はじめに
本記事は NSSOL Advent Calendar 2019 その2 の25日目の記事です。
はじめまして!今年から新入社員として入社したしました!
弊社の新入社員研修では、Javaや模擬プロジェクトといった研修だけでなく、業務が終わった後に自由参加でAWSを触ったり、Webサービスを構築してみたりする場が設けられていました。
私自身も自然言語処理とGANを題材にして自由活動に参加しており、新人研修の締め括りともいえる最終報告会では、実際に作成したアプリ(完成はしていませんでしたが…)を発表しました。自然言語処理とGANはゼロから勉強を始めましたが、発表の場に向けての準備や開発の経験など得られるものは多かったです。
実際に発表した題材は 「Text-to-Imageのモデルを用いていらすとやの画像をテキストから生成する」 というものです。そこで本記事では、改めてText-to-Imageの変遷をまとめ、実際にいらすとやのデータを使用して画像生成を試してみようと思います。
概要
今回は10月ごろに投稿されたText-to-Imageのサーベイ論文をもとに、主要な手法や課題をまとめていき、最後にいらすとやデータセットを使用して提案されたモデルの検証を行ってみたいと思います。
自分がやったことよりは、論文の内容によりフォーカスしている内容になっています。
また、自分で実装を行う際のメモ内容に近いので、一部わかりにくい部分があるかと思いますが留意してください。
目次
- Text-to-Imageタスクとは何か
- GANとは何か
- 手法
- 評価
- いらすとやデータセットへの適用
- 感想
1. Text-to-Imageタスクとは何か?
1.1 タスク概要
Text-To-Imageタスクとは、以下の図に示されているように任意のテキストに対して、そのテキストの意味に合う画像を生成するタスクになります。

1.2 取り組みの歴史
従来の手法では、テキストに出現する単語を表す画像を事前に準備しておき、実際の入力テキストに合わせてそれらの画像を組み合わせるような取り組みがなされていました。
しかし、GANといった深層生成モデルの発展により、近年ではテキストを入力条件として、直接画像を生成する取り組みが盛んであり、関連する論文も多く発表されています。
またこういったタスクを通して、コンピュータ補助によるデザイン設計や、画像編集、アート生成、次世代ビデオゲームのためのエンジンなどといった様々な応用先が考えられています。
Ian Goodfellow氏によって発表されたGANが行っている潜在変数から画像を生成するようなタスクに加え、Text-To-Imageでは以下の課題を解決していく必要があります。
- 画像のピクセル数に伴う高次元なデータ分布の学習
- テキストと画像間の特徴のマッピング
今回は、各論文でこれらの課題を解決するためにどのようなGANのモデルや損失関数の提案がなされてきたのかを俯瞰していきます。
2. GANとは何か?
2.1 Vanilla GAN
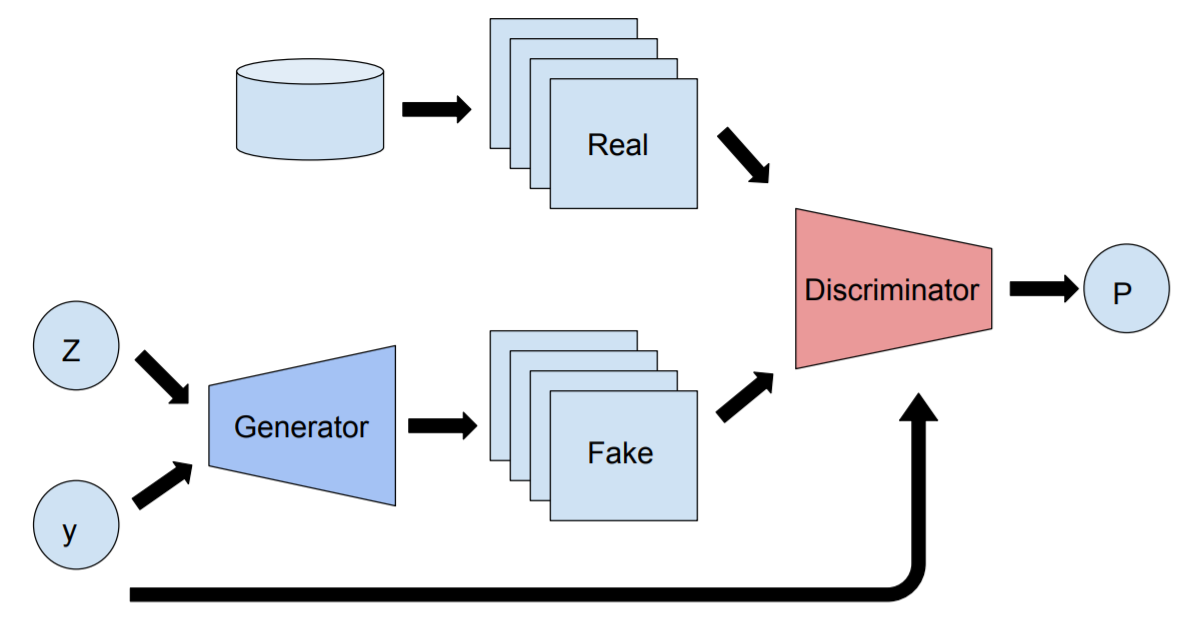
GAN(Goodfellow et al, 2014)とは2014年にIan Goodfellow氏によって発表された深層生成モデルの1種であり、GeneratorとDiscriminatorという2つのニューラルネットワークによって構成されています(以下の図がGANの基本構造です)。
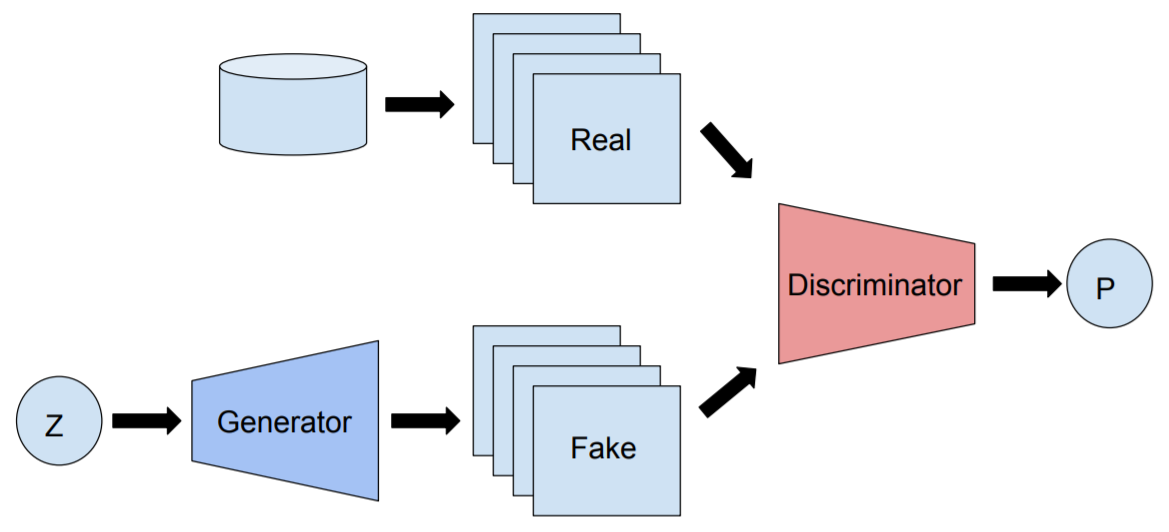
Generatorは訓練データの分布を学習させることで本物に近い画像を生成し、Discriminatorは本物の画像と偽物の画像から本物画像を識別できるようになることを目指します。この学習プロセスを続けていくと、最終的にGeneratorは訓練データと似たデータを生成できるようになっているはずです。
実際にはGANは以下の損失関数を最適化するように学習を進めます。
($z$は潜在変数、$x$は本物の画像、本物の画像のラベルは$1$、偽物の画像のラベルは$0$です。)
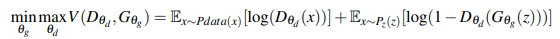
上記の式をもとにGeneratorとDiscriminatorをそれぞれ別個に学習させます。
Generatorの学習
Generatorを学習させる際には以下の数式を最適化することになります。
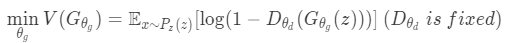
$log$の引数を最小化させる、つまり$G_{\theta_g}(z)$によって生成された偽物の画像に対し、$D_{\theta_d}$に本物の画像だと識別させる(ラベルが1だと識別させる)ことで最小化を達成できます。これでDiscriminatorを騙すような本物の画像に近い画像を生成するように学習できます。
Discriminatorの学習
Discriminatorを学習させる際には以下の数式を最適化することになります。
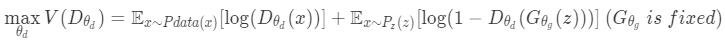
Generatorは固定されているので、各項の$log$の引数を最大化させるためには、第1項では$D_{\theta_{d}}(x)$が本物の画像だと識別(ラベルを1だと識別)させ、第2項では$G_{\theta_g}(z)$によって生成された画像を偽物だと識別(ラベルを0だと識別)させることで最大化を達成できます。これで本物の画像と偽物の画像を正しく識別できるように学習できます。
課題
理想的な状況は、GeneratorとDiscriminatorの損失関数が収束することで、Generatorは実画像に近い画像を生成できるようになり、同時にDiscriminatorは本物の画像と偽物の画像を完全に判別できるようになることです。
しかし片方のモデルのコストを削減すると、もう片方のモデルのコストが増加してしまい、これがGANの学習を難しくしています。現在ではこの問題点に関する様々な研究が進められています。
参考文献
参考記事を載せておきます。
今さら聞けないGAN(1) 基本構造の理解
はじめてのGAN
2.2 Conditional GAN
Conditional GAN(Mirza et al, 2014)はGANの発表のすぐ後に提案された条件付きの深層生成モデルです。これは元のGANの損失関数にクラスラベルによる条件付き確率を導入したものです。
cGANの損失関数は以下の数式であり、Vanilla GANとの違いはクラスラベルによる条件付きの部分のみで、ほかの部分や考え方自体は何も変わっていません。
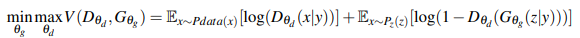
cGANの良いところは、潜在変数だけでなくクラスラベルなどの情報で条件付きの生成にすることで、出力されるサンプルを制御することに成功したことでした。
cGANをText-to-Imageに適用する際には、テキスト自体を埋め込み表現などのベクトルに変換して、これをGeneratorとDiscriminatorの入力に組み込み、生成される画像を制御します。
なおその際に条件となるテキストが実画像と紐づいていることが重要です。条件として"黄色の鳥"を入力として与えているのに、赤色の鳥の実画像を与えると誤って学習してしまいます。
2.3 Text-to-Image cGAN
cGANの弱点としては、複雑な条件を取り扱うことができないことです。cGANではラベル情報をモデルに与えるためテキストのように入力数が不定のような状況では使用することができませんでした。
しかし、cGANの考え方を基礎として様々なText-To-Imageのモデルが提案されています。以下の図が、提案されている応用モデルの典型的なパターンになります。
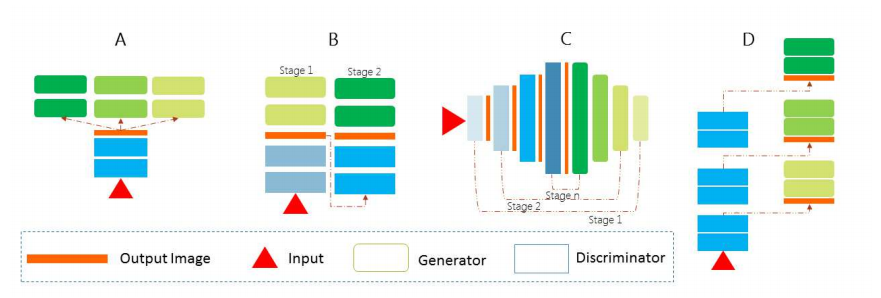
以下で提案されているText-To-Imageを俯瞰していきますが、提案モデルが上記の中のどの構造を採用しているのか把握することで、モデルを分類するときの1つの指針にすることが可能です。
3. 手法
今回紹介している論文では、それぞれのGANのフレームワークを4つのカテゴリに分類しています。テキストから画像を生成する際、人間がどのように画像を構築していくのかを考えていきます。重要な点は、人によって同じテキストであっても考え付く画像が異なることです。
- Semantic Enhancement GANs
- 1つ目のグループでは、テキストの意味を正確に理解し、意味合いに沿った画像を生成する人たちを想定しています。
- この分類では、入力テキストをニューラルネットを使用することで畳み込み表現などに変換し、そのテキストに合うように異なるニューラルネットを使用して画像を生成します。
- Resolution Enhancement GANs
- 2つ目のグループでは、テキストの意味を正確に理解したうえで、より画像を鮮明に描いたり、背景を凝って描くような人たちを想定しています。
- この分類では、画像を生成するニューラルネットを複数使用して、多段構成にすることでより高解像度な画像を生成します。
- Diversity Enhancement GANs
- 3つ目のグループでは、テキストの意味を正確にとらえたうえで、外観や色などを変化させることで多様性のある画像を描く人たちを想定しています。
- この分類では、出力画像の多様性を向上させるために、テキストと画像の意味合いがどの程度似ているのかを計算する要素が追加して画像を生成します。
- Motion Enhancement GANs
- 4つ目のグループでは、テキストにあった画像を描くだけでなく、時系列に沿ったモーション情報などを描く人たちを想定しています。
- この分類では、まずテキストに記載された動きに関する画像を生成し、その後に生成した画像を時系列に沿って整える処理を加えて、一連の画像を生成します。
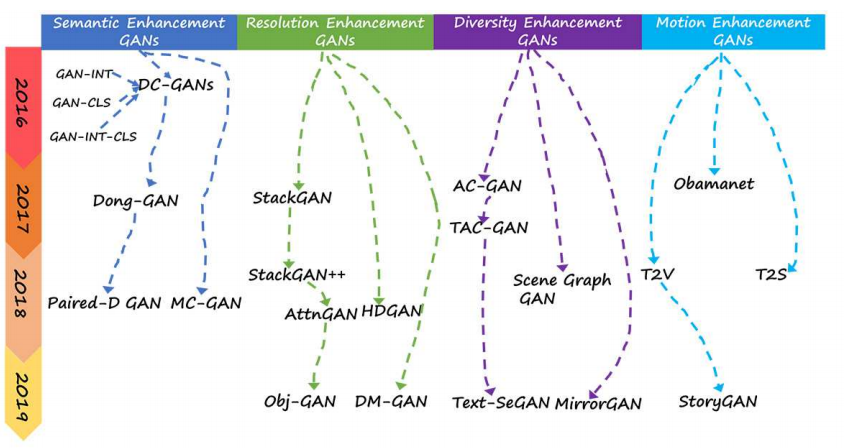
本記事では、上記の図に記載されている各種モデルの貢献した部分や課題をまとめていきます。
※Motion Enhancement GANに関しては、今回取り組んだテキストから 画像 を生成するだけのタスクではないので、詳細は省きたいと思います。
※ただ今後追記していくこともあるかもしれません。
3.1 Semantic Enhancement GAN
3.1.1 DC-GAN
DC-GAN(Reed et al, 2016)とは、Text-To-Imageタスクに対してGANを適用した初めての手法です。同じ論文内でGAN-CLSやGAN-INTといったコンポーネントを提案しています。
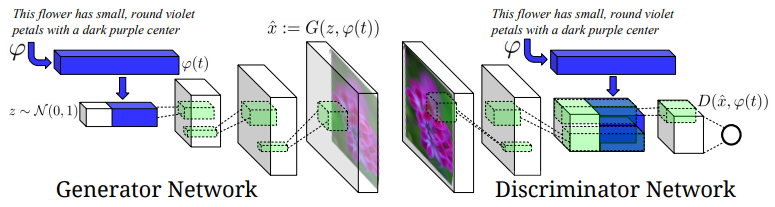
上記にDC-GANの構造を載せています。
まず、入力となるテキストをRNNなどを使用して埋め込み表現$\varphi(t)$として取得します。次にこの埋め込み表現を線形結合層を使用して低次元に圧縮し、別の入力である潜在変数$z$に結合させてGANへの入力とします。
GANは通常の画像生成と同様に、転置畳み込みを使用して次元数を上げていきます。
Discriminatorの処理としては、まずは画像を入力として受け取り、$4\times4$の大きさになるまで畳み込み層とストライド層で計算を行います。その後に、Generatorの入力と同様に埋め込み表現$\varphi(t)$として獲得したテキストの入力を線形結合層を使用して次元数を圧縮し、Discriminatorの出力する画像の特徴量の次元に合わせて複製を行います(今回は$4\times4$のサイズに複製します。)。
次に$1\times1$畳み込みを使用して特徴量を圧縮し、最後に$4\times4$畳み込み層を使用して最終的な確率を出力します。
なおテキストを埋め込み表現にマッピングする手法としては、Char-CNN-RNNモデル(Reed et al, 2016)を事前学習させることを採用しています。
3.1.2 GAN-CLS
Text-To-ImageタスクにおいてcGANを学習させる単純なやり方としては、テキストと画像のペアをDiscriminatorに渡して、このペアが本物か偽物なのかを識別できるようにすることです。この手法では、テキストと画像の意味があっているのか明確に計算することはありません。
そこでDiscriminatorが識別する学習ペアを以下のように追加することで、Generatorに追加のシグナルを与えることができます。このDiscriminatorを matching-aware discriminator と呼びます。
- Discriminator(本物の画像、画像に合うテキスト) → Real
- Discriminator(偽物の画像、画像に合うテキスト) → Fake
- Discriminator(本物の画像、画像に合わないテキスト) → Fake
- この項を追加することで画像とテキストの整合性も学習するようにします。
以下が実際に適用するアルゴリズムになります。

3.1.3 GAN-INT
深層学習で獲得した特徴量に関して、学習した特徴量ベクトルのペアを補間した特徴量ベクトルも、同じ多様体の近くに存在することが知られています(Bengio et al., 2013; Reed et al., 2014。
この考え方をもとに、テキストの埋め込み表現のペアで補間したデータを、学習データに使用するようにしたモデルが GAN-INT になります。
当然新たに補間されたデータは、実データに存在するどのテキストにも合致することはありません。そこでこの新たに生成された埋め込み表現をGeneratorの損失関数に追加します。実際に$\beta=0.5$の場合、うまく動作することが確認されています。
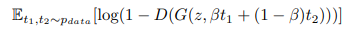
Discriminatorに対して、この合成されたテキストに合致する本物の画像は存在していません。しかし、Discriminatorは画像とテキストの意味があっているのかを識別するので、Discriminatorがうまくこのタスクを満たすように学習できている場合、Generatorは訓練データ間の多様体内のギャップを埋目るような画像を生成できるようになります。
3.1.4 Dong-GAN
Dong-GAN(Dong et al., 2017)では、実在している画像に対して、追加したい要素を記述しているテキストを与えることで、元の画像を編集することに成功したGANのモデルになります。
ベースとなるモデルは、DC-GANの論文内で提案された、GeneratorをStyle Transfer用に反転させたモデルです。
テキストの埋め込み表現$\varphi(t)$が画像の内容(花の形や色など)を反映できている場合、本物のような画像を生成させるためには、Generatorに入力する潜在変数$z$には、背景色や姿勢といったテキストに表現されていない情報が含まれていてるべきです。
そこで生成されたサンプルから元の入力された潜在変数を復元することで、画像のスタイルをエンコーダー$S$に学習させます。その際に以下のような損失関数がReedらによって提案されました。
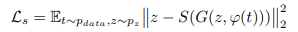
上記のモデルの弱点としては、エンコーダーがGeneratorによって生成された偽物の画像でしか学習しないことであり、実際にはGeneratorが実画像の分布を学習することは困難であるため、うまく実画像の埋め込み表現が得られない可能性があります。
以下の図がDong-GANのモデルの構造であり、画像から学習した潜在表現とテキストの埋め込み表現を結合させることで、Decoder側の画像生成を行うネットワークの入力としています。
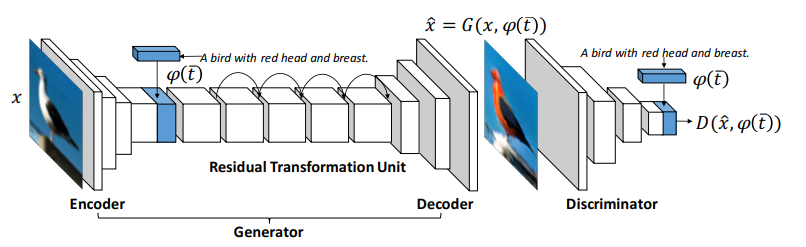
Dong-GANでは、学習させるデータのペアとして3つの種類を提案しています。
(学習に使用するテキストをそれぞれ、画像に合うテキストを$t$、画像に合わないテキストを$\hat{t}$、意味合い的には似ているが正確には画像に合っていないテキスト$\bar{t}$とします。)
Discriminatorの出力としてはこの3つの種類への分類確率です。
- $s_{r}^{+}$ ← $D(x,\varphi(t))$:実画像と意味の合うテキスト
- $s_{w}^{-}$ ← $D(x,\varphi(\hat{t}))$:実画像と意味の合わないテキスト
- $s_{s}^{-}$ ← $D(\hat{x},\varphi(\bar{t}))$:生成画像と意味が似ているテキスト
ここで$\bar{t}$を導入したことによって、以下の2点がうまくいくようになっています。
1つ目は、画像に対してテキストが意味の合わないものであるときに、Generatorが本物のような画像を生成することを防ぐことができます。
2つ目は、似ているだけのテキストを敵対的学習に使用することです。学習初期段階ではGeneratorは本物のような画像を生成することはできないため、Discriminatorはテキスト情報を使用することなく識別できてしまいます。
そこで以下の組み合わせを考慮して意味が似ているテキスト$\bar{t}$を利用する理由を見ていきます。
- $s_{s}^{-}$のペアで意味の合わないテキスト$\hat{t}$を使用してしまうと、Generatorは最終的に$\hat{t}$に合うような画像を生成してしまい、これは本来のテキスト$t$と何も関連性のないテキストであり、意味合いがあっていない画像を生成してしまうことになります。
- $s_{s}^{-}$のペアで意味の合うテキスト$t$を使用してしまうと、Generatorが実画像に近い画像を生成するとパターンとして$s_{r}^{+}$と同じになってしまい、Generatorはテキスト情報を無視して常に画像を生成するようになります。つまり過学習してしまいます。
- $\bar{t}$はペアとなる画像と関連性があること自体は保証されているので、学習時に使用することで過学習を防ぐことができます。
これらを考慮すると以下の損失関数を導入します。
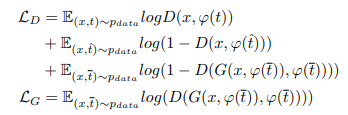
Dong-GANでは、補間されたテキストを使用して学習のペアを新たに考えだしたことがポイントです。
3.1.5 Paired-D GAN
Paired-D GAN(Vo and Sugimoto 2018)では、画像の中で前面側に配置されている物体と背景に描かれている物体の識別を行う2つのDiscriminatorによって構成されたモデルです。
前面に存在する物体を識別するためにテキストと生成画像がマッチしているかどうかを学習を行うDiscriminatorと、入力された実画像と生成画像を比較して背景の要素が保存されているかどうかを識別するDiscriminatorによって構成され、Generatorと合わせて3つのモデルを使用して敵対的学習を進めていきます。(以下の図はPaired-D GANの構造になります。)
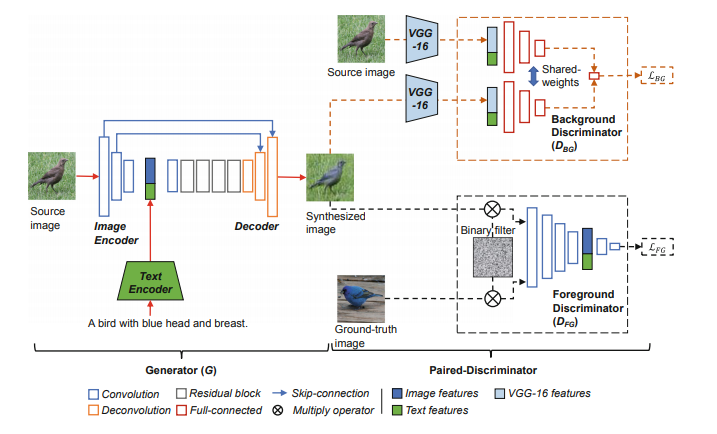
Generatorの構造はDong-GANで提案された構造と同じものを採用しており、エンコーダーとデコーダーによって構成されています。
なお学習段階では使用している画像の値を$[-1,1]$の範囲に変換しています。
また浅い層で生成された画像の背景情報を特徴量として学習させるために、エンコーダーの浅い層とデコーダー側の深い層をSkip-Connectionによって接続しています。
前面の物体を学習させるDiscriminator($D_{FG}$)に関しては、損失関数はDC-GANで提案された損失関数を採用しています。
なおこのDiscriminatorには、画像をそのまま入力させるのではなく、各ピクセル値を0か1で表現しているマスク画像を適用します。こうすることで、画像全体を見るのではなく対象の前面にある物体のみに焦点を当てることができ、効果的に特徴量を学習させることができます。また、学習の収束を早めることができることも確認されています。
背景情報を学習するDiscriminator($D_{BG}$)では、入力された実画像と生成画像の背景がどの程度異なっているのかを判定します。しかし学習に使用する画像の中で、背景が非常に似通っているものなどは数多く存在しているわけではないため、Metric Learningなどで活用されるSiamese Networkを使用しています。
学習を行う際は、3つのモデルのうち学習対象のモデルのみに限定し、残りの2つのモデルのパラメータは固定するようにしておきます。
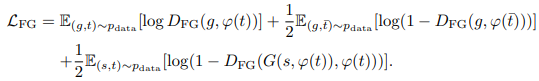
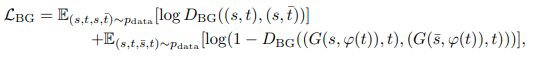
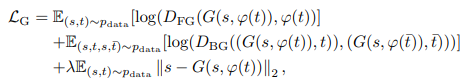
Paired-D GANでは、前面の物体と背景を異なるDiscriminatorで識別させるようにした部分がポイントです。
3.1.6 MC-GAN
MC-GAN(Park et al., 2018)では、学習段階で全面の物体を識別できる特徴量と背景の情報を識別できる特徴量を分離させる要素をモデルに追加することで、実画像と入力テキストを使用して、追加の物体を画像中の任意の場所に配置するような画像の編集を行うことができるようになりました。
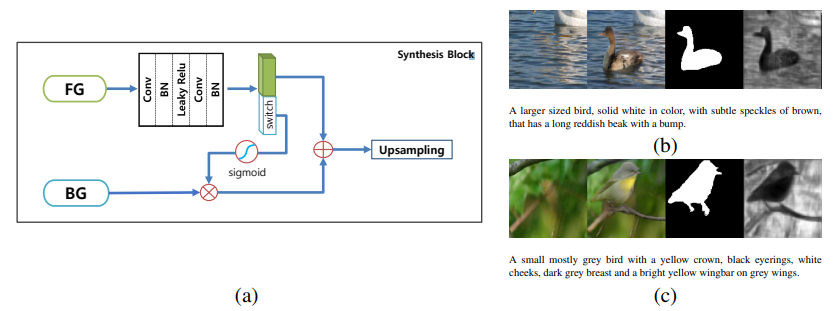
MC-GANで新たに提案された合成ブロックでは、背景情報($BG$)は入力された画像から抽出し、前面の物体($FG$)に関する情報は直前の層の特徴量マップをから抽出します。
$FG$は途中の畳み込み層で特徴量のチャンネル数を2倍に拡大させ、半分を$BG$へ適用させ、もう半分を次の合成ブロックに渡します。
以下の画像中の(b)と(c)はそれぞれ左から、(1)画像内から切り取られた背景領域、(2)生成された画像、(3)生成されたマスク画像、(4)switch層で取得した特徴量マップになります。
Generatorでは以下の画像の左端にあるテキストの埋め込み表現$\varphi{(t)}$、右端にある画像内から切り取られた画像を入力とします。
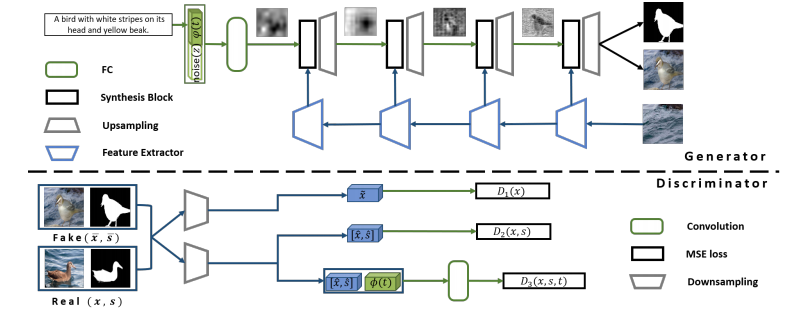
Discriminatorは、生成された画像$x$、生成されたマスク画像$s$、テキスト情報$t$のペアを入力にしています。使用するペアの種類としては以下の4種類になります。
- $(x_{1},s_{1},t_{1})$:実画像と画像に合うテキスト、およびマスク画像
- $(x_{1},s_{1},t_{2})$:実画像と画像に合うマスク画像、および意味の合わないテキスト
- $(x_{1},s_{2},t_{1})$:実画像と画像に合うテキスト、および意味の合わないマスク画像
- $(x_{g},s_{g},t)$ :生成画像と生成マスク画像、および入力のテキスト
これらのペアを使用して、入力情報がどのペアなのかを分類するDiscriminatorの損失関数を計算します。
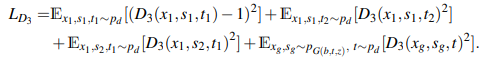
画像とマスク画像を使用するDiscriminatorの損失関数としては、以下のように各ペアの分類を行います。
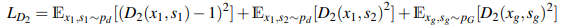
また実画像と生成画像を使用するDiscriminatorの損失関数としては、以下のように画像の判定を行います。
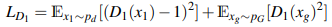
Generatorに関しては、生成される画像の識別をDiscriminatorが間違えるようにする項と、Conditioning Augmentationで導入された正則化項、背景画像への再構成損失の項で構成されます。
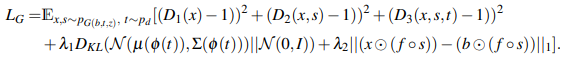
MC-GANでは、マスク画像を生成することで、テキストから任意の場所に物体を編集することができるようになったことがポイントです。
3.2 Resolution Enhancement GAN
3.2.1 StackGAN
StackGAN(Zhang et al., 2017)では、GANを多段構成にすることによって、最初のステージのGANで大枠をとらえた低解像度な画像を生成し、以降のステージのGANでより高解像度な画像を生成することに成功しました。
またConditioning Augmentationという手法を使用することで、cGANの学習を安定させ、生成される画像の多様性を改善することに成功しました。
(以下の図がConditioning Augmentationになります。)
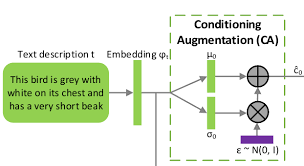
テキスト表現をエンコーダーを使用して埋め込み表現に変換する場合、非線形に変換する結果、通常高次元のベクトルになってしまいます(100次元以上)。データセットの量に制限がある場合は、高次元の潜在空間内で非連続な状態になってしまい、Generatorに与える入力も同様に制限されてしまいます。
そこでエンコーダーによって固定値の埋め込み表現を利用するのではなく、上図で示されているように埋め込み表現に対して、ガウス分布のノイズを加えることで、同じ画像に対して変動が加えられた埋め込み表現を獲得できるため、より頑強なモデルを学習させることが可能です。
また過学習を抑えるために以下の数式であらわされる正則化項をGeneratorに導入しています。
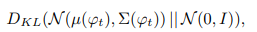
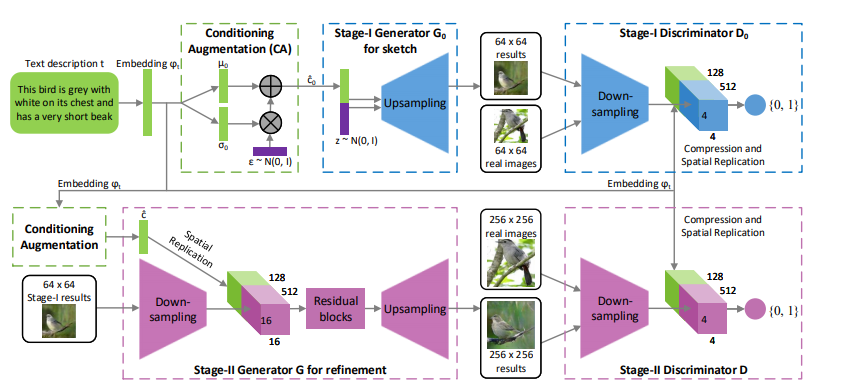
上図がStackGANの構造になります。まず最初のステージのGANでは、低解像度の画像を生成することを目的としており、Conditioning Augmentationによって変動が加えられたテキストの埋め込み表現$\hat{c_{0}}$と潜在変数$z$を結合させたベクトルを入力として受け取ります。
2つ目のステージのGANでは、より高解像度な画像を生成すること、かつ初期ステージで生成された低解像度な画像の細部を描画することを目的としています。入力には、初期ステージと同様にConditioning Augmentationによって変動が加えられたテキストの埋め込み表現$\hat{c_{0}}$と、初期ステージで生成された低解像度の画像を使用します。
採用しているDiscriminatorは各ステージで基本的な構造は変わっていません。GAN-CLS(Reed et al., 2016)によって提案されたmatching-aware Discriminatorを使用しています。
最初のステージと2つ目のステージの基本的なモデル構造は変化していないので、損失関数に関してもどちらとも似通った数式になります(入力などが異なります)。
- Stage-I
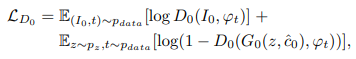
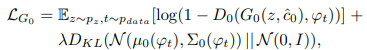
- Stage-II
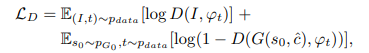
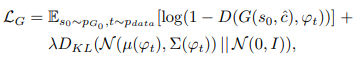
StackGANでは、GANを多段構成にすることでより高解像度の画像を生成することに成功し、Conditioning Augmentationによって学習データを増強できるようにしたことがポイントです。
3.2.2 StackGAN++
StackGAN++(Zhang et al., 2017)では、従来のStackGANが各ステージごとに独立して学習させる必要があった状態から、複数のスケールの画像を複数のGeneratorを用いて生成することで、end-to-endに学習できる状態を目指したモデルです。
GeneratorはそれぞれのDiscriminatorからの誤差をまとめて学習することができ、異なるスケールの分布を同時に近似していくことができます。これで最初のGeneratorとDiscriminatorでは、基本的な色や構造を学習し、それ以降の層ではより詳細な部分を学習してくことが期待されます。
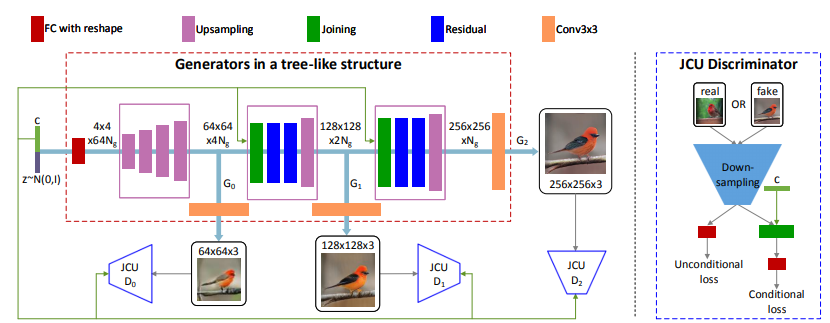
まずは上図のピンクで囲われている部分で、ノイズやテキスト・前の層の特徴量などを使用して、各層で異なる特徴量$h_{i}$を学習することができます。
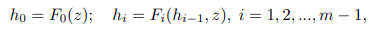
次に各層で学習できた入力に対する特徴量を使用して、実際に画像の生成をGeneratorで実行します。
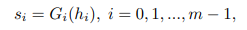
最後に各層のDiscriminatorによって本物の画像か偽物の画像かを識別させることで学習を進めていきます。
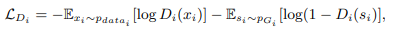
これら複数のDiscriminatorからの誤差をGeneratorでは一度に学習させます。
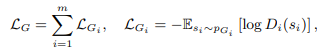
このStackGAN++モデルでは、従来はテキストと画像をペアとして識別させることで条件付きの画像分布を近似させていた部分を、条件付きと条件付きでない両方の分布に近似させています。
従ってGeneratorとDiscriminatorの両方とも損失関数は、以下のように条件付き分布への近似の項と、非条件付き分布への近似の項の2つで構成されます。
Discriminator(JCU Discriminator)
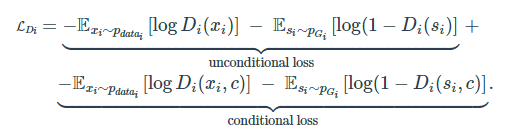
Generator
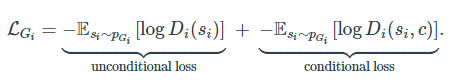
StackGAN++では、新たにColor-Consistency正則化を追加しています。
複数のスケールで生成される画像に対して、当然基本的な構図や色などはどのスケールであっても同じであるべきです。この制限を損失関数に追加することで、生成される画像の質を向上させることができます。
考え方はとてもシンプルで各スケールで生成される画像に対して、全ピクセルに対する平均値と共分散が同じになるように損失を計算します。
($s_{i}^{j}$は$i$番目のGeneratorによって生成された$j$番目の画像)
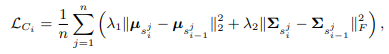
StackGAN++では、複数のスケールの画像生成を行うGeneratorをend-to-endで学習させることに成功したこと、またColor-Consistencyによって異なるスケールの画像の特徴に一貫性を持たせることができたことがポイントです。
3.2.3 AttnGAN
AttnGAN(Xu et al., 2017)では、従来入力されるテキスト全体の埋め込み表現のみを使用して画像を生成していた状態から、単語レベルの埋め込み表現も活用することで、より詳細な画像を生成することに成功しました。また画像とテキストの類似度を単語レベルと文レベルの両方で評価できるモジュールの提案も行っています。

上記の図では、各スケールで生成された画像と、AttnGANのモデルが、入力された各単語に対して画像のどの領域をより詳細に描いているのかを表しています。
モデルの構造はAttention機構以外はStackGAN++と同様の構造となっています。
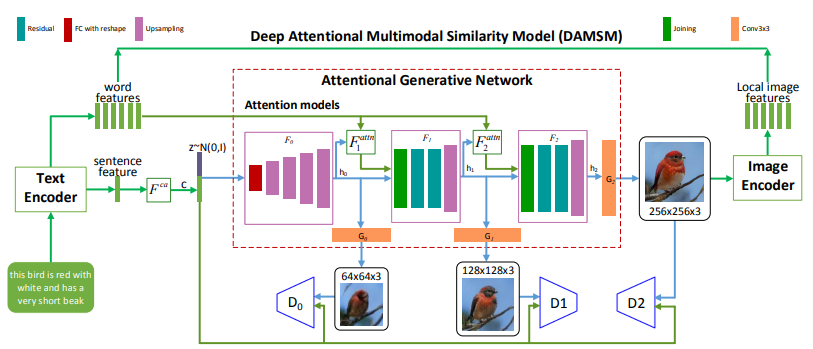
まずは潜在変数$z$と文レベルの埋め込み表現にConditioning Augmentationを適用したベクトル$\bar{e}$を入力し、最初の層の特徴量を学習させます。
2層目以降の計算では、1つ前の層の特徴量$h_{i-1}$と、単語レベルの埋め込み表現$e$と1つ前の層の特徴量$h_{i-1}$をもとに計算された重み付けされた$c_{i-1}$を入力として、特徴量$h_{i}$を生成します。
ここまで計算が終了した後で、その層の特徴量$h_{i}$を使用してGeneratorで画像を生成します。
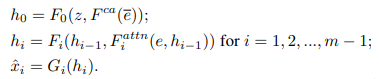
このAttentionモデルで実行している画像の小領域と単語レベルの埋め込み表現の計算イメージは以下のようなものです。
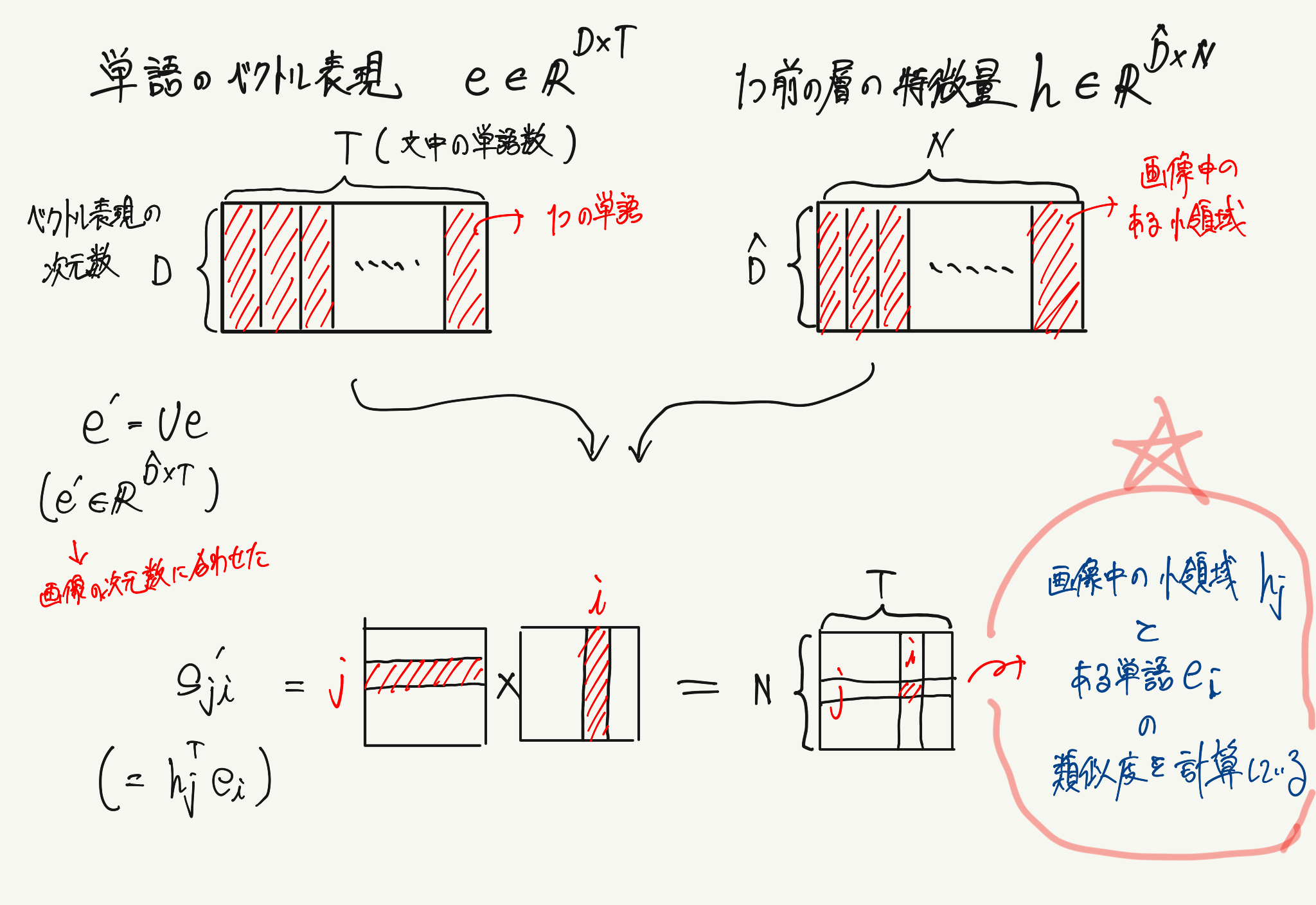
まずは通常のAttention機構と同様に重み付きを計算する対象のベクトル群に対して、類似度を計算します。
最後に計算された重み付きを使用して、元のベクトルとの重み付き和を計算すれば終了です。
AttnGANでは、単語レベルの埋め込み表現と対応する画像を、同じ特徴量空間にマッピングすることで画像とテキスト間の類似度を計算するDAMSM(Deep Attentional Multimodal SimilaDeep Attentional Multimodal Similarity Model)モジュールを提案しています。
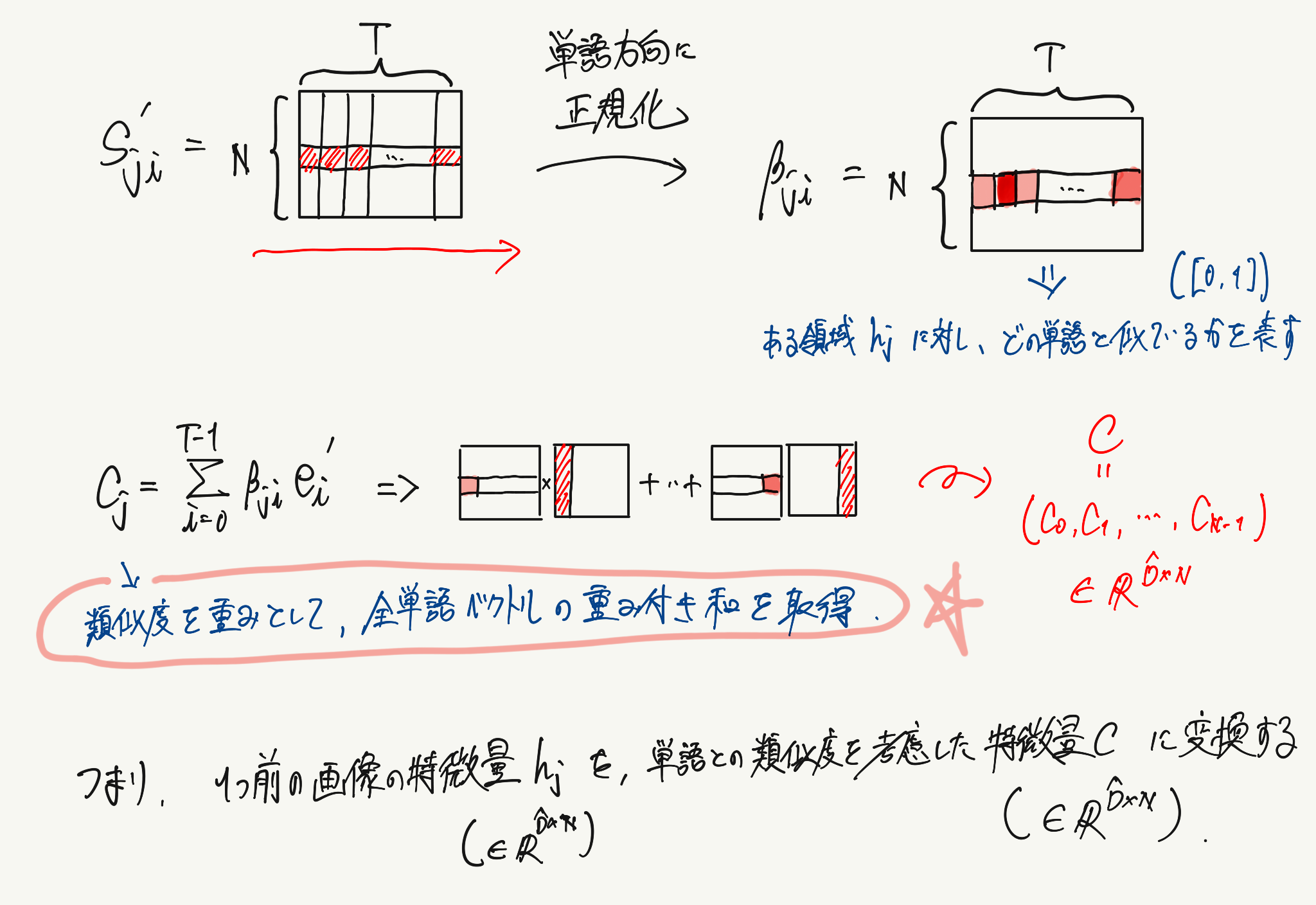
このmatching scoreを算出する際に行っている計算のイメージは以下のようになります。
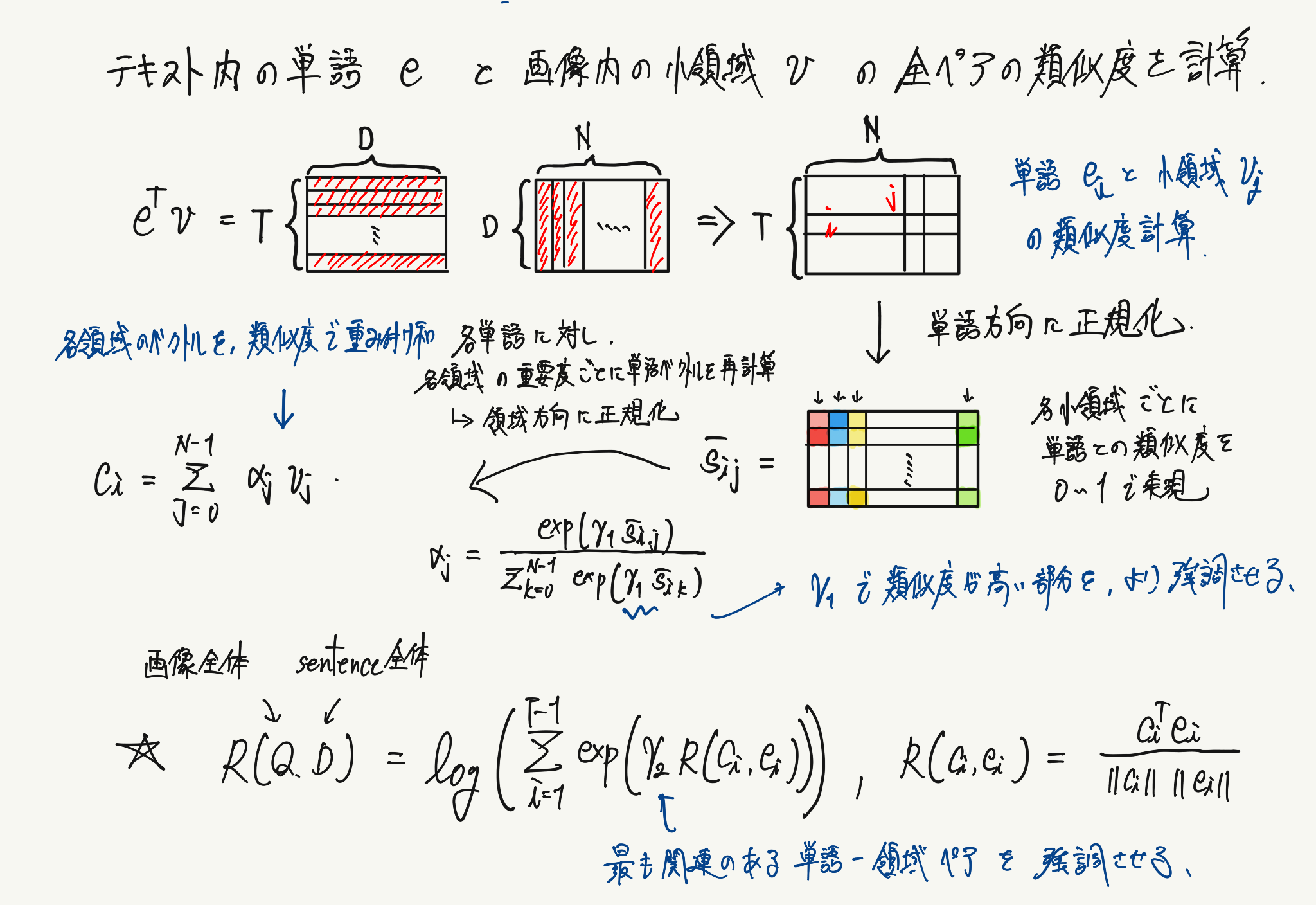
画像の特徴量の次元数を単語の特徴量の次元に変換し、同じ特徴量空間に落とし込んだ後でベクトルの類似度を計算しています。

DAMSM損失関数の計算では、単語と画像に関する事後分布に対して、負の対数尤度を計算することで算出することが可能です。
単語と小領域、文と画像全体の2つに対して、事後分布を互いに計算するので、最終的に得られる損失関数の式は以下になります。
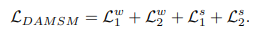
AttnGANでは、Attention機構を使って単語情報を活用できるようにしたこと、またDAMSMの提案によりエンコーダーの事前学習ができるようになったことがポイントです。
3.2.4 Obj-GAN
未完成です。patch部分の処理が追いきれませんでした…
追記する際に修正します…
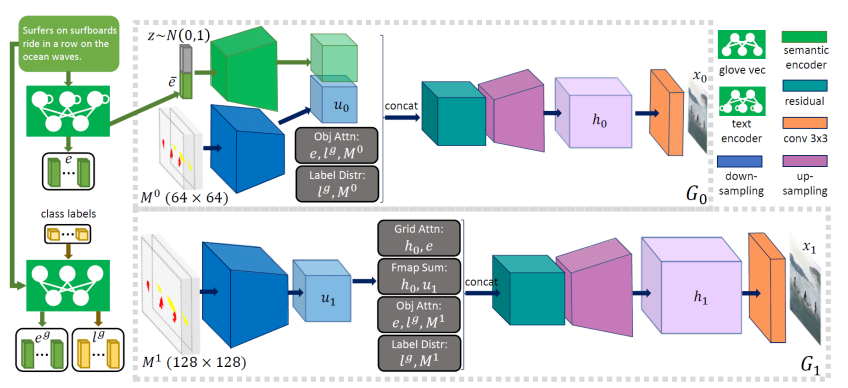
Obj-GAN(Li et al., 2019)では、レイアウトを生成するプロセスと、単語レベルの情報から物体の細部まで描画した画像を生成する2つのプロセスで構成されるネットワークになります。
テキストから画像を生成するモデルは、鳥や花のデータセットのような単純な画像に対してはリアルな画像を生成できています。しかしCOCOデータセットのような複雑な画像に対しては、物体の細部と互いの関連性を描き切ることができていません。

実際にAttnGANを使用して、”Several people in their ski gear are in the snow”というテキストを与えても、人やスキー板などを描画できておらず、またスキー板の上に人が乗っているような位置関係も表現できていません。
この問題を解決するために提案されたObj-GANの構造は以下のようになります。
モデルの入力には、事前学習済みの双方向LSTMを使用し、単語($e\in \mathbb{R}^{D\times T}$)と文($\hat{e}\in\mathbb{R}^{D}$)の埋め込み表現を使用します。
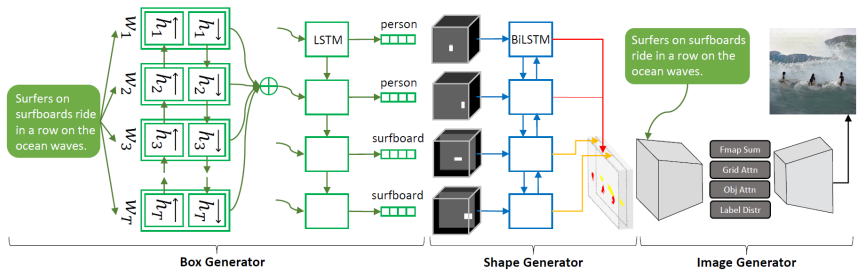
まずモデルはテキストの単語の埋め込み表現を、注意機構付きのSeq2Seqモデルに投入し、各単語に対してのクラスラベルとバウンディングボックスを計算します。
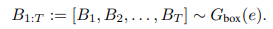
この$B_{t}$はクラスラベルとバウンディングボックスで構成されています($B_{t}=(l_{t},b_{t})$)。
ここで計算された$B_t$と対応するノイズベクトル$z$を、次の双方向LSTMを使用しているShape Generatorプロセスの入力にします。
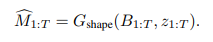
ここで生成されたレイアウト画像を次のImage Generatorプロセスで使用します。
このプロセスは2つのAttention機構付きのGeneratorで構成されています。
それぞれのネットワークで行っている処理は複雑なので、まずは全体の数式を俯瞰した後で個々の要素を見ていきます。
それぞれのネットワークで画像を生成する直前の特徴量($h_0,h_1$)を取得するまでの処理は以下の数式であらわされます。
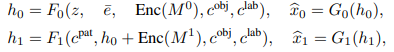
($c^{pat}$はpatch-wise context vector、$c^{obj}$はobject-wise context vector)
ここで出てくるPatch-Wise Context VectorもObject-Wise Context Vectorも画像に対して特定の領域を示しているベクトルであり、画像の特定領域と最も関連している単語からベクトルの情報をエンコードしています。
※追記します。
3.2.5 HDGAN
HDGAN(Zhang et al., 2018)では、1つのGeneratorを使用して複数のスケールの画像を生成することで、テキストから高解像度な画像を生成することに成功しました。
Generatorの中間層から出力された各スケールの画像に対してDiscriminatorを適用します。
Generatorでは、まず潜在変数$z$と、文レベルの埋め込み表現$t$を入力として、各スケールの画像($X_{1}, \ldots, X_{s}$)を出力します。
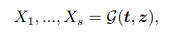
これらの画像に対してそれぞれDiscriminatorを適用させることで、低解像度の画像に対しては画像内の基本構造(物体の外観や色など)を識別できるようになり、続く高解像度の画像に対しては、物体のより詳細な部分を描画できるようになることが期待されます。
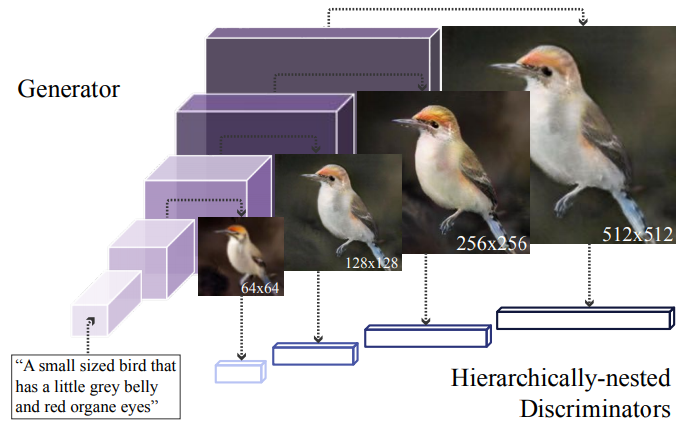
途中で生成される各解像度の画像に対して、意味が一貫しておりテキストに合った画像であることを保証する必要があります。そこでDiscriminatorの構造としてDC-GAN(Reed et al., 2016)で提案されたmatching-aware discriminatorを採用しています。
しかしこのDiscriminatorでは入力された画像が、本物の画像なのか偽物の画像なのか区別できるようにするための明確な損失関数は存在していません(行うことはあくまでもペアの分類です)。これら複数のタスクを1つのネットワークで実行することは非常い難しいです。
また、画像が高解像度になるにしたがって、画像全体のペア損失を計算するだけでは、全体の特徴を捉えることはできても画像の細部まで特徴を補足することは難しいです。
そこでそれぞれのDiscriminatorを2つのサブネットワークに分けます。1つ目は、画像を入力として受け取りペアがどの種類なのかを判定するネットワークであり、2つ目は、画像をパッチ領域に分けて各パッチ画像に対して本物の画像か偽物の画像なのかを判定させるネットワークです。
(Patch GANはpix2pixの論文で提案されました。)
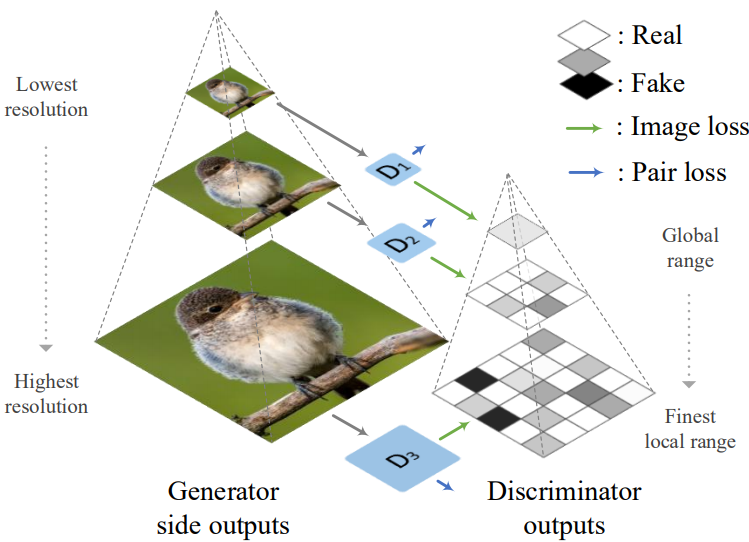
これらのネットワーク構造を考慮した場合の損失関数は以下のように定義できます。
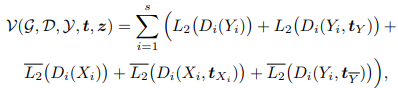
HD-GANでは、1つのGeneratorに対して複数のDiscriminatorを使用することで高解像度の画像を生成することに成功したこと、またPatchGANを導入することで異なるタスクをDiscriminatorに解かせることに成功したことがポイントです。
3.2.6 DM-GAN
DM-GAN(Zhu et al., 2019)では、Stack構造を有するモデルにメモリ構造を導入することで、入力されるテキスト対して重要度を計算し、各層で画像を生成する際に使用する情報を分けることで高精度な画像を生成することに成功しました。
Text-To-Imageのタスクで高精度な画像の生成に成功したStack構造を有するモデルには、以下の問題点が存在しています。
- 最初ステージの画像生成が失敗した場合、後のステージで高精度な画像を生成することは難しい
- 画像をより詳細に描いていく各ステージで、同じ単語の埋め込み表現を使用しており非効率である
DM-GANではこの問題に対処するために、それぞれ以下の提案を行っています。
- メモリ構造を持たせたネットワークに初期の生成画像をクエリとして与えて、初期の生成画像を修正する特徴量をメモリネットワークから取得する
- 生成された画像に関連する単語を動的に選択できるmemory writing gateを導入し、画像を生成する各ステージで使用するテキスト情報に重み付けを行う
DM-GANは(1)初期画像の生成と(2)高解像度な画像をベースにしたメモリ構造の2つの要素で構成されています。
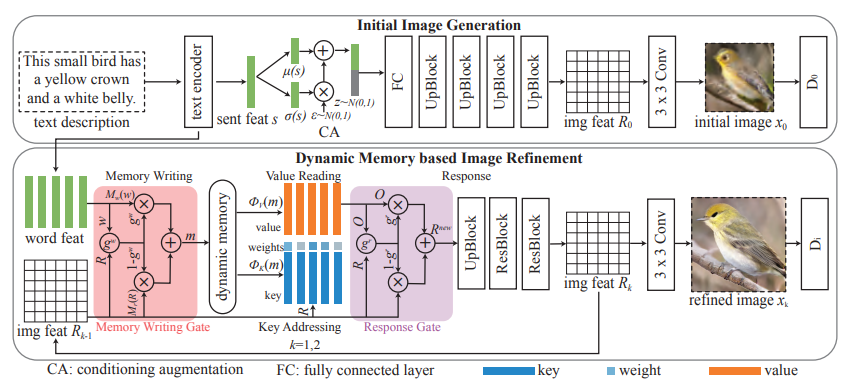
最初はStackGANなどと同様に、テキストをエンコードして得られた文レベルの埋め込み表現を、Conditioning Augmentationを行い得られたベクトルと潜在変数$z$を使用して、低解像度の画像の特徴量(画像ではないことに注意)を生成します。
より高解像度な画像を生成する際は、メモリ構造のネットワークを適用します。
メモリ構造の要素は以下の4つです。
- Memory Writing
- Key Addressing
- Value Reading
- Response
このメモリ構造のネットワークへの入力は以下になります。
($T$は単語数、$N_w$は単語の特徴量の次元数、$N$は画像のピクセル数、$N_r$は1つのピクセルを表現する特徴量の次元数)
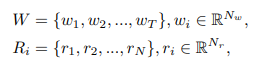
Memory Writing
テキスト内の各単語の情報を、メモリネットワークから読み出せるように$1\times1$畳み込みを使用して特徴量空間(次元数$N_m$)に変換します。
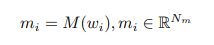
Key Addressing
入力される画像の特徴量$r_j$と、単語の情報を埋め込んだメモリスロット$m_i$に対して、互いに一番関連しているものはどれなのか計算します(Attentionの計算と同様に重み付けを求めます)。
($\phi_{K}$はKeyにアクセスする際の処理であり、$1\times1$畳み込みで実装します。)
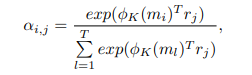
Value Reading
Key Addressingで計算されたメモリと画像の特徴量の類似度をもとに、あるピクセルに対して、全メモリとの類似度を使用した重み付き和を計算します。
($\phi_{V}$はValueにアクセスする際の処理であり、$1\times1$畳み込みで実装します。)
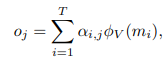
Response
Value Reading処理によって得られた、全メモリと各ピクセルごとの重み付き和を使用して、元のピクセルを新しいピクセルに更新します。
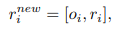
ここまでがnaiveな実装を考えた際の処理になります。
本論文では、これらの処理に対していくつか改善を加えています。
(LSTMのGate処理を思い浮かべてもらうと理解しやすいです。)
Gated Memory Writing
通常のMemory Writingでは、1つの単語を使用してメモリを計算していました。
DM-GANでは、まずメモリに保存する単語と画像の全ピクセルの特徴量が互いにどの程度関連しているのかを計算します(LSTMなどのgate処理と似ています)。
($A$は$1\times N_W$行列、$B$は$1\times N_w$行列)
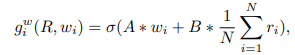
得られたgateを使用して、単語と全ピクセルに対してGate処理を行い、メモリネットワークから読み出せるように$1\times1$畳み込みを使用して特徴量空間(次元数$N_m$)に変換します。
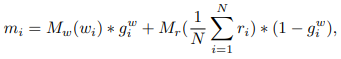
Gated Response
通常のResponseでは、得られた重み付き和と各ピクセルの情報を結合させただけでした。
ここでは重み付き和と直前の画像の特徴量の間で、Gate処理をおこなってどちらの情報をより多く残すのかを決めます。
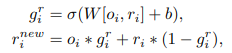
あとはこの一連のプロセスを繰り返して計算することで、より高解像度な画像を生成していきます。
Generatorの損失関数は全部で以下の数式になります。
($L_{G_{i}}$はStackGAN++で導入された条件付き損失関数と非条件付き損失関数の組み合わせ、$L_{CA}$はStackGANで導入されたConditioning Augmentationに対する正則化項、$L_{DAMSM}$はAttnGANで導入されたマルチモーダルを考慮した損失関数)
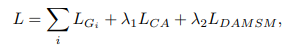
Discriminatorの損失関数は、StackGAN++と同じです。
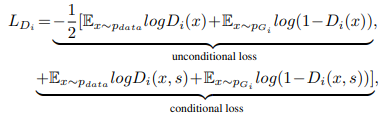
DM-GANでは、メモリ構造を有するネットワークを追加することで、初期画像の崩壊を防ぐこと、かつ後のステージで使用する単語情報に重み付けを行ったことがポイントです。
3.3 Diversity Enhancement GAN
3.3.1 AC-GAN
AC-GAN(Odeba et al., 2016)では、Discriminatorに本物の画像と偽物の画像を識別させるタスクに加えて、与えられた画像のクラスを識別タスクも解かせることで、高解像度かつ多様性のある画像の生成に成功しました。
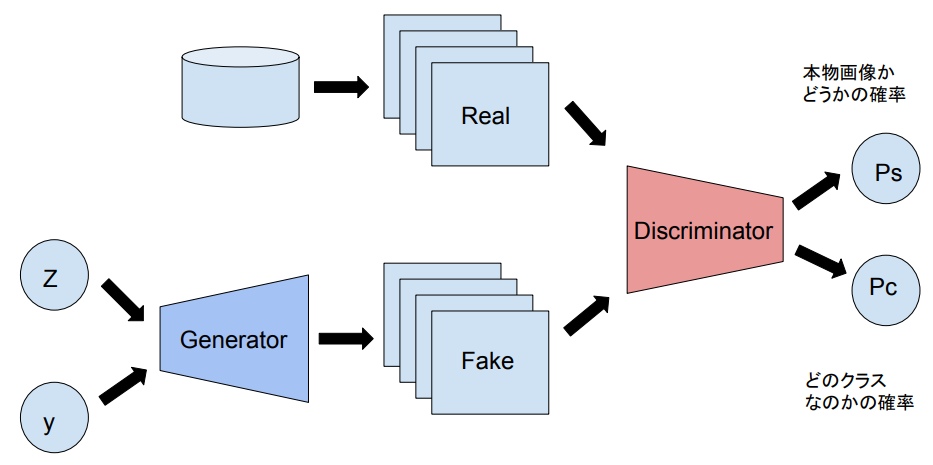
損失関数としては本物かどうかを識別できるようにする項と、正しいクラスを識別できるようする項で構成されており、Discriminatorに対しては$L_C+L_S$を最大化させ、Generatorに対しては$L_C-L_S$を最小化させるように学習させます。
(Sは画像のSourceを表しており、Cは画像のクラスを表します。)
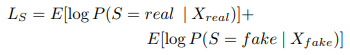
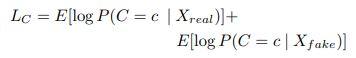
論文中ではImageNetの1000クラスの画像生成に対して、10クラスごとに生成するAC-GANを100個使用して、ImageNetの全クラスを生成することに成功しています。
AC-GANでは、クラス分類を行うタスクをDiscriminatorに追加することで、多様性のある画像を生成することに成功したことがポイントです。
3.3.2 TAC-GAN
TAC-GAN(Dash et al., 2017)では、クラス情報しか使用していなかったAC-GANを発展させ、テキストの埋め込み表現を入力として受け取ることができるようにモデルを拡張させました。
モデルの構造自体はAC-GANとほぼ同じです。画像に対応するテキストの埋め込み表現に対して、ほかのモデルと同様に線形結合層を使用して埋め込み表現を潜在表現に変換します。
このベクトルと潜在変数$z$を結合させてGeneratorへの入力とします。
Discriminatorに対しても、ほかのモデルと同様に画像の特徴を抽出したベクトルに対して、別の潜在表現に変換させたテキストの埋め込み表現を結合させて最終的な識別タスクを行います。
構造としてはAC-GANとGAN-CLSの組み合わせのような感じです。
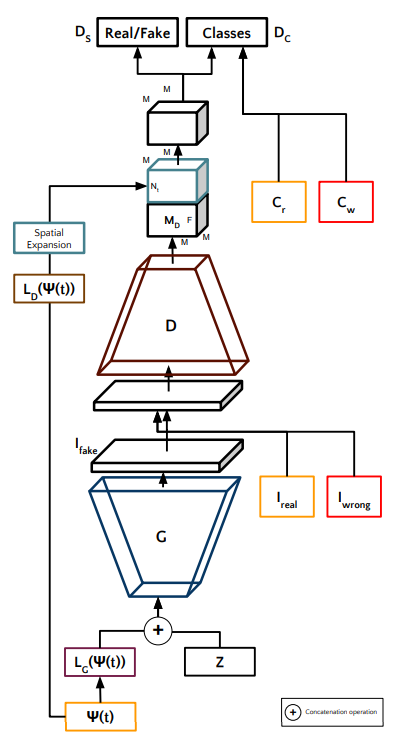
学習を行う際のDiscriminatorの損失関数は以下のように定義できます。
($H$は2値クロスエントロピー、$I_r$は入力のテキストに対して本物の画像、$I_f$は生成された画像、$I_w$テキストに対応していない本物の画像を表します。)
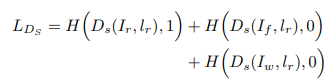
つまり(1)本物の画像と対応するテキストのペア、(2)生成画像と対応するテキストのペア、(3)異なる本物の画像と対応するテキストのペアを学習するときのデータとしており、若干GAN-CLSとは異なる構造です(GAN-CLSは、本物の画像と異なるテキストのペア($D_s(I_r, l_w)$)を使用している)。
またクラス分類を行う際の損失関数は以下のように定義できます。
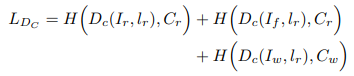
画像に対応しているクラスをペアとして使用します。
Generatorの損失関数は、Discriminatorの損失関数内で生成画像を使用している項のみを考えれば大丈夫です。
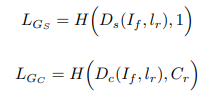
Generatorの場合は、生成画像$I_f$と対応するテキスト$l_r$のラベルを本物のペア($=1$)として学習させることに注意してください。
TAC-GANでは、AC-GANをテキストの埋め込み表現を取り込めるように拡張したこと、かつ分類タスクでデータのペアを考案したことがポイントです。
3.3.3 Text-SeGAN
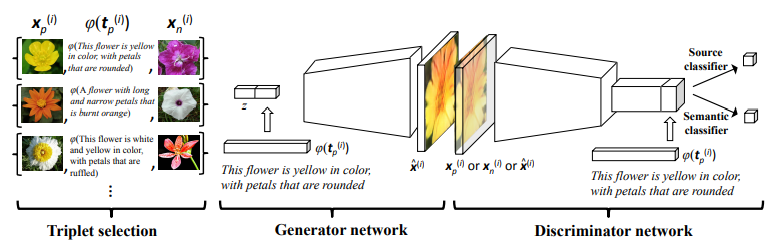
Text-SeGAN(Cha et al., 2018)では、画像は本来複数のラベルにマッチするようなものであるという考え方から、Discriminatorでクラス分類を行うのではなく、入力画像とテキストの意味の関連性を直接評価するようにモデルを改変することに成功しました。
学習する際には、Triplet Samplingを採用しており、図にあるように対象の画像$X_{p}^{(i)}$、対象の画像に対応しているテキストの埋め込み表現$\varphi(t_{p}^{(i)})$、テキストに対応していない画像$X_{n}^{(i)}$を使用します。これらのデータのペアをDiscriminatorに適用します。
画像とテキスト間の関連性を評価する損失関数は、以下のように定義します。
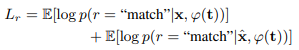
Triplet Samplingで学習させる際に重要となるのは、学習させるPositiveなデータとNegativeなデータをどのように構成させるかということです(全パターンは計算量的に難しい)。
サンプリング戦略1:Random Negatives
これはDC-GAN(Reed et al., 2016)で提案された方法と同じく、Positiveな画像に対応しているクラス以外の画像を無作為に選択して、Negativeな画像として採用する戦略です。
サンプリング戦略2:Easy Negatives
この戦略では、画像間の類似度を測定するために入力テキストの埋め込み表現を使用します。
対象としているPositiveな画像に対して、クラス外のサンプルのうち最もテキスト表現が離れているものをNegativeとしてサンプリングします。
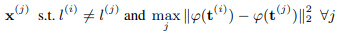
サンプリング戦略3:Hard Negatives
Easy Negatives戦略とは反対に、クラス外のサンプルのうち最も対象のテキスト表現に近いものをNegativeとしてサンプリングします。
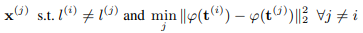
サンプリング戦略4:Semi-easy Negatives
Easy Negatives戦略でサンプリングしたものを学習に使用すると、実用上はDiscriminatorの性能を悪化させてしまうため、テキスト表現が最も離れているものではなく、ある距離より離れているものをサンプリングします。なおサンプリングする際は、Easy Negatives戦略の数式を使用してMサンプルを抽出して、その中から対象をサンプリングします。
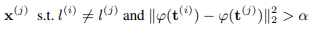
サンプリング戦略5:Semi-hard Negatives
Hard Negatives戦略でサンプリングしたものを学習に使用すると、モデルが崩壊してしまうため、テキスト表現が最も近いものではなく、ある距離より近しいものをサンプリングします。なおサンプリングする際は、Hard Negatives戦略の数式を使用してMサンプルを抽出して、その中から対象をサンプリングします。
サンプリング戦略6:Easy-to-Hard Negatives
学習を進めていき中で採用するサンプリング戦略を変えていきます。
- クラス外のNegativeなテキストをM個ランダムに選択します。
- PositiveなテキストとNegativeのテキスト群に対して、Cosine類似度を計算しヒストグラムを計算します。
- $\beta \ (0\lt\beta\le1)$を使用して百分率の中の$100\times\beta$の数だけサンプリングします。
- $\beta$を徐々に上げていき、Easy NegativeからHard Negativeのサンプリング比率を上げます。
この中でもサンプリング戦略6の徐々に難易度を上げていく方式が、もっとも精度が高かったです。
Text-SeGANでは、クラス分類ではなく直接単語と画像の意味の関連度を計算するDiscriminatorを考案したこと、また学習データのサンプリング方法を改善したことがポイントです。
3.3.4 Scene Graph GAN
Scene Graph GAN(Johnson et al., 2018)では、テキストから複雑な画像を生成するために、入力のテキストグラフで表現し、グラフ畳み込みを行うことで、画像内の各物体間の位置関係などを説明できるモデルを作成しました。
説明しようとしましたがグラフ畳み込みがよくわかりませんでした…
悲しみ…
以下の記事を読んでから出直します。
- GNNまとめ(1): GCNの導入 - Qiita
- GNNまとめ(2): 様々なSpatial GCN - Qiita
- GNNまとめ(3): 発展編とこれから - Qiita
- グラフ構造を畳み込む -Graph Convolutional Networks- Qiita
3.3.5 MirrorGAN
MirrorGAN(Qiao et al., 2019)では、Text-To-Imageタスクだけではなく、生成された画像に対してImage-To-Textタスクを解くことも追加したモデルを提案しました。
また、AttnGANでは各スケールの画像を生成する際に単語レベルの情報しか使用していなかった状態から、文レベルの情報を加えることで全体の意味の一貫性を保持するようにしています。
MirrorGANは3つのモジュールで構成されています。
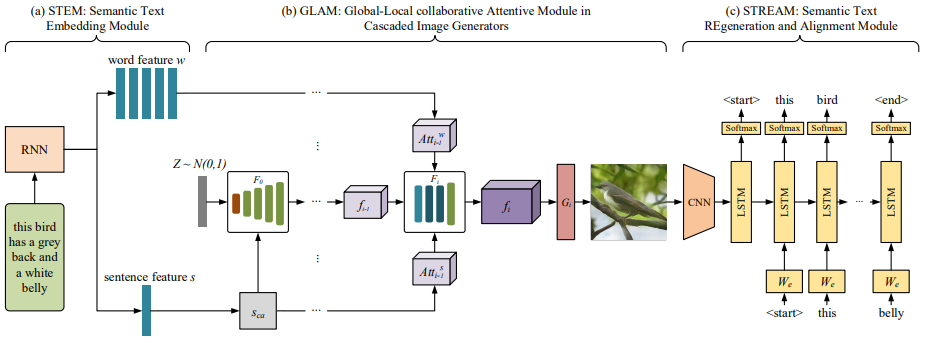
STEM(Semantic Text Embedding Module)モジュール
RNNを使用して、入力されたテキストを単語レベルと文レベルの埋め込み表現に変換します。また文レベルの埋め込み表現に対しては、Conditioning Augmentationを適用して変動を加えるようにしておきます。
(単語の埋め込み表現$w$、文の埋め込み表現$s$、変動を加えた文の埋め込み表現$s_{ca}$)
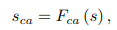
GLAM(Global-Local collaborative Attentive Module)モジュール
GLAMモジュールでは各スケールの画像の特徴量を計算し、Generatorで学習の生成を行います。最初のステージでは潜在変数$z$と文レベルの情報$s_{ca}$を入力として受け取りますが、2つ目のステージ以降では、1つ前の層の画像の特徴量$f_{i-1}$と単語レベルの情報$w$と文レベルの情報$s_{ca}$の3つを入力として受け取ります。
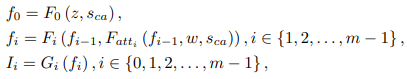
(画像の特徴量$f_{i} \in \mathbb{R}^{M_{i}\times N_{i}}$、生成された画像$I_{i}\in\mathbb{R}^{q_{i}\times q_{i}}$を表します。)
注意機構に関しては、文レベルの情報に対する重みを計算する要素と、単語レベルの情報に対する重みを計算する要素で構成されています。
(AttnGANのAttentionモジュールと考え方は同じです。)
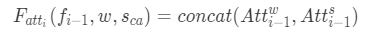
STREAM(Semantic Text REgeneration and Alignment Module)モジュール
生成された画像を入力として受け取り、キャプション生成タスクを行って画像に対するテキストを再生成できるように学習を行います。
(画像の特徴量$x_{-1} \in \mathbb{R}^{M_{m-1}}$、単語から画像の特徴量へのマッピング行列$W_{e} \in \mathbb{R}^{M_{m-1}\times D}$)
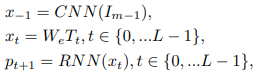
実際に学習を行う際は、このSTREAMモジュールに関して事前学習を行って、全体の学習を安定化させ、学習コストを下げるようにしています。
学習する際の損失関数には、通常のGANと同じく本物か偽物かを識別する項と、テキストの画像のペアを判定する項で構成されています(matching-aware discriminatorと同様です)。
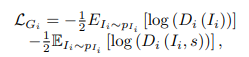
またSTREAMを用いてで予測された、生成された画像に対するテキストに対して、Cross-Entropyを使用して再構成損失関数を適用しています。
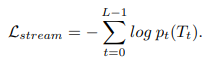
上記の提案されている損失関数を使用して全体のネットワークの学習を進めていきます。
Discriminatorに対しては、matching-aware discriminatorと同様に、入力画像と対応するテキストの組み合わせを予測するタスクを行います。
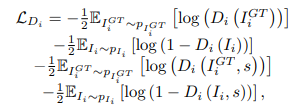
MirrorGANでは、生成した画像からテキストを再構成することで入力テキストと意味がずれていないかどうかを計算できるようにしたこと、画像を生成する際に単語と文の両方の情報を使用するようにしたことがポイントです。
3.4 Motion Enhancement GAN
この分野に関しては今回は省きます。
※追記していくかもしれません。
4. 評価
4.1 Contribution
発表された後で多くの論文で採用しているアイデアは多分こんな感じ。
- Conditioning Augmentation
- matching-aware discriminator
- Stack構造
- DAMSM損失関数
- UnConditional LossおよびConditional Loss
4.2 性能評価
以下に各データセットに対して各モデルを適用させた場合のInception Scoreを載せています。
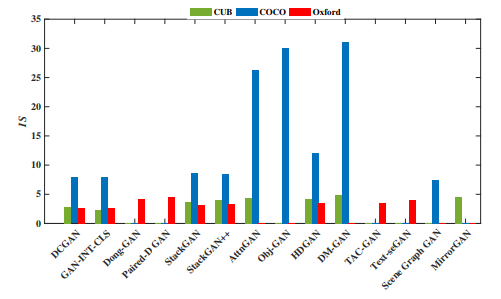
性能的にはCOCOデータセットにおいて、AttnGAN・Obj-GAN・DM-GANが突出しています。
こういう性能表を見ていると特定のタスクにしか適用していない論文もあるため、すべてのデータセットでIS以外の指標に関しての一覧表とかも見てみたいと思いますね。
5. いらすとやデータセットへの適用
本記事では、いらすとやのデータセットに対してStackGANを適用します(なお研修での発表ではMirrorGANとAttnGANを使用しました)。
StackGANではchar-CNN-RNNモデルを事前学習させていました。今回は画像と関連する特徴をとらえているかは不明ですが、近年使いやすくなった事前学習済みのBertを使用して、文レベルの埋め込み表現を計算していこうと思います。
transformers
1週間前くらいにhuggingfaceのtransformersで日本語学習済みのBERTが公式で使用できるようになったため、このモデルをテキストの埋め込み表現を獲得するために使用します。
おはようござえます、日本の友達
— Hugging Face (@huggingface) December 13, 2019
Hello, Friends from Japan 🇯🇵!
Thanks to @NlpTohoku, we now have a state-of-the-art Japanese language model in Transformers, `bert-base-japanese`.
Can you guess what the model outputs in the masked LM task below? pic.twitter.com/XIBUu7wrex
環境
- PC
- OS Windows 10 Home
- RAM 32GB
- GPU NVIDIA GeForce RTX-2080ti
- Python
- python 3.7.5
- torch 1.2.0
- transformers 2.2.2
文ベクトルの取得
まずは文章をトークン化するためのモデルと、トークンを受け取って文ベクトルと単語ベクトルを取得するモデルを読み込みます。なお、MeCabが必要です。
from transformers.modeling_bert import BertModel
from transformers.tokenization_bert_japanese import BertJapaneseTokenizer
transformersでは、単語の分散表現を学習させているBertModelを基準にして、文書の分類や感情分類などの各種タスクを実行できるモデルを提供しています。
今回は元となっているBertModelを使用します。
model_name = 'bert-base-japanese-whole-word-masking'
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
このモデルに対して、以下の画像に記載されているテキストを入力して、どのようなトークンが抽出されるのかを確認します。

sample_text = "お酒を飲んで酔っ払っている人たちが街にくりだして騒いでいるイラストです。"
# token化を行う
tokens = tokenizer.tokenize(sample_text)
print(tokens)
> ['お', '酒', 'を', '飲ん', 'で', '酔っ', '##払っ', 'て', 'いる', '人', 'たち', 'が', '街', 'に', 'くり', '##だし', 'て', '騒', '##い', 'で', 'いる', 'イラスト', 'です', '。']
# tokenに対応した単語IDを取得する
tokens_id = tokenizer.convert_tokens_to_ids(tokens)
print(tokens_id)
> [73, 2438, 11, 14716, 12, 27581, 24118, 16, 33, 53, 558, 14, 1243, 7, 12342, 14406, 16, 3919, 28457, 12, 33, 4307, 2992, 8]
# モデルに投入する形式にエンコードする
# 最初と最後に文の開始と終了を表すIDが付与されている
encoded_tokens = tokenizer.encode(sample_text)
> [2, 73, 2438, 11, 14716, 12, 27581, 24118, 16, 33, 53, 558, 14, 1243, 7, 12342, 14406, 16, 3919, 28457, 12, 33, 4307, 2992, 8, 3]
# 実際にモデルに投入する際は、入力のテンソルの形式をを指定します。
input_id_tensor = tokenizer.encode(sample_text, return_tensors='pt')
# モデルに入力して単語ベクトルと文ベクトルを取得する
w, s = model(input_id_tensor)
print(w.size())
> torch.Size([1, 26, 768])
print(s.size())
> torch.Size([1, 768])
実際にいらすとやから収集したテキストに対して、上記のサンプルテキストの文ベクトルを取得して、コサイン類似度を計測し似ている文はどのようなものなのかをTop5を見てみます。
女性がコンサートやライブのチケットを手に入れて嬉しそうに掲げているイラストです。
マンションが火災になって大きな炎が燃え広がっているイラストです。
お年寄りの女性が驚きの発言をして吹き出しが爆発しているイラストです。
お坊さんが静かに座禅を組んでいるイラストです。
私服姿の女性が集まって真剣な顔で話し合いをしているイラストです。
お坊さん以外は何となく意味合いが似ていますね。
(なぜお坊さんの類似度が高いのでしょうか)
いらすとやのデータセットでのStackGAN
いらすとやには画像とセットで画像の説明文がついているので、これを1つのデータセットとして学習させてみます。
以下は学習時に生成された画像になります。
なかなかいい感じの崩壊っぷりですね。


実際に学習時に含まれていないテキストを入力すると、さらにひどい画像が生成されました。
ここら辺は論文の通りに実装するだけでなく、何かしら工夫が必要ですね。
崩壊した画像しか生成されませんが、試しに使ってみたい人は以下のリンクをたどってください。
(なお実行環境としてDockerが必要です。)
研究分野で利用されているCUB birdデータセットには1つの画像に対して説明文が5つ、COCOデータセットには1つの画像に10個の説明文がついていますが、いらすとやデータセットの場合は、1つの画像に対して説明文は1つだけなので上記の2つのデータセットほどは精度を出すのが難しいですね。
6. 感想
研修の際に初めて自然言語処理やGANなどの生成モデルを勉強しましたが、0の状態から独学のみでかなり分野について理解できるようになりました。
これからは、より高精度なモデルを作成するために特定のタスクだけではなくGAN全体でサーベイを行っていこうと思います。
また、今後の予定としてファインマン先生の教えにのっとり、今回紹介しているモデルを1から実装していく内容を記事にしていこうかと思います。
今後追加するかもしれない内容
- Obj-GANとScene Graph GAN
- Motion Enhancement GANの領域
- ほかの論文
- Semantics Disentangling for Text-to-Image Generation ttps://arxiv.org/abs/1904.01480
参考文献・引用文献
-
Jorge Agnese, Jonathan Herrera, Haicheng Tao, Xingquan Zhu (2019), A Survey and Taxonomy of Adversarial Neural Networks for Text-to-Image Synthesis, https://arxiv.org/abs/1910.09399
-
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio (2019), Generative Adversarial Networks, https://arxiv.org/abs/1406.2661
-
Mehdi Mirza, Simon Osindero (2014), Conditional Generative Adversarial Nets, https://arxiv.org/abs/1411.1784
-
Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee (2016), Generative Adversarial Text to Image Synthesis, https://arxiv.org/abs/1605.05396
-
Hao Dong, Simiao Yu, Chao Wu, Yike Guo (2017), Semantic Image Synthesis via Adversarial Learning, https://arxiv.org/abs/1707.06873
-
Duc Minh Vo and Akihiro Sugimoto (2018), Paired-D GAN for Semantic Image Synthesi, http://www.dgcv.nii.ac.jp/Publications/Publication.html
-
Hyojin Park, YoungJoon Yoo, Nojun Kwak (2018), MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis, https://arxiv.org/abs/1805.01123
-
Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas (2016), StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, https://arxiv.org/abs/1612.03242
-
Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas (2017), StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks, https://arxiv.org/abs/1710.10916
-
Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, Xiaodong He (2017), AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks, https://arxiv.org/abs/1711.10485
-
Wenbo Li, Pengchuan Zhang, Lei Zhang, Qiuyuan Huang, Xiaodong He, Siwei Lyu, Jianfeng Gao (2019), Object-driven Text-to-Image Synthesis via Adversarial Training, https://arxiv.org/abs/1902.10740
-
Zizhao Zhang, Yuanpu Xie, Lin Yang (2018), Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network, https://arxiv.org/abs/1802.09178
-
Minfeng Zhu, Pingbo Pan, Wei Chen, Yi Yang (2019), DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis, https://arxiv.org/abs/1904.01310
-
Augustus Odena, Christopher Olah, Jonathon Shlens (2016), Conditional Image Synthesis With Auxiliary Classifier GANs, https://arxiv.org/abs/1610.09585
-
Ayushman Dash, John Cristian Borges Gamboa, Sheraz Ahmed, Marcus Liwicki, Muhammad Zeshan Afzal (2017), TAC-GAN - Text Conditioned Auxiliary Classifier Generative Adversarial Network, https://arxiv.org/abs/1703.06412
-
Miriam Cha, Youngjune L. Gwon, H.T. Kung (2018), Adversarial Learning of Semantic Relevance in Text to Image Synthesis, https://arxiv.org/abs/1812.05083
-
Justin Johnson, Agrim Gupta, Li Fei-Fei (2018), Image Generation from Scene Graphs, https://arxiv.org/abs/1804.01622
-
Tingting Qiao, Jing Zhang, Duanqing Xu, Dacheng Tao (2019), MirrorGAN: Learning Text-to-image Generation by Redescription, https://arxiv.org/abs/1903.05854
-
Scott Reed, Zeynep Akata, Bernt Schiele, Honglak Lee (2016), Learning Deep Representations of Fine-grained Visual Descriptions, https://arxiv.org/abs/1605.05395