概要
深層学習を用いた、単一画像における超解像手法であるDRRNの実装したので、それのまとめの記事です。
Python + Tensorflow(Keras)で実装を行い、2倍拡大の超解像にチャレンジしました。
今回紹介するコードはGithubにも載せています。
(【5/29 19:12追記】GithubのリポジトリがPrivateになっていたのでPublicに変更しました。)
DRRNのアルゴリズム
まずはじめに、DRRNのアルゴリズムの概要図を示します。(図は論文から引用)
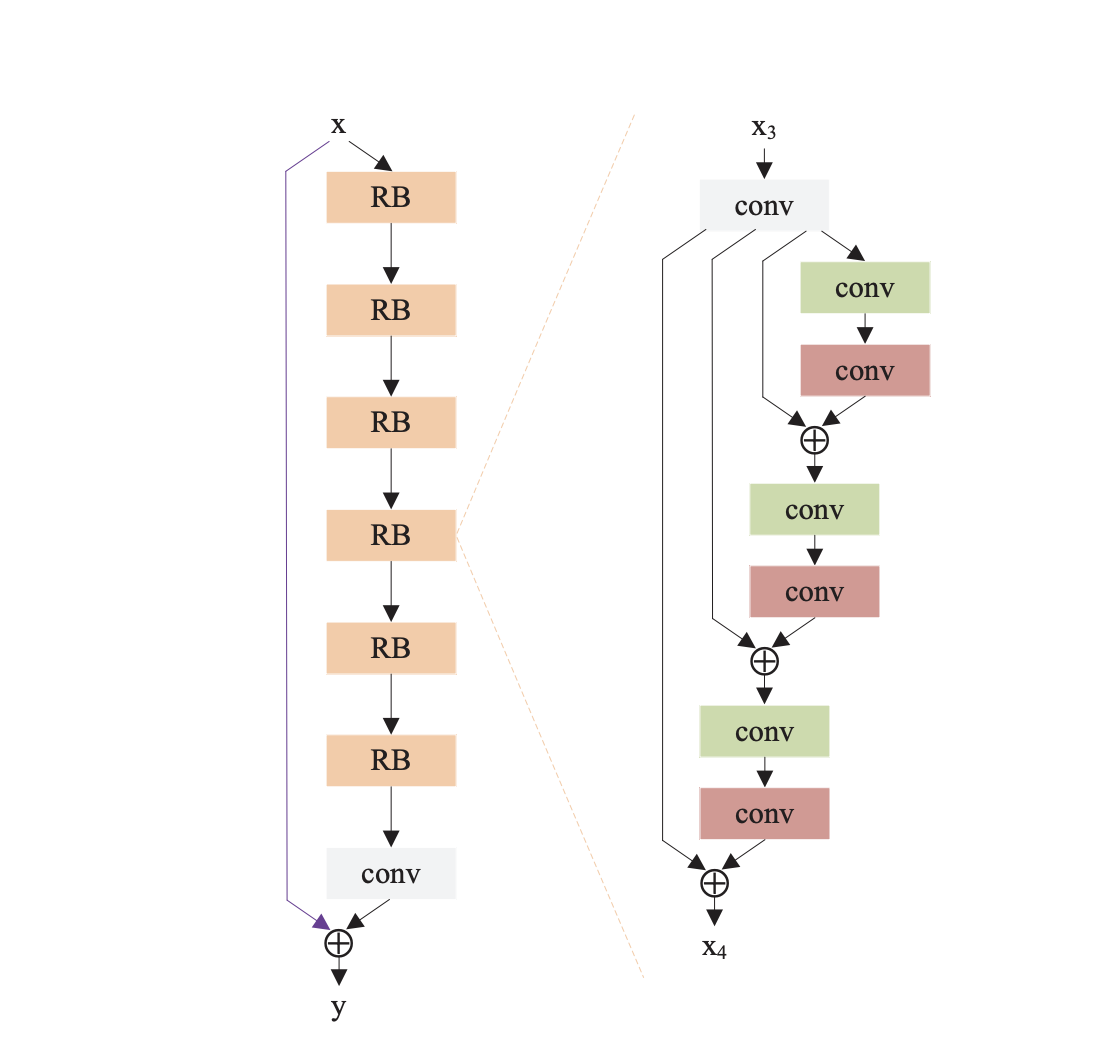
DRRNの全体図は左のようになっています。
DRRNは任意の数のRecursive Blockから成立しており、最後にConvolutionで結果を出力します。
今回の図だと、Recursive Blockの数は6つとなっています。(図のRBの数)
Recursive Blockの中の構成は図の右のようになっています。
Residual Unitsという名前で論文では紹介されており、図のような構成になっています。
しかし、Convolutionだけではなく、毎回Batch NormalizationとReLUも下の図のように行っているので注意が必要です。
また、各畳み込み層で重みを共有しており、他のユニットのConvolutionと重み共有を行っています。

こちらも好きな数を設定することができますので、お好みでという感じです。
数ごとによる構成の変化は以下の図のようになります。(下の図だと、Unitの数は3つ)
毎回Skip connectionみたいに足し合わせるのを忘れないようにしないといけません。

今回実装したDRRNでは、事前にbicubicで拡大処理を行います。
また、論文では1つのRecursive Blockと25つのResidual Unitsで構成されています
実装したアルゴリズム
今回、実装したDRRNのモデルは以下のように組みました。(コードの一部を抽出)
def DRRN(recursive_brocks, recursive_units, input_channels, filter_num = 128, filter_size = (3, 3)):
"""
recursive_brocks : numbers of recursive blocks.(>=1)
recursive_units : Number of residual units in the recursive block.(>=1)
input_channels : Channels of input_img.(gray → 1, RGB → 3)
filter_num : Filter numbers.(default 128)
filter_size : Filter size.(default 3*3)
"""
Units_conv_1 = Conv2D(filters = filter_num, kernel_size = filter_size, padding = "same")
Units_conv_2 = Conv2D(filters = filter_num, kernel_size = filter_size, padding = "same")
"""
units_conv → same weight
"""
#model
input_shape = Input((None, None, input_channels))
#recursive blocks
for B in range(recursive_brocks):
if B == 0:
conv2d_0 = Conv2D(filters = filter_num, kernel_size = filter_size, padding = "same")(input_shape)
else:
conv2d_0 = Conv2D(filters = filter_num, kernel_size = filter_size, padding = "same")(add_conv)
#a box of variables for looping.
add_conv = conv2d_0
#recursive units
for U in range(recursive_units):
unit_batch_1 = BatchNormalization()(add_conv)
unit_relu_1 = ReLU()(unit_batch_1)
unit_conv_1 = Units_conv_1(unit_relu_1)
unit_batch_2 = BatchNormalization()(unit_conv_1)
unit_relu_2 = ReLU()(unit_batch_2)
unit_conv_2 = Units_conv_2(unit_relu_2)
add_conv = Add()([conv2d_0, unit_conv_2])
#output conv2d
conv2d_out = Conv2D(filters = input_channels, kernel_size = filter_size, padding = "same")(add_conv)
#skip connection
skip_connection = Add()([input_shape, conv2d_out])
model = Model(inputs = input_shape, outputs = skip_connection)
model.summary()
return model
Skip connectionという、処理前の画像を足し合わせる工程が随所にあるので、forによる繰り返しを導入してモデルを作成しました。
使用したデータセット
今回は、データセットにDIV2K datasetを使用しました。
このデータセットは、単一画像のデータセットで、学習用が800種、検証用とテスト用が100種類ずつのデータセットです。
今回は、学習用データと検証用データを使用しました。
パスの構造はこんな感じです。
train_sharp - 0001.png
- 0002.png
- ...
- 0800.png
val_sharp - 0801.png
- 0802.png
- ...
- 0900.png
このデータをbicubicで縮小したりしてデータセットを生成しました。
コードの使用方法
このコード使用方法は、自分が執筆した別の実装記事とほとんど同じです。
学習データ生成
まず、Githubからコードを一式ダウンロードして、カレントディレクトリにします。
Windowsのコマンドでいうとこんな感じ。
C:~/keras_DRRN>
次に、main.pyから生成するデータセットのサイズ・大きさ・切り取る枚数、ファイルのパスなどを指定します。
main.pyの12~21行目です。
使うPCのメモリ数などに応じで、画像サイズや学習データ数の調整が必要です。
parser.add_argument('--train_height', type=int, default=31, help="Train data size(height)")
parser.add_argument('--train_width', type=int, default=31, help="Train data size(width)")
parser.add_argument('--test_height', type=int, default=720, help="Test data size(height)")
parser.add_argument('--test_width', type=int, default=1280, help="Test data size(width)")
parser.add_argument('--train_dataset_num', type=int, default=50000, help = "Number of train datasets to generate")
parser.add_argument('--test_dataset_num', type=int, default=5, help="Number of test datasets to generate")
parser.add_argument('--train_cut_num', type=int, default=10, help="Number of train data to be generated from a single image")
parser.add_argument('--test_cut_num', type=int, default=1, help="Number of test data to be generated from a single image")
parser.add_argument('--train_path', type=str, default="../../dataset/DIV2K_train_HR", help="The path containing the train image")
parser.add_argument('--test_path', type=str, default="../../dataset/DIV2K_valid_HR", help="The path containing the test image")
指定したら、コマンドでデータセットの生成をします。
C:~/keras_DRRN>python main.py --mode train_datacreate
これで、train_data_list.npzというファイルのデータセットが生成されます。
ついでにテストデータも同じようにコマンドで生成します。コマンドはこれです。
C:~/keras_DRRN>python main.py --mode test_datacreate
学習
次に学習を行います。
設定するパラメータの箇所は、epoch数と学習率、今回のモデルの層の数です。
まずは、main.pyの22~26行目。
parser.add_argument('--recursive_brocks', type=int, default=3, help="Number of Inference nets in the model")
parser.add_argument('--recursive_units', type=int, default=3, help="Number of Inference nets in the model")
parser.add_argument('--input_channels', type=int, default=1, help="Number of channels for the input image")
parser.add_argument('--first_learning_rate', type = float, default = 1e-4, help = "First learning_rate")
parser.add_argument('--BATCH_SIZE', type=int, default=128, help="Training batch size")
parser.add_argument('--EPOCHS', type=int, default=1000, help="Number of epochs to train for")
recursive_brocksとrecursive_unitsは、上で紹介したモデルの層の数を示すパラメータです。
その下では、学習率や学習回数などを指定します。
次に、学習のパラメータをあれこれ好きな値に設定します。
main.pyの80~93行目のパラメータを調節します。
train_model = model.DRRN(args.recursive_brocks, args.recursive_units, args.input_channels)
optimizers = tf.keras.optimizers.Adam(lr = args.first_learning_rate)
train_model.compile(loss = "mean_squared_error",
optimizer = optimizers,
metrics = [psnr])
train_model.fit(train_x,
train_y,
epochs = args.EPOCHS,
verbose = 2,
batch_size = args.BATCH_SIZE)
train_model.save("DRRN_model.h5")
optimizerはAdam、損失関数はmean_squared_errorを使用しています。
論文ではoptimizerにSGDを用いていましたが、収束しなさそうだったので代わりにAdamを使用しています。
学習はデータ生成と同じようにコマンドで行います。
C:~/keras_DRRN>python main.py --mode train_model
これで、学習が終わるとモデルが出力されます。
評価
最後にモデルを使用してテストデータで評価を行います。
これも同様にコマンドで行いますが、事前に①でテストデータも生成しておく必要があります。
C:~/keras_DRRN>python main.py --mode evaluate
このコマンドで、画像を出力してくれます。
結果
出力した画像の結果例を以下に示します。
なお、今回は輝度値のみで学習を行っているため、カラー画像には対応していません。
まず、今回検証に使用した画像は以下の通りです。

bicubicとDRRNの各アルゴリズムのPSNRの数値は以下のようになりました。
PSNRの数値が高いほど元画像に近い高解像度の画像になります。
| 補間・拡大処理 | PSNR(dB) |
|---|---|
| bicubic | 29.43 |
| DRRN | 30.67 |
この画像では、PSNRの値が1ほど向上しました。
今回のモデルでは、Batch Normalizationが入っているので収束が終わりませんでした。
収束させるまで学習させるとPSNRはもう少し向上すると思います。
また、他の画像でも試しましたが、PSNRの差があったりほぼなかったりと色々な結果になりました。
小規模学習だったりパラメータだったりと色々理由はありそうですね...
最後に元画像・低解像度画像・生成画像の一部を並べて拡大表示してみます。

窓枠のゆがみなどが抑えられていることが結果からも分かります。
コードの全容
前述の通り、Githubに載せています。
pythonのファイルは主に3つあります。
各ファイルの役割は以下の通りです。
-
data_create.py: データ生成に関するコード。 -
model.py: 超解像のアルゴリズムに関するコード。 -
main.py: 主に使用するコード。
実装環境
-
PC環境
-
CPU: AMD Ryzen 5 3500 6-Core Processor -
memory size: 40GB -
GPU: NVIDIA GeForce RTX 2060 SUPER -
OS: Windows 10
-
-
ライブラリ環境
-
python: 3.7.9 -
tensorflow-gpu: 2.4.1 -
keras: 2.4.3 -
opencv-python: 4.4.0.43
-
まとめ
今回は、単一画像における超解像手法であるDRRNを実装してみました。
記事が長くなってしまいましたが、最後まで読んでくださりありがとうございました。
参考文献
・Image Super-Resolution via Deep Recursive Residual Network
実装の参考にした論文。
・DIV2K dataset
今回使用したデータセット。