地味に盛り上がっている「ディープラーニングによる画像の異常検知」に関する投稿の続きです。
今回は、可視化部分を改良します。

これまでの動き
以前に、以下の記事を投稿しました。
ここで使われている「DOC」という技術は学習済のモデルを利用できるため、
精度と速度を天秤にかけて自由に変えることができます。従って、軽量な
モデルを選べば、ラズパイなどのモバイル端末でも動かせます。
さらに、@koshian2 さんから以下の投稿がありました。
https://qiita.com/koshian2/items/b4c4ffda99c07a1ac6b8
Triplet lossを使った高速の異常検知です。こちらの内容はまだしっかり理解
していないのですが、高速かつ精度良く異常検知できるとのことで、素晴らしい
内容だと思います。
さらに、DOCの高速化について@PINTO さんから以下の投稿がありました。
https://qiita.com/PINTO/items/0a52062cb6ebe9ef5051
TensorFlow Lite等を駆使してDOC+ラズパイで15FPSという
とてつもない数値をたたき出しています。こちらも工場の生産ラインでは
なくてはならない「高速化」の技術で、素晴らしい内容です。
DOCの課題点
DOCの課題点をまとめておきます。
速度が遅い
もはやTriplet lossを使った高速の異常検知には敵わないのですが、DOCを
高速化すると、速度と精度はどうなるのかを改めて明記したいと思います。
可視化が弱い
これは、DOCの課題点というより私の課題点といえます。
DOCの論文では可視化は言及されておらず、以前の記事では私がテキトーに
設計した可視化の部分が「低速」で、かつ「異常部分がうまく表示できない」
という問題を抱えていました。
そこで、今回は可視化部分をしっかり設計して改良します。
DOCの高速化
まずは、DOCの高速化について説明します。
実は、既にがんばる人のための画像検査機の記事で高速化は実施済です。
高速化の中身が気になる方はこちらをご覧ください。
Colaboratoryでは計測していなかったため、改めて速度と精度(AUC)を記載します。
| 速度(msec/1枚) | AUC | |
|---|---|---|
| 以前の記事 | 140 | 0.9 |
| 高速化後 | 20 | 0.88 |
今回は、若干精度が下がってしまいました。これは学習データの組み合わせで多少変動します。
ただ、以下の調整を行うと精度が改善されることがあります。精度を出したい人はチャレンジしてみてください。
- 「重みを凍結する層」を変更してみる
- DOCの出力を最終層ではなく手前の層に変更する
特に、DOCの出力層を手前にすることで、精度だけではなく速度も若干
改善されるのでおススメです。AUCが0.02くらい改善することもあります。
DOCの可視化
使い方
こちらにリポジトリをアップした(DOC_Visulaization)のですが、weights_visual.h5が
重すぎて欠如しています。ラズパイで動かす際は、自分で学習させたweights_visual.h5と
その他のモデル(合計4つ)をご用意ください。
使い方は以前と同じです。
- 「DOC_Visualization」をラズパイ上に持ってくる。
- USBにウェブカメラを接続し、DOC_Visualization/main.pyを実行する。
- モデルの展開に2分くらいかかります。
- ウェブカメラのリアルタイム映像が描画されたら「s」キーを押してください。(Sキーの反応が悪いです。辛抱強く押してください。)
- ヒートマップが出力されたら、リアルタイム描画が開始されています。
- リアルタイム描画はラズパイをフル稼働させるため、5分くらいすると熱暴走してフリーズします。長期稼働する際は、冷却しながら動かしてください。
Grad-CAMでは難しい
ここからは可視化の中身を説明します。
以前の記事ではGrad-CAMで可視化を行いました。
ご覧のように成功しているとは言い難いです。
Grad-CAMは本来、出力が相互に関係してくるソフトマックス関数であることを
念頭において作られているはずです。従って、DOCのような独立した出力に
適用してもうまくいく確率は低いです。
そこで、今回は昔からあるAutoEncoderによる可視化を試みました。
AutoEncoder
AutoEncoderの説明はここではしませんが、気になる方は以下のリンクをご覧ください。
https://deepage.net/deep_learning/2016/10/09/deeplearning_autoencoder.html
https://qiita.com/fukuit/items/2f8bdbd36979fff96b07
AutoEncoderでは、情報を圧縮し、圧縮された情報を基に復元を行います。
学習データと似たような画像であれば、きちんと復元されますが、
全然似ていない画像の場合、似ていない箇所だけが復元されない
可能性が高いです。今回はその性質を利用します。
※DOCは、DOC=CNN+LOF(KNN) という形でCNNとLOF等を合わせたもの指します。
説明の便宜上、DOC'=CNNという形で説明します。ここでは CNN=MobileNETV2 です。
DOC' + Decoder
全体像は以下のとおりです。

AutoEncoderはEncoder部とDecoder部から成っており、Encoder部はDOC'にて
既に特徴量抽出が行われているため、DOC'をEncoder部とします。
一方、Decoder部は新たに設け、画像の復元をさせるために学習データで学習させます。
なお、今回はLOFによるスコアの算出はカットしています。
ヒートマップは以下の手順で生成します。

まず、Original画像をDOC'に投げます。そして、以下のように復元画像
(Reconstruction)を取得します。
Original(96×96×3) → DOC'(1280) → Decoder → Reconstruction(96×96×3)
次に、以下のようにOriginal とReconstruction の差の絶対値をとります。
Difference = |Original - Reconstruction|
最後に、DifferenceをOriginalと合成してHeatMapを得ます。
コード
通常用
通常のDecoderを設計しました。
Kerasで書くと以下のとおりです。
import keras
from keras.layers import BatchNormalization, Activation
from keras.layers import Reshape, UpSampling2D, Convolution2D
from keras.initializers import he_normal
def convolutional_decoder():
model = keras.Sequential()
model.add(Dense(input_dim=(feature_out), output_dim=1024))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(128*12*12))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((12,12,128)))
model.add(UpSampling2D((2,2)))#24*24
model.add(Convolution2D(128,5,5,border_mode='same', kernel_initializer=he_normal()))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2,2)))#48*48
model.add(Convolution2D(256,5,5,border_mode='same', kernel_initializer=he_normal()))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2,2)))#96*96
model.add(Convolution2D(3,5,5,border_mode='same', kernel_initializer=he_normal()))
model.add(Activation('sigmoid'))#out_shape=(96,96,3)
return model
モバイル用
こちらを参考にMobileNETライクなDecoderを設計しました。
上記に比べ描画性能は劣りますが、速度は2倍速いです。
import keras
from keras.layers import BatchNormalization, Activation, Input
from keras.layers import Reshape, UpSampling2D, Conv2D
from keras.layers import ReLU, DepthwiseConv2D, ZeroPadding2D
from keras.initializers import he_normal
def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1):
pointwise_conv_filters = int(pointwise_conv_filters * alpha)
if strides == (1, 1):
x = inputs
else:
x = ZeroPadding2D(((0, 1), (0, 1)),
name='conv_pad_%d' % block_id)(inputs)
x = DepthwiseConv2D((3, 3),
padding='same' if strides == (1, 1) else 'valid',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(x)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = ReLU(6., name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return ReLU(6., name='conv_pw_%d_relu' % block_id)(x)
def convolutional_decoder():
inputs = Input(shape=(feature_out,))
x = Dense(1024)(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Dense(128*12*12)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Reshape((12,12,128))(x)
x = UpSampling2D((2,2))(x)#24*24
x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=1)
x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=2)
x = UpSampling2D((2,2))(x)#48*48
x = _depthwise_conv_block(x, 128, 0.5, 1,block_id=3)
x = _depthwise_conv_block(x, 64, 0.5, 1,block_id=4)
x = UpSampling2D((2,2))(x)#96*96
x = Conv2D(3,(5,5),padding='same')(x)
x = Activation('sigmoid')(x)
return Model(inputs,x)
学習コード
学習コードは以下のとおりです。
train = model.predict(X_train_s)#X_train_sは元の画像,modelはDOC'
test_s = model.predict(X_test_s)#X_test_sは元の画像
test_b = model.predict(X_test_b)#X_test_bは元の画像
decoder = convolutional_decoder()
# initiate Adam optimizer
opt = keras.optimizers.adam(lr=0.0001, decay=1e-6, amsgrad=True)
# Let's train the model using Adam with amsgrad
decoder.compile(loss='mse',
optimizer=opt)
hist = decoder.fit(train,X_train_s,
validation_data=(test_s,X_test_s),
epochs=10,
verbose=1,
batch_size=128)
またHeatMapのコードは以下のとおりです。
from keras.preprocessing.image import array_to_img
import cv2
def plot_heat(x):
original = x.reshape((1,96,96,3))
re = model.predict(original)
#re = ms.transform(re)
re = decoder.predict(re)
map_ = np.abs(re-original).reshape((96,96,3))
jet = cv2.applyColorMap(np.uint8(255 * map_), cv2.COLORMAP_JET) # モノクロ画像に疑似的に色をつける
jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB) # 色をRGBに変換
jet = (np.float32(jet) + original.reshape((96,96,3))*255 / 2) # もとの画像に合成
plt.imshow(array_to_img(jet), cmap='gray')
plt.title("HeatMap")
plt.axis("off")
plt.show()
なお、ラズパイの描画はOpenCVでやっているため、違う書き方になっています。
ラズパイ用のコードは付録に載せておきます。ただし、未だにここに書いた
クセが残っておりますが、ご了承ください。
Fashion-MNISTによる実験
実験方法
今回使用するデータは、以前と同様に以下のように振り分けました。
| 個数 | クラス数 | 備考 | |
|---|---|---|---|
| リファレンスデータ | 6,000 | 8 | スニーカーとブーツを除く |
| ターゲットデータ | 6,000 | 1 | スニーカー |
| テストデータ(正常) | 1,000 | 1 | スニーカー |
| テストデータ(異常) | 1,000 | 1 | ブーツ |
結果
結果を見てみましょう。Decoderは通常用を使用しました。
・ スニーカー(正常)の画像


ご覧のようにほとんどが青い画像になっています。
・ ブーツ(異常)の画像
最初に、うまくいった例です。

ご覧のようにブーツの「口」あるいは「かかと」の部分が赤くなっています。
直感的に合っているような気がします。
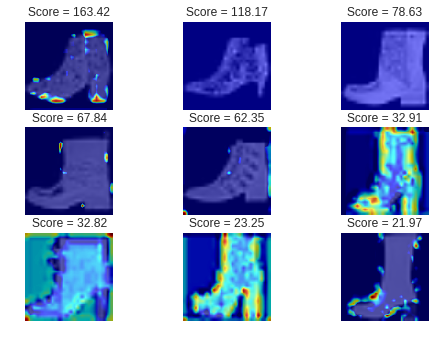
次に失敗した例です。

これらは異常スコアが最も高い、つまり最も異常な画像のベスト3です。
従って、復元が全くうまくいかず、ほとんどが赤くなっています。
次に、異常スコアが最も低い、つまり最も「正常に近い」と判断された
異常画像のベスト3です。

ご覧のようにほとんど青くなっています。
これらはスニーカーに酷似したブーツなので、仕方がないような気もします。
ラズパイによる実験
実験方法
前と同じようにナットを学習させました。
Decoderはモバイル用としました。
学習させた画像はこんな感じ。

そして、正常品として以下を用意しました。

異常品としてマジックで落書きしたナットを用意しました。

結果
・正常品

・異常品

若干左側が黄色くなっているのが分かるでしょうか。
解像度を下げたせいで分かりにくくなっています。
正直、モバイル用のDecoderは微妙です。
もう少し設計を見直せばうまくいく気もしますが、通常用のDecoderを使った方が
スマートな気がします。なお、通常用のDecoderを使うとラズパイで1FPSになります。
実際の使い方としては、普段は可視化を切っておいて、異常スコアが閾値を
上回ったときだけ、通常用のDecoderで可視化するのが良いと思います。
まとめ
- DOC'にDecoderを付けることで、DOCの可視化部分が改良できました。
- ラズパイで可視化を実行すると、速度は5FPS → 2FPS(あるいは1FPS)に下がりますが、普段は可視化機能を切ることで速度低下を抑えることができます。
付録
最後に、ラズパイ用のコードを載せておきます。
import cv2
import time
import os
import numpy as np
from sklearn.neighbors import LocalOutlierFactor
from sklearn.preprocessing import MinMaxScaler
from keras.models import model_from_json
from keras import backend as K
threshold = 2
m_input_size, m_input_size = 96, 96
path = "pictures/"
if not os.path.exists(path):
os.mkdir(path)
model_path = "model/"
if os.path.exists(model_path):
# LOF
#print("LOF model building...")
#x_train = np.loadtxt(model_path + "train.csv",delimiter=",")
#ms = MinMaxScaler()
#x_train = ms.fit_transform(x_train)
# fit the LOF model
#clf = LocalOutlierFactor(n_neighbors=5)
#clf.fit(x_train)
# Visual model
print("Visual Model loading...")
model_visual = model_from_json(open(model_path + 'model_visual.json').read())
model_visual.load_weights(model_path + 'weights_visual.h5')
# DOC
print("DOC Model loading...")
model_doc = model_from_json(open(model_path + 'model_doc.json').read())
model_doc.load_weights(model_path + 'weights_doc.h5')
print("loading finish")
else:
print("Nothing model folder")
def main():
camera_width = 352
camera_height = 288
fps = ""
message = "Push [p] to take a picture"
result = "Push [s] to start anomaly detection"
flag_score = False
picture_num = 1
elapsedTime = 0
score = 0
score_mean = np.zeros(10)
mean_NO = 0
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FPS, 2)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
time.sleep(1)
while cap.isOpened():
t1 = time.time()
ret, image = cap.read()
image=image[:,32:320]
if not ret:
break
# take a picture
if cv2.waitKey(1)&0xFF == ord('p'):
cv2.imwrite(path+str(picture_num)+".jpg",image)
picture_num += 1
# quit or calculate score or take a picture
key = cv2.waitKey(1)&0xFF
if key == ord("q"):
break
if key == ord("s"):
flag_score = True
if key == ord("p"):
cv2.imwrite(path + str(picture_num) + ".jpg", image)
picture_num += 1
if flag_score == True:
img = cv2.resize(image, (m_input_size, m_input_size))
img_ = np.array(img).reshape((1,m_input_size, m_input_size,3))/255
test = model_doc.predict(img_)
#test = test.reshape((len(test),-1))
#test = ms.transform(test)
#score = -clf._decision_function(test)
#visualization
re = model_visual.predict(test)
map_ = np.abs(re-img_).reshape((96,96,3))
jet = cv2.applyColorMap(np.uint8(255*map_), cv2.COLORMAP_JET)
#jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB)
jet = cv2.addWeighted(jet,0.2,img,0.8,2.2)
image = cv2.resize(jet, (camera_height, camera_height))
# output score
if flag_score == False:
cv2.putText(image, result, (camera_width - 350, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA)
else:
#score_mean[mean_NO] = score[0]
mean_NO += 1
#if mean_NO == len(score_mean):
# mean_NO = 0
#if np.mean(score_mean) > threshold: #red if score is big
# cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA)
#else: # blue if score is small
# cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1, cv2.LINE_AA)
# message
cv2.putText(image, message, (camera_width - 285, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
cv2.putText(image, fps, (camera_width - 164, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, ( 255, 0 ,0), 1, cv2.LINE_AA)
cv2.imshow("Result", image)
# FPS
elapsedTime = time.time() - t1
fps = "{:.0f} FPS".format(1/elapsedTime)
cv2.destroyAllWindows()
if __name__ == '__main__':
main()