本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
AWSにおける標準的なDatabricksデプロイメントにおける会話
これはAWSでDatabricksをデプロイするクラウドエンジニア向けのベストプラクティスとガイダンスを説明する3パートのシリーズのパート2です。シリーズのパート1はこちらから参照できます。
説明しているように、このシリーズの対象者は、Amazon Web Services (AWS)におけるDatabricksデプロイメントのデプロイと強化に責任を持つクラウドエンジニアです。この記事では、標準的なDatabricksデプロイメント、ネットワーク要件、一般的にされる質問の技術的詳細に踏み込みます。
このブログ記事の理解を容易にし、ネットワーキングに関するドキュメントが必要にならないようにこの記事を、架空のお客様であるACMEクラウドエンジニアリングチームに、我々のソリューションアーキテクトがベストプラクティスや質問に対する回答を説明してるかのように記述しています。
この会話は現実のものではありませんが、我々がほぼ毎日現実のお客様と行っている会話を集約したものとなっています。
進める前の注意点ですが、次のセクションではネットワークとデプロイメントの要件を議論するので、Databricksが複雑に見えるかもしれません。しかし、我々はアーキテクチャ上のシンプルさの一形態として、常にこのオープン性を目撃しています。標準的なAWSツール(VPC Flow Logs、CloudTrail、CloudWatchなど)を用いて、お使いの環境にデプロイされる計算資源を知り、Databricksデータプレーンに対してどのように通信を行い、どのようなアクティビティが発生しているのかを知ることができます。
レイクハウスプラットフォームとして、Databricksの背後にある計算資源は、オブジェクトストア、ストリーミングシステム、外部データベース、公衆インターネットなどからの様々なリソースとやり取りを行います。あなたのクラウドエンジニアリングチームが新たなユースケースを導入すると、お使いのクラシックデータプレーンは、これらのやり取りが効率的かつセキュアになるようにする基盤を提供します。
そして、もちろんですが、背後の計算資源をDatabricksに管理させたいのであれば、Databricks SQLサーバレスのオプションがあります。
この記事の残りでは、自分をJ(JD Braun)、お客様をCとします。この記事の最後で会話が終了したら、AWSでDatabricksをデプロイする方法をカバーするパート3で何を話すのかを議論します。
注意
このシリーズのパート1を読んでおらずDatabricksに詳しくない場合には、この記事を読み進める前にパート1をお読みください。パート1では、コンセプトレベルでAWSにおけるDatabricksのアーキテクチャとワークフローを説明しています。
会話
J: 皆さんようこそ、本日は参加いただきありがとうございます。
C: 問題ありません。ご存知の通り、我々はACMEのクラウドエンジニアリングチームに属しており、我々のデータアナリティクスのリードが、実施したDatabricksのPOCについて話しており、今ではどのようにプロダクションがAWSエコシステムに組み込まれるのかを知りたがっています。しかし、我々はプラットフォームに詳しくなく、AWSにDatabricksをデプロイするのに何が必要なのかを理解したいのです。なので、要件や推奨事項、ベストプラクティスをウォークスルーしていただけると大変助かるのですが。また、いくつかの質問があります。
J: 喜んで標準的なDatabricksデプロイメントのコンポーネントをウォークするさせていただきます。ウォークスルーする途中で、気軽に割り込んでいただき質問してください。
J: それでは始めましょう。私は以下のように標準的なデプロイメントの要件をまとめるのが好きです: 顧客管理VPC、データプレーンからコントロールプレーンへの接続、クロスアカウントIAMロール、S3ルートバケットです。このコールを通じて、この情報を登録するDatabricksアカウントコンソールの場所を指し示します。もちろん、これはすべて自動化することができますが、どの部分を議論しているのかをビジュアルで示したいと思います。それでは、顧客管理VPCからスタートしましょう。
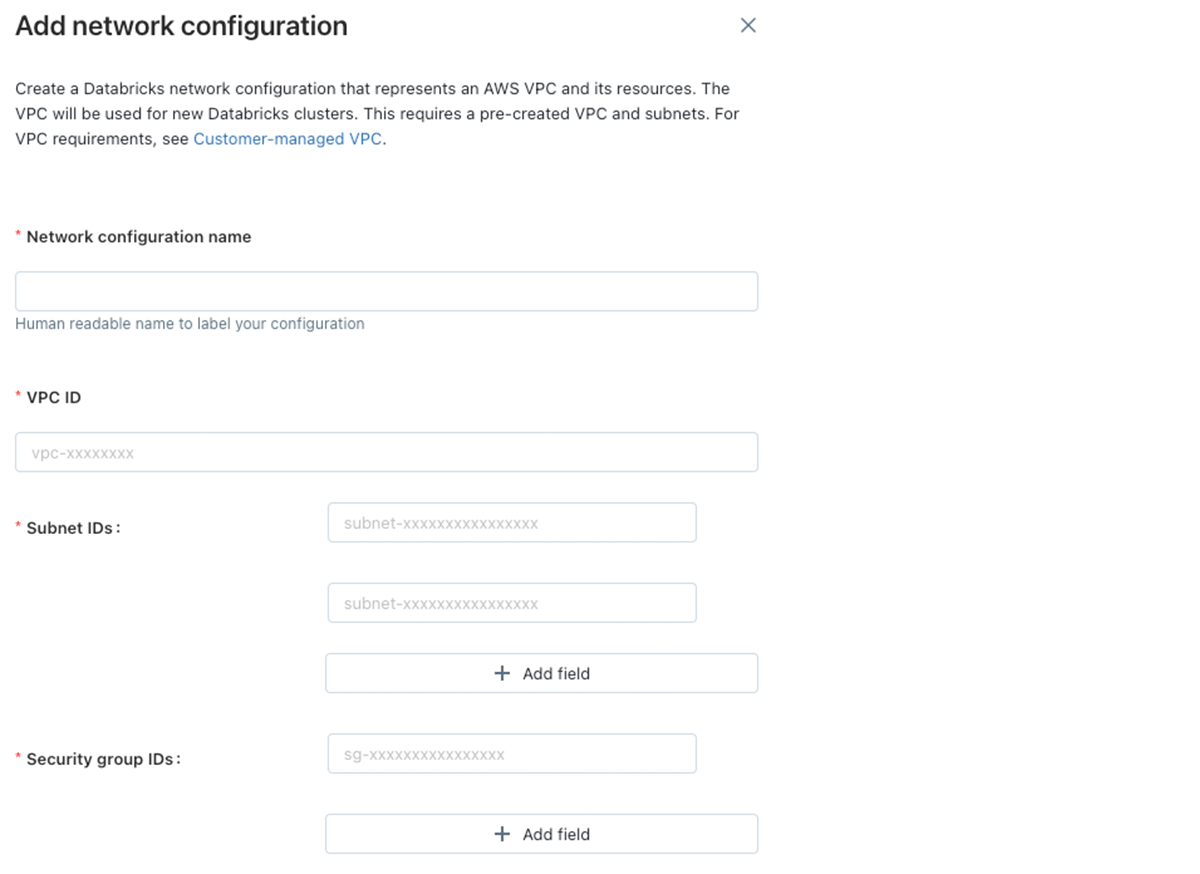
Databricksアカウントコンソールでの顧客管理VPCの追加
J: 様々なネットワーク、セキュリティ要件に基づいて、顧客管理VPCは様々な形状やサイズとなります。私は、ベースラインとなる要件の基盤からスタートし、皆様の環境固有の要件をその上に構築するのが好きです。VPC自身は非常にわかりやすいものです。/25ネットマスクより小さく、DNSホスト名とDNS解決を有効化しなくてはなりません。
J: 次にサブネットです。ワークスペースには、ネットマスクが/17と/26の間である、それぞれ異なるアベイラビリティゾーンに存在する最小2つの専用のプライベートサブネットが必要になります。サブネットは別のワークスペースで再利用することはできず、当該サブネット空間には別のAWSリソースを配置することは推奨しません。
C: ワークスペースのサブネットに関して幾つか質問があります。通常、ユーザーはワークスペースにどの程度のサイズのサブネットを使用しますか?そして、他のワークスペースで使えないのはなぜですか?同じサブネットに他のリソースを配置していけないのはなぜですか?
J: 鋭い質問です。サブネットのサイズはお客様によって異なります。しかし、あなたのレイクハウスアーキテクチャで必要となるであろうApache Spark (™)ノード数を計算することで推定することは可能です。それぞれのノードでは2つのプライベートIPアドレスが必要となり、一つはトラフィックの管理、もう一つはApache Spark (™)アプリケーション用です。ワークスペースでネットマスク/26のサブネットを二つ作成すると、単一のサブネットで合計64個のIPアドレスを作成できることになり、AWSが最初の4つのIPアドレスと最後のIPアドレスを使用するので、59個が利用できることになります。これは、最大約32ノードを使用できることを意味します。最終的には、サブネットをのサイズを適切に設定するために、より小さい大量のサブネット(US-EAST-1での6サブネットなど)やより大きい少数のサブネットを経由するのかなど、皆様のユースケースから逆算することが可能です。
| サブネットサイズ(CIDR) | VPCサイズ(CIDR) | AWS Databricksクラスターノードの最大数 |
|---|---|---|
| /17 | >= /16 | 32768 |
| /21 | >= /20 | 4096 |
| /26 | >= /25 | 32 |
C: ありがとうございます。様々な開発用ワークスペースに単一の専用VPCを割り当てたい場合、これらを分割するための推奨はありますか?
J: はい。それでは、アドレス空間11.34.88.0/21のVPCを5つのワークスペースにブレークダウンしてみましょう。その後では、使用法に基づいて適切なワークスペースにユーザーを割り当てなくてはいけません。もし、ユーザーが数百Gバイトのデータを処理するために非常に大きいクラスターを必要としているのであれば、彼らをX-Largeに割り当ててください。もし、小規模なデータのサブセットに対してインタラクティブな分析を行うのであれば、smallワークスペースに割り当ててください。
| Tシャツサイズ | ワークスペースあたり最大クラスターノード数 | サブネットCIDR #1 | サブネットCIDR #2 |
|---|---|---|---|
| X-Large | 500ノード | 11.34.88.0/23 | 11.34.90.0/23 |
| Large | 245ノード | 11.34.92.0/24 | 11.34.93.0/24 |
| Medium | 120ノード | 11.34.94.0/25 | 11.34.94.128/25 |
| #1 Small | 55ノード | 11.34.95.0/26 | 11.34.95.64/26 |
| #2 Small | 55ノード | 11.34.95.128/26 | 11.34.95.192/26 |
J: 2つ目の質問に関してですが、クラスターをデプロイやリサイズする際に、IP枯渇によってエンドユーザーがインパクトを受けないように、アカウントレベルでサブネットが重複しないことを強制しています。これが、企業のデプロイメントにおいて、同じサブネットに他のリソースを配置しないよう警告している理由です。単一のワークスペースでIPの利用を最適化するために、すべてのクラスターで自動アベイラビリティゾーン(auto-AZ)のオプションを使用することをお勧めしています。
J: そして、顧客管理VPCではVPCやサブネットを移動するなど、必要に応じていつでもネットワーク設定を切り替えることができることを覚えておいてください。
J: サブネットに関して追加の質問が無いのであれば、Databricksワークスペースを作成する際に登録が必要な別のコンポーネント、セキュリティグループに移りましょう。Databricksで使用するEC2インスタンス用のセキュリティグループのルールでは、同じセキュリティグループの他のリソースからのすべてのインバウンド(ingress)トラフィックを許可しなくてはなりません。これは、Sparkノード間のトラフィックを許可するためのものです。アウトバウンド(egress)トラフィックルールは以下の通りです:
- 443: Databricksのインフラストラクチャ、クラウドデータリソース、ライブラリのリポジトリ
- 3306: デフォルトHiveメタストア
- 6666: PrivateLinkが有効化されたワークスペースにおけるセキュアクラスター接続リレー
- お使いのアプリケーションが必要とするその他のアウトバウンドトラフィック(Amazon Redshiftの5409など)
J: 皆様がApache KafkaやRedshiftなどへの接続に失敗する際のよくある間違いは、接続がプロックされていることによるものです。ワークスペースのセキュリティグループがアウトバウンドのポートを許可していることを確認してください。
C: 今の所、セキュリテイグループのルールに問題はありません。しかし、Databricksのドキュメントを見たのですが、どうしてDatabricksのデプロイメントでは、インバウンドのネットワークACLサブネットルールでALLOW ALLが必要なのですか?
J: 我々はサブネットに対してデフォルトのNACLルールが使用される多層セキュリティモデルを使用していますが、EC2インスタンスに対して厳しいセキュリティグループルールによってさらにリスクを軽減することができます。さらに、多くのお客様は公衆インターネット向けのすべてのアウトバウンドアクセスを制限するために、ネットワークファイアウォールを追加しています。こちらに、不正あるいは意図しない攻撃者からデータを防御する方法を説明している、データ漏洩防御に関する記事があります。
J: OK、ここまででVPC、サブネット、セキュリティグループ、NACLをカバーしました。次に、顧客管理VPCとデータプレーンからコントロールプレーンへの接続に関する要件についてお話しします。クロスアカウントIAMロールがあなたのAWSアカウントでEC2インスタンスを起動すると、クラスターの最初のアクティビティの一つはコントロールプレーンと呼ばれるDatabricksのAWSアカウントに連絡をすることです。
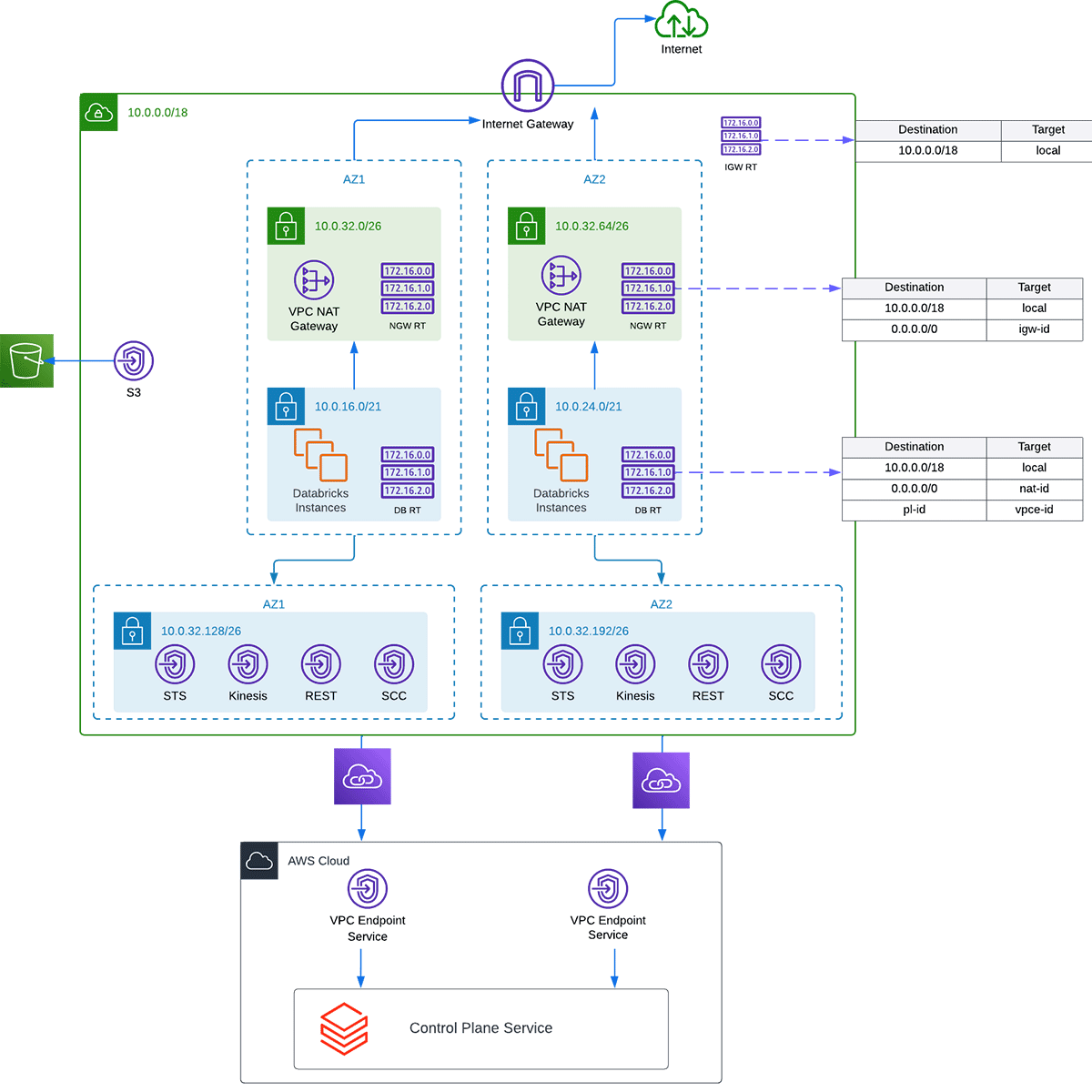
エンタープライズにおけるDatabricksデプロイメントの例
J: この連絡のプロセスのことを、セキュアクラスター接続リレーあるいは略してSCCと呼びます。このリレーによって、あなたの環境のDatabricksではEC2インスタンスのパブリックIPやオープンなポートが不要となり、常にトラフィックはデータプレーンからコントロールプレーンに流れるようになります。このアウトバウンドトラフィックのルートに関しては2つの選択肢があります。最初のオプションは、SCCをNATゲートウェイとインターネットゲートウェイ、あるいは、他のマネージドインフラストラクチャ経由で公衆インターネットにルーティングさせるというものです。標準的なエンタープライズのデプロイメントにおいては、SCCリレーやREST APIのトラフィックをAWSのバックボーンインフラストラクチャ経由でルーティングするAWS PrivateLinkエンドポイントを用いることで、さらなるセキュリティ層を追加することを強くお勧めしています。
C: 我々のユーザーがトランジットVPCからコントロールプレーンのDatabrikcsワークスペースにルーティングされるように、PrivateLinkをフロントエンド接続でも使えますか?
J: はい。PrivateLinkが有効化されたワークスペースを作成する際、プライベートアクセスオブジェクト、PASを作成する必要があります。PASには公衆回線によるアクセスを有効にするか、無効にするかのオプションがあります。ワークスペースのURLはインターネット上で有効ですが、PASの公衆回線アクセスがfalseに設定されており、ユーザーがVPCエンドポイント経由でルーティングされていない場合、不正なネットワークからワークスペースにアクセスしたと判断されサインインすることはできません。エンタープライズのお客様がフロントエンドPrivateLink接続の代わりに用いているのは、IPアクセスリストです。
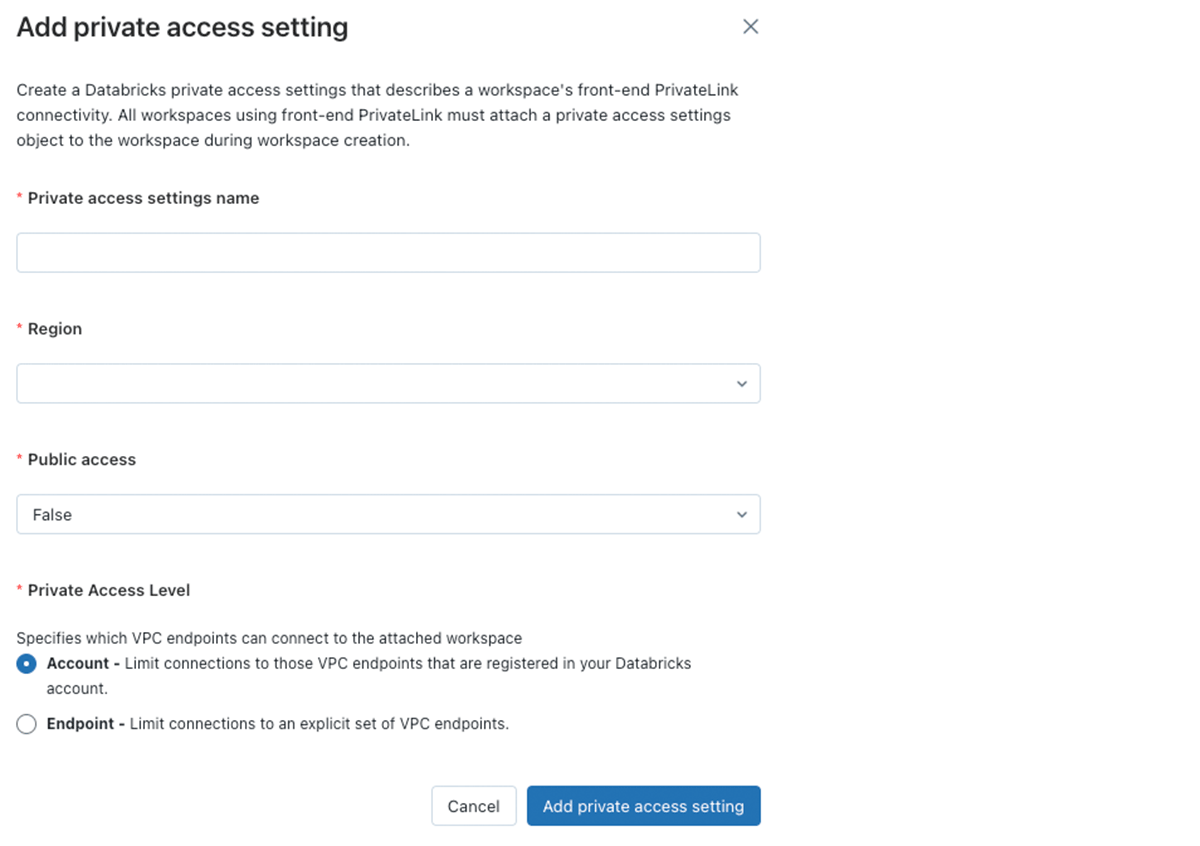
Databricksアカウントコンソールにおけるプライベートアクセス設定の追加
C: それでは、適切なPrivateLink設定によって、コントロールプレーンへのルーティングをPrivateLink経由にし、EC2インスタンスが使用するインターネットゲートウェイを設けない場合、クラスターは完全にロックダウンされることになりますか?
J: はい、可能です。しかし、依然としてS3ゲートウェイエンドポイント、Kinesisインタフェースエンドポイント、STSインタフェースエンドポイントは必要です。あと、DatabricksのデフォルトHiveメタストアや、PyPI、Mavenのようなリポジトリにアクセスできないことに注意してください。デフォルトHiveメタストアにアクセスできないので、自身のRDSインスタンスあるいはAWS Glue Catalogを使用する必要があります。そして、パッケージに関しては、ご自身の環境でリポジトリをホストする必要があります。これらの理由から、代わりにユーザーのクラスターが公衆インターネットのどの領域にアクセスできるのかを制限するために、外向け通信のファイアウォールをお勧めしています。
C: S3、Kinesis、STS、なぜこれらのエンドポイントが必要なのですか?
J: そうですね。S3エンドポイントはEC2がルートバケットに到達するために必要なだけではなく、あなたのデータを格納しているS3にアクセスするために必要となります。これによって、費用を削減し、S3へのトラフィックをAWSバックボーンに保持することで、さらなるセキュリティ層を追加することになります。Kinesisは、重要なセキュリティ情報、監査情報などを含むクラスターから収集される内部ログのためのものです。STSはEC2インスタンスに引き渡される一時的な資格情報のためのものです。
J: それでは、カバーしてきたものをラップアップしましょう。VPC、サブネット、セキュリティグループ、PrivateLink、その他のエンドポイント、EC2インスタンスがコントロールプレーンへのアウトバウンド接続をどのように行うのかを議論しました。デプロイメントに関してお話ししたい最後の2つのパーツは、クロスアカウントIAMロールとワークスペースルートバケットです。
J: デプロイメントに必要な要素であるクロスアカウントIAMロールは、あなたの環境でEC2インスタンスを起動する際に使用されます。API、ユーザーインタフェース、スケジュールされたジョブに関係なく、これはクラスターを作成するためにDatabricksがassumeするロールとなります。そして、Unity Catalogや直接インスタンスプロファイルを追加する際、DatabricksはEC2インスタンスに必要なロールを引き渡します。
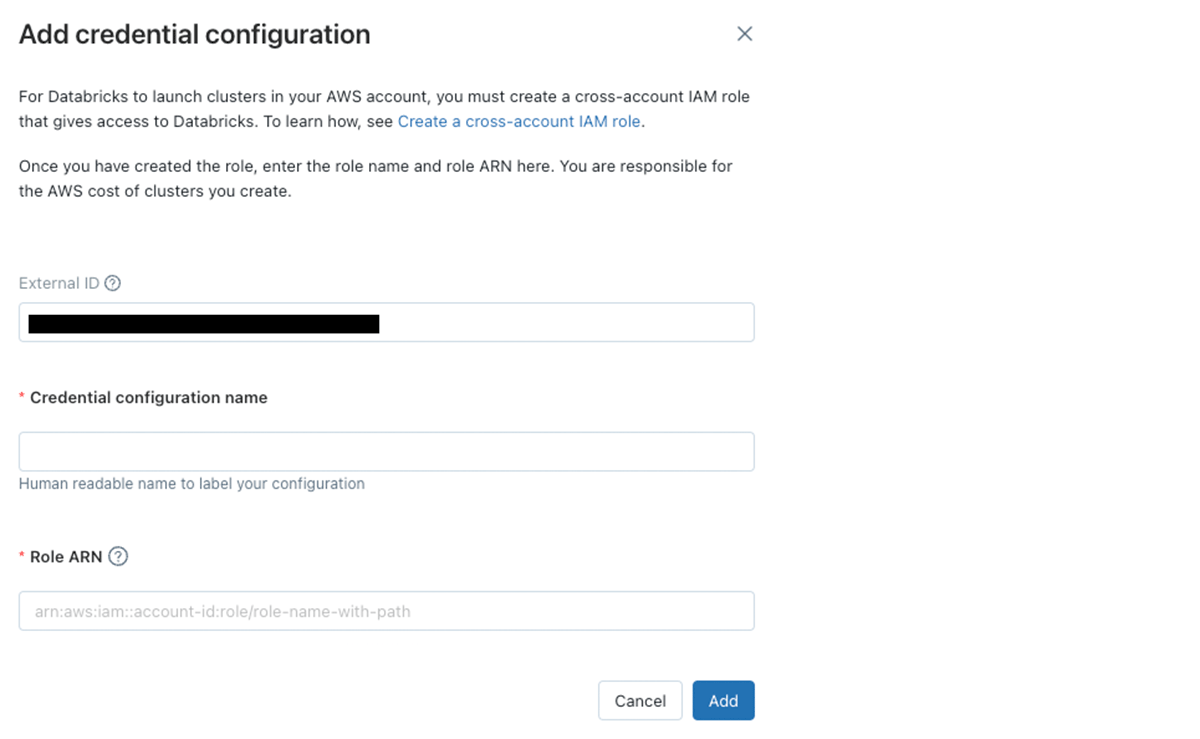
Databricksアカウントコンソールでのクロスアカウントロールの追加
C: クロスアカウントロールは、我々の環境におけるPaaSソリューションで標準となっているので問題ありません。しかし、VPC、サブネットを制限したクロスアカウントロールのサンプルはありますか?
J: もちろんです。必要なリソースに対してのみクロスアカウントを制限することをお勧めしています。ドキュメントでポリシーを参照することができます。他の適用できる制限として、同じページで説明されていますがソースとなるEC2 AMIを制限するということです。あと、ドキュメントでUnity Catalogとサーバレス向けの適切なIAMロールを参照することができます。
J: デプロイメントで必要になる最後の要素は、ワークスペースのルートバケットです。このS3バケットは、クラスターログ、ノートブックの改訂履歴、ジョブの実行結果やライブラリのようなワークスペースオブジェクトの格納のために使用されます。Databricksのコントロールプレーンが書き込めるように固有のバケットポリシーを設定します。このバケットを顧客データや複数のワークスペースで使用しないことがベストプラクティスとなります。通常のバケットと同じように、これらのバケットをCloudTrailで追跡することができます。
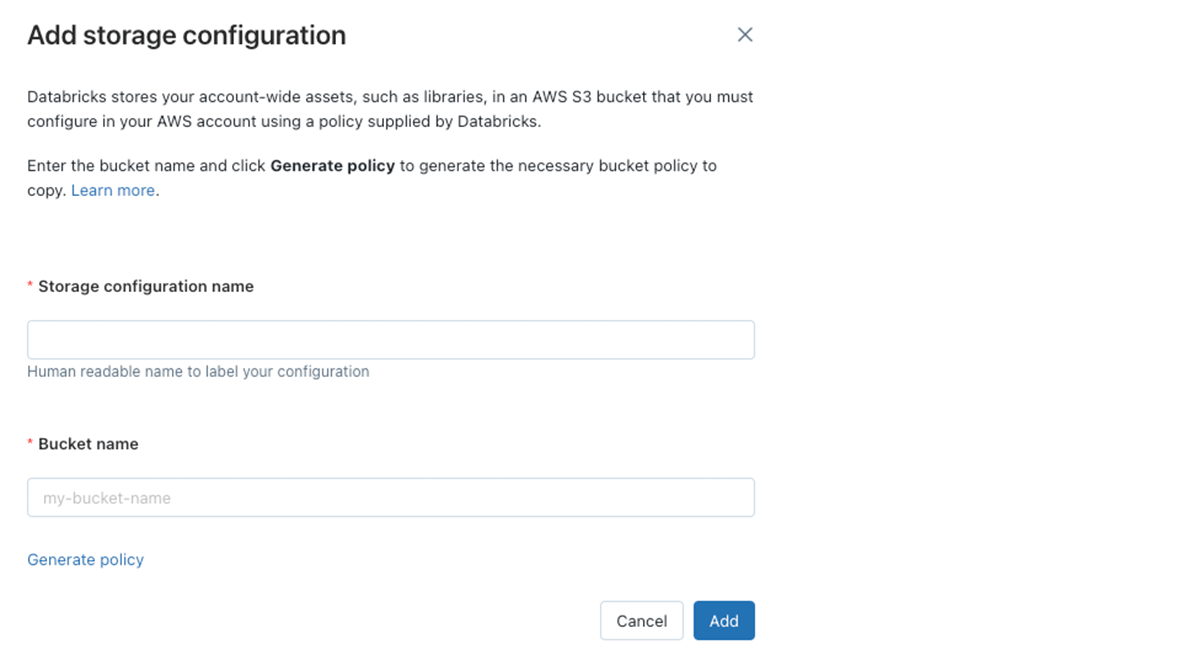
Databricksアカウントコンソールにおけるワークスペースルートバケットの追加
C: AWSアカウントにあるすべてのS3バケットに対して暗号化の要件があります。顧客管理キーを用いてルートバケットを暗号化することはできますか?
J: はい、可能です。言っていただいて助かりました。デプロイメントの一部として、あるいは後で追加する設定として、マネージドストレージやワークスペースストレージに対して顧客管理キーを追加することができます。
- ワークスペースストレージ: 上述したルートバケット、EBSボリューム、ジョブの実行結果、Delta Live Tablesなどを格納します。
- マネージドストレージ: ノートブックソースやメタデータ、パーソナルアクセストークン、Databricks SQLのクエリーを格納します。
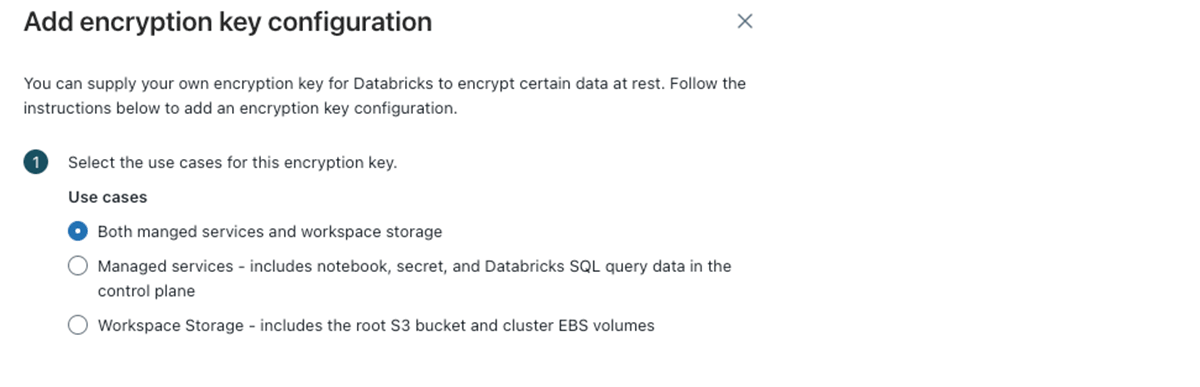
Databricksアカウントコンソールにおける暗号化キー設定の追加
J: このコールの後にドキュメントをお送りするようにします。
J: もうそろそろ時間のようですね。それでは、本日議論した推奨事項をまとめさせてください。説明したように、AWSにおけるDatabricksデプロイメントでは、3つの必要なパーツと1つのオプションのパーツがあります。ネットワーク設定、ストレージ設定、資格情報設定です。
- ネットワーク設定: 適切なユースケースやユーザー数に応じて、VPCとサブネットのサイジングを行う必要があります。この設定では、バックエンドPrivateLinkがデファクトの推奨事項となります。ユーザーアクセスを制限する際にはフロントエンドPrivateLinkやIPアクセスリストを検討してください。クラスターをデプロイする際にIP空間を最大限利用できるように、サブネットにデプロイする際にオートAZを使うようにしてください。最後に、PrivateLinkを使っているかどうかに関係なく、最低でもSTS、Kinesis、S3エンドポイントを追加するようにしてください。AWSバックボーンで通信を行うことで、さらなるセキュリティレイヤーを追加できるだけでなく、コストを劇的に削減することができます。
- ストレージ設定: ワークスペースのルートバケットを作成した後は、このバケットを顧客データや他のワークスペースの共有目的で使用しないでください。
- 資格情報設定: 上で議論したように、ドキュメントに基づいてクロスアカウントロールのポリシーを絞り込んでください。
- 暗号キー設定: ワークスペースのストレージ、EBSボリューム、マネージドオブジェクトに対する暗号化の実装を計画してください。ワークスペースをデプロイした後に実装することができますが、ワークスペースストレージオブジェクトに関しては、新規に作成されたオブジェクトのみが暗号化されます。
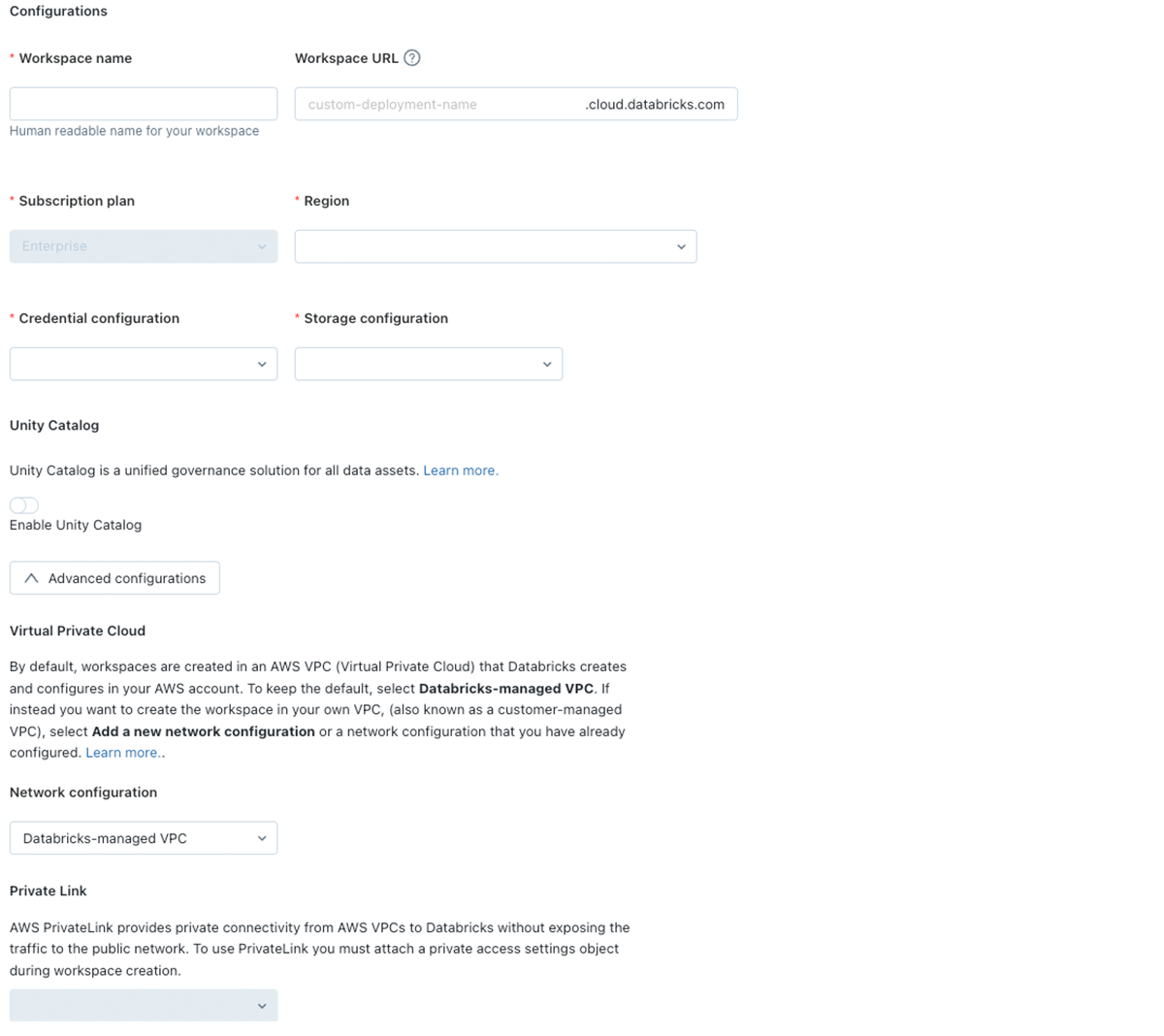
Databricksアカウントコンソールにおけるワークスペースの作成
C: 説明していただきありがとうございます。最後の質問ですが、これら全てのデプロイを自動化することは可能ですか?我々はTerraformを使っていますが、この時点ではどのツールでも構いません。
J: もちろんです。我々にはTerraformプロバイダーがあります。このコールの後に資料をお送りします。また、POCで使用でき、Terraformスクリプトと連携できるCloudFormationテンプレートであるAWS QuickStartもあります。
J: いずれにしても本日はありがとうございました。質問があればご連絡ください!
まとめ
この会話スタイルの記事が、AWSでDatabricksをデプロイする際の要件、推奨事項、ベストプラクティスの理解に役立てば幸いです。
次の記事では、API、CloudFormation、Terraformを用いてデプロイメントの自動化とベストプラクティスについて議論します。
次を楽しみにしていてください!