2014年から2018年までのCVPR, ECCV, ICCV などのトップ画像処理学会に採択された、ディープラーニング(DL)を用いた超解像モデルのまとめです。
TensorFlow アドベントカレンダー 8日目の記事です。 本来はtensorflowのコードも合わせて紹介したかったのですが、論文の数が増えてしまったのでそれはまた別の記事で書きます。
単画像超解像は各学会でも毎年沢山の論文が採択される主要分野ですが、2014年に初めてDLを使ったモデルが発表されたのを皮切りにその性能や適用分野を大きく広げています。この記事では主要な17の論文をざっくりと系統立ててまとめ、それぞれの論文でどのような問題にどんなテクニックでアプローチしているかを確認していきます。
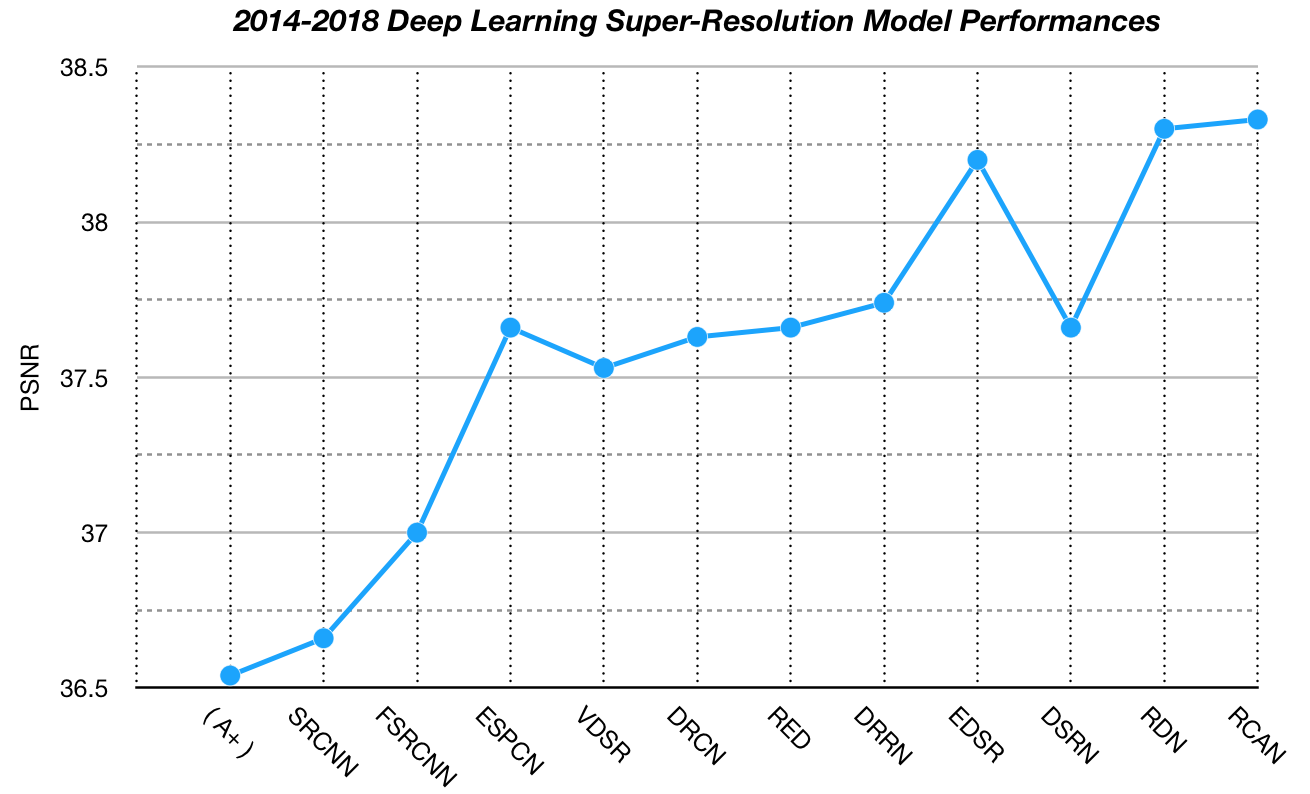
パフォーマンスの大まかな推移が下記のグラフです。論文リストは記事の最後に!
- 数式なしで主要アーキテクチャを説明してみる
- DL業界の動きの速さを実感して年末の怠惰な空気を払拭!
- 各論文で使われている小技__(重要)__を整理しておき、実装するときの参考に
そもそも単眼超解像とは
超解像とは解像度の低い画像の解像度をあげる技術です。その中にもいろいろな手法があり、時間方向や空間方向、あるいは異なったセンサから複数の画像を取得してそこから解像度を上げる技術などもあります。ここでテーマにしているのはその中の一つ、単眼超解像(Single Image Super Resolution)です。

ぼやけたセキュリティカメラの画像から人の顔やナンバープレートの文字を復元したり、古くて解像度の低いコンテンツを最近のデバイスに合うように解像度を上げたりと応用性が高いです。
事前に自然界に存在する画像の特徴を学習・汎化しておき、間のサンプルが抜けているデータがあった時にその値を補間するというのが単眼超解像の主要原理です。1枚のCNNから構築することもでき、素人にも挑戦しやすいので興味のある人は是非やってみて下さい。(my github)
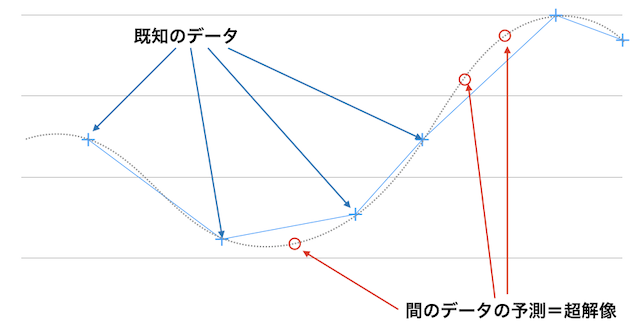
近年のCVPRなどのトップ画像処理学会では、DLを使ってモデルの大幅な精度向上や用途の多角化が行われています。本来は "単眼"超解像 が正しい呼び名ですが最近は単に超解像と呼んでしまうことが多いです。そのため本記事でも以降は超解像(SR)と呼びます。
それでは世代順に主要論文を追っていきましょう!
各論文のヘッダーは、[モデルの略称], "論文タイトル"(arxivへのリンク), submitされた日付あるいは掲載日, 発表された学会, (Google Scholarによる被引用数)としています。性能指標としてはSet5データセットでの2倍拡大時のPSNR値を指標とします。
2014-2015
[SRCNN]
"Image Super-Resolution Using Deep Convolutional Networks” 6/2014, ECCV 2014, (1309)
DLを初めて超解像に適用した論文です。それ以前はマルチレベルパーセプトロンをデノイズや復元に使った例はあったものの、3層以上のCNNの例は無かったようです。またend-to-endで学習したSRモデルとしても初めてのもののようで、被引用数も1309と非常に高いです。やはり何でも最初にやった人は偉いのです。

単にCNNを3枚かけているだけなのですが、実はそれぞれのCNNは異なった意味を持ちます。以降のDLモデルも基本はこの構成になっているのでじっくり見ておきましょう。
まず 1)最初の層では各画素の輝度値が入力として与えられるわけですが、これに9x9のCNNをかけることで周辺画素の特徴を抽出します。2)第二層では、得られた画像特徴量から 5x5のCNNを用いて画像復元のための特徴量に変換します。そして 3)最後の層で画像を復元します。それぞれ異なる意図を持った演算なのですが、全てCNN(+Bias)でできてしまうのが面白いですね。またCNN演算はピクセルワイズであるため、入力された彽解像度画像を最初に拡大して高解像度画像と同じ大きさにしています。
学習データセットにはYang91、アクティベータにReLU、オプティマイザにSGD、ロスは正解画像との二乗誤差(MSE)を使っています。論文では3層だけでなく4層、5層も試しているのですが思ったように性能が上がらず、"Deeper structure does not always lead to better results" と言ってしまっています。しかし、実際はこれからしばらく後に一気に戦国時代に突入します。 :)
2016
 SRCNNでは3層で限界だったモデルですが、各種アーキテクチャの導入によってdeepなモデルでも学習できるようになり、一気に16層や30層といったモデルが出てきます。
SRCNNでは3層で限界だったモデルですが、各種アーキテクチャの導入によってdeepなモデルでも学習できるようになり、一気に16層や30層といったモデルが出てきます。
[FSRCNN]
"Accelerating the Super-Resolution Convolutional Neural Network”, 8/2016, ECCV 2016, (318)
SRCNNのメイン構造はある程度そのままにして、各種のテクニックやデータの追加で高速・高性能化を実現した論文です。
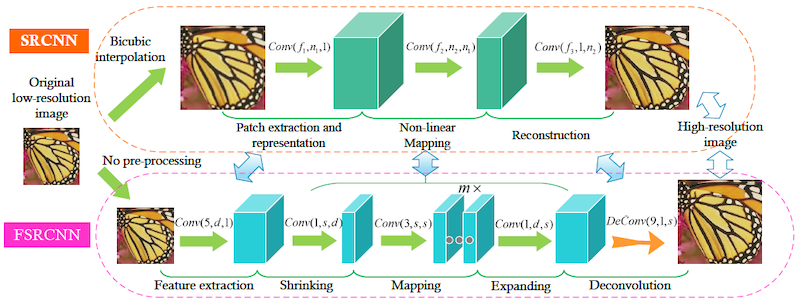
SRCNNには無かったアップサンプリング層を追加し、最初に行なっていた既存アルゴリズムでの拡大を排除しました。モデルの最後でデコンボリューションを用いて高解像度化するようにしています。そのため各層のCNNのサイズを小さくすることができ、また最初にアップサンプリングされた余分なピクセルの特徴抽出・変換を避けることで効率良い演算ができるようにしています。
CNNのサイズを小さくし、General100をデータセットに追加。 さらにscalingやrotationを用いてデータを拡張しています。復元用の特徴の計算にCNNを2層追加。さらにアップサンプリング層のみ他より低いラーニングレートを使い、アクティべータにはPReLUを使うなどより細かい調整をしています。同じような構造のモデルであっても、データを増やし細かな調整を行うことで一気に性能が上がる良い例ではないでしょうか。
[ESPCN]
"Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network”, 9/2016, CVPR2016, (476)
FSRCNNと似たモデル/コンセプトの論文ですが、デコンボリューション演算にはデメリットがありました。これに対して、後に広く使われるようになる__Pixel Shuffler__というアップサンプリングメソッドを提案しています。

デコンボリューションは、元々は"CNNの演算を逆方向に行うことでアップサンプリングができるのでは?"というアイデアで実装されたものだと記憶しているのですが、実はデメリットも多い演算方法でした。まず一つはフィルタのサイズとストライドサイズが異なる場合に演算対象がオーバーラップしてしまい、格子状のアーティファクトが出てしまう点。二つ目としては、アップサンプリング時に足りないセルをゼロパディングしているため余分な演算が発生しており、演算速度が遅いという点です。
本論文(ESPCN)のPixel Shufflerでは各ピクセルの持つチャンネルを空間方向にマップしています。例えば4chのデータを持つピクセルがあった場合に、その各ピクセルを1chの2x2のピクセルにマップする手法です。(この場合は実質的にアップサンプリング処理は事前のCNNレイヤーで行われていることになりますね。)これにより無駄な演算をなくし格子状アーティファクトの低減と演算の高速化を実現しました。以降の論文でも積極的に利用されています。
[VDSR]
“Accurate Image Super-Resolution Using Very Deep Convolutional Networks”, 11/2015, CVPR2016, (871)
超解像モデルを多層化するために、皆さんご存知のResNetの手法を取り入れた論文です。モデルは入力値との差分値のみを学習すればよくなり、学習係数を従来論文(SRCNN)の__1万倍!__に設定することができ、20層という当時ではかなりdeepなネットワークでも非常に早い時点での収束を実現しています。

まず既存の手法を使って、入力画像を高解像度の出力画像と同じサイズに拡大します。その後に多層のCNNをかけて最後にモデルの入力画像と足し合わせるだけという単純なモデルです。ですが、特に超解像においてはskip connectionは大変重要です。というのも超解像では画像認識のように最終的にサマライズされた結果を出せば良いのではなく、入力データ自体の情報も保持しておかないとうまく復元できません。そのためどうにかして入力値を復元時まで持っていく工夫が必要になります。
トレーニングデータにはYang91に追加してBerkeley Segmentation DatasetからBSD200を利用。レイヤーの増加と共に総トレーニングパラメータ数も爆発的に増加しています。そのために過学習してしまうのを防ぐためか、各CNNウェイトへのL2正則化項をロスに追加。初期化にはHeの初期化(MSRA)、オプティマイザはMomentumを使用しています。
[DRCN]
“Deeply-Recursive Convolutional Network for Image Super-Resolution” 11/2015, CVPR2016, (354)
モデルを多層化するとパラメータ数が爆発し学習しにくくなるという問題に対して、同じCNNを何度もリカーシブにかけることでウェイトを正則化するという論文です。また各層の途中計算結果を取り出して混ぜ合わせることで簡易なアンサンブル効果を実現しており、圧倒的に少ないパラメータ数で当時最高性能を達成するという面白い論文です。

実はこの論文の著者は一つ前に紹介したVDSRの著者と同じです。同時期にもう一つ出して両方ともCVPRに通すなんてその気合いと技術力がすげぇ!
上図でH1からHdなどのCNNは全て同じウェイトを使っていて、基本的にはRNNと同じ構造になっています。また同じウェイトを共有してトレーニングすることで正則化の効果もあるようです。そのため通常はCNNには64枚のフィルタ(特徴量)を使うことが多いのですが、DRCNでは256枚のフィルタを使うことを可能にしています。また各レイヤーの出力を取り出し、トレーニング初期は近いレイヤーがより強く学習するようにし、順に後ろのレイヤーまで学習が進むようにコントロールするなどの工夫も見られます。
[RED]
“Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections” 4/2016, CVPR2016, (210)
通常CNNを何層もかけていくとより広域の情報をサマライズして特徴抽出をすることができますが、その分ローカルな近傍の情報や入力値の情報が失われていきます。それに対応して15層のEncoder(CNN)と同数のDecoder(デコンボリューション)層を対にしてskip connectionで繋げて情報をキープするようにしたのがこの論文です。
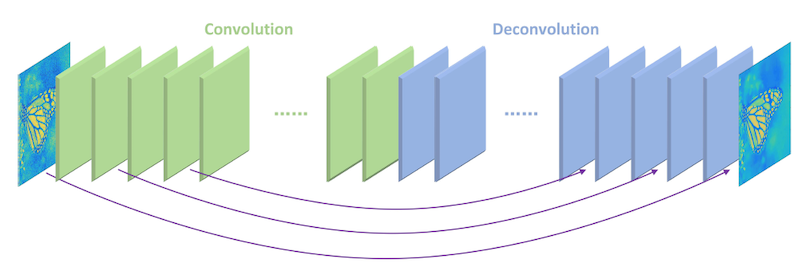
対応するEncoderとDecoderを2枚おきにSkip Connectionで接続することで、各レイヤの元情報を保持する機能を持ちます。通常CNNをかけていくとより凝縮された重要な情報が残るようになりますが、その残った情報と入力データの両方を用いて復元を行うイメージでしょうか。個人的には、間のプーリング処理はないものの概念としてはU-Netに近いと捉えています。これによってEncoderは画像の特徴抽出を、Decoderは画像復元機能を学習することができ、また同様のモデルでデノイズなどにも応用できるそうです。
[RAISR]
"RAISR: Rapid and Accurate Image Super Resolution” 6/2016, (78)
実はDLの手法は使っていないのですが、Google発ということで非常に話題になった論文です。DLの弱点であるCNN計算のコスト(速度が遅い)に対し、画像処理の手法と学習的アプローチを組み合わせて従来より10倍以上高速なモデルを提案しています。

実は本モデルはDLとは言えないですし復元性能も高くはないのですが、現実的ではあります。基本的には学習ベースとは言え、その前段で輝度勾配を用いて特徴量を計算していて、例えば画像内の小さなパッチの中でどの方向に輝度が変化しているかや輝度変化の激しさなどから3つの特徴量を抽出しています。この特徴量抽出にはハッシュを用いて高速に行い、そこから学習されたフィルタを適用します。画像を復元する時の対象ピクセルの位置(既知ピクセルとの位置関係)で4つのグループに分けたり、他にもアーティファクトを防ぐための工夫などがあって既存手法もまだまだ捨てたもんじゃないなと感じます。プロダクトとしての実際の落とし所はこの辺りなのかもしれませんね。
2017

2017年ではPixel Shuffler, ResNet, GANなどの各種技術がそれぞれで発展しながらも、これらの技術を複数使いこなしてさらに一段上の性能が実現されていきます。
[DRRN]
”Image Super-Resolution via Deep Recursive Residual Network”, 7/2017, CVPR2017 (146)
DRCNではRNNの手法を用いてパラメータの総数を大きく削減していましたが、その代わりにモデルの複雑性(ポテンシャル)が犠牲になってしまっていました。本論文ではアンサンブル的に中間層をマージしていた構造をシンプルにし、代わりに多段のResidualブロックを追加して複雑性を上げています。

一番右が本論文(DRRN)です。DRCNでは途中の出力結果をアンサンブル的にマージしていましたが、DRRNではそれを排除してシンプルな直列構造としています。オレンジの点線で表されているのがResidual Block(RB)で、その中に複数のResidual Unit(緑色の点線)があり、各Residual Unitは一度出力するごとに入力データを足してその結果を次のResidual Unitの入力としています。各Residual Unitは二つのCNNで構成されていますが、この前段のCNNは他の全てのResidual UnitのCNNと、後段のCNNは他のユニットのCNNとウェイトの値を共有しています。上の図ではResidual Block数(B)=6, Residual Unit数(U)=2の図となっていますが、本論文で最終的に提案するモデルではB=1, U=25という、非常に長く多段のResidualがつながっているモデルになっています。(トータルで52層)
DRRNでは入力に近い層から順に学習するように工夫していたのですが、本論文ではCNNが2段になりユニットの複雑性が増えたにも関わらず、residualのおかげでそのまま学習ができるようになっているようです。
 また、面白いのはResidual Unit内のCNNについて、まず__Batch Normalization__(BN)をかけてからReLUを適用し、その後でCNNをかけている点です。通常と逆の順序になっているこの並びは__Pre-Activtion__と呼ばれます。詳細は[別の論文](https://arxiv.org/abs/1603.05027)にありますが、BNと共にResidual Unitを構築する場合はこの構造にすることで1000層という超deepなモデルでも学習が安定させられるとのことでした。
また、面白いのはResidual Unit内のCNNについて、まず__Batch Normalization__(BN)をかけてからReLUを適用し、その後でCNNをかけている点です。通常と逆の順序になっているこの並びは__Pre-Activtion__と呼ばれます。詳細は[別の論文](https://arxiv.org/abs/1603.05027)にありますが、BNと共にResidual Unitを構築する場合はこの構造にすることで1000層という超deepなモデルでも学習が安定させられるとのことでした。
トレーニングデータはYang91とBSD200、どうやらこの組み合わせは効率が良いようで他の論文でもこの組み合わせを利用しているのが目立ちます。さらに勾配の値をクリッピングする__Gradient Clipping__や、データの拡張を行って8倍に水増しするなど色々な手法を使用してdeep(52層)な直列モデルでも学習中に勾配が消えないように工夫されています。
[SRResNet][SRGAN]
"Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, 9/2016, CVPR2017 (1112)
今までの超解像では人の知覚による評価が考慮されておらず、復元性能の評価はGTとのMSEベースで行われていました。ここでついにtwitterの研究者よりGANを使ったアプローチが登場し、人から見てより自然な内容の復元を試みます。さらに本論文で使われている超解像用のモデル(SRResNet)もシンプルながら完成度が高く、個人的にも非常に評価の高い論文です。
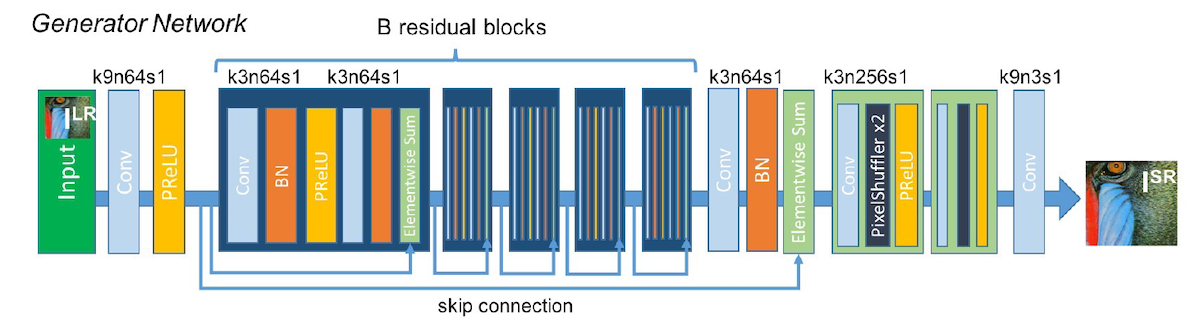 まず超解像用の __SRResNet__ を見ておきましょう。一番大きな部分としては、一番外側のResidual以外にも2つのCNNごとに入力データを足しているローカルなResidualがある点です。このおかげでモデルは復元する値の2階微分を推定することに特化しています。さらにアップサンプリングにはESPCNで提案されたPixel Shufflerを利用して効率良いアップサンプリングを行います。アクティベータにはPReLUを使い、トレーニングデータはより沢山のイメージを持つ[ImageNet](http://www.image-net.org)、オプティマイザにAdamを使用しています。
まず超解像用の __SRResNet__ を見ておきましょう。一番大きな部分としては、一番外側のResidual以外にも2つのCNNごとに入力データを足しているローカルなResidualがある点です。このおかげでモデルは復元する値の2階微分を推定することに特化しています。さらにアップサンプリングにはESPCNで提案されたPixel Shufflerを利用して効率良いアップサンプリングを行います。アクティベータにはPReLUを使い、トレーニングデータはより沢山のイメージを持つ[ImageNet](http://www.image-net.org)、オプティマイザにAdamを使用しています。
さて、上記のSRResNetでは通常の超解像モデルのようにMSEをロスとしてトレーニングされています。ですが、このMSEベースだとテクスチャのようなランダム性の高かったり周波数成分の高い画像を復元することができません。
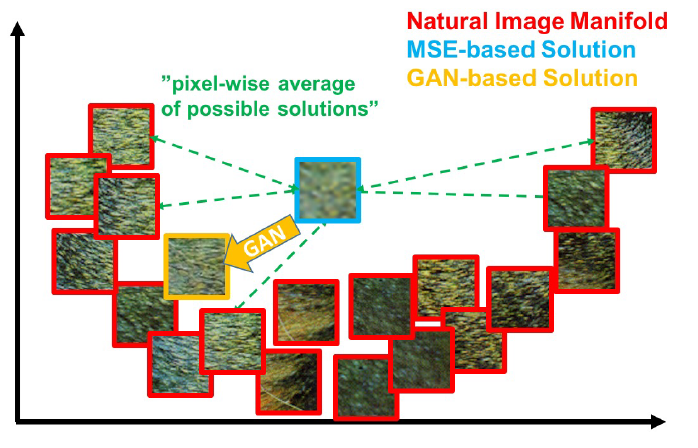
上記の図で、自然界に存在する実際の画像パッチが赤枠のものだとします。この場合はモデルがこの赤枠内のどれかの画像を推定できれば正解となるわけですが、MSEベースでは推定結果(学習バイアス)がこの全ての赤枠画像の平均画像(水色枠)に寄ってしまい、ぼやけたものになってしまいます。そのため本論文ではPerceptual LossとGANを使ったアプローチを提案しています。
 __SRGAN__ではSRResNetをGenerator, 上の図をDiscriminatorネットワークとして使います。
Perceptual Lossは画像認識用のVGGネットワークに画像を入れた時にその中間層で出力される特徴量ベクトルの距離を用いてロスとする手法です。ピクセルレベルの比較ではなく、その画像を人が見た時に感じる特徴の近さをロスとしているわけです。このPerceptual Lossと、Discriminatorにより人工画像と見破られたかどうかの二つのロスをあるウェイトで足し合わせてトレーニングされたものがSRGANです。結果としてMSEベースのSRResNetも最高性能をマークし、またSRGANを用いた画像について26人のテスターによって行われたMean opinion score (MOS)テストにおいてもよりクオリティが高いと評価されています。
__SRGAN__ではSRResNetをGenerator, 上の図をDiscriminatorネットワークとして使います。
Perceptual Lossは画像認識用のVGGネットワークに画像を入れた時にその中間層で出力される特徴量ベクトルの距離を用いてロスとする手法です。ピクセルレベルの比較ではなく、その画像を人が見た時に感じる特徴の近さをロスとしているわけです。このPerceptual Lossと、Discriminatorにより人工画像と見破られたかどうかの二つのロスをあるウェイトで足し合わせてトレーニングされたものがSRGANです。結果としてMSEベースのSRResNetも最高性能をマークし、またSRGANを用いた画像について26人のテスターによって行われたMean opinion score (MOS)テストにおいてもよりクオリティが高いと評価されています。
[EDSR]
"Enhanced Deep Residual Networks for Single Image Super-Resolution”, 7/2017, NTIRE2017 (206)
SRResNetを改良し、2017年の超解像コンテスト(NTIRE 2017)で優勝したモデルです。SRResNetをベースに細かい改良が加えられています。
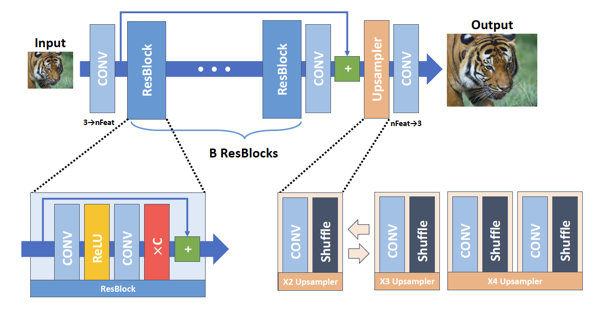
基本的な構成はSRResNetと同じですが、Batch Normalization層を削除しています。恐らくResidual Blockが細かく入っているためBNはなくても収束するということだと思います。さらに最後のResidualブロックの最後では出力を0.1倍に減衰させると安定するというあまり他で見たことのない調整をしています。またロスにはL1を使っています。この方がGTに近い領域では勾配が出やすい感じがしますね。
また__self-ensemble__という手法も利用しています。これは入力画像が与えられた時に左右反転や回転などの処理を加えた計7パターンの画像を用意し、それぞれの入力画像に対する出力画像を全て合わせて平均化し最終的な結果を得るというもので、多少の汎化効果があるようです。トレーニングにはNTIRE用に作成された高解像度のDIV2Kを使っています。
2018

いよいよ今年も終わりですね。2018年初めでは、Residual in ResidualやGANも実装されてほぼ超解像の技術的には落ち着いたかなと思っていましたがまだまだいろいろと出てきました。性能も着実に上がっていきます。
[DSRN]
“Image Super-Resolution via Dual-State Recurrent Networks”, 3/2018, CVPR2018, (8)
RNNを使ったモデルの新バージョンです。実は昨年に発表されたSoAのDRRNよりも若干性能としては良くないのですが、リカレントのループを複数持つというアイデアが面白くまだ発展する余地がありそうなので載せておきます。

上図 左側が実際のモデルで、右側がそれを計算方向に展開したグラフになります。各フレームでデコンボリューションによるアップサンプリングを行って高解像画像の作成(fup)を行いつつ、その作成された高解像画像をCNNでダウンサンプリング(fdown)して入力画像にフィードバックするという構造です(githubに公開されているソースコードを読むとCNNではなく単にアベレージプーリングを使ってダウンサンプルしているように見えますが...)。
低解像度のデータと高解像度のデータに対してそれぞれRNNを適用しつつ、それぞれのループはお互いのループの結果を足しこんでいきます。
モデル自体は非常にシンプルでパラメータ数も圧倒的に少ないので、組み込み向けなど限られた用途ではなかなか有効です。またRNNのこのような構造はビデオの処理にも向いており、この方向の発展もまだまだ期待できそうです。トレーニングデータにはYnag91やDIV2Kを使用、Gradient clipping、またほとんどはReLUですが一部のアクティベーション層にPReLUを使っています。
[FRVSR]
“Frame-Recurrent Video Super-Resolution”, 1/2018, CVPR2018, (8)
超解像のビデオへの応用版です。ビデオの場合は過去のフレームのデータを情報として使える代わりに動画内の対象に動きがあったりなどいろいろと難しいのですが、本論文にも複数の工夫があります。モデルとしては若干複雑になりがちなビデオへの応用ですが、複数のモデルが協調しながらもend-to-endでトレーニングでき、実際の応用として動作速度も速く、また素晴らしい性能を発揮しています。

上図青色のボックスが低解像度の元画像です。ビデオの場合は過去のフレームが複数あるのでそれらの情報を考慮して超解像を行うことができますが、その場合時間方向のスライディングウィンドウを作成して常に直近の複数のフレームを保持しなければなりません。また毎回の処理ごとにそれらの複数のフレームを全て処理して超解像処理を行うため低速になってしまいます。
本論文では複数のフレームを保持せず、代わりに一つ前のフレームで行った超解像処理中の特徴量だけを参考情報とすることで非常に高速な動作を実現しています(上図緑色のボックス)。また通常オプティカルフローなどを使って現パッチ画像が前フレームではどこにあったかを推定する必要があるのですが、ここにもDLのモデルを使っています。
実際の動作を見てみましょう。まず 1)現フレームの画像と前フレームの画像の二つを入力とし、出力として各ピクセルがどの方向に動いたかを推定するフローマップを作成します。このフローマップ作成をDLのモデル(FNet)を使っています。ネットワーク構造は前段でプーリングした後に後段でアップサンプルしていくエンコーダー/デコーダーモデルのような構造です。(下図)

2)作成されたフローマップをバイリニアで拡大し、高解像度用のマップにします。 3)フローマップを使って前フレームの特徴量マップを現フレーム用の位置に変換します。 4)得られた前フレームの高解像度版の超解像用特徴量(ややこしい)をPixel Shufflerの手法を使ってダウンサンプリング(space to depth)し、低解像度版にマップします。これによりマップの解像度を情報のロスなく低解像度のものに変換します。そして最後に5)現フレームの低解像度画像とビデオ内の位置の移動を考慮された前フレームの超解像用特徴量が手に入り、これらをコンカチネイトしてSRResNetに似た超解像モデル(SRNet)を使って復元します。
モデルがFNetとSRNetの複数出来てしまいますが、"SRNetの出力と高解像度GT画像のMSE" と ”FNetの出力結果を使って前フレームの画像から現フレームの推定を行い、その推定結果と実際の現フレームとのMSE" の2つのロスを使ってend-to-endで一度に最適化しています。
[FSRNet][FSRGAN]
“FSRNet: End-to-End Learning Face Super-Resolution With Facial Priors”, 11/2017, CVPR2018, (11)
顔画像専用の超解像モデルで、顔のパーツ推定モデルを含む4つのモデルを組み合わせてend-to-endでトレーニングができるモデルです。
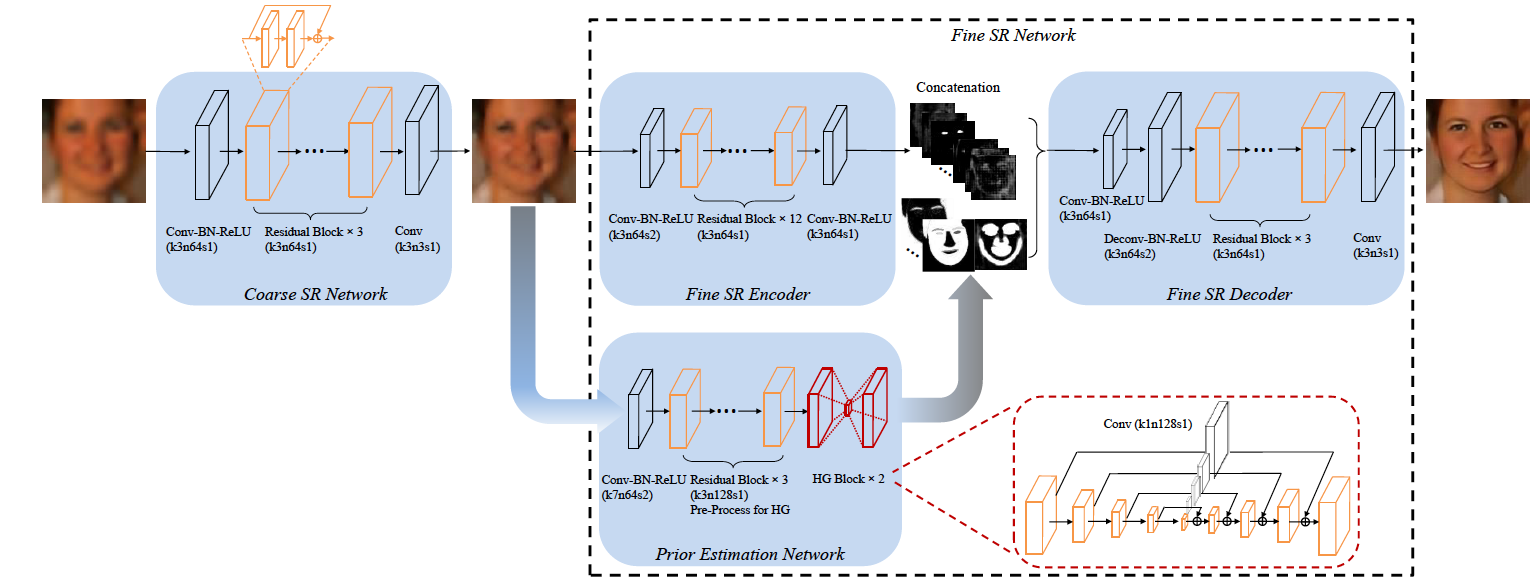
FSRNetは4つのモデルに分けられます。1)ラフな前処理としての超解像モデル(Coarse SR Net)、 2)得られた中間の高解像画像から特徴抽出を行うエンコーダー(Fine SR Encoder)、 3)中間の高解像画像から顔のパーツの推定やランドマークとしての重要度を推定する推定器(Prior Estimation Net)、 4)得られた特徴量とパーツ情報/ランドマーク情報から顔画像を復元する復元器(Fine SR Decoder)です。
それぞれのネットワーク構成は上図を見れば分かるようにシンプルな設計になっていて、顔パーツ推定モデルのみ最終段にskip connectionで各サイドをつなげた砂時計型のエンコーダー/デコーダーモデルを使っています。画像が低解像度になってしまうとテクスチャ的な細部の情報は失ってしまいますが、顔全体の情報やパーツの形は残っていて推定しやすいため、それらを先に推定して顔画像の復元時に追加することで精度の高い復元を実現しています。
ロスの計算には
1)[Coarse SR Net]の出力に対するGT画像とのMSE
2)[Fine SR Decoder]の最終出力に対するGT画像とのMSE
3)[Prior Estimation Net]に対して別の既存モデルを使って作成したGTとのMSE
の3つを全て足して最終的なロスとしています。
この論文でポイントになる部分は、end-to-endで複数のモデルを一気に学習させてしまうことで各モデルを同時に最適化するところだと思っています(個人的にはend-to-endにこだわる必要はないとは思っているのですが)。Discriminatorまで含めると全体ではだいぶdeepな構成になりますが、中途でロスの評価を行いつつGANの仕組みを用いてうまく学習させることができています。
[RDN]
“Residual Dense Network for Image Super-Resolution”, 2/2018, CVPR2018, (37)
シンプルな構造のSRモデルとしてはほぼ現状の最適解ではないかと思えるような、シンプルでかつパフォーマンスの高いモデルです。DenseNetと、上で紹介したEDSRを組み合わせた構造です。

一つのResidualブロックの前半の3つのCNN(特徴抽出)の層では各層の入力と出力をそれぞれDenseに連結(コンカチ)しています。こうすると特徴量の次元が増えてしまうのですが、Residualを足しこむ直前で1x1 CNNを使って入力データの次元と同じ次元数に削減しています。このResidualブロック(図中赤ブロック)を直列に接続して、同様に各ブロックの出力を全て最終層でコンカチしてから次元を削減して入力データを足し込み、復元用の特徴量を作成します。この構造により、ローカルな狭域の特徴量と後段の広域特徴量の両方を使って復元することができます。最後に3層のCNNを使ってアップサンプリングしてからPixel Shufflerを用いて高解像度画像へ変換しています。
今まで発展してきた各アーキテクチャを綺麗にまとめている印象です。トレーニングにはDIV2Kデータセットを利用、また論文には記述はないですが公開されたコードを見るとアップサンプリング用のCNNのみ若干大きめの初期値を使ってアップサンプル後の出力値の範囲を適切なものにしています。EDSRに倣ってSelf-ensembleを行い、ロスもL1を使用しています。
[PConv]
"Image Inpainting for Irregular Holes UsingPartial Convolutions”, 4/2018, ECCV2018, (25)
さて、今までの超解像では常に2倍や3倍など、等間隔に既知のサンプルが並んでいる状況が対象でした。こちらのnVidiaからの論文ではデータがごっそりなくなっていても復元できる技術としてをPartial Convolutionを提案しています。

Partial Convolutionでは、通常の色画像とは別にマスク画像も用意し、補間したいピクセルのマスクをOnにしておきます。CNNを適用する場合にはそのCNN内の対象ピクセルのマスクが全てOnの場合は無視します。マスクがOffである有効な画素が一つでもある場合は、有効画素のみから補間値を計算します(さらにCNN計算に利用できる画素の数で結果を割ります)。画素を補間することができればそのマスクはOffにして次のピクセルへ進みこれを繰り替えします。これは、欠損領域があった場合にマスク領域周辺の通常データが幾らか存在する部分から順に補間を行っていくことになります。
論文では8x2層のU-Netを用いて補間値を出力するネットワークを利用しています。またロスにはperceptual lossを含む計6項のロスを用いており興味深いです。
[SRAE]
“Super-Resolving Very Low-Resolution Face Images with Supplementary Attributes”, 6/2018, CVPR2018 (5)
この論文は顔画像用のGANの復元ネットワークです。8倍などの高倍率な復元になるとどうしても元データからの情報が少なくなり、性別の転換など根本的な間違いが生じてしまいます。SRAEではこれに対して、復元する顔画像の属性(年齢や性別、あごひげやメイクの有無など)を追加で入力することで高倍率でも高精度な復元を可能にしています。さらに面白いのが、属性を変更することで画像の特徴を自由に変更できる点です。

パッと見ると良くあるGANのネットワークになっていますが、Generatorの前半部分にskip connectionで対応するレイヤをつなげたEncoder/Decoderネットが入っています。属性情報は入力画像に追加されるのではなく、このエンコーダー部の一番最終の層にコンカチされて追加されるところがポイントです(図中緑色のボックス)。さらにDiscriminatorではモデルの中間部分にこの属性情報が追加されています。これがあるため、Generatorが追加された属性情報を無視して復元をした場合にDiscriminatorはNGを出すことができる構造になっています。
トレーニング後の画像復元時にこの属性情報を変更することで、画像を指定した属性のものに変更して復元できるところがまた興味深いです。

またロスについては、指定した属性に対して正しく復元できているかを判断するためにGeneratorではL2 Loss に加えてPerceptual Lossを、Discriminatorでは交差エントロピーをベースとしています。
[RCAN]
"Image Super-Resolution Using Very Deep Residual Channel Attention Networks” 7/2018, ECCV 2018, (10)
ついに最後の論文です!最近注目度を増してきたアテンションネットワークを利用しています。
モデルがdeepになるにつれパラメータ数や中途の特徴量が増えていきます。ただしこの特徴量の中では低周波成分の特徴を表すものも多く、復元時は高周波成分の特徴を表している特徴量の方がより重要になってきます。この論文ではチャンネルアテンションネットワークを用いて、各レイヤーごとにより着目すべき特徴量(チャンネル)を特定しアテンション情報として追加することを試みています。
 全体の構造としては上図です。まず直列に10個のレジュールグループ(RG)があり、その外側にグローバルなResidual(Long Skip Connection)が繋がっています。その出力結果にPixel Shufflerベースのアップサンプリングをかけるという、SRResNetに似た構造です。
全体の構造としては上図です。まず直列に10個のレジュールグループ(RG)があり、その外側にグローバルなResidual(Long Skip Connection)が繋がっています。その出力結果にPixel Shufflerベースのアップサンプリングをかけるという、SRResNetに似た構造です。
一つのレジュールグループは直列な20のチャンネルアテンションブロック(RCAB)で構成され、やはり最初から最後の層までResidualが挿入されています。さて、いよいよアテンションブロックの中を見ていきます。
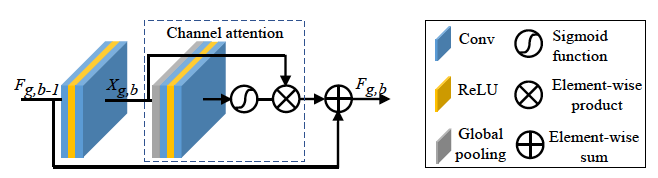
パッと見ると2つのCNNが2ブロックあるだけに見えますが、よく見ると後段のCNNの前にグローバルプーリングという見慣れない層が入っています。この後段のブロックがチャンネルのアテンション情報の計算ブロックです。各チャンネル毎に重要度としてのウェイトが出力され、前段の計算結果に掛け算することで重要チャンネルの出力をブーストします。

いよいよここが本質部分のチャンネルアテンションの計算部分です。まず、各チャンネル毎に画像内の各画素の該当チャンネルを全て合算し平均値を計算します(グローバルプーリング)。これによりチャンネル数(C)のベクタが作成できます。このベクタに対してまずr次元にマッピングして次元を削減し、ReLUをかけた上でもう一度C次元にマッピングします。恐らく一度次元を下げて重要な情報だけを残しているイメージでしょうか。論文ではC=64,r=16として使っています。一度4分の1に情報を削減しているわけですね。そしてこの出力結果にシグモイドをかけてチャンネルアテンション情報を算出しています。
トレーニングにはDIV2Kデータセットを使い、ロスにはL1を利用しています。チャンネルアテンションの効果によりRDNよりもdeepなモデルを学習させることができ、RDNを超えた最高性能を達成しています。
2019
以上駆け足で見てきました。
2019年はどのような技術が出てくるのか楽しみですね。
ここでとりあげた論文は本当に一部で、実際にはこの3-5倍以上の論文が主要学会に掲載されています。興味のある方は探してみて下さい。良いお年を!
- 超解像 主要論文リスト(github)
- トレーニング用データセット Yang91, General100, BSD200, ImageNet, DIV2K
Paper List
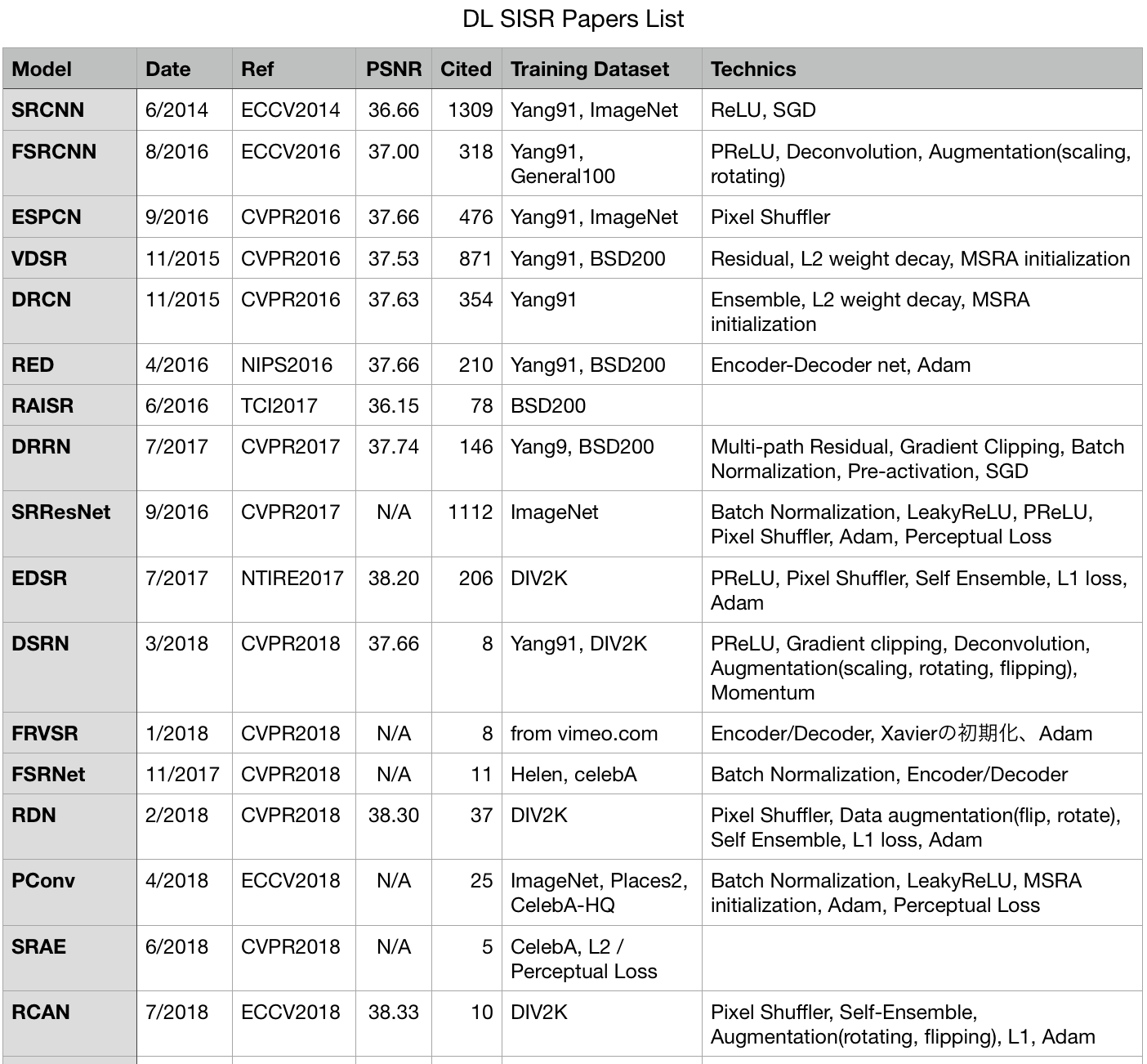
- 本記事の各論文の紹介文にある画像は、ほとんど全てがその紹介論文からの引用画像です
- 日付は 1) arxivなどへのサブミットの日付 2)発表学会の日付 で1)を優先にして載せていますが、学会発表後にarxivにサブミットした場合など、それぞれの日付が前後することがあります。あくまで参考程度にして下さい。