Databricksクイックスタートガイドのコンテンツです。
自分で振り返ってみても、Databricksを学び始めた頃「ローカルマシンからデータをDatabricksにアップロードして、読み込む時ってどうするんだっけ?」となっていたので、手順をまとめました。
こちらでは、以下のデータをローカルにダウンロードし、Databricksにアップロードする流れを説明します。
国勢調査 時系列データ CSV形式による主要時系列データ | ファイル | 統計データを探す | 政府統計の総合窓口
データのダウンロード
以下のリンクをクリックすると、CSVファイルc01.csvがローカルマシンにダウンロードされます。こちらのデータは都道府県別の年ごとの人口推移となっています。
Databricksにおけるデータの格納場所
Databricksをデプロイする際にS3の設定を行なっており、Databricksで使用するデータはこちらのS3バケットに格納されます。DatabricksからS3のデータにアクセスする際には、Databricksファイルシステム(DBFS) 経由でアクセスすることになります。DBFSを利用することで、S3のURLなどを意識することなしに、フォルダー、ファイルの概念でファイルを操作することができます。

DBFSのアクセス権に関する重要な情報
DBFSルートを除き、DBFSにマウントされたオブジェクトストレージのオブジェクトに対してすべてのユーザーが読み書きのアクセス権を持ちます。
しかし、インスタンスプロファイルを用いてマウントが作成されている場合、IAMロールが許可するユーザーのみがアクセス権を持ち、当該インスタンスプロファイルを使用するように設定されたクラスターのみがアクセスすることができます。このため、インスタンスプロファイルを用いて作成されたマウントにはDBFS CLIでアクセスすることはできません。
インスタンスプロファイルを用いたS3バケットのマウントに関しては、DBFSを通じたS3バケットへのアクセスをご覧ください。
参考資料
データのアップロード
手元のマシンにある小規模なデータをDatabricksで分析したい場合には、UIを用いてDBFSにデータをインポートすることができます。
注意
以下の手順2でDBFSが表示されない場合、以下の手順でDBFSブラウザーを有効化してください。
- 管理者ユーザーでDatabricksにログインし、サイドメニューの設定 > 管理コンソール(Admin console) を選択します。
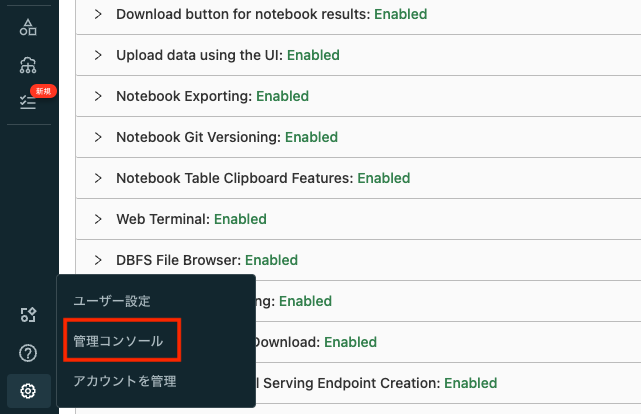
-
Workspace settingsタブを開きます。
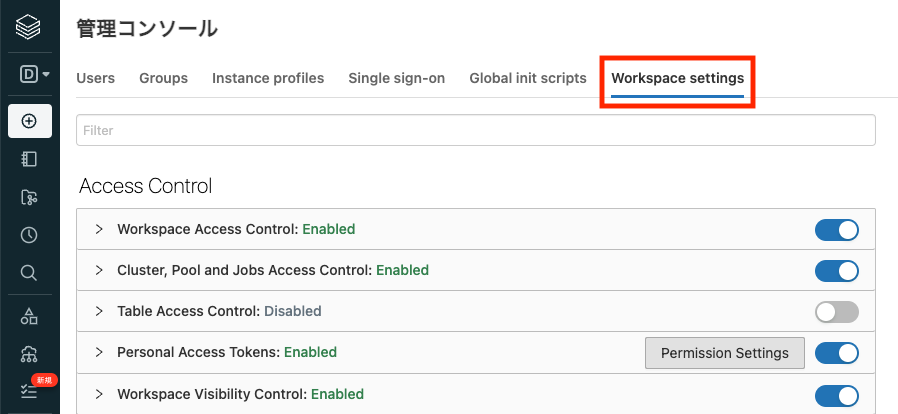
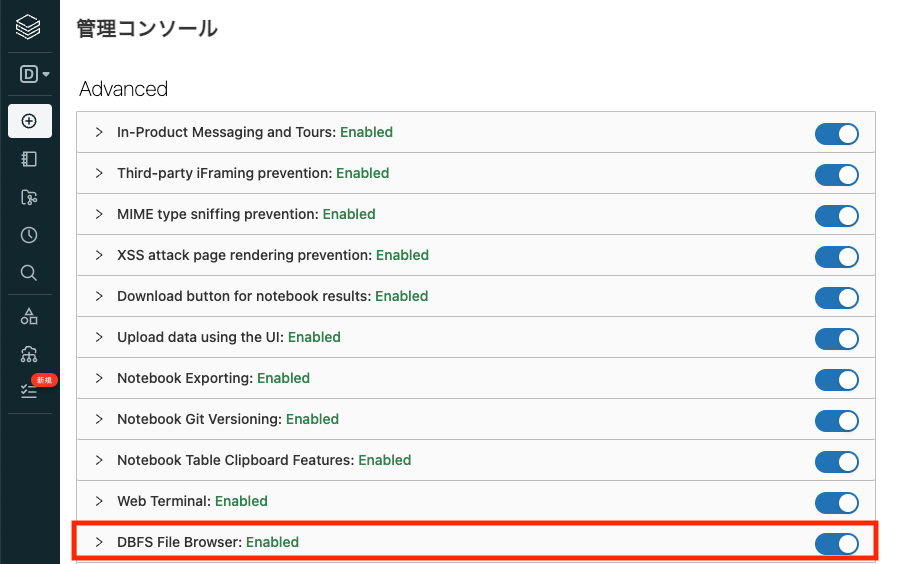
- AdvancedセクションにあるDBFS File Browserの右のスイッチを切り替えてEnabledになることを確認します。
- 画面左の
をクリックします。
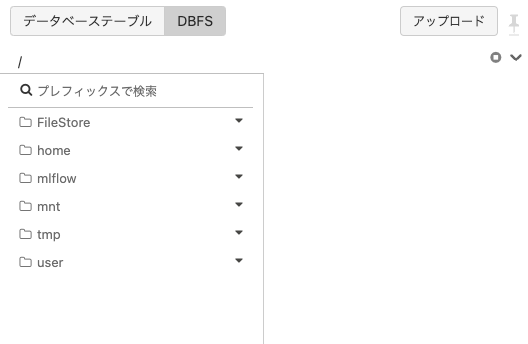
- 画面上部のDBFSをクリックし、DBFSのブラウザーに切り替えます。
- 画面上に表示されるアップロードボタンをクリックします。
- アップロード用のダイアログが表示されます。アップロード先のパスを指定して、ファイルをドラッグアンドドロップする流れとなります。
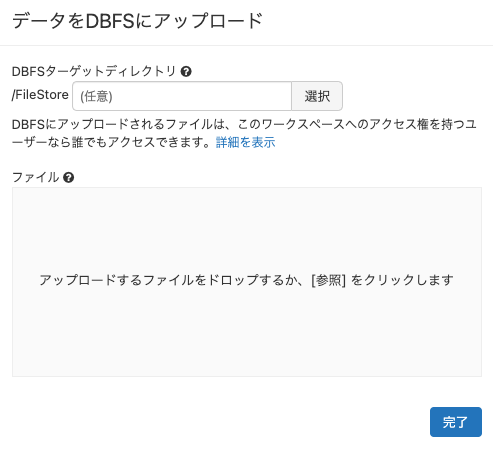
- 選択ボタンをクリックすると、フォルダーブラウザが開くのでアップロードしたいフォルダーを選択します。あるいはパスを入力します。
-
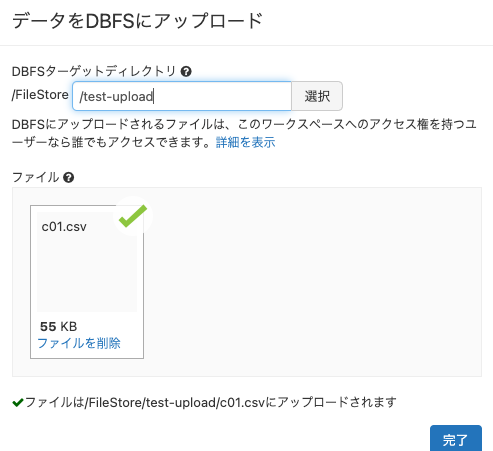
ファイルのボックスに、データのダウンロードでダウンロードしたCSVファイルをドラッグアンドドロップします。あるいは、ボックスをクリックしてファイル選択ダイアログを開いてファイルを選択します。
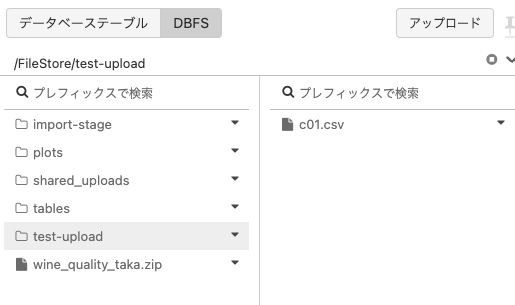
- DBFSブラウザを参照して、ファイルがアップロードされたことを確認します。
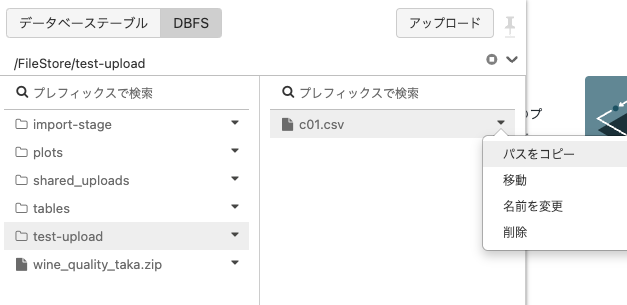
- ファイル名の右にある▼をクリックするとメニューが表示されるので、パスをコピーをクリックします。
- ファイルのパスが表示されます。ここでは、Spark API形式の方のコピーをクリックして、パスをコピーしておきます。ここでは二つの形式の違いは説明しませんが、興味のある方はこちらを参照してください。

ティップス
ノートブックのメニューからもデータをアップロードすることができます。
- ノートブックを開き、上部のメニューからファイル > データをアップロードを選択します
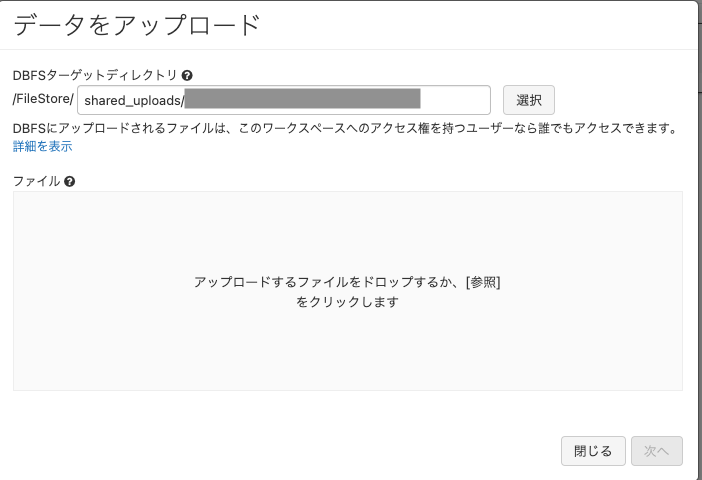
- ダイアログが表示されるので、アップロード先とファイルを選択します。
参考資料
データの読み込み
上のステップを経て、データをDatabricksにアップロードしたので、Databricksノートブックで読み込みます。アップロードしたファイルの文字コードがshift-jisなの文字レコードセットを指定しています。
注意
以下のfile_pathの値を上のステップでコピーしたパスで置き換えてください。
file_path = "dbfs:/FileStore/shared_uploads/takaaki.yayoi@databricks.com/c01.csv"
df = spark.read.option("header", True).option('charset', 'shift-jis').csv(file_path)
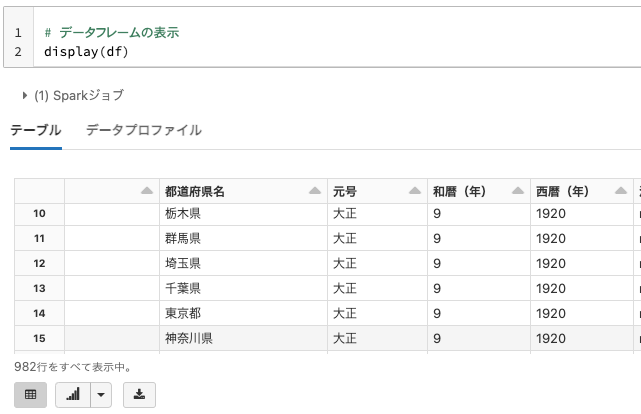
# データフレームの表示
display(df)
これでデータを読み込めましたので、いろいろな分析にトライしてみてください!