Databricksにおけるデータの取り込み、ETL、ジョブのオーケストレーションをカバーします。
典型的なデータパイプライン
Databricksに限らず、データ分析のためのデータを準備するためには生データからスタートし、クレンジングを経て、BIや機械学習に用いるデータを生成するパイプラインを構築するのが一般的です。これはメダリオンアーキテクチャと呼ばれるものです。
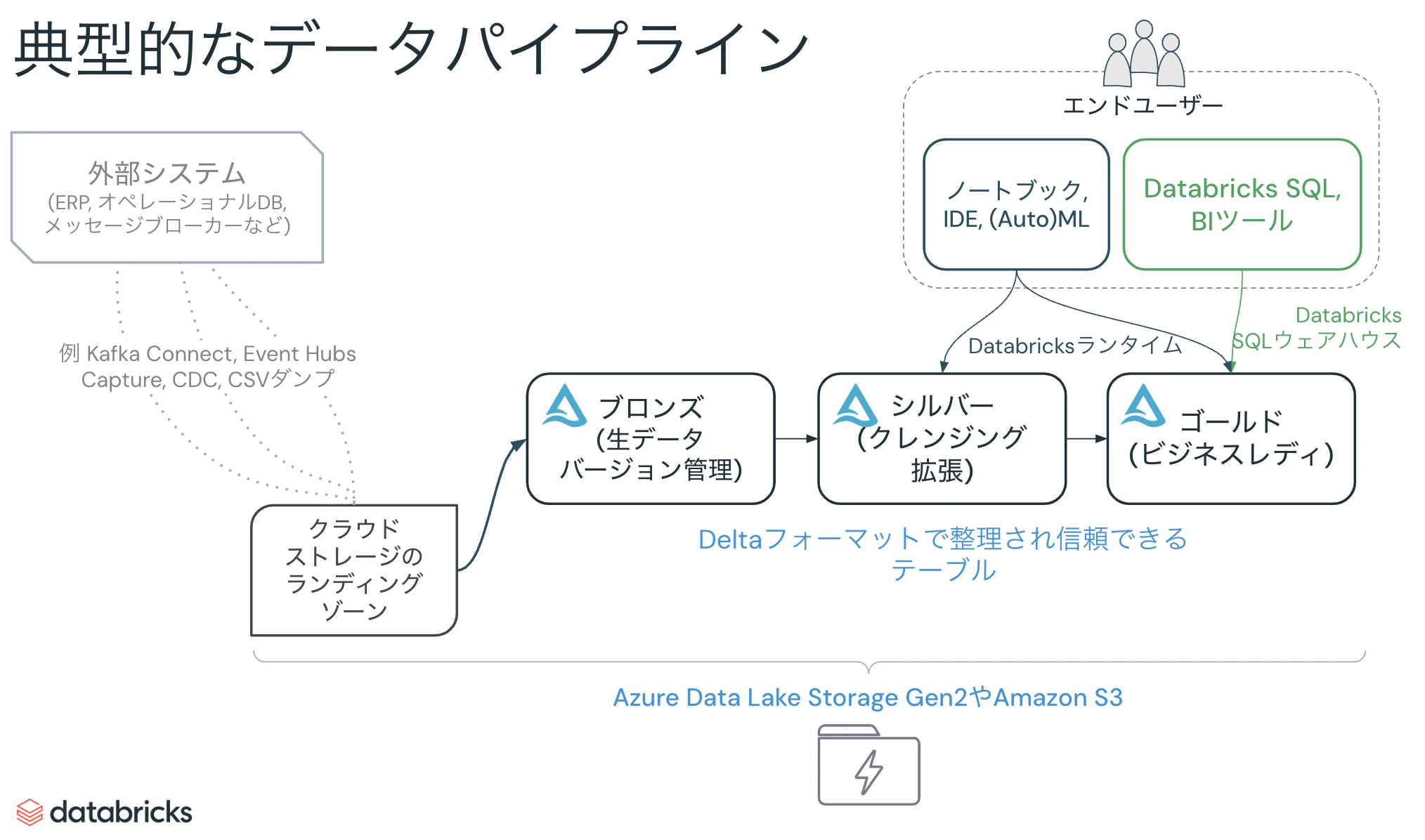
しかし、生データを準備する時点からいくつかの課題に遭遇することになります。

ランディングゾーンからブロンズテーブルを準備する際の課題
- 間違っていくつかのファイルをスキップしてしまう → データの欠損
- 間違って以前のファイルを取り込んでしまう → 重複し、エラーを含むBIやレポートを作り出すことになってしまう
- DIYのファイル追跡 / 一覧はスケールせず、コスト効率が悪い
- スキーマの変更 / 問題 → ジョブの失敗
- スキーマの変更 / 問題 → ファイルの損失、破損 (有害!)

Auto Loaderによるデータ取り込み
DatabricksのAuto Loaderを用いることで、スケーラブルなexactly-onceのデータ取り込みを実現し、上記の課題を解決します。
- 新規データファイルがクラウドストレージに到着するとインクリメンタルかつ効率的に処理します。
- ファイル通知モードによってイベント駆動の取り込みを実現(あなたの代わりに自動でEvent Grid / Amazon SNS + Azure Queue Storage / Amazon SQSをセットアップします)
- 到着ファイルのスキーマを自動で推定、あるいはスキーマヒントで既知の情報を提示
- 自動のスキーマ進化
- レスキューデータ列 - 決してデータを失いません

Python、SQLで利用することができます。PySparkの場合、formatでcloudFilesを指定します。
df = spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://…" or "s3://")
.<apply your transformations>
.writeStream
.option("checkpointLocation","/chk/path")
.start("/out/path")
大量のデータが流入する場合にも、複数のジョブを起動することで柔軟に対応することができます。

Delta Live Tablesによるデータパイプライン開発
データパイプラインの開発、運用においては様々な課題があり、それらを解決するために上述のAuto Loaderや、ここで説明するDelta Live Tables(DLT)が提供されています。

Delta Live Tablesでは、どのようにデータを処理するのかを記述するのではなく、期待するデータを宣言することで、何のデータが必要なのかにフォーカスすることができます。また、エラーハンドリング、自動テスト、オートスケーリングなどの機能を提供しているので、データエンジニアはデータパイプラインのロジック開発に注力することができます。

チェンジデータキャプチャ(CDC)もサポートしています。
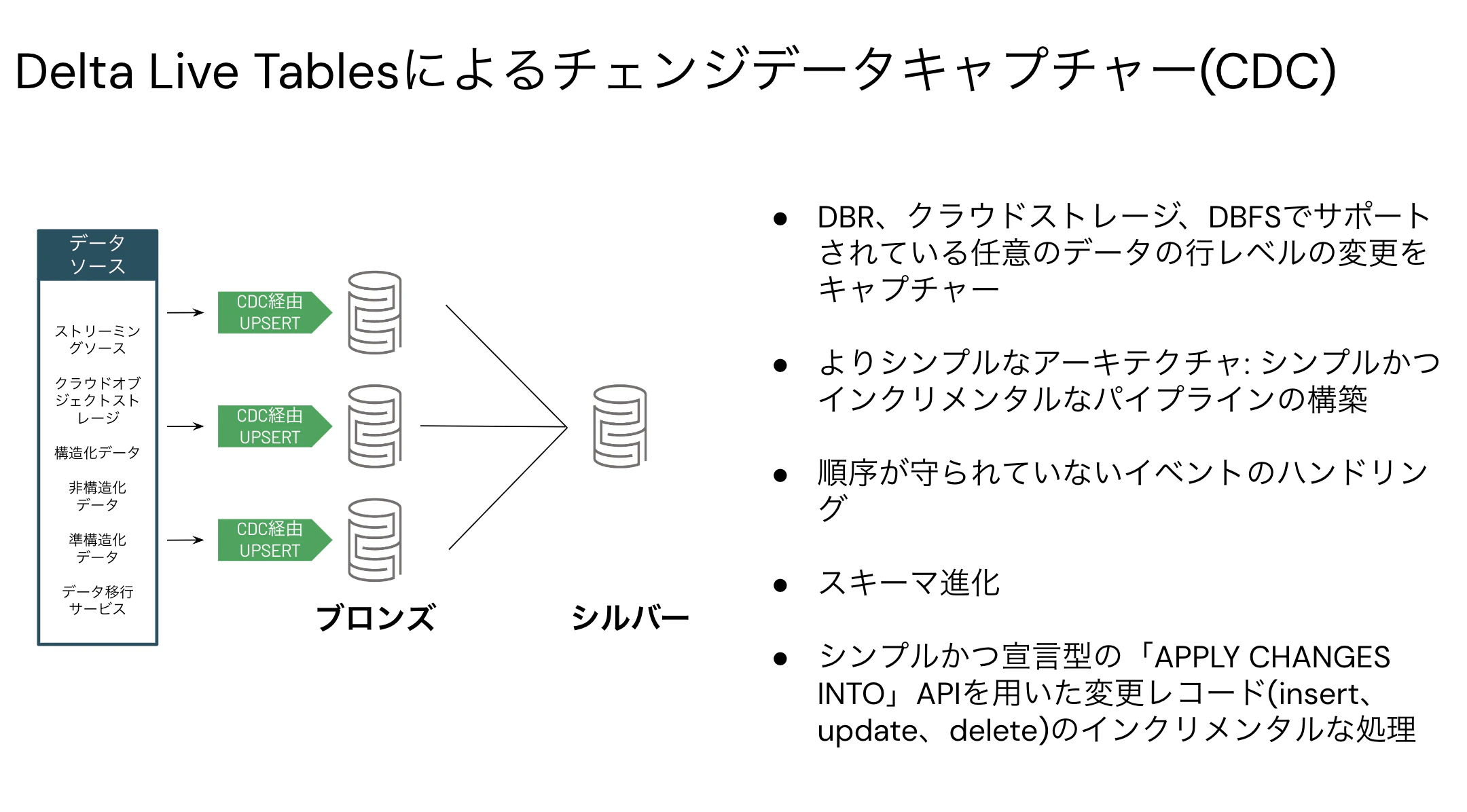
データに対する期待(エクスペクテーション)を定義することで、自動テストを実装することができます。
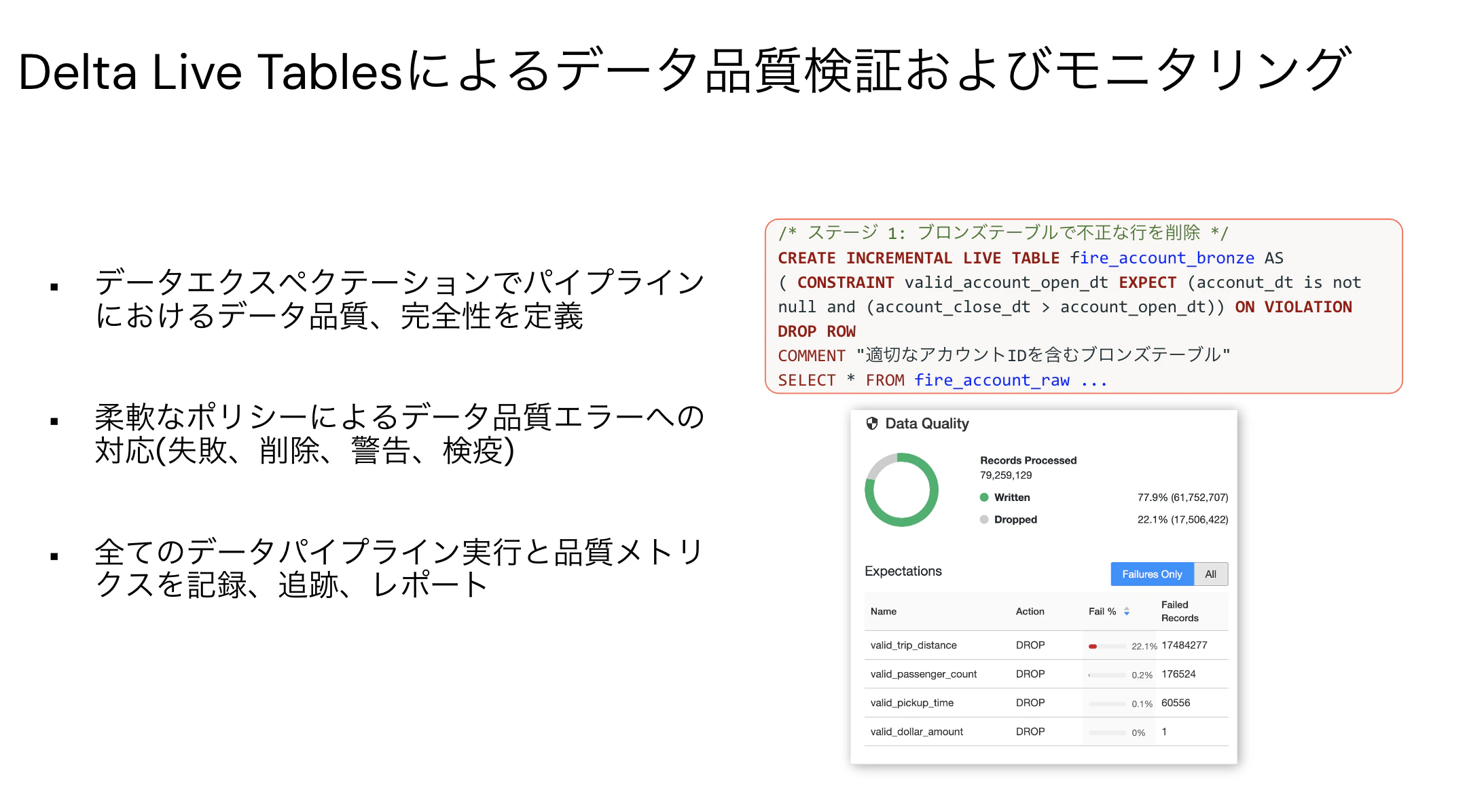
パイプラインのイベントログも自動で記録されるので、容易にパイプラインの健康状態を監視するダッシュボードを構築することも可能です。

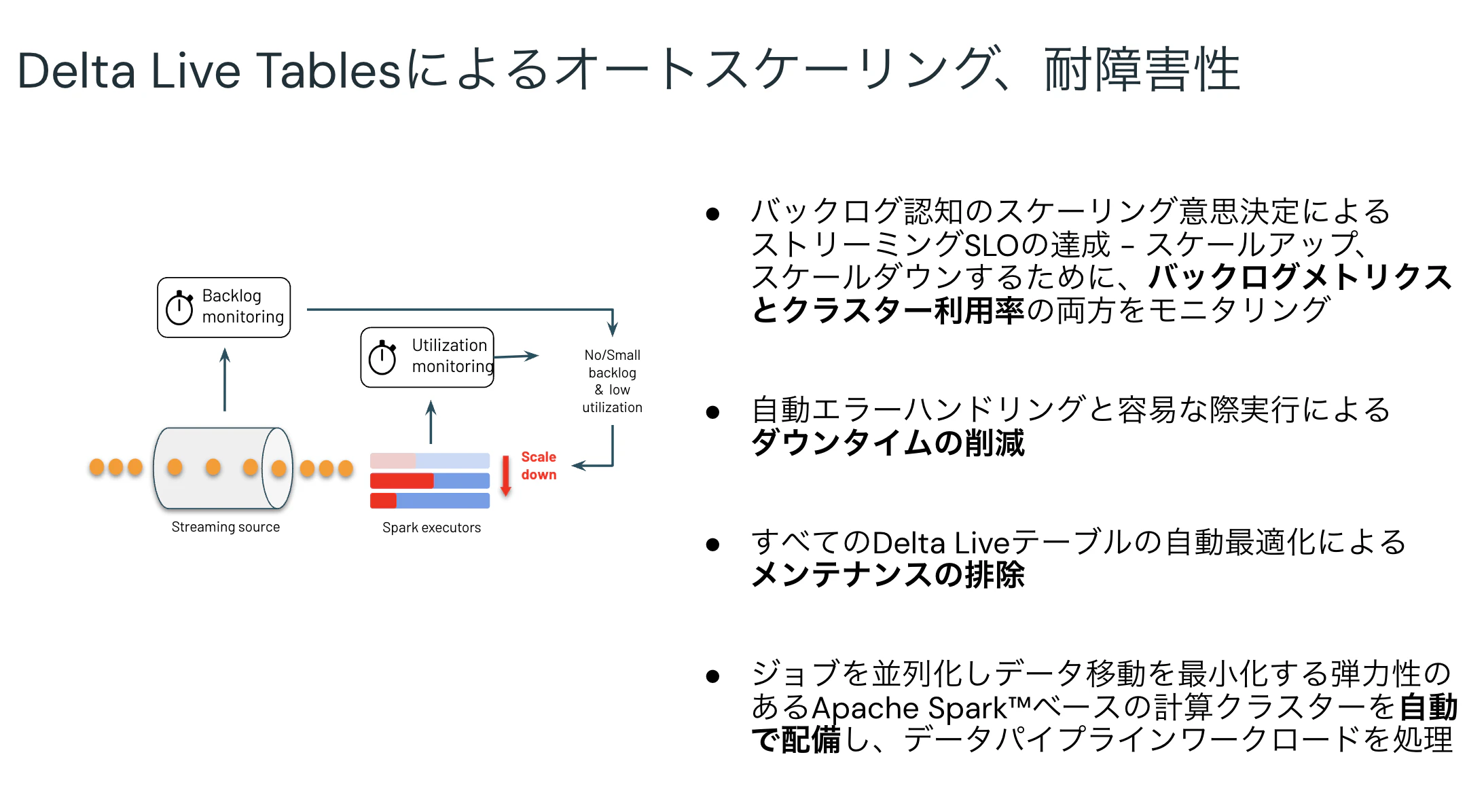
パイプラインに流入するデータが増加したとしても、オートスケーリングでリソースを確保し、時間内に処理を終わらせるようにします。
Databricksワークフローによるオーケストレーション
モダンなデータエンジニアリングにはモダンなデータオーケストレーションが必要です。
しかし、そのためには複数のユースケースに対する複雑なデータフローを効率的に構築、運用できる必要があります。

すでに、多くのお客様がモダンなデータオーケストレーションでコスト削減などのメリットを享受しています。

しかし、モダンなデータオーケストレーションのためには様々なツールの組み合わせが必要となり、苦戦しているお客様も多数存在しています。

Databricksにおいても、複数のオーケストレータを組み合わせることは可能です。
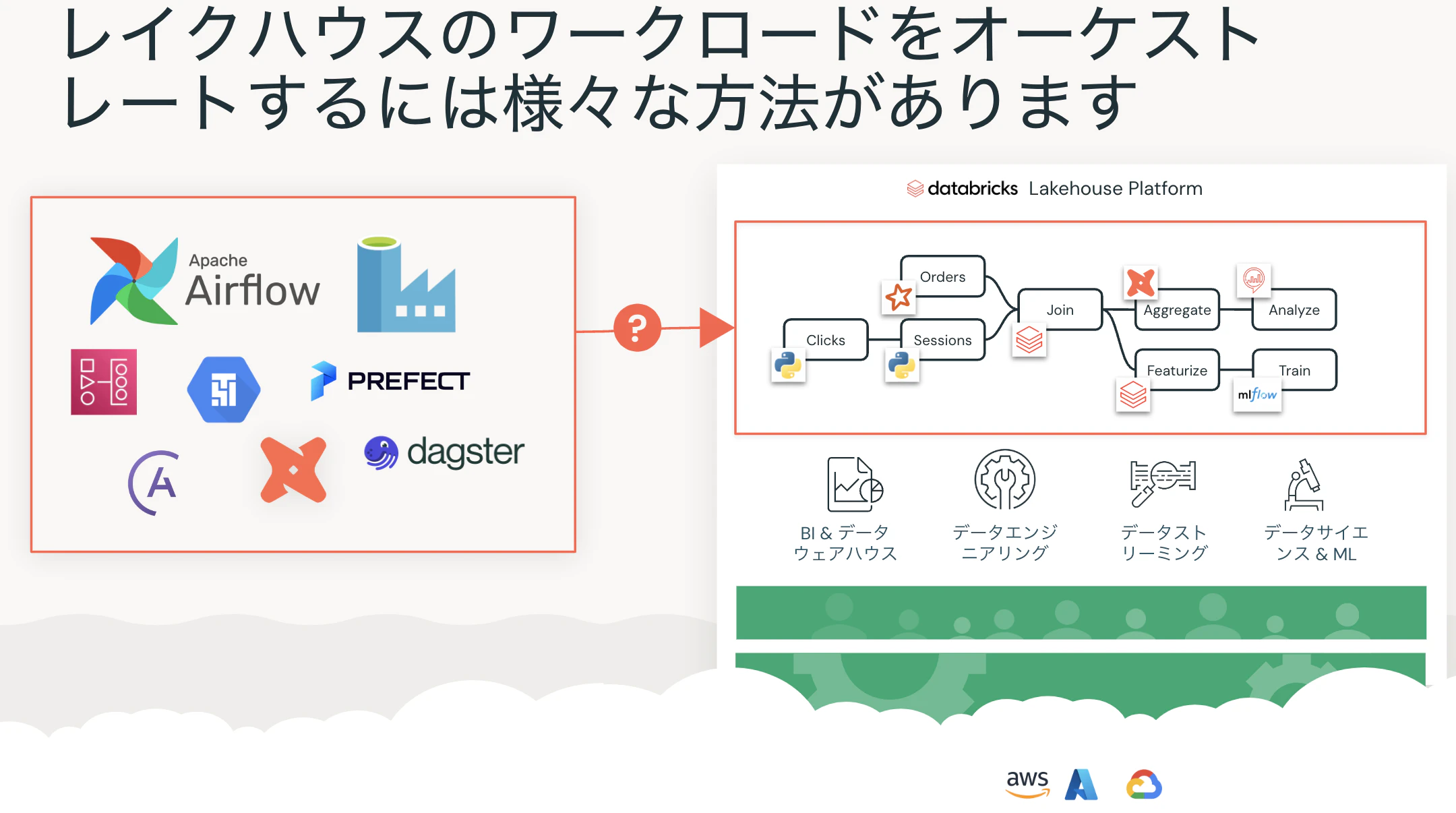
しかし、これは様々な課題を引き起こします。
- 多くの実践者には利用が難しい -> データチームの生産性の悪化
- 問題が発生した際の根本原因の理解が困難 -> 悪いデータが後段のアプリケーションの価値を損なう
- 管理と維持には複雑なアーキテクチャ -> 所有コストの増加、信頼性の低下
そして、これらのツールはDatabricksデータインテリジェンスプラットフォームと統合されていません。

そこで、我々はDatabricksワークフローを提供します。データインテリジェンスプラットフォームにおけるデータ、分析、AIのための統合オーケストレーションを実現します。

Databricksワークフローは以下のようなメリットをもたらします。
- シンプルな作成手順 -> すべてのデータ実践者が活用
- アクション可能な洞察 -> リアルタイムの監視
- 立証された信頼性 -> プロダクション向け

すべてのデータ実践者向けのシンプルな作成手順
Databricksでの数クリック、あるいはお好きなIDEに接続することで、洗練されたワークフローを構築できます。
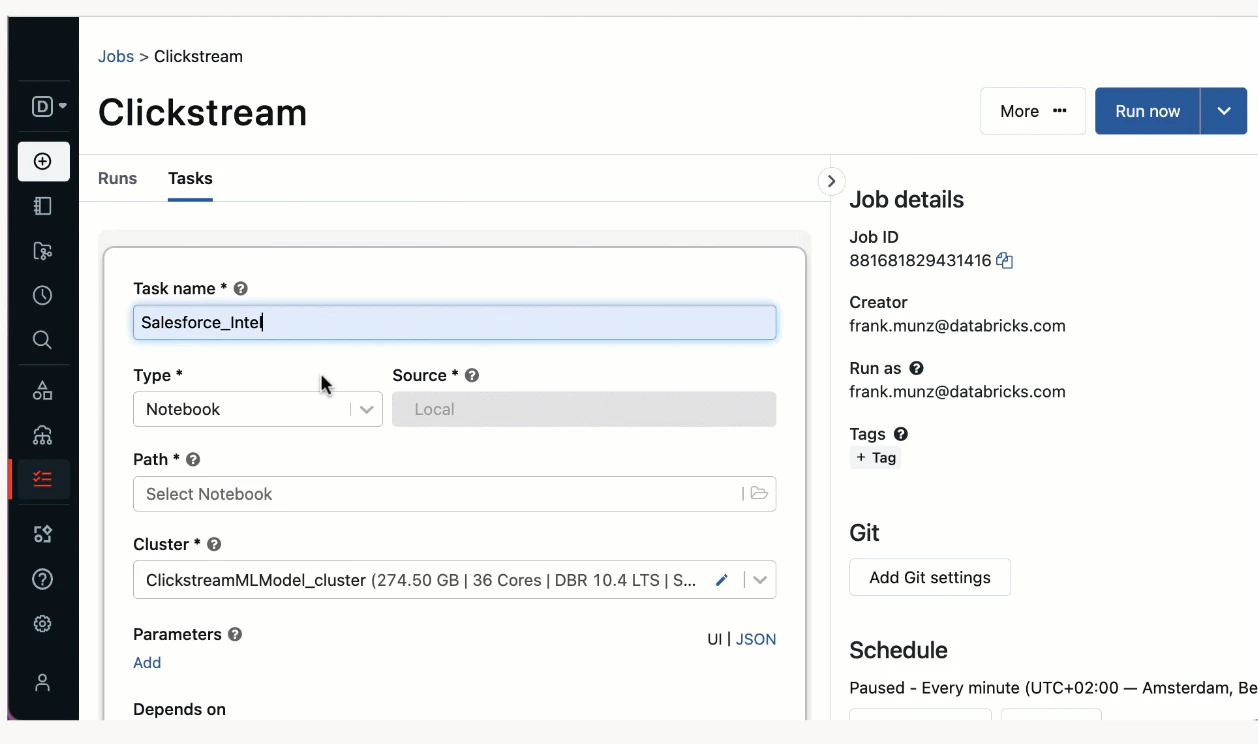
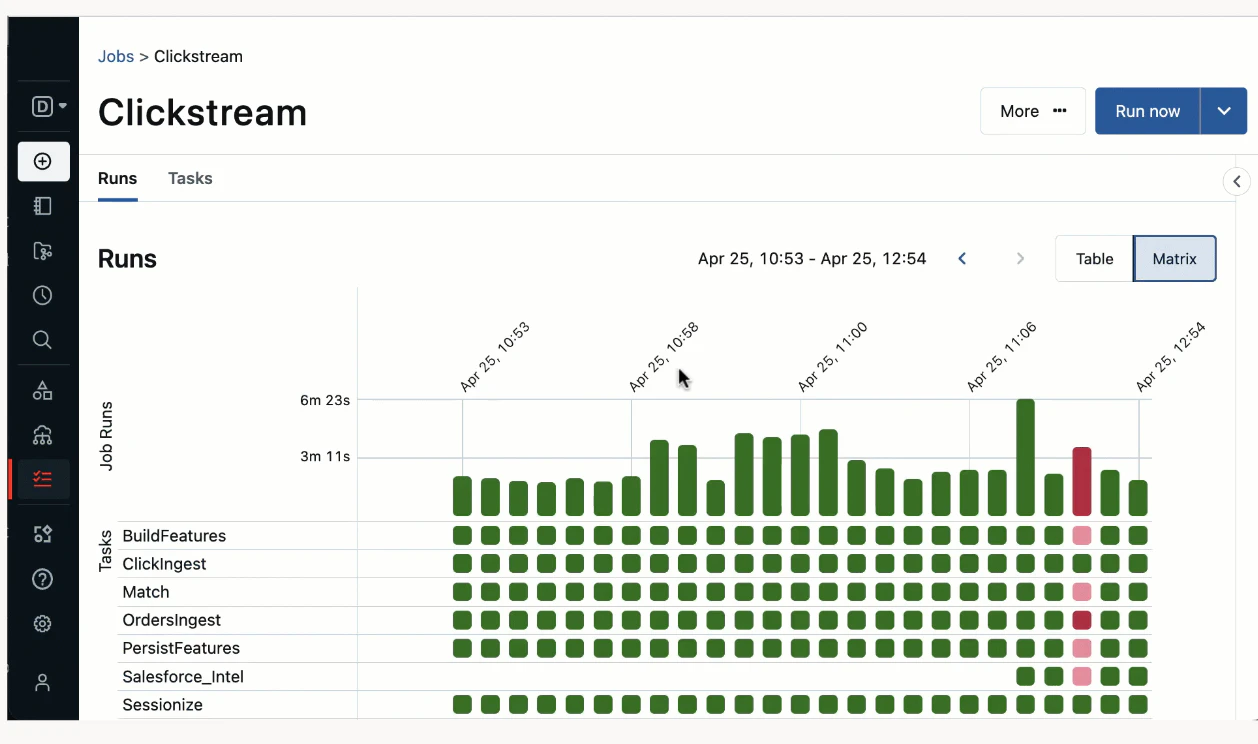


リアルタイム監視によるアクション可能な洞察
シンプルかつ直感的なモニタリングUIによって、すべてのワークフロー実行に対するリアルタイムメトリクスと詳細分析を提供します。

どのタスクがなぜ失敗したのかを理解するためにドリルダウンすることで、あなたのお客様にインパクトが出る前のトラブルシュートを可能とします。

プロダクションワークロードで立証された信頼性
数百万のプロダクションワークロードを実行する数千のお客様からの信頼を得ています。

まとめ
- Auto Loaderによってデータ取り込みを堅牢かつスケーラブルに
- Delta Live Tablesはエンドツーエンドでデータパイプラインを管理し、可視性を提供
- 基盤としてのDelta Lakeが、データのバージョン管理、信頼性、パフォーマンスを充当
- Databricksワークフローがすべてをオーケストレーション