はじめに
今回の記事はこちらの記事をqiita用に書き直したものです。
超解像度化
超解像度化とは一言で言うと、「画像の解像度を上げる」ことです。そう聞くとただ画像を引き延ばすだけと思う人もいるかもしれませんが、画像を縮小する際には元の画像の情報がどうしても抜け落ちてしまいます。簡単な検証をしてみます。まずは適当な画像を二分の一のサイズに縮小します。その後bilinear法を使って、画像のサイズがもとの画像と同じになるように拡大します。その結果が下の画像です。

左が下の画像、右が一度縮小した後拡大した画像
一目では分かりづらいですが解像度は同じでも、ぼやけてしまい細かい特徴が消えてしまっています。解像度をただ上げるだけではなく細かい特徴を補いながら解像度の高い画像へと変換するのが、超解像度化のタスクです。
ESPCNについて
ESPCN(efficient sub-pixel convolutional neural network)は2016年に発表されたディープニューラルネットワークベースの超解像度化モデルです。
これに類似のモデルとして、2015年に発表されたSRCNN(Super-Resolution Convolutional Neural Network)があります。これは、超解像度のタスクにニューラルネットワークを用いたもので、三つの畳み込み層によって高解像度の画像へと変換するモデルです。
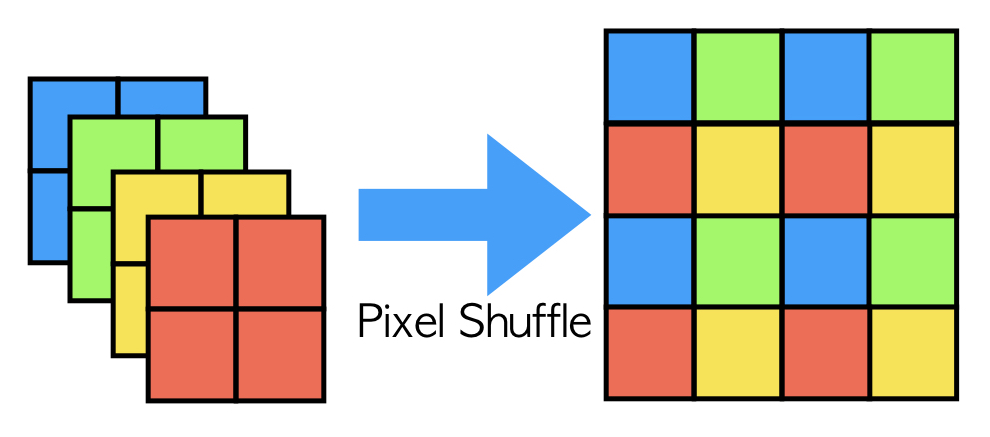
ESPCNの特殊な点として、通常は解像度を上げる際には逆畳み込みという操作を加えるのですがこの操作によって、格子状のノイズが発生することがあります。これを克服するためにESPCNではPixel Shuffleという操作によって解像度を上げています。例えば画像を二倍のサイズにしたい時には、出力の直前で四枚の画像を作りその四枚を決まった位置関係で組み合わせて出力にします。
実装と結果
こちらのコードとスクレイピングして得た画像を用いて学習を行いました。ちなみに学習に用いた画像は10000枚ほどです。

左が下画像、中央が一度縮小したのち拡大した画像、右がESPCNを用いた画像。
若干元画像と比べると細かい部分で違和感がありますが、ほとんど復元できていますね。これを使えば動画でも解像度を高くすることもできそうです。
終わりに
今回はESPCNを用いて超解像度化を試してみました。こういうモデルを使って、APIなどを作ってみるのも面白そうです。他にもGANなどを用いて生成した画像をこのモデルを使うことで解像度を上げるなどといった使い方もできそうです。
以下が今回の記事の作成の際に参考にしたサイトと論文です。
画像の超解像度化: ESPCN の pytorch 実装 / 学習
Image Super-Resolution Using Deep Convolutional Networks(2015)
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(2016)