概要
**「今まで作ってきた超解像手法のうち10種類を、全く同じデータセットで学習させて検証をしてみた」**という記事です。
色々実装していたので一度してみたかった内容になっています!
なお、割と安易な考えなので、パラメータなども大体同じにして学習させています。
そのため、超解像の論文のベンチマークテストみたいに、きっちりかっちりしていないのでご了承ください。
ちなみに超解像は、解像度の低い画像から解像度を向上させた画像を出力する技術です。
もう少し噛み砕いて説明すると、画質の荒い画像を綺麗にするみたいな感じです。
コードはGithubに置いていますが、過去の実装のコードをひとまとめにしただけなので長いです。
今回比較したアルゴリズムの紹介
今回使用した10種類のアルゴリズムの概要を紹介します。
10種類全部紹介するので長めになります。結果だけチラ見したい方は飛ばしてください!
まず、今回紹介するアルゴリズムは以下の通りです。
それぞれ自分が書いた実装記事をリンク付けしておくので、詳しく見たい方はそちらをご覧ください。
これらのうち、VSRnet・RVSR・VESPCNは、動画像を対象とした超解像手法です。
高解像度化するフレームは1枚なので、同じデータセットで比較することができます。
以下で、各手法の概要を紹介します。
SRCNN
SRCNNは初めて超解像分野に深層学習を導入したモデルで、Convolutionを3層組み合わせたモデルとなっています。
SRCNNのアルゴリズムの概要は以下の通りです。(図は論文から引用)
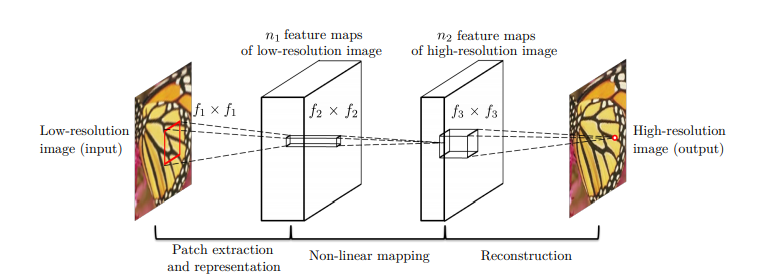
今回実装したSRCNNは、事前にbicubicで拡大処理を行います。
FSRCNN
FSRCNNのアルゴリズムの概要は以下の通りです。(図は論文から引用)
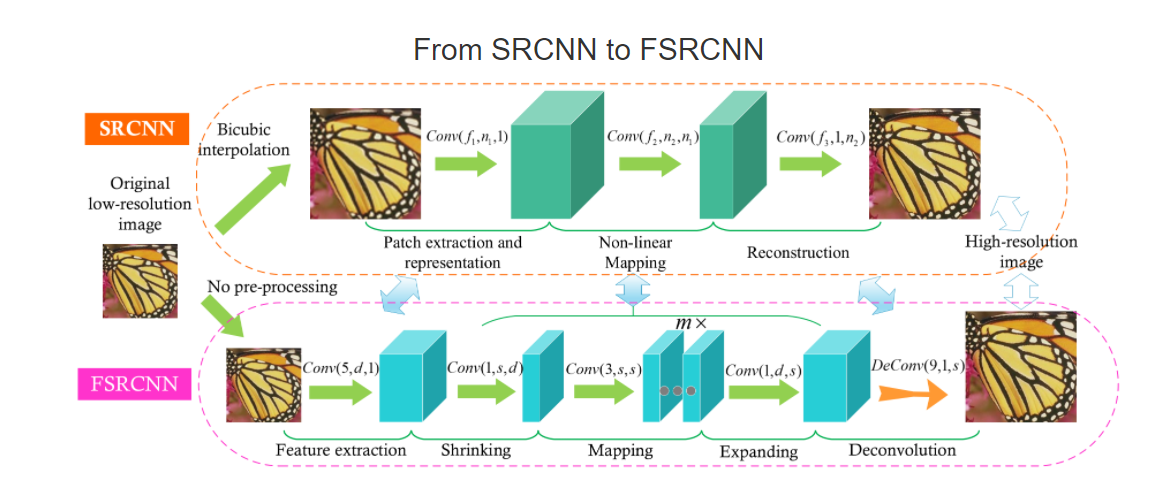
上の図がSRCNN、下の図がFSRCNNのモデルの概要図となっています。
SRCNNでは、最初にBicubic法で画像を補間してからニューラルネットワークに入力しており、画像サイズが大きい状態で特徴抽出や返還を行っていました。
そのため、CNNのサイズが大きくなったり、計算が非効率になっているという問題がありました。
そこで、FSRCNNではSRCNNの大まかなモデルの構造はそのままに、
Feature extractionShrinkingMappingExpandingDeconvolution
のいくつかの層に分けており、効率化に成功しています。
ESPCN
ESPCNのアルゴリズムの概要は以下の通りです。(図は論文から引用)
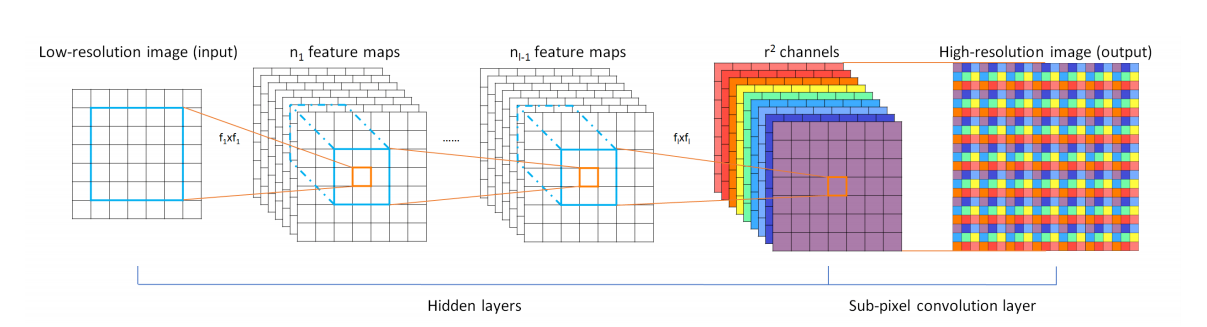
ESPCNは畳み込み処理を行った後、Sub pixel convolutional layerを通して最終的な結果を出力します。
これによって、画像を拡大しています。
VDSR
VDSRのアルゴリズムの概要は以下の通りです。(図は論文から引用)
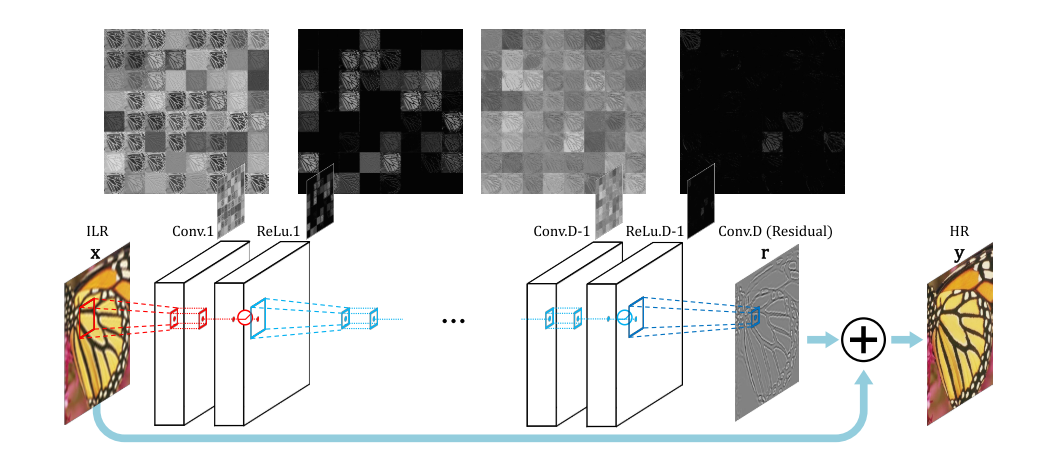
Convolution層を多数重ねることで、学習をさせていますが、
最後に入力画像と畳み込み演算の結果を足し合わせるSkip Connnectionを導入していることが大きな特徴です。
これを行う意図としては、多数の畳み込み演算によって生じる勾配消失を防ぎ、画像の特徴を失わないようにするためです。
最後に入力画像を足し合わせることで、画像の特徴は残しつつ処理を行うことができる、というわけです。
今回実装したVDSRは、事前にbicubicで補間処理をした画像を入力します。
DRCN
DRCNのアルゴリズムの概要図は以下の通りです。(図は論文から引用)
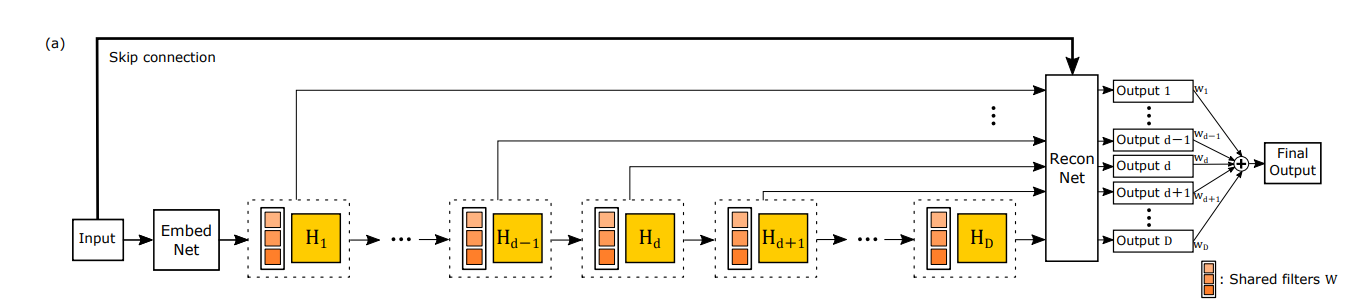
主に、
-
Embedding net:特徴マップの生成ネットワーク -
Inference net:メインの超解像ネットワーク -
Reconstruction net:再構成のネットワーク +Skip_connection
の3つのネットワークに分かれています。
図では多数のネットワークが描かれていますが、同じ畳み込み層を繰り返し利用するので、パラメータ数は控えめになっています。
このモデルのイメージとしては、繰り返しCNNに画像を入力することで、徐々に画像をきれいにしていく感じです。
もう少し詳しい概要図は以下の通りです。(図は論文から引用)
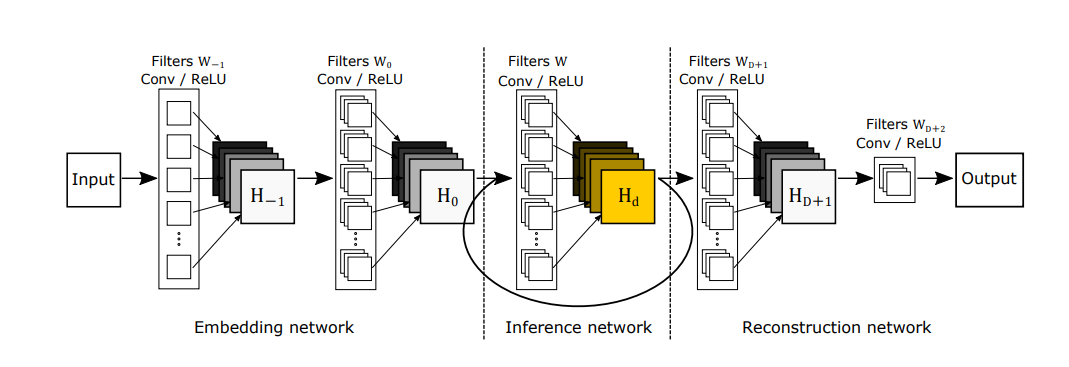
図の通り、Conv + ReLUが基本構成になっています。また、フィルター数やフィルターサイズは基本的には同じものを使用します。
今回実装したDRCNは、事前にbicubicで拡大処理を行います。
RED_Net
RED-Netのアルゴリズムの概要は以下の通りです。(図は論文から引用)
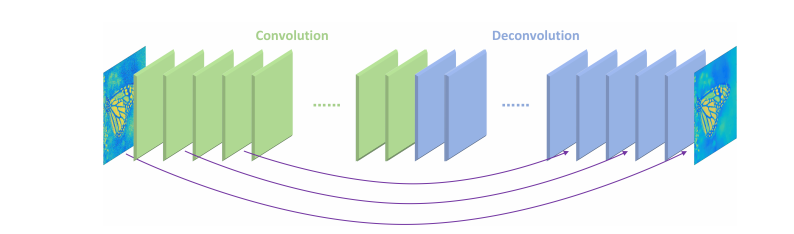
同じ数のConvolution layerとDeconvolution layerで構成されており、
Deconvolutionを2回行うごとに、Skip connectionでConvolutionの結果を足し合わせています。
Skip connectionは、学習に伴う勾配消失の問題を防ぐために使用されています。
また、Skip connectionによる結果の足し合わせを行ったとき、以下の図の例のようにReLUの活性化関数を通します。
(図は論文から引用)
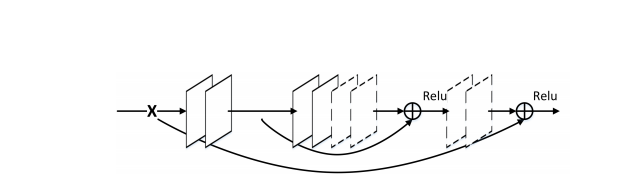
上の図では、実線がConvolution layerで破線はDeconvolution layerを表しています。
今回実装したRed-Netは、事前にbicubicで拡大処理を行います。
DRRN
DRRNのアルゴリズムの概要は以下の通りです。(図は論文から引用)
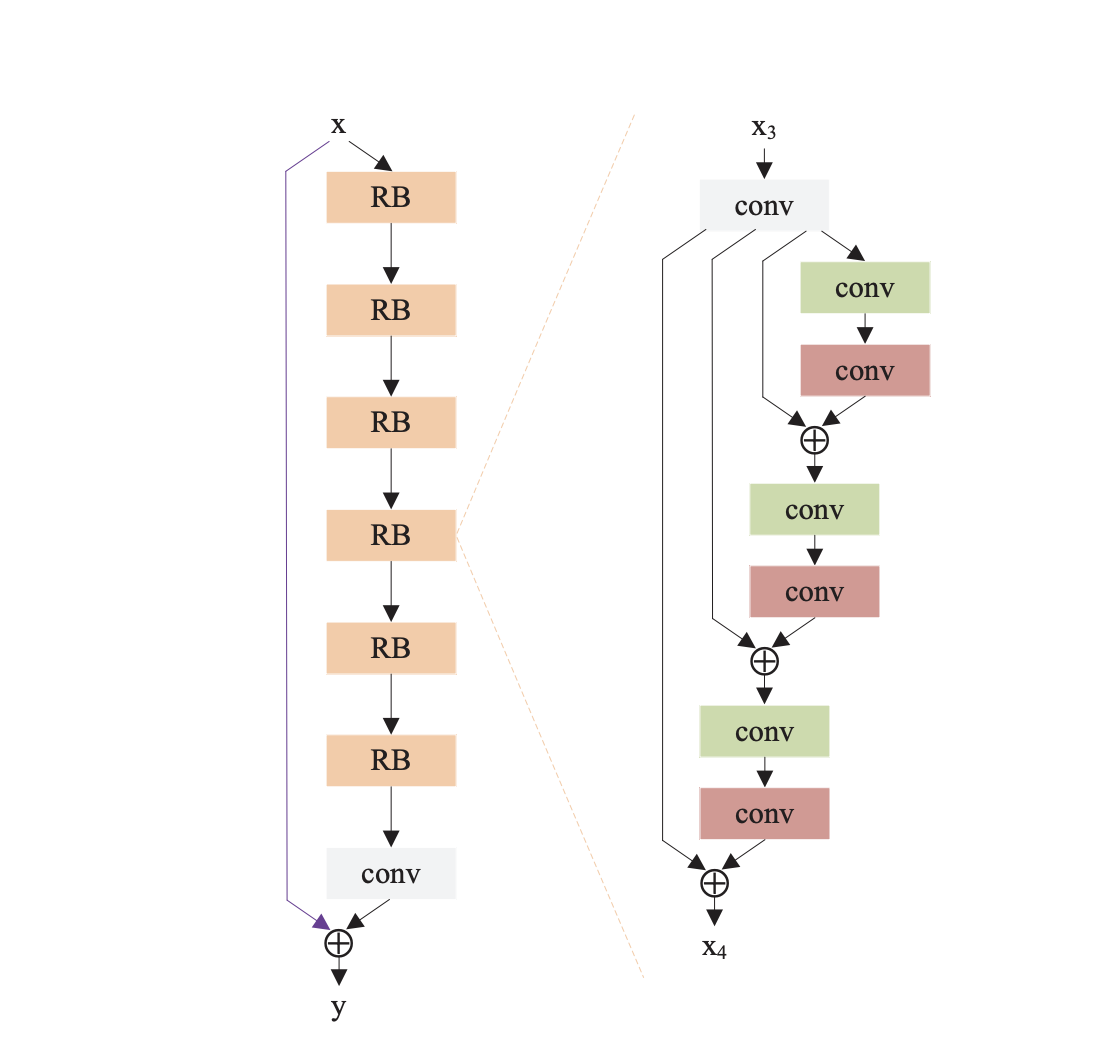
DRRNの全体図は左のようになっています。
DRRNは任意の数のRecursive Blockから成立しており、最後にConvolutionで結果を出力します。
今回の図だと、Recursive Blockの数は6つとなっています。(図のRBの数)
Recursive Blockの中の構成は図の右のようになっています。
Residual Unitsという名前で論文では紹介されており、図のような構成になっています。
VSRnet
VSRnetは、3層のConvolutionから構成されていますが、入力する3枚のフレームを結合する位置に応じてモデルが3つあります。
architecture(a)は、Convolution層に入力する前に結合します。
architecture(b)は、1回それぞれの入力フレームをConvolution層に入力した後に結合します。
architecture(c)は、2回それぞれの入力フレームをConvolution層に入力した後に結合します。
概要図を見ると分かりやすいので、以下で概要図を示します。(図は論文から引用)
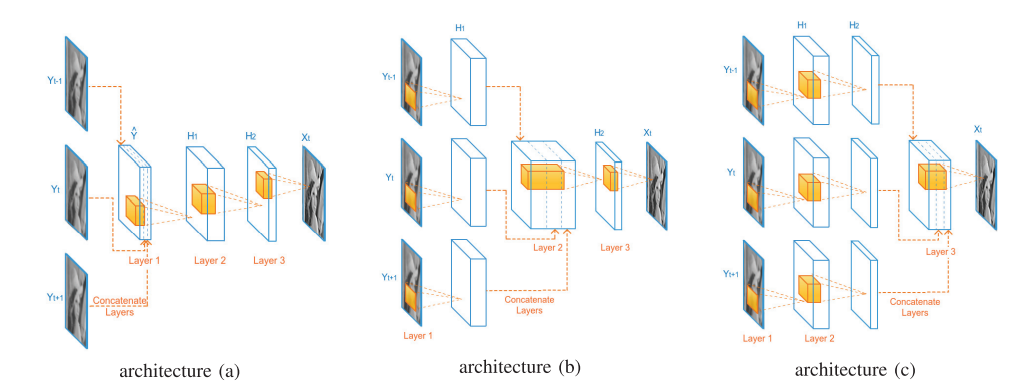
今回実装したVSRnetはarchitecture(b)で、事前にbicubicで拡大処理を行います。
RVSR
RVSRのアルゴリズムの概要は以下の通りです。(図は論文から引用)
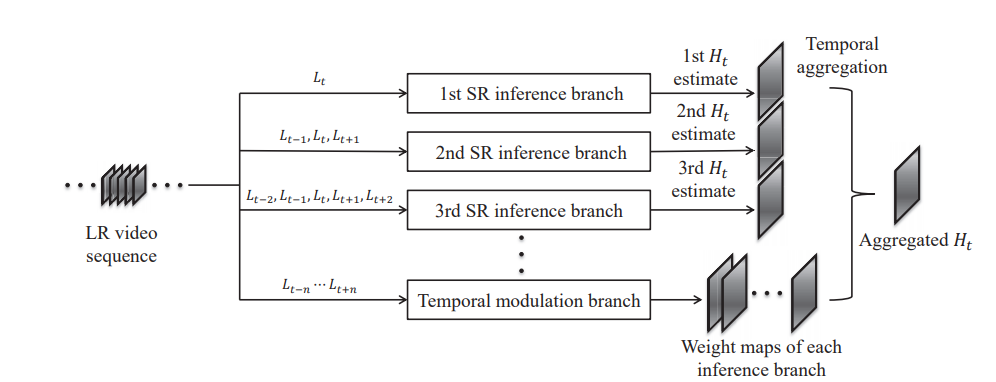
この超解像アルゴリズムは主に3つのパートに分かれています。
- SR inference branch:高解像度画像の候補を出力。
- Temporal modulation branch:weight mapの出力。
- Temporal aggregation:最終的な結果の出力。
VESPCN
VESPCNのアルゴリズムの概要は以下の通りです。(図は論文から引用)
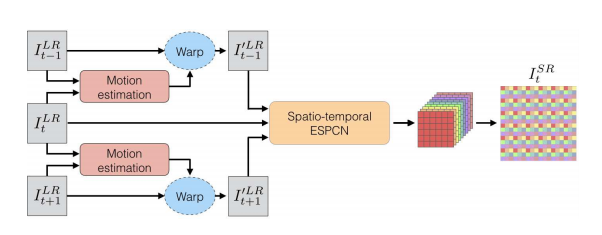
この超解像手法は、3枚の連続するフレームを入力して、1枚の高解像度画像を出力します。
前半のMotion estimationが動き補償などのデータ前処理の部分、
後半のSpatio-temporal ESPCNが超解像を行う部分になっています。
学習・検証に使用したデータセット
今回は、データセットにREDSを使用しました。
このデータセットは、動画像の超解像用のデータセットで、240種類の学習用データ、30種類の検証用データ、30種類のテスト用データの計300種類のデータセットです。
パスの構造はこんな感じです。
train_sharp - 001 - フレーム100枚
- 002 - フレーム100枚
- ...
val_sharp - 001 - フレーム100枚
- 002 - フレーム100枚
- ...
このデータをbicubicで縮小したりしてデータセットを生成しました。
今回、入力フレームが5枚のアルゴリズムがあったので、データセットも5フレームで1セットにしています。
そのため、単一画像用のアルゴリズムは中央のフレームを、入力フレームが3枚のアルゴリズムでは、中央に近い3フレームを入力することで、全く同じデータセットでの学習を行っています。
学習条件
今回学習を行った環境は以下の通りです。
-
PC環境
-
CPU: AMD Ryzen 5 3500 6-Core Processor -
memory size: 40GB -
GPU: NVIDIA GeForce RTX 2060 SUPER -
OS: Windows 10
-
-
ライブラリ環境
-
python: 3.7.9 -
tensorflow-gpu: 2.3.0 -
keras: 2.4.3 -
opencv-python: 4.4.0.43
-
また、今回設定したパラメータは以下の通りです。(コードの一部抜粋)
まず、学習に関連するパラメータはtrain.pyに記載しています。
parser.add_argument('--train_height', type = int, default = 48, help = "Train data HR size(height)")
parser.add_argument('--train_width', type = int, default = 48, help = "Train data HR size(width)")
parser.add_argument('--train_dataset_num', type = int, default = 30000, help = "Number of train datasets to generate")
parser.add_argument('--train_cut_num', type = int, default = 10, help = "Number of train data to be generated from a single image")
parser.add_argument('--train_path', type = str, default = "../../dataset/reds_train_sharp", help = "The path containing the train image")
parser.add_argument('--LR_num', type = int, default = 5, help = "Number of LR frames")
parser.add_argument('--learning_rate', type = float, default = 1e-4, help = "Learning_rate")
parser.add_argument('--BATCH_SIZE', type = int, default = 32, help = "Training batch size")
parser.add_argument('--EPOCHS', type = int, default = 1000, help = "Number of epochs to train for")
ここでは、学習データのサイズ・データセットの数・学習率などを指定しています。
次に、検証用データに関連するパラメータを以下で示します。test.pyに記載しています。
parser.add_argument('--test_height', type = int, default = 360, help = "Test data HR size(height)")
parser.add_argument('--test_width', type = int, default = 640, help = "Test data HR size(width)")
parser.add_argument('--test_dataset_num', type = int, default = 50, help = "Number of test datasets to generate")
parser.add_argument('--test_cut_num', type = int, default = 1, help = "Number of test data to be generated from a single image")
parser.add_argument('--test_path', type = str, default = "../../dataset/reds_val_sharp", help = "The path containing the test image")
parser.add_argument('--LR_num', type = int, default = 5, help = "Number of LR frames")
parser.add_argument('--mag', type = int, default = 2, help = "Magnification")
同様に、検証用データセットのサイズや数などを指定しています。
検証結果
今回は、学習率や学習回数、データセットの数など、同じにできる部分は全て同じ値で学習させました。
以下は、その前提で読んでいただけると幸いです。
今回、検証結果として2種類の結果を紹介します。
50枚の結果のPSNRの平均・ピックアップした1枚の画像のPSNRの2種類です。
検証用データ50枚の平均結果で比較
低解像度画像は、bicubicで補間して画像サイズを揃えました。
以下は、bicubicと各アルゴリズムのPSNRの結果一覧です。
PSNRの数値が高いほど元画像に近く、高解像度の画像であることを示しています。
| 補間・拡大処理 | PSNR(dB) |
|---|---|
| bicubic | 30.88 |
| SRCNN(2015) | 31.90 |
| FSRCNN(2016) | 32.25 |
| ESPCN(2016) | 32.10 |
| VDSR(2016) | 31.61 |
| DRCN(2016) | 31.44 |
| REDNet(2016) | 31.96 |
| DRRN(2017) | 32.03 |
| VSRnet(2016) | 32.19 |
| RVSR(2017) | 31.84 |
| VESPCN(2017) | 31.35 |
まさかのFSRCNNのPSNRが一番高くなりました。
後発の論文ほど理論上数値が高くなるはずなのですが、やはり学習に依存されるみたいですね...
1枚の画像で比較
次は、上の画像から1枚をピックアップして比較していきます。
今回、比較に使用した画像は以下の通りです。

見た感じ、動物園で撮影した写真のようです。
よく見てみると、所々歪んでいることが分かります。
この画像を高解像度化した結果の比較は以下の通りです。
| 補間・拡大処理 | PSNR(dB) |
|---|---|
| bicubic | 29.43 |
| SRCNN(2015) | 30.89 |
| FSRCNN(2016) | 31.30 |
| ESPCN(2016) | 31.21 |
| VDSR(2016) | 30.91 |
| DRCN(2016) | 30.24 |
| REDNet(2016) | 31.09 |
| DRRN(2017) | 31.17 |
| VSRnet(2016) | 31.24 |
| RVSR(2017) | 30.91 |
| VESPCN(2017) | 30.27 |
上記の平均結果と同様に、FSRCNNのPSNRが最も高い数値になりました。
最後に、高解像度画像の一覧を表示します。
横で比較しやすいように、bicubicだけ2回表示しています。


画像をみても、高解像度化がしっかりと行われていることが分かります。
コードの全容
前述の通り、Githubに載せています。
pythonのファイルは主に5つあります。
各ファイルの役割は以下の通りです。
-
data_create.py: データ生成に関するコード。 -
model.py: 超解像のアルゴリズムに関するコード。 -
train.py: 学習の際に使用するコード。 -
test.py: 検証の際にに使用するコード。 -
MyPReLU.py:PReLUの活性化関数のコード
まとめ
今回は、10種類の超解像アルゴリズムを比較してみました。
割と安易な考えで比較してみましたが、色々比較してみれて楽しかったです。
今後も、ちょくちょく超解像のアルゴリズムの記事を書きたいなと思います!
記事が長くなってしまいましたが、最後まで読んでくださりありがとうございました。