はじめに
oneWEXを使ってみた時のメモです。
おさらい
Watson Explorer の概要
Watson™ Explorer は、検索とコンテンツ分析を組み合わせることによって、ユーザーが非構造化情報を見つけて理解できるよう支援します。ユーザーはその情報を使用して、作業を効率化し、急所となる時点でより的確で信頼できる意思決定を行うことができます。 Watson Explorer では、以下のことができます。
- コグニティブ探索: すべての組織のデータを形式、格納場所、管理場所にかかわらず、安全に接続したり、検索したり、探索したりできます (既知の項目の検出)。
ここでは、oneWEXの"検索/探索"という機能に着目し、ContentMinerを使って文書の検索がどのように行えるかをやってみたいと思います。
("分析"の辺りはまた別途。)
関連記事
インストール関連
oneWEX導入メモ / Ubuntu編
oneWEX導入メモ / RHEL7.6 オフライン編
検索関連
oneWEX検証メモ - (0) 概要理解
oneWEX検証メモ - (1)ファイルシステムクローラーによるデータの取り込み / データセット、コレクションの作成
oneWEX検証メモ - (2)Windowsファイルシステムクローラーによるデータの取り込み
oneWEX検証メモ - (3)ContentMinerによる文書の検索
oneWEX検証メモ - (4)ApplicationBuilderによるWebアプリの作成と文書の検索
分析関連
oneWEX検証メモ - (5)ContentMinerによる分析 / ガイド付きモード
oneWEX検証メモ - (6)ContentMinerによる分析 / 各種"ID情報"をベースとした分析
API関連
oneWEX検証メモ - (7)REST API
全体像
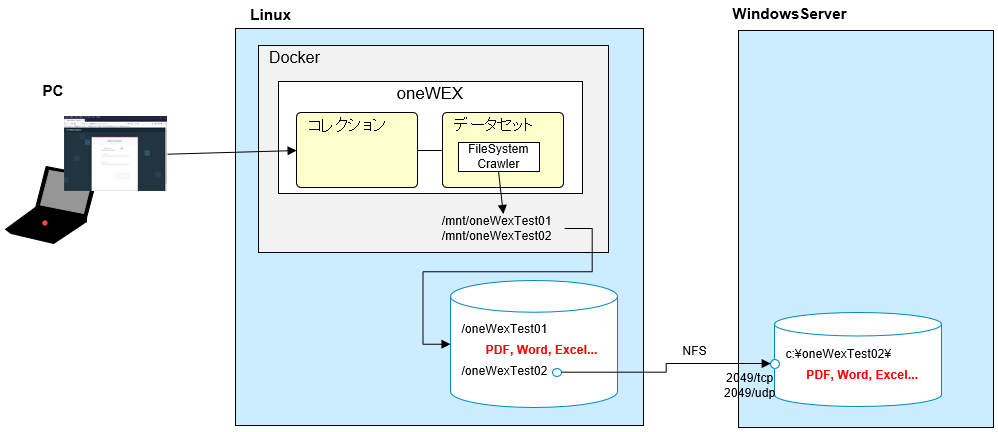
文書の検索/探索のバリエーションを試す
検索(search)、探索(explore)という2つの用語が使われていますが、前者はキーワードを入れてそれに関連する文書を見つける、後者は他の様々な切り口から対象を絞り込んでいって目的の文書にたどり着く、というイメージでしょうか。
とりあえず、前回までの手順で作成したデータに、検証用のExcelファイルも2つほど追加して、検索/探索を試してみます。
以下のTroubleReport以下のWordファイルx3、および、Case01以下のExcelファイルx2 の合計5ファイル取り込んだ状態で試します。
https://github.com/tomotagwork/WEXTest01/tree/master/SampleFiles
基本的な挙動はいずれのコレクションでも同じはずなので、ここではoneWexTest02(NFS接続構成)のコレクションを利用します。
キーワード検索 / 基本
単純に「トランザクション」というキーワードを入力して検索してみます。
目的としては、「トランザクション」というキーワードを含む文書をリストアップしたい。
ContentMinerでコレクションを選択し、一番上のフィールドに「トランザクション」を入力して虫眼鏡ボタンを押します。
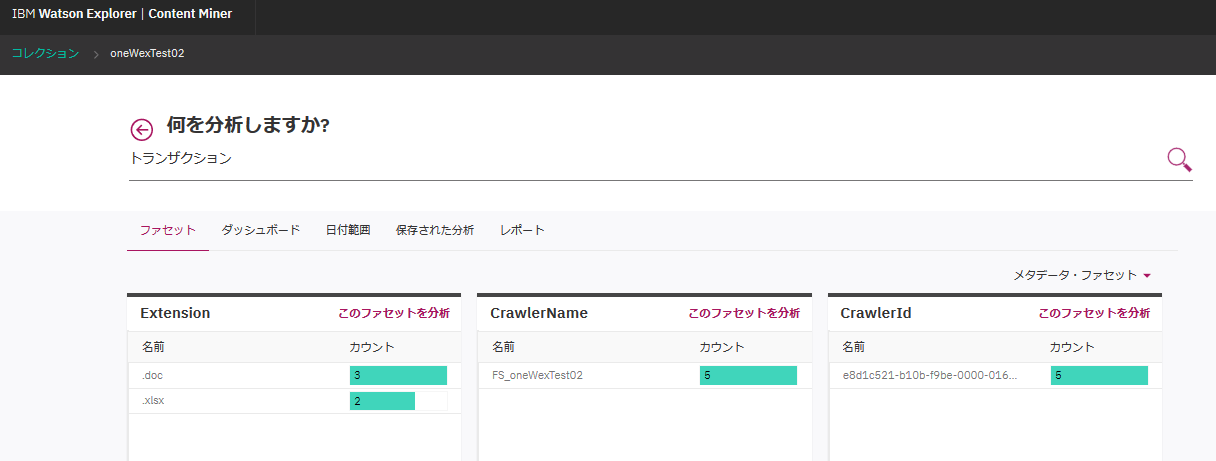
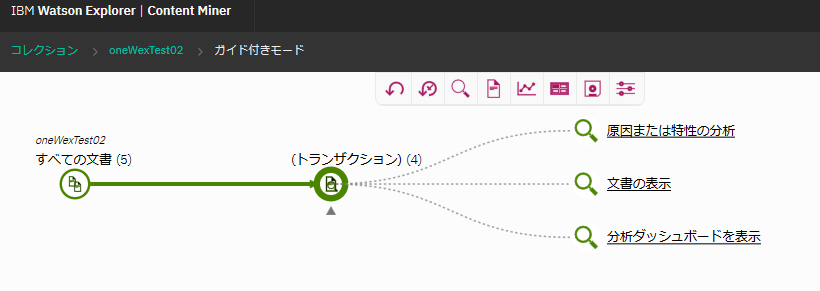
全体で5件のファイルがあるうちの、4件ヒットしたことが分かります。文書の表示をクリックします。
キーワードを含む文書の一覧が表示されました。文書のURIと指定したキーワードを含む前後の文章も合わせて表示されています。Google検索っぽい結果ですね。
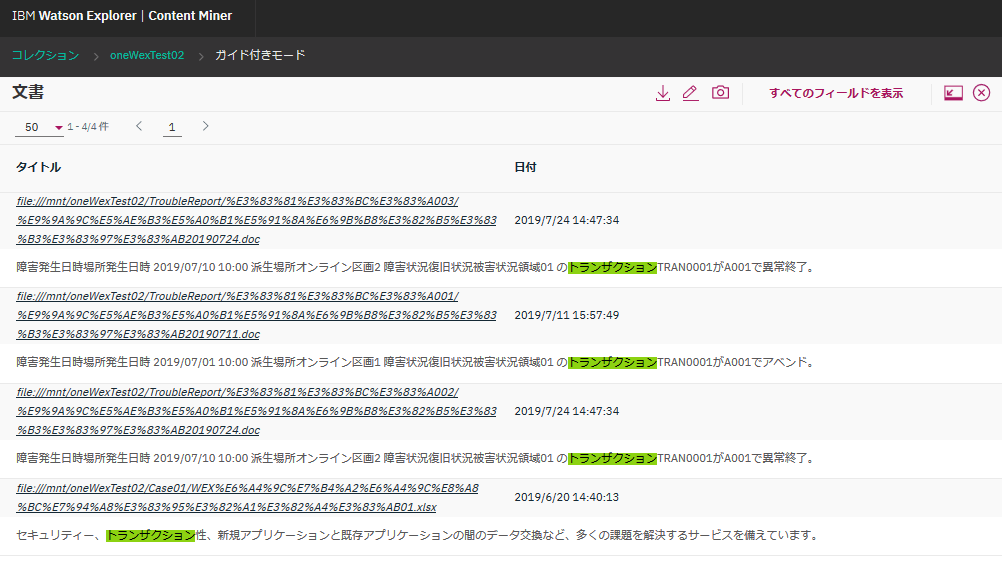
ただ、ディレクトリ名やファイル名に日本語が含まれていると、それらはURLエンコードされてしまうらしく、上の画像のようによくわからない表示になってます。(この画面をカスタマイズできるのかは不明。)
上のリストのURIの1つ(1番下のExcelファイル)をクリックしてみると、こんな感じで対象ファイルの中身が確認できます。
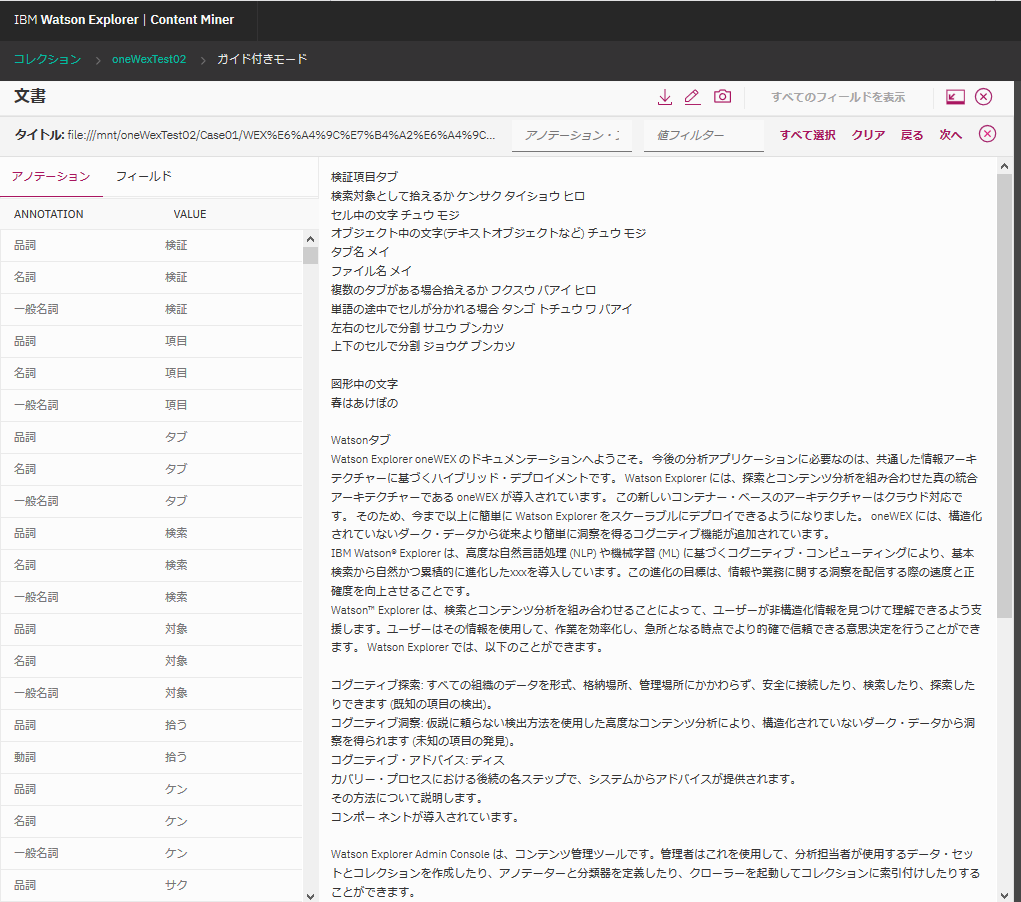
Excelから文字列情報を抽出して本文として解釈しているイメージでしょうか。
ちなみに元のExcelファイルはこんなイメージです。
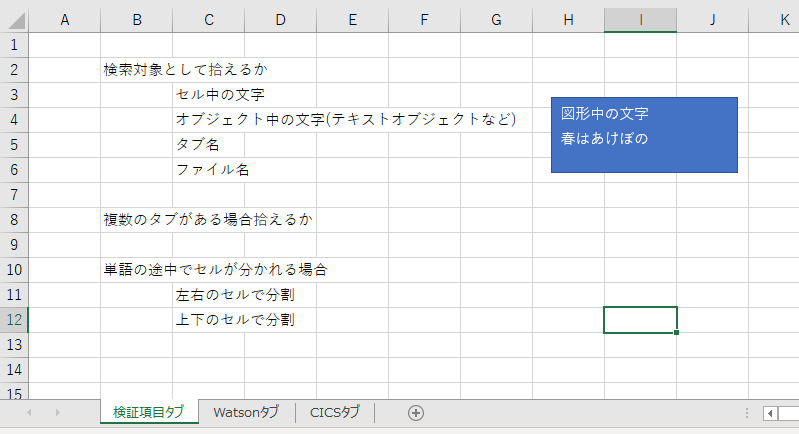
先頭のタブの情報には、なぜか実際のExcelファイルには存在しないカタカナの情報も混在しているようです("ケンサクタイショウヒロ"など)。この挙動は謎です。
ただ、タブ名や図形オブジェクト中の文字列もbodyに取り込まれているため、検索対象にはなり得そうです。
ファイル名自体はbodyに含まれるので検索対象にはならないようです。
また、1つの単語が左右や上下に連続しているセルに分割されてしまう場合、そこで文字列が分割されてしまうため、連続した文字列としては判別してくれません(まぁこれはだいたい想像通りです)。
※追記
作成されたコレクションをAdmin Consoleで見ると、「フィールド」タブに「フリーテキストで検索可能」というチェックボックスがフィールド単位にあります。デフォルトではbodyにしかチェックが入っていないので、例えばFileNameフィールドにチェック入れてあげれば、ファイル名も検索対象になってくれると思われます(検証はできてないですが)。
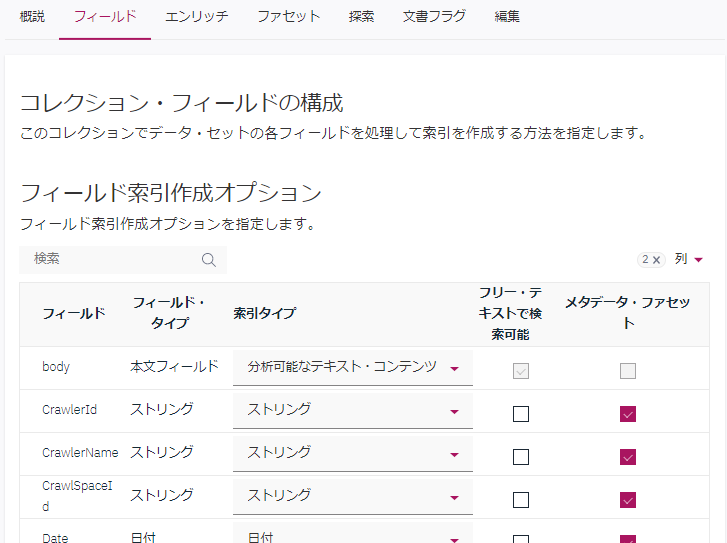
さて、本来の目的は、簡単に対象となるファイルにたどり着きたいということです。キーワードを元に、対象となるファイル探したら、当然そのファイルを開きたい訳なんですが、どうやらこのContentMinerのUIには、対象のファイルをブラウザ経由でダウンロードする仕組みが提供されていなさそうです。かゆい所に手が届かない感じ。
なんで??? なんで??? Webサーバー機能あるなら仮想ディレクトリからそのファイル辿れるようにしてくれればブラウザからファイルダウンロードできるんじゃね? そのくらいやってくれてもいいんじゃないの? 手抜きなの? 意地悪なの? ファイルを扱うのはそもそも眼中に無いの?
気づいていないだけでそういう機能はあるはずだと思って有識者に聞いてみたところ「それはWEXの役割じゃない」と普通に言われてしまったので、やっぱりできないんでしょう...。ちなみにOSSのFESSでは普通にできます(参考:Fess環境構築メモ)。
ということで、対象のファイルにたどり着いたはいいが、いざそのファイルを開こうと思うと、正直困ります。
URIからファイルの配置場所とファイル名は判断できるので、まず、URLエンコーディングされている文字列をどうにかしてデコードしてあげて、そのうえで、LinuxもしくはWindowsから個別にファイルを入手する、ということをしなければなりません。つまり、ファイルを共有するための仕組みは別途用意しておく必要があるということのようです(FTP, SCPなどでファイルを入手するのか、Windowsにリモートデスクトップで接続してファイルをコピーするのか、Webサーバーを別途立ててブラウザ経由でアクセスできるようにするのか...)。
一応、対象ファイルを選択した後、"フィールド"というタブを選択すると、各フィールド情報が参照でき、その中にFileNameのフィールドがあって、この部分については日本語名称が確認できました。パスは相変わらずエンコードされたままですが。
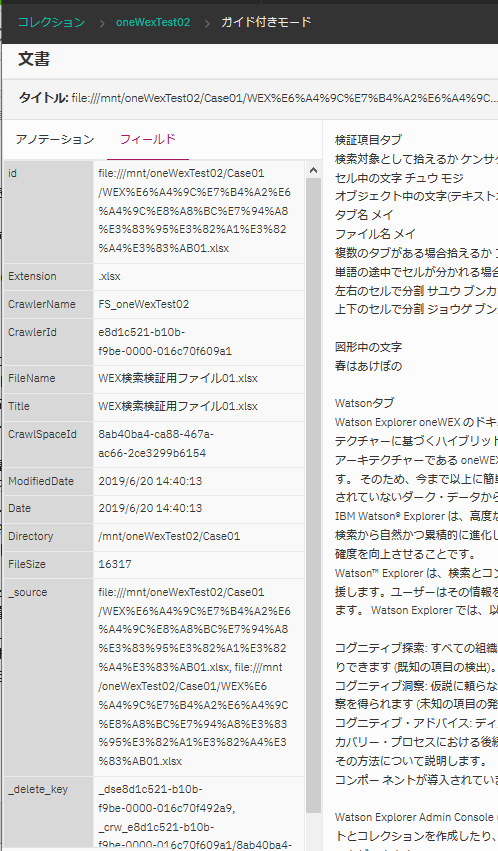
んー、厳しくないか、これ。
とりあえず一旦忘れて次にいきます。
キーワード検索 / 複数条件指定
AND, OR, NOTの指定ができるようです。
| キーワード指定 | 検索内容 |
|---|---|
| トランザクション | "トランザクション"を含む文書 |
| トランザクション AND CICS | "トランザクション"を含み、かつ"CICS"を含む文書 |
| トランザクション OR てすと | "トランザクション"を含む、もしくは"てすと"を含む文書 |
| トランザクション AND (NOT CICS) | "トランザクション"を含み、かつ"CICS"を含まない文書 |
「トランザクション AND CICS」での検索結果例
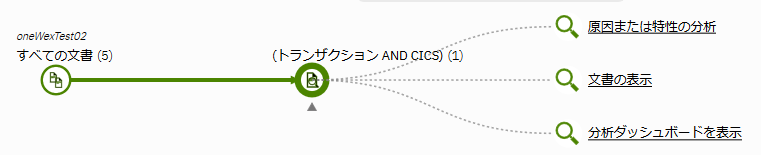
ファセット値の検索
上の検索は、いわゆる本文(body)の内容の検索でしたが、ファセット値を指定した検索もできるようです。
例えば、ファイル名はbodyに含まれないので上の検索の対象とはなりませんが、FileNameファセットとして認識されているので、FileNameファセットを明示的に指定すれば検索可能です。
「<ファセット名>:<ファセット値>」というような指定方法をすると、特定の値を持つファセットを検索できます。また、ファセット値にはワイルドカード"*"も指定できます。
例えば、ファイル名として"障害報告"という文字列を含むファイルを探索したい場合、「Filename:*障害報告*」と指定して検索すればよいです。
また、「Directory:*チーム01* AND FileName:*障害報告*」と指定すれば、ディレクトリ名に"チーム01"を含み、かつ、ファイル名に"障害報告"を含む文書の検索が行えます。

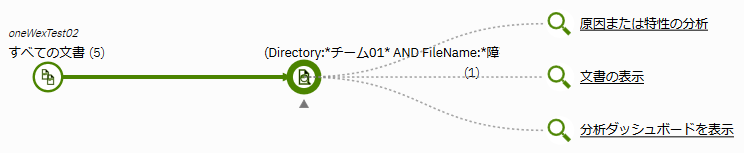
メタデータファセットから探索
コレクションを開いたときに下に表示されているファセットのファセット値を選択してみます。
例えば、Extensionの.xlsxをクリックします。すると、検索窓に.xlsxが追加されます。
これは、Extensionが.xlsxのものを抽出する、つまりExcelファイルを抽出する、ということになります。
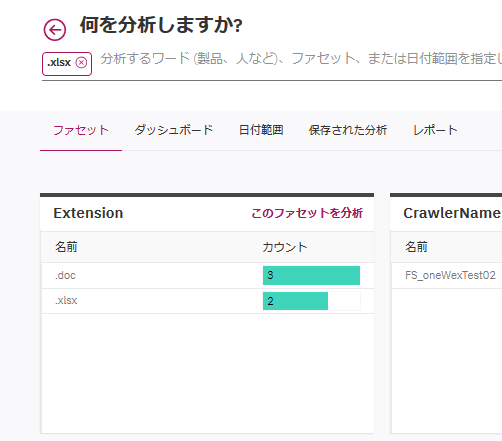
これで検索ボタンを押せば、Excelファイルが抽出されます。
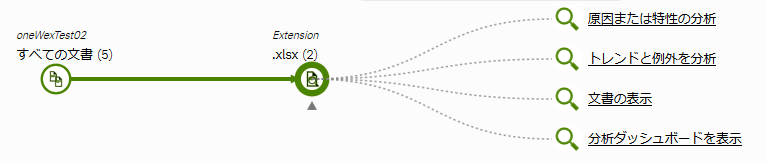
文書の表示をクリックすれば先の例と同じように対象ファイルのリストが表示されます。
複数のファセットを選択すれば、AND条件で絞り込みが行えます。
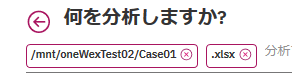
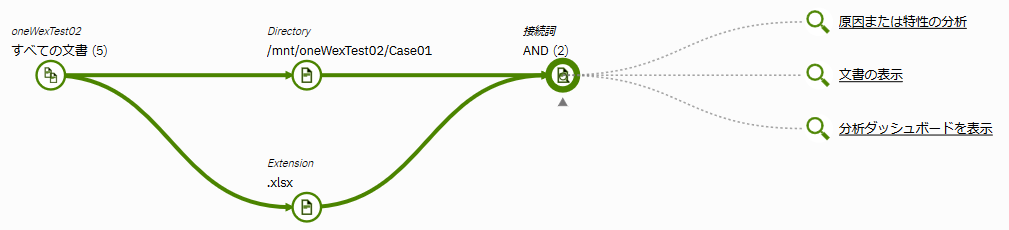
例えば、以下の例では、Directoryから/mnt/oneWexTest02/Case01を選択し、Extensionから.xlsxを選択しています。これはmnt/oneWexTest02/Case01ディレクトリ下にある.xlsxファイルを抽出する、ということになります。
品詞ファセットから探索
デフォルトだと、品詞に関するファセットが自動で付与されています。右上のプルダウンからファセットを選択すると、品詞に関するファセットの一覧が表示されます。
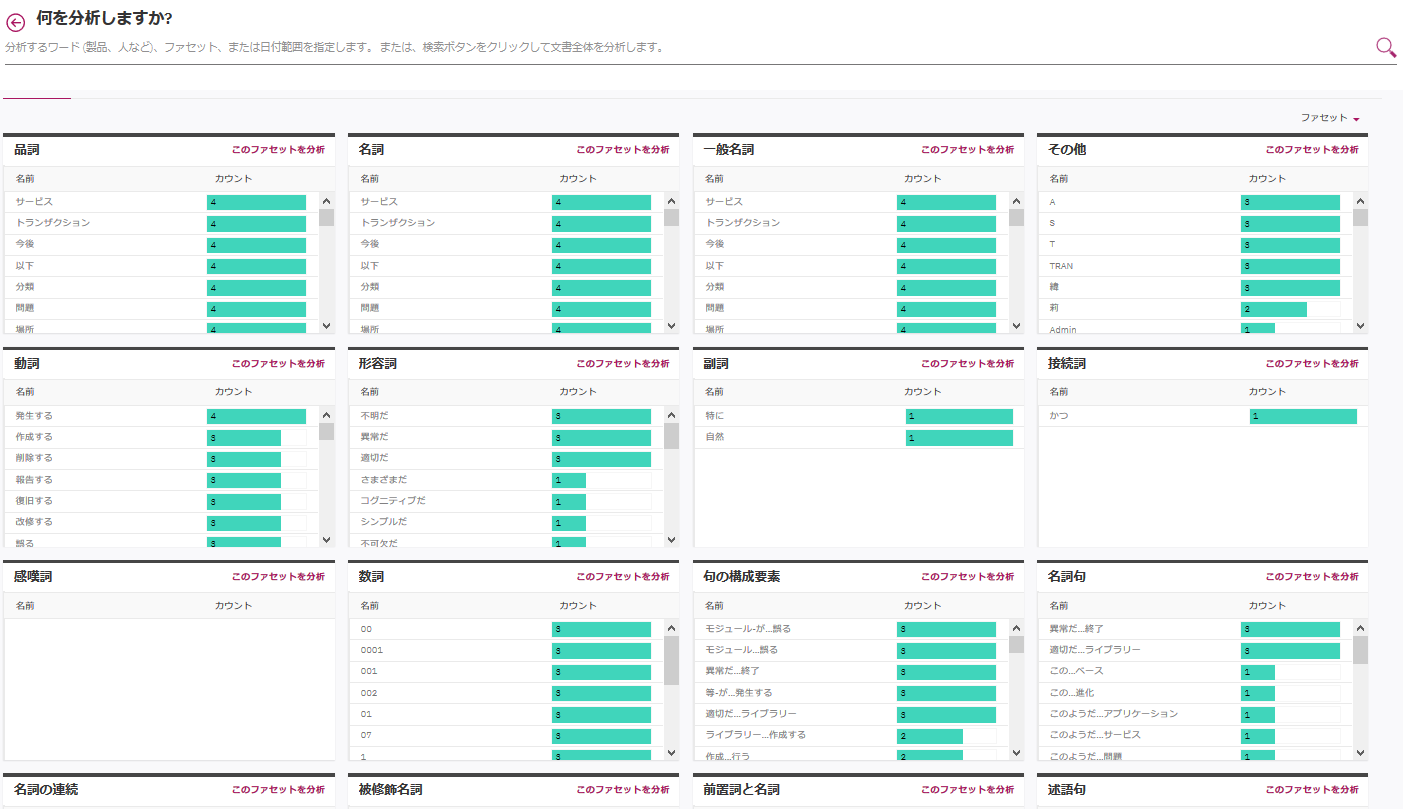
bodyに含まれる文字列情報が形態素解析されて品詞毎に上のように管理されています。例えば、名詞に関して言えば"トランザクション"という文言が含まれている文書は4件ありますよ、とか、形容詞として"異常だ"という意味の文言が含まれている文書は3件ありますよ、というのが分かります。
メタデータ・ファセットと同じように、ファセット値を選択して検索すれば、該当する文書の検索ができます("異常だ"という形容詞を含む文書を検索するなど)。
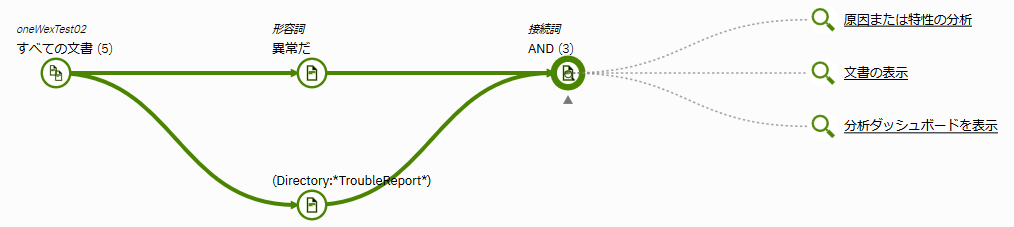
例えば、形容詞から"異常だ"を選択して、かつ、DirectoryとしてTroubleReportを含むものを指定するといった検索もできます。(障害報告書の中から"異常だ"という表現を含むものを検索)

検索条件の追加
一旦検索条件を指定して検索したのち、件数がまだ多いような場合にさらに絞り込みを行うこともできます。
表示されたグラフの右端のノードをクリック-照会テキストの追加をクリックします。
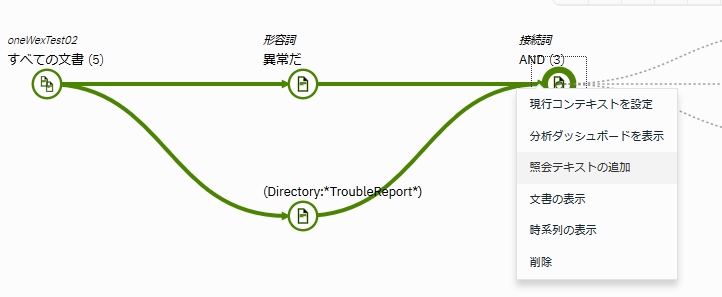
"アベンド"というキーワードを追加
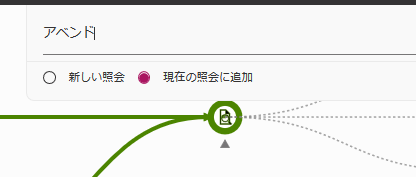
さらに条件が追加されて絞り込みが行われます。

自然言語処理についての考察
内部的には、"全文検索"を効率的に行うために、転置インデックスというものを作成してどういう言葉がどの文書に含まれているか、という情報を保持しています。その際、操作対象となる日本語の文章はトークナイザによって形態素解析が行われて各品詞に分類され、さらに正規化が行われてゆらぎを吸収しつつインデックスの作成が行われています。(内部的にはそのようにしているはず...)
参考: 検索エンジンの常識をApache Solrで身につける
対象の文章がどのように解釈され、どのように検索されるのかを、少し細かく追ってみます。
検索キーワードの解釈と、対応する文書の判定の流れ
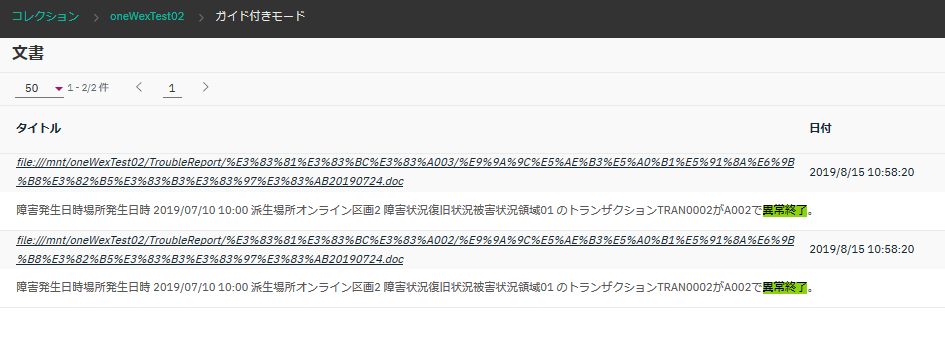
例えば、「異常終了」という文字列で検索してみます。
検索結果の文書を一覧表示させた画面がこちら。
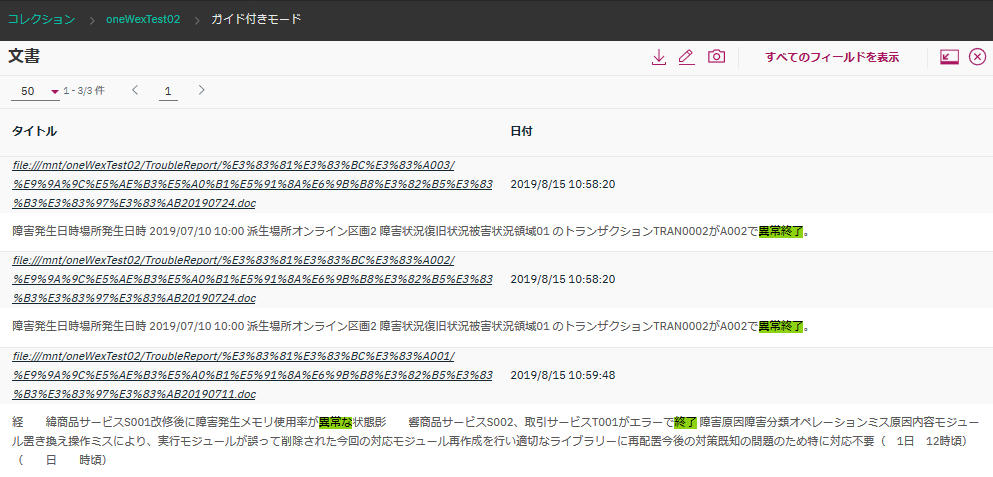
ヒットした箇所が緑色でハイライトされていますが、"異常終了"という文字列だけでなく、"異常な" ... "終了" という文書もヒットしています。
これは、恐らく、検索文として入力した「異常終了」という文字列も形態素解析され、"異常な" "終了"というように形容詞+名詞と判断され、両者が含まれる文書がヒットした、ということだと推察されます。
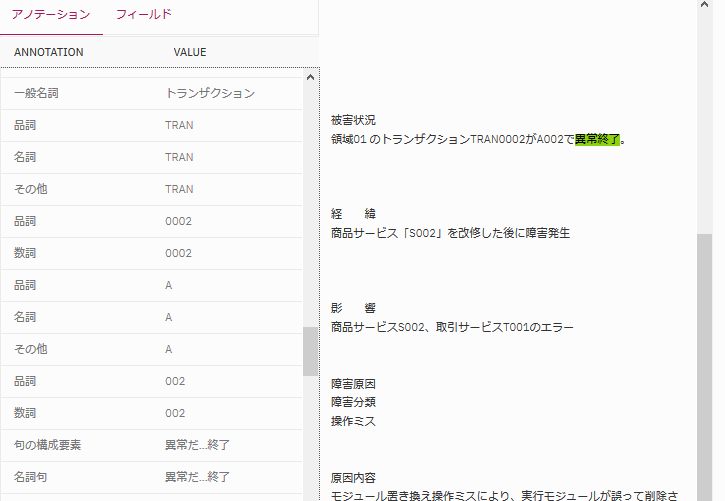
取り込まれた文書がどのように解釈されているのかも見てみます。
文書を選択してアノテーションの所をみると、この文書がどのような品詞に分類されているのかが分かります。
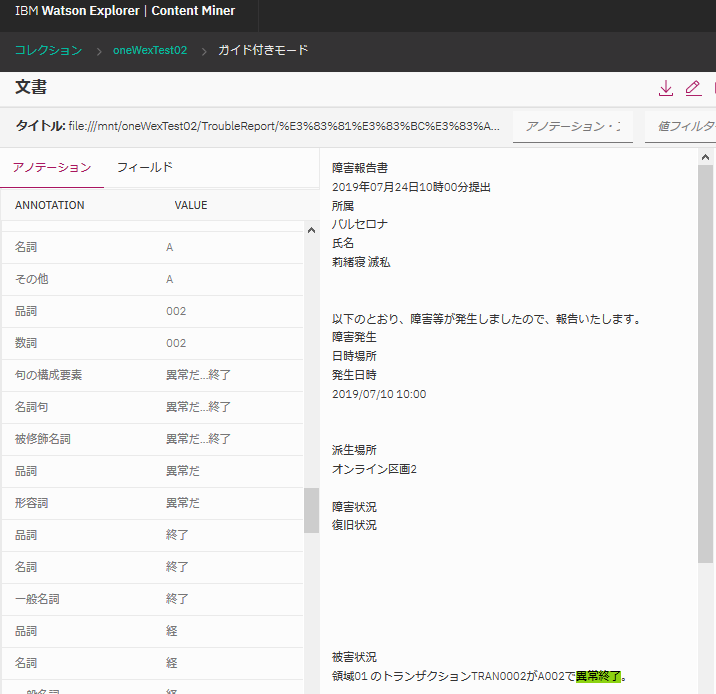
"異常終了"に関する部分を見ると、"異常だ...終了"という句で判断されて、形容詞としての"異常だ"と名詞としての"終了"がアノテーションとして付与されていることが分かります。つまり、形容詞"異常だ"と名詞"終了"を含む文書であると認識されている訳です。
「異常終了」と検索窓に入れて検索すると、正に形容詞"異常だ"と名詞"終了"を含む文書を探しにいき、この文書がヒットした、ということになると思われます。
検索キーワードをダブルクォーテーションでくくる
「"異常終了"」というように、ダブルクォーテーションで文字列をくくった場合はどうなるでしょうか。

結果は"異常な ... 終了..."という文字列が含まれる文書はヒットせず、"異常終了"が含まれる文書のみがヒットしました。
最初、ダブルクォーテーションでくくると、完全一致になるのかなと思いましたが、ヒットした文書に付与されているアノテーションを見ても"異常終了"という単語が認識されている訳では無く、なぜこれがヒットするのか解せませんでした。
次に、以下のようにダブルクォーテーション付きで「"異常な終了"」と入れて検索すると、全く同じ結果で、"異常終了"を含む文書がヒットしました。

このことから推察するに、恐らく、ダブルクォーテーションでくくられたキーワードは、形態素解析により形容詞"異常だ"と名詞"終了"と解釈され、かつ、それが連続して登場するもの、という条件で該当する文書を探しに行っているのではないかと思われます。
「"異常だ終了"」、「"異常に終了"」というキーワードでも、同様に、"異常終了"を含む文書が検索されました。
「"終了異常"」だとヒットしません。
結論: ダブルクォーテーションでくくった場合、文字列完全一致で検索する訳ではない。形態素解析は行われて、かつ、その連続性が検索条件に加わるものと思われます。
エラーコード/メッセージIDのようなもの (A001)
例えば、A147とかDFS0006Eなど、アルファベットと数字の組み合わせのコードが含まれる文書があるとします。例えば障害報告書なんていうのは、そういうエラーメッセージのコードとかエラーの種類を示すアベンド・コードとかが重要だったりします。
これも、アノテーションの情報を見る限りでは、アルファベット部分を名詞として、数字部分を数詞として識別しているようです。
"TRAN0002" => 名詞"TRAN" + 数詞"0002"
"A002" => 名詞"A" + 数詞"002"
検索キーワードとしても同様に解釈されるので、単に「A001」(ダブルクォーテーション無し)で検索すると、"A"という文字列と"001"という文字列を含む文書を検索してしまいます。
連続したA001を検索したい場合は、ダブルクォーテーション付きで「"A001"」と入力して検索する必要があります。

専門用語の登録
上で見た例のように、"異常終了"というのは形容詞"異常だ"+名詞"終了"と解釈されます。これは、デフォルトで使われているトークナイザーが一般的な日本語としての解釈に基づいて分類を行っているためです。
"異常終了"というのはシステム屋さんの間では1つの名詞のように扱われると思うので、1つの単語として扱って欲しい所です。分野によってはそういう専門用語が色々とあると思いますが、それを解釈させるために"辞書"を登録する機能があります。
登録したいキーワードのリスト準備
テキストファイル(UTF-8)で、登録したいキーワードのリストを用意します。
とりあえずここでは以下の3つのIT関連の名詞のリストを作成します。
異常終了
アベンド
メインフレーム
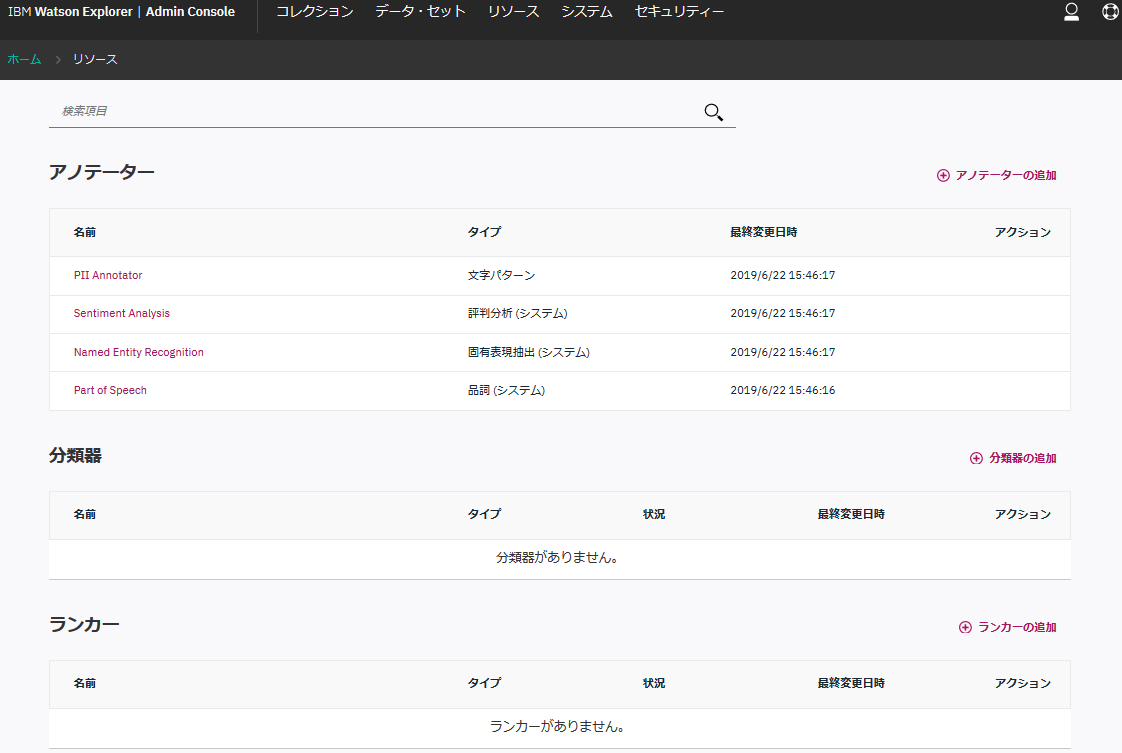
辞書アノテーターの追加
Admin Consoleのリソースというメニューを開き、アノテーターの追加ボタンを押します。
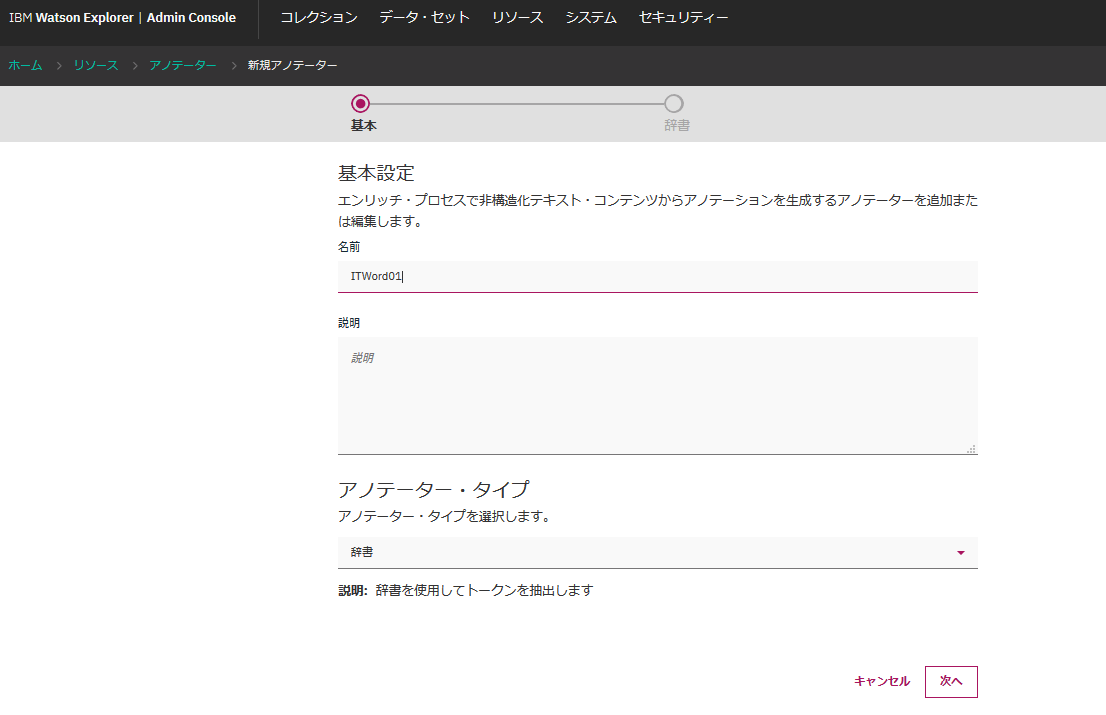
名前を付けて、アノテータータイプに"辞書"を指定し、次へ。
インポートを選択して、先に作っておいたキーワードリストのファイルを選択
インポート!
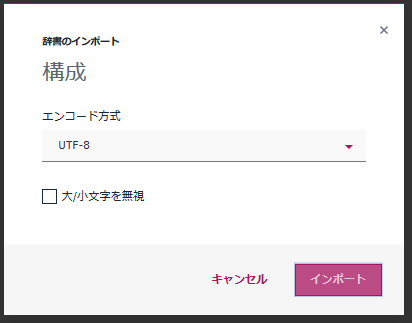
ファセット名などを指定します。言語は日本語を指定。
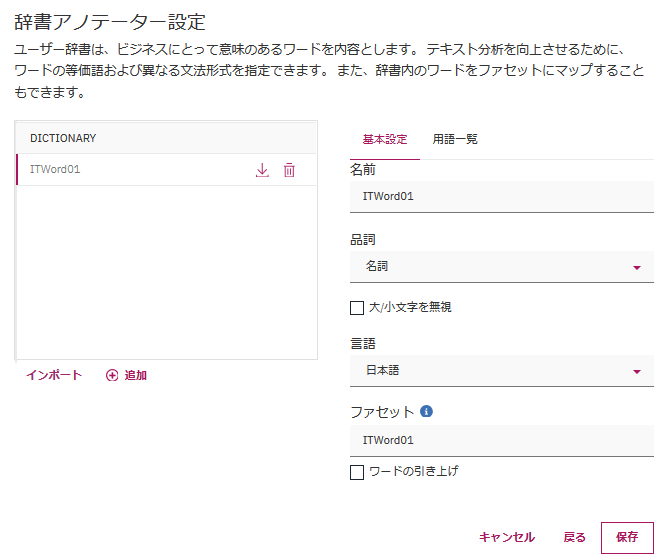
用語一覧をみると、取り込まれた用語を確認できます。ここで個別に追加/削除/編集もできます。
OKだったら保存します。
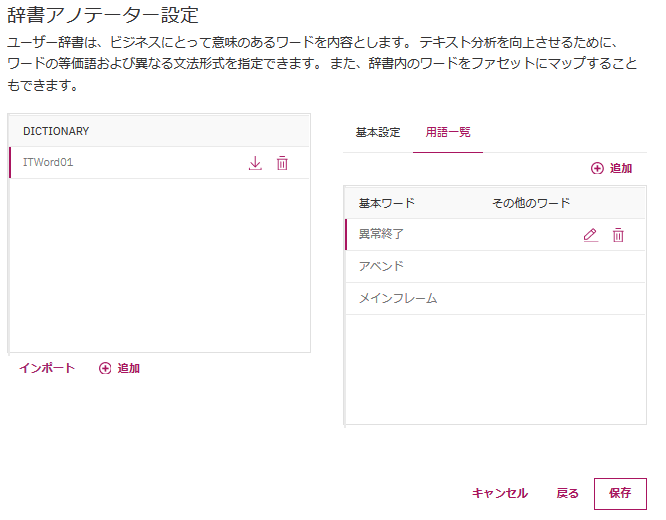
コレクションに辞書を適用
上で作成した辞書をコレクションに適用します。
AdminConsoleにてコレクションを選択し、エンリッチのタブを開きます。
アノテーターの欄に、上で作成した辞書アノテーター(ITWord01)が表示されるので、チェックを入れて、変更を保存します。
以下のポップアップが聞かれるので「はい」を押して索引を再作成します。
索引再作成が完了したら、準備OKです。
辞書登録した用語の動作確認
ContentMinerで辞書アノテーターを適用したコレクションを開いてみると、ITWord01というファセットが追加されています。
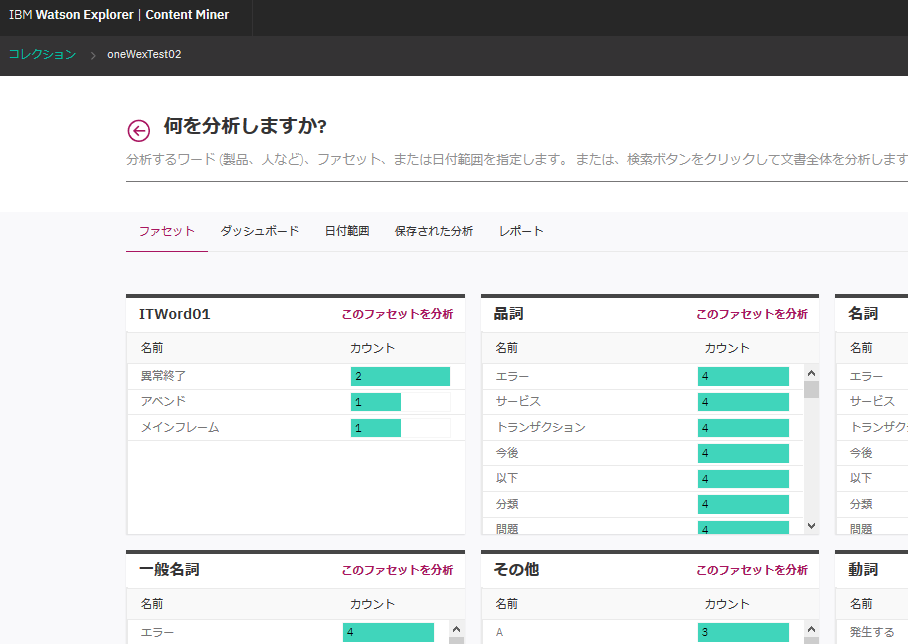
このファセットの"異常終了"クリックして検索してみます。
"異常終了"というIT用語が含まれる文書のみがヒットしました。
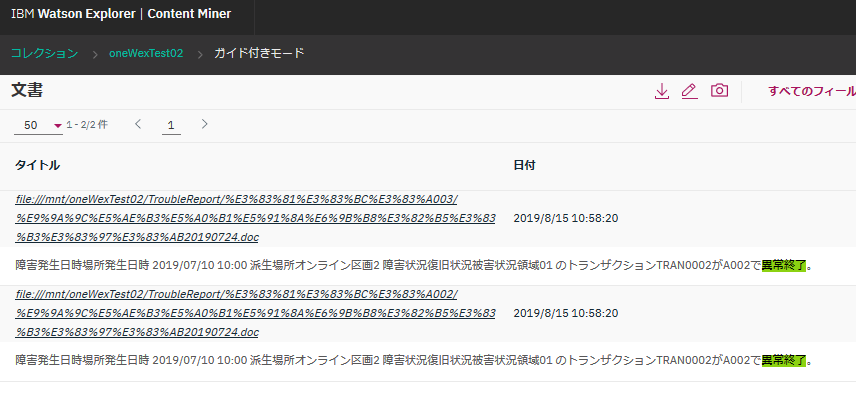
ヒットした文書の1つを選択してアノテーションの情報を見てみると...
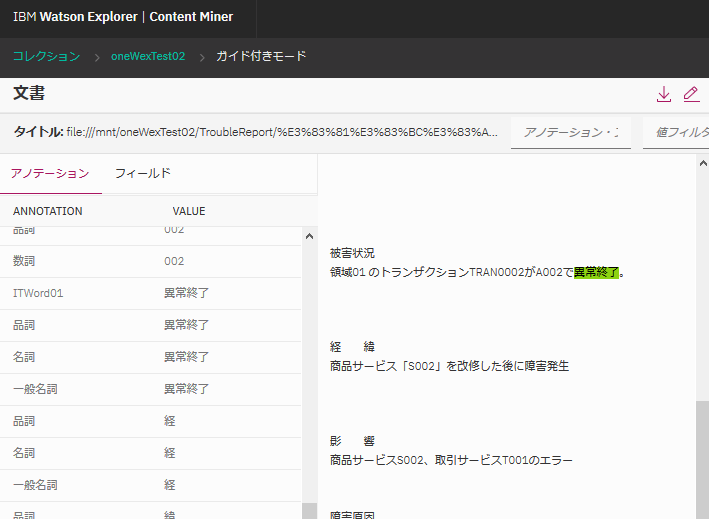
"異常終了"という名詞が認識されて、形容詞"異常だ"、名詞"終了"というのは含まれていませんでした。
謎の挙動???
さて、上のところまでは想定通りだったのですが、ちょっと説明ができない動きがあります。
上に示した通り、辞書を適用すると、形容詞"異常だ"、名詞"終了"というアノテーションは付いていないので、それらの用語で普通に検索した場合(ファセットやダブルクォーテーションを付けんない場合)、この文書はヒットしないだろうと想定しました。
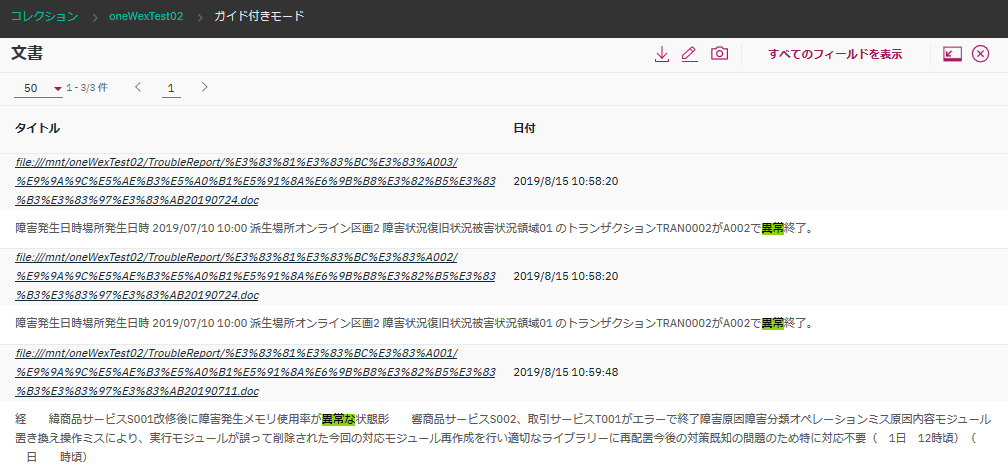
ところが、どちらも検索結果として"異常終了"を含む文書がヒットしちゃいました!
「異常だ」で検索した結果
「終了」で検索した結果
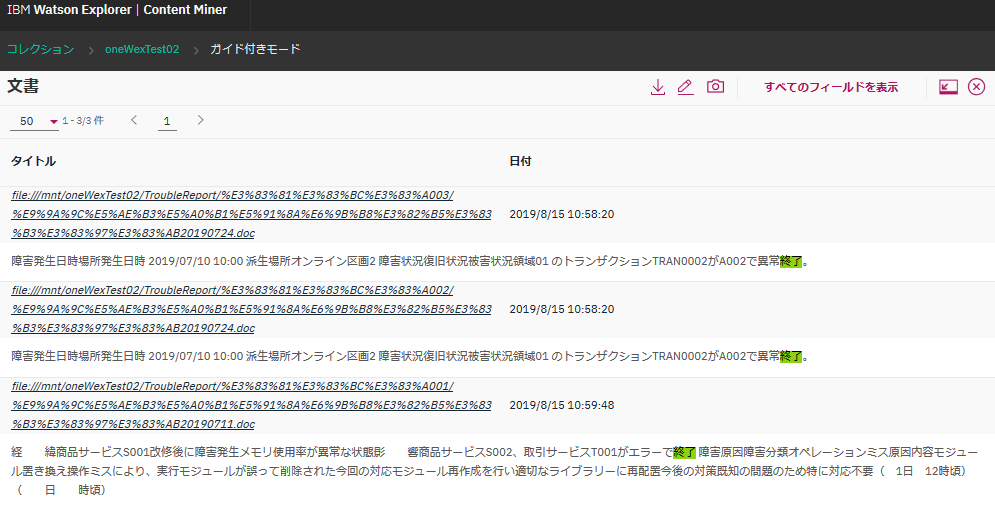
んー、なんで?
これがヒットするロジックがちょっと不明でした。
もちろん、明示的にファセットから形容詞の「異常だ」を指定したり(annotation._word.adj:"異常だ")、名詞の「終了」を指定(annotation._word.noun:"終了")した場合はヒットしないんですけど。
シノニム(同義語)の登録
異なる単語であっても同じ意味の言葉があります。例えば、異常終了とアベンドとか(一応補足しておくと、アベンドとは、Abnormal Endの略です)。
"異常終了"を調べたら、"異常終了"を含む文書だけでなく、"アベンド"を含む文書も検索して欲しいですね。その場合、同義語を登録しておくことでそのようなことが実現できます。
登録したい同義語リストの準備
テキストファイル(UTF-8)で、登録したい同義語のリストを用意します。1行にカンマ区切りで同じ意味として捉えてほしいキーワードを並べます。
とりあえずここでは以下の3種類IT関連の名詞のリストを作成します。
異常終了,アベンド,abend
メインフレーム,ホスト,Mainframe,Host
CICS,キックス
※カタカナでキックスなんて書いてるの見たことないけどね。テスト用なので...
コレクションにシノニムを適用
AdminConsoleにてコレクションを選択し、探索のタブを開きます。
シノニムの欄のアップロードボタンを押して、上で作成したファイルを選択します。
この変更の場合、索引の再作成は不要なので、これで準備OKです。
同義語の動作確認
ContentMinerで登録した同義語で検索してみます。
「異常終了」で検索してみます。

"異常終了"だけでなく、"アベンド"も検索されるようになりました。
「abend」で検索しても同じ結果となります。
まとめ
UIについて
色々柔軟に検索できそうなことは分かりましたが、目的のファイルにたどり着いたとしても、それを直接ブラウザ経由でダウンロードしたり開いたりすることができない、というのは致命的な気がします。
WordやExcelやPDFなどのファイルを対象とする場合、ContentMinerはあくまで"分析用"のツールとして利用する、もしくは管理用/確認用のツール?、と捉えるべきなんですかね。
WEXとしては、ここで検索/分析しているような操作に対応するAPIを提供しているはずなので、ファイルのダウンロード機能を含め、UIとして色々とカスタマイズをしたい場合は、それらのAPIを使用してアプリケーションを個別に作成する必要がありそうです。
その辺についてはApplicationBuilderというツールでWebアプリを簡単に開発するための支援ツールが提供されているので、とりあえずはそちらが一つの解決策になりえそうですが...。
ApplicationBuilderは出来合いのウィジェットをペタペタ張り付けるだけでWebアプリ簡単に作成/カスタマイズできますよ、というものです。ただ、できることは限られそうですし、コードレベルでのカスタマイズもできるのですが、いかんせんマニュアルに情報が少なすぎて、PDもすぐ行き詰るし、凝ったことをしようと思うとハードルがかなり高いです。
一般ユーザー(?)に公開するようなきちんとした仕組みを作りたいのであれば、提供されているAPI使って一からアプリ作る必要があるのかなと思います。
ApplicationBuilderについては別の記事で取り上げます。
メタデータファセットについて
クローラーによりファイルを取り込む場合、探索や分析の切り口になり得るメタデータファセットは、結構限られた情報のみです(ディレクトリ、ファイルサイズ、更新日時、拡張子など)。その中でも更新日時は要注意です。oneWEXに取り込むために、既存のファイルをある程度分類して、oneWEXから取り込める場所に配置する、というようなことを事前に行うことが想定されますが、その際、ファイルの移動の仕方によっては、ファイルのタイムスタンプが更新されてしまうため、ファイル更新日時の情報が全部同一になってしまう可能性があります。そうすると、そのファイル更新日情報はほとんど意味をなさなくなってしまいます(一度更新されてしまうと本来の時刻に戻すのは困難なため、この情報をきちんとコントロールするのは結構シビアです...)。
これら以外に、外から付加情報をどれだけ与えられるか...??? (一体何をどうやって???)
検索/分析対象の本文について
Excelでたくさんのタブから構成される文書であっても、Wordの中にたくさんの表や多くのページにわたって記載されている情報でも、1つのファイルに含まれる情報は全てbodyというフィールドに1かたまりの巨大でフラットな文字列情報として保持されています。タブで分類されていようが、表形式で項目とパラメータが1対1になっていようが、そこを人間が見て判断するように、意味のある構造を勝手に解釈するようなことはしてくれていなさそうです。さて、こういう状態で取り込まれたデータを使って、どんな分析ができて、どういう洞察を与えてくれるのでしょうか...。