概要
深層学習を用いた、単一画像における超解像手法であるDRCNの実装したので、それのまとめの記事です。
Python + Tensorflow(Keras)で実装を行いました。
論文では長時間学習させているみたいですけど、今回は凄く控えめな規模で行っているので、ほぼ変化はありません...
この論文は、CVPR2016で採択された論文で、以前実装したVDSRと同じ著者です。
同時期に2本も論文を執筆していたそうです... 凄い...
今回紹介するコードはGithubにも載せています。
学習済みモデルは容量の関係でアップロードできませんでした...
1. 超解像のおさらい
超解像について簡単に説明をします。
超解像とは解像度の低い画像に対して、解像度を向上させる技術のことです。
ここでいう解像度が低いとは、画素数が少なかったり、高周波成分(輪郭などの鮮鋭な部分を表す成分)がないような画像のことです。
以下の図で例を示します。(図は[論文]より引用)
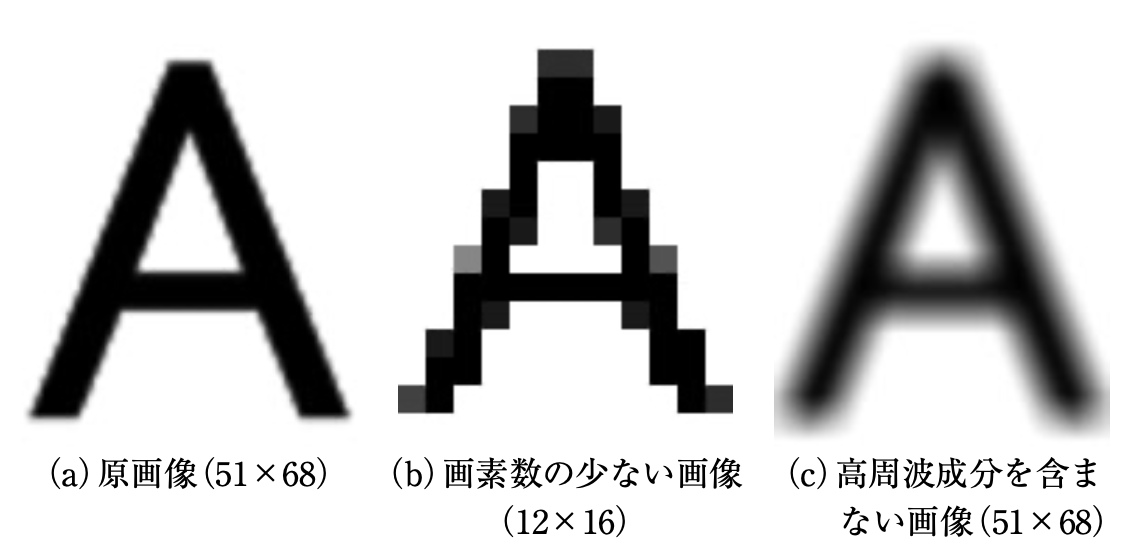
(a)は原画像、(b)は画素数の少ない画像を見やすいように原画像と同じ大きさにした画像、(c)は高周波成分を含まない画像の例です。
(b)と(c)は、荒かったりぼやけていたりしていると思います。
このような状態を解像度が低い画像といいます。
そして、超解像はこのような解像度が低い画像に処理を行い、(a)のような精細な画像を出力することを目的としています。
2. DRCNの超解像アルゴリズム
DRCN(Deeply-Recursive Convolutional Network)は、その名の通りリカーシブなモデルとなっています。
リカーシブは、IT用語としてはよく聞くかもしれません。
日本語では、再帰的という意味です。
関数の定義の一部で,その関数自身が用いられるものを示します。
これを、深層学習的な意味合いに置き換えると、同じ畳み込み層を使用して、層の重みを共有しよう!
といった感じになっています。
実際、今回紹介するモデルでは同じ畳み込み層を何度も繰り返し使用することで重みの共有をしています。
DRCNのアルゴリズムの概要図は以下の通りです。(図は論文から引用)
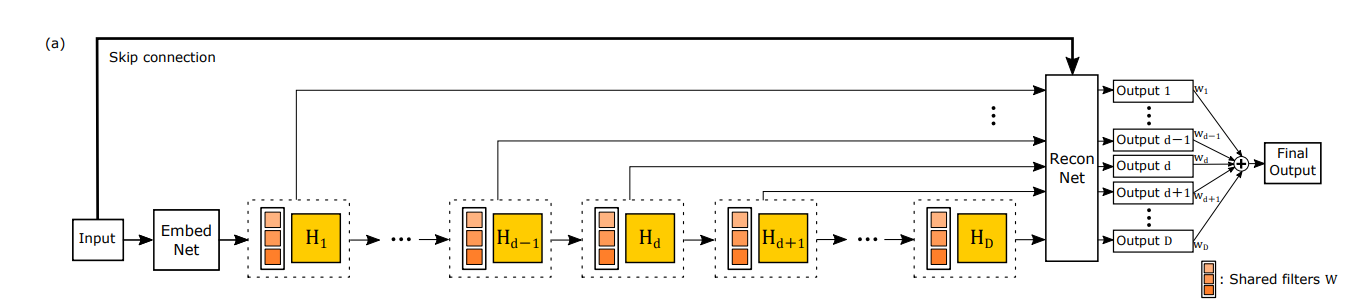
主に、
-
Embedding net:特徴マップの生成ネットワーク -
Inference net:メインの超解像ネットワーク -
Reconstruction net:再構成のネットワーク +Skip_connection
の3つのネットワークに分かれています。
図では多数のネットワークが描かれていますが、同じ畳み込み層を繰り返し利用するので、パラメータ数は控えめになっています。
このモデルのイメージとしては、繰り返しCNNに画像を入力することで、徐々に画像をきれいにしていく感じです。
もう少し詳しい概要図は以下の通りです。(図は論文から引用)
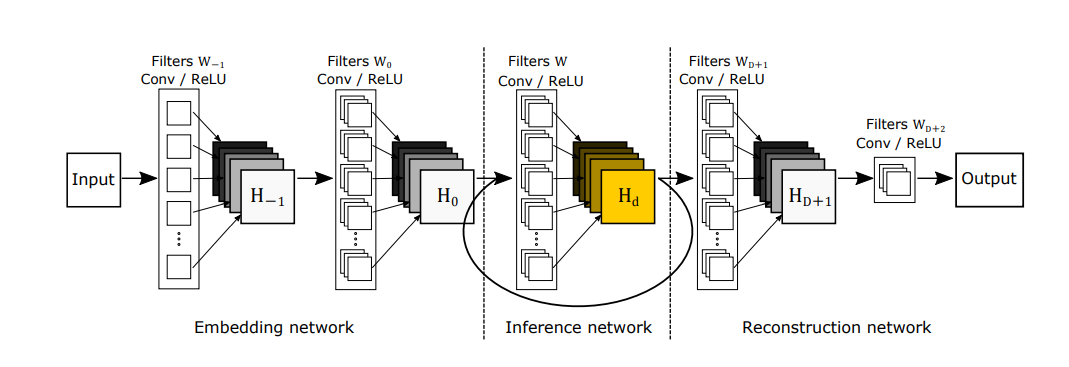
図の通り、Conv + ReLUが基本構成になっています。また、フィルター数やフィルターサイズは基本的には同じものを使用します。
今回実装したDRCNは、事前にbicubicで拡大処理を行います。
3. 実装したアルゴリズム
今回、実装したDRCNのモデルは以下のように組みました。(コードの一部を抽出)
今回は繰り返し数を16、フィルター数は256、フィルターサイズは3*3で実装しています。
def DRCN(recursive_depth, input_channels, filter_num = 256):
"""
recursive_depth : numbers of recursive_conv2d.
input_channels : channels of input_img.(gray → 1, RGB → 3)
filter_num : filter numbers.(default 256)
"""
Inferencd_conv2d = Conv2D(filters = filter_num, kernel_size = (3, 3), padding = "same", activation = "relu")
"""
Inferencd_conv2d : Inference net.
"""
#model
input_shape = Input((None, None, input_channels))
#Embedding net.
conv2d_0 = Conv2D(filters = filter_num, kernel_size = (3, 3), padding = "same", activation = "relu")(input_shape)
conv2d_1 = Conv2D(filters = filter_num, kernel_size = (3, 3), padding = "same", activation = "relu")(conv2d_0)
#Inference net and Reconstruction net.
weight_list = recursive_depth * [None]
pred_list = recursive_depth * [None]
for i in range(recursive_depth):
Inferencd_output = Inferencd_conv2d(conv2d_1)
Recon_0 = Conv2D(filters = filter_num, kernel_size = (3, 3), padding = "same", activation = "relu")(Inferencd_output)
Recon_1 = Conv2D(filters = input_channels, kernel_size = (3, 3), padding = "same", activation = "relu")(Recon_0)
weight_list[i] = Recon_1
for i in range(recursive_depth):
skip_connection = Add()([weight_list[i], input_shape])
pred = Multiply()([weight_list[i], skip_connection])
pred_list[i] = pred
pred = Add()(pred_list)
model = Model(inputs = input_shape, outputs = pred)
model.summary()
return model
簡単なコードの説明をします。
まず、モデルの関数を呼び出す時に、いくつか値を設定します。
def DRCN(recursive_depth, input_channels, filter_num = 256):
"""
recursive_depth : numbers of recursive_conv2d.
input_channels : channels of input_img.(gray → 1, RGB → 3)
filter_num : filter numbers.(default 256)
"""
ここでは、recursive_depthが繰り返し数、input_channelsは入力画像のチャンネル数、filter_numがフィルター数を示しています。
今回は繰り返し数を16、フィルター数は256で実装したので、それを入れてもらえれば大丈夫です。
また、学習にグレースケール画像を使用したので、input_channelsは1です。
Kerasでは、レイヤーの重みを共有するために、事前にレイヤーを定義しておく必要があります。
事前にレイヤーを定義しておき、重みを共有したい層でそのレイヤーを都度呼び出すという感じです。
Kerasのドキュメントに詳細が書かれています。
本モデルでは以下のように、定義しました。Inference netの重みを共有させています。
Inferencd_conv2d = Conv2D(filters = filter_num, kernel_size = (3, 3), padding = "same", activation = "relu")
"""
Inferencd_conv2d : Inference net.
"""
また、最終的な結果は以下のように出力しました。
各再構成層の重みを $w_{n}$、Skip_connectionで足し合わせる入力画像を $y$、最終的な出力画像を $\hat{y}$、繰り返し数を $d$とすると、
$\hat{y} = \sum_{n = 1}^{d} w_{n}(y + w_{n}) $
となります。
各Reconstruction netの重みとSkip_connectionを足し合わせ、更に重みを掛け合わせ、それぞれの結果の和を出力結果としました。
4. 使用したデータセット
今回は、データセットにDIV2K datasetを使用しました。
このデータセットは、単一画像のデータセットで、学習用が800種、検証用とテスト用が100種類ずつのデータセットです。
今回は、学習用データと検証用データを使用しました。
パスの構造はこんな感じです。
train_sharp - 0001.png
- 0002.png
- ...
- 0800.png
val_sharp - 0801.png
- 0802.png
- ...
- 0900.png
このデータをBicubicで縮小したりしてデータセットを生成しました。
5. 画像評価指標PSNR
今回は、画像評価指標としてPSNRを使用しました。
PSNR とは Peak Signal-to-Noise Ratio(ピーク信号対雑音比) の略で、単位はデジベル (dB) で表せます。
PSNR は信号の理論ピーク値と誤差の2乗平均を用いて評価しており、8bit画像の場合、255(最大濃淡値)を誤差の標準偏差で割った値です。
今回は、8bit画像を使用しましたが、計算量を減らすため、全画素値を255で割って使用しました。
そのため、最小濃淡値が0で最大濃淡値が1です。
dB値が高いほど拡大した画像が元画像に近いことを表します。
PSNRの式は以下のとおりです。
PSNR = 10\log_{10} \frac{1^2 * w * h}{\sum_{x=0}^{w-1}\sum_{y=0}^{h-1}(p_1(x,y) - p_2(x,y))^2 }
なお、$w$は画像の幅、$h$は画像の高さを表しており、$p_1$は元画像、$p_2$はPSNRを計測する画像を示しています。
6. コードの使用方法
このコード使用方法は、自分が執筆した別の実装記事とほとんど同じです。
① 学習データ生成
まず、Githubからコードを一式ダウンロードして、カレントディレクトリにします。
Windowsのコマンドでいうとこんな感じ。
C:~/keras_DRCN>
次に、main.pyから生成するデータセットのサイズ・大きさ・切り取る枚数、ファイルのパスなどを指定します。
main.pyの12~21行目です。
使うPCのメモリ数などに応じで、画像サイズや学習データ数の調整が必要です。
parser.add_argument('--train_height', type=int, default=41, help="Train data size(height)")
parser.add_argument('--train_width', type=int, default=41, help="Train data size(width)")
parser.add_argument('--test_height', type=int, default=360, help="Test data size(height)")
parser.add_argument('--test_width', type=int, default=640, help="Test data size(width)")
parser.add_argument('--train_dataset_num', type=int, default=10000, help = "Number of train datasets to generate")
parser.add_argument('--test_dataset_num', type=int, default=5, help="Number of test datasets to generate")
parser.add_argument('--train_cut_num', type=int, default=10, help="Number of train data to be generated from a single image")
parser.add_argument('--test_cut_num', type=int, default=1, help="Number of test data to be generated from a single image")
parser.add_argument('--train_path', type=str, default="../../dataset/DIV2K_train_HR", help="The path containing the train image")
parser.add_argument('--test_path', type=str, default="../../dataset/DIV2K_valid_HR", help="The path containing the test image")
指定したら、コマンドでデータセットの生成をします。
C:~/keras_DRCN>python main.py --mode train_datacreate
これで、train_data_list.npzというファイルのデータセットが生成されます。
ついでにテストデータも同じようにコマンドで生成します。コマンドはこれです。
C:~/keras_DRCN>python main.py --mode test_datacreate
② 学習
次に学習を行います。
設定するパラメータの箇所は、epoch数と学習率、今回のモデルの層の数です。
まずは、main.pyの22~26行目
parser.add_argument('--recursive_depth', type=int, default=16, help="Number of Inference nets in the model")
parser.add_argument('--input_channels', type=int, default=1, help="Number of channels for the input image")
parser.add_argument('--BATCH_SIZE', type=int, default=64, help="Training batch size")
parser.add_argument('--EPOCHS', type=int, default=100, help="Number of epochs to train for")
後は、学習のパラメータをあれこれ好きな値に設定します。74~90行目です。
今回は、モデルを使用するために、モデルの層の数とチャンネル数を設定しないといけません。
また、Loss functionの値に応じて、学習率を変更させる必要があるため、81行目でreduce_lrというKerasのコールバックを使用しています。詳しくはKerasのドキュメントをご覧ください。
train_model = model.DRCN(args.recursive_depth, args.input_channels)
optimizers = tf.keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=1e-4, nesterov=False)
train_model.compile(loss = "mean_squared_error",
optimizer = optimizers,
metrics = [psnr])
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor = 'loss', factor = 0.1, patience = 5, mode = "min", min_lr = 1e-6)
train_model.fit(train_x,
train_y,
epochs = args.EPOCHS,
verbose = 2,
callbacks = [reduce_lr],
batch_size = args.BATCH_SIZE)
train_model.save("DRCN_model.h5")
optimizerはmomentum、損失関数はmean_squared_errorを使用しています。
学習はデータ生成と同じようにコマンドで行います。
C:~/keras_DRCN>python main.py --mode train_model
これで、学習が終わるとモデルが出力されます。
③ 評価
最後にモデルを使用してテストデータで評価を行います。
これも同様にコマンドで行いますが、事前に①でテストデータも生成しておいてください。
C:~/keras_DRCN>python main.py --mode evaluate
このコマンドで、画像を出力してくれます。
7. 結果
出力した画像はこのようになりました。
なお、今回は輝度値のみで学習を行っているため、カラー画像には対応していません。
-
元画像

-
低解像度画像

-
生成画像
PSNR:24.48

平滑化フィルタみたいな感じの結果になってしまいました...
パラメータとかモデルの構造をもう一回見直したほうがいいかもしれません。
最後に元画像・低解像度画像・生成画像の一部を並べて表示してみます。

8. コードの全容
前述の通り、Githubに載せています。
pythonのファイルは主に3つあります。
各ファイルの役割は以下の通りです。
- data_create.py : データ生成に関するコード。
- model.py : 超解像のアルゴリズムに関するコード。
- main.py : 主に使用するコード。
9. まとめ
今回は、最近読んだ論文のDRCNを元に実装してみました。
これ本当に超解像なのか???という残念な結果になってしまいましたが、論文ではちゃんと結果が出ています!!!
詳しくは論文を読んでいただけると幸いです。
私自身もモデルの構造の再検討を後日してみようと思います。
記事が長くなってしまいましたが、最後まで読んでくださりありがとうございました。
参考文献
・Deeply-Recursive Convolutional Network for Image Super-Resolution
実装の参考にした論文。
・画素数の壁を打ち破る 複数画像からの超解像技術
超解像の説明のために使用。
・DIV2K dataset
今回使用したデータセット。
・Kerasドキュメント
重み共有・コールバックの実装の参考に使用。