自分もはじめはうまく理解できていなかったので、改めてここで整理します。まず、サマリーから書きます。
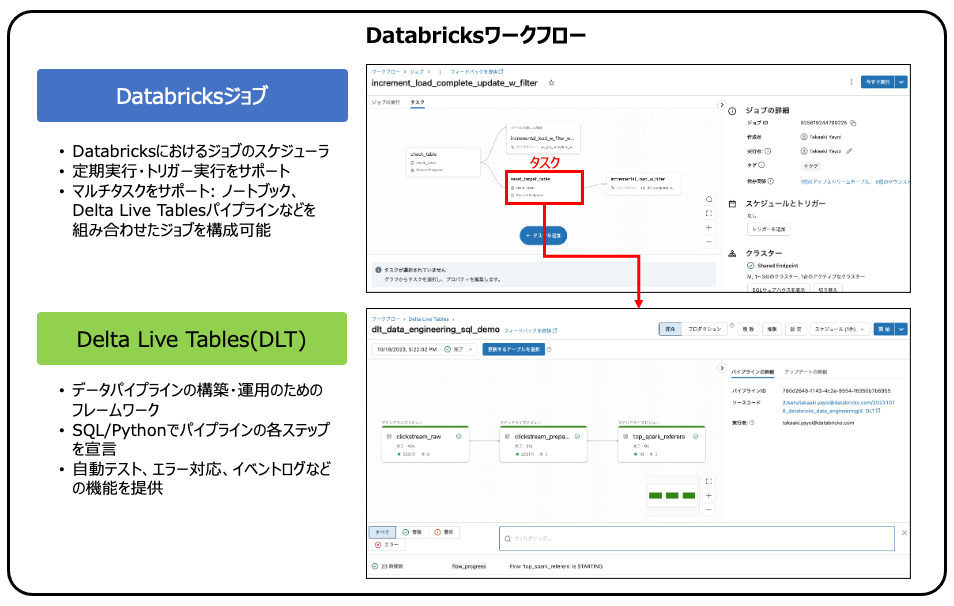
- Databricksでオーケストレーションを一手に担っているのがDatabricksワークフローで、ワークフローにはDatabricksジョブとDelta Live Tablesが含まれています。ワークフロー自体は概念を指す言葉なので、実際の機能はDatabricksジョブとDelta Live Tables(DLT)が提供しています。
- Databricksジョブではマルチタスクをサポートしており、タスクとしてはノートブックやDelta Live Tablesのパイプラインを実行することができます。
- Delta Live Tablesはデータパイプラインを構築・運用するためのフレームワークであり、少ないコーディングで高信頼・高パフォーマンスのパイプラインを構築することができます。
| 機能 | 用途 | 処理対象 |
|---|---|---|
| Databricksジョブ | マルチタスクのオーケストレーション | Databricks上の資産(ノートブック、SQLクエリー、Delta Live Tablesパイプライン、ダッシュボードなど) |
| Delta Live Tables | データパイプラインの構築・運用 | Delta Lakeテーブル |
Databricksワークフローとは
Databricksワークフローは、Databricksのマネージドオーケストレーションサービスを意味します。実態としては、以下の2つの機能から構成されています。ワークフロー自体の機能は現時点では存在しておらず、以下の2つを包含する概念と理解していただくのがよろしいかと思います。
Databricksジョブとは
Databricksジョブは、ノートブックのようなインタラクティブな方法で処理を行うのではなく、スケジュール実行、トリガー実行など人間を介さない形で処理を実行するための機能を提供するジョブスケジューラです。マルチタスクをサポートしており、ノートブック、SQLクエリー、Delta Live Tablesパイプラインなどのタスクを組み合わせてジョブを実行することができます。条件分岐をサポートしており処理の並列化などで活用することができます。
Delta Live Tablesとは
Databricksでのデータパイプラインの構築を容易にするフレームワークです。SQLあるいはPythonでデータパイプラインの各ステップを宣言していただくだけで、複雑なパイプラインを容易に構築することが可能です。この他にもエラー時の対応、イベントログの取得、自動テストなどデータパイプラインの運用に不可欠な機能を提供しているので、データエンジニアの方はパイプラインのロジックの構築にフォーカスすることができます。
DatabricksジョブとDelta Live Tablesの組み合わせパターン
- Delta Live Tablesを用いて、S3に到着する新規ファイルを自動で取り込み、クレンジングや集計を行うデータパイプラインを開発します。

- パイプラインを実行してデバッグを行います。この際には開発モードを使用します。開発モードの場合、パイプラインが失敗しても自動リトライが実行されないので、繰り返しの開発が容易になります。また、クラスターも処理完了後に即時には停止しません。プロダクションモードの場合は、自動リトライが実行され、パイプライン終了後即座にクラスターが停止します。パイプラインの動作が確認できたら、プロダクションモードに切り替えます。

- テーブルの存在確認を行うなど前処理のSQLクエリーを作成します。
- Databricksジョブを作成します。最初のタスクでは上で作成したクエリーを実行するようにします。

- 以下の例では、存在確認が失敗した場合、すなわち、テーブルが存在しない場合にはDelta Live Tablesパイプラインを実行します。

- 存在確認が成功した場合、すなわち、テーブルが存在する際にはテーブルを削除した後に、Delta Live Tablesパイプラインを実行します。

- マルチタスクの各ステップの成功・失敗はジョブの実行から確認することができます。

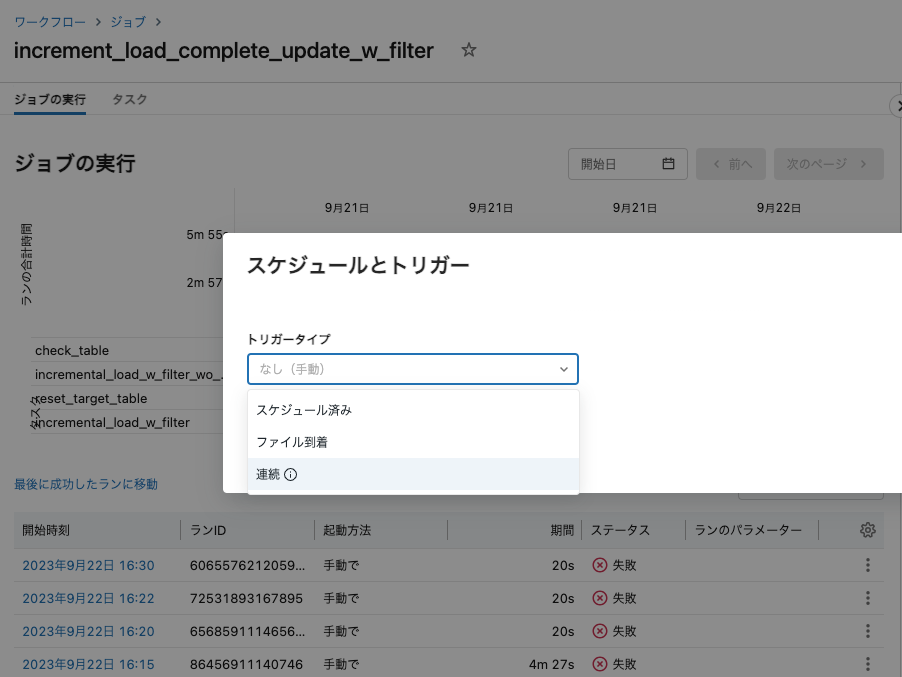
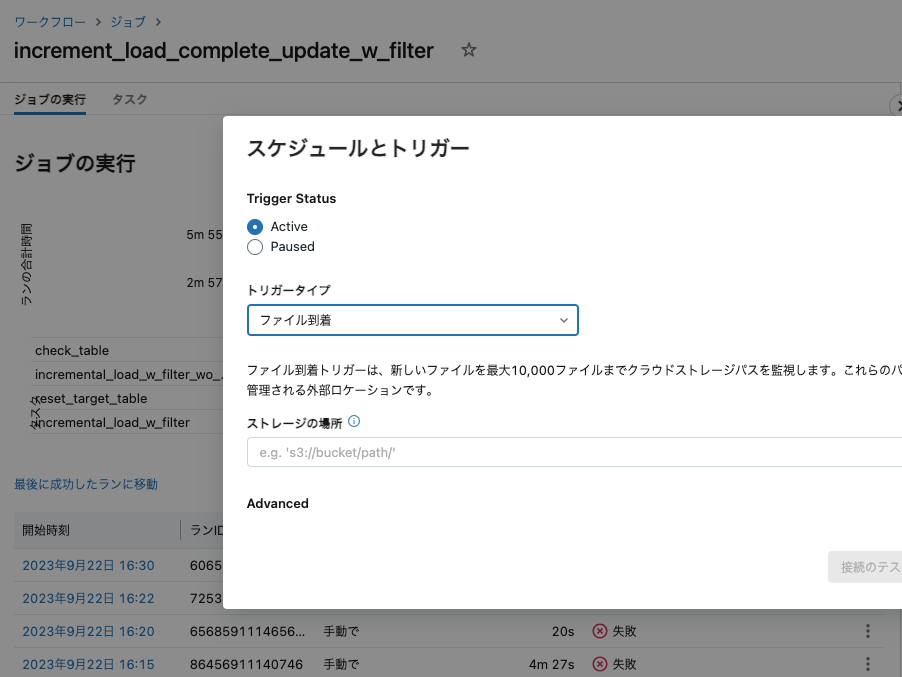
このジョブをスケジュール実行あるいはファイル到着を契機として実行することができます。また、上で示したように、即時実行するケースにおいても、複雑な処理をまとめ上げたいという用途でもご活用いただけます。
非常に強力なツールですので、是非ご活用ください!