Customer-managed VPC | Databricks on AWS [2021/6/1時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
重要!
この機能はE2バージョンのDatabricksプラットフォームで利用できます。
概要
デフォルトでは、お客様のAWSアカウント上にDatabricksが単一のAWS VPC(Virtual Private Cloud)を作成します。オプションとして、お客様の組織の標準に従いながらも、Databricksの要件に応えるために、お客様の手で作成した顧客管理のVPC(customer-managed VPC)を使うこともできます。
重要!
AWS PrivateLink(Public Preview)を利用したワークスペースを設定するには、対象のワークスペースで顧客管理VPC(customer-managed VPC)を使用する必要があります。
以下のケースでは、顧客管理VPCは良いソリューションとなります:
- お客様の情報セキュリティによって、お客様のAWSアカウントではPaaSプロバイダーによるVPCを許可していない。
- 内部情報セキュリティ、クラウドエンジニアリングチームによって作成されたドキュメントで規定され、設定されるようにVPC作成の承認プロセスが存在する。
以下のメリットがあります:
- 権限レベルを低い状態に保てる: ご自身のAWSアカウントに対するコントロールを保持できます。Databricks管理のVPCのケースでは必要なクロスアカウントIAMロールを通じたDatabricksへの権限委譲が不要になります。
- ネットワークオペレーションの簡素化: ネットワークの領域を有効活用できます。ワークスペースのサブネットをデフォルトのCIDR /16より小さいサイズに設定できます。他のソリューションでは必要になるかもしれない複雑なVPCピアリングの設定は不要です。
- VPCの統合: 複数のDatabricksワークスペースは一つのデータプレーンVPCを共有できるので、インスタンス、課金管理の観点で好ましい形にできます。
-
外向き通信の制限: デフォルトでは、データプレーンはDatabricksランタイムのワーカーノードからの外向きの通信を制限しません。顧客管理VPCを使用するように設定されたワークスペースにおいては、特定の内外のデータソースにアクセスを制限するように、外向きのファイアウォール、プロキシーアプライアンスを使用できます。
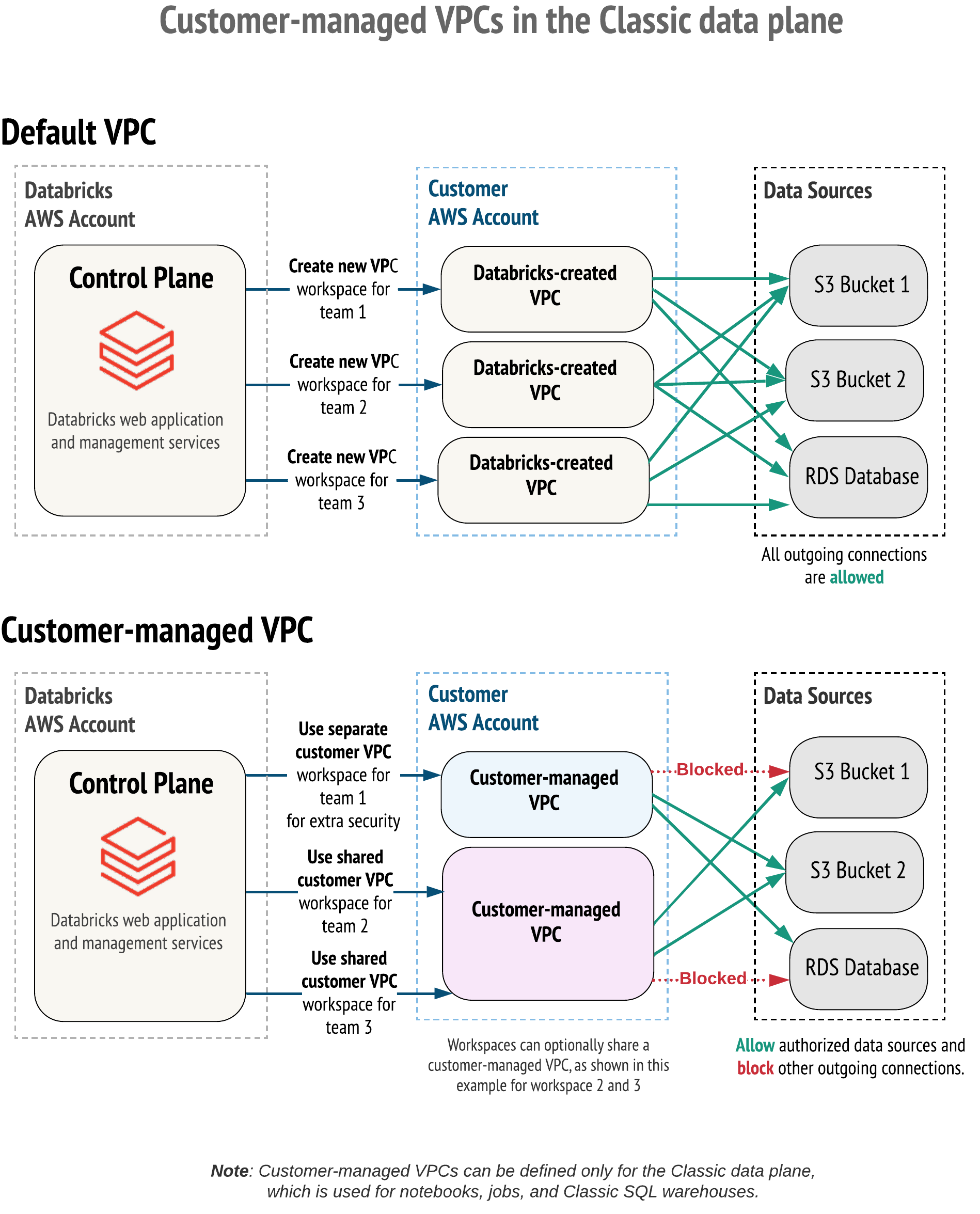
顧客管理VPCを活用するためには、最初にDatabricksワークスペースを作成する際にVPCを指定する必要があります。既存のDatabricks管理のワークスペースをお客様のVPCに持ち込むことはできません。しかし、お客様管理VPCにある既存のワークスペースを別のお客様管理VPCに移動することは可能です。稼働中のワークスペースの更新を参照ください。
顧客管理VPCを用いたワークスペースの設定
お客様管理のVPCにワークスペースをデプロイするには、以下の作業が必要となります。
-
以下のVPCの要件に合致するVPCを作成します。
-
ワークスペース作成時に、Account APIを用いて、VPCのネットワーク設定をDatabricksに登録します。Step 4: Configure customer-managed VPC (optional, but required if you use PrivateLink)を参照ください。
VPCをDatabricksに登録する際には、VPC ID、サブネットID、セキュリティグループIDを指定する必要があります。
情報
具体的な設定例に関しては、Databricksにおける顧客管理VPC(実践編)をご覧ください。
VPCの要件
Databricksワークスペースをホストするためには、VPCは以下の要件を満たす必要があります。以下に構成例を図示します。
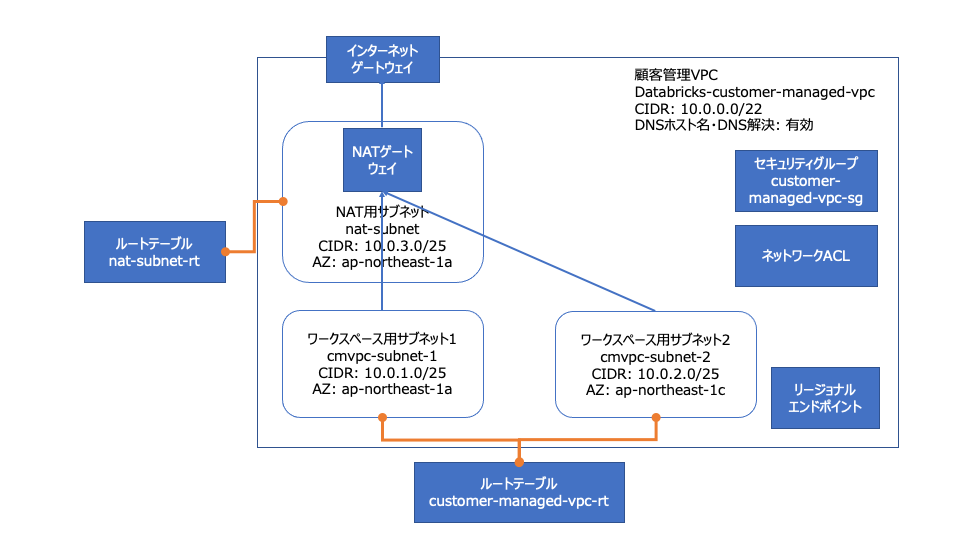
VPC構成例:CIDRやワークスペース用サブネットの数はお客様要件に基づいて決定してください
要件:
VPCのリージョン
ワークスペースのデータプレーンVPCは、AWSのap-northeast-1、ap-south-1、ap-southeast-2、ca-central-1、eu-west-1、eu-west-2、eu-central-1、us-east-1、us-east-2、us-west-1、us-west-2リージョンに存在する必要があります。しかし、マネージドサービスやワークスペースストレージをお客様管理の鍵で暗号化する場合には、us-west-1リージョンは利用できません。
VPCのサイズ
単一のAWSアカウントにおいて、一つのVPCを複数のワークスペースで共有することができます。しかし、ワークスペース間でサブネットとセキュリティグループを再利用することはできません。VPCとサブネットのサイズを適切に設定するようにしてください。Databricksはノードごとに2つのIPアドレスを割り当てます。一つは管理用トラフィック、一つはApache Sparkアプリケーション用となります。それぞれのサブネットにおけるインスタンス総数は、利用可能なIPアドレスの数の半分になります。サブネットをご覧ください。
VPC IPアドレスのレンジ
DatabricksはワークスペースVPCに対するネットマスクを制限しませんが、それぞれのサブネットは/17と/26の間のネットマスクを持つ必要があります。このことは、ワークスペースが/26のネットマスクの2つのサブネットを持つ場合は、ワークスペースのVPCのネットマスクは、/25より小さいものである必要があることを意味します。
重要!
VPCにセカンダリーCIDRブロックが設定されている場合には、Databricksワークスペースに対するサブネットが、同じVPC CIDRブロックに設定されていることを確認してください。
DNS
VPCはDNSホスト名を持ち、DNS解決が有効になっている必要があります。
サブネット
Databricksは、少なくともそれぞれのワークスペースの二つのサブネットにアクセスする必要があり、それぞれのサブネットは異なるアベイラビリティゾーンに存在する必要があります。Create network configuration APIの呼び出しにおいては、アベイラビリティゾーンに対して、複数のDatabricksワークスペースサブネットを指定することはできません。ネットワークセットアップの際にアベイラビリティゾーンに複数のサブネットを設定できますが、Databricksワークスペースに対して、アベイラビリティゾーンごとに選択できるサブネットは一つだけです。
Databricksはノードごとに2つのIPアドレスを割り当てます。一つは管理用トラフィック、一つはApache Sparkアプリケーション用となります。それぞれのサブネットにおけるインスタンス総数は、利用可能なIPアドレスの数の半分になります。
それぞれのサブネットは/17と/26の間のネットマスクを持つ必要があります。
重要!
顧客管理VPCに指定するサブネットは、1つのDatabricksワークスペースに対してのみ使用する必要があります。これらのサブネットを、他のDatabricksワークスペースを含む他のリソースと共有することはできません。
追加のサブネット要件
- プライベートサブネットである必要があります。
- サブネットはNATゲートウェイとインターネットゲートウェイ、あるいは他の同様の顧客管理アプライアンスインフラストラクチャを用いて、パブリックネットワークに対してアウトバウンドのアクセスができる必要があります。
- NATゲートウェイはNATゲートウェイ専用のサブネット内でセットアップされる必要があり、インターネットゲートウェイ、あるいは類似の顧客管理のアプライアンスストラクチャに対して
(0.0.0.0/0)トラフィックをルーティングするように設定される必要があります。
重要!
セキュアクラスター接続(2020/9/1からデフォルトとなっています)を使用しているワークスペースでは、VPCからパブリックネットワークに対するアウトバウンド接続が必要です。
サブネットのルートテーブル
ワークスペースのサブネットに対するルーティングテーブルは、適切なネットワーク機器に向かう(0.0.0.0/0)トラフィックを含む必要があります。ワークスペースがセキュアクラスター接続(2020/9/1からデフォルトとなっています)を使用している場合には、(0.0.0.0/0)トラフィックはNATゲートウェイ、あるいはお客様管理のNATデバイス、プロキシーアプライアンスをターゲットにする必要があります。
重要!
Databricksを利用する際、サブネットの許可リストに0.0.0.0/0を含める必要があります。外向きの通信を制限するには、Databricksが接続する必要があるURLへの通信のみを許可し、他の通信をブロックするために、イグレスファイアウォールかプロキシーアプライアンスを使用してください。ファイアウォールアプライアンスインフラストラクチャを参照ください。
ここで説明しているのはベースラインのガイドラインです。要件はお客様によります。質問がある場合には、Databricks窓口にお尋ねください。
セキュリティグループ
Databricksは1個から5個のAWSセキュリティグループにアクセスする必要があります。新たなセキュリティグループを作成するのではなく、既存のセキュリティグループを再利用することもできます。
セキュリティグループには以下のルールが含まれている必要があります。
イグレス(アウトバウンド):
- ワークスペースのセキュリティグループに対して、すべてのTCP、UDPアクセスを許可(内部トラフィック用)
- 以下のポートにおける
0.0.0.0/0に対するTCPアクセスを許可- 443: Databricksインフラストラクチャ、クラウドデータソース、ライブラリリポジトリ向け
- 3306: メタストア向け
- 6666: PrivateLinkを使用している場合にのみ必要
イングレス(インバウンド):
- 通信元が同じセキュリティグループを使用している場合には全てのポートのTCP通信を許可
- 通信元が同じセキュリティグループを使用している場合には全てのポートのUDP通信を許可
サブネットのネットワークACL
サブネットのネットワークACLは、すべての内向き、外向きのいかなる通信を拒否してはいけません。Databricksはワークスペース作成時に以下のルールを検証します。
- ソース
0.0.0.0/0に対してALLOW ALL - イグレス(インバウンド)
- ワークスペースVPCのCIDRの全ての通信を許可(内部トラフィック向け)
- 以下のポートの
0.0.0.0/0へのTCPアクセスを許可- 443: Databricksインフラストラクチャ、クラウドデータソース、ライブラリリポジトリ向け
- 3306: メタストア向け
- 6666: PrivateLinkを使用している場合にのみ必要
重要!
アウトバウンド通信に追加のALLOW、DENYの設定をした場合には、Databricksが要求するルールが上書きするように最も高い優先度(最も少ないルールナンバー)にしてください。
注意
Databricksを使用する際、サブネットのネットワークACLの許可リストに0.0.0.0/0を追加する必要があります。外向きの通信を制限するには、Databricksが接続する必要があるURLへの通信のみを許可し、他の通信をブロックするために、イグレスファイアウォールかプロキシーアプライアンスを使用してください。ファイアウォールアプライアンスインフラストラクチャを参照ください。
ファイアウォールアプライアンスインフラストラクチャ
セキュアクラスター接続(2020/9/1からデフォルトとなっています)を使用している場合、Databricksが接続する必要があるURLへの通信のみを許可し、他の通信をブロックするために、イグレスファイアウォールかプロキシーアプライアンスを使用してください。以下の接続が行えるように設定してください。
- ファイアウォールやプロキシーアプライアンスが、DatabricksワークスペースVPCと同じVPCに存在している場合は、以下の接続を許可するように設定してください。
- 異なるVPC、あるいはオンプレミスにファイアウォール、プロキシーアプライアンスが存在する場合には、
0.0.0.0/0を、当該VPC、ネットワークにルーティングし、その通信を許可するようにプロキシーアプライアンスを設定してください。
以下の接続を許可してください。
- Databricksウェブアプリケーション: 必須。あなたのワークスペースに対するREST API呼び出しにも使用されます。
- Databricksセキュアクラスター接続(SCC)リレー: セキュアクラスター接続を使用している場合(2020/9/1以降のE2環境ではデフォルトで有効)には必須。
- AWS S3グローバルURL: DatabricksがルートS3バケットにアクセスするために必要。
- AWS S3リージョナルURL: オプションですが、他のS3バケットにアクセスする際には、S3リージョナルエンドポイントへのアクセスを許可する必要があります。代わりに、AWSネットワークバックボーンのプライベートトンネルを通じて通信されるように、S3エンドポイントを作成することをお勧めします。
- AWS STSグローバルURL: 必須。
- AWS STSリージョナルURL: リージョナルエンドポイントへの切り替えが起こるので必須。
-
AWS KinesisリージョナルURL: ソフトウェアを管理、監視するために必要となるログを記録するために、Kinesisエンドポイントが必要になります。多くのリージョンではリージョナルURLを使用してください。しかし、
us-west-1のVPCでは現在利用できないので、Kinesis URLがus-west-1ではなくus-west-2に許可されていることを確認してください。代わりに、AWSネットワークバックボーンのプライベートトンネルを通じて通信されるように、Kinesis VPCエンドポイントを作成することをお勧めします。 - (データプレーンリージョンにおける)テーブルメタストアRDSリージョナルURL: お使いのワークスペースが、お使いのデータプレーンリージョンと同じリージョンに存在するデフォルトのHiveメタストアにアクセスする際には必須となります。同じ国でもコントロールプレーンと異なるリージョンになるケースはあります。デフォルトのHiveメタストアの代わりに、ご自身でテーブルメタストアを実装することも可能ですが、この場合、ご自身でネットワークルーティングを設定する必要があります。
必要となるデータプレーンのアドレス
お使いのリージョンに合わせて、以下のアドレスからの接続を許可して下さい。
注意
以下の表はap-northeast-1リージョンに限定しています。全てのデータは原文を参照してください。
| エンドポイント | VPCリージョン | アドレス | ポート |
|---|---|---|---|
| Webapp | ap-northeast-1 | tokyo.cloud.databricks.com | 443 |
| SCC relay | ap-northeast-1 | tunnel.ap-northeast-1.cloud.databricks.com | 443 |
| ルートバケット用S3 global | すべて | s3.amazonaws.com | 443 |
| 他のバケット用S3 regional: VPCエンドポイントの利用を推奨 | すべて | s3.<リージョン名>.amazonaws.com | 443 |
| STS global | すべて | sts.amazonaws.com | 443 |
| Kinesis: VPCエンドポイントの利用を推奨 | ほとんどのリージョン | kinesis.<リージョン名>.amazonaws.com | 443 |
| RDS(ビルトインメタストアを利用する場合) | ap-northeast-1 | mddx5a4bpbpm05.cfrfsun7mryq.ap-northeast-1.rds.amazonaws.com | 3306 |
| Databricksコントロールプレーンインフラストラクチャ | ap-northeast-1 | 35.72.28.0/28 | 443 |
リージョナルエンドポイント
顧客管理VPC(オプション)を使用して、セキュアクラスター接続(2020/9/1以降はデフォルト)を使用している場合には、AWSグローバルエンドポイントと比較して、より直接的な接続とコスト削減の観点から、VPCがAWSサービスに対するリージョナルVPCエンドポイントのみを利用するようにしたいケースがあると思います。顧客管理VPCによるDatabricksワークスペースが接続すべきAWSサービスは4つあります。STS、S3、Kinesis、RDSです。
ご利用のVPCからRDSサービスへの接続が必要になるのは、デフォルトのDatabricksのメタストアを利用する場合のみです。RSDのVPCエンドポイントは存在しませんが、デフォルトのメタストアを利用する代わりにご自身でメタストアを設定することができます。HiveメタストアとAWS Glueを用いて外部メタストアを実装することができます。
他の3つのサービスに関しては、パブリックネットワークではなくセキュアなAWSバックボーンを介してクラスターからの適切なリージョン内通信が可能な、VPCゲートウェイあるいはインタフェースエンドポイントを作成することができます。
-
S3: Databricksクラスターのサブネットから直接アクセスできるVPCゲートウェイエンドポイントを作成します。これによって、ワークスペースからリージョン内のS3バケットへの通信をエンドポイント経由にすることができます。クロスリージョンバケットへのアクセスに際しては、イグレスアプライアンスでS3グローバルURL
s3.amazonaws.comへのアクセスを解放するか、0.0.0.0/0からAWSインターネットゲートウェイへの通信をルーティングします。リージョナルエンドポイントとDBFS FUSEを使用するには以下の設定を行います。
- Databricksランタイム6.x以降ではクラスター設定で環境変数
AWS_REGION=<aws-region-code>を設定する必要があります。例えば、北バージニアリージョンにワークスペースにデプロイされた場合には、AWS_REGION=us-east-1を設定します。全てのクラスターに設定を適用するにはクラスターポリシーを使用します。 - Databricksランタイム5.5 LTSでは、
AWS_REGION=<aws-region-code>とDBFS_FUSE_VERSION=2を設定します。
- Databricksランタイム6.x以降ではクラスター設定で環境変数
-
STS: Databricksクラスターのサブネットから直接アクセスできるVPCインタフェースエンドポイントを作成します。エンドポイントをワークスペースのサブネットに作成できます。これによってワークスペースからSTSへの通信がエンドポイント経由になります。
-
Kinesis: Databricksクラスターのサブネットから直接アクセスできるVPCインタフェースエンドポイントを作成します。エンドポイントをワークスペースのサブネットに作成できます。ワークスペースのVPCと同じセキュリティグループを使用することをお勧めします。これによってワークスペースからKinesisへの通信がエンドポイント経由になります。ここでの唯一の例外は
us-west-1リージョンにワークスペースが存在するケースです。この場合、Kinesisのストリームはus-west-2へのクロスリージョンとなります。
リージョナルエンドポイントのトラブルシュート
期待した通りにVPCエンドポイントが動作しない場合、例えば、データソースにアクセスできない、通信がエンドポイント経由にならない場合には、以下のアプローチを試してください。
-
クラスター設定に、お使いのリージョンを示す
AWS_REGION環境変数を追加します。全てのクラスターに適用する際には、クラスターポリシーを使用します。DBFS FUSEを使用するために設定済みの場合があります。 -
必要なApache Spark設定を追加します。
- ソースとなるノートブック
Scala
%scala
sc.hadoopConfiguration.set("fs.s3a.endpoint", "https://s3..amazonaws.com")
sc.hadoopConfiguration.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts..amazonaws.com")
```
**Python**
```python
%python
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "https://s3..amazonaws.com")
sc._jsc.hadoopConfiguration().set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts..amazonaws.com")
```
- あるいはクラスターのApache Spark設定
```
spark.hadoop.fs.s3a.endpoint https://s3..amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts..amazonaws.com
```
全てのクラスターに設定を適用するには、クラスターポリシーを使用してください。
(オプション)アウトバウンドアクセスの制限
アウトバウンド通信に制限をかけたい場合には、AWS S3に対してクロスリージョンアクセスをしていないことを確認してください。
アウトバウンド通信に制限をかけるには以下の手順を踏みます。
-
外向きのルーティングを行なっているインフラストラクチャに対して、ウェブアプリケーション、セキュアクラスター接続リレー、メタストアエンドポイントに対して明示的にアクセスを許可します。これはNATゲートウェイやインターネット接続を有するサードパーティのアプライアンスになります。ファイアウォールアプライアンスインフラストラクチャを参照してください。
重要!
接続先の指定においては、IPアドレスではなくドメイン名を指定することを強くお勧めします。 -
NATゲートウェイのターゲットから
0.0.0.0/0のディスティネーションを削除します。作成したVPCによってはディスティネーションが設定されていないかもしれません。その場合には、この手順をスキップしてください。
(オプション)インスタンスプロファイルを用いたS3へのアクセス
インスタンスプロファイルを用いてS3マウントにアクセスするには、以下のSpark設定を行ってください。
-
ソースのノートブック
Scala
%scala
sc.hadoopConfiguration.set("fs.s3a.endpoint", "https://s3..amazonaws.com")
sc.hadoopConfiguration.set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts..amazonaws.com")
```
**Python**
```python
%python
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "https://s3..amazonaws.com")
sc._jsc.hadoopConfiguration().set("fs.s3a.stsAssumeRole.stsEndpoint", "https://sts..amazonaws.com")
```
-
あるいはクラスターのApache Spark設定
spark.hadoop.fs.s3a.endpoint https://s3..amazonaws.com
spark.hadoop.fs.s3a.stsAssumeRole.stsEndpoint https://sts..amazonaws.com
```
全てのクラスターに設定を適用するには、クラスターポリシーを使用してください。
警告!
S3サービスに関しては、ノートブック、クラスターレベルで追加のリージョナルエンドポイントを適用する際に制限があります。特に、イグレスファイアウォール、プロキシーでグローバルS3URLが許可されていたとしても、クロスリージョンのS3アクセスはブロックされます。お客様のDatabricksデプロイメントがクロスリージョンのS3アクセスを必要とする場合には、ノートブック、クラスターレベルでのSpark設定が適用されないことに注意してください。
(オプション)S3へのアクセス制限
S3に対する読み書きの多くはデータプレーンで完結するものです。しかし、いくつかの管理オペレーションはDatabricksが管理するコントロールプレーンから起動されます。特定のIPアドレスからS3へのアクセスを限定する際には、S3バケットポリシーを作成します。バケットポリシーでは、aws:SourceIpリストにIPアドレスを含めます。VPCエンドポイントを使用している場合には、ポリシーのaws:sourceVpceにエンドポイントを追加します。
S3バケットポリシーの詳細に関しては、Amazon S3ドキュメントのLimiting access to specific IP addressesを参照してください。このトピックに関するバケットポリシーのサンプルもあります。
バケットポリシーの要件
クラスターが適切にアクセスできるように、バケットポリシーは以下の要件を満たす必要があります。
- お使いのリージョンのコントロールプレーンのNAT IPからのアクセスを許可する必要があります。
- 以下のいずれかを実施することで、データプレーンVPCからのアクセスを許可する必要があります。
- (推奨)お使いの顧客管理VPCのゲートウェイVPCエンドポイントを設定し、バケットポリシーの
aws:sourceVpceに追加する。あるいは、 -
aws:SourceIpリストにデータプレーンのNAT IPを追加。
- (推奨)お使いの顧客管理VPCのゲートウェイVPCエンドポイントを設定し、バケットポリシーの
- **Amazon S3のエンドポイントポリシー**を使っている場合は、ポリシーに以下を含める必要があります。
- お使いのワークスペースのルートストレージバケット
- お使いのリージョンにおけるアーティファクト、ログ、共有データセット向けバケット
- お客様の企業ネットワークからの接続を維持するために、お客様の企業VPNのパブリックIPアドレスのように、既知かつ信頼のおけるIPアドレスからのアクセスを常に許可することをお勧めします。これはAWSコンソールにおいても拒否条件が適用されるためです。
必要なIPアドレスとストレージバケット
以下の表には、ワークスペースのS3バケットへのアクセスを制限するために、S3バケットポリシーとVPCエンドポイントポリシーを使用する際に必要な情報も含まれています。
注意
以下の表はap-northeast-1リージョンに限定しています。全てのデータは原文を参照してください。
| リージョン | コントロールプレーンのNAT IP | アーティファクトストレージバケット | ログストレージバケット | 共有データセットバケット |
|---|---|---|---|---|
| ap-northeast-1 | 18.177.16.95/32 | databricks-prod-artifacts-ap-northeast-1 | databricks-prod-storage-tokyo | databricks-datasets-tokyo |
バケットポリシーのサンプル
以下のサンプルでは、推奨されるIPアドレスと必要なストレージバケットを指定するためのプレースホルダーが含まれます。クラスターが適切に起動しアクセスできるように要件を確認してください。
Databricksコントロールプレーン、データプレーン、信頼されたIPのみにアクセスを制限する
このS3バケットポリシーは、Deny条件を用いて、コントロールプレーンとデータプレーン、指定した企業VPNのIPにのみアクセスを許可します。環境に応じてプレースホルダーを置換してください。任意のIPをポリシーに追加できます。保護したいS3バケットごとにポリシーを作成します。
重要!
VPCエンドポイントを使っている場合には、このポリシーは不完全なものになります。Databricksコントロールプレーン、VPCエンドポイント、信頼されたIPのみにアクセスを制限するを参照ください。
{
"Sid": "IPAllow",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<S3-BUCKET>",
"arn:aws:s3:::<S3-BUCKET>/*"
],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": [
"<CONTROL-PLANE-NAT-IP>",
"<DATA-PLANE-NAT-IP>",
"<CORPORATE-VPN-IP>"
]
}
}
}
Databricksコントロールプレーン、VPCエンドポイント、信頼されたIPのみにアクセスを制限する
S3にアクセスするためにVPCエンドポイントを使用している際には、ポリシーに第二の条件を追加する必要があります。aws:sourceVpceリストにVPCエンドポイントを追加することでアクセスを許可します。
このS3バケットポリシーは、VCPエンドポイント、コントロールプレーン指定した企業VPNのIPにのみアクセスを許可します。
VPCエンドポイントを使用する際には、S3バケットポリシーの代わりにVPCエンドポイントp路シーを使用できます。VPCEポリシーは、お使いのルートS3バケットへ、お使いのリージョンにおけるアーティファクト、ログ、共有データセット向けバケットへのアクセスを許可する必要があります。詳細をAWSドキュメントのVPCエンドポイントポリシーの使用で確認することができます。
環境に応じてプレースホルダーを置換してください。
{
"Sid": "IPAllow",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<S3-BUCKET>",
"arn:aws:s3:::<S3-BUCKET>/*"
],
"Condition": {
"NotIpAddressIfExists": {
"aws:SourceIp": [
"<CONTROL-PLANE-NAT-IP>",
"<CORPORATE-VPN-IP>"
]
},
"StringNotEqualsIfExists": {
"aws:sourceVpce": "<VPCE-ID>"
}
}
}