Databricksクイックスタートガイドのコンテンツです。
Image | Databricks on AWS [2021/5/10時点]の翻訳です。
重要!
生のバイト列として画像データをSparkデータフレームに読む込む際には、バイナリーファイルデータソースを使用することをお勧めします。画像データの取り扱いにおいてお勧めするワークフローに関しては、画像アプリケーションに対するDatabricksリファレンスソリューションを参照ください。
画像データソースは、詳細な画像の表現方式を抽象化し、画像データを読み込むための標準的なAPIを提供します。画像ファイルを読み込むには、データソースのformatをimageに指定します。
df = spark.read.format("image").load("<path-to-image-data>")
Scala、Java、Rでも同様のAPIを提供しています。
画像データソースを用いることで、ネストされたディレクトリ構造(例えば、/path/to/dir/**のようなパス)をインポートすることができます。特定の画像に対しては、パーティションディレクトリ(/path/to/dir/date=2018-01-02/category=automobileのようなパス)のパスを指定することで、パーティションディスカバリーを使用することもできます。
画像データの構造
画像はimageという列を持つデータフレームに読み込まれます。imageは以下のフィールドを持つstruct型のカラムとなります。
image: 画像データ全てを格納する構造体
|-- origin: ソースURIを表現する文字列
|-- height: 画素数による画像の高さ、整数値
|-- width: 画素数による画像の幅、整数値
|-- nChannels
|-- mode
|-- data
-
nChannels: カラーチャンネルの数。典型的な値はグレースケールの画像場合は1、RGBのようなカラーイメージは3、アルファチャネルを持つカラーイメージは4となります。
-
mode: データフィールドを解釈するための整数値の情報を提供します。格納されているデータのデータ型とチャンネルオーダーを保持しています。フィールドの値は、以下のテーブルにあるように、OpenCVタイプの一つにマッピングされることを期待されます(強制はされません)。OpenCVタイプは1、2、3、4のチャネル、画素値に対するいくつかのデータタイプを定義します。チャネルの順序は、色が格納される順序を指定します。例えば、赤、青、緑のコンポーネントを持つ典型的な3チャネルの画像を取り扱う際、6つの順序を取り得ます。多くのライブラリはRGBかBGRを使用します。3(4)チャネルのOpenCVのタイプはBGR(A)の順序であることが期待されます。
OpenCVの値(データタイプ x チャンネルの数)に対するタイプのマッピングは以下の通りとなります。
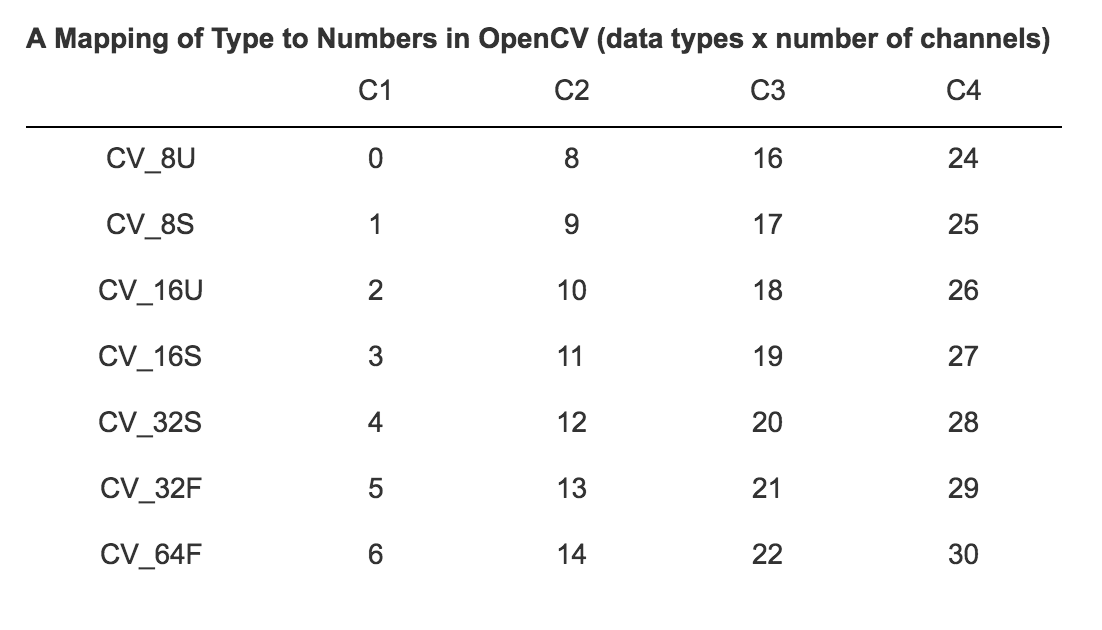
-
data: バイナリー形式で格納された画像データです。画像データは、次元の形状(height, width, nChannels)の3次元の配列、modeで指定されるt型の配列値となります。配列は行優先(row-major)で格納されます。
画像データの表示
Databricksのdisplay関数は画像データの表示をサポートしています。詳細はこちらを参照ください。
サンプルノートブック
以下のノートブックでは、どのように画像ファイルを読み書きするのかを説明しています。
画像データソースノートブック
画像データソースの制限
画像データソースはSparkデータフレームを作成する過程で画像ファイルをデコードするのでデータサイズが増加し、以下のシナリオにおいては制限が生じます。
- データフレームの永続化: アクセスを容易にするためにDeltaテーブルでデータフレームを永続したい場合には、ディスク容量を節約するために生のバイト列を永続化すべきです。
- パーティションのシャッフル: デコードされた画像をシャッフルする際には、多くのディスク容量とネットワーク帯域が必要となるためシャッフルが遅くなります。画像のデコードは可能な限り後回しにすべきです。
- 他のデコード方法の利用: 画像データソースは、画像をデコードするためにjavaxの画像IOライブラリを使用します。このため、カスタムのデコードロジックや性能改善のために他の画像でコードライブラリを使用できません。
これらの制限は、画像データをロードする際にバイナリーファイルデータソースを使用し、必要な時のみデコードすることで回避できます。