年末年始でこの辺りの記事を読んでいました。
一応、自分の専門はデータエンジニアなのですが、それに至るパスというのをあまり考えたことがありませんでした。キャリアパスという観点では、一つ目の記事が非常に示唆に富んでいたと思います。こちらの記事ではビジネスアナリスト(データアナリスト/BIエンジニア)からデータエンジニアにロール変更を行う際の実践的なステップが紹介されています。
そこで、こちらの記事でDatabricksを活用しているデータアナリストがデータエンジニアに転換するにはどういった取り組みが必要なのかをウォークスルーします。
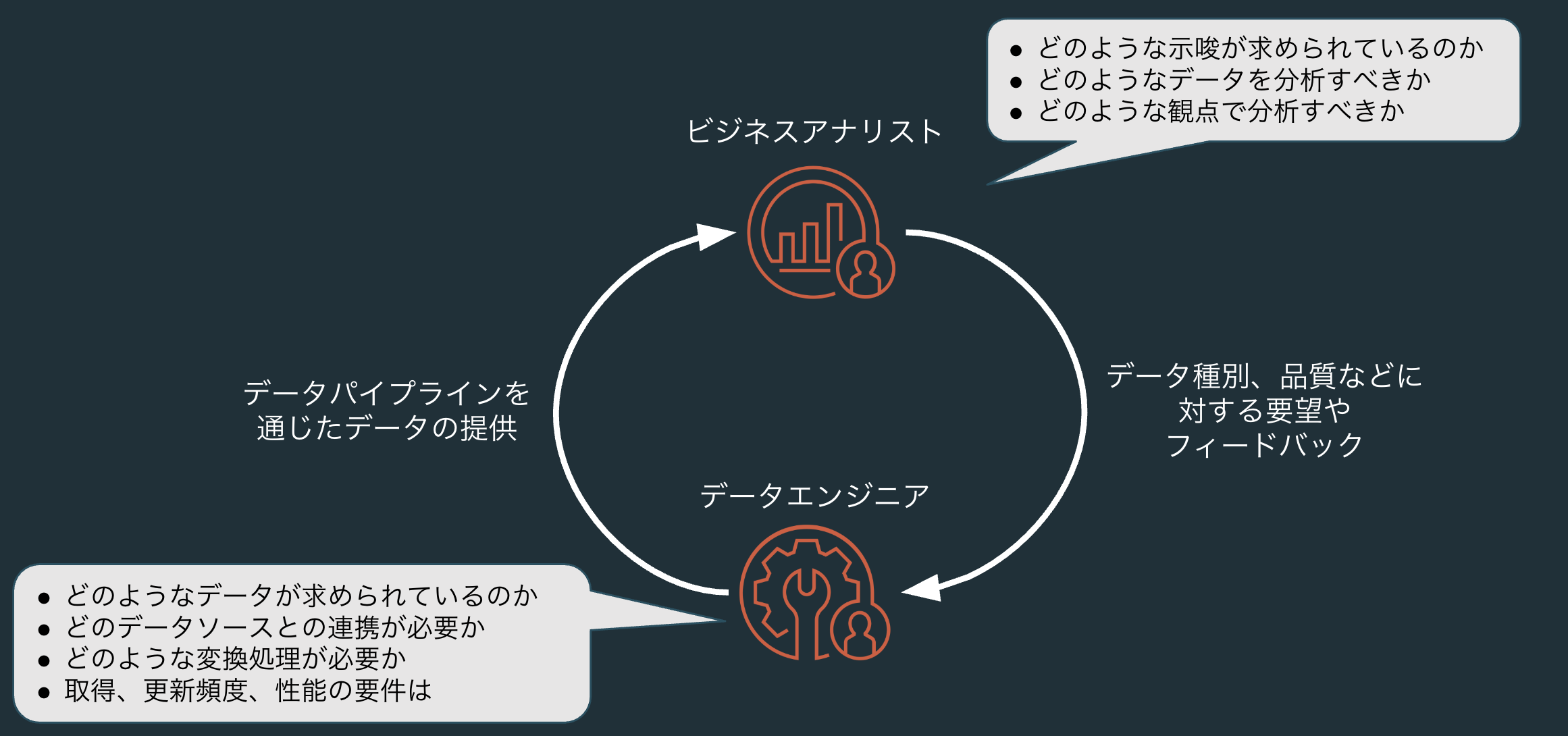
ビジネスアナリストとデータエンジニア
こちらの記事でも触れられていますが、改めて書き出してみます。

ビジネスアナリスト
- 分析データや機械学習モデルのアウトプットからビジネス示唆を抽出します。その際には、BIツール(可視化やダッシュボード、レポート)を駆使して、ステークホルダーとコミュニケーションします。
- つまり、分析対象データ自体は別のペルソナであるデータエンジニアに準備してもらうことがほとんどです。
- 関心事項: 分析に求められる観点、利用可能な分析データやBIツール
- データエンジニアとの関係: 分析に必要なデータの種類、品質、更新頻度などに関する要望やフィードバックをデータエンジニアにインプットします。
データエンジニア
- データ分析に至るデータパイプラインを構築し、質の高いデータを提供します。
- データエンジニアはビジネスアナリストやデータサイエンティストの要請に基づいてデータパイプラインを設計、実装し、運用に責任を持ちます。
- 関心事項: データの種類、品質、更新頻度、データ処理に対する要件、データパイプラインの安定稼働
- ビジネスアナリストとの関係: ビジネスアナリストが分析に必要とするデータの種類、品質、更新頻度を満足するデータパイプラインを設計、実装、運用することで、彼らのニーズに応えます。
データサイエンティストは今回の文脈から外れるので割愛します。ビジネスアナリストとデータエンジニアとでは関心事項が異なり、連携することでビジネス提供価値を高めることができます。
DatabricksにおけるBI
Databricksネイティブで活用できるBI機能はDatabricks AI/BIです。PowerBIやTableauと連携することも可能ですが、ここではDatabricks AI/BIを活用したBIをウォークスルーします。マニュアルはこちらです。
DatabricksにおけるBIに関連する機能を以下の赤枠で示します。
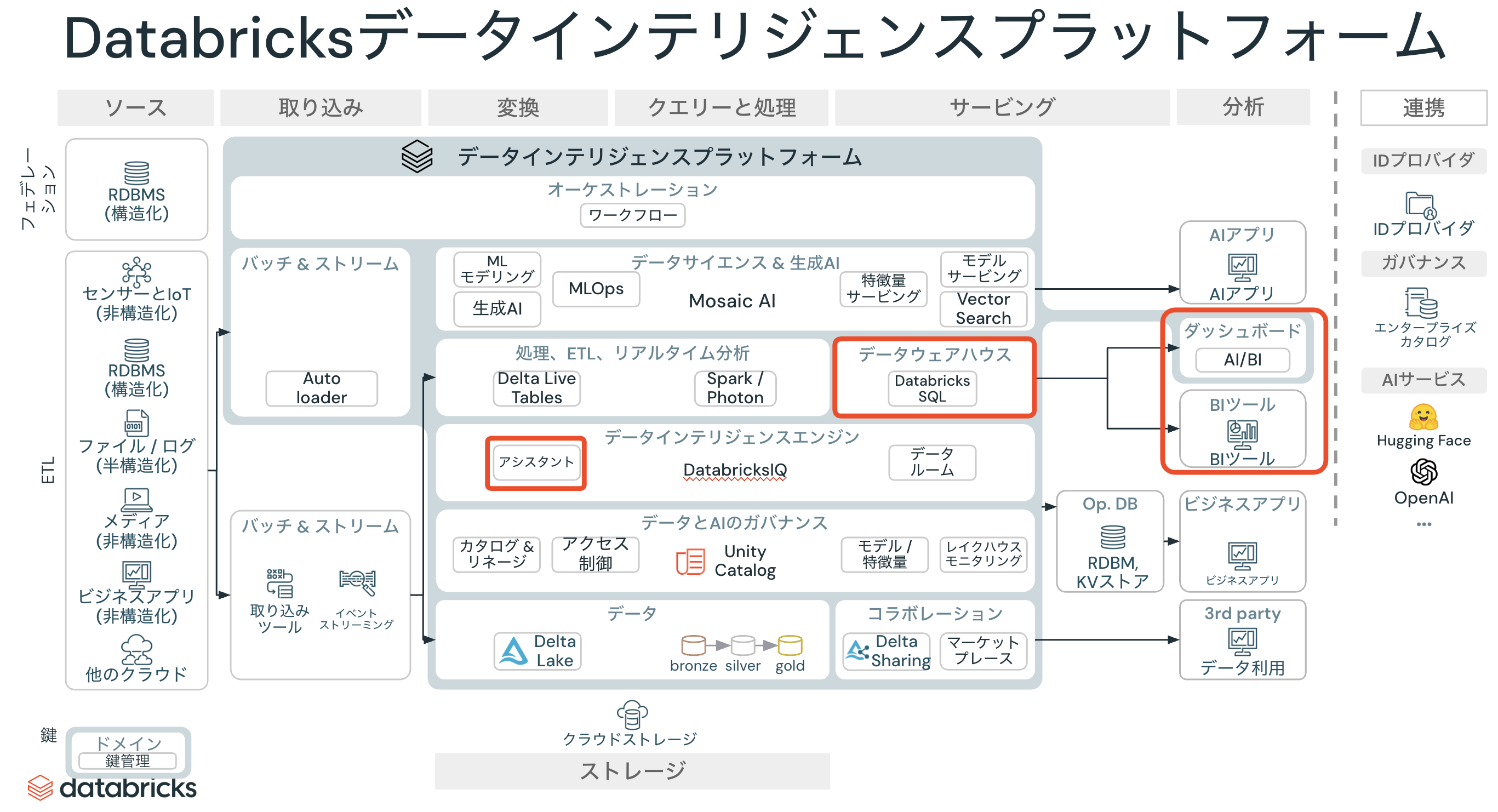
Databricks AI/BIはダッシュボードとGenieから構成されており、これら二つの機能は補完関係にあります。
- ダッシュボード: 生成AIを活用することでローコード、ノーコードでダッシュボードを作成することができます。データの概観を把握する助けとなります。
- Genie: データをベースとした生成AIとの会話を通じて、データへの理解を深めることができます。
このように、BIの文脈に生成AIを持ち込むことで、これまでにないBI体験を提供しているのがAI/BIとなります。AI/BI誕生の背景に関してはこちらをご覧ください。
ここでは、Databricksワークスペースに最初から組み込まれているサンプルデータを用いて、以下のステップでBIをウォークスルーします。
- データの特定
- (分析目的に基づいた)分析観点の検討
- クエリーの作成
- ダッシュボードの作成
- ダッシュボードの公開
データの特定
こちらで説明されているように、Databricksではテーブルやファイルは3レベルの名前空間カタログ.スキーマ(データベース).テーブルで管理されます。1つのカタログの中には複数のスキーマが存在し、1つのスキーマの中には複数のテーブルやモデル、ファイルが格納されます。

Databricksでデータ(テーブルやファイル)にアクセスする最も簡単な方法は、カタログエクスプローラを用いることです。サイドメニューのカタログをクリックすることで、カタログエクスプローラにアクセスすることができます。

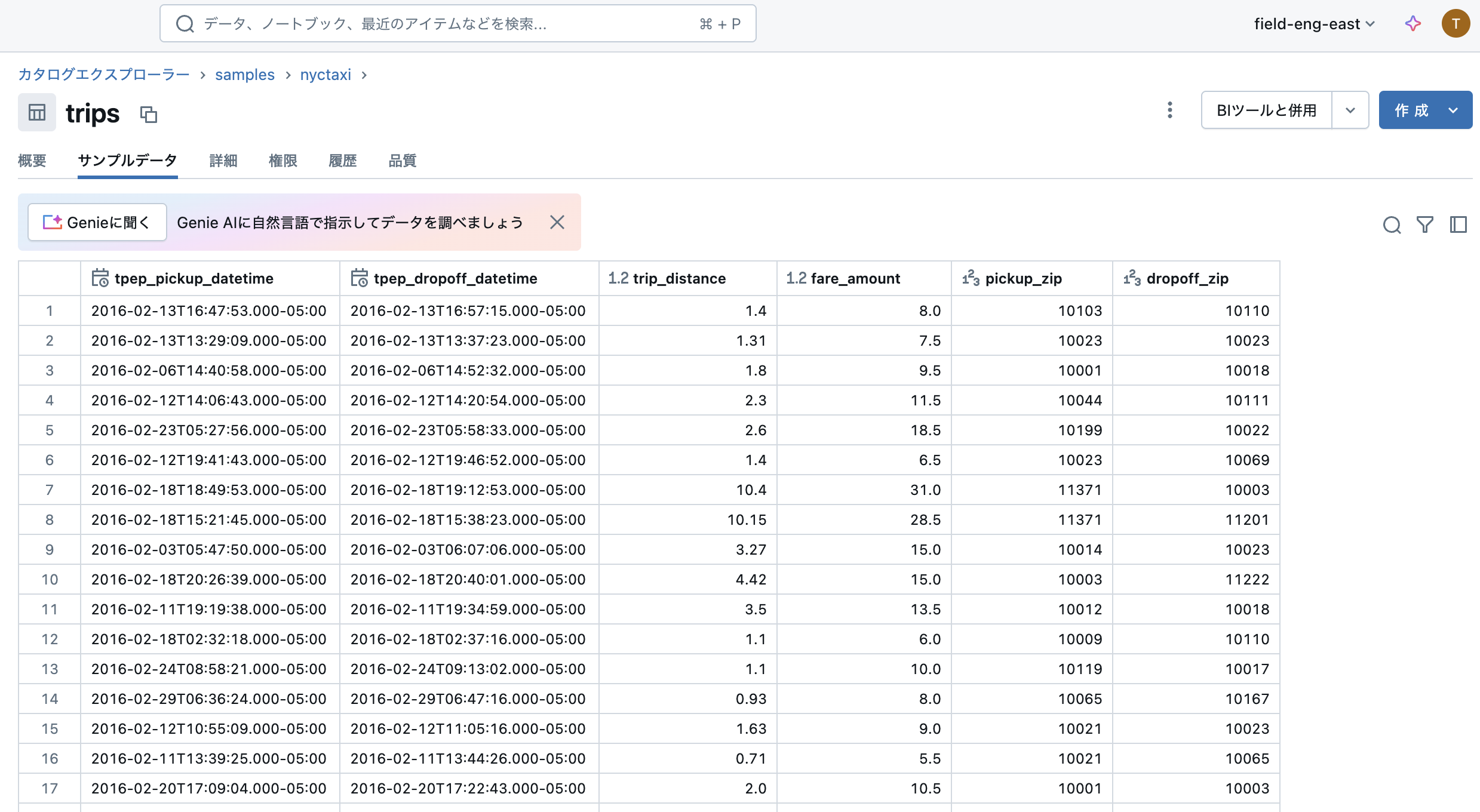
ここでは、共有の下にあるsamplesカタログ配下のnytaxiスキーマにあるtripsテーブルを使用します。これはニューヨークにおけるタクシーの乗降記録のデータです。

BIであろうとデータエンジニアリングであろうと、カタログエクスプローラは頻繁にアクセスすることになりますので、データの検出やデータベース オブジェクトを探索するを参考にしてカタログエクスプローラのUIに慣れておきましょう。
サンプルデータタブをクリックすると、テーブルの中身を確認することができます。この時点で、データのイメージを掴むことができます。
(分析目的に基づいた)分析観点の検討
今回はウォークスルーなので、以下のような観点で分析を行います。もちろん、ご自身の想像力を発揮して好きな観点で分析しても構いません。
- 移動距離(
trip_distance)と料金(fare_amount)の相関関係 - 乗車時刻(
tpep_pickup_datetime)のトレンド
クエリーの作成
上で定めた分析観点に基づいてデータを取得、集計するためのクエリーを作成します。クエリーを作成するためには、SQLの基本的な知識が必要となります。データエンジニアリングにおいても、SQLは非常に多くの場面で活用することになりますので、データエンジニアに転換する際にはSQLの学習を進めることを強くお勧めします。BIの場合、SELECT文による参照系のクエリーがほとんどですが、データエンジニアリングではINSERT、UPDATE、DELETEのような更新系クエリー、CREATE TABLE、DROP TABLEのような定義系クエリーを駆使することになります。
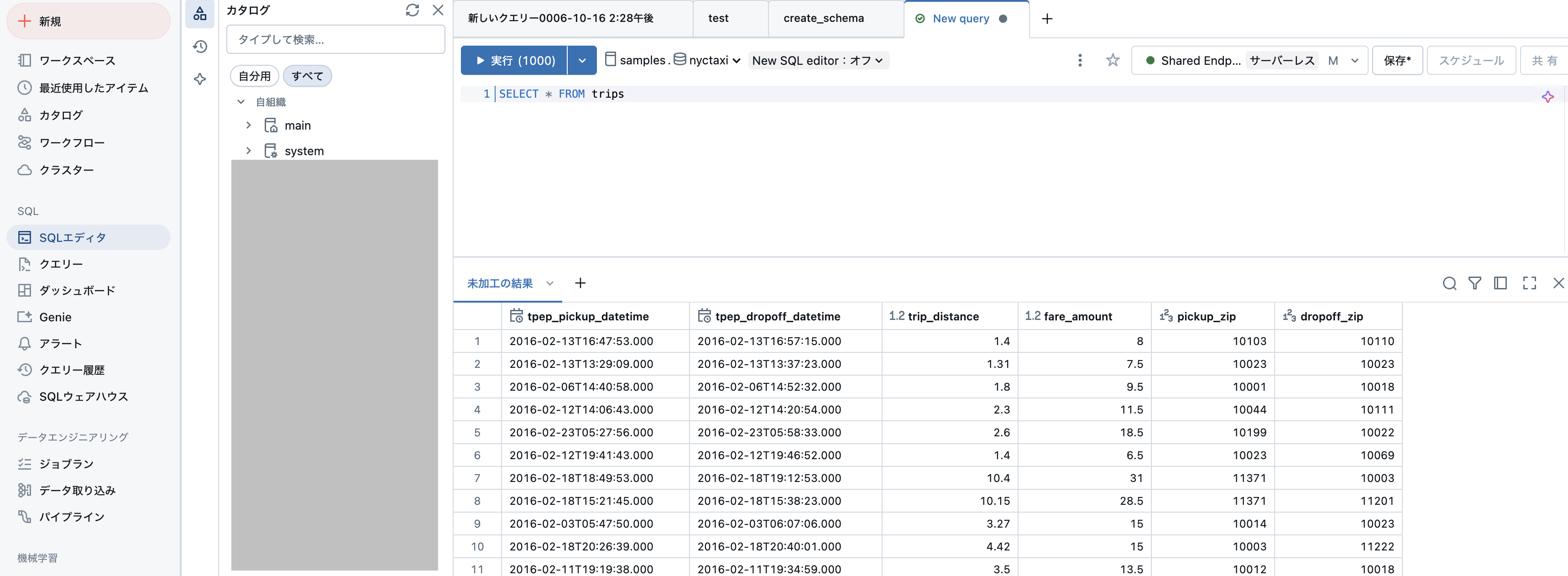
tripsテーブルが表示されている状態で、画面右上の作成 > クエリーボタンをクリックします。
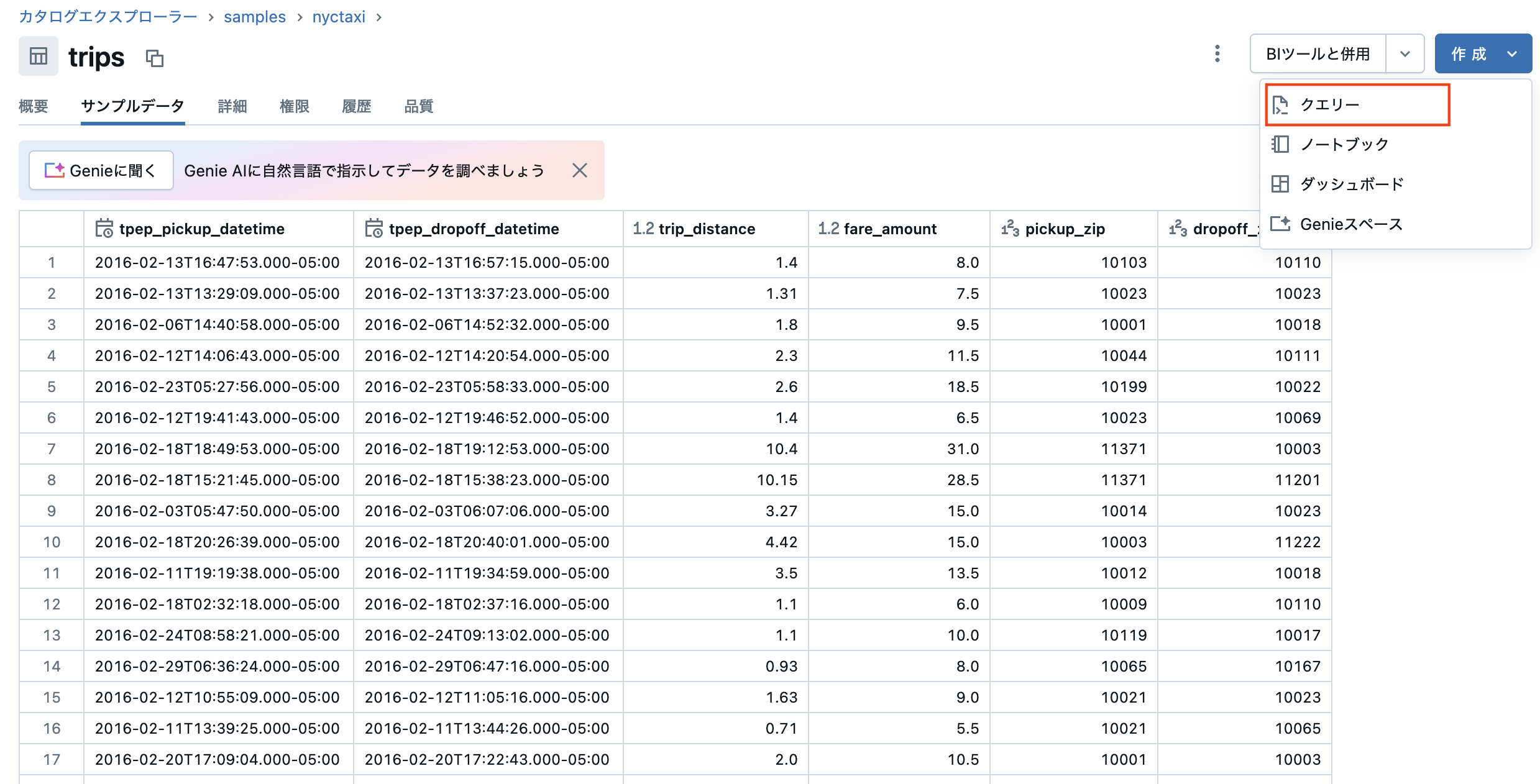
すると、SQLエディタに遷移します。ここで、SQLを用いたクエリーを作成、実行することができます。

計算資源であるウェアハウスを選択し、エディタにSQLを記述し、実行ボタンを押すことで実行結果を表示させるという流れになります。表示されているSQLクエリーSELECT * FROM tripsを実行することで、テーブルの中身が表示されます。 BI、データエンジニアリングの両方において、SQLエディタも頻繁に使用することになるので、こちらを参考にUIに慣れ親しむようにしましょう。
分析観点に即したクエリーを実行し、その結果を可視化することでダッシュボードの部品(ウィジェット)を作成することができます。これらのウィジェットを組み合わせることでダッシュボードを作成することができます。
移動距離(trip_distance)と料金(fare_amount)の相関関係
この観点では、二つの列から散布図を作成することで可視化できます。未加工の結果の右にある + > 可視化をクリックすることで可視化を行うことができます。可視化のダイアログが表示されます。

以下の設定を行います。
- Visualization type: Scatter(散布図)
- X column: trip_distance
- Y columns: fare_amount

設定を行うとプレビューが表示されるので、いろいろな設定を試してみてください。満足できるものが得られたら、右下の保存をクリックします。

乗車時刻(tpep_pickup_datetime)のトレンド
同じように、+ > 可視化をクリックして可視化を追加します。
以下の設定を行います。
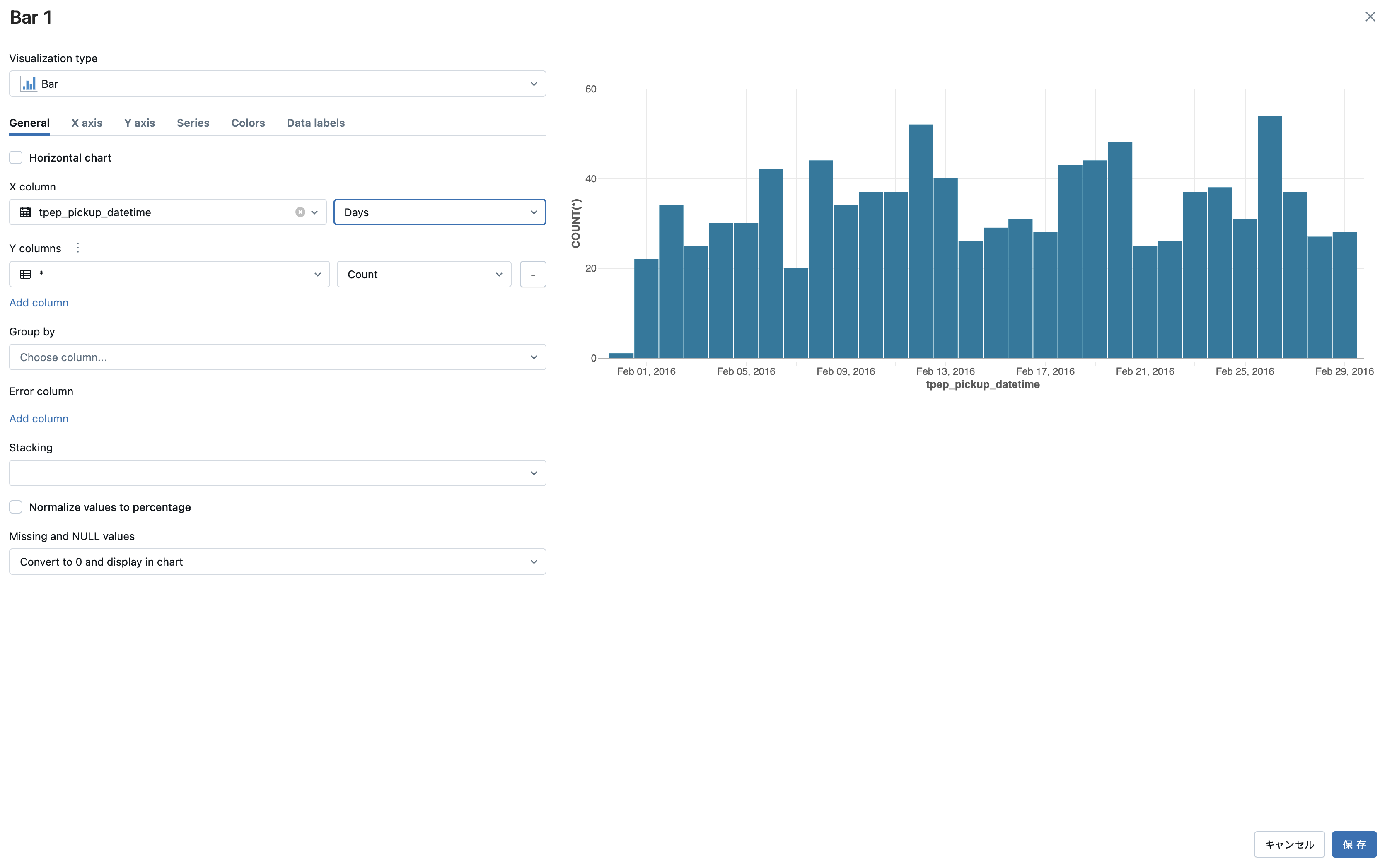
- Visualization type: Bar(棒グラフ)
- X column: tpep_pickup_datetime、Daysで集計
- Y columns:
*とCountを選択
このように設定することで、tpep_pickup_datetimeの日毎の件数を集計して可視化することができます。同じように保存します。
これで、ダッシュボードに必要なウィジェットが準備できました。

実際には、可視化の設定を試行錯誤したり、クエリーを編集して必要な洞察を導き出す営みを行うことになります。また、SQLエディタではDatabricksアシスタントを活用することもできます。


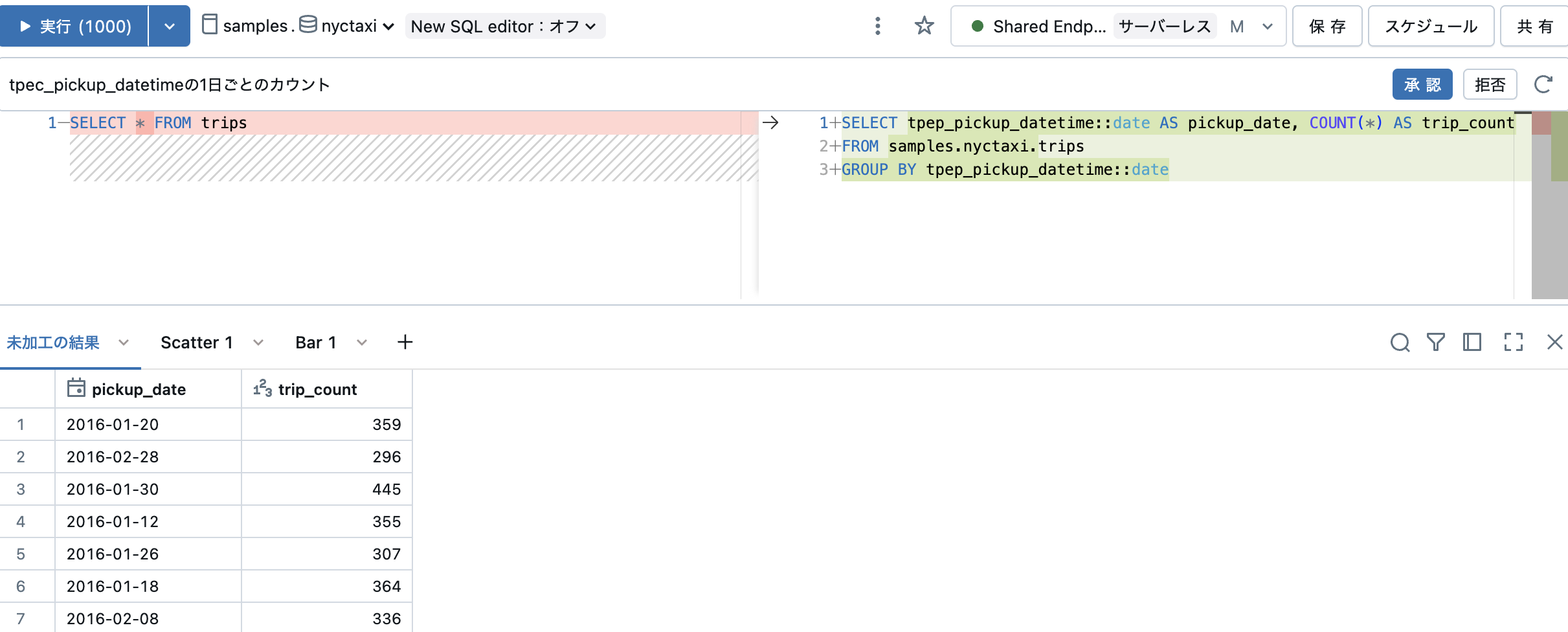
ダッシュボードの作成
可視化の部品のタブの右にある下向きの矢印をクリックして、コンテキストメニューを呼び出します。ここで、ダッシュボードに追加を選択します。

すると、ダッシュボード作成のダイアログが表示されます。
以下の設定を行います。
- 新規ダッシュボードを作成
- 名前:
NYタクシー乗降データダッシュボードなど分かりやすい名前を指定 - ウィジェット: ダッシュボードに含めたいウィジェットにチェック
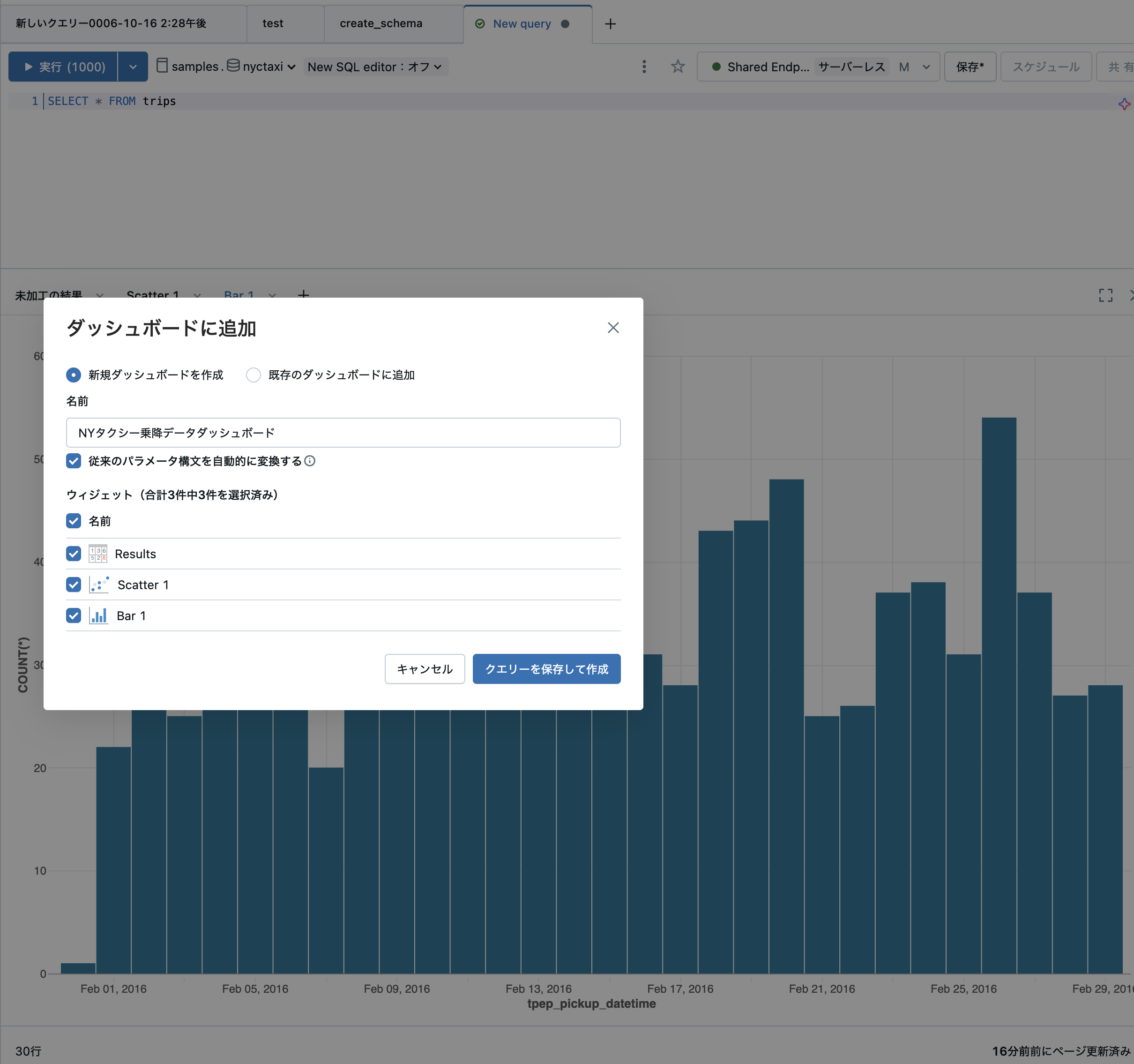
クエリーを保存して作成をクリックします。
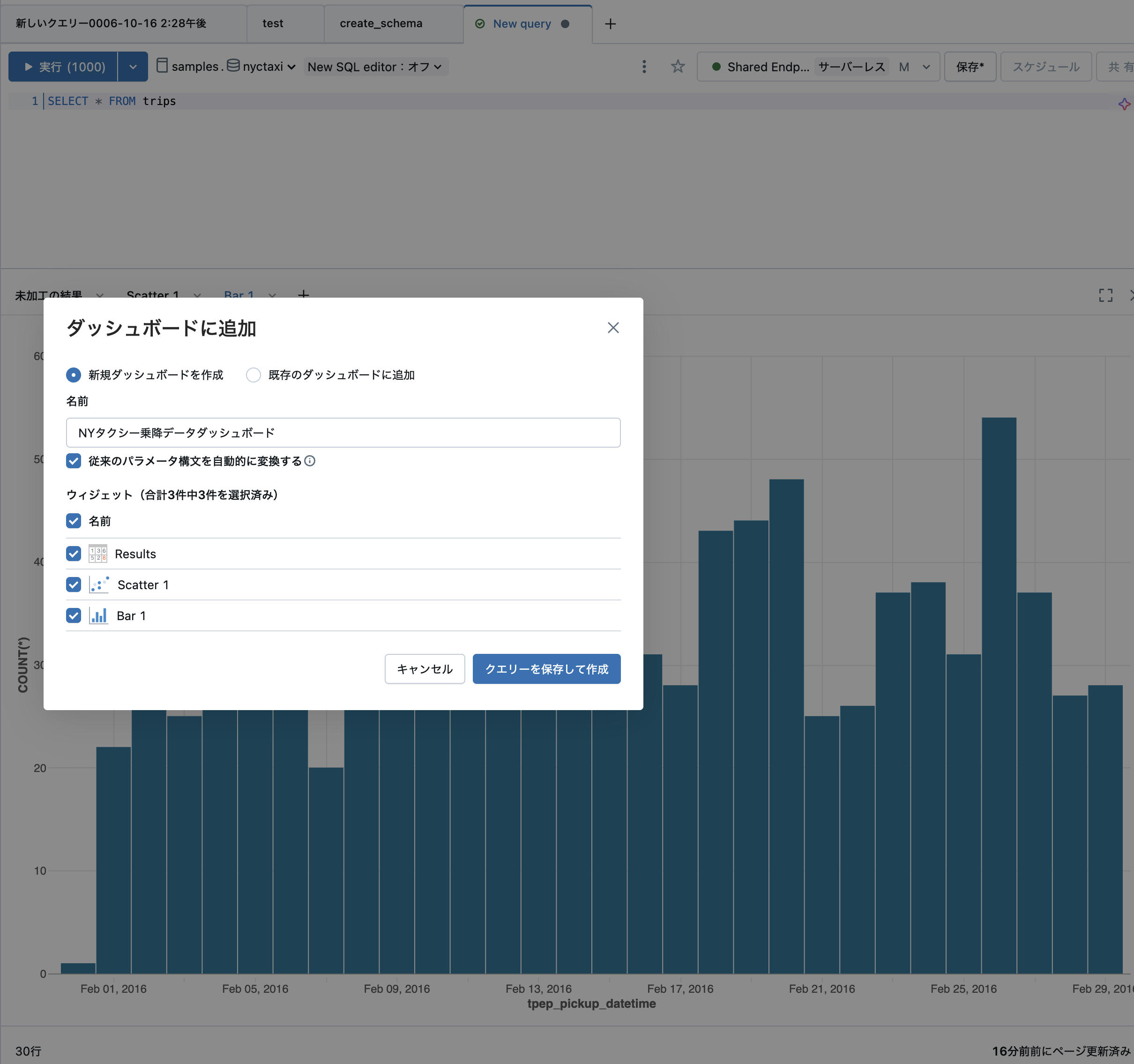
上で作成したクエリーに名前をつけて、適切な場所に保存します。

すると、ダッシュボードの画面に遷移します。

配置されているウィジェットは、ドラッグ&ドロップで移動やサイズ変更ができるので、好きなように編集します。さまざまな設定が可能ですので、こちらを参考にウォークスルーしてみてください。

また、ウィジェットの作成でもAIアシスタントの助けを借りることができます。(日本語を含む)自然言語でウィジェットの作成を指示することができます。

また、この時点でデータタブにアクセスし、テーブルとしてtripsテーブルを追加しておきます。これを設定しておかないと、あとでGenieスペースが正常に動作しません。

ダッシュボードの公開
ここまでで作成したダッシュボードは下書き状態であり、あなた以外の方が参照することはできません。あなたが導き出した示唆を他のメンバーに共有するためにダッシュボードを公開しましょう。
ダッシュボード名の右にある下書きを展開し、公開を選択します。
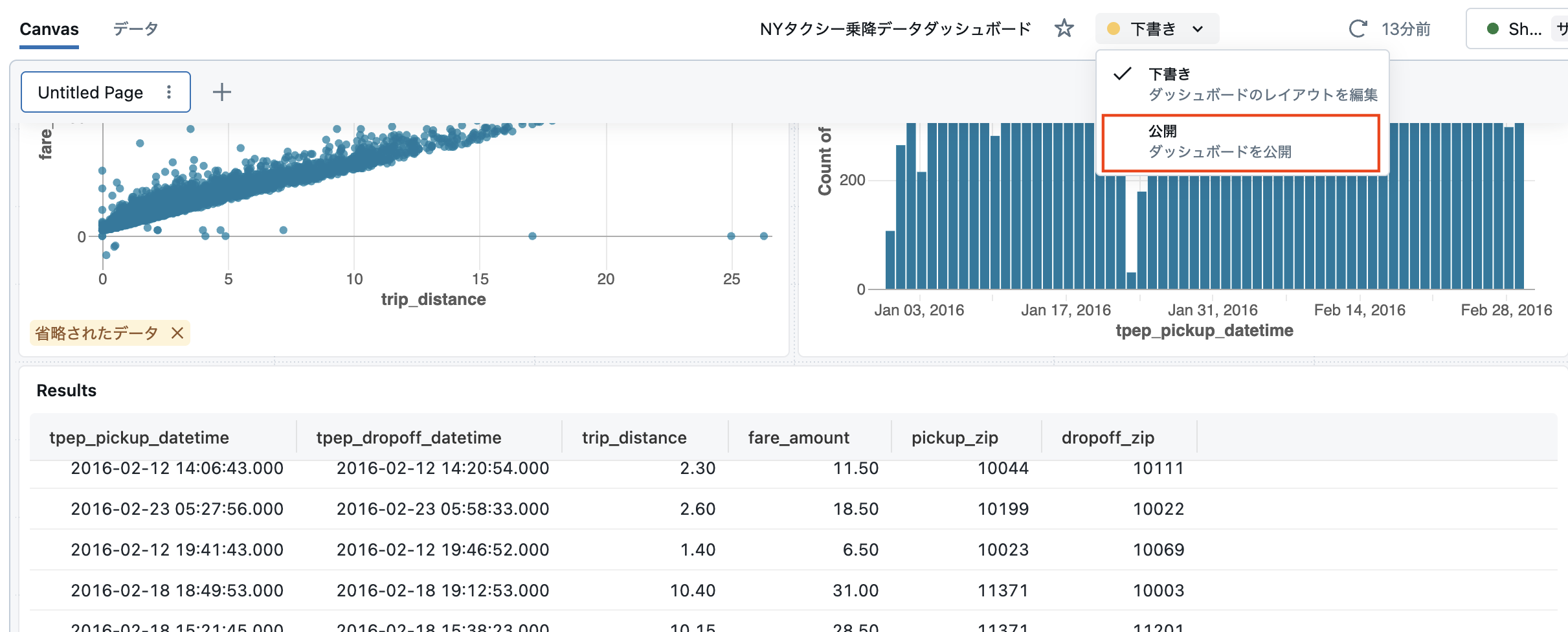
ここで、公開設定のダイアログが表示されます。
- 資格情報を埋め込むがデフォルトになっています。この場合、ダッシュボードの参照者はあなたの資格情報を用いてダッシュボードにアクセスすることになります。認証情報を埋め込まないを選択することで、ダッシュボードの参照者は参照者自身の資格情報を用いてダッシュボードにアクセスすることになります。セキュリティ要件に基づいて設定を行ってください。ここでは、デフォルトの資格情報を埋め込むのままにしておきます。
- アクセス許可のある人は、デフォルトはあなた自身と管理者のみです。次の画面で、アクセス可能なユーザーを指定することになります。
- Genieを有効にしてくださいのトグルをオンにすることで、このダッシュボードと連携するGenieのスペースを作成することができます。ここではオンにしておきます。デフォルトのAuto-generate Genie space(Ginieスペースを自動生成)を選択します。

設定が完了したら公開をクリックします。
必要に応じて、ダッシュボードにアクセスできる人を追加します。
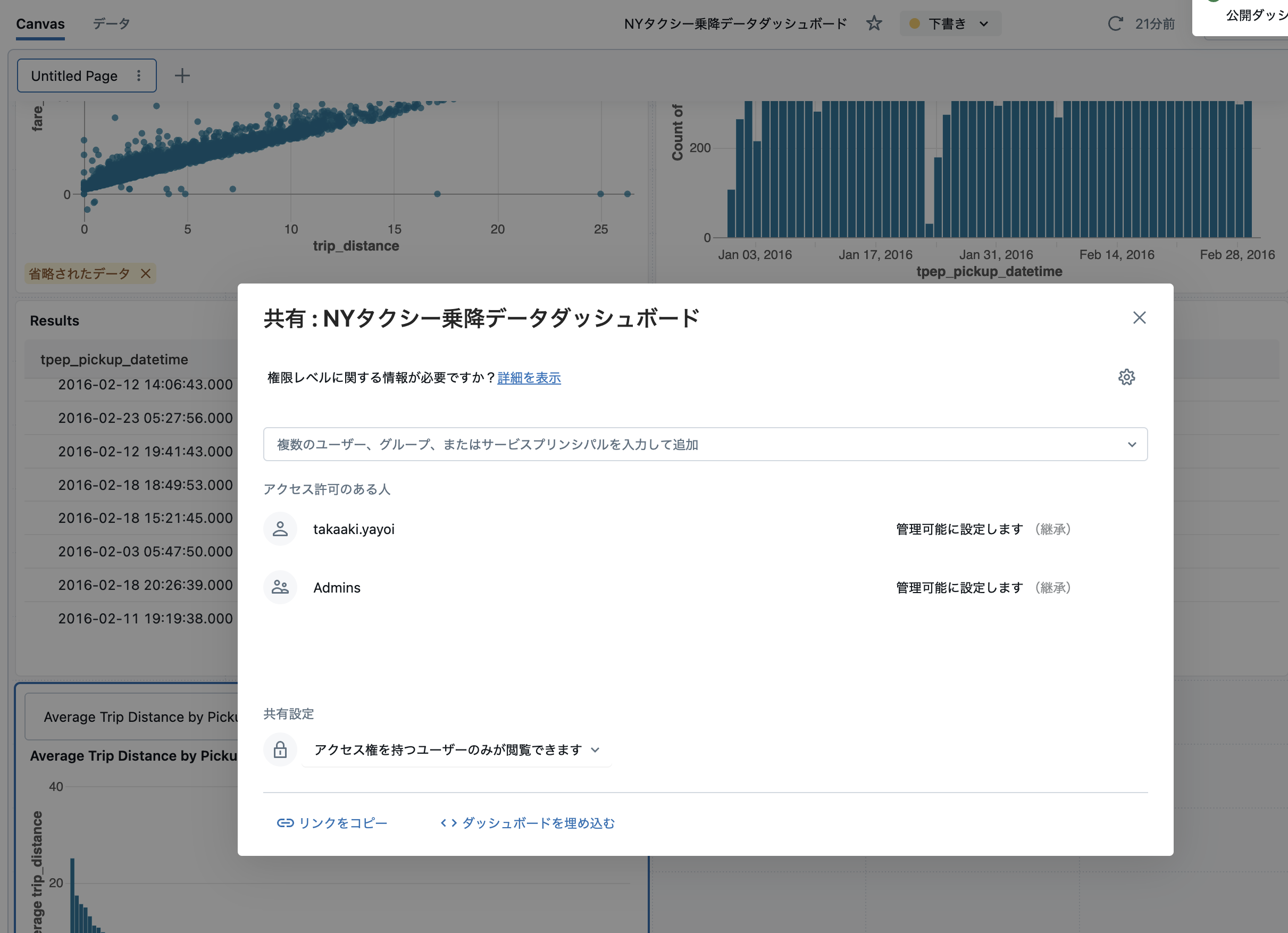
上のダイアログを閉じると、公開状態のダッシュボードに遷移します。
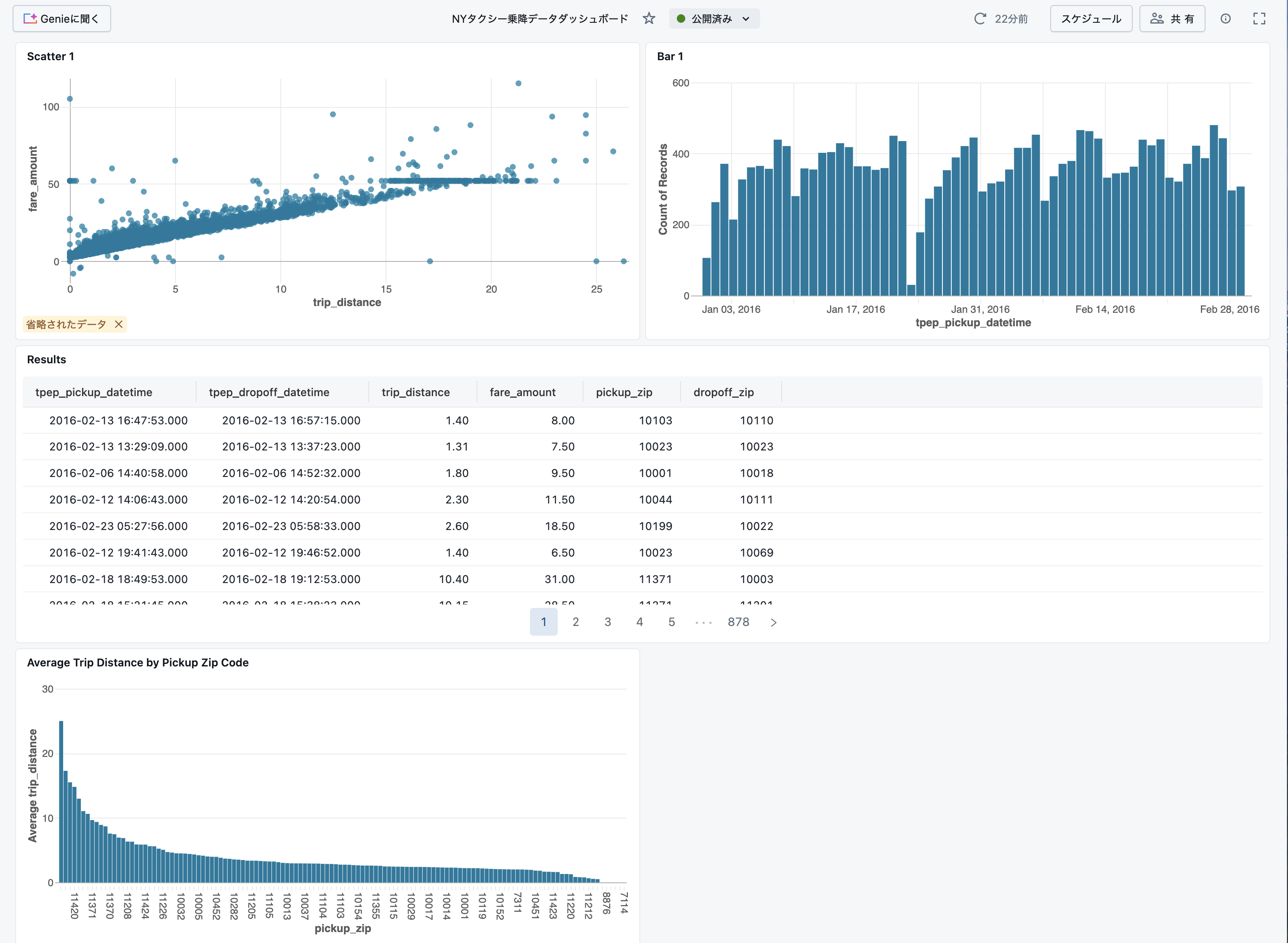
これでダッシュボードが公開されましたので、ステークホルダーに示唆を共有しましょう!
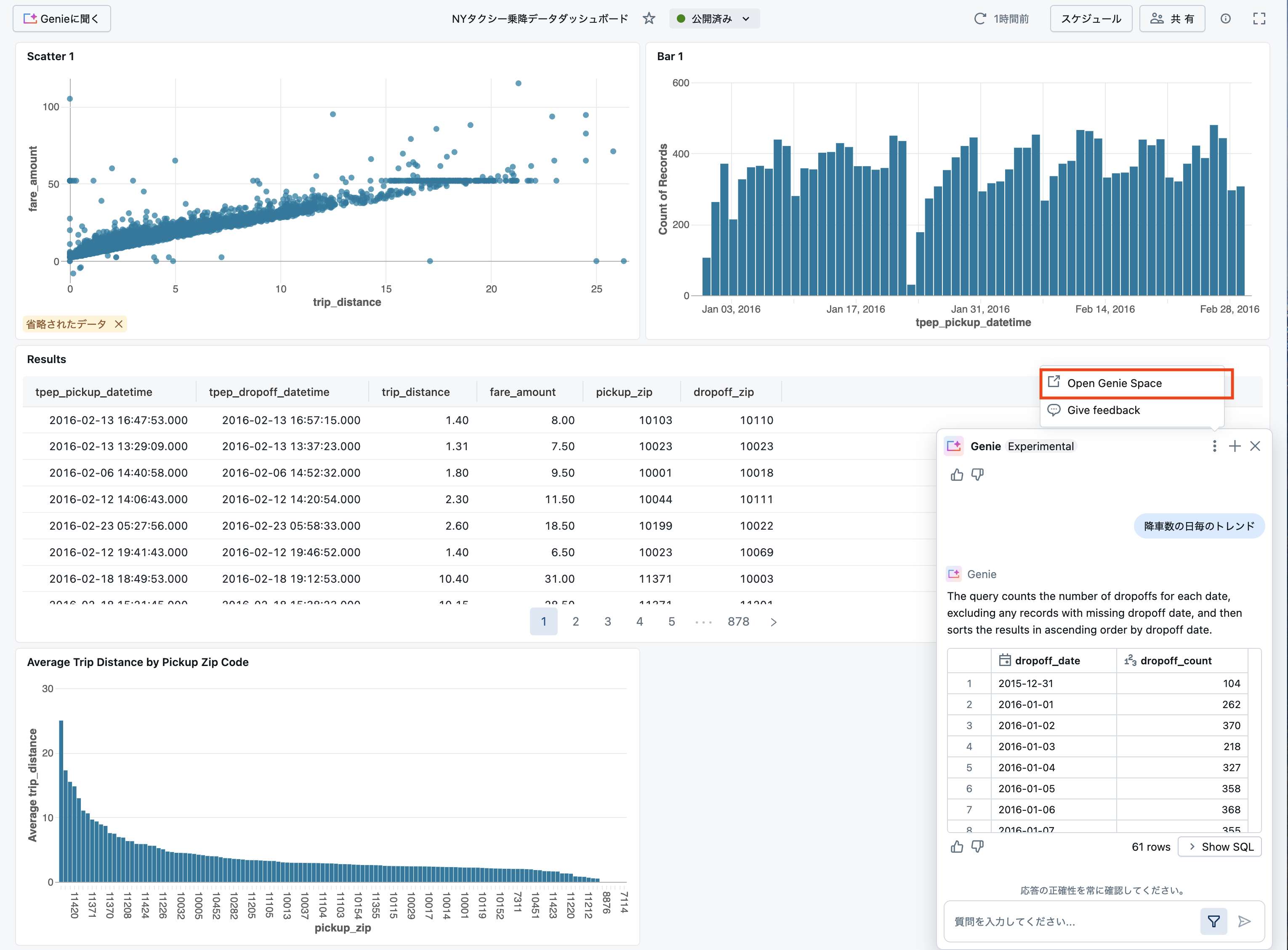
Genieの活用
ダッシュボードが公開されましたが、この可視化の結果からさらに深掘り分析を行いたいということはよくあることかと思います。その際に、一からクエリーを作成することも可能ですが、強力な相談相手になってくれるのがGenieです。汎用型の生成AIとは異なり、データという文脈を与えることで、あなたが取り扱っているデータに基づく質問を自然言語で行えるのがGenieの大きな特徴の一つです。
ダッシュボード左上に表示されているGenieに聞くをクリックします。

Genieとの対話画面が右下に表示されます。
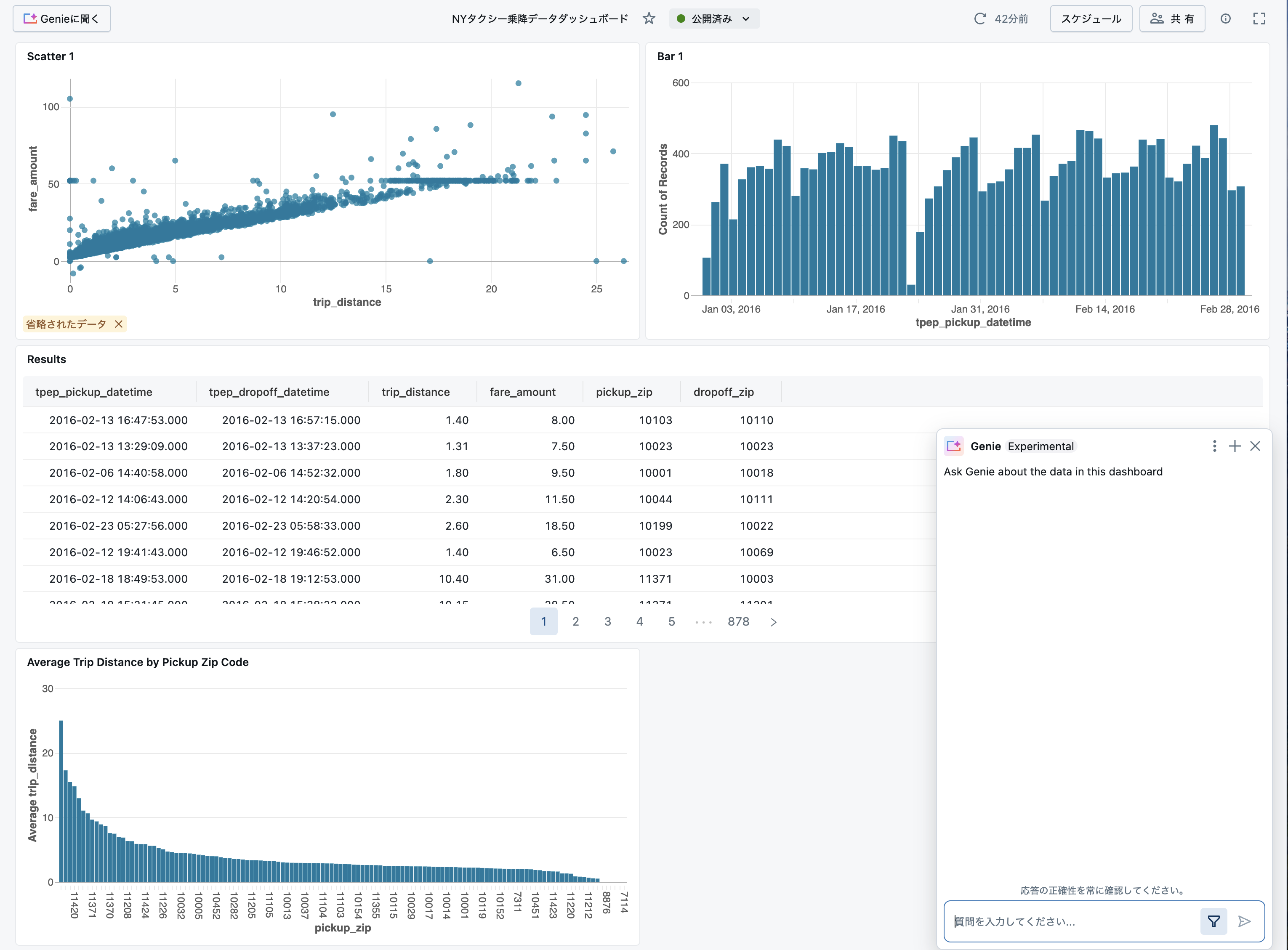
データに関する質問を行い、データに対する理解を深めましょう!
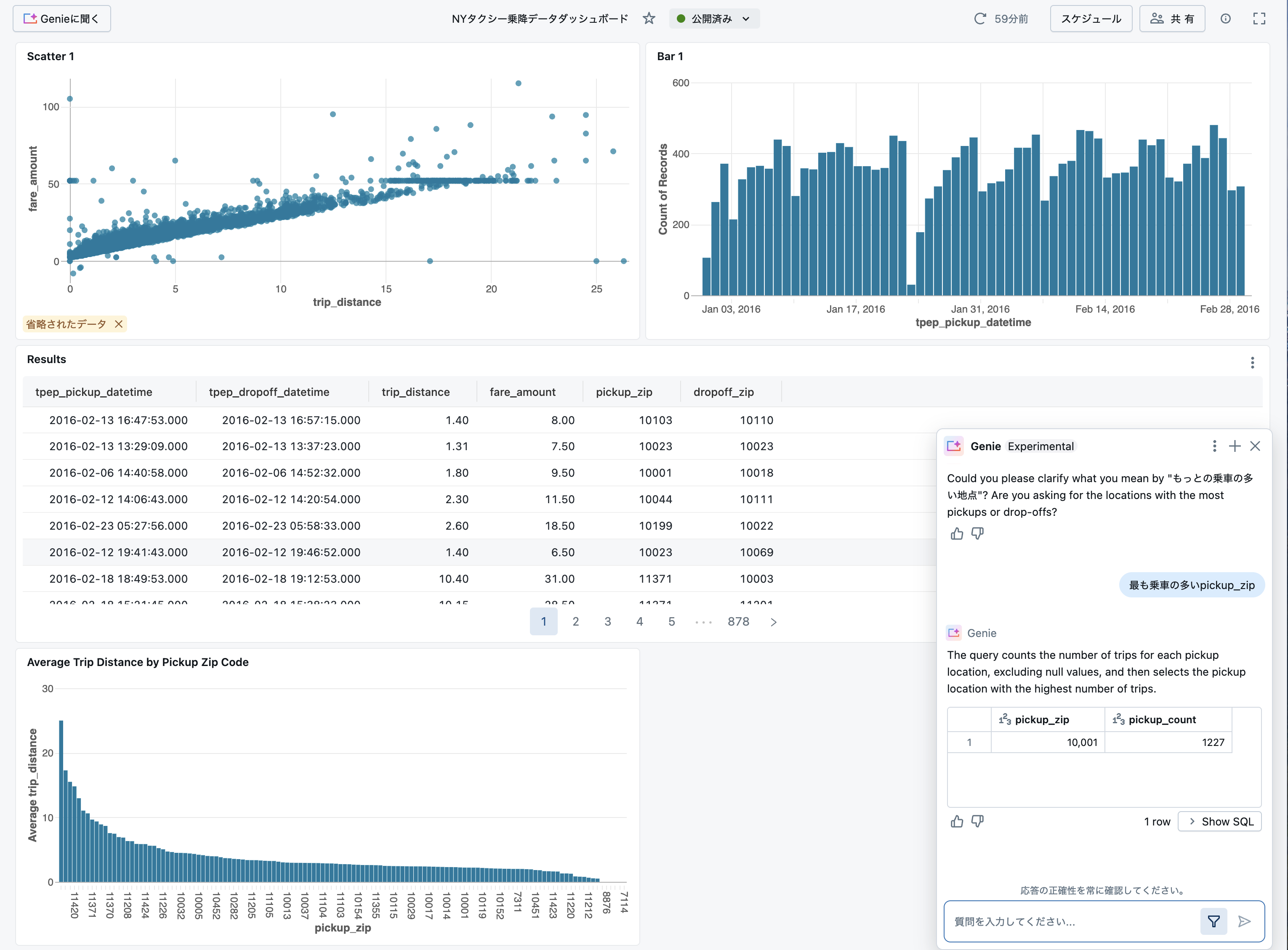
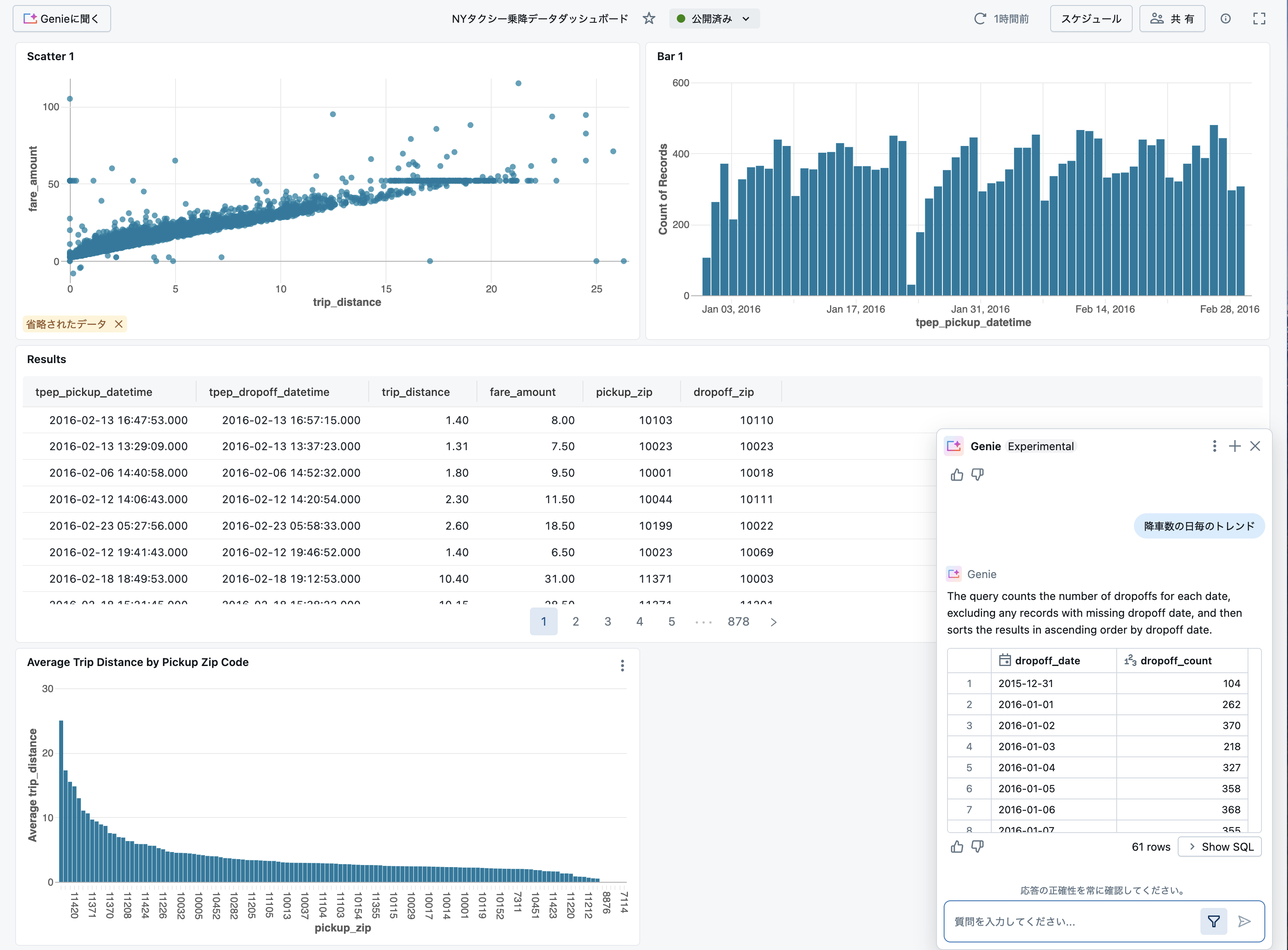
ウィンドウの3点リーダーをクリックし、Open Genie Spaceをクリックすることで、スペースに移動してより詳細なやり取りを行うことも可能です。

DatabricksにおけるBIの振り返り
- カタログエクスプローラで分析データを特定しました。
- クエリーとウィジェットを作成しました。その際にはアシスタントのサポートを受けることができます。
- ウィジェットを組み合わせでダッシュボードを作成しました。
- ダッシュボードとGenieスペースと連携させることで、鳥瞰と深掘りを行ったり来たりすることができました。
ビジネスアナリストからデータエンジニアへの転換
冒頭で触れたロールの違いに基づいて、改めて違いを確認します。
- BIは分析データの特定がスタートであるが、データエンジニアリングは分析データの提供がゴールであり、そのゴールに到達するためにデータソースを調査することがスタート地点となります。
- BIでは基本的には参照系のクエリーしか使用しませんが、データエンジニアリングではテーブルの作成やデータの更新が必要となります。
- データエンジニアリングでは、データソースから分析データに到達するデータパイプラインの開発、運用が主要なタスクとなります。
結果として、以下のようなスキルの拡張や新規習得、マインドセットの転換が求められます。
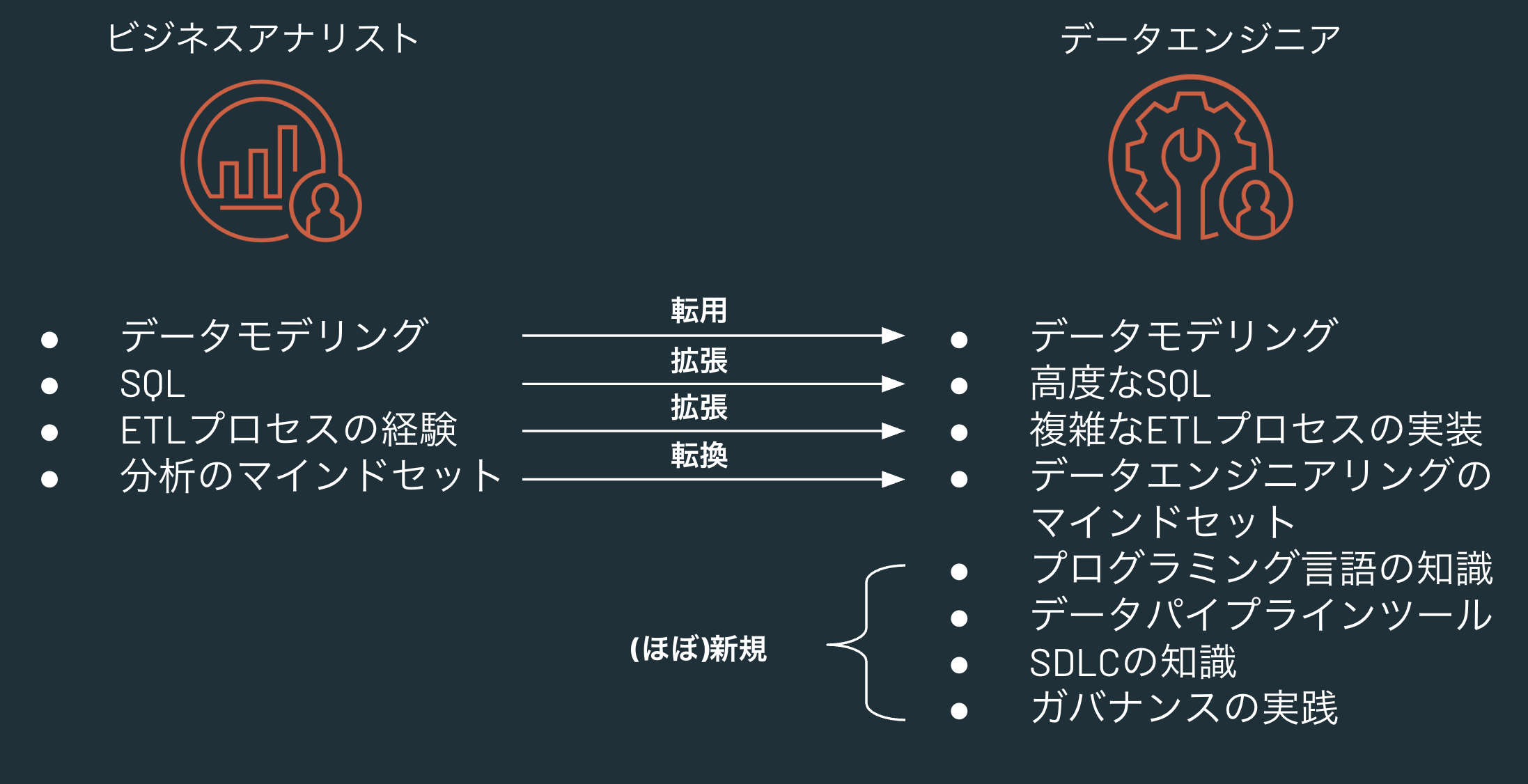
| ビジネスアナリスト | データエンジニア |
|---|---|
| データモデリング | データエンジニアでもデータモデリングは必要(転用) |
| SQL | 基礎的なSQLから高度なSQLへ(拡張) |
| ETLプロセスの経験 | BIツール上でもETLは行われていましたが、それをデータパイプラインとして実装することになります(拡張) |
| 分析のマインドセット | 分析のマインドセットを踏まえて、データエンジニアリングのマインドセットを持つ必要が出てきます(転換)。むしろ、分析のマインドセットを持っていることが強みになる(データ利用者の気持ちがわかる)と思います。 |
| - | データパイプラインの実装においては、SQLだけでは達成できないユースケースも出てくるので、Python(PySpark)の知識が必要となります。 |
| - | Sparkなど高速にデータを処理できるデータパイプラインの理解、習熟が求められます。並列分散処理のコンセプトの理解、実践が求められます。 |
| - | パイプラインの開発とソフトウェア開発には共通する点が多くあります。SDLC(ソフトウェア開発ライフサイクル)に対する理解と実践が求められます。 |
| - | データのみならず、機械学習モデルなどデータパイプラインに関連する資産が適切に管理されていることが重要となります。ガバナンスの理解と実践が重要となります。 |
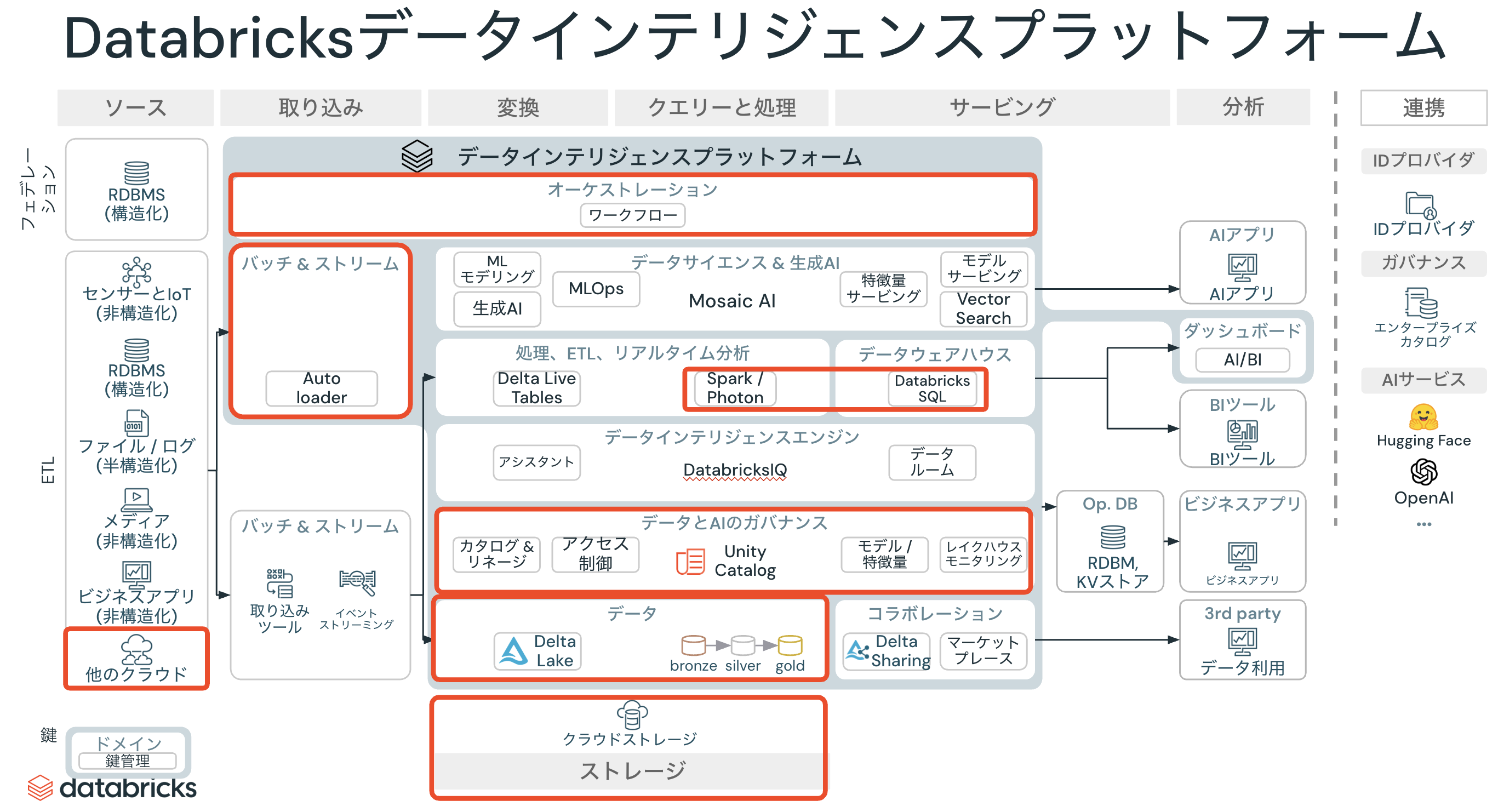
Databricksにおけるデータエンジニアリング
Databricksにおけるデータエンジニアリングに関連する機能を以下の赤枠で示します。BIと比べて非常に多岐に渡っていることがわかるかと思います。

ここでは、Delta Live Tablesやストリーミング処理など全ての機能はカバーせず、こちらのチュートリアルに基づいて簡易なデータパイプラインを実装してジョブ化するところまでをカバーします。
データエンジニアリングのマインドセット
以下は個人的な経験も踏まえてのデータエンジニアリングに必要なマインドセットとなります。こちらの記事も参考になります。
- ビジネスアナリストやデータサイエンティストから必要とされるデータの種類、量、鮮度、品質を理解する。
- 利用可能なデータソースを理解する。不足がある場合に入手方法を検討する。
- 格納されるデータの実態はファイルであることを理解する。
- データ読み書きのインパクトを理解する。
- プロダクションシステムに不必要な負荷を与えない(閑散期にデータアクセスを行うなど)。
- データ書き込み先への権限があることを確認する。
- ソースデータから分析データに至る変換ロジックをスマートに実装する。
- メダリオンアーキテクチャやETL(Extract、Transformation、Load)を理解する。
- SQLやPython(PySpark)を習熟し、必要な場合にはSparkなどを用いた並列処理を行う。
- 洗い替えでなくインクリメンタルな処理やチェンジデータキャプチャを実装する。
- ワークフローなどを活用して可能な限り自動化する。
- データエンジニアリングで使用するリソース(ジョブ、ノートブック、テーブル、ファイルなど)の所在を適切に管理する。
データエンジニアリングのチュートリアル
こちらをウォークスルーします。
- インターネットからデータをダウンロードしてボリュームに保存
- ボリュームのデータを読み込んで変換処理を適用
- 変換したデータをテーブルに書き込み
データ格納場所(ボリューム)の作成
このチュートリアルでは、インターネットからダウンロードしたファイルを保存します。Databricksでファイルを保存する方法はいくつかありますが、一番のおすすめはボリュームを用いることです。チュートリアルではmain.default.my-volumeというボリュームを使用していますが、他の方と名前が重複するので別の名前を指定して、ボリュームを作成します。
カタログエクスプローラにアクセスし、カタログmain、スキーマdefaultにナビゲートします。
画面右上の作成 > ボリュームを作成をクリックします。

ボリュームの作成ダイアログが表示されます。

ご自身の名前など他の方と重複しない名前を入力し、ボリュームタイプは管理ボリュームのままとし、オプションでコメントを入力して作成をクリックします。ここでは、taka-yayoi-volumeという名前にしています。
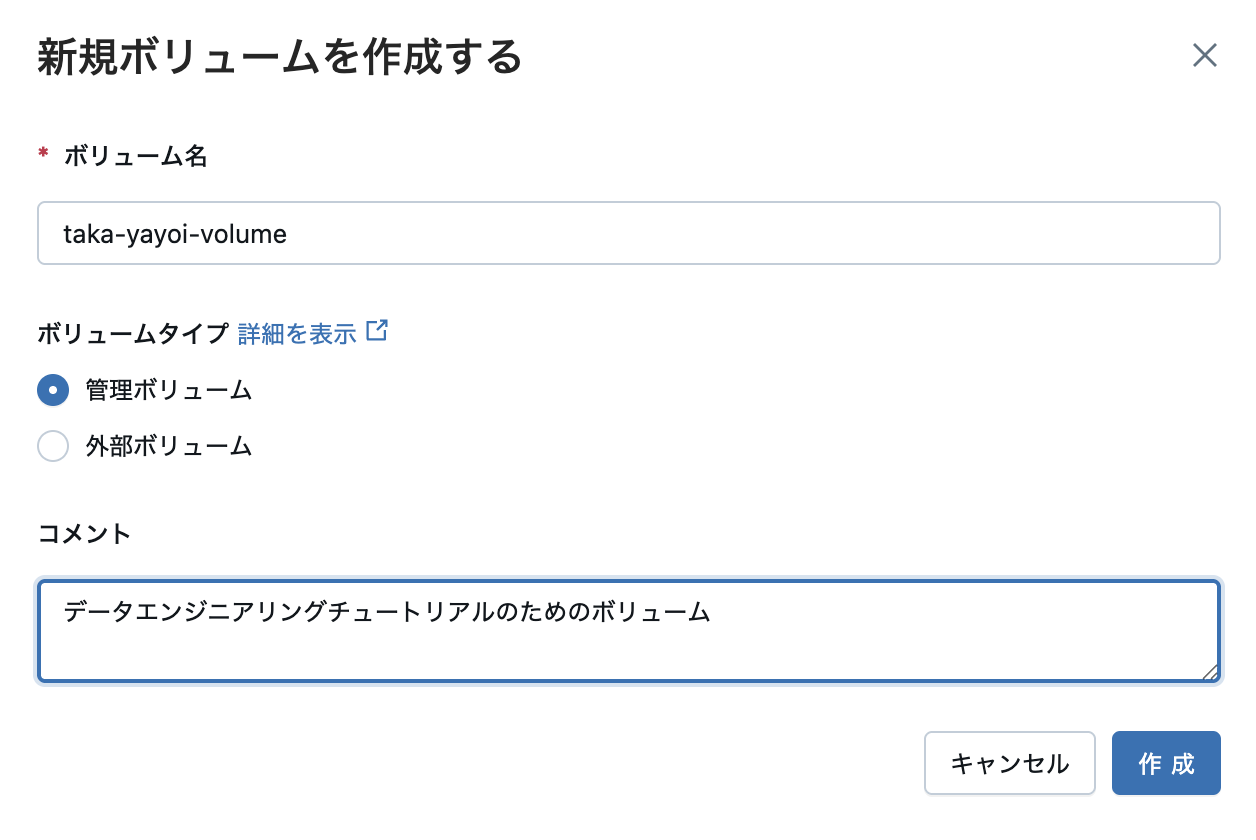
これで、main.default.taka-yayoi-volumeという名前空間でアクセスできるボリュームが作成されました。このボリュームのファイルパスは/Volumes/main/default/taka-yayoi-volumeとなります。
ボリュームが作成できない場合には、Databricks管理者にあなた自身がこちらの要件を満たしているのかをご確認ください。
ジョブ用ノートブックの作成
データパイプラインはノートブックで実装します。
データ取り込みノートブック
まず、ETLにおけるE(Extract)の処理を実装します。
ノートブックを作成するには、サイドメニューの + > ノートブック を選択します。

ノートブックが開きます。こちらにPythonやSQLの言語を記述することで、データパイプラインを実装します。Databricksにおけるデータエンジニアリングでは、ノートブックを用いた開発を頻繁に行うので、こちらを参考にUIや使い方に習熟するようにしましょう。ノートブックでもアシスタントを活用することができますので、困ったことがあったらアシスタントに質問しましょう。

ノートブックのセルに以下のコードを貼り付けます。taka-yayoi-volumeの部分は、上のステップで作成したご自身のボリュームを指定します。
import requests
response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv')
csvfile = response.content.decode('utf-8')
dbutils.fs.put("/Volumes/main/default/taka-yayoi-volume/babynames.csv", csvfile, True)
このコードでは、Pythonを用いてhttps://health.data.ny.gov/api/views/jxy9-yhdk/rows.csvのファイルをダウンロードしてボリュームに保存しています。
アシスタントにコードを説明してもらうことも可能です。セルの右上の星マークをクリックします。
プロンプトボックスが開くので、以下の指示を行い生成をクリックします。
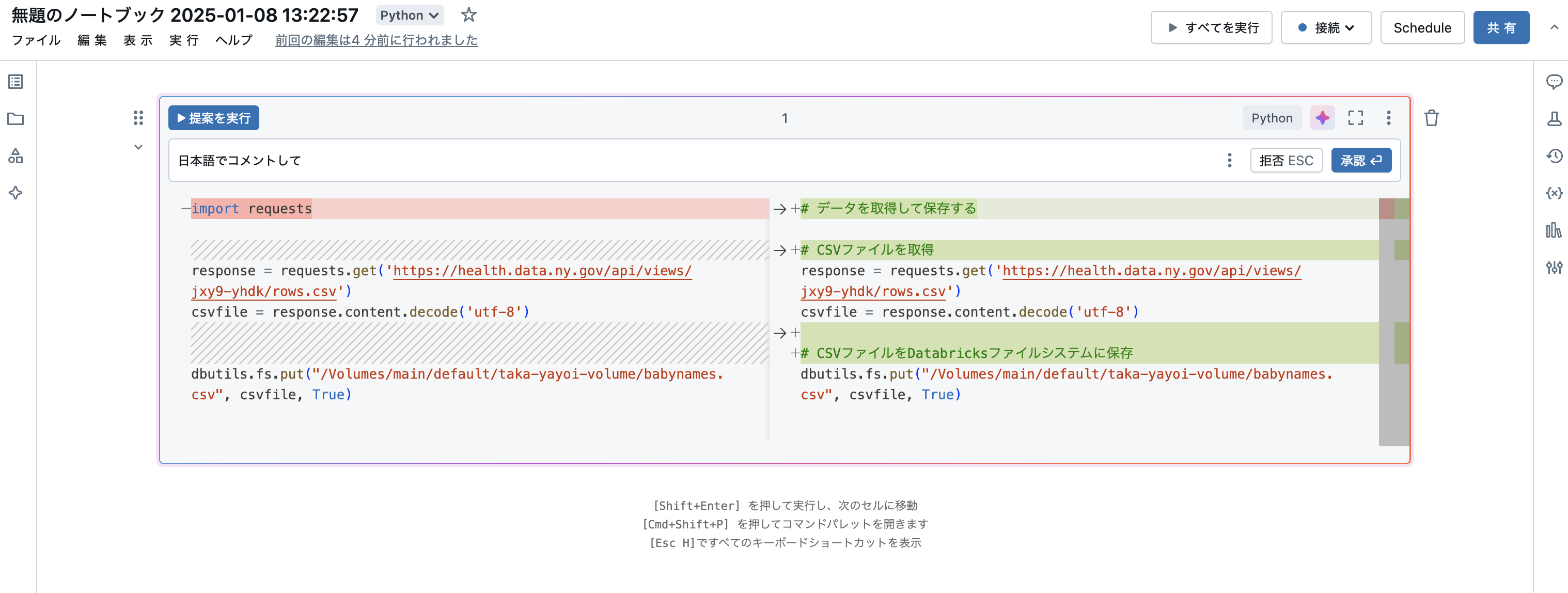
日本語でコメントして
すると、日本語でコメントが追加されます。承認をクリックすることで提案を確定できます。このようにして、アシスタントの助けを借りてコードの理解を深めることも可能です。
ノートブックのタイトルの部分にカーソルを合わせ、データ取り込みというように名前を変更します。
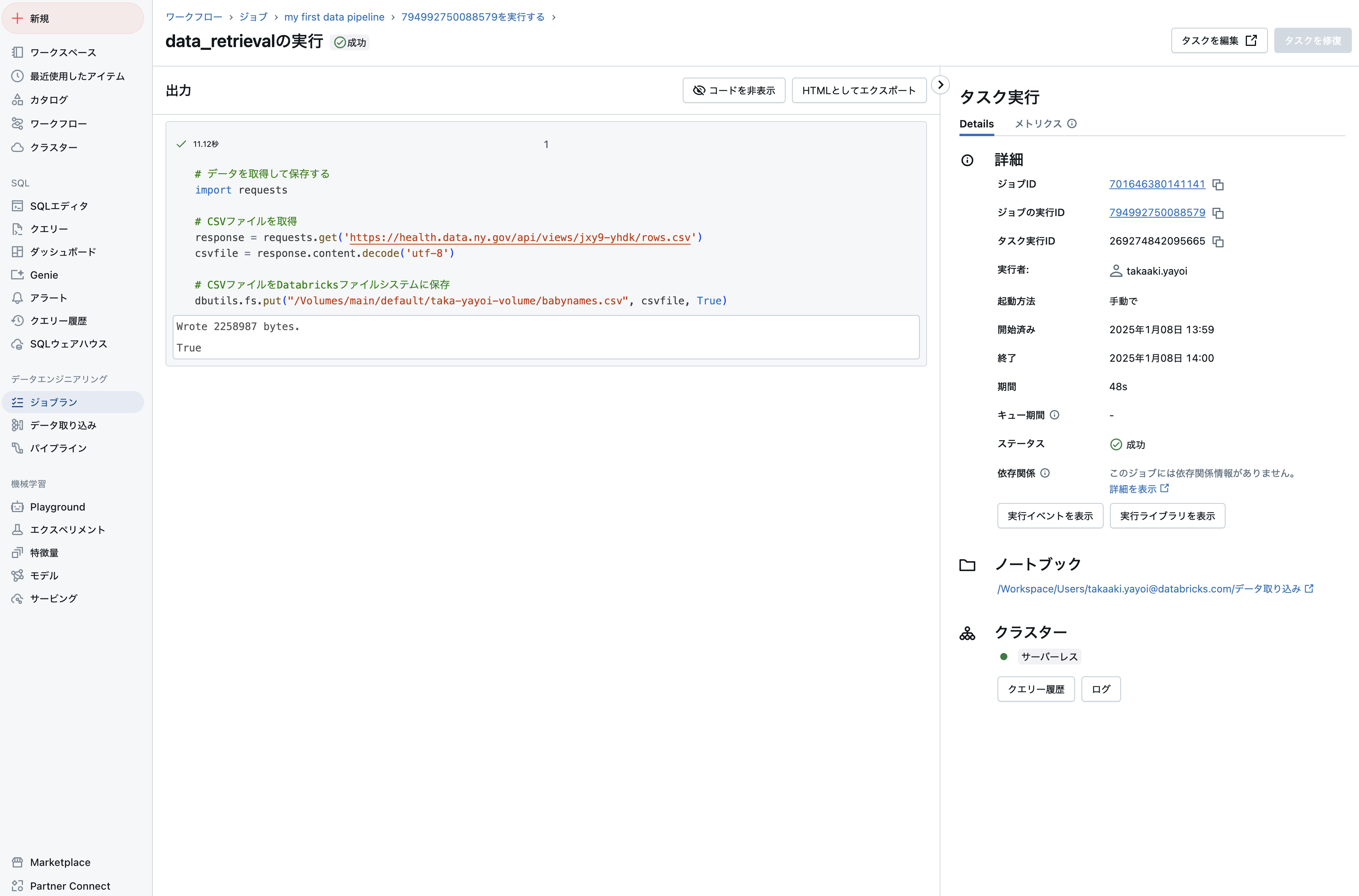
開始時刻をクリックすることで、さらに詳細表示することができます。

データ変換、テーブル保存ノートブック
規模の小さいデータパイプラインであればノートブックを分ける必然性はありませんが、本番運用されるようなデータパイプラインであれば、ノートブックを分割してモジュール化する必要があります。ここでは、モジュール化を体験いただくために、データ変換のノートブックを別に作成します。また、元のノートブックではテーブルを保存していませんが、ここではダッシュボードの作成に繋げられるようにテーブルを保存します。ETLにおけるT(Transformation)とL(Load)に該当します。
再びサイドメニューの + > ノートブック を選択します。
まず、今回のノートブックはSQLを記述するので、ノートブック名の隣にある言語セレクターからSQLを選択します。その後、以下のコードを記述します。読み込みファイルのパスのtaka-yayoi-volumeやテーブル名taka_yayoi_babynames_tableは適宜変更してください。

-- CSVファイルを読み込む
CREATE OR REPLACE TEMPORARY VIEW babynames AS
SELECT * FROM read_files("/Volumes/main/default/taka-yayoi-volume/babynames.csv", header=>'true');
-- 年を整数型に変換し、2014年のデータをフィルタリング
CREATE OR REPLACE TEMPORARY VIEW babynames_transformed AS
SELECT
`First Name` AS First_Name,
CAST(Year AS INT) AS Year,
County,
Sex,
Count
FROM babynames
WHERE CAST(Year AS INT) = 2014;
-- テーブルに保存
CREATE OR REPLACE TABLE main.default.taka_yayoi_babynames_table AS
SELECT * FROM babynames_transformed;
なお、データの変換にPython(PySpark)を使用することもできます。以下は上と同様の処理をPySparkで実装しています。
# CSVファイルを読み込む
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/taka-yayoi-volume/babynames.csv")
# 年を整数型に変換し、2014年のデータをフィルタリング
babynames_transformed = babynames.withColumnRenamed("First Name", "First_Name").withColumn("Year", babynames["Year"].cast("int")).filter(babynames["Year"] == 2014)
# テーブルに保存
babynames_transformed.write.mode("overwrite").saveAsTable("main.default.taka_yayoi_babynames_table")
ノートブック名をデータ変換とロードなどに変更します
今回はホームフォルダにノートブックを作成していますが、実際に運用する際にはジョブごとにフォルダを作成することを強くお勧めします。
ジョブの作成
これでジョブを作成する準備が整いました。サイドメニューからワークフローにアクセスして、ジョブを作成をクリックします。
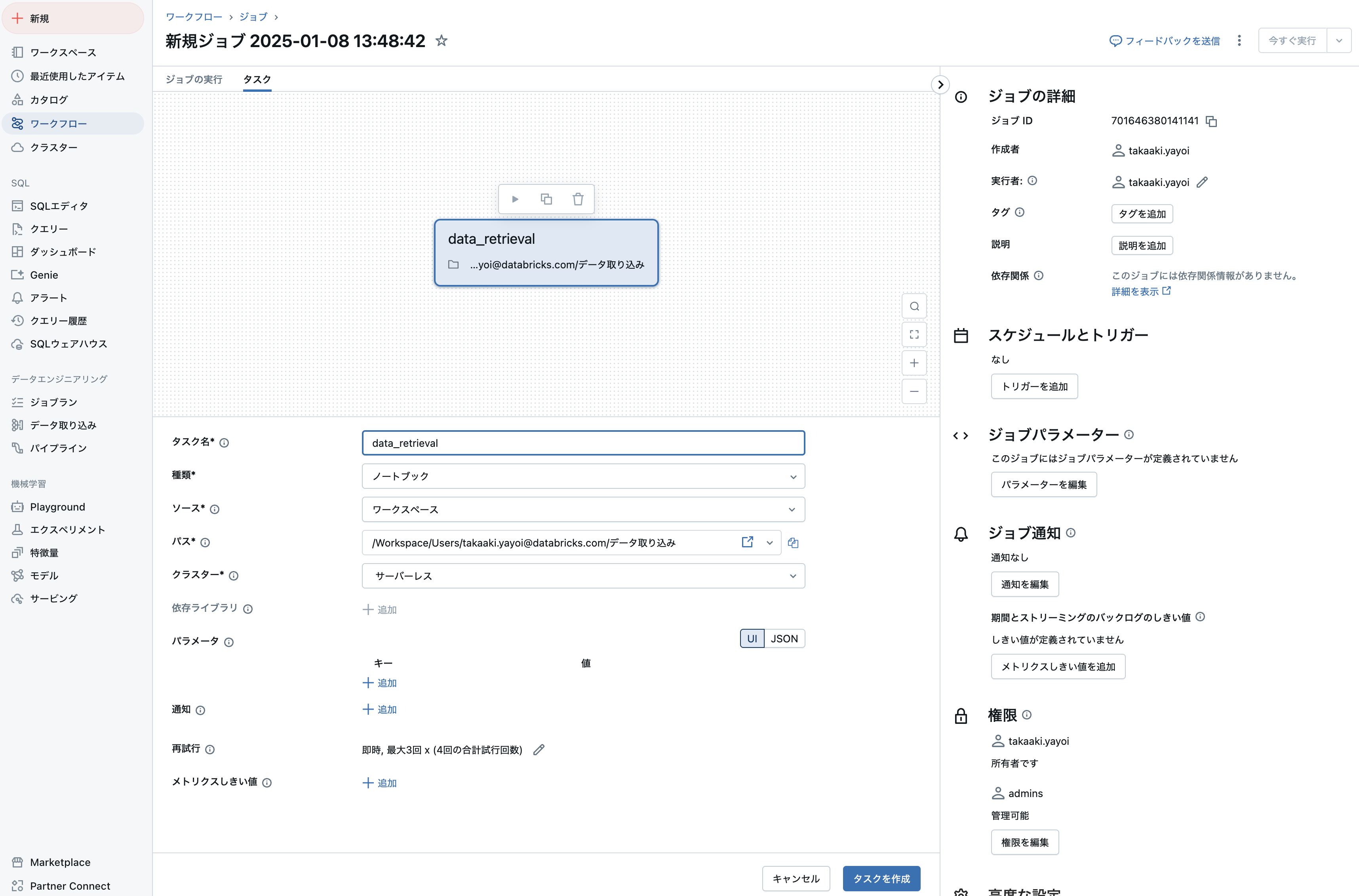
ジョブは複数のタスクから構成することができ、タスクにはノートブックやダッシュボードなどを指定することができます。ここでは、上で作成した2つのノートブックをタスクとして指定します。

一つ目のタスクを作成します。デフォルトはノートブックタスクになっていますので、パスをクリックして上のデータ取り込みノートブックを選択します。

タスク名は英数字とアンダースコアのみが許可されるので、data_retrievalといった名前にしてタスクを作成をクリックすると、1つ目のタスクが作成されます。
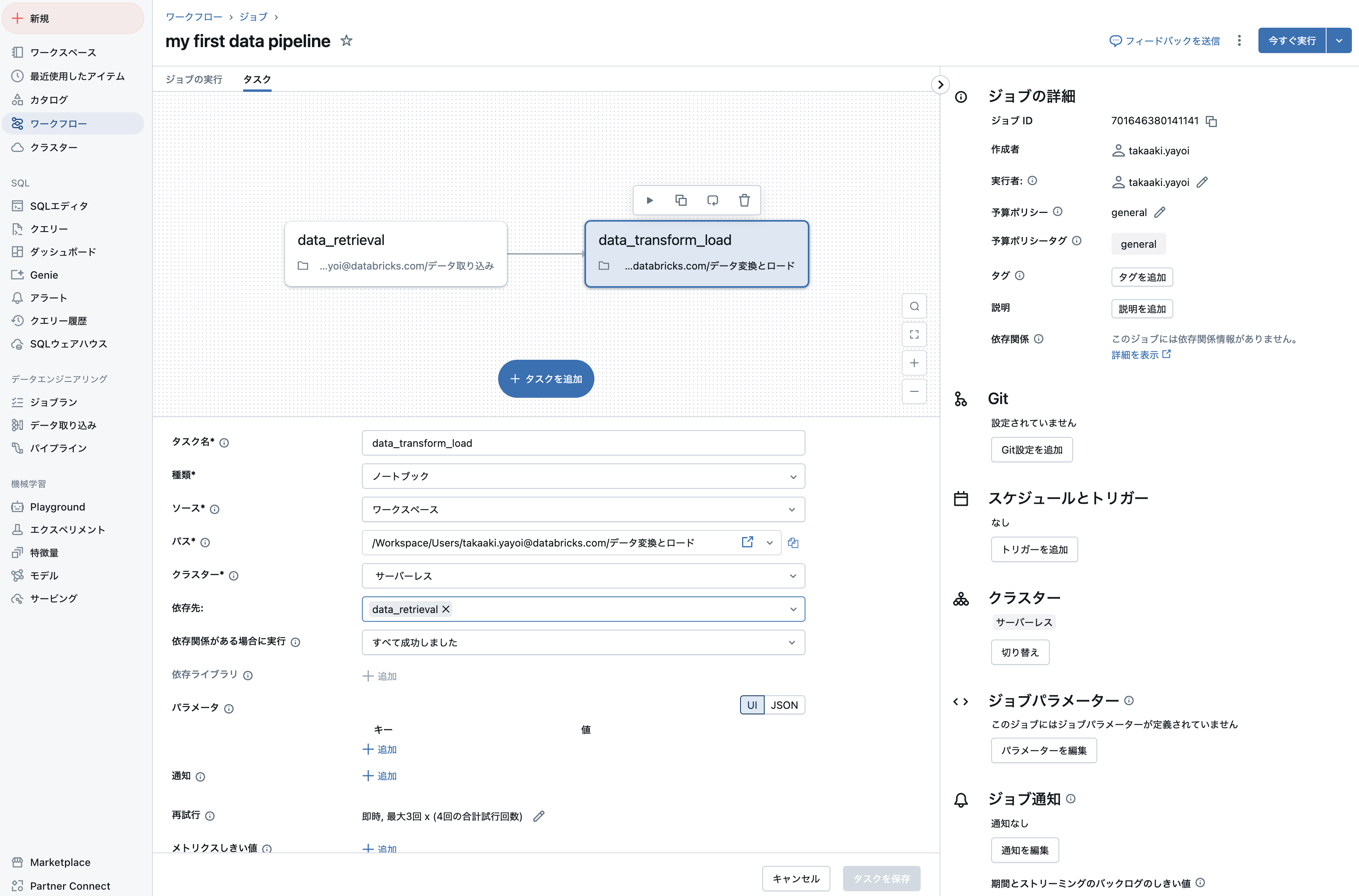
タスクを追加 > ノートブックをクリックして後段のタスクを作成します。

今度はパスにデータ変換とロードノートブックを指定して、タスク名をdata_transform_loadとして、タスクを作成をクリックします。

最後にジョブ名をわかりやすいものに変更して準備は完了です。
ジョブの実行
ジョブは即時実行やスケジュール実行などが可能です。即時実行するには右上の今すぐ実行をクリックします。

ジョブの実行タブに切り替えると、実行中のジョブの進捗を確認できます。
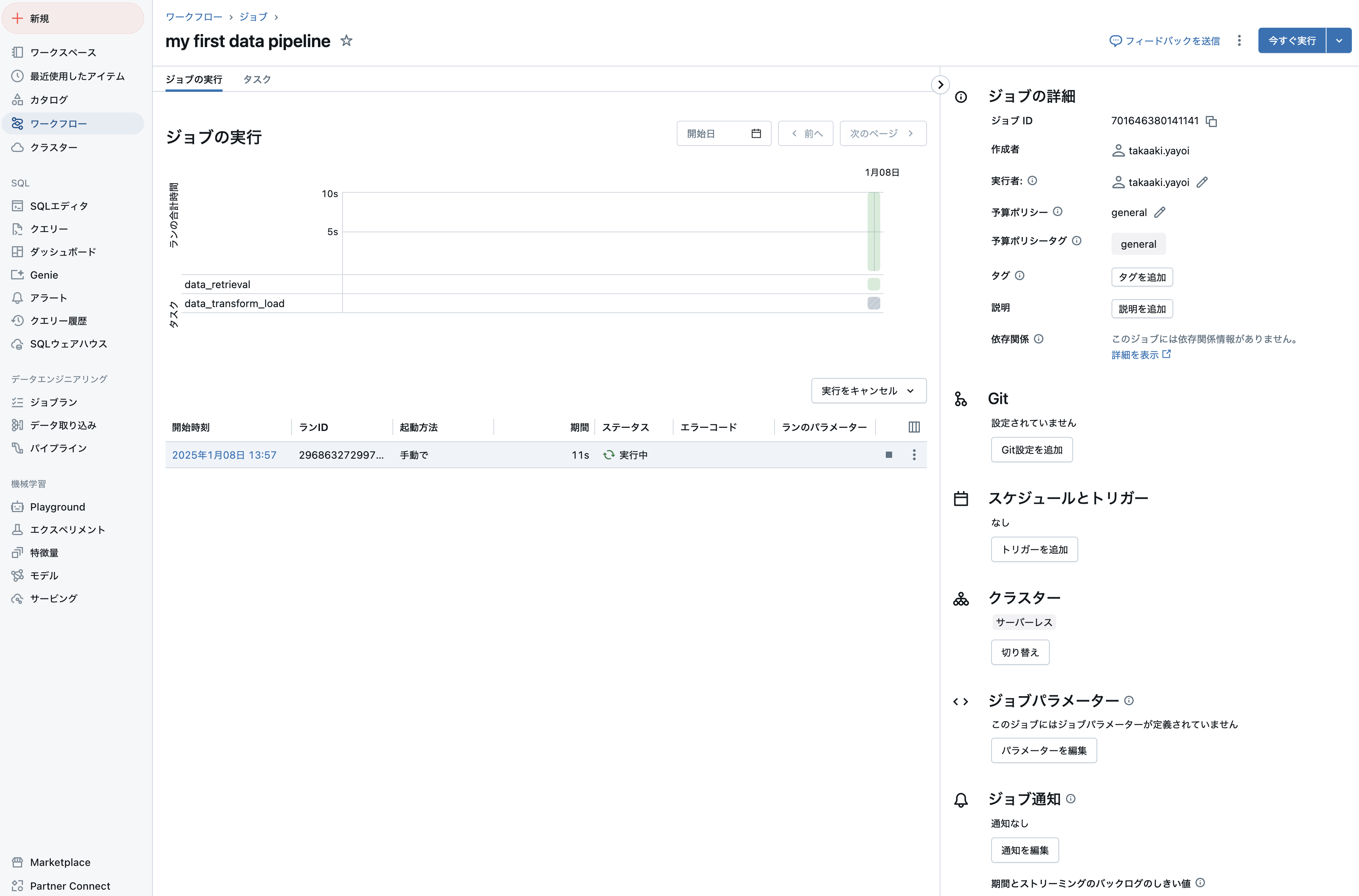
問題がなければ処理は正常終了します。
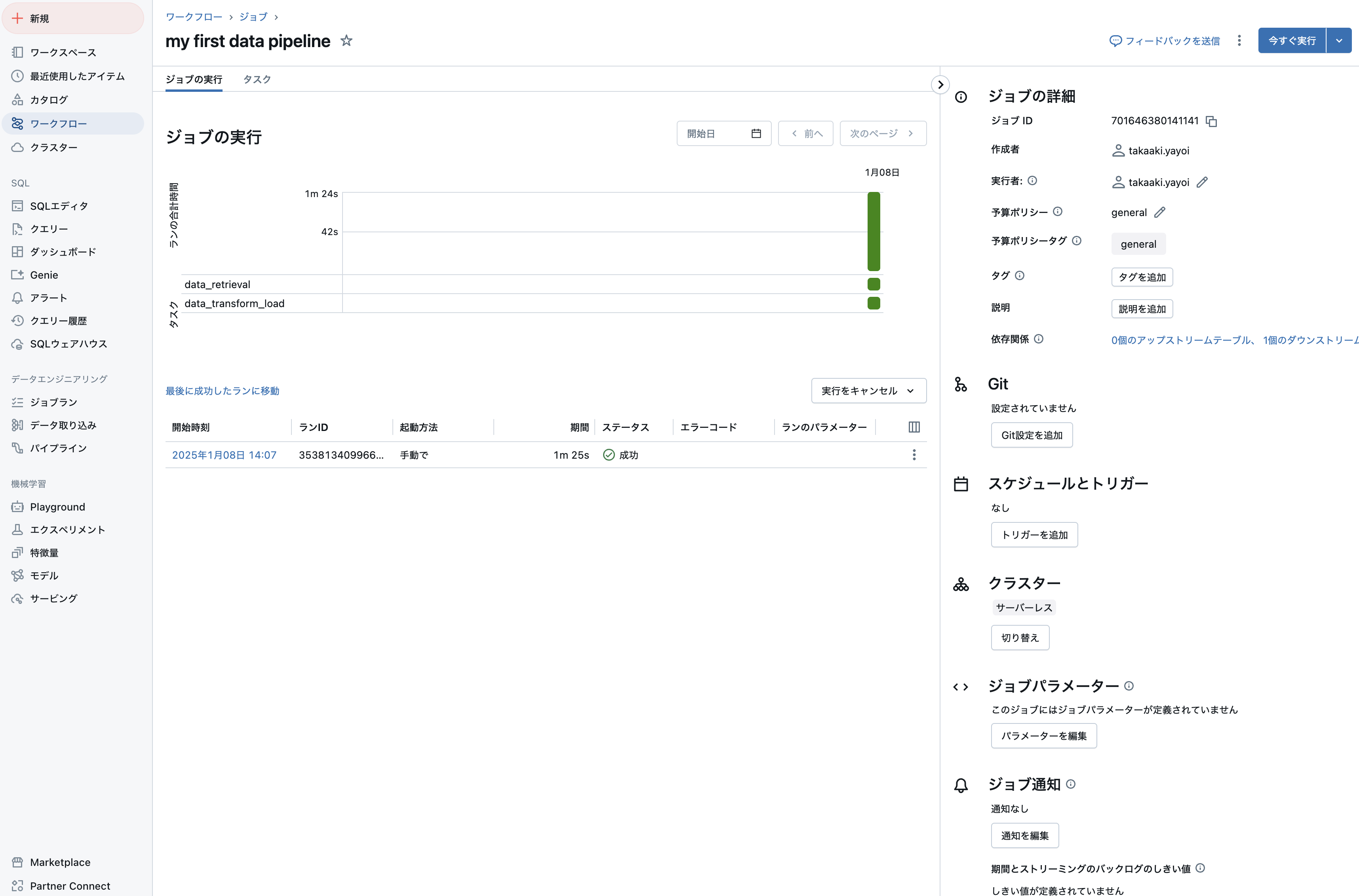
データパイプラインによって作成されたテーブルをカタログエクスプローラで確認することができます。

非常にシンプルなデータパイプラインではありますが、これで一通りの実装とジョブとしての実行を体験することができました!
ジョブのスケジュール実行
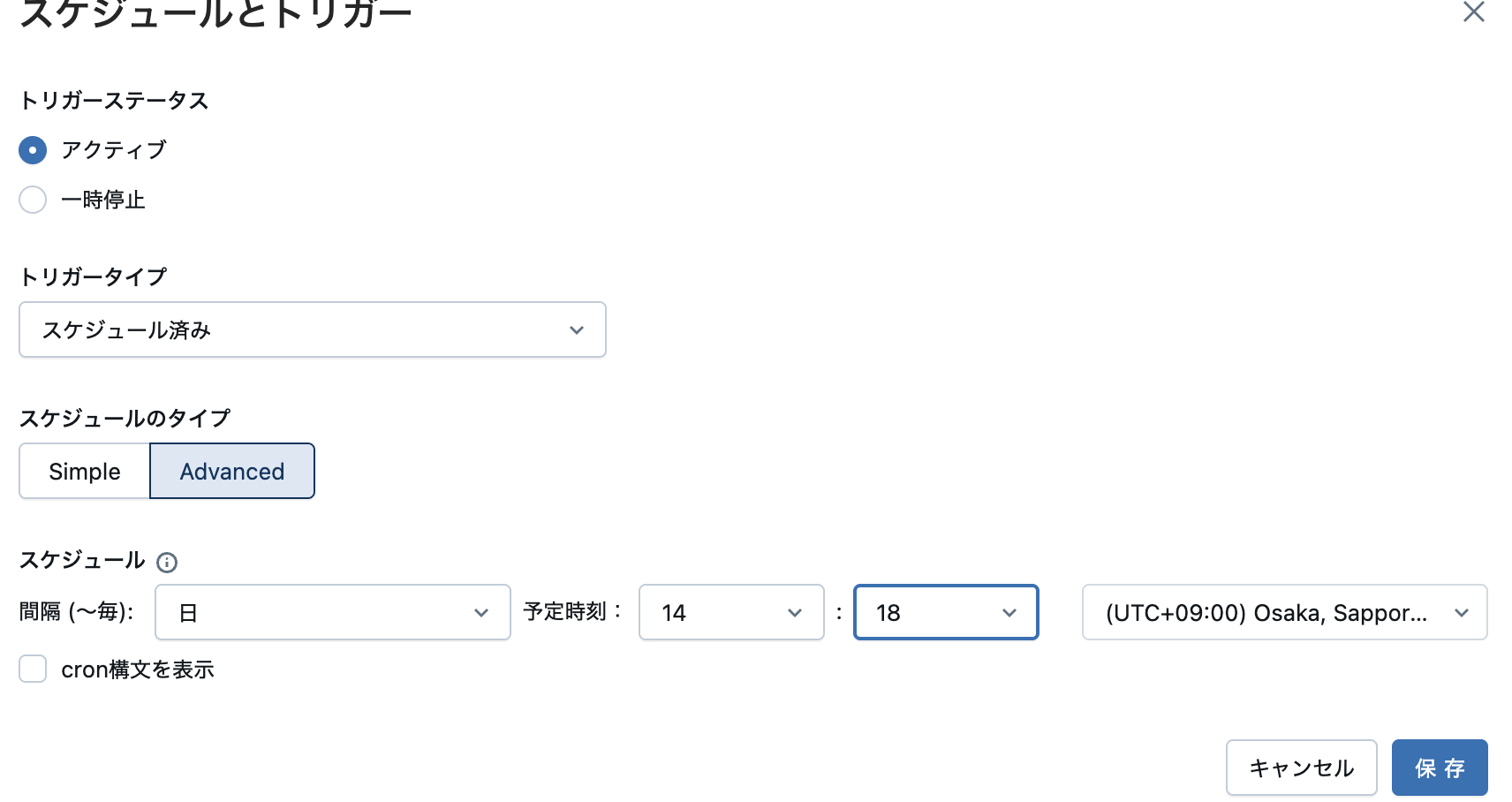
通常、ジョブは夜間に実行するなどスケジューリングすることが一般的です。ジョブのトリガーを追加をクリックします。

トリガータイプでスケジュール済みを選択します。

スケジュールのタイプでAdvancedを選択し、タイムゾーンをUTC+09:00を選択して、数分後に実行されるように設定します。
設定した時間になるとジョブが起動します。

スケジューリングされたジョブは定期実行されるので、不要になったジョブは一時停止あるいは削除するようにしてください。

Databricksにおけるデータエンジニアリングの振り返り
- BIと対比してデータエンジニアリングで活用するDatabricksの機能を概観しました。
- データエンジニアリングのマインドセットをカバーしました。
- Databricksノートブックを用いて簡単なデータパイプラインを実装しました。
- Databrikcsワークフローを用いてデータパイプラインをジョブ化しました。
このデータパイプラインによって作成されるテーブルを用いることで、ビジネスアナリストはダッシュボードを作成できるようになります。

これが、データエンジニアとビジネスアナリストのコラボレーションとなるわけです。
まとめ
今回は、DatabricksにおけるBIからデータエンジニアリングへの転換の助けとなるように、それぞれの機能をウォークスルーしました。ビジネスアナリストに求められるスキルセットとデータエンジニアに求められるスキルセットは異なりますが重複する部分もあります。そして、正直なところデータエンジニアに求められるスキルセットの方が広範です。しかし、BIやデータサイエンスのみならず、昨今の生成AIの文脈においてもデータエンジニアリングは非常に重要な位置を占める技術領域となっています。綺麗なデータなしには優れたLLMやLLMアプリを実現することはできません。
DatabricksではBI、データエンジニアリングの両方の機能を提供しているので、実験を繰り返しながらBIのスキルをデータエンジニアリングのスキルに拡張、転換していくことは比較的容易だと思います。いずれのシナリオでもAIアシスタントの助けを借りることもできます。
本記事がビジネスアナリストからデータエンジニアへのロール変更を検討されている方の助けになれば幸いです。