データ管理という概念自体広範なものですが、これまでに書いた資料などをこちらにまとめます。個人的体験を踏まえて以下の観点で整理します。

データエンジニアリングの基礎の図をベースに筆者がDatabricksの観点で加筆、修正
- データモデリング(どのようなデータを取り扱うのか): 取り扱うデータを整理して理解しやすくします。具体的には、どんな情報があって、それぞれがどのように関係しているのかを図や表にして表現できるようにします。
- データエンジニアリング(どのようにデータを処理するのか): データアナリストやデータサイエンティストなどのデータの消費者がデータを活用できるように生のデータを加工します。加工を粉ぷデータパイプラインの開発、運用を行います。
- データガバナンス(どのようにデータを管理するのか): 取り扱うデータを資産と捉え、その資産のライフサイクルを通じて管理できるようにするための原則、プラクティス、実践です。
データのモデリング
DatabricksでスタースキーマやData Vaultなどのデータモデルを実装することができます。目の前にあるデータがどのような特性を持っており、どのように組み合わせることで目的とする情報を得るのかをデザインします。ER図を使うことが多いと思いますが、Databricksでは定義したテーブルから簡単にER図を表示することができます。
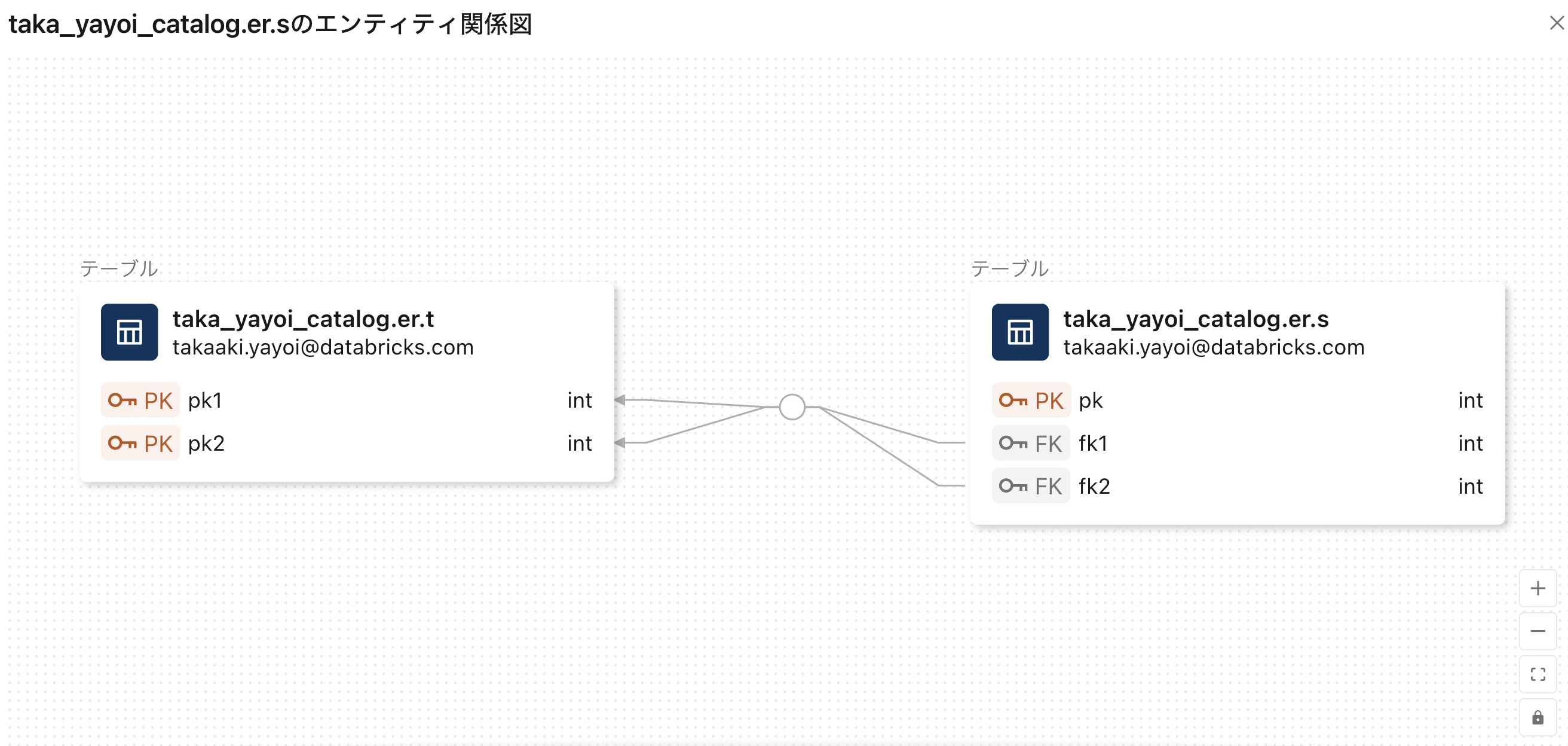
- データ モデリング - Azure Databricks | Microsoft Learn
- スタースキーマを理解する | Databricks
- データボルト | Databricks
- Databricks レイクハウスプラットフォームでのデータウェアハウスのモデリングと実装 | Databricks Blog
- Delta Lakeを用いてDatabricksでスタースキーマを実装する5つのシンプルなステップ
- DatabricksレイクハウスプラットフォームにおけるData Vault実装の規範的ガイド
- DatabricksレイクハウスにおけるData Vaultのベストプラクティスと実装
- モダンレイクハウスにおけるディメンションモデリングのベストプラクティスと実装
- DatabricksのカタログエクスプローラでER図がサポートされます
以下の図は、Databricks提供機能においてデータモデリングと関係の深い箇所を赤枠で示したものとなります。

データエンジニアリング
データモデリングが一段楽したら、そのデータモデルに基づいてテーブルを作成することになります。そして、テーブルは静的なものもあれば、日々データが投入されるものもあります。データの消費者が常に高品質で新鮮なデータを利用できるようにする営みがデータエンジニアリングです。データエンジニアは分析要件などに基づいて適切にデータが処理されるようにデータパイプラインを構築、運用することに責任を持ちます。データエンジニアリングに対する考え方についてはこちらの書籍が勉強になりました。
Databricksではデータエンジニアリングを効率的、効果的に行うための機能が多数提供されています。最初から全てを使いこなそうとはせずに、ステップバイステップで理解を深めていくことをお勧めします。
データエンジニアリングにフォーカスしたワークショップのスライドです。ステップバイステップ(データエンジニアリングの基礎→ジョブによるオーケストレーション→Delta Live Tables)で学習を進めるように設計しています。
関連資料です。
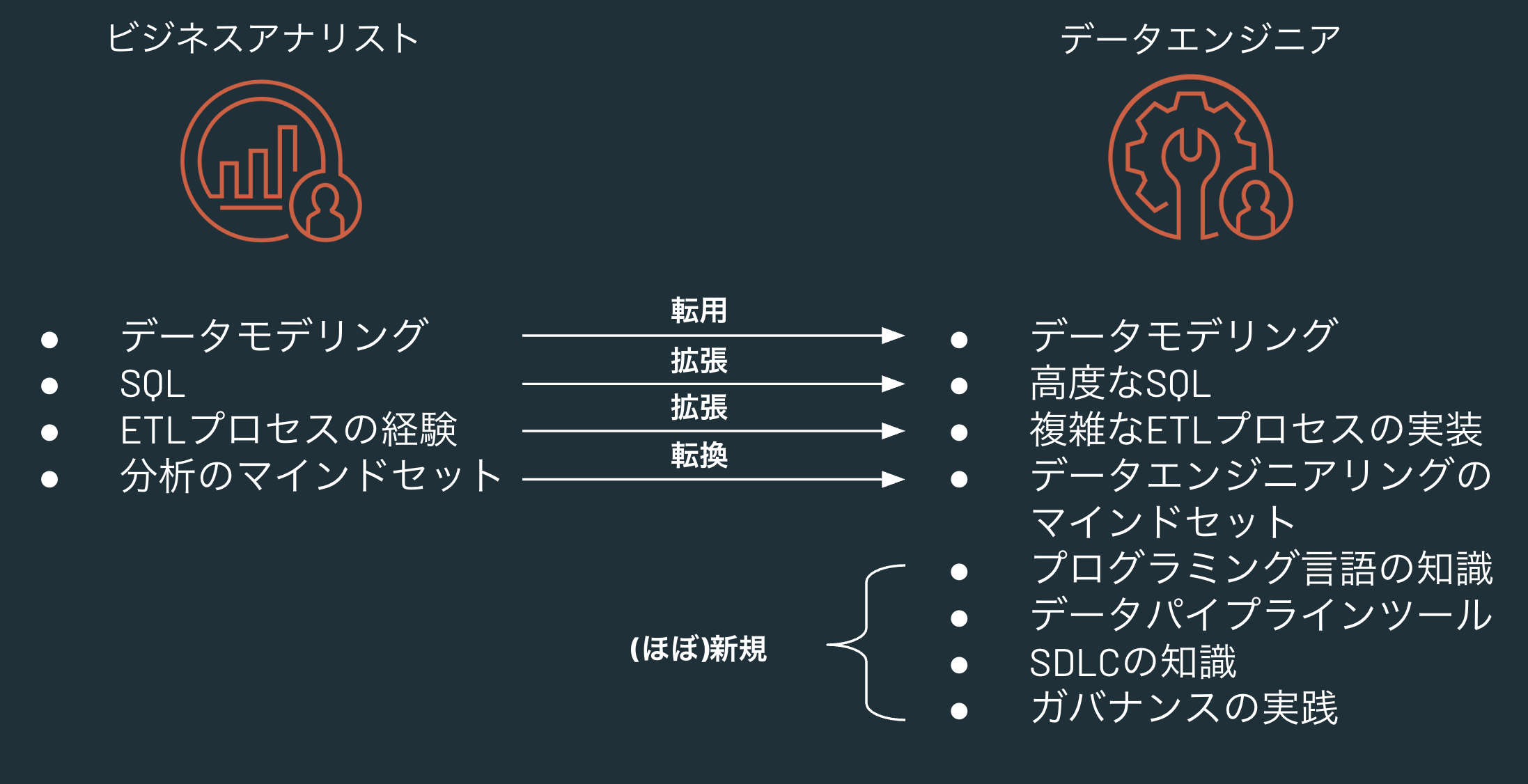
- Databricksにおけるビジネスアナリストからデータエンジニアへの転換
- ETLのT(Transformation)実践
- ETLのE(Extract)実践
- Databricksにおけるデータパイプラインとオーケストレーション
Databricksのデータエンジニアリング機能は主にDatabricksワークフロー(まもなくLakeFlowという名称に変更されます)として提供されています。ワークフロー、ジョブ、Delta Live Tablesの関係性をこちらにまとめています。
機能面を深掘りしていくと、上述のワークフローに加えて、SparkやDelta Lake、Unity Catalogにも習熟していくことになります。いきなり全てをカバーしようとするのではなく、データエンジニアリングの実践を進めていく中で必要に応じて理解を深めていくことをお勧めします。ただ、Unity Catalogに関しては、次のデータガバナンスで非常に重要な役割を担うので、早い段階でそれなりに深い理解を求められるようになります。
また、Sparkに関しては、(私を含む)Databricks Japanのエンジニアによって翻訳された書籍があります。
以下の図は、Databricks提供機能においてデータエンジニアリングと関係の深い箇所を赤枠で示したものとなります。上のスライドでも触れていますが、Databricksの非常に大きな部分をデータエンジニアリングの機能(データエンジニアリング以外でも活用できるものもありますが)が占めていることがわかります。

そして、上述のデータモデリングはデータエンジニアリングにおいても必要となるすkです。こちらで言及しているように、BIに取り組んでいるビジネスアナリストの方がデータエンジニアにロール変更をする際には、データモデリングのスキルをそのまま転用することができます。
データのガバナンス
データパイプラインによってデータが流れるようになっためでたしめでたし、ではありません。今の時代、データの価値や重要性は高まる一方であり、それにともなってデータ漏えいなどによるリスクも高まっています。企業として、データが適切管理、運用されていることを確実にするために重要なのがデータガバナンスです。最近ではAIガバナンス(取り扱うAIモデルが適切に管理されているかどうか)という話も出てきていますが本書では割愛します。
Databricksでデータ(とAIの)ガバナンスのための機能を提供しているのがUnity Catalogです。名前の通り、カタログソリューションですがデータベースやテーブルに対するカタログだけではなく、ファイルやAIモデルなどに対するカタログとしても機能します。
Unity Catalogの概要を説明しているスライドです。
こちらはIT管理にフォーカスしたスライドです。
関連資料です。
- データガバナンスの包括ガイド | Databricks
- データガバナンス | Databricks
- Unity Catalog でデータ ガバナンスを使用する - Azure Databricks | Microsoft Learn
- Unity Catalogに関するQiita記事
ガバナンスにおいては、どのような目的(避けるべきリスク、達成すべきSLAなど)でガバナンスを適用するのか、そのためのメトリクスは何か、メトリクスをどのようにモニタリングするのかなど様々な観点での検討が必要となります。DatabricksのUnity Catalogではそれらを支援、促進するために、以下のような機能が提供されています。
個人的には、カタログエクスプローラのUIに慣れ親しみつつ、Unity Catalogの基本コンセプトを理解し、ユースケースに応じて各種機能の習熟を進めることをお勧めします。
以下の図は、Databricks提供機能においてデータガバナンスと関係の深い箇所を赤枠で示したものとなります。いずれにしてもUnity Catalogが中心的役割を担います。
