本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
クラウドエンジニア向けDatabricksアーキテクチャおよびワークフロー
クラウドエンジニアリングチームとして、お使いのAmazon Web Services (AWS)環境にplatform as a solution (PaaS)をデプロイするように、他のチームからリクエストを受け取ることは日常的なことでしょう。これらのリクエストは「POCのために開発用AWSアカウントにDatabricksをデプロイしなくてはなりません。すでにセキュリティとレビューを行いOKをもらっています」と言ったものかもしれません。
これらのリクエストを受け取ると、リクエスト元から更なる文脈を得るためのミーティングの設定からスタートし、ネットワーク要件やPaaSベンダーのウェブサイトのアーキテクチャサンプルのドキュメントを組み合わせ、利用できそうなインフラストラクチャアズコード(IaC)のサンプルを探すことになるかもしれません。
このブログシリーズでは、クラウドエンジニアの視点からDatabricks on AWSをブレークダウンすることで、皆様の発見プロセスを短縮するお手伝いをします。このブログシリーズの最後までに達成するゴールは、DatabricksとDatabricksがデータチームに提供する価値、プラットフォームのアーキテクチャ、お使いのAWS環境に対する影響、皆様の会社のネットワークトポロジーにワークスペースをデプロイするための道筋を理解するということです。
これら全ての情報を3つのブログシリーズに分割しています:
- このブログ記事では、Databricksレイクハウスプラットフォームが皆様のデータチームが達成したいことをどのように実現するのかを説明し、Databricksアーキテクチャと一般的なワークフローをブレークダウンし、クラウドエンジニアリングチームの観点におけるアーキテクチャのメリットを説明します。
- 次のブログ記事では、お客様から頻繁に質問を受ける顧客管理VPCの要件についてカバーします。
- 最後のブログ記事では、POCからプロダクションにおいてDatabricksワークスペースを活用しているお客様で目撃される一般的なデプロイメント方法について話します。
注意
Databricksでは、計算資源がDatabricksのAWSアカウント(サーバレスデータプレーン)でホストされるサーバレスSQLデータウェアハウスを提供しています。このシリーズでは、クラウド計算資源が顧客のAWSアカウント(クラシックデータプレーン)でホストされるDatabricksクラシックモデルをカバーします。このブログシリーズではサーバレスデータプレーンはカバーしません。
Databricksレイクハウスプラットフォーム
アーキテクチャとワークフローに踏み込む前に、Databricksレイクハウスプラットフォームについて簡単に説明させてください。
簡単に言えば、Databricksは皆様のモダンデータスタックをシンプルにする統合アプローチを実現するために、データレイクとデータウェアハウスのベストな要素を組み合わせます。
ビジネスインテリジェンスのユースケースやモデルを公開するための機械学習プラットフォームを実現するために、非構造化データやプロプライエタリなクラウドデータウェアハウスを処理するために、皆様のデータチームがオープンソースのApache Spark(™)ソリューションをメンテナンスするのではなく、彼らはDatabricksレイクハウスプラットフォームで3つのペルソナすべてを統合することができます。
Databricksを用いることで、企業のデータ処理、分析、ストレージ、ガバナンス、サービングをシンプルにしつつも、皆様のデータエンジニア、データアナリスト、データサイエンティストはともにコラボレーションできるようになります。
クラウドエンジニアに意味すること: このように単一のソリューションにデータペルソナを統合することで、データチームが権限、ネットワーク設定、セキュリティを管理する製品の数を削減することができます。別々のセキュリティグループ、IAM(identity and access management)権限、モニタリングを必要とする複数のツールではなく、単一のプラットフォームに限定することができます。
Databricksレイクハウスプラットフォームとその使い方を簡単にカバーしたので、Databricksのアーキテクチャとサンプルデータエンジニアリングワークフローを詳しく見ていきましょう。
レイクハウスの詳細について興味があるのであれば、アーキテクチャパターンをより詳細に説明しているこちらの記事を見てみてください。
注意
このブログシリーズにおいて、Databricksの文脈でクラスターやSQLデータウェアハウスに言及する際、お使いのAWSアカウントのプライベートサブネットに存在するDatabricksのAmazon Machine Image (AMI)がアタッチされたAmazon Elastic Compute Cloud (EC2)を参照していると思っていただいて構いません。
クラウドエンジニア向けDatabricksアーキテクチャ
Databricksアーキテクチャは2つの主要なコンポーネントに分割されます: コントロールプレーンとデータプレーンです。この構成の目的は、Databricksによって管理される膨大なバックエンドサービスを維持しつつも、セキュアな部門横断チームのコラボレーションを実現するというものであり、皆様のデータチームがデータサイエンス、分析、エンジニアリングにフォーカスできるようになります。
- コントロールプレーンは、DatabricksのAWSアカウントでDatabricksが管理するバックエンドサービスから構成されます。これには、格納時に暗号化されるノートブックコマンドと数多くのワークスペース設定が含まれます。
- データプレーンは、ノートブック、ジョブ、皆様のAWSアカウントで起動するクラシックSQLデータウェアハウスのための計算リソースから構成されます。
このアーキテクチャがどのように動作するのかの現実世界の例を皆様のデータチームに提供するために、Databricksにサインインして、Amazon Kinesisから到着する生データを変換し、Amazon Simple Storage Service (S3)に永続化するノートブックにコードを記述するデータエンジニアがいるものとしましょう。
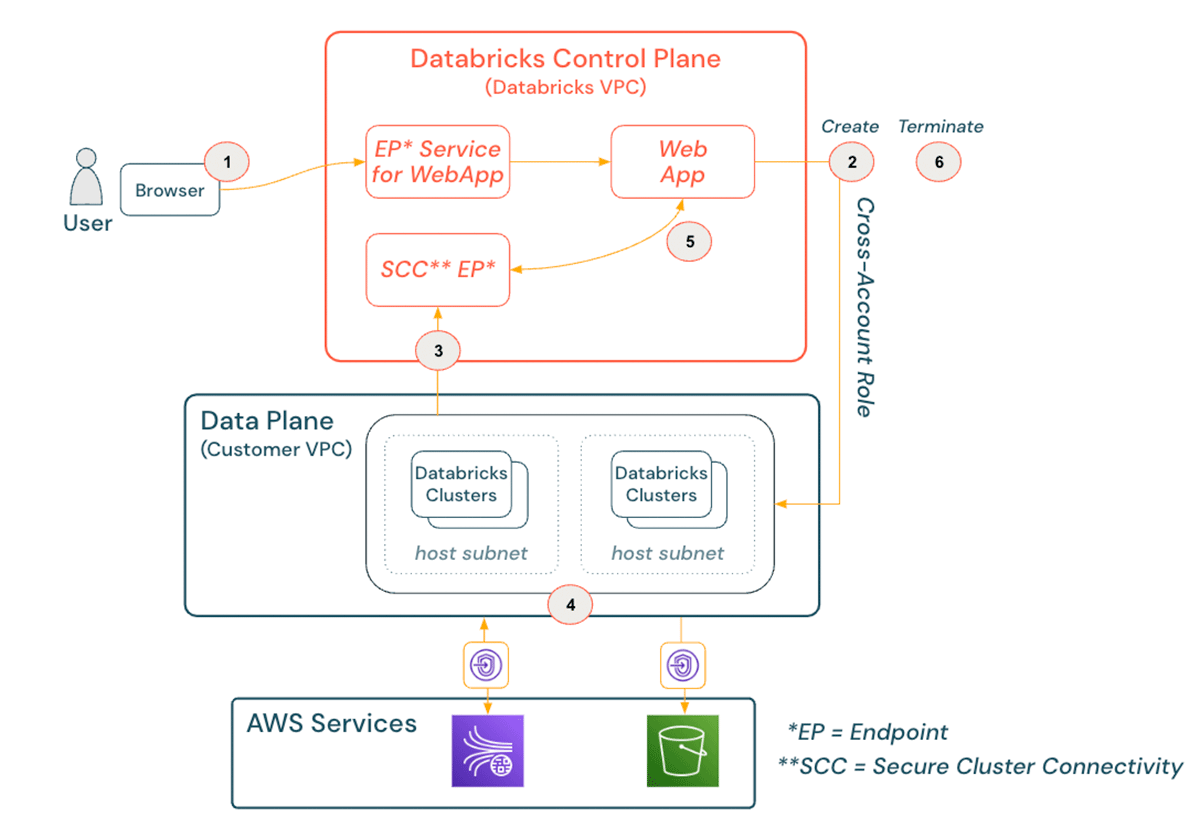
Databricksにおけるデータエンジニアリングワークフローのサンプル
クラウドエンジニアリングの観点からこのデータエンジニアリングワークフローがどのように見えるのかを以下に示します:
- DatabricksのAWSアカウントでホストされるコントロールプレーンのウェブUIで、必要であればシングルサインオン経由でデータエンジニアの認証を行います。追加のオプションとして、フロントエンドのPrivateLink接続やIPアクセスリストを実装することができます。
- データエンジニアはコンピュートタブに移動し、一連の設定(サイズ、オートスケーリング、自動停止など)を指定してクラスターを作成します。バックエンドでは、最新のDatabricks AMIを持つEC2インスタンスが、ワークスペース作成時に割り当てられたクロスアカウントロールを用いて、適切なVPC、サブネット、セキュリティグループで起動されます。
- クラスターがアクティベートされると、セキュアクラスター接続リレーと呼ばれるコントロールプレーン向きの外向き接続が公衆インターネットあるいはAWS PrivateLinkを用いたバックボーンインフラストラクチャ経由で試行されます。
- クラスターとコントロールプレーン間の接続が確立されると、データエンジニアは自由にコードを書き始めることができます。データ変換コードがコントロールプレーンからクラスターにプッシュされ、クラスターがKinesisからデータをプルし、S3に書き込みます。
- ジョブが処理されると、クラスターはコントロールプレーンのクラスターマネージャにステータスやユーザーアウトプット(データのプレビュー、メタデータなど)をレポートするので、データエンジニアはどのようにジョブが実行されているのかを確認することができます。
- ジョブがラップアップすると、データエンジニアはDatabricksのUIで手動でクラスターを停止するか、事前の設定に基づく自動停止を行うことができます。停止リクエストが背後のAWSリソースで受信されると、環境において即座に停止されます。
これはクラウドエンジニア向けの表現ですが、これらのバックエンドプロセスはデータチームにとっては完全に難解なものとなります。ウェブアプリケーションでは、データチームはクラスターを起動し、実行状態になると緑のチェックマークを確認し、この時点から仮説検証のためのコーディングのレースをスタートすることができます。
クラウドエンジニアにとってのDatabricksアーキテクチャのメリット
ここまでで、Databricksアーキテクチャの概要を見てきました。このアーキテクチャが、皆様と皆様のクラウドエンジニアリングチームに提供する3つの主要なメリットを議論させてください。
メリット #1 - ユースケース導入が容易
お使いのAWSアカウントにDatabricksワークスペースがデプロイされたら、次にデータチームが起票するチケットは、「オンプレミスのKafkaインスタンスやデータベースからのデータが必要になりました」や「RDSからデータをクエリーする必要があります」、「このAPIからデータを取得する必要があります」と言ったことであろうと想定できます。
我々のアーキテクチャのメリットは、このようなチケットを受け取った際、2つの観点から問題を検討するだけで良いと言うことです:
- プライベートサブネットにあるクラスターは接続先に到達できるか?
- プライベートサブネットにあるクラスターは接続先に接続する権限を持っているか?
この例をいくつか見ていきましょう:
- 別のAWSアカウントにあるAmazon Relational Database Service (RDS)インスタンスに接続したい場合、これを「自分のクラスターはどのように当該データベースに到達できるのか?」と言う視点から検討します。この時点で、標準的なネットワークアーキテクチャパターンを検討していることになります。VPC間のVPCピアリング、あるいはアカウント間のトランジットゲートウェイを活用することができます。クラスターからのトラフィックのルーティングに使用したいパターンを確立したら、皆様のデータチームがデータベースにクエリーできるようになります。
- 同様のシチュエーションで、データチームがAmazon Redshiftからデータを読み込もうとした際に接続を拒否されると言っている場合には、IAMの権限、あるいはRedshiftインスタンスやDatabricksクラスターのトラフィックをブロックしているセキュリティグループに問題を限定することができます。
ソースがストリーミング、バッチ、非構造化、構造化に関係なく、Databricksはデータチームのためにアクセス、変換、特定場所への永続化を行うことができます。そして、クラウドエンジニアのあなたにとっては、クラスターが接続でき、必要な権限を持っている限り、新たなソースシステムをオンボーディングする際の問題はほとんどありません。
メリット #2 - デプロイメントの柔軟性
ここまでで、Databricksのアーキテクチャを議論し、なぜ新たなユースケースの導入が容易になるのかを話してきました。次に、お使いのAWSアカウントにDatabricksをデプロイする際に活用できる柔軟性について触れさせてください。
標準的なDatabricksワークスペースデプロイメントには2つのパーツが存在します。お使いのアカウントで必要となるAWSリソースと、これらのリソースをDatabricksコントロールプレーンに登録するためのAPI呼び出しです。このオープン性によって、クラウドエンジニアリングチームはどのようにAWSリソースをデプロイし、必要なAPIを呼び出すのかに関して主導権を持つことができます。
- Terraform専門ですか?ワークスペースのデプロイに活用できるHashiCorp Terraformプロバイダーを公開しています。
- AWS CloudFormationが好きですか?皆様の要件に合わせて導入できるオープンソースのCloudFormationテンプレートやすぐに利用できるAWS QuickStartを活用することができます。
- コンソールを使うのが好きですか?顧客管理VPCに必要なAWSリソースをデプロイしたら、REST APIを呼び出すことでワークスペースを作成することができます。
- すべてのネットワークリソースをデプロイするために何もしたくありませんか?Databricks管理のVPCを作成するためにアカウントコンソールのクイックスタートを活用してください。Databricksが必要なすべてのリソースをデプロイし、約10分でワークスペースがデプロイされます。
ネットワークのトポロジーはお客様によって異なることを理解しているので、我々はお客様と様々な方法でDatabricksをデプロイしています。クラウドジャーニーにいる皆様とクラウドエンジニアリングチームの方々にお会いできればと考えています。
より詳細にこれらのデプロイメントオプションを議論するブログシリーズのパート3を楽しみにしていてください。
メリット #3 - 広範囲なクラウド監視の機会
説明したいDatabricksアーキテクチャの最後のメリットは、広範囲なクラウドリソースのモニタリングの能力です。
利用に対するビジネスユニットへの課金、EC2インスタンスからのネットワークトラフィックの追跡、不正なAPI呼び出しの登録などにおいて、お使いのAWSリソースやその周辺で起きていることを監視することは、環境の完全性を維持するために重要なこととなります。
Databricksアーキテクチャは、既存あるいはまもなく実装される追跡方法に正しくフィットします。クラスターのタグ付け、課金データの監視、背後にあるEC2インスタンスから許可あるいは拒絶されたトラフィックを確認するためのVPCフローログの調査、クロスアカウントロールから為されるAPI呼び出しの検証において、我々のプラットフォームはオープンであり、ユーザーによってどのようにデータがアクセス、処理されているのかに関する透明性を確保し続けたいと考えています。
お使いの環境における計算資源の監視や、様々なクラスターの状態監視に興味があるのであれば、DatadogやAmazon Cloudwatchのように一般的に使用される製品でステータスを監視することができます。
次は?
この記事では、クラウドエンジニアのペルソナを念頭に置いて、Databricksレイクハウスプラットフォームの概要を説明しました。ユースケース導入の容易性、デプロイメントの柔軟性、広範囲なクラウドリソース監視の機会のように、皆様のチームに提供するDatabricksアーキテクチャのメリットを議論しました。
次のブログ記事では、クラシックデータプレーンの構成要素にディープダイブします。顧客管理VPCの作成における要件とお客様からよく聞かれる質問をウォークスルーします。
とにかく、この最初の記事がクラウドエンジニアの皆様がDatabricksレイクハウスプラットフォームになれる助けになればと思っています。すぐにパート2をお出ししたいと思っています。それまでは、Databricks無料トライアルを始めておいてください!