はじめに
oneWEXを使ってみた時のメモです。
Word, Excel, PDFなどのファイルをクロールして収集した情報をベースに、oneWEXを使って何らかの"分析"を行う場合、素のままだとなかなか厳しそうなことが分かってきました。"分析"を行うのは"ファセット"が肝になりそうなので、各文書に分析の軸となりそうな何らかの情報を付加する必要がありそうです。
このシリーズでは、障害報告書やシステムの設計書といったものが入力元に含まれている想定で話を進めています。こういったケースでとりあえず思いつくのは、各種"ID"や"コード"(メッセージIDや異常終了コード)といったもので検索や分析を行うことが多いのではないかということです。
例えば、APPL001というアプリケーションがX001というエラーで異常終了したから、過去の類似事象を探したいとか、APPL001に関連するサービスの情報を引っ張ってきたいとか、各サービスの改修要求がどのくらいの頻度で発生していかを知りたいとか、....。各種ファイルに含まれる"コード"情報をベースに検索や分析をしたいというケースがあるんじゃないかな? こういうことができると色々応用が利くんじゃないかな?と考えた次第です。
そこで使えそうなのが、"文字パターンアノテーター"という機能です。今回は、この機能に着目して、ファイルに含まれる"ID情報"をベースにした分析をやってみようと思います。
参考: 文字パターン・アノテーター
関連記事
インストール関連
oneWEX導入メモ / Ubuntu編
oneWEX導入メモ / RHEL7.6 オフライン編
検索関連
oneWEX検証メモ - (0) 概要理解
oneWEX検証メモ - (1)ファイルシステムクローラーによるデータの取り込み / データセット、コレクションの作成
oneWEX検証メモ - (2)Windowsファイルシステムクローラーによるデータの取り込み
oneWEX検証メモ - (3)ContentMinerによる文書の検索
oneWEX検証メモ - (4)ApplicationBuilderによるWebアプリの作成と文書の検索
分析関連
oneWEX検証メモ - (5)ContentMinerによる分析 / ガイド付きモード
oneWEX検証メモ - (6)ContentMinerによる分析 / 各種"ID情報"をベースとした分析
API関連
oneWEX検証メモ - (7)REST API
事前準備
分析に使用する"ID情報"の選定とフォーマットの確認
使用しているシステムや文書に含まれる情報として、どのような"ID情報"があって、何を抽出するかを決めます。ここでは、以下のようなミドルウェアの情報と、業務アプリで定義しているものを想定します。
(文書としては、IMS, Db2を使うz/OS上の業務アプリケーションについての障害報告書や設計書、改修依頼書、などがあり、その中に各種"ID情報"が含まれている想定。)
各々、IDのフォーマットを確認し、それらの正規表現で表してみます。
ミドルウェア
IMS
IMS メッセージの概要
IMSメッセージの正規表現: DFS[0-9]{3,4}[AEIWX]?
Db2
メッセージ番号の解釈方法
Db2メッセージの正規表現 DSN[A-Z0-9][0-9]{3,5}[AEI]
SQL
コード番号の解釈方法
Db2_SQLコードの正規表現: SQL[+-]?[0-9]{3,5}
業務アプリケーション
各業務アプリケーションは、システムに応じてプログラム、トランザクション、サービスなど各種実装されている単位が様々だと思いますが、それぞれ実装上、なんらかのコード(例えばTRAN0001など)で管理されていることが多いと思います。また、メッセージや異常終了コードなどもアプリケーション独自に体系化されたものを用意していることが多いと思います。
ここでは、仮に、以下のようなコード体系を設定してみます。
サービスID
フォーマット: "S" + 部門コード(数字2桁) + グループコード(英字2桁) + 通し番号(数字3桁)
例: S01AA001
正規表現: S[0-9]{2}[A-Z]{2}[0-9]{3}
トランザクションID
フォーマット: "T" + カテゴリー(英字3桁) + 通し番号(数字4桁)
例: TCIC0001
正規表現: T[A-Z]{3}[0-9]{4}
異常終了コード
フォーマット: "A" + 通し番号(数字3桁)
異常終了コード: A001
正規表現: A[0-9]{3}
テスト用ファイルの準備
上のコードを含むテスト用のファイル(障害報告書)を適当にいくつか用意します。
今回テストで使用するファイル群はこちら。
=> https://github.com/tomotagwork/WEXTest01/tree/master/SampleFiles4
これらをクローラーを使ってデータセットとして取り込んでおきます。
文字パターンアノテーターの作成
oneWex AdminConsoleの"リソース"タブから、アノテーターの追加を選択します。
ここでは、CodeTest01という名前を指定し、アノテーター・タイプとして"文字パターン"を選択します。
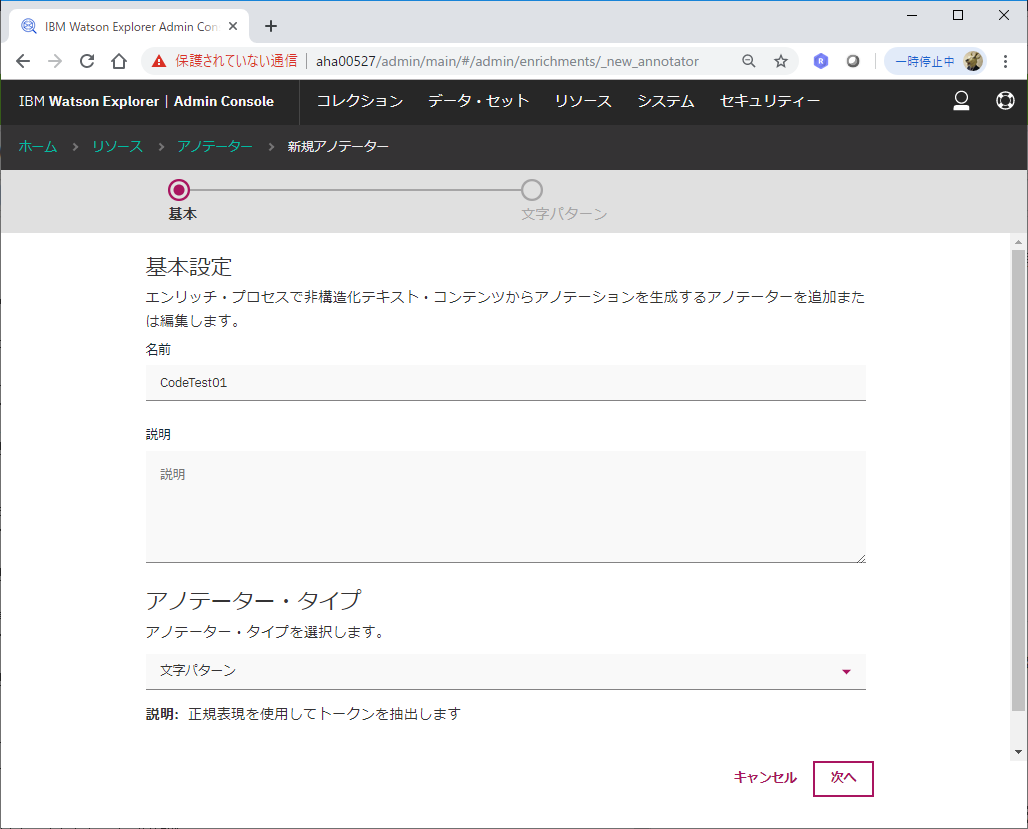
ここで、上で整理したID情報の正規表現と、ファセット名を定義していきます。
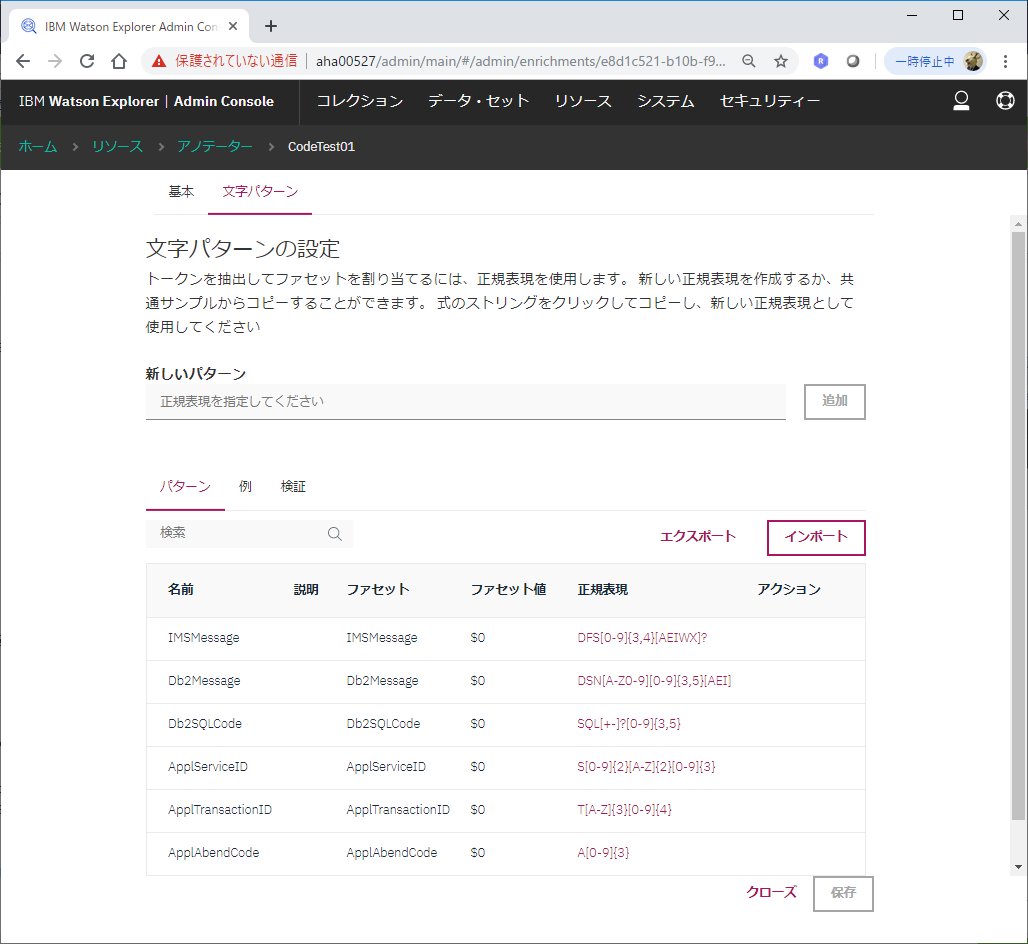
Webの画面から一つ一つ定義することもできますし、以下のようなJSONファイルを作成しておいてそれをインポートすることもできます。以下は、Webの画面で作成した定義をエクスポートしたもの。(facetPathに指定した名前の先頭に、勝手にピリオドが付いてました...。ruleIdは恐らく勝手に付与されるものだと思います。)
モノはこちらにもアップしています => annotator_CodeTest01.json
[
{
"ruleId": "5d537f73-0549-402b-87a2-b859a86d3c7b",
"name": "IMSMessage",
"description": null,
"matchType": "Document",
"pattern": "DFS[0-9]{3,4}[AEIWX]?",
"facetPath": ".IMSMessage",
"facetValue": "$0"
},
{
"ruleId": "d13bc179-d63e-49b1-9ede-f8a53fc96faf",
"name": "Db2Message",
"description": null,
"matchType": "Document",
"pattern": "DSN[A-Z0-9][0-9]{3,5}[AEI]",
"facetPath": ".Db2Message",
"facetValue": "$0"
},
{
"ruleId": "681858bf-c0f6-4a8c-a9ac-1e7532912897",
"name": "Db2SQLCode",
"description": null,
"matchType": "Document",
"pattern": "SQL[+-]?[0-9]{3,5}",
"facetPath": ".Db2SQLCode",
"facetValue": "$0"
},
{
"ruleId": "3db841e7-46da-4650-9d0c-b44b243b74e6",
"name": "ApplServiceID",
"description": null,
"matchType": "Document",
"pattern": "S[0-9]{2}[A-Z]{2}[0-9]{3}",
"facetPath": ".ApplServiceID",
"facetValue": "$0"
},
{
"ruleId": "e66ec7eb-c881-41f3-8846-50047f2f3f55",
"name": "ApplTransactionID",
"description": null,
"matchType": "Document",
"pattern": "T[A-Z]{3}[0-9]{4}",
"facetPath": ".ApplTransactionID",
"facetValue": "$0"
},
{
"ruleId": "9c178824-8606-4fc8-875e-794839df4ab9",
"name": "ApplAbendCode",
"description": null,
"matchType": "Document",
"pattern": "A[0-9]{3}",
"facetPath": ".ApplAbendCode",
"facetValue": "$0"
}
]
※注意!
画面上のファセットパスの説明には、以下の記載があります。
ファセット・パスを指定します。 ドット区切り構文を使用して、階層ファセットを指定できます。 例えば、aaa.bbb と指定すると、aaa は親ファセットで、bbb は子ファセットになります。
最初、この例にならって階層化してCodeTest01.IMSMessageみたいなネーミングにして作成してみたのですが、それを適用したコレクションを分析させようとすると、InternalServerError(500)が発生してうまく動きませんでした。バグっぽいですが、とりあえず階層化をやめてフラットなファセットパスを指定したらうまく分析が動いたようなので、ここでは階層化されたファセット(ドット区切り)はやめておいた方が無難でしょう。こういう地雷がちょいちょいあるな...
コレクションの作成
データセットからコレクションを作成する際、上の文字パターンアノテーターを適用します。(既存のコレクションに後から追加適用も可)。
"エンリッチ"のカテゴリの中の、アノテーターで、先ほど作成した"CodeTest01"にチェックを入れます。
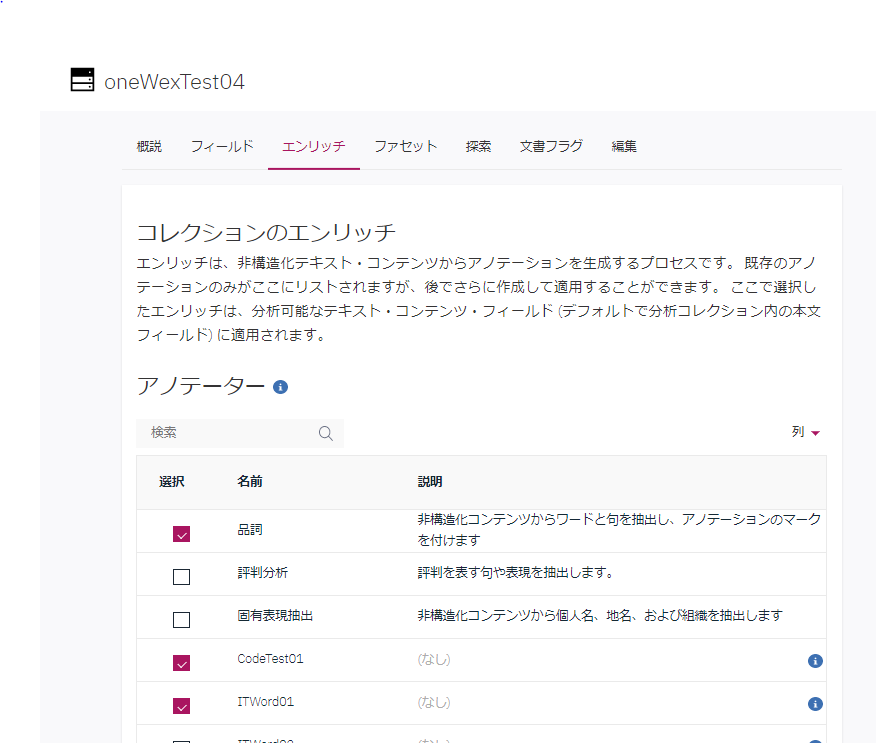
これでコレクション作成(もしくは索引再作成)を行えばOKです。
ContentMinerによる分析
ファセットの確認
ContentMinerで上のコレクションを開いてみると、コレクション作成時に追加した文字パターンアノテーターをベースに付与されたファセット情報が確認できます。
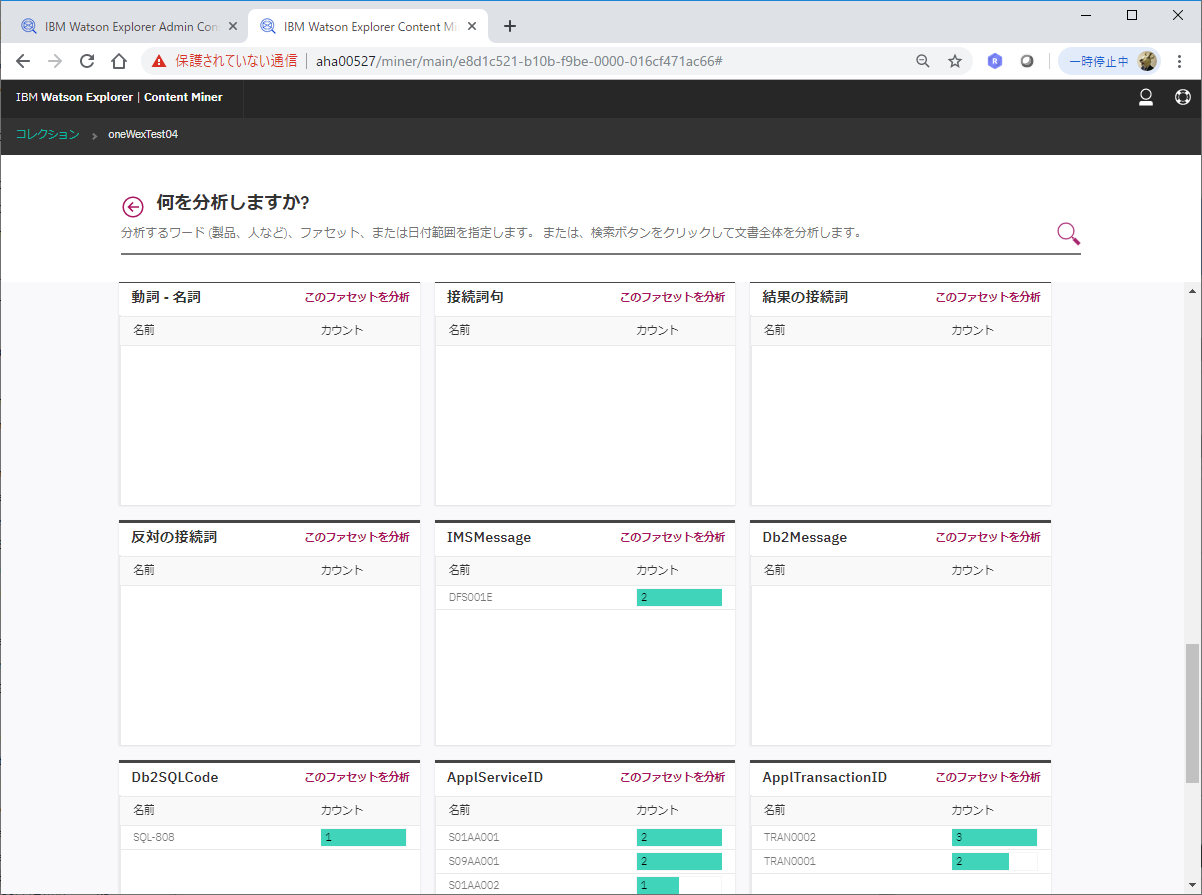
例えば、IMSMessageとして"DFS001E"というIDが含まれる文書が2件あって、トランザクションID "TRAN0002"を含む文書が3件あって... というのが見て取れます。
原因または特性の分析
ApplTransactionIDファセットから"TRAN0002"を選択して検索し、"原因または特性の分析"をクリックしてみます。
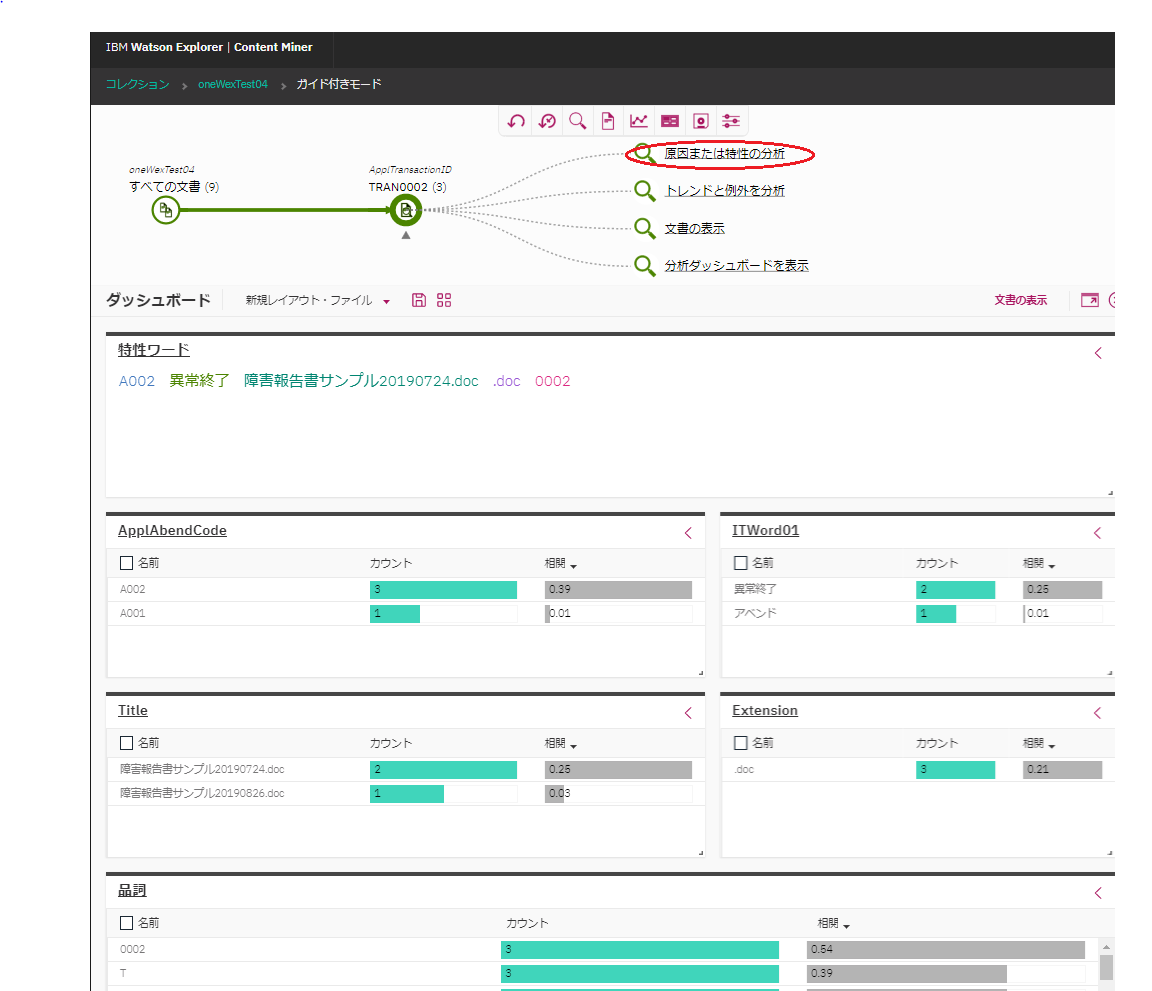
これは一つ前の記事でも記載したように、関連性の高いと思われる用語や、相関が高いファセットなどが表示され、さらなる分析/絞り込みのヒントが表示されます。
これにより、"A002"というアベンドコードとの相関が比較的高いな、というのがパッと分かる訳です。
時系列分析
ApplAbendCodeから"A002"を選んで検索し、その後、"時系列の表示"のアイコンをクリックしてみます。
そうすると、更新日時を横軸として、ApplAbendCodeとして"A002"を含む文書の件数が棒グラフで表示されます。
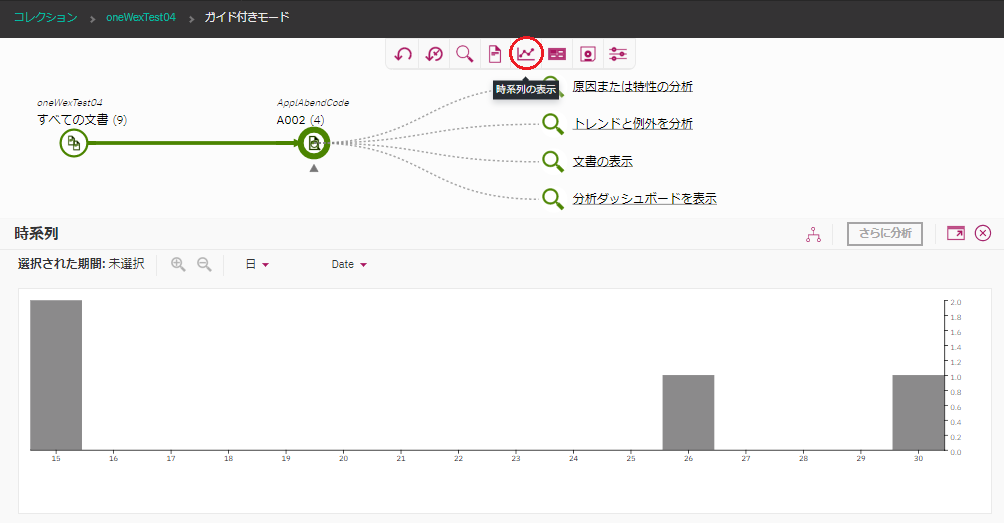
"A002"というIDが含まれる障害報告がいつ、どのくらいの件数発生しているのか、というのが可視化されることになります。
(ただし、あくまで"A002"という文字列が含まれている障害報告書がヒットするだけで、必ずしも"A002"というコードの障害かどうかは不明です。)
いくつか、このような時系列をベースとした分析が行えますが、ここで利用されるのはファイルの最終更新日時です。前の記事にも記載しましたが、このファイル更新日がどういう意味があるのか(そもそも意味のある情報として考えてよいのか)は、きちんと理解した上でこの分析結果を捉える必要があります。(例えば、障害発生日時と、障害報告書の最終更新日にはそれなりにギャップが生じることでしょう。)
トレンドと例外を分析
ApplAbendCodeから"A002"を選んで検索し、その後、"トレンドと例外を分析"をクリックしてみます。
そうすると、更新日時を横軸として、ApplAbendCodeの"トレンド"と"例外"(トピック?)の棒グラフが表示されます。上の時系列情報と類似していますが、それに加えて、特異点を分かりやすく表示してくれるもののようです。
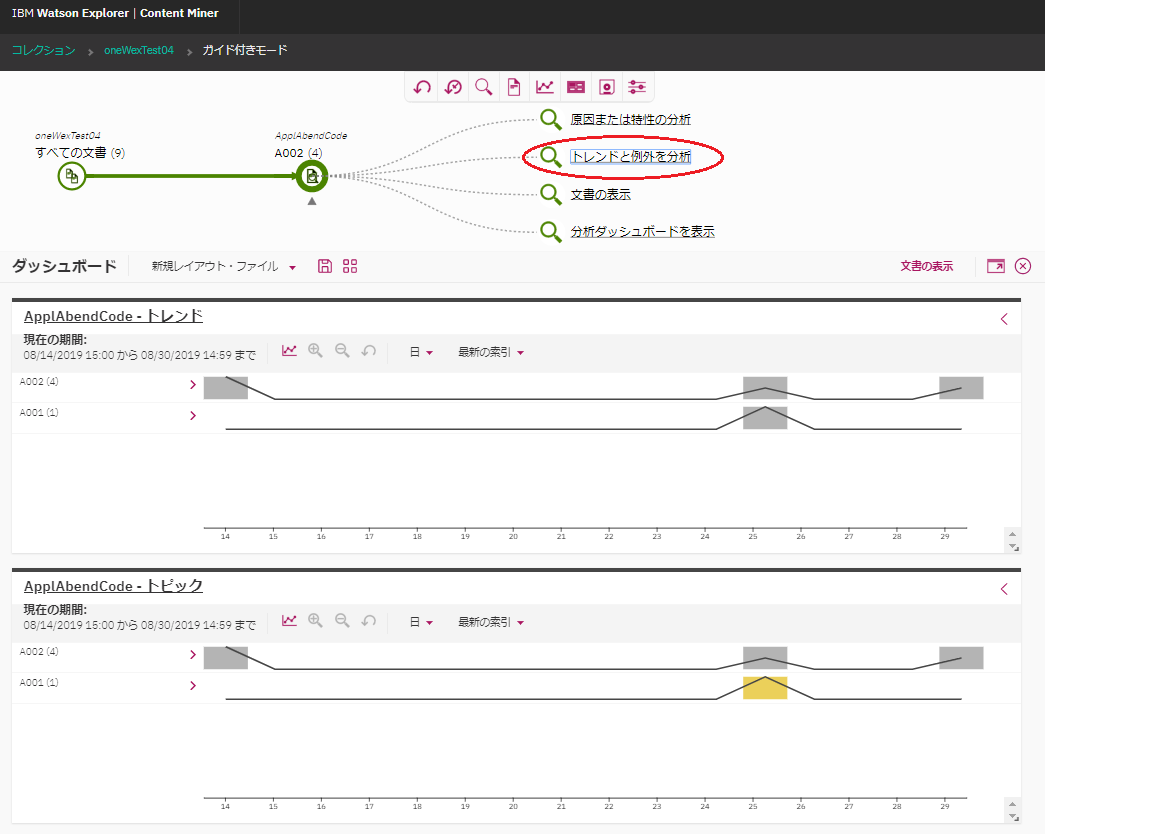
参考: 時系列ダッシュボード
例外というのは"トピック"という表で表されているものだと思われます。これらの、"トレンド"と"例外"(トピック?)が何を示すのか、ということについて説明が見当たらないのですが、マニュアルの別の箇所に説明されている以下のような内容が表示されているのではないかと推察します。
トレンド => "時間の経過にともなう予期しない頻度の増加の識別"
例外?(トピック?) => "特定の期間に関するファセット値の偏差の識別"
ここでの結果はサンプルファイルが少なすぎるので、棒グラフが分かりにくい表示になってしまっていますが、恐らく、"トレンド"は傾向が変わる点(傾きが大きく変わるなど)、"例外"(トピック)は平均からの差分が大きい点(スパイク的な要素)を、色を変えて分かりやすく表示してくれるものだと思われます。
月末にこの障害報告が増えてるね、とか、あるサービスをリリースした直後から急に障害報告の数が増えてるね、みたいなことが分かったりするかもしれません。
(まぁそれくらいのことは別途Excelとかで集計してそうですけど。)
ペア
2つのファセットの関連を表示できます。
"異常終了"というキーワードで検索した後、右側のメニューのファセット分析の箇所で"ペア"を選択し、ターゲットファセットから行/列のファセットとして"AppTransactionID", "AppAbendCode"を選択します。両者を含む文書の件数と相関値が表で表現されます。
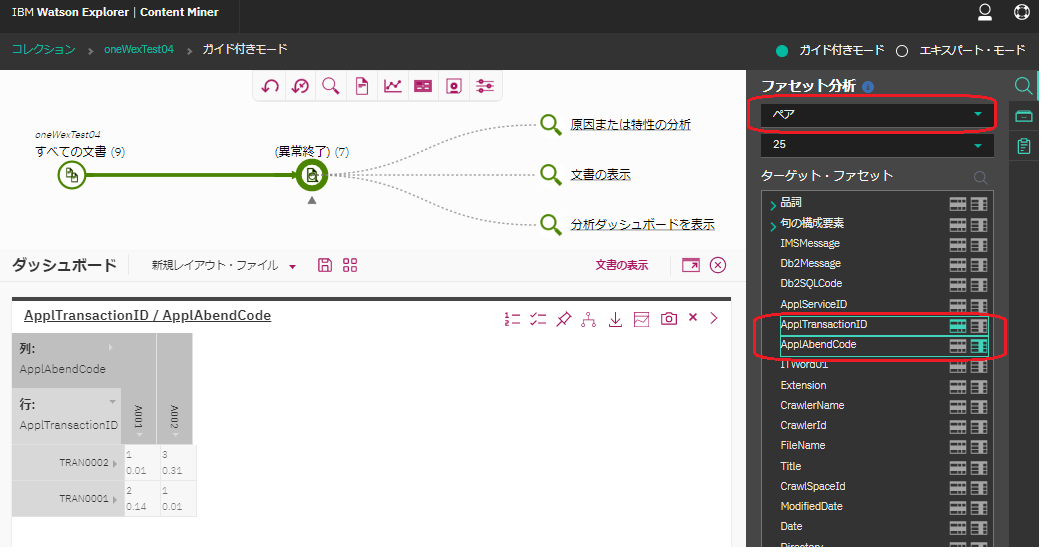
まぁ、いわゆるピボットテーブルですね。ただ、残念ながら2次元までしか対応していないようです(選択できるファセットは2つのみ)。
視覚化のアイコンで"ペア表"を選べば、以下のような表示に切り替わります。
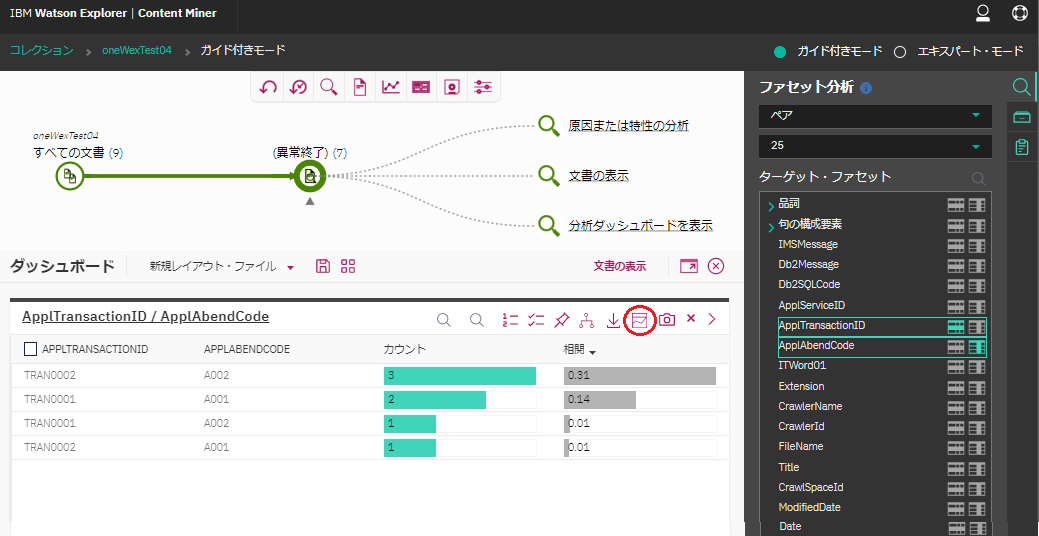
このトランザクションIDとこのアベンドコードが一緒に含まれている文書が多いな、ということが直感的に分かりやすく表示されていると思います。
(あくまで両者が同一文書に含まれているというだけであって、そのトランザクションがそのコードでアベンドしたか、というような文脈を含めて判断している訳では無いので注意!!!)
恐らく以下の辺りの説明が該当しそう。
参考: ファセット・ペア間の相関の識別
接続
右側のメニューのファセット分析の箇所で"接続"を選択。
ファセット値の関連をネットワークグラフで表示してくれるっぽいが...
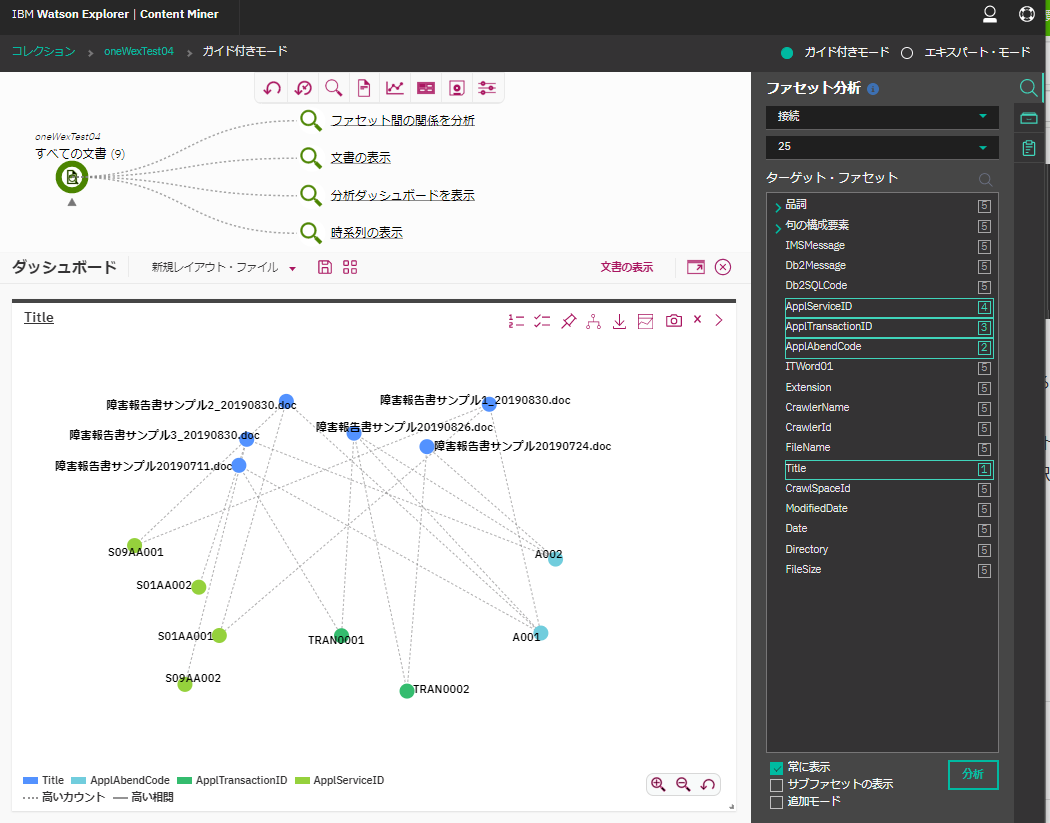
ファセットは1~5つまで選択でき、それぞれ選択順が考慮されるらしいが、それらが何を意味するのか不明。
AppTransactionIDとAppAbendCodeの関係を表示させようと思ってそれら2つを選択しただけだと、グラフは全く表示されない。TitleとかFileNameあたりを選択しないとどうもグラフが表示されない。挙動がよくわからない。
マニュアルからも詳細な説明が見当たらないし。
この辺りが近そうではあるけど... => ファセット間の関係の識別
動的クラスター
右側のメニューのファセット分析の箇所で"動的クラスター"を選択。
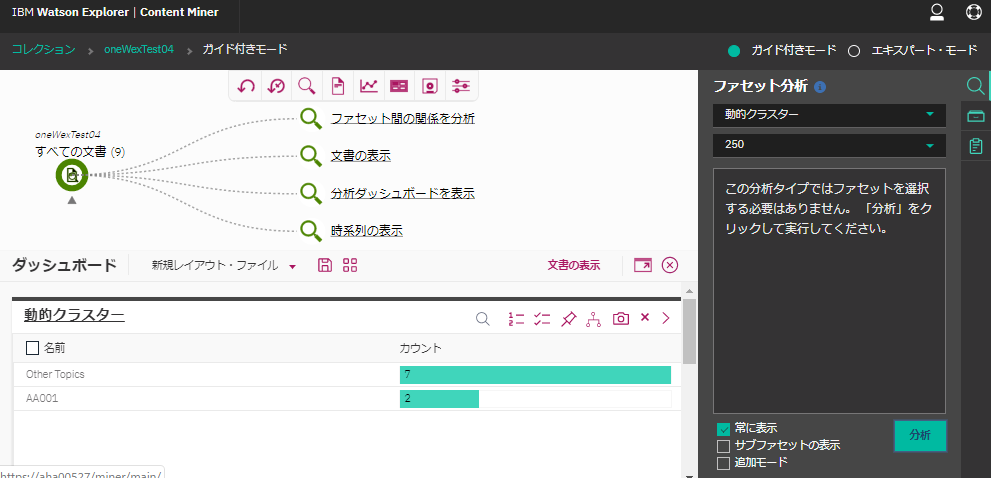
これは特にファセットは選択するものではなく、文書を自動で分類してくれるっぽい。
よくわからない分類がされている....。サンプル文書が少ないせいか?
考察
とりあえず、"ID情報"をベースにしたファセットを作ることで、そこを軸としてこういう感じで分析操作ができるのね、という雰囲気は分かりました。
これらの機能を使って本当に意味のある何らかの洞察が得られそうか?というのは、実際に活用したい業務に基づいたデータを使って試行錯誤しないといけないんだと思います。
また、ContentMinerで可視化できるものについては、詳細情報がマニュアルに見つからなかったり融通が利かない部分もありそうなので、可視化の部分は公開されているAPI使って独自実装した方がよさそう....、と思ったのですが、分析系の情報を取得するためのAPIって提供されてない???(例えば"接続"に関する情報とか動的クラスターに関する情報を取得するためのAPIは見当たらない...)。うーん....。