眼鏡)を押してみます。
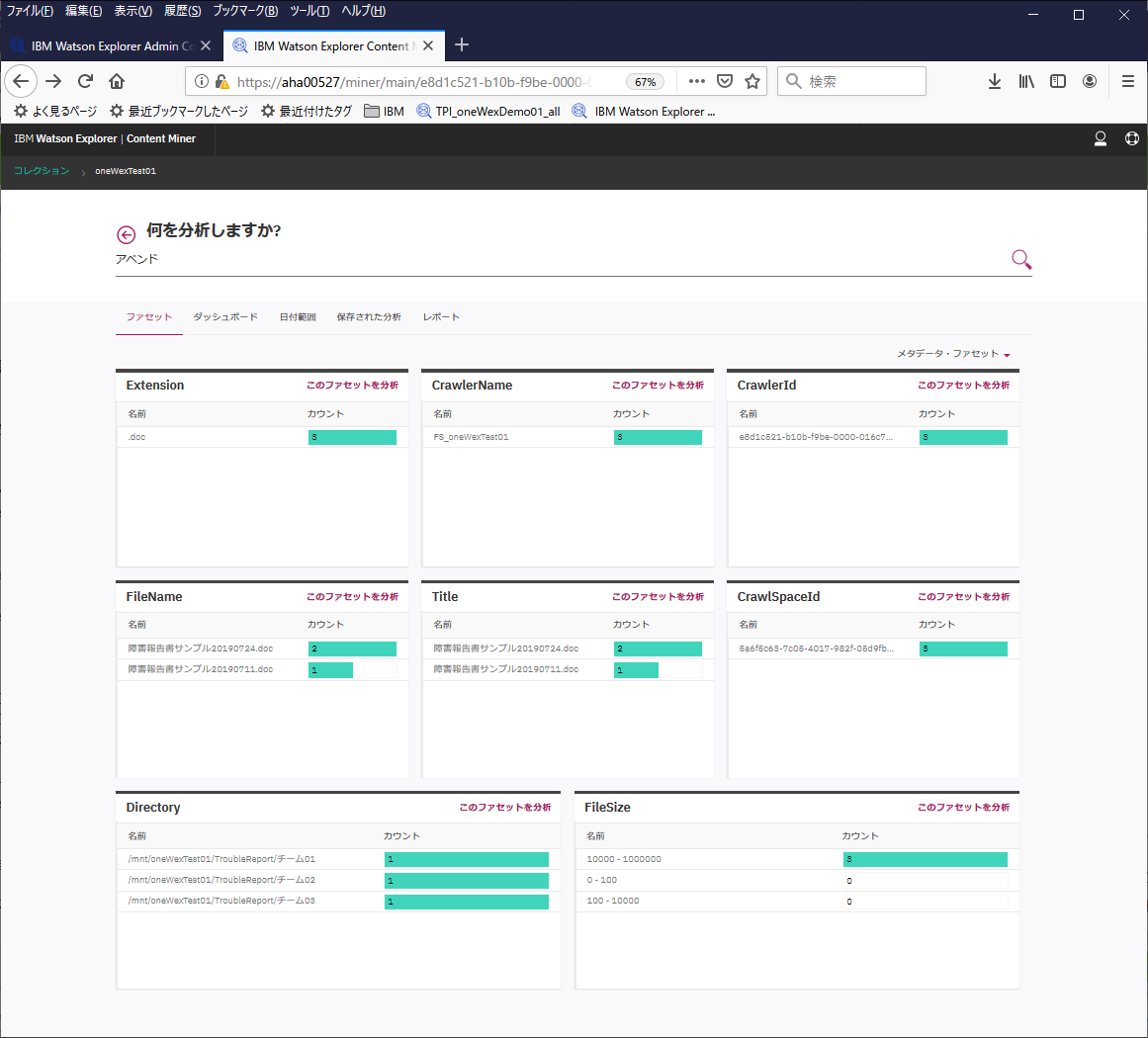
すると、全文書3件のうち、該当するものが1件あって、さらにそこからより掘り下げた分析を行うためのメニューが出てきたりします。
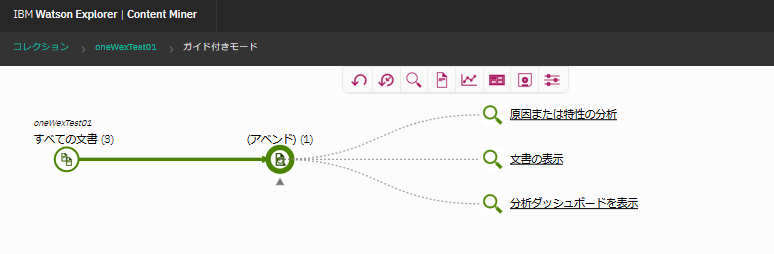
とりあえず、こんな感じで、ファイルを取り込んで操作できるという所まで確認できました。
ContentMinerの分析については今後もう少し掘り下げていければと思います。
補足
クローラー/データセット/コレクションの関係
1つのデータセットの中に複数のクローラーを追加することができますので、いくつかのディレクトリや異なるデータストアにあるものを、まとめて1つのデータセットとして扱うことができます。
一方で、コレクションを作成する時は、1つのデータセットしか指定できないようです。
ディスクのサイズ
対象データ(PDF,Excelなどに保持されている情報)は、一旦データセット作成時にoneWEX上に取り込まれ、コレクションでの索引付けでさらに分析用に加工されたデータが付与されてることになります。
取り込まれる情報は基本的にテキスト情報ということになりますが、データセット作成の際は元のデータと同程度のサイズが消費されることになります。さらにコレクションの索引付けでは対象データやコレクションの設定(アノテーションなど)にもよりますが、元のデータの10~20倍のサイズが消費される場合があるようです。
従って、それなりにディスクのサイズの確保が必要になってきます。
ですが、残念ながら、各データセット/コレクションで、どのくらいディスクを消費しているかはAdminConsoleから確認することはできないようです。
oneWEXはdockerコンテナとして実装されており、取り込んだデータを永続化するためにホストOS上のディスクをマウントして利用しているようです。
[root@test11 /var/lib/docker/volumes/wex12dae]# docker volume ls
DRIVER VOLUME NAME
local wex12dae
[root@test11 /var/lib/docker/volumes/wex12dae]# docker volume inspect wex12dae
[
{
"CreatedAt": "2019-08-09T10:16:02+09:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/wex12dae/_data",
"Name": "wex12dae",
"Options": null,
"Scope": "local"
}
]
これによると/var/lib/docker/volumes/wex12dae/_dataが消費されていくようです。
ここで上げたシンプルなケースでデータセット、コレクションを作成した直後のこのディレクトリ下のtree構造を出力させてみました。
結果はこちらです。
tree_var_lib_docker_volumes_wex12dae_data.txt
で、ここがパンクするとoneWEXの起動すらできなくなってしまうらしく、そうなってしまうと不要なデータセットとかコレクションを削除する術が無く、結構致命的な状況になってしまいます。その割には、ディスクのパンクを抑制するような機能はなさそうなので、泥臭い回避策になってしまいますが、このファイルシステム上にダミーのファイル(数GBとかそこそこサイズの大きなファイル)を置いておいて、パンクしたら一旦そのダミーファイルを削除してoneWEX起動し、oneWEX上の余分なデータセット/コレクションを削除するってことをできるようにしておくとよいでしょう。。
Linux - Windowsサーバー接続
この記事の例では、LinuxからWindowsサーバー間のマウント処理をNFSを使って実現しましたが、Windows共有(SMB)でもマウントできました。
参考: Ubuntu から Windows の共有フォルダをマウントして利用する
その場合のWindowsServer側のポートは445/TCPが使われます。
参考: Windowsネットワークの基礎:第7回 ファイル共有プロトコルSMBの概要
Tips
- ファイルシステムパンクに備えて、事前に、
/var/lib/docker/volumes/wex12dae/_dataと同じファイルシステムに、1GBくらいの大きなダミーファイルを配置しておくとよいでしょう。 - クロール対象のファイル名や配置するディレクトリ名にはなるべく日本語名はつかわずにアルファベットのみにしておく方がよいでしょう(ファイル名は既存のものを想定しているので難しいですが、ディレクトリについてはクロール用に再配置することも大いにあり得るので、その場合は英語名にしておいた方が後々不都合が少ないです)。
- コレクション作成時のエンリッチのカテゴリの「言語の識別」では、デフォルトの"自動検出"ではなく"日本語"のみを指定しておくのがよいでしょう。