2026年1月に大幅更新しました。サーバーレスコンピューティング、Databricks Assistant、Lakeflow等の最新機能を反映しています。

対象読者
- これからDatabricksを使い始めるが、どこから手をつけたらいいのか悩んでいる。
- 個人学習やプロトタイピングでDatabricksを試してみたい。
2026年1月更新: 本記事は Databricks Free Edition を前提に解説しています。Free Editionは2025年6月にリリースされた無料版で、学生、教育者、愛好家、データとAIを学びたいすべての方が対象です。2026年1月1日にCommunity Editionは廃止され、Free Editionに移行しました。
環境の準備
ワークスペースがない場合は、以下のいずれかを選択してください。
- Databricks Free Edition(推奨): 無料で始められます。クレジットカード不要で、サインアップ後すぐに利用可能です。本記事はFree Editionを前提としています。
- 無料トライアル: エンタープライズ向け機能を評価したい場合はこちら。
Free Editionの特徴
Databricks Free Editionは、従来のCommunity Editionと比較して大幅に機能強化されています。
| 項目 | Community Edition(廃止) | Free Edition |
|---|---|---|
| 計算資源 | シングルノードクラスターのみ | サーバーレス(起動待ち不要) |
| Unity Catalog | 利用不可 | 利用可能 |
| Databricks Assistant | 制限あり | フル機能 |
| AI/BI Genie | 利用不可 | 利用可能 |
| Agent Framework | 利用不可 | 利用可能 |
| Databricks Apps | 利用不可 | 利用可能(1アプリまで) |
Free Editionには以下の制限があります:
- クォータ制限: 1日あたりの利用量に上限があり、超過するとその日のコンピュートが利用不可になります(データは削除されません)
- 商用利用不可: 学習・プロトタイピング目的のみ
- SLA対象外: サポートやサービスレベル保証はありません
- サーバーレスのみ: 従来型クラスターは作成できません
関連記事
Free Editionの詳細やチュートリアルについては以下の記事も参考にしてください。
- Databricks Free Edition - Free Editionの概要と始め方
- Databricks Free Editionチュートリアル - 体系的なチュートリアル
- Databricks Free Editionで学ぶDatabricksノートブック - ノートブックの使い方
- Databricks Free Editionで学ぶAI/BI Genie - 自然言語でのデータ分析
- Databricks Free Editionで学ぶAIエージェント - Agent Frameworkの入門
- Databricks Free Editionで始めるDatabricks Apps - アプリ開発入門
- Databricks Free Editionで始めるApache Spark - Sparkの基礎
- 【2025年版】Google Colab/Jupyter経験者のためのDatabricks学習ロードマップ - 学習の進め方
お悩み事
これまでに以下のようなお悩み事を伺っているので、可能な限り解消していきたいと思います。
- Databricksとは何かがわからない、何ができるのかわからない
- Jupyter NotebookやGoogle Colaboratoryと何が違うのかがわからない
- Databricksをどう使えばいいのかがわからない
- 画面が英語でとっつきにくい
- Databricksのメニュー項目が多すぎてどれがどれかがわからない
- 不用意にデータやファイルを上書きしてしまわないかが怖い
Databricksとは
すごくざっくり言えば データやAIの活用というユースケースで必要となるさまざまな便利機能を搭載しているノートブック開発環境 です。ざっくりしすぎかもしれませんが、データサイエンティストやデータエンジニアの方が最初に触れるインタフェースはJupyter NotebookやGoogle Colaboratoryと同様のノートブックです。
Jupyter NotebookやGoogle Colaboratoryとの違い
Jupyter Notebookとの違い
Databricksではビルトインのビジュアライゼーションの機能があるなど、細かいところを挙げると色々ありますが、大きな違いは ラップトップで稼働させるのか、クラウドで稼働させるのか だと思います。稼働する場所で何が違うのかというと:
| Jupyter Notebook | Databricks | |
|---|---|---|
| 計算リソース | Jupyter Notebookが稼働しているラップトップ、サーバーのリソースに制限を受けます。多くの場合、pandasの利用が前提となるのでメモリーの制約を受けます。 | クラウドプロバイダー(AWS/Azure/GCP)が提供するリソースを理論上無制限に活用できます。pandasに加えてSparkも活用できるので、並列処理による恩恵を享受することができます。 |
| コラボレーション | ラップトップで動作しているJupyter Notebookでの他のユーザーとのコラボレーションは限定的であり、JupyterHubを用いたとしてもその機能は限定的です。 | 複数ユーザーによるコラボレーションを前提としており、ノートブックやデータに対するアクセス制御やノートブックの同時参照、同時編集をサポートしています。 |
| ガバナンス | ラップトップで動作しているJupyter Notebookでは、個人のデータサイエンティストによる管理しか行えず、企業全体でのデータやコード、機械学習モデルの管理を統一することができません。 | MLOpsを前提としており、データ、コード、機械学習モデルは全てUnity Catalogによって管理されます。 |
| 本格運用(Production) | ラップトップ上で実験的にPythonを実行するには適してますが、本格運用するためにジョブを組むには別のシステムが必要となります。 | DatabricksにはLakeflow Jobsの機能が搭載されているので、実験・テストを経たロジックを簡単に本格運用に移行することができます。また、さまざまなAPIを公開しているので、他のシステムとの連携も容易です。 |
Google Colaboratoryとの違い
Google Colaboratoryもクラウドで稼働するのでJupyter Notebookのリソースやコラボレーションの課題はある程度解消されますが、以下のような違いがあります。
| Google Colaboratory | Databricks Free Edition | |
|---|---|---|
| ホスティング | Googleがホスティング | Databricksがホスティング(サーバーレス) |
| データソース | Google Drive | Unity Catalog |
| AI支援 | Gemini | Databricks Assistant |
| ビジュアライゼーション | matplotlibなど | ビルトイン可視化 + matplotlibなど |
ガバナンスや本格運用などその他の違いに関してはJupyter Notebookと同様です。Free EditionではGPUは利用できませんが、サーバーレスにより起動待ち時間なしで処理を開始できます。
Databricksの使い方
私は 全体像を大まかに理解してから、必要に応じて詳細に踏み込む アプローチが好きです。最初から全てを理解しようとしていたら、いつまで経っても一歩を踏み出せません。
ということで、使い方のイメージをざっくり書いてみました。
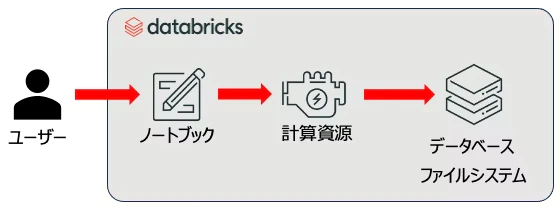
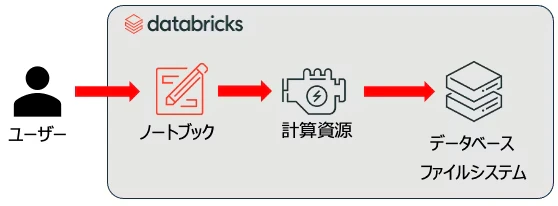
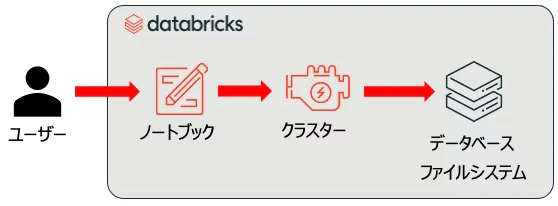
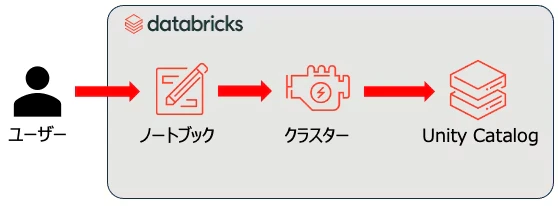
ユーザーはデータサイエンティストやデータエンジニアです。それ以外の登場人物はこちらです。
- ノートブック: そのままです。Pythonなどでロジックを記述します。
- 計算資源: Jupyter Notebookを利用している際にはあまり意識しないかもしれませんが、ラップトップであればラップトップのCPUやメモリーを使ってプログラムが実行されます。
- データベース・ファイルシステム: データを読み込んだり永続化するにはデータベースやファイルシステムが必要となります。Jupyter NotebookであればローカルのファイルシステムやODBC/JDBC経由で接続したデータベースになるでしょう。
なので、Databricksを使うにしても、使い方にはJupyter Notebookと大きな違いはないと言えます(LLMなど複雑なことをやり始めるとこの限りではありませんが)。
とは言え、これではあまりにも抽象的なので、以下のステップを経てDatabricksでどういうことができるのかをウォークスルーしていきます。
- Databricksワークスペースへのアクセス
- ノートブックの作成
- 計算資源の準備
- データの読み込み
- データの加工
- データの保存
Databricksワークスペースへのアクセス
Free Editionにサインアップすると、自動的にワークスペースが作成されます。サインアップ時に使用したアカウント(Google、Microsoft、またはメールアドレス)でログインできます。
ワークスペースのURLはお客様固有のものとなります。環境構築をされた方にURLを確認してください。
初回アクセスの際、画面がすべて英語で表示さた場合には、以下の手順に従ってください。
- 画面右上のローマ字入り丸アイコンをクリックして、Settings をクリック。
- Userの下にある Preference をクリック。
-
Language から 日本語 を選択。
まずは、画面構成に慣れましょう。これもざっくり。
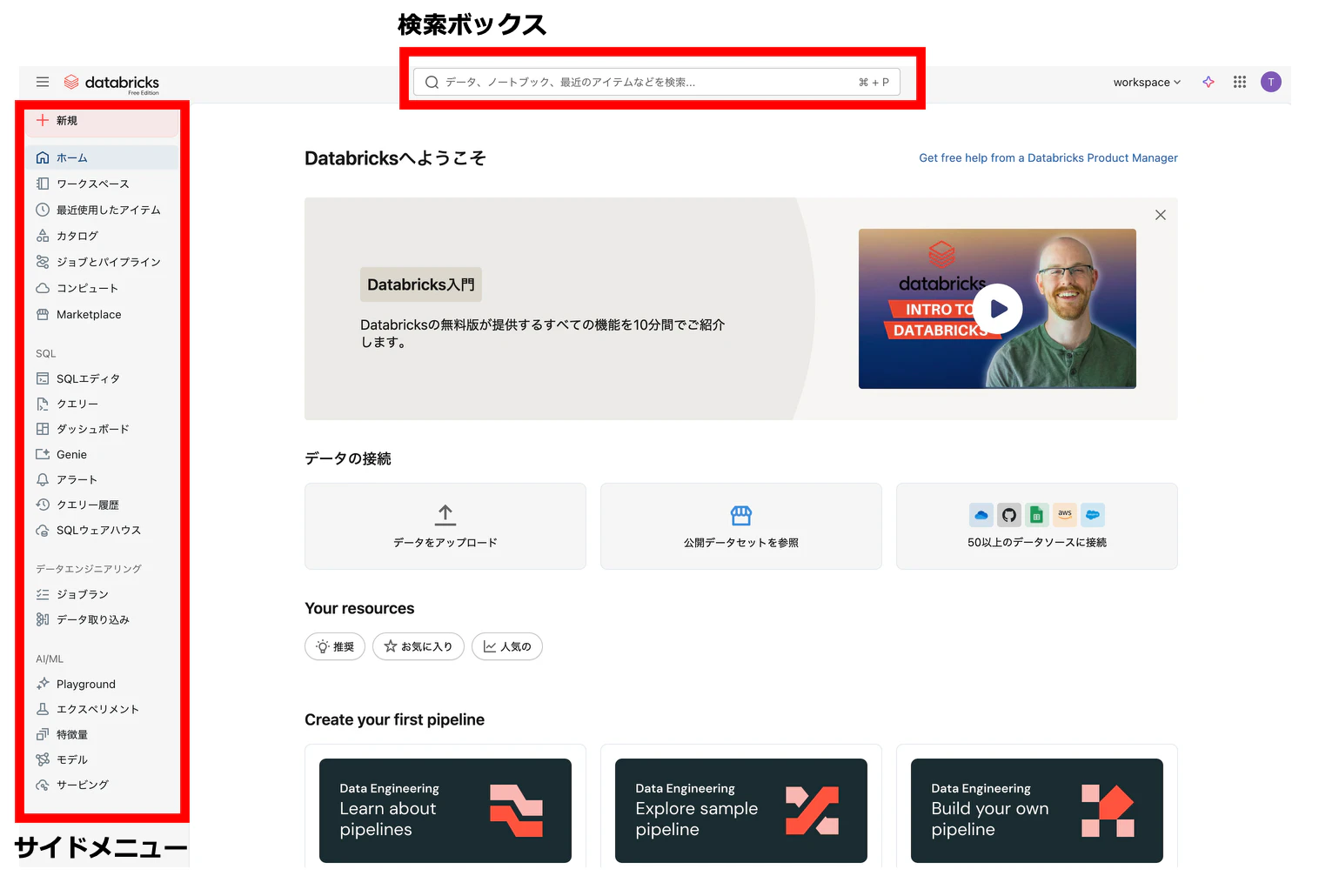
まず慣れる必要があるのは、画面左にある サイドメニュー です。Databricksの主要機能にアクセスする際に使用することになります。サイドメニュー上にカーソルを移動するとメニューが展開されます。
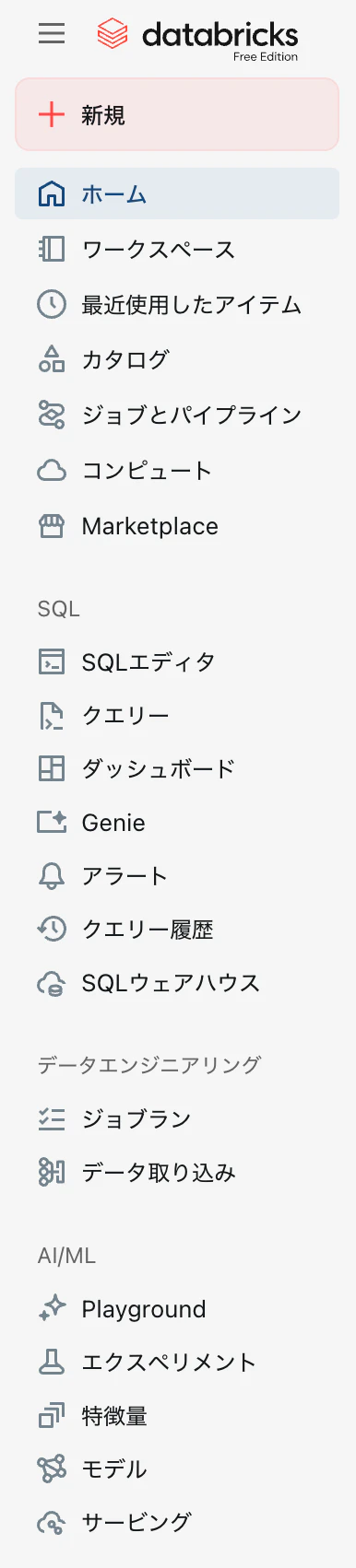
ここでも最初から全てを理解するのではなく、以下の項目にフォーカスします。他の機能は必要になったら勉強すればいいのです。
- 新規: Databricksにおけるさまざまなアセット(資産)を作成するときに使います。ノートブックやクラスターなど色々なアセットを作成できます。
- ワークスペース: アセットはフォルダで整理することができます。このフォルダ階層にアクセスするために使うメニュー項目がワークスペースです。
- カタログ: Databricksにビルトインされているデータベースのようなものです。テーブルだけでなくファイルや機械学習モデルなども格納することができます。
- コンピューティング: Databricksにおける計算資源です。ノートブックの編集では計算資源は不要ですが、プログラムを実行する際には計算資源は必須となります。
ノートブックの作成
Databricksでもプログラムを実行するにはノートブックを作成する必要があります(IDE連携をするなどすればPythonファイルを実行することもできます)。ノートブックを作成する前に、Databricksワークスペースのフォルダ階層を理解しましょう。
上述したようにDatabricksの環境は複数ユーザーによるコラボレーションを前提としています。このため、以下のフォルダがデフォルトで作成されます。
- ホームフォルダ: 各ユーザーごとのホームフォルダ。自分のアセットはデフォルトでホームフォルダ配下に作成されます。アクセス権を付与しない限り、他のユーザーがあなたのアセットにアクセスすることはできません。しかし、管理ユーザーはこの限りではありません。
- Workspace: ワークスペースに登録されたユーザーそれぞれのホームフォルダを格納します。
- Shared: すべてのユーザーが読み書きできるフォルダです。ノートブックの共有などの目的で使用します。
- お気に入り: ノートブックやフォルダをお気に入りに登録するとこちらに表示されます。ショートカットできます。
- ゴミ箱: 削除されたノートブックなどは一定期間こちらに格納されます。元に戻すこともできます。
自分のアセットはホームフォルダ配下、削除されたアセットはゴミ箱をまず覚えておくと良いかと思います。
ホームフォルダ直下にノートブックを作成しても構いませんが、整理できるように私は作業内容ごとにフォルダを作成しています。ワークスペースを表示している状態で右上の 作成 をクリックします。
フォルダ を選択します。
フォルダ名を入力します。

ノートブックを作成する手段はいくつかありますが、上と同じように 作成 > ノートブック を選択します。
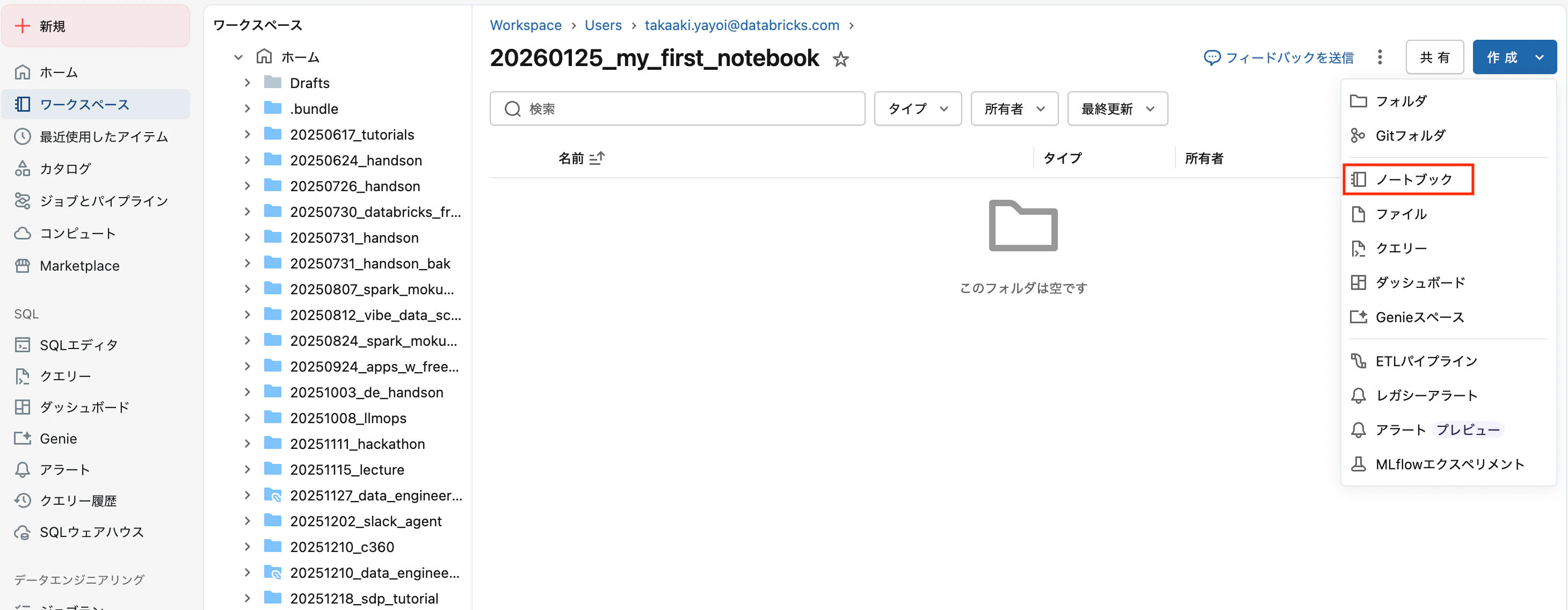
これでノートブックを作成できました。
ここで、ノートブックの画面にも慣れておきましょう。ちなみに、サイドメニュー上の三本線アイコンでサイドメニューの表示、非表示を切り替えられます。
ノートブックのインタフェース自体はJupyterやColaboratoryと大きな違いはないと思います。
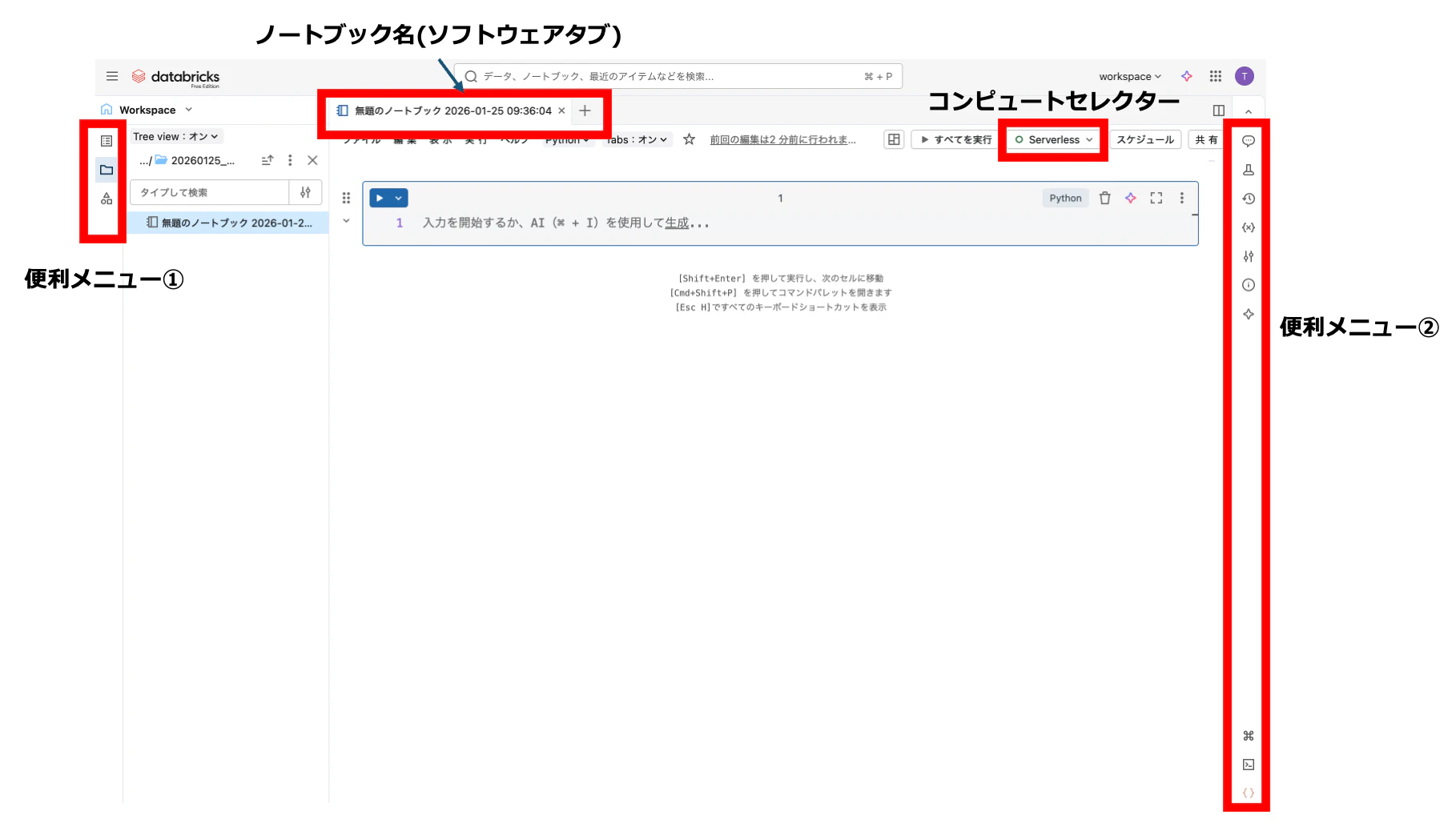
ノートブック名はクリックで編集できます。また、ノートブック名の部分はソフトウェアタブになっているので、複数のノートブックやファイルを開いてもブラウザタブを増やす必要はありません。
今回、便利メニューの説明は割愛します。目次の表示、ワークスペースフォルダへのアクセス、Unity Catalogメタストアへのアクセス、AIアシスタント、ノートブックコメント、機械学習モデルのトラッキング、バージョン履歴、変数エクスプローラ、ライブラリエクスプローラなどを利用できます。詳細はこちらをご覧ください。
今回重要になるのはノートブック本体と計算資源セレクターです。ノートブックにプログラムを記述するのは当たり前ですが、Databricksの 計算資源(コンピュート) が必要となります。
計算資源の準備
Free Editionでは サーバーレスコンピュート のみ利用可能です。従来のCommunity Editionではクラスター起動に数分かかっていましたが、サーバーレスでは数秒で処理を開始できます。
サーバーレスコンピュート
サーバーレスコンピュートは、Databricksがインフラストラクチャを完全に管理する計算資源です。以下のメリットがあります。
- 即座に利用開始: クラスター起動を待つ必要がなく、数秒で処理を開始できます
- インフラ管理不要: Databricksが自動的にリソースを最適化・スケーリングします
- 自動アップグレード: 最新のDatabricks Runtime(現在17.x系)が自動で適用されます
ノートブック画面で、右上のコンピュートセレクターをクリックします。
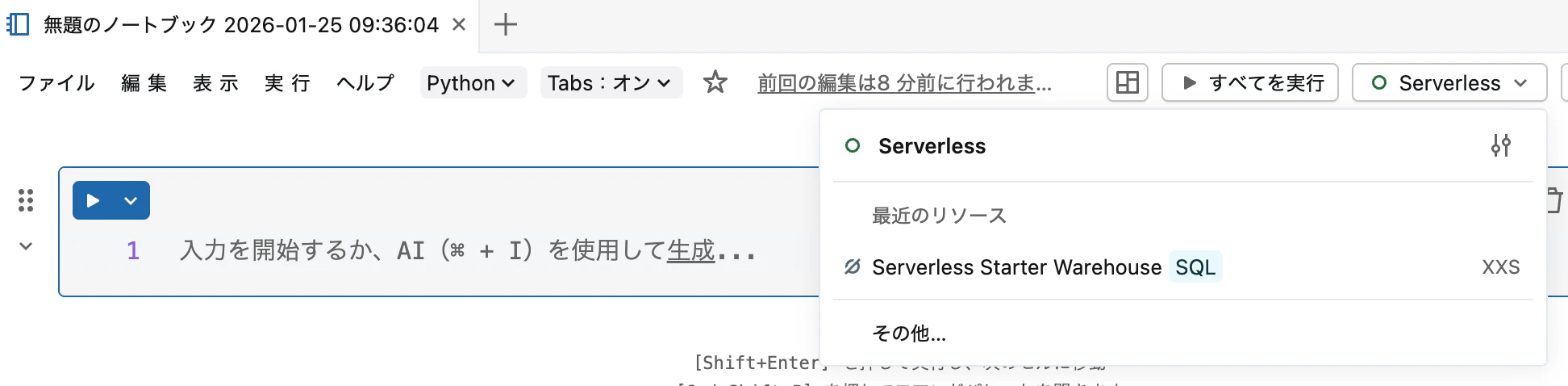
Serverless(サーバーレス) を選択します。
これだけで準備完了です!クラスターの起動を待つ必要はありません。
Free Editionではサーバーレスのみ利用可能です。エンタープライズ版や無料トライアルでは、大規模データ処理や特定の設定が必要な場合に従来型クラスター(Classic compute)も使用できます。また、Databricksにおいては、クラスターとコンピュートは同義語と考えていただいて構いません。
お約束のプログラムを実行
計算資源を選択したら、お約束のプログラムを実行しましょう。セルに以下を記述します。
print("Hello Databricks!")
セルの左上にある▶️をクリックし、セルを実行 をクリックします。
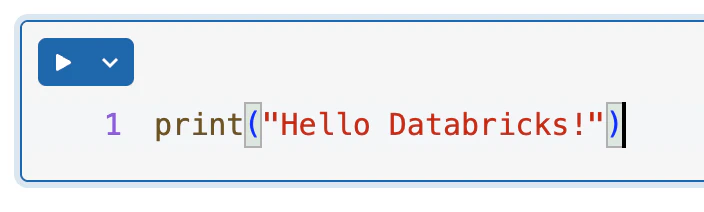
動きました!
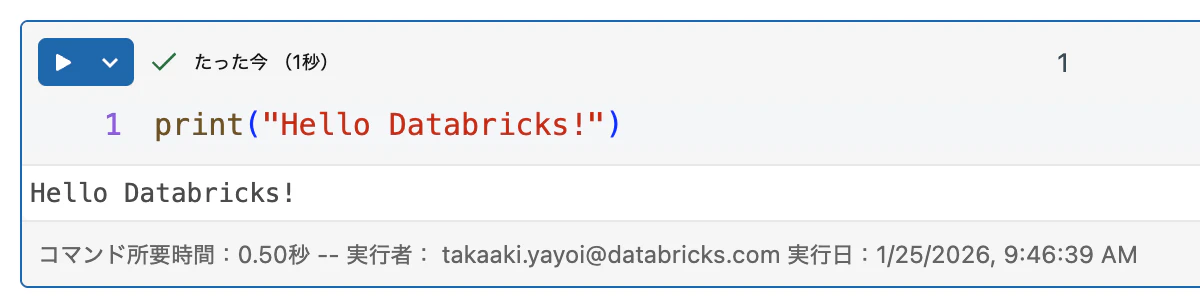
エラーが出る場合には、ノートブック名の右にある言語がPythonであるかどうかを確認してください。
Databricksアシスタントを活用しよう
2026年現在、Databricksには強力なAIアシスタント機能が搭載されています。初心者の方にとって非常に心強い味方になりますので、積極的に活用しましょう。
アシスタントの基本的な使い方
画面右上のAssistantアイコンをクリックするとアシスタントパネルが開きます。
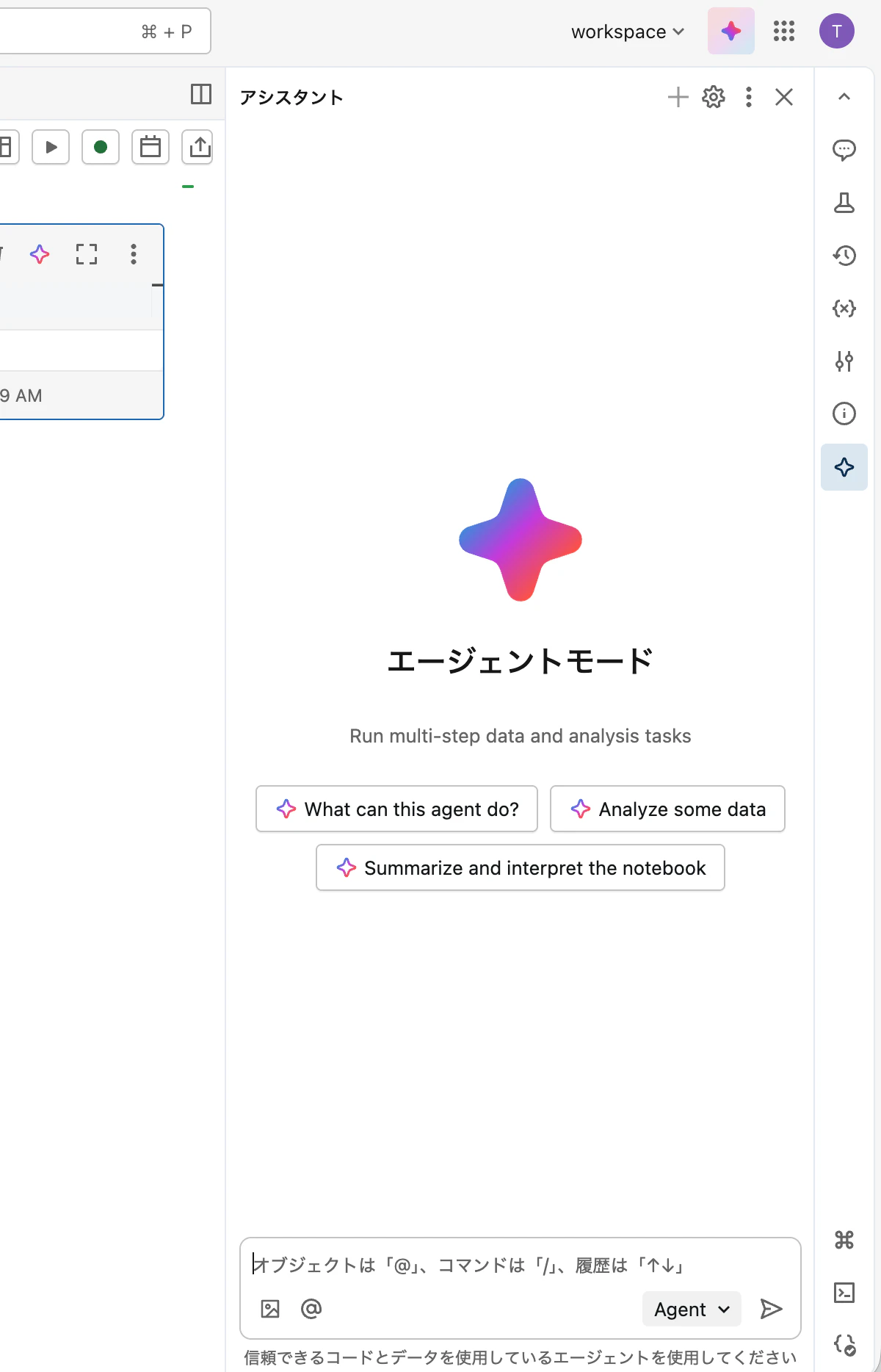
アシスタントは以下のようなことができます。
- コード生成: 自然言語でやりたいことを伝えると、PythonやSQLのコードを生成してくれます
- コード説明: 複雑なコードの意味を解説してくれます
- エラー修正: エラーが発生した際に、原因と修正方法を提案してくれます
- ドキュメント参照: Databricksの公式ドキュメントから関連情報を引用して回答してくれます
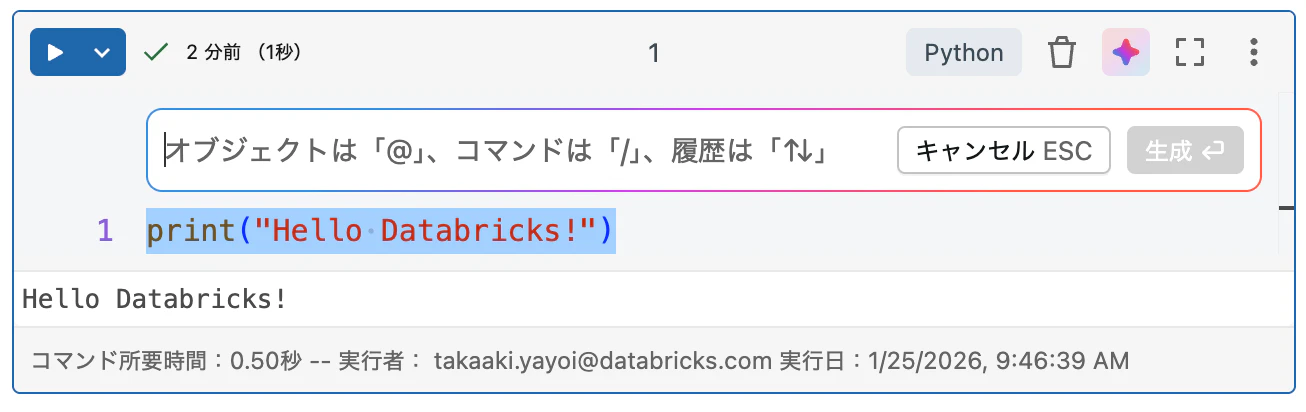
セル内からの直接呼び出し
ノートブックのセル内で Cmd+I(Mac)または Ctrl+I(Windows)を押すと、その場でアシスタントを呼び出せます。
エージェントモード(データサイエンスエージェント)
2025年に追加された エージェントモード は、アシスタントをさらに強力にした機能です。単一のプロンプトから複数ステップの処理を自動で実行できます。
- データの探索と分析
- コードの生成と実行
- エラーの自動修正
- 結果の可視化
アシスタントパネル下部のモードセレクターから「Agent」を選択して利用できます。
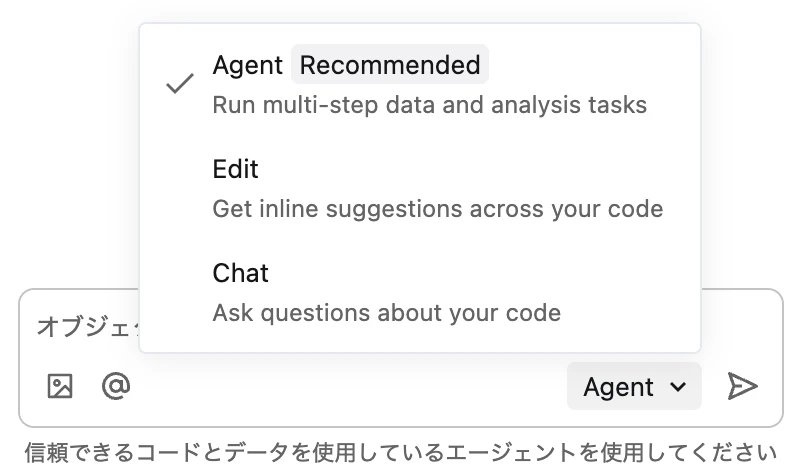
Editモード
Editモード は、単一のプロンプトでノートブック内の複数セルに対して編集を適用できる機能です。リファクタリングや変数名の一括変更などに便利です。
データの読み込み
これでDatabricksでプログラムを実行できるようになりました。早速データを処理していきましょう。ノートブックにセルを追加するには、ノートブックの上か下の端にカーソルを移動します。+ ボタンが表示されるのでこれをクリックします。
Databricksにおいてデータやファイル、機械学習モデルを管理するためのソリューションはUnity Catalogです。名前の通り、カタログソリューションであり上述のアセットのアクセス管理、監査ログ、依存関係などをまるっと面倒見てくれます。色々な機能を提供しますが、ここではデータの読み書きにフォーカスします。
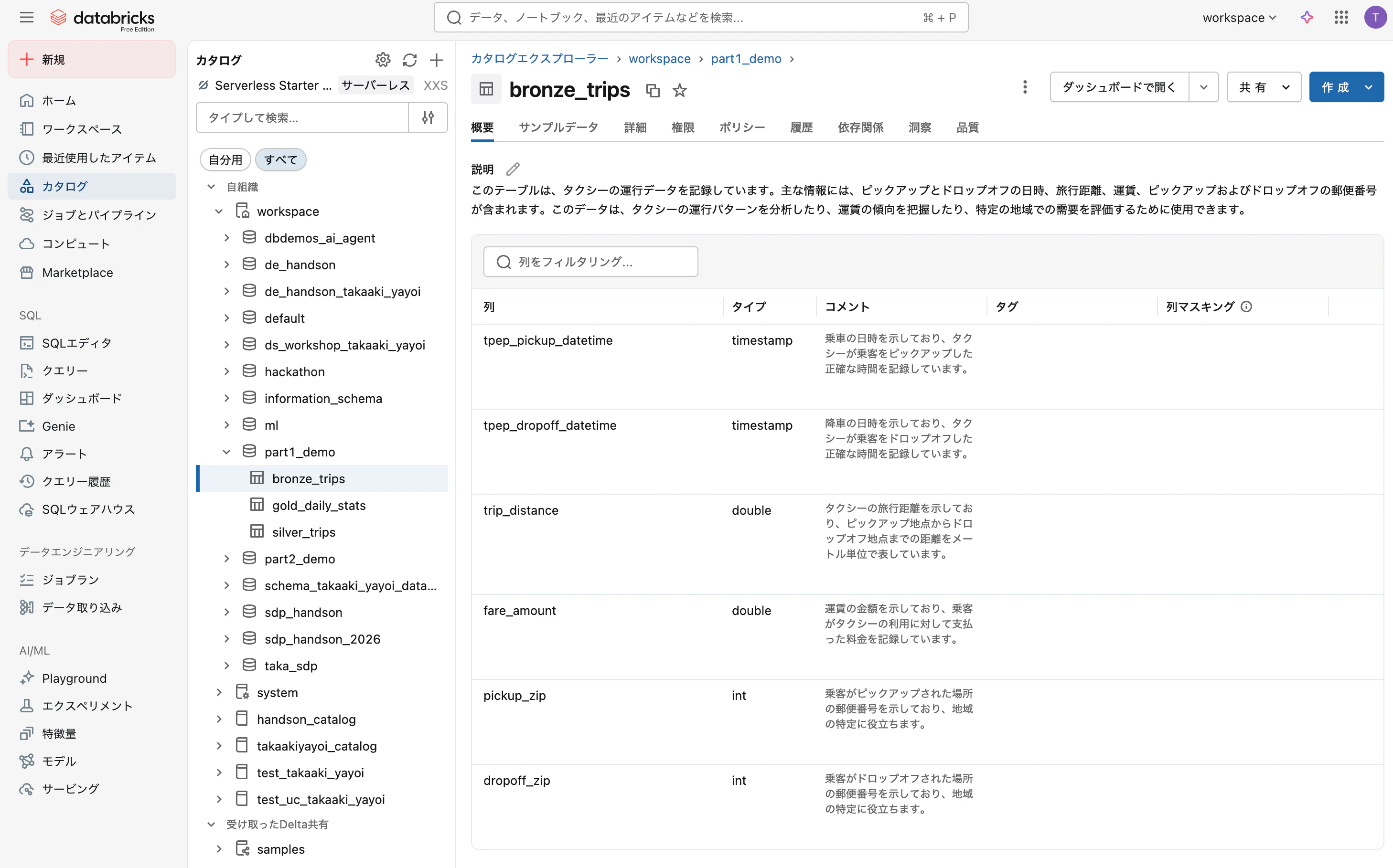
Unity Catalogにはすぐに利用できるサンプルデータが格納されているので、ここではそれを使います。Unity Catalogで管理されているデータをクイックに確認するには カタログエクスプローラ が便利です。サイドメニューの カタログ をクリックします。スキーマやデータを簡単に確認できます。
ノートブックに戻ります。ここでのノートブックはPythonなので、Pythonで処理するのが素直だと思うのですが、データベースの処理をするならSQLの方がわかりやすいので、PythonノートブックでSQLを使います。これもDatabricksの提供する柔軟性の一つです。セルの先頭にマジックコマンド %sql を追加することでそのセルの言語をSQLに切り替えることができます。他の言語(R、SQL、Python)も同様です。
%sql
SELECT * FROM samples.tpch.orders LIMIT 1000;
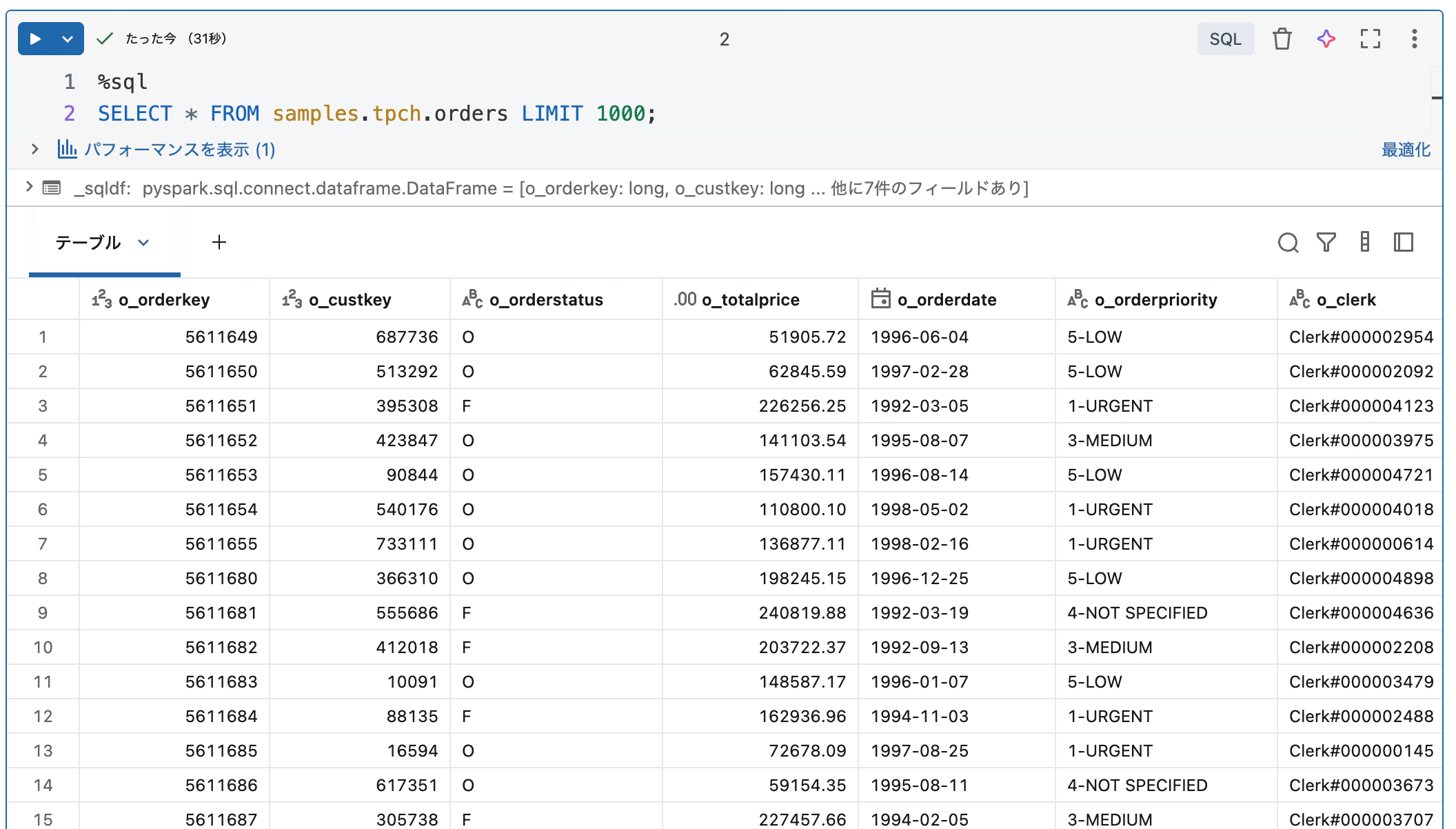
テーブル名を samples.tpch.orders と指定していることに注意してください。Unity Catalogで管理されるテーブルは 3階層の名前空間 で管理されます。<カタログ>.<スキーマ(データベース)>.<テーブル> で個々のテーブルを特定します。テーブルだろうがファイルだろうが、データを読み書きする際には、どのデータを対象に処理をしているのかを意識する ことが重要です。テーブルなら上記の名前空間、ファイルならパスとなります。よくある間違いの一つは 意図しないテーブルやパスのファイルを読み込んだり、書き込んだりしていた だと思います。
読み込み処理はこれで終わりではありません。上のスクリーンショットには テーブル の右に + が表示されてます。これをクリックします。可視化を選択します。
こちらの手順に従ってビジュアライゼーションの設定を行います。その後で保存をクリックします。
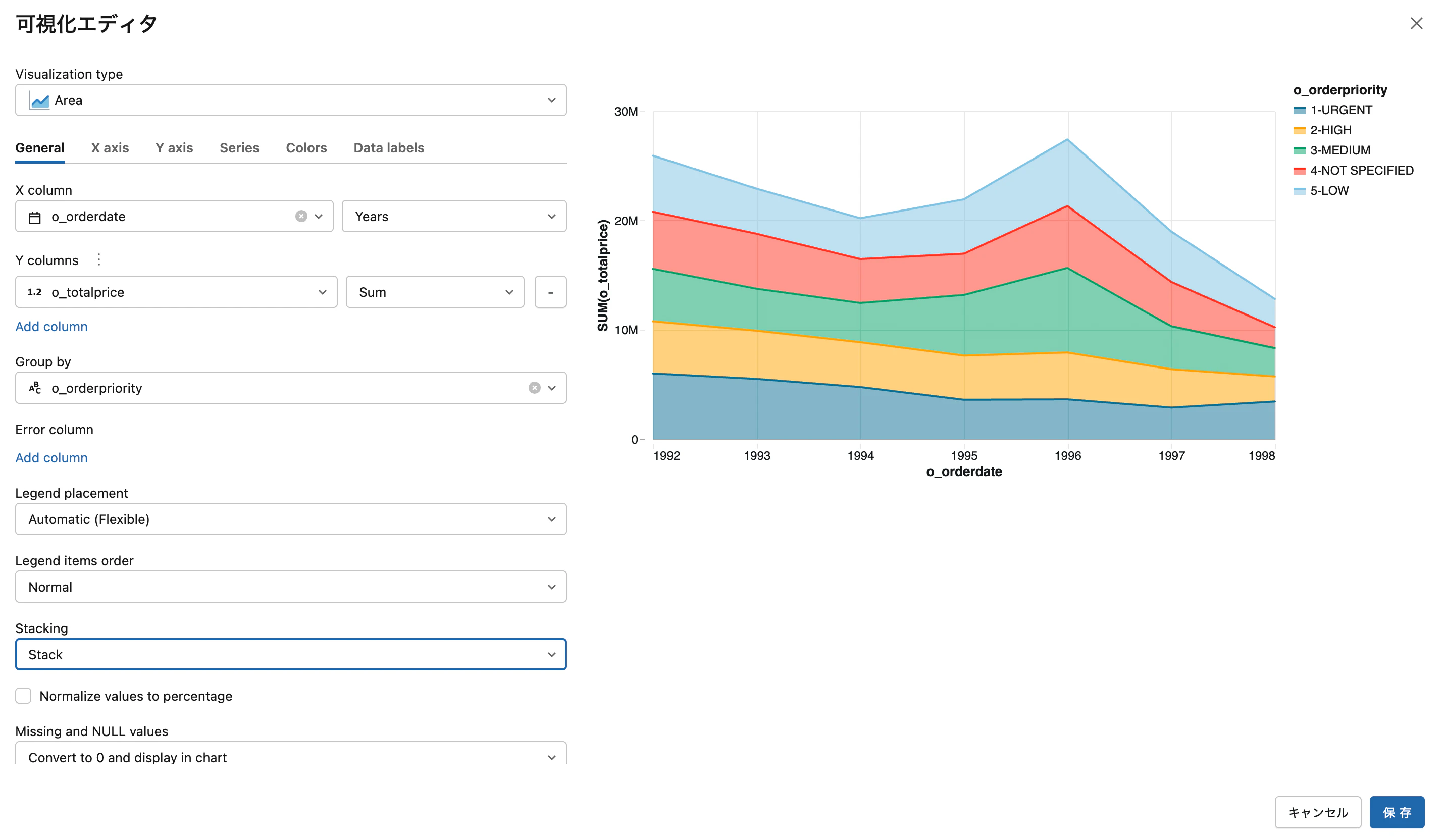
これでノートブックにグラフを追加することができました。Jupyterなどであればmatplotlibやseabornで可視化のロジックを記述しないとグラフにすることができませんが、Databricksならこの辺りはお手軽にできます。もちろん、matplotlibやseabornも使えます。
データの加工
こちらでも書いていますが、どのような変換を行いたいのかに応じて処理を実装することになります。
ここではすでに別の方(データエンジニアなど)によってデータが準備されていることを前提にします。自分でデータを準備する場合にはこちらをご一読ください。
例えば、対象データの特定の列と特定の行に限定したいというフィルタリング処理を行ってみます。行の絞り込みでは o_orderdate と o_totalprice にフィルタリング条件を適用しています。
%sql
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority
FROM
samples.tpch.orders
WHERE
o_orderdate = "1998-07-01"
AND o_totalprice >= 100000
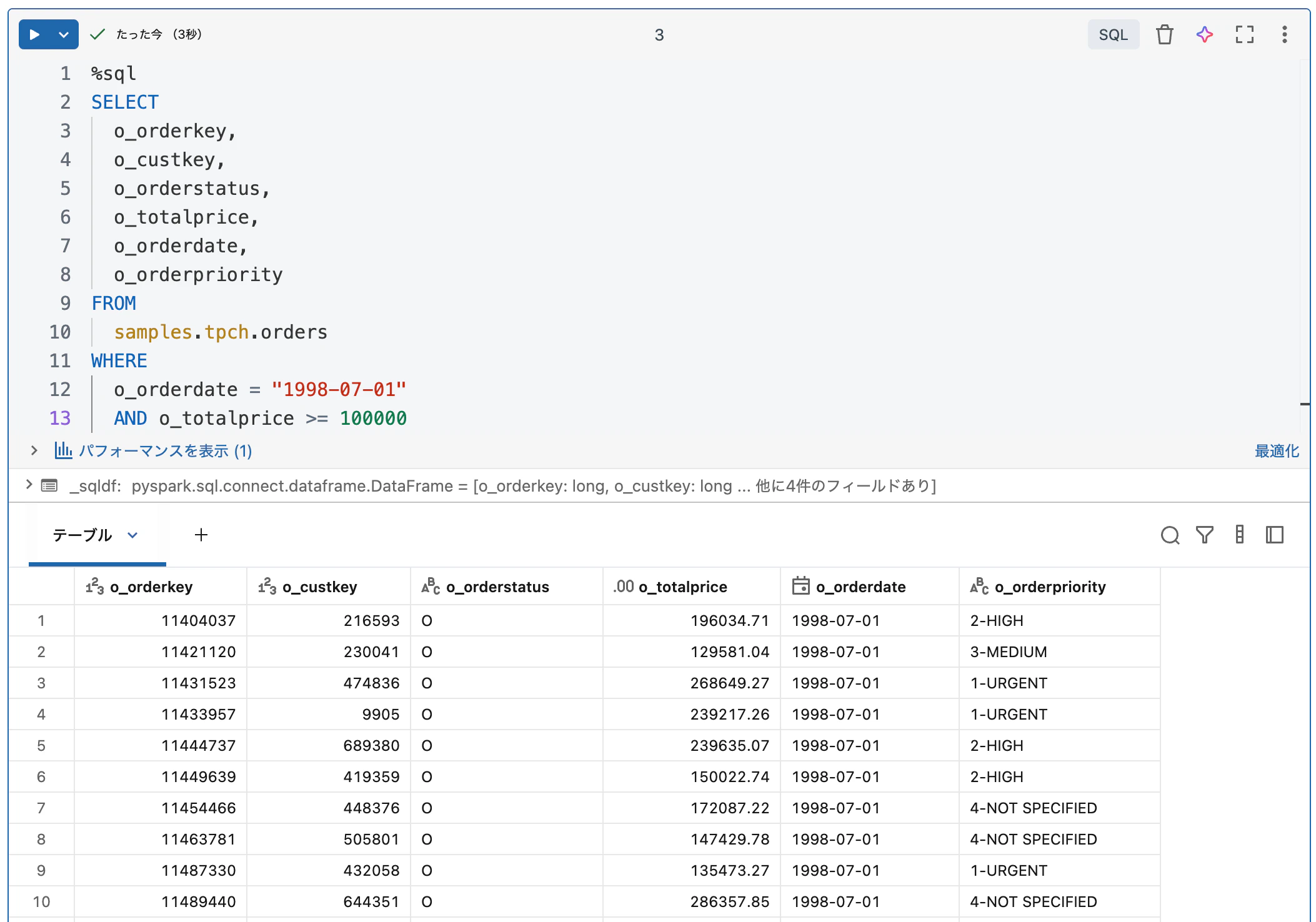
このように、どのような形状のデータが必要なのかという要件に応じてデータを加工することになります。
データの書き込み
上述したように、どこに書き込みを行うのか を意識することが重要です。特に書き込みの際には対象データを上書きしてしまう可能性があるので注意してください。当たり前の話ですが、どんなに仕組みが洗練されたとしても既存データに対して書き込み権限があるのであれば、データの上書きは可能です。
管理者の方向けの話となりますが、誤った操作でデータを上書きしてしまうというのは日常的に起こる事故といえます。このような事故を避けるためにも環境の分離(開発用/本番用)や適切なアクセス権の設定を行うことをご検討ください。なお、Databricksにおけるデフォルトのテーブル形式であるDelta Lakeではテーブルの更新ログが自動で記録されますので、テーブル状態のロールバックは可能です。
テーブルへの書き込み
加工したデータを自分用のカタログ、スキーマ(データベース)配下のテーブルとして保存するのがよくある使い方でしょう。ここでは、自分用のカタログ takaakiyayoi_catalog、スキーマ tpch が作成されており、権限が付与されているものとします。カタログの作成権限があるかどうか、自分が使えるカタログがあるのかについては管理者の方に確認してください。
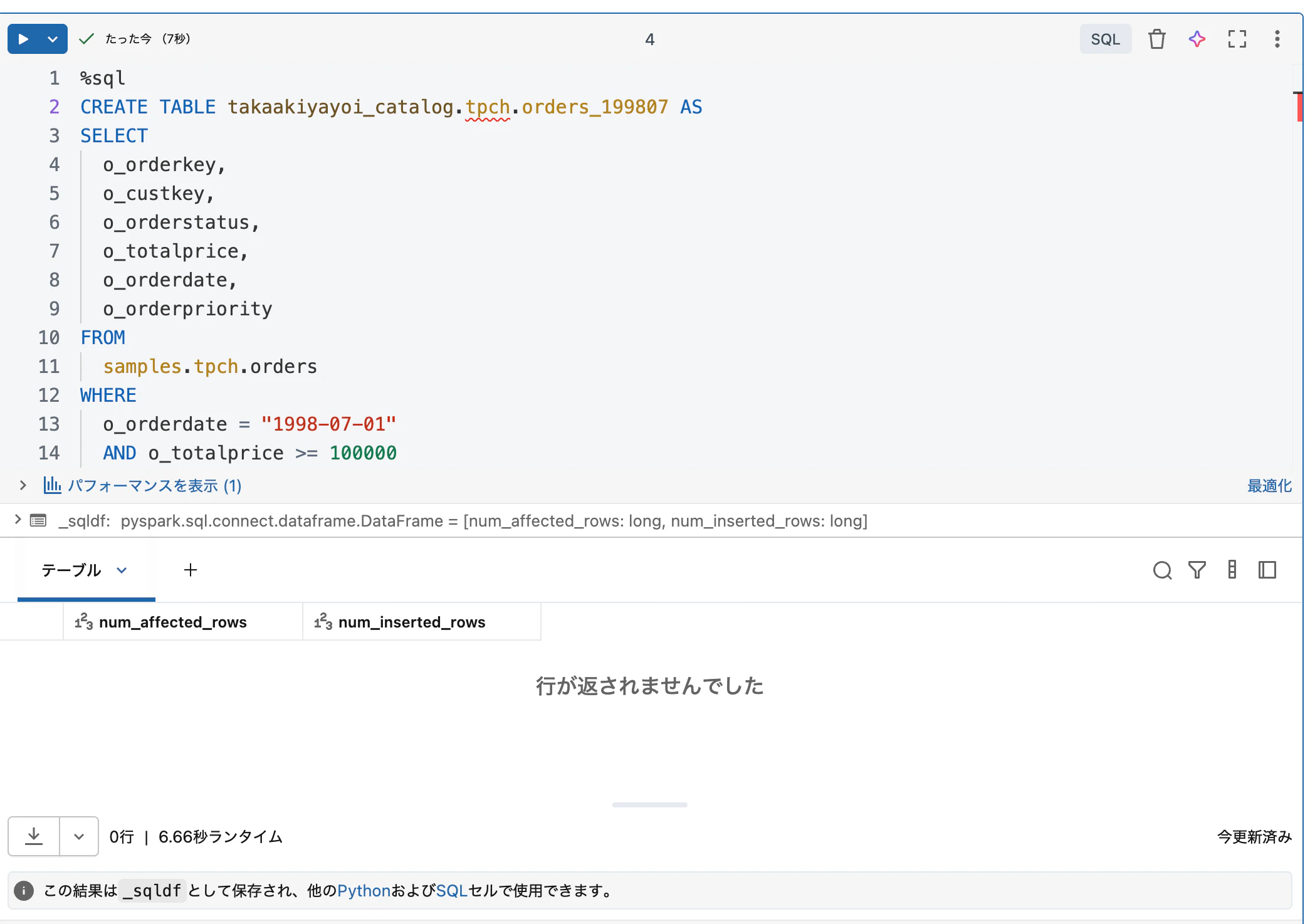
ここがテーブルの書き込み先となります。一旦SQLでやり切るのでいわゆるCTAS(Create Table As Select)構文を使います。作成するテーブル名は上述のカタログとスキーマを使うので takaakiyayoi_catalog.tpch.orders_199807 とします。
%sql
CREATE TABLE takaakiyayoi_catalog.tpch.orders_199807 AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority
FROM
samples.tpch.orders
WHERE
o_orderdate = "1998-07-01"
AND o_totalprice >= 100000
エラーが出なければ問題なくテーブルを書き込めています。
カタログエクスプローラにアクセスすると、作成されたテーブルを確認できます。表示されていない場合には、画面左上の更新ボタンを押します。
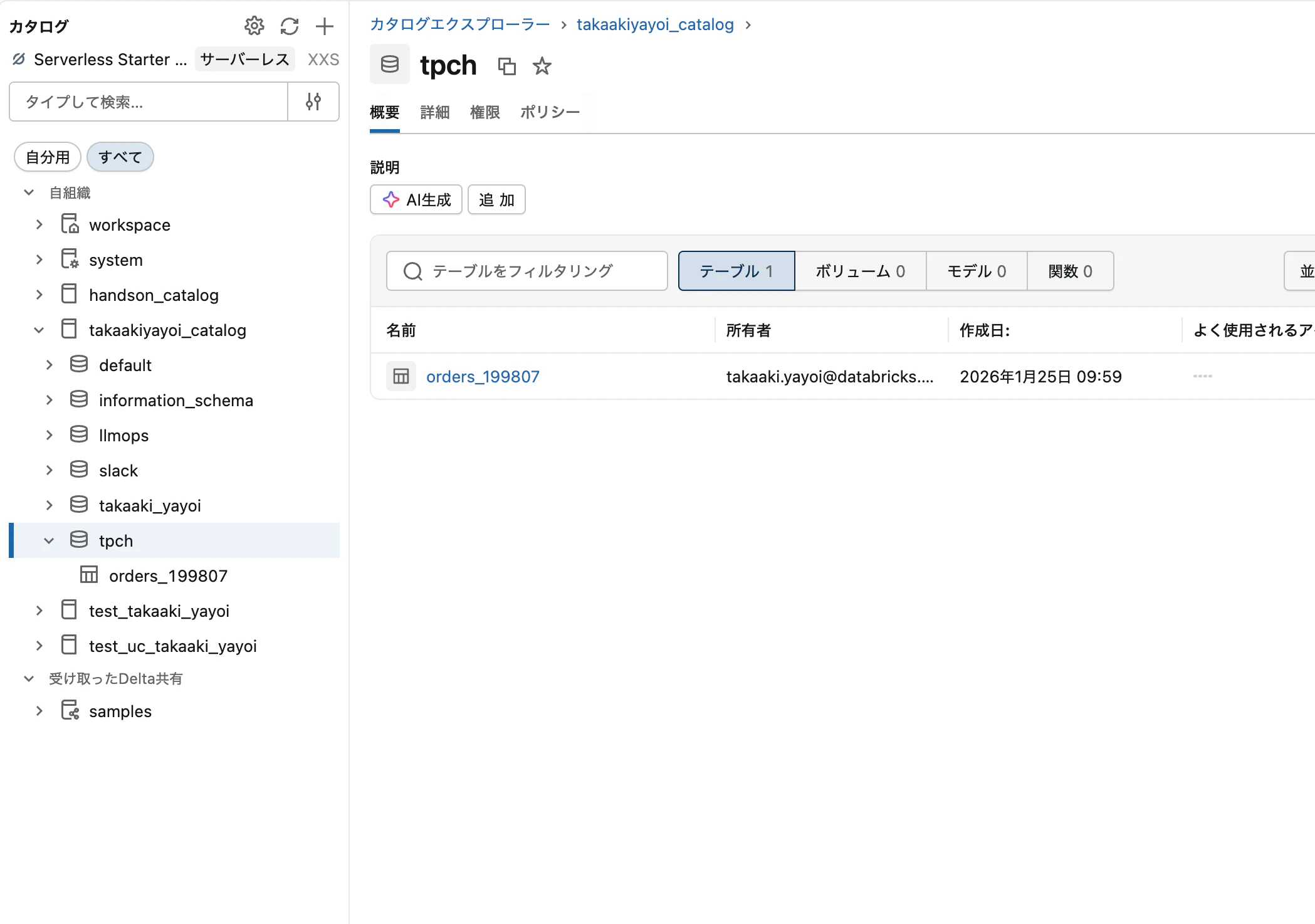
これでデータを永続化することができました。もう一つ重要な観点が 権限 です。デフォルトではテーブルの作成者(あなた)のみがこのテーブルにアクセスできます。このデータを他のユーザーと共有したい場合には、権限を付与することで他のユーザーの方も活用できるようになります。このような機能もデータによるコラボレーションを促進するためのものです。
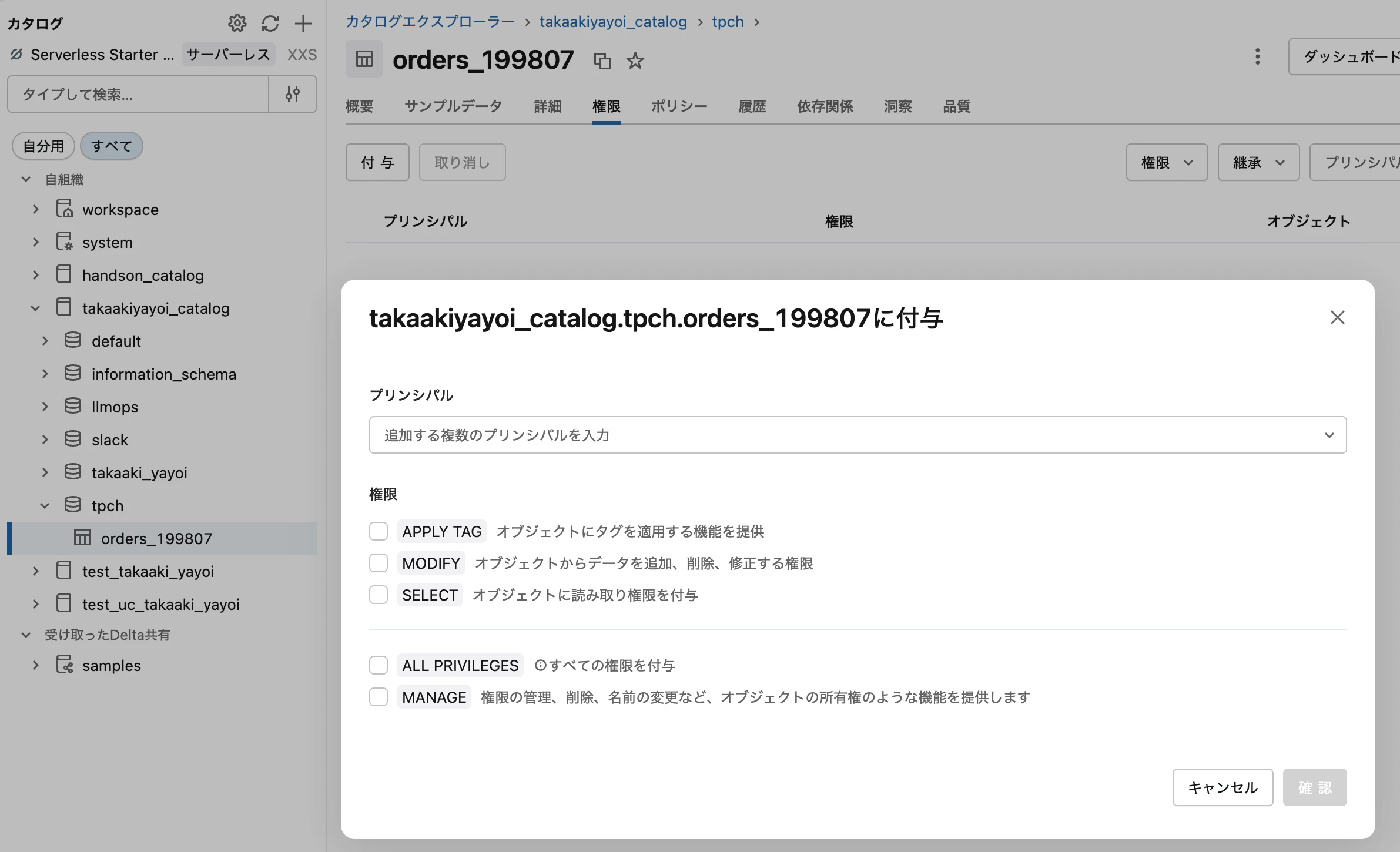
ずっとSQLで処理を記述してきましたが、Pythonでも同様のことは可能です。ここまでSparkの話はしてきていませんでしたが、Databricksの処理の肝になっているのがApache Sparkです。大量データの処理を効率的に行うための分散処理フレームワークです。ここでは詳細に踏み込みませんが、これもざっくりいうとペタバイトであろうがエクサバイトのデータであろうが、マシン台数を増やして並列に高速に処理できる仕組みです。この処理には、上で行ったようなデータの加工や機械学習モデルのトレーニングなどさまざまなものが含まれます。そして、Sparkの長所の一つにさまざまな言語のサポートがあります。上でSQLを実行していましたが、これはSparkによって処理されています。それ以外にもPython、R、Scalaもサポートしています。Pythonを使う際にはSparkに対するPython APIであるPySparkを使います。
プログラムとしてロジックを記述するのであれば、SQLよりもPythonがおすすめとなります。ループや条件分岐をSQLで記述するのは相当難易度高いです。
ただ、「PySparkは敷居が高い」という声も伺います。しかし、pandasやRを使いこなしている方であれば、PySparkは方言の一つと言えるのではないかと個人的には思いますし、パフォーマンス最適化などの話が出てくると細かい設定が必要となりますので、早い段階でPySparkに慣れていただくのが良いかと思います。「PySparkをマスターするぜ」という気概のある方はこのあたりからいかがでしょうか。
あと、SparkでPandas APIを実行する手段もあります。
なお、上のSQLのロジックをPySparkで実装すると以下のようになります。
上のSQLのロジックをPySparkで実装すると以下のようになります。
sdf = spark.table("samples.tpch.orders")
(
sdf.select(
[
"o_orderkey",
"o_custkey",
"o_orderstatus",
"o_totalprice",
"o_orderdate",
"o_orderpriority",
]
)
.filter("o_orderdate = '1998-07-01' AND o_totalprice >= 100000")
.write.saveAsTable("takaakiyayoi_catalog.tpch.orders_199807")
)
このように、データフレームを保存するのであればテーブルとして保存するのがおすすめです。カタログエクスプローラで容易にメタデータを確認できますし、他のユーザーへの共有も楽です。
ボリュームへの書き込み
ファイルとして保存したい場合には、ボリュームを活用ください。Unity Catalogで管理されるファイルシステムのマウントポイントです。ボリュームでもUnity Catalogの名前空間の考え方は踏襲されています。パスは /Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data のように /Volumes/<カタログ>/<スキーマ>/<ボリューム> となります。pandas/PySpark/シェルコマンドなど使うツールに関係なくこれらのファイルにアクセスできます。
以下のようにpandasで読み込めます。
import pandas as pd
covid_pdf = pd.read_csv(
"/Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/newly_confirmed_cases_daily.csv"
)
display(covid_pdf)
ちなみに上の display 関数はDatabricksで使える便利コマンドで、データフレームを表示する際にお使いください。上述の可視化機能も利用できます。
pandasデータフレームをCSVとしてボリュームに保存します。
covid_pdf.to_csv("/Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/pandas_data.csv")
上書きの回避策
Sparkの場合には防御機構があります。例えば、テーブルを再度作成しようとすると以下のようにエラーとなりテーブルは上書きされません。すでにテーブルが存在しているというメッセージです。
TableAlreadyExistsException: [TABLE_OR_VIEW_ALREADY_EXISTS] Cannot create table or view
tpch.orders_199807because it already exists.
このような場合、明示的に 上書きを指示することができます。CREATE OR REPLACE TABLE を使います。テーブルが存在する場合にはデータを洗い替えするコマンドです。
%sql
CREATE OR REPLACE TABLE takaakiyayoi_catalog.tpch.orders_199807 AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority
FROM
samples.tpch.orders
WHERE
o_orderdate = "1998-07-01"
AND o_totalprice >= 100000
PySparkでも同様です。明示的に上書きを指示するには、write の後に mode("overwrite") を指定します。
sdf = spark.table("samples.tpch.orders")
(
sdf.select(
[
"o_orderkey",
"o_custkey",
"o_orderstatus",
"o_totalprice",
"o_orderdate",
"o_orderpriority",
]
)
.filter("o_orderdate = '1998-07-01' AND o_totalprice >= 100000")
.write.mode("overwrite").saveAsTable("takaakiyayoi_catalog.tpch.orders_199807")
)
ですので、通常Sparkを使ってデータを書き込む際に上書きを心配する必要はないのですが、最悪のパターンは 明示的に上書きを指定していることを忘れて上書きしてしまった というものです。これは、上述の どこに書き込みを行うのか に加えて、どのAPIのどの書き込みモードを使っているのか についても注意を払う以外に対策はありません。
2025年〜2026年の新機能・変更点
Databricksは急速に進化しており、2025年から2026年にかけて多くの重要な機能追加・変更がありました。ここでは主要なものを紹介します。
サーバーレスコンピューティングの本格展開
2025年以降、サーバーレスコンピューティングがDatabricksの標準的な計算資源として位置づけられるようになりました。
- Serverless Compute for Notebooks/Workflows: クラスター作成不要で数秒で起動
- 自動アップグレード: 常に最新のDatabricks Runtimeが適用される
- コスト最適化: 使用した分だけの課金
Free Editionではサーバーレスコンピューティングのみ利用可能です。エンタープライズ版では従来型クラスター(Classic compute)も引き続き利用できます。
Databricks Assistantの強化
Databricks Assistantが大幅に強化されました。
- Agent Mode: 複数ステップのタスクを自動で実行、エラーの自動修正
- Edit Mode: 単一のプロンプトで複数セルへの編集を一括適用
- カスタム指示: ユーザーごとの好みや要件を設定可能
MLflow 3とMosaic AI
機械学習・生成AIの開発基盤が大幅に強化されました。
- MLflow 3.0: 生成AI対応、トレーシング、LLMジャッジ機能
- Mosaic AI Agent Framework: エージェント構築・評価の統合フレームワーク
- Mosaic AI Gateway: 複数のAIモデルプロバイダーを統合管理
Lakeflow (旧Delta Live Tables/Workflows)
データパイプライン関連の機能が「Lakeflow」ブランドに統合されました。
- Lakeflow Declarative Pipelines (旧Delta Live Tables)
- Lakeflow Jobs (旧Workflows)
- Lakeflow Connect: 各種データソースへのマネージドコネクタ
まとめ
書き込みのセクションは注意すべきことが多いので量が増えてしまいましたが、以下を注意いただきつつDatabricksを活用いただけると幸いです。
- データの読み書きはテーブルがお勧めです。アクセスが容易で上書きしたとしてもロールバックが簡単です。
- どのテーブル、ファイルを読み込んでいるのかを常に意識ください。
- どのテーブル、ファイルに書き込みを行うのかを常に意識ください。
- どのAPIのどの書き込みモードを使っているのか。明示的に上書きを指定している場合、それは適切なものであるのかをご確認ください。
- サーバーレスコンピューティング のおかげで、すぐに分析を始められます。
- Databricks Assistant を積極的に活用して、学習を加速させましょう。
そして、「これだとJupyter Notebookと大差ないのでは?」と思われた方もいらっしゃるかもしれませんが、これは「はじめてのDatabricks」です。ここでご紹介したのはDatabricksのほんの一部の機能です。
こちらに説明があるように、Databricksは以下のような用途でご活用いただけます。
- データ処理ワークフローのスケジューリングと管理
- ダッシュボードとビジュアライゼーションの生成
- セキュリティー、ガバナンス、高可用性、およびディザスタリカバリーの管理
- データの検出、アノテーション、探索
- 機械学習(ML)のモデリング、追跡、モデルサービング
- 生成AIソリューション
本書ではビジュアライゼーションとガバナンスの一部に触れたに過ぎません。それ以外の機能についても今後紹介していこうと思いますし、これまでに記述した記事はこちらにありますので、ご興味のある方は一覧いただけると幸いです。
Free Editionはサーバーレスのみなので、アイドル時間後に自動停止します。課金の心配はありませんが、1日あたりのクォータ制限には注意してください。
参考資料
公式ドキュメント
- Databricks Free Editionにサインアップ | Microsoft Learn
- Databricks Free Editionの制限事項 | Microsoft Learn
- Databricksとは | Databricks on AWS
- Databricksノートブック入門 | Databricks on AWS
- サーバーレスコンピューティング | Databricks on AWS
- Databricks Assistantとは | Databricks on AWS
- Databricks での探索的データ分析 : ツールとテクニック | Databricks on AWS
- ビジュアライゼーションの種類 | Databricks on AWS
Free Edition関連記事
- Databricks Free Edition
- Databricks Free Editionチュートリアル
- Databricks Free Editionで学ぶDatabricksノートブック
- Databricks Free Editionで学ぶAI/BI Genie
- Databricks Free Editionで学ぶAIエージェント
- Databricks Free Editionで始めるDatabricks Apps
- Databricks Free Editionで始めるApache Spark
- 【2025年版】Google Colab/Jupyter経験者のためのDatabricks学習ロードマップ
書籍
Databricks Free Edition