Databricksのワークスペース管理者がDatabricksユーザーを招待し、Databricksユーザーが利用を開始するまで(ノートブック上でコマンドを実行するまで)の手順をまとめています。
Databricksクイックスタートガイドのコンテンツです。

ワークスペース管理者の作業
招待したユーザーがすぐに作業を開始できるように、ワークスペース管理者が準備を行います。
機能の有効化・無効化
サイドメニューから設定 > 管理コンソールにアクセスし、Workspace settingsタブを開きます。
DBFSブラウザを有効にするなどワークスペースの機能のオンオフを行います。

お勧め設定
- REST APIを呼び出す際に使用するパーソナルアクセストークンを利用させない。
- Access Controlの下にあるPersonal Access Tokensをオフにします。
- ワークスペースのサイドメニューからDBFS(Databricks File System)をブラウジングできるようにしたい。
- AdvancedのDBFS File Browserをオンにします。
- ノートブックのコマンドの実行結果のダウンロードを許可しない。
- AdvancedのDownload button for notebook resultsをオフにします。
- GUIを用いたローカルからのファイルのアップロードを許可しない。
- AdvancedのUpload data using the UIをオフにします。
- ノートブックのエクスポートを許可しない。
- AdvancedのNotebook Exportingをオフにします。
クラスターの作成
デフォルトの設定では、Databricksユーザーは計算処理を行うDatabricksクラスターを作成することができません。
ここでは、ワークスペースにアクセスできる全ユーザーが利用できる(起動・ノートブックのアタッチ)クラスターを準備します。
-
サイドメニューからクラスターにアクセスし、クラスターの作成ボタンをクリックします。
-
以下の設定でクラスターを作成します。
- クラスター名: 共用クラスター
- クラスターモード: ハイコンカレンシー(同時接続性の高いクラスターです)
- Databricksランタイムのバージョン: Runtime 10.5 ML
- オートスケールの有効化: オン
- 非アクティブ状態が120分継続した後に終了(アイドル状態が120分続いたら自動でクラスターが停止します)
-
ワーカータイプ: i3.2xlarge
- ワーカーの最小数: 2
- ワーカーの最大数: 8

クラスターのアクセス権の設定
-
画面右上のその他をクリックし権限を選択します。

-
アクセス権を設定します。

-
NAMEからグループの下にあるすべてのユーザーを選択します。

-
PERMISSIONから再起動が可能を選択します。

-
+追加をクリックします。

-
Saveをクリックします。
注意
- 同時に利用するユーザー数など性能要件に応じてクラスターのスペックを変更してください。
- セキュリティポリシーに応じてクラスターのアクセス権を変更してください。アクセス権とユーザーができることの関係は以下の通りとなります。詳細は原文を参照ください。
| できること | アクセス権なし | アタッチ可 | 再起動が可能 | 管理可能 |
|---|---|---|---|---|
| ノートブックをクラスターにアタッチ | x | x | x | |
| Spark UIの参照 | x | x | x | |
| クラスターメトリクスの参照 | x | x | x | |
| ドライバーログの参照 | x | x | x | |
| クラスターの停止 | x | x | ||
| クラスターの起動 | x | x | ||
| クラスターの再起動 | x | x | ||
| クラスターの編集 | x | |||
| ライブラリをクラスターにアタッチ | x | |||
| クラスターのリサイズ | x | |||
| アクセス権の変更 | x |
お勧め設定
複数のユーザーで1台のクラスターを共有する
メリット: 管理するクラスターの台数を限定できるので管理が楽です。
デメリット:
- 1台のクラスターを複数人で使用するので、リソースの取り合いが起こる可能性があります。
- GPUクラスターを使用したいなど、特定のユースケースに柔軟に対応することができません。
設定内容: 上述の設定を参考にしてください。
複数のユーザーで1台のクラスターを共有する(管理者がクラスターの起動・停止を行う)
上の設定よりもユーザーの自由度は減り、クラスターの起動・停止はできなくなります。
メリット: ユーザーは稼働中のクラスターにノートブックをアタッチするだけでいいので操作が楽です。
デメリット: 管理者がクラスターの手動起動・停止を行う必要があります。
設定内容:
上のアクセス権の設定で付与する権限をアタッチ可に変更します。
各ユーザーが許可された裁量でクラスターを管理する
メリット: ユーザーが一定の自由度の下でクラスターを作成、利用することができます。
デメリット:
- クラスターが乱立することになり多くのクラスターを管理しなくてはなりません。
- クラスターポリシーを活用しないと野放図にクラスターが作成されることになります。
- コストのコントロールが効きづらくなります。
設定方法
管理者がクラスターポリシーを作成し、ユーザーにクラスターポリシーのアクセス権限を与えます。
-
ワークスペース管理者は、サイドメニューのクラスターにアクセスし、クラスターポリシータブをクリックします。
-
クラスターポリシーを作成ボタンをクリックします。

-
クラスターポリシーの名前とポリシーのルール(JSON)を指定します。ここでは、名前を
一般的なクラスターポリシーとし、定義タブに貼り付けるポリシーのルールは以下のようにします。このルールでは以下のルールを規定しています。
- ハイコンカレンシークラスター
- プールの使用不可
- Databricksランタイムは10.x系のみ
- 指定できるインスタンスタイプは`i3.xlarge,i3.2xlarge,i3.4xlarge"のみ
- ワーカーノードの最小数は1
- ワーカーノードの最大数は10
- ディスクのオートスケールを有効化
- 自動停止するアイドル時間は30分
- カスタムタグとして
teamにproductを指定
JSON{ "spark_conf.spark.databricks.cluster.profile": { "type": "fixed", "value": "serverless", "hidden": true }, "instance_pool_id": { "type": "forbidden", "hidden": true }, "spark_version": { "type": "regex", "pattern": "10\\.[0-9]+\\.x-scala.*" }, "node_type_id": { "type": "allowlist", "values": [ "i3.xlarge", "i3.2xlarge", "i3.4xlarge" ], "defaultValue": "i3.xlarge" }, "driver_node_type_id": { "type": "fixed", "value": "i3.xlarge", "hidden": true }, "autoscale.min_workers": { "type": "fixed", "value": 1, "hidden": true }, "autoscale.max_workers": { "type": "range", "maxValue": 10, "defaultValue": 2 }, "enable_elastic_disk": { "type": "fixed", "value": true, "hidden": true }, "autotermination_minutes": { "type": "fixed", "value": 30, "hidden": true }, "custom_tags.team": { "type": "fixed", "value": "product" } }
-
権限タブをクリックします。
-
NAMEにはすべてのユーザー、PERMISSIONには使用可能を選択し、+追加をクリックします。

これでクラスターポリシーが作成されました。
ユーザーは権限が与えられているクラスターポリシーを指定してクラスターを作成します。
注意
ユーザーは使用可能権限が与えられているクラスターポリシーを使用してしかクラスターを作成することはできません。
- サイドメニューからクラスターを選択し、クラスターの作成をクリックします。
- 使用できるクラスターポリシーが複数ある場合には、クラスターポリシーから使用するポリシーを選択できますが、1つしかない場合にはクラスターポリシーは固定されます。

- 変更が許可されている設定を必要に応じて変更して、クラスターを作成ボタンをクリックします。
- これでクラスターが作成されます。
クラスターポリシーの詳細に関しては、Databricksクラスターポリシーの管理をご覧ください。
ユーザーの招待
- サイドメニューの設定 > 管理コンソールを選択します。
- Usersタブが選択されていることを確認します。
-
+ ユーザーを追加ボタンをクリックします。
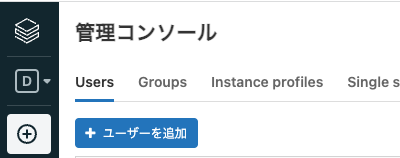
-
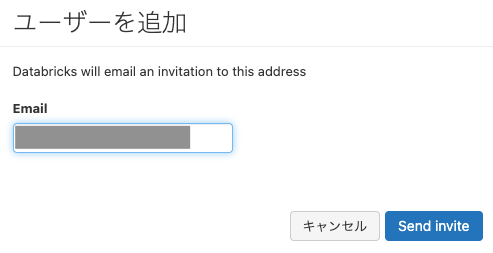
Emailに招待したいユーザーのメールアドレスを入力し、Send inviteをクリックします。
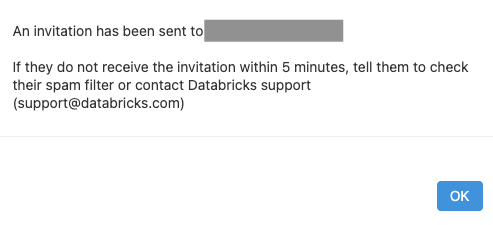
- 招待メールが送信された旨のメッセージが表示されるのでOKをクリックします。他のユーザーを招待するにはステップ4からの操作を繰り返します。
ユーザーの作業
招待メールの受信およびワークスペースへのログイン
注意
上の操作から5分以内に確認メールが届かない場合には、迷惑メールに分類されていないか確認してください。
- Databricksからの確認メール(メールタイトル: 管理者の名前 has invited you to collaborate using Databricks)を開きます。招待者の名前とメールアドレスを確認の上、メールに記載されているURLをクリックします。

- Databricksワークスペースに遷移します。ここで、First and last nameに自分の名前、PasswordとConfirm passwordにパスワードを入力し、Sign Upボタンをクリックします。
注意
パスワードは最低8文字を指定してください。
これで、Databricksワークスペースにログインできました!
注意
このタイミングでワークスペースをブックマークしておくことをお勧めします。URLはワークスペース固有なので、他のワークスペースと混同しないように、ブックマークにわかりやすい名前をつけておくことをお勧めします。
画面操作に慣れる
- まずは言語を日本語に切り替えましょう。こちらの手順に従って、画面の言語を日本語に切り替えてください。
- ワークスペースの画面は以下のような構成となっています。画面左側のサイドメニューから主要機能にアクセスします。

- サイドメニューにマウスカーソルを移動するとメニューが展開します。なお、この挙動は一番下のメニューオプションから変更することができます。

- 以下のメニュー項目となっていますので、それぞれにアクセスしてみてください。
-
Data Science & Engineering こちらはペルソナスイッチャーと呼ばれるものです。作業内容がデータサイエンス&データエンジニアリングであればD、機械学習(Machine Learning)に関するものであればM、SQL分析であればSを選択することで、メニューや画面がそのペルソナに適したものに変更されます。

-
作成 ノートブック、テーブル、クラスターなどをクイックに作成することができます。
-
ワークスペース ワークスペース上のフォルダー、ノートブックを一覧、アクセスすることができます。ワークスペースにはユーザーごとのホームフォルダが作成され、このフォルダの中にノートブックやフォルダを作成することになります。

-
リポジトリ Git連携機能であるDatabricks Reposにアクセスします。
-
最近利用したアイテム 最近アクセスしたノートブックが一覧表示されます。
-
検索 ワークスペースを検索できます。
-
データ ワークスペースのデータベースにアクセスします。
-
クラスター Databricksクラスターの一覧画面に移動します。
-
ワークフロー ノートブックの処理を定期実行することができます。
-
ノートブックを作成する
Databricksではノートブックにコードを記述し、ノートブックを稼働中のクラスターにアタッチしたあとでコードを実行します。なので、まず初めにノートブックを作成します。
- 上のサイドメニューから作成 > ノートブックを選択します。
- 作成するノートブックの名前を指定し、デフォルト言語はPython、クラスターは上のステップで管理者が作成したクラスターを選択します。これでノートブックの作成とともにノートブックがクラスターにアタッチされます。
-
作成をクリックします。

- ノートブックが表示されます。左上でクラスターが選択されていることを確認してください。

Pythonコードを実行する
-
最初から表示されているセルにPythonコードを入力します。
Pythonprint("test")
-
セルのコマンドを実行します。セル右上に表示されている▶︎をクリックし、セルを実行をクリックします。

-
Pythonが実行されました!

注意
アイドル状態が120分継続すると自動でクラスターは停止する設定になっていますが、クラスターを使用しない場合には手動でクラスターを停止してください。