※こちらはPythonデータ分析勉強会#05の発表資料です。
タイトルはこちらを使わせていただきました。
私が考えるよりナイスなタイトルを付けてくれました。感謝!
本稿は、前回の続きとなっております。

$ 正常品(スコア1.4) \rightarrow 異常品(スコア2以上)$
※なお、本稿に掲載している内容は商用・私用に問わず自由に使っていただいて
結構です。商品化やGithubへの掲載も可能です。ただし、本稿の内容に起因する
いかなる損害は一切負いかねますので、予めご了承ください。また、商品化の際は
本稿の元になった論文のライセンスも確認していただくようお願いします。
特長
今回開発した画像検査機の特長は、以下のとおりです。
- コストは1万円以下(従来品は100万円オーバーもある)
- 異常検知精度は最高峰(論文発表時点でstate-of-the-artです。詳しくは前回の記事をご覧ください。)
- コンパクト(ラズパイとWeb Cameraだけ)
- ラズパイでディープラーニングを使っているのにもかかわらず速い(5FPS)
応用範囲として、工業製品の外観検査だったり、コンパクトさを生かしてこちらに
あるようなドローンに乗せて橋梁の検査をやったり、低コストを生かしてこちらに
あるような監視カメラで使ったりと様々なシーンで使えます。
使い方
まずは、使ってみたいという方はこちらの顔認識の異常検知機を使ってみてください。
ただし、以下のライブラリ・モジュールを使えることが前提です。
- Numpy 1.15.4
- scikit-learn 0.19.2
- Keras 2.2.4
- Opencv
リポジトリの「DOC」をダウンロードして、以下の手順で実行してください。
PC上でも動作するはずです。
- 「DOC」をラズパイ上に持ってくる。
- USBにウェブカメラを接続し、DOC/main.pyを実行する。
- モデルの展開に2分くらいかかります。
- ウェブカメラのリアルタイム映像が描画されたら「s」キーを押してください。
- スコアが表示されたら、異常検査が開始されています。
- 異常検査はラズパイをフル稼働させるため、5分くらいすると熱暴走してフリーズします。長期稼働する際は、冷却しながら動かしてください。
「人の顔」が映ればスコアは下がり(正常)、それ以外が映るとスコアは上がります。(異常)
CelebAで学習させました。
技術的な内容
ここからは、自分でモデルを学習させたい方を対象に技術的な内容を掲載します。
全体の流れは、以下の図のようになっています。
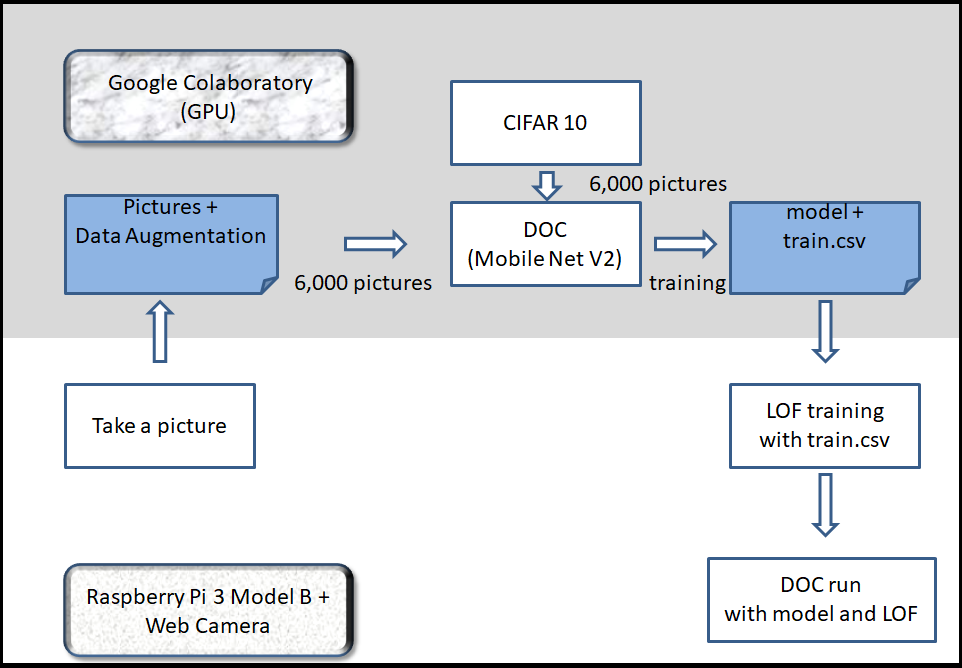
結果的に、計算負荷は大きくなかったため、全ての処理をラズパイで完結する
ことも可能です。ただ、CIFAR10をダウンロードするため、ネットワークに
つながった端末で処理する必要があります。
異常検知手法(DOC)の中身が気になる方は前回の記事をご覧ください。
学習データの取得
まずは、学習用の写真を撮影します。
以下の留意点に気を付けながら写真を撮影してください。
- ダウンロードしたDOCフォルダからmodelフォルダを削除してください(起動が早くなります)。
- ウェブカメラを接続し、DOC/main.pyを実行してください。
- ウェブカメラの映像が出たら、「p」キーを押すと、写真が撮影できます。
- 「p」キーの認識がうまくいかないこともありますので、DOC/picturesフォルダを確認しながら撮影してください。
- ちなみに、私は10枚ほど撮影しました。
main.pyのコードは付録に記載しています。
ウェブカメラの使い方は、以下の記事を参考にさせていただきました。
https://qiita.com/PINTO/items/628e45e32070777360ae
なお、私が使ったウェブカメラは正方形サイズに撮影できなかったため、
以下のように強引にサイズ変更しています。$(352\times288)\rightarrow(288\times288) $
camera_width = 352
camera_height = 288
・
・
・
image=image[:,32:320]
リサイズ
写真撮影後は、DOC/picturesフォルダをGoogleドライブにアップします。
そして、ここからはColaboratory上で処理します。Colaboratory上でGoogleドライブを
マウントする方法はこちらの記事を参考にしてください。
今回もMobileNetV2で学習させるため、以下のコードで画像をリサイズします。
import cv2
import numpy as np
import os
from PIL import Image
from keras.preprocessing import image
from keras.preprocessing.image import array_to_img
img_path = 'pictures/'
NO = 1
def resize(x):
x_out = []
for i in range(len(x)):
img = cv2.resize(x[i],dsize=(96,96))
x_out.append(img)
return np.array(x_out)
x = []
while True:
if not os.path.exists(img_path + str(NO) + ".jpg"):
break
img = Image.open(img_path + str(NO) + ".jpg")
img = image.img_to_array(img)
x.append(img)
NO += 1
x_train = resize(x)
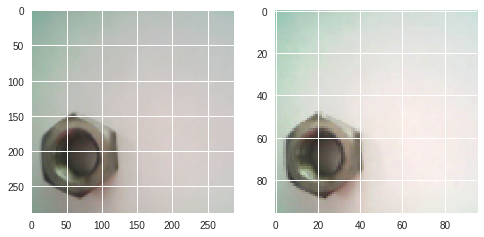
左図がリサイズ前($288\times288\times3$)、右図がリサイズ後($96\times96\times3$)。
Data Augmentation
今回、各種のデータの個数は以下のとおりです。
| 個数 | クラス数 | 備考 | |
|---|---|---|---|
| リファレンスデータ | 6,000 | 10 | CIFAR10 |
| ターゲットデータ | 6,000 | 1 | ナットの画像 |
撮影した画像(ターゲットデータ)は10枚だったので、Data Augmentationで水増しします。
from keras.preprocessing.image import ImageDataGenerator
X_train = []
aug_num = 6000 # DataAugを何枚用意するか
NO = 1
datagen = ImageDataGenerator(
rotation_range=10,
width_shift_range=0.2,
height_shift_range=0.2,
fill_mode="constant",
cval=180,
horizontal_flip=True,
vertical_flip=True)
for d in datagen.flow(x_train, batch_size=1):
X_train.append(d[0])
# datagen.flowは無限ループするため必要な枚数取得できたらループを抜ける
if (NO % aug_num) == 0:
print("finish")
break
NO += 1
X_train = np.array(X_train)
X_train /= 255
こんな感じでData Augmentationされます。

ポイントは以下のコード
fill_mode="constant",
cval=180,
画像を平行移動した際に、空白部分を埋める色を指定しました。
ここは適宜調整すると良いかと思います。
また、今回は色の違いも見たいので、通常のData Augmentationを使っていますが、
物体の形状だけを見たい場合はPCA Data Augmentationを実行すると良いかもしれません。
リファレンスデータ
今回はカラーの画像を使うため、CIFAR10の画像をリファレンスデータに使います。
from keras.datasets import cifar10
from keras.utils import to_categorical
# dataset
(x_ref, y_ref), (x_test, y_test) = cifar10.load_data()
x_ref = x_ref.astype('float32') / 255
# refデータからランダムに6000個抽出
number = np.random.choice(np.arange(0,x_ref.shape[0]),6000,replace=False)
x, y = [], []
x_ref_shape = x_ref.shape
for i in number:
temp = x_ref[i]
x.append(temp.reshape((x_ref_shape[1:])))
y.append(y_ref[i])
x_ref = np.array(x)
y_ref = to_categorical(y)
X_ref = resize(x_ref)
こちらもリサイズしています。
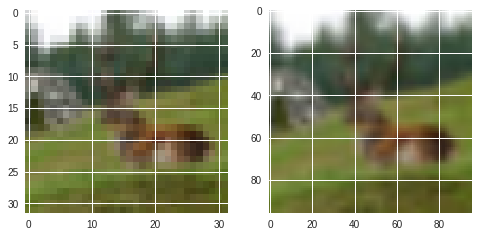
左図がリサイズ前($32\times32\times3$)、右図がリサイズ後($96\times96\times3$)。
学習
学習コードは前回のコードを流用しています。
下記のコマンドで学習させてください。
model = train(X_train, X_ref, y_ref, 5)
学習後は以下のコードでモデルを保存します。
train_num = 1000# number of training data
model_path = "model/"
if not os.path.exists(model_path):
os.mkdir(model_path)
train = model.predict(X_train)
# model save
model_json = model.to_json()
open(model_path + 'model.json', 'w').write(model_json)
model.save_weights(model_path + 'weights.h5')
np.savetxt(model_path + "train.csv",train[:train_num],delimiter=",")
これによって、modelフォルダが作成されます。
modelフォルダには「モデル」と「重み」と「train.csv」3つが入っています。
なお、train_num = 1000# number of training dataが気になる方は
LOFの高速化をご覧ください。
実行
modelフォルダをラズパイ上のDOC直下に入れてください。
そして、DOC/main.pyを実行してください。操作方法は顔認識の異常検知機と同じです。
main.py上のthresholdは閾値です。これを超えるとスコアが赤字になります。
本当は画面上にスライダを用意して、thresholdをダイレクトに変えられるように
したかったのですが、断念しました。誰か改良してくれる人お願いします。
また、異常スコアは10回の移動平均となっています。
従って、画面が変わっても2秒ほどタイムラグがあります。
結果
ナットの画像で実験した結果を示します。
なお、正常品の写真は以下のようになっています。


$ 正常品A(スコア1.3) \rightarrow 異常品(錆、スコア1.6)$
$ 正常品A(スコア1.4) \rightarrow 異常品(サイズ違い、スコア2以上)$
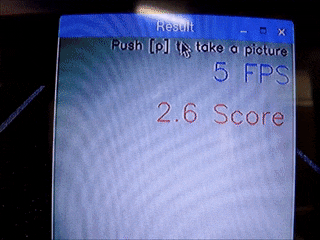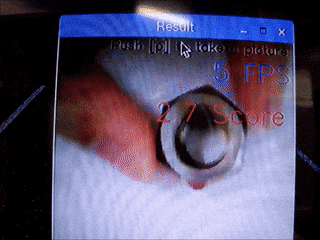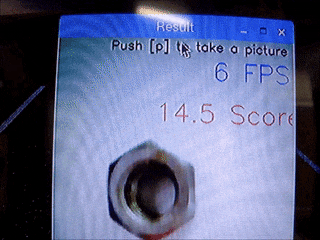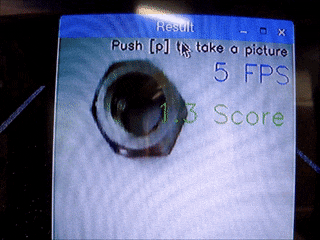
正常品Aを移動させる(位置によるスコアの差はほとんど見られない)

$ 正常品B(スコア1.2) \rightarrow 正常品A(スコア1.3) $
LOFの高速化
本編とは関係ありませんが、LOFの高速化について記しておきます。
LOFはニューラルネットワークと違って、学習データの個数によって推論時間が
大きく変わります。下の図は前回投稿したスニーカーのデータを使って、LOFの
学習データの個数と推論時間の関係を見たものです。
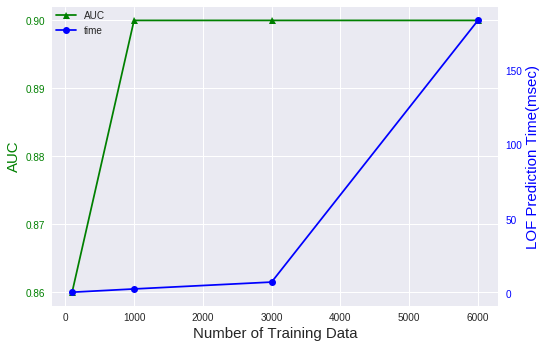
基本的に、LOFはk近傍法と同じように学習データを記憶して異常検知しているため、
学習データの個数が増えると加速度的に推論時間が上がっていきます。
ここで注目したいのは、AUCの推移は学習データ1000個のときに飽和している点です。
つまり、学習データが1000個以上あっても性能には影響を与えず、推論時間だけが増加
するということです。
そこで、今回は1000個の学習データを使ってLOFを構築しています。これにより、性能と
推論速度をバランス良く取り入れることができ、180msce以上の時間短縮となりました。
これにより、DOC+LOFの推論時間はラズパイ単体で200msec(5FPS)ほどに
なっています。ラズパイをもっとブーストしたい方は是非試してみてください!
GPUを使うと20msec(50FPS)ほどで動くこともあります。
闇の世界
何回か闇の世界に落ちかけたので、注意事項を記しておきます。
Data Augmentationの闇
ディープラーニングでは、Data Augmentationが多用されますが、元画像をリサイズして
学習させる場合は注意が必要です。
Data Augmentationの正解手順は次のとおりです。
①学習用画像を用意する。
②上記の画像で回転や平行移動する(Data Augmentation)
③リサイズ
④学習
②と③が逆になると悲惨な結果が待っています。私はこの闇に落ちました。
下の図で説明します。
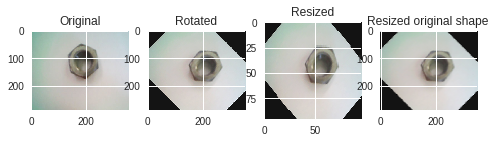
元の画像 → 回転 → 小さいサイズにリサイズ(学習用画像) → 元のサイズにリサイズ
こちらは正解手順でData Augmentationしたものです。一番右の画像を水増しした
ことになりますが、ちゃんと正常っぽい画像が水増しされました。
一方、②と③を逆にしたのが下の図です。
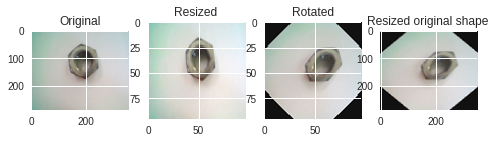
元の画像 → 小さいサイズにリサイズ → 回転(学習用画像) → 元のサイズにリサイズ
一番右の画像を水増したことになりますが、どう見ても歪んだ異常データを水増し
た結果となっています。この画像で学習させても、正しい異常検知はできないでしょう。
これらを避ける一番の解決方法は、元の画像の比率と学習用画像の比率を同じにすることです。
本稿の実装では画面の比率を1:1に統一しました。そうすれば、②と③が逆になっても大丈夫です。
scikit-learnの闇
冒頭の全体図で「なぜ、LOFをColaboratory上で学習させないのか?」と
不思議に思われた方もいらっしゃるかもしれません。
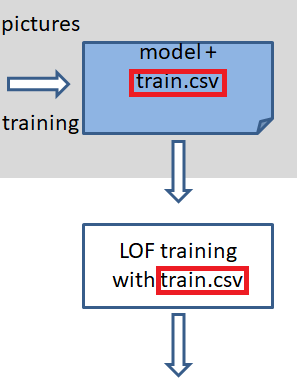
本当は、学習が早いのでColaboratory上で学習させたかったのですが、Colaboratory(64bit)で
学習させたモデルはラズパイ(32bit)に持っていけないそうです。
scikit-learnではときどき起こる現象らしく、こちらによると、今のところ修正する予定は
ないようです。従って、train.csvファイルを渡してラズパイ上でLOFを学習させています。
まとめ
- 従来の画像検査機は二値化や正常品の定義など、前処理で多くの作業時間がかかっていました。
- 本システムを使えば、写真撮影などの作業時間は10分ほどで完了し簡単に使えます。
- また、従来の検査機は照明や位置などガチガチに決めないと検査できないことがありました。
- 本システムであれば、照明や位置などある程度柔軟に対応できる可能性があります。
次回はDOCを使った他の取り組みを行います。
2019/3/7追記 可視化部分を改良しました。
https://qiita.com/shinmura0/items/c2f7a86b156ebc5c5daa
2019/5/16追記 弱異常検知(AUC:0.99)の記事を書きました。
https://qiita.com/shinmura0/items/1af83f5a5857d50cabc2
付録
最後にラズパイ用のコードを載せておきます。
import cv2
import time
import os
import numpy as np
from sklearn.neighbors import LocalOutlierFactor
from sklearn.preprocessing import MinMaxScaler
from keras.models import model_from_json
from keras import backend as K
threshold = 2
m_input_size, m_input_size = 96, 96
path = "pictures/"
if not os.path.exists(path):
os.mkdir(path)
model_path = "model/"
if os.path.exists(model_path):
# LOF
print("LOF model building...")
x_train = np.loadtxt(model_path + "train.csv",delimiter=",")
ms = MinMaxScaler()
x_train = ms.fit_transform(x_train)
# fit the LOF model
clf = LocalOutlierFactor(n_neighbors=5)
clf.fit(x_train)
# DOC
print("DOC Model loading...")
model = model_from_json(open(model_path + 'model.json').read())
model.load_weights(model_path + 'weights.h5')
print("loading finish")
else:
print("Nothing model folder")
def main():
camera_width = 352
camera_height = 288
fps = ""
message = "Push [p] to take a picture"
result = "Push [s] to start anomaly detection"
flag_score = False
picture_num = 1
elapsedTime = 0
score = 0
score_mean = np.zeros(10)
mean_NO = 0
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FPS, 5)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
time.sleep(1)
while cap.isOpened():
t1 = time.time()
ret, image = cap.read()
image=image[:,32:320]
if not ret:
break
# take a picture
if cv2.waitKey(1)&0xFF == ord('p'):
cv2.imwrite(path+str(picture_num)+".jpg",image)
picture_num += 1
# calculate score
if cv2.waitKey(1)&0xFF == ord('s'):
flag_score = True
if flag_score == True:
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)##2019.6.12追加
img = cv2.resize(img, (m_input_size, m_input_size))
img = np.array(img).reshape((1,m_input_size, m_input_size,3))
test = model.predict(img/255)
test = test.reshape((len(test),-1))
test = ms.transform(test)
score = -clf._decision_function(test)
# output score
if flag_score == False:
cv2.putText(image, result, (camera_width - 350, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA)
else:
score_mean[mean_NO] = score[0]
mean_NO += 1
if mean_NO == len(score_mean):
mean_NO = 0
if np.mean(score_mean) > threshold: #red if score is big
cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA)
else: # blue if score is small
cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1, cv2.LINE_AA)
# message
cv2.putText(image, message, (camera_width - 285, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
cv2.putText(image, fps, (camera_width - 164, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, ( 255, 0 ,0), 1, cv2.LINE_AA)
cv2.imshow("Result", image)
# FPS
elapsedTime = time.time() - t1
fps = "{:.0f} FPS".format(1/elapsedTime)
# quit
if cv2.waitKey(1)&0xFF == ord('q'):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
main()