概要
今回は、超解像手法の1つであるESPCN(efficient sub-pixel convolutional neural network)を組みましたので、そのまとめとして投稿します。
元論文はこちらから→Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
目次
1.はじめに
2.ESPCNとは
3.PC環境
4.コード説明
5.終わりに
1.はじめに
超解像とは、解像度が低い画像や動画像に対して解像度を向上させる技術のことであり、ESPCNは2016年に提案された手法のことです。(ちなみに初のDeeplearningの手法として挙げられるSRCNNは2014年)
SRCNNはバイキュービック法など、既存の拡大手法に組み合わせて解像度の向上を図る手法でしたが、このESPCNではDeeplearningのモデルの中に拡大フェーズが導入されており、任意の倍率で拡大することができます。
今回は、この手法をpythonで組みましたので、コード紹介をしたいと思います。
コードの全容はGitHubにも投稿しているのでそちらをご確認ください。
https://github.com/nekononekomori/espcn_keras
2.ESPCNとは
ESPCNとは、DeeplearningのモデルにSubpixel Convolution(Pixel shuffle)を導入して解像度の向上を図った手法のことです。コードを載せるのがメインなので、詳細の説明は省きますが、ESPCNについて説明しているサイトを載せておきます。
https://buildersbox.corp-sansan.com/entry/2019/03/20/110000
https://qiita.com/oki_uta_aiota/items/74c056718e69627859c0
https://qiita.com/jiny2001/items/e2175b52013bf655d617
3.PC環境
cpu : intel corei7 8th Gen
gpu : NVIDIA GeForce RTX 1080ti
os : ubuntu 20.04
4.コード説明
GitHubを見ていただくと分かるのですが、主に3つのコードからなっています。
・datacreate.py → データセット生成プログラム
・model.py → ESPCNのプログラム
・main.py → 実行プログラム
datacreate.pyとmodel.pyで関数を作成し、main.pyで実行しています。
datacreate.pyの説明
import cv2
import os
import random
import glob
import numpy as np
import tensorflow as tf
# 任意のフレーム数を切り出すプログラム
def save_frame(path, #データが入っているファイルのパス
data_number, #1枚の画像から切り取る写真の数
cut_height, #保存サイズ(縦)(低画質)
cut_width, #保存サイズ(横)(低画質)
mag, #拡大倍率
ext='jpg'):
#データセットのリストを生成
low_data_list = []
high_data_list = []
path = path + "/*"
files = glob.glob(path)
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#がウシアンフィルタでぼかしを入れた後に縮小
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
#numpy → tensor + 正規化
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
これは、データセットを生成するプログラムになります。
def save_frame(path, #データが入っているファイルのパス
data_number, #1枚の画像から切り取る写真の数
cut_height, #保存サイズ(縦)(低解像度)
cut_width, #保存サイズ(横)(低解像度)
mag, #拡大倍率
ext='jpg'):
ここは関数の定義です。コメントアウトで書いている通りですが、
pathはフォルダのパスです。(例えば、fileという名前のフォルダに写真が入っているなら、"./file"と入力です。)
data_numberは1枚の写真を複数枚切り取ってデータのかさましをします。
cut_heightとcut_wedthは低解像度の画像サイズです。最終的な出力結果は倍率magをかけた値になります。
(cut_height = 300, cut_width = 300, mag = 300なら、
結果は900 * 900のサイズの画像となります。)
path = path + "/*"
files = glob.glob(path)
ここは、ファイルにある全ての写真をリストにして返しています。
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#ガウシアンフィルタでぼかしを入れた後に縮小
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
ここは先ほどリストにした写真を1枚ずつ取り出して、data_numberの数だけ切り取っています。
切り取る場所をランダムにしたいのでrandom.randintを使用しています。
そして、ガウシアンフィルタでぼかして低解像度画像を生成しています。
最後にリストにappendで追加しています。
#numpy → tensor + 正規化
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
ここは、keras, tensorflowではnumpy配列ではなくtensorに変換する必要があるため、変換を行っています。同時に正規化もここでしておきます。
最後に、低解像度の画像を格納したリストと高解像度の画像を格納したリストを返して関数は終了です。
main.pyの説明
import tensorflow as tf
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Conv2D, Input, Lambda
def ESPCN(upsampling_scale):
input_shape = Input((None, None, 1))
conv2d_0 = Conv2D(filters = 64,
kernel_size = (5, 5),
padding = "same",
activation = "relu",
)(input_shape)
conv2d_1 = Conv2D(filters = 32,
kernel_size = (3, 3),
padding = "same",
activation = "relu",
)(conv2d_0)
conv2d_2 = Conv2D(filters = upsampling_scale ** 2,
kernel_size = (3, 3),
padding = "same",
)(conv2d_1)
pixel_shuffle = Lambda(lambda z: tf.nn.depth_to_space(z, upsampling_scale))(conv2d_2)
model = Model(inputs = input_shape, outputs = [pixel_shuffle])
model.summary()
return model
さすがと言いますか、短いですね。
さて、ESPCNの論文をみていると、このような構造をしていると書いています。
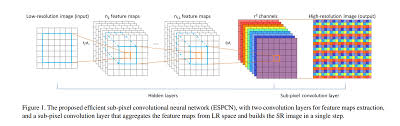
Convolution層の詳細はこちらを→kerasのドキュメント
pixel_shuffleはkerasには標準搭載されていないので、lambdaで代用しました。
lambbdaは任意の式をモデルに組み込めるので、拡大を表しています。
lambdaのドキュメント→https://keras.io/ja/layers/core/#lambda
tensorflowのドキュメント→https://www.tensorflow.org/api_docs/python/tf/nn/depth_to_space
ここのpixel shuffleに関しては色々なやり方があるみたいです。
model.pyの説明
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
if __name__ == "__main__":
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #写真が入ったフォルダ
test_file_path = "../photo_data/DIV2K_valid_HR" #写真が入ったフォルダ
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #切り取る画像のpath
cut_traindata_num, #データセットの生成数
train_height, #保存サイズ
train_width,
mag) #倍率
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
# https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #切り取る画像のpath
cut_testdata_num, #データセットの生成数
test_height, #保存サイズ
test_width,
mag) #倍率
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg")
change_res.save(path + "high_" + str(i) + ".jpg")
y_pred.save(path + "pred_" + str(i) + ".jpg")
else:
raise Exception("Unknow --mode")
メインは結構長いのですが、短くできるならもっとできるかなぁというのが感想です。
以下で、中身の説明をしていこうと思います。
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
ここでは、関数や同じディレクトリ にある別のファイルを読み込んでいます。
datacreate.pyとmodel.pyとmain.pyは同じディレクトリにおいてください。
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
今回は、生成画像の良し悪しの判断基準にpsnrを使用しましたので、そこの定義です。
psnrはピーク信号対雑音比という名前で、簡単に言うと比較したい画像の画素値の差分を計算するって感じです。ここでは詳細の説明を省きますが、この記事とかは割と詳しく、複数の評価法が記載されています。
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #写真が入ったフォルダ
test_file_path = "../photo_data/DIV2K_valid_HR" #写真が入ったフォルダ
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
ここは、今回使用する値を設定しています。config.pyとして別にしている方もgithubを見ていたら結構いますが、大規模プログラムではないため、まとめています。
学習データのサイズは、trainデータは論文が5151と書いてあったのでそのmagで割った値の1717を採用しました。testは見やすいように大きめにしているだけです。結果はこれの3倍の大きさになります。
データの数はファイルに含まれている画像の数の10倍です。(800枚であればデータ数は8,000)
今回、データに使用したのはよく超解像で使われているDIV2K Datasetです。データの質がいいので、少ないデータである程度の精度が出ると言われています。
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
ここは、モデルの学習と評価を分けたかったのでこのような形にして、--modeで選択できるようにしました。
詳細の説明はしないので、python公式のドキュメントを載せておきます。
https://docs.python.org/ja/3/library/argparse.html
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #切り取る画像のpath
cut_traindata_num, #データセットの生成数
train_height, #保存サイズ
train_width,
mag) #倍率
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
# https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
ここで、学習させています。srcnnと選択(後ほどやり方は記載)するとこのプログラムが動きます。
data_create.save_frameで、data_create.pyのsave_frameという関数を読み込んで、使えるようにしています。ここで、train_xとtrain_yにデータが入ったので、モデルを同様に読み込んで、compile, fitを行います。
compileなどの詳細の説明はkerasのドキュメントをご覧ください。割と論文と同じものを採用して行っています。
最後にモデルを保存してお終いです。
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #切り取る画像のpath
cut_testdata_num, #データセットの生成数
test_height, #保存サイズ
test_width,
mag) #倍率
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg")
change_res.save(path + "high_" + str(i) + ".jpg")
y_pred.save(path + "pred_" + str(i) + ".jpg")
else:
raise Exception("Unknow --mode")
いよいよラストの説明です。
まずは、psnrが使えるように先ほど保存したモデルを読み込みます。
次に、test用のデータセットを生成し、predictで画像を生成します。
psnr値をその場で知りたかったので、計算してます。
画像を保存したかったので、tensorからnumpy配列に変換して、保存してついに終わりです!
こんな感じでしっかり高解像度化できています。


5.終わりに
今回はESPCNを組んでみました。次はどの論文を実装してみようか悩みどころですね。
要望・質問などいつでもお待ちしております。読んでいただきありがとうございました。