こちらを書いてから、「やっぱりExtract(抽出)も重要だなー」と思った次第です。
オプションの指定が必要なので、設定がしやすいPySparkで処理します。以下のようなケースをカバーします。
- データベースの抽出
- 単一CSVファイルの抽出
- 複数CSVファイルの抽出
- Parquetファイルの抽出
- JSONファイルの抽出
- 画像ファイルの抽出
抽出結果はすべてSparkデータフレームになるので、データフレームに変換処理(T)を適用したり、ターゲットデータベースにロード(L)することもできます。
抽出処理の実践
データの準備
ちょうど、Databricksにはサンプルデータがあるのでこれらに対してExtract処理を実行してみます。
抽出戦略の立案
兎にも角にもソースデータの場所とフォーマットを確認することからです。
- データの所在の確認: ストレージ上のファイルかデータベースかメッセージか
- データフォーマットの確認: ファイルの場合は中身を確認します。それ以外の場合には仕様を確認しましょう
- (ファイルの場合)ファイル個数の確認: ファイルは一つか複数か
データベースの抽出
前回作成したブロンズテーブルから抽出するものとします。spark.tableを用いることで、データがSparkデータフレームとして読み込まれます。
df = spark.table("takaakiyayoi_catalog.etl_in_action.bronze")
display(df)
単一CSVファイルの抽出
ファイルを確認します。マジックコマンド%fsを用いることで、DBFSに対するコマンドを実行することができます。このケースではheadが適しています。
%fs
head /databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv
ヘッダーありのCSVであることがわかります。
[Truncated to first 65536 bytes]
"","carat","cut","color","clarity","depth","table","price","x","y","z"
"1",0.23,"Ideal","E","SI2",61.5,55,326,3.95,3.98,2.43
"2",0.21,"Premium","E","SI1",59.8,61,326,3.89,3.84,2.31
"3",0.23,"Good","E","VS1",56.9,65,327,4.05,4.07,2.31
"4",0.29,"Premium","I","VS2",62.4,58,334,4.2,4.23,2.63
"5",0.31,"Good","J","SI2",63.3,58,335,4.34,4.35,2.75
"6",0.24,"Very Good","J","VVS2",62.8,57,336,3.94,3.96,2.48
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(df)
単一ファイルなのでpandasでも読み込めます。
import pandas as pd
pdf = pd.read_csv("/dbfs/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(pdf)
複数CSVファイルの抽出
Sparkの場合、同じディレクトリに格納されているスキーマが同一のファイルは、ディレクトリ指定で一括で読み込むことができます。なお、pandasの場合にはリストやループなどで実装しないといけないですし、そもそもメモリに乗り切らなくてエラーになる可能性が高まります。
df = spark.read.option("header", False).csv("dbfs:/databricks-datasets/airlines/")
display(df)
おや、ヘッダーが無いようです。もう少し調査してみます。
%fs
ls dbfs:/databricks-datasets/airlines/

README.mdを確認します。
%fs
head dbfs:/databricks-datasets/airlines/README.md
有用なことは書いてありません。
================================================
Airline On-Time Statistics and Delay Causes
================================================
## Background
The U.S. Department of Transportation's (DOT) Bureau of Transportation Statistics (BTS) tracks the on-time performance of domestic flights operated by large air carriers. Summary information on the number of on-time, delayed, canceled and diverted flights appears in DOT's monthly Air Travel Consumer Report, published about 30 days after the month's end, as well as in summary tables posted on this website. BTS began collecting details on the causes of flight delays in June 2003. Summary statistics and raw data are made available to the public at the time the Air Travel Consumer Report is released.
FAQ Information is available at http://www.rita.dot.gov/bts/help_with_data/aviation/index.html
## Data Source
http://www.transtats.bts.gov/OT_Delay/OT_DelayCause1.asp
最初のデータファイルを確認します。
%fs
head dbfs:/databricks-datasets/airlines/part-00000
[Truncated to first 65536 bytes]
Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,CRSArrTime,UniqueCarrier,FlightNum,TailNum,ActualElapsedTime,CRSElapsedTime,AirTime,ArrDelay,DepDelay,Origin,Dest,Distance,TaxiIn,TaxiOut,Cancelled,CancellationCode,Diverted,CarrierDelay,WeatherDelay,NASDelay,SecurityDelay,LateAircraftDelay,IsArrDelayed,IsDepDelayed
1987,10,14,3,741,730,912,849,PS,1451,NA,91,79,NA,23,11,SAN,SFO,447,NA,NA,0,NA,0,NA,NA,NA,NA,NA,YES,YES
1987,10,15,4,729,730,903,849,PS,1451,NA,94,79,NA,14,-1,SAN,SFO,447,NA,NA,0,NA,0,NA,NA,NA,NA,NA,YES,NO
1987,10,17,6,741,730,918,849,PS,1451,NA,97,79,NA,29,11,SAN,SFO,447,NA,NA,0,NA,0,NA,NA,NA,NA,NA,YES,YES
1987,10,18,7,729,730,847,849,PS,1451,NA,78,79,NA,-2,-1,SAN,SFO,447,NA,NA,0,NA,0,NA,NA,NA,NA,NA,NO,NO
このファイルにはヘッダーがあります。つまり、最初のデータファイルのみにヘッダーがあるということです。やり方はいくつかありますが、最初のデータファイルはヘッダーありで読み込み、残りのデータファイルはヘッダーなしで読み込んで明示的にヘッダーを付与し、これらを結合することにします。
ヘッダーありファイルの抽出
df_first = spark.read.option("header", True).csv("dbfs:/databricks-datasets/airlines/part-00000")
display(df_first)
ヘッダー情報を取得しておきます。
df_schema = df_first.schema
df_schema
StructType([StructField('Year', StringType(), True), StructField('Month', StringType(), True), StructField('DayofMonth', StringType(), True), StructField('DayOfWeek', StringType(), True), StructField('DepTime', StringType(), True), StructField('CRSDepTime', StringType(), True), StructField('ArrTime', StringType(), True), StructField('CRSArrTime', StringType(), True), StructField('UniqueCarrier', StringType(), True), StructField('FlightNum', StringType(), True), StructField('TailNum', StringType(), True), StructField('ActualElapsedTime', StringType(), True), StructField('CRSElapsedTime', StringType(), True), StructField('AirTime', StringType(), True), StructField('ArrDelay', StringType(), True), StructField('DepDelay', StringType(), True), StructField('Origin', StringType(), True), StructField('Dest', StringType(), True), StructField('Distance', StringType(), True), StructField('TaxiIn', StringType(), True), StructField('TaxiOut', StringType(), True), StructField('Cancelled', StringType(), True), StructField('CancellationCode', StringType(), True), StructField('Diverted', StringType(), True), StructField('CarrierDelay', StringType(), True), StructField('WeatherDelay', StringType(), True), StructField('NASDelay', StringType(), True), StructField('SecurityDelay', StringType(), True), StructField('LateAircraftDelay', StringType(), True), StructField('IsArrDelayed', StringType(), True), StructField('IsDepDelayed', StringType(), True)])
ヘッダーのないファイルの抽出
ヘッダーのないファイルのみを対象にしたいので、オプションpathGlobFilterを使用します。こちらを参考にさせていただきました。ただ、正規表現に自信がなかったので確認のためのロジックを組み込んでいます。input_file_nameは入力ファイルのパスを取得できるので、これを追加カラムとして組み込んでいます。自信がある場合には確認はスキップしてください(でも、確認することをお勧めします)。
from pyspark.sql.functions import input_file_name
df_rest = spark.read.option("header", False).csv(
"dbfs:/databricks-datasets/airlines/",
schema=df_schema,
pathGlobFilter="part-[0-9][0-9][0-9][0-9][1-9]",
)
df_rest = df_rest.withColumn("filename", input_file_name())
display(df_rest)
このデータフレームをテーブルに見立ててSQLで確認したいので、一時ビューとして登録します。
df_rest.createOrReplaceTempView("df_rest")
これでSQLからアクセスすることができます。
%sql
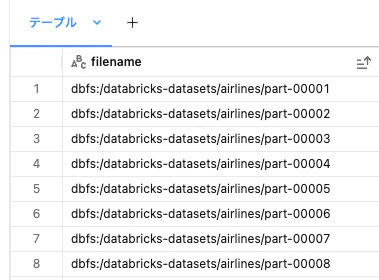
SELECT DISTINCT filename FROM df_rest;
part-00000がスキップされていることが確認できました。
結合に不要な列があるので、もう一度データフレームを作り直してからunionで結合します。
df_rest = spark.read.option("header", False).csv(
"dbfs:/databricks-datasets/airlines/",
schema=df_schema,
pathGlobFilter="part-[0-9][0-9][0-9][0-9][1-9]",
)
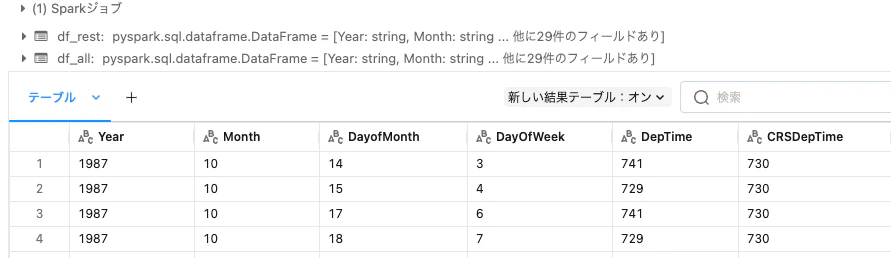
df_all = df_first.union(df_rest)
display(df_all)
完了です。
Parquetファイルの抽出
フォーマットでParquetを指定するだけで大丈夫です。
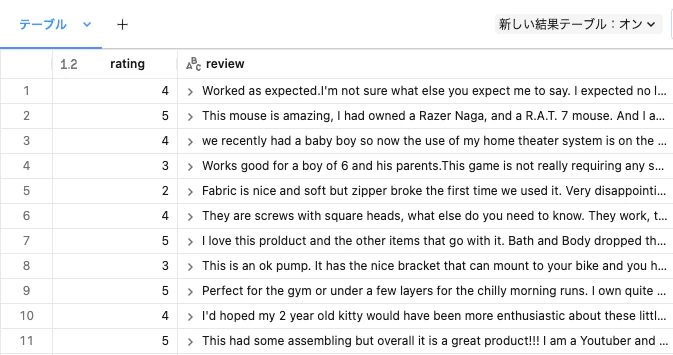
df = spark.read.format("parquet").option("header", True).load("dbfs:/databricks-datasets/amazon/data20K/")
display(df)
JSONファイルの抽出
フォーマットでjsonを指定するだけで大丈夫です。
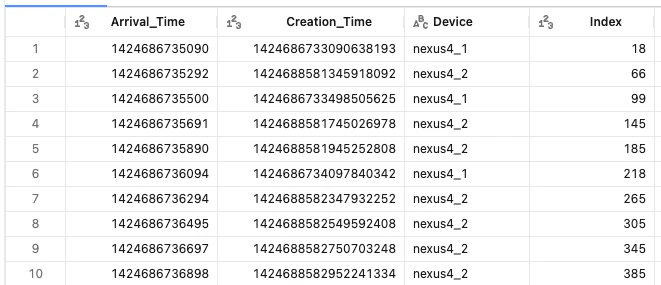
df = spark.read.format("json").load("dbfs:/databricks-datasets/definitive-guide/data/activity-data/")
display(df)
画像ファイルの抽出
Sparkでは画像データソースもサポートしています。お手軽にディレクトリに格納されている画像ファイルをデータフレームに取り込むことができます。
%fs
ls dbfs:/databricks-datasets/cctvVideos/train_images/
label=xというディレクトリが格納されています。

それぞれのディレクトリに画像(JPG)ファイルが格納されています。
%fs
ls dbfs:/databricks-datasets/cctvVideos/train_images/label=0/

formatでimageを指定します。
df = spark.read.format("image").load("dbfs:/databricks-datasets/cctvVideos/train_images/")
display(df)
画像がデータフレームとして読み込まれ、親ディレクトリのlabel=xも列に追加されています。この機能を活用すると、画像分類タスクなどにおける教師データとして容易に活用できるようになります。

まとめ
- まずはソースデータを確認しましょう。
headコマンドが一番お手軽かと。 - 時には複雑な前処理が必要になる場合がありますが、必要な関数などは揃ってます!
- 大量データを処理する場合には、コア数の多いマシンで並列度を高めてSparkで高速に処理しましょう。