概要
深層学習を用いた、単一画像における超解像手法であるFSRCNNの実装したので、それのまとめの記事です。
Python + Tensorflow(Keras)で実装を行いました。
今回紹介するコードはGithubにも載せています。
1. 超解像のおさらい
超解像について簡単に説明をします。
超解像とは解像度の低い画像に対して、解像度を向上させる技術のことです。
ここでいう解像度が低いとは、画素数が少なかったり、高周波成分(輪郭などの鮮鋭な部分を表す)がないような画像のことです。
以下の図で例を示します。(図は[論文]より引用)
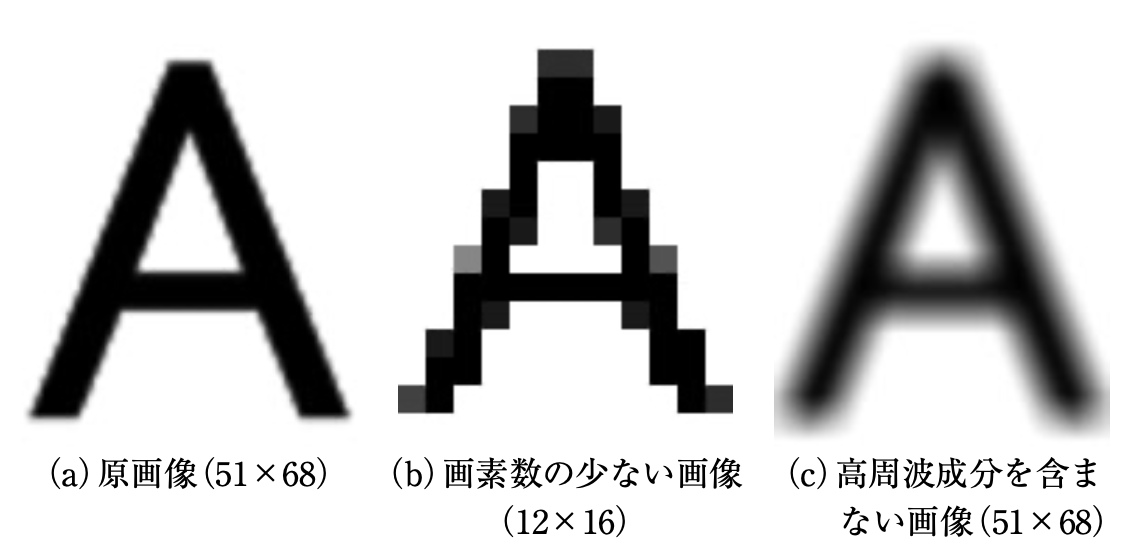
これは、超解像の説明をする時によく使われる画像です。
(a)は原画像、(b)は画素数の少ない画像を見やすいように原画像と同じ大きさにした画像、(c)は高周波成分を含まない画像の例です。
(b)と(c)は、荒かったりぼやけていたりしていると思います。
このような状態を解像度が低い画像といいます。
そして、超解像はこのような解像度が低い画像に処理を行い、(a)のような精細な画像を出力することを目的としています。
2. 論文の超解像アルゴリズム
超解像のアルゴリズムの概要図は以下の通りです。(図は論文から引用)
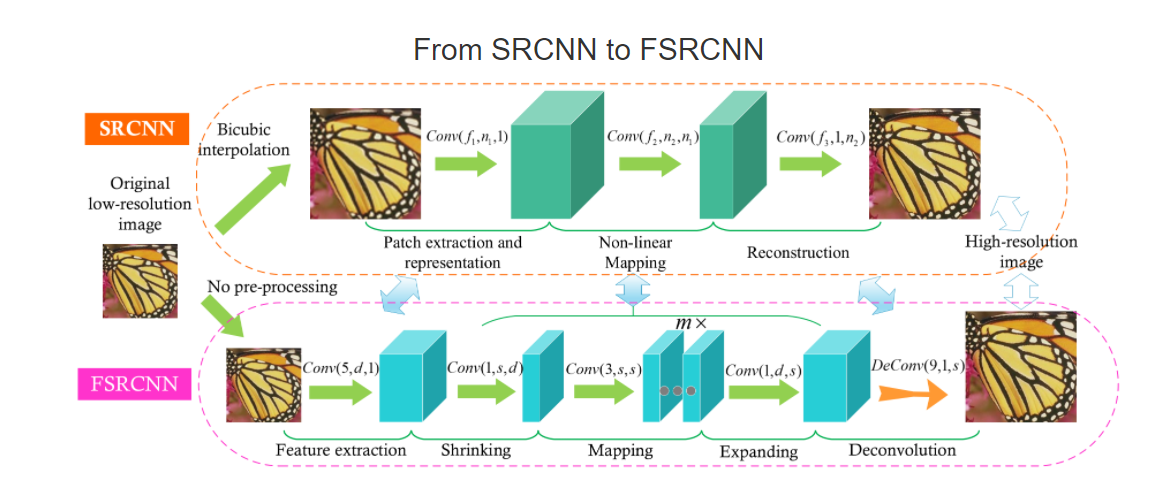
上の図がSRCNN、下の図がFSRCNNのモデルの概要図となっています。
SRCNNでは、最初にBicubic法で画像を補間してからニューラルネットワークに入力しており、画像サイズが大きい状態で特徴抽出や返還を行っていました。
そのため、CNNのサイズが大きくなったり、計算が非効率になっているという問題がありました。
そこで、FSRCNNではSRCNNの大まかなモデルの構造はそのままに、
Feature extractionShrinkingMappingExpandingDeconvolution
のいくつかの層に分けることで、各層のCNNのサイズを小さくすることに成功しました。
また、LR画像から直接ピクセルの特徴抽出・変換を行うことで、で効率良い演算ができるようにしているのも特徴です。
3. 実装したアルゴリズム
今回、実装したFSRCNNの構造のコマンドラインは以下の通りです。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, None, None, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, None, None, 56) 1512
_________________________________________________________________
conv2d_1 (Conv2D) (None, None, None, 16) 928
_________________________________________________________________
conv2d_2 (Conv2D) (None, None, None, 16) 2336
_________________________________________________________________
conv2d_3 (Conv2D) (None, None, None, 16) 2336
_________________________________________________________________
conv2d_4 (Conv2D) (None, None, None, 16) 2336
_________________________________________________________________
conv2d_5 (Conv2D) (None, None, None, 16) 2336
_________________________________________________________________
conv2d_6 (Conv2D) (None, None, None, 56) 1008
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, None, None, 1) 4537
=================================================================
Total params: 17,329
Trainable params: 17,329
Non-trainable params: 0
_________________________________________________________________
なお、mappingの回数は4回でモデルを制作しています。
活性化関数はPReLUを使用しました。
KerasのClass PReLUの状態だと、Input_shape = (None, None, 1)の任意の自然数に対応していないので、今回は独自のClass PReLUを作成しました。
コードは以下の通りです。
class MyPReLU(Layer): #PReLUを独自に作成
def __init__(self,
alpha_initializer = 'zeros',
alpha_regularizer = None,
alpha_constraint = None,
shared_axes = None,
**kwargs):
super(MyPReLU, self).__init__(**kwargs)
self.alpha_initializer = initializers.get('zeros')
self.alpha_regularizer = regularizers.get(None)
self.alpha_constraint = constraints.get(None)
def build(self, input_shape):
param_shape = tuple(1 for i in range(len(input_shape) - 1)) + input_shape[-1:]
self.alpha = self.add_weight(shape = param_shape,
name = 'alpha',
initializer = self.alpha_initializer,
regularizer = self.alpha_regularizer,
constraint = self.alpha_constraint)
self.built = True
def call(self, inputs, mask=None):
pos = K.relu(inputs)
neg = -self.alpha * K.relu(-inputs)
return pos + neg
def compute_output_shape(self, input_shape):
return input_shape
def get_config(self):
config = {
'alpha_initializer': initializers.serialize(self.alpha_initializer),
'alpha_regularizer': regularizers.serialize(self.alpha_regularizer),
'alpha_constraint': constraints.serialize(self.alpha_constraint),
}
base_config = super(MyPReLU, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
stack over flowの質問を参考に、Kerasのドキュメントを変更して作成しました。
4. 使用したデータセット
今回は、データセットにDIV2K datasetを使用しました。
このデータセットは、単一画像のデータセットで、学習用が800種、検証用とテスト用が100種類ずつのデータセットです。
今回は、学習用データと検証用データを使用しました。
パスの構造はこんな感じです。
train_sharp - 0001.png
- 0002.png
- ...
- 0800.png
val_sharp - 0801.png
- 0802.png
- ...
- 0900.png
このデータをBicubicで縮小したりしてデータセットを生成しました。
5. 画像評価指標PSNR
今回は、画像評価指標としてPSNRを使用しました。
PSNR とは Peak Signal-to-Noise Ratio(ピーク信号対雑音比) の略で、単位はデジベル (dB) で表せます。
PSNR は信号の理論ピーク値と誤差の2乗平均を用いて評価しており、8bit画像の場合、255(最大濃淡値)を誤差の標準偏差で割った値です。
今回は、8bit画像を使用しましたが、計算量を減らすため、全画素値を255で割って使用しました。
そのため、最小濃淡値が0で最大濃淡値が1です。
dB値が高いほど拡大した画像が元画像に近いことを表します。
PSNRの式は以下のとおりです。
PSNR = 10\log_{10} \frac{1^2 * w * h}{\sum_{x=0}^{w-1}\sum_{y=0}^{h-1}(p_1(x,y) - p_2(x,y))^2 }
なお、$w$は画像の幅、$h$は画像の高さを表しており、$p_1$は元画像、$p_2$はPSNRを計測する画像を示しています。
6. コードの使用方法
このコード使用方法は、自分が執筆した別の実装記事とほとんど同じです。
① 学習データ生成
まず、Githubからコードを一式ダウンロードして、カレントディレクトリにします。
Windowsのコマンドでいうとこんな感じ。
C:~/keras_FSRCNN>
次に、main.pyから生成するデータセットのサイズ・大きさ・切り取る枚数、ファイルのパスなどを指定します。
main.pyの15~26行目です。
使うPCのメモリ数などに応じで、画像サイズや学習データ数の調整が必要です。
train_height = 120 #HRのサイズ
train_width = 120
test_height = 720 #HRのサイズ
test_width = 1280
train_dataset_num = 10000 #生成する学習データの数
test_dataset_num = 10 #生成するテストデータの数
train_cut_num = 10 #一組の動画から生成するデータの数
test_cut_num = 1
train_path = "../../dataset/DIV2K_train_HR" #画像が入っているパス
test_path = "../../dataset/DIV2K_valid_HR"
指定したら、コマンドでデータセットの生成をします。
C:~/keras_FSRCNN>python main.py --mode train_datacreate
これで、train_data_list.npzというファイルのデータセットが生成されます。
ついでにテストデータも同じようにコマンドで生成します。コマンドはこれです。
C:~/keras_FSRCNN>python main.py --mode test_datacreate
② 学習
次に学習を行います。
設定するパラメータの箇所は、epoch数と学習率とかですかね...
まずは、main.pyの28~31行目
mag = 4 #拡大倍率
BATSH_SIZE = 32
EPOCHS = 1000
後は、学習のパラメータをあれこれ好きな値に設定します。81~94行目です。
なお、今回のFSRCNNではこちらが設定するパラメータがいくつかあります。
model.pyには書いているのですが、こちらにも記載しておきます。
まずは、FSRCNNのパラメータはこのようになっています。
def FSRCNN(d, s, m, mag):
"""
d : The LR feature dimension
s : The number of shrinking filters
m : The mapping depth
mag : Magnification
"""
main.pyのパラメータ設定はこのようになっています。
train_model = model.FSRCNN(56, 16, 4, mag)
optimizers = tf.keras.optimizers.Adam(learning_rate=1e-4)
train_model.compile(loss = "mean_squared_error",
optimizer = optimizers,
metrics = [psnr])
train_model.fit(train_x,
train_y,
epochs = EPOCHS,
verbose = 2,
batch_size = BATSH_SIZE)
train_model.save("FSRCNN_model.h5")
optimizerはAdam、損失関数は平均二乗誤差を使用しています。
学習はデータ生成と同じようにコマンドで行います。
C:~/keras_FSRCNN>python main.py --mode train_model
これで、学習が終わるとモデルが出力されます。
③ 評価
最後にモデルを使用してテストデータで評価を行います。
これも同様にコマンドで行いますが、事前に①でテストデータも生成しておいてください。
C:~/keras_FSRCNN>python main.py --mode evaluate
このコマンドで、画像を出力してくれます。
7. 結果
出力した画像はこのようになりました。
なお、今回は輝度値のみで学習を行っているため、カラー画像には対応していません。
対応させる場合は、modelのInputのchannel数を変えたり、データセット生成のchannel数を変える必要があります。
-
元画像

-
低解像度画像(4倍縮小)

-
生成画像
PSNR:25.15

分かりにくいので、低解像度画像を拡大にして生成画像と同じサイズにしたものも載せておきます。
- 低解像度画像(生成画像と同じサイズに拡大)

低解像度画像に比べると生成画像の粗さが取れていることがわかります。
最後に元画像・低解像度画像・生成画像の一部を並べて表示してみます。

並べて比べてみると、補間よりは高解像度化がされているのが分かります・
流石に4倍だとなかなかうまくいかないのが現実です。
ついでに、大失敗した例も載せておきます。

低解像度生成の状態から既に線が分離しており、上手く高解像度化ができていません。
このことからも分かるように、超解像に適した画像とそうでない画像があります。
8. コードの全容
前述の通り、Githubに載せています。
pythonのファイルは主に3つあります。
各ファイルの役割は以下の通りです。
- data_create.py : データ生成に関するコード。
- model.py : 超解像のアルゴリズムに関するコード。
- main.py : 主に使用するコード。
9. まとめ
今回は、最近読んだ論文のFSRCNNを元に実装してみました。
FSRCNNは、拡大処理もニューラルネットワークの中に入っているのが特徴です。
超解像の失敗例も一緒に載せれたのでよかったです。
記事が長くなってしまいましたが、最後まで読んでくださりありがとうございました。
参考文献
・Accelerating the Super-Resolution Convolutional Neural Network
今回実装の参考にした論文。
・画素数の壁を打ち破る 複数画像からの超解像技術
超解像の説明のために使用。
・DIV2K dataset
今回使用したデータセット。
・Keras advanced_activations.py
KerasのPReLUが記載されている元コード。今回はこれをコピーして変更した。
・stack overflowの質問
PReLUに関する質問。PReLUを採用しているモデルの入力次元数が指定されていない場合の対処法を記している。