こんな人に
2014年に発表されたGAN(Generative Adversarial Network)ですが、画期的な研究故に最近では派生研究が多くてなにがなんやら。。私自身Google先生をフル活用して色々調べてみたものの、主要な関連研究をわかりやすくまとめた日本語文献はなかなか見つけることができませんでした、残念!ということで、本記事はGAN関連の研究の流れのアウトラインを掴みたい人や、それぞれの研究を一々調べるのがめんどくさいから論文とコードにサクッとワンクリックでとびたい人向けとなっております。ちなみに本記事は、主にGenerative Adversarial Networks - The Story So Farを参考に書かせて頂いています。
そもそもGANってなんぞや?という方へ
- @triwave33さんの今さら聞けないGAN(1)
- SONYのNeural Network Console公式YouTubeチャンネル(全体の概要)
- @typecprintさんの今さら聞けないGANの目的関数(学習過程と目的関数の説明)
などを参考にしてみてください。
GANファミリーご紹介
- GAN (Generative Adversarial Network)
- CGAN (Conditional Generative Adversarial Network)
- DCGAN (Deep Convolutional Generative Adversarial Network)
- CoGAN (Coupled Generative Adversarial Networks)
- Pix2pix
- WGAN (Wasserstein Generative Adversarial Network)
- CycleGAN
- StackGAN (Stack Generative Adversarial Network)
- ProGAN (Progressive Growing of Generative Adversarial Network)
- SAGAN (Self-Attention Generative Adversarial Network)
- BigGAN (Big Generative Adversarial Network)
- StyleGAN (Style-based Generative Adversarial Network)
大家族ですね。(本当はもっともっと大家族です。)ここからそれぞれの研究の
- 研究論文
- コード
- ポイント
- オススメ参考文献(世界には親切で頭の良い人が沢山います)
を紹介していきます。
1. GAN (Generative Adversarial Network)
- Generative Adversarial Networks
- コード
- ポイント:
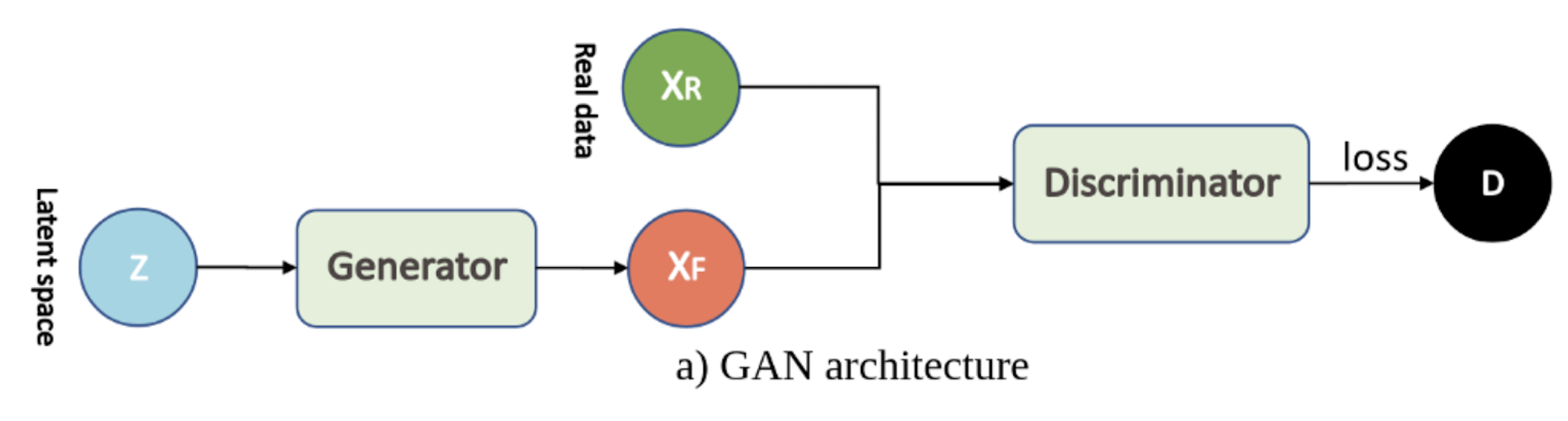
- 2つのニューラルネットワーク(GeneratorとDiscriminator)を用いている
- Generatorは「本物らしい」画像を作成する(最初の画像はランダムノイズから作成)
- Discriminatorは、Generatorによって生成された偽物の画像と、インプットされる本物の画像を識別する
- GeneratorとDiscriminatorは以下の目的関数を共有しており、Generatorはこの値を最小化、Discriminatorはこの値を最大化、することを目標に学習を進める
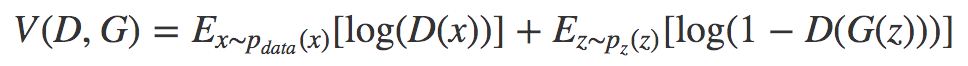
2. CGAN (Conditional Generative Adversarial Network)
- Conditional Generative Adversarial Nets
- コード
- ポイント:クラス条件ベクトル(下図のy)をGeneratorとDiscriminatorに加えることで、クラスごとに生成する画像を書き分けることができるようになった!
- オススメ参考文献:今さら聞けないGAN(6)

3. DCGAN (Deep Convolutional Generative Adversarial Network)
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- コード
- ポイント:以下の手法を用いて画像のクオリティを向上した
- プーリング層を、ストライドありのConvolution層に入れ替える(下図)
- アンサンプリングでは逆畳み込み層を用いる
- 全結合をなくす
- 全ての層に対してバッチ正規化を行う(Generatorの出力層と、Discriminatorの入力層以外)
- Generatorにおいて、出力層以外ではReluを用いる(出力層にはtanhを用いる)
- DiscriminatorではLeakyReLUを用いる
- オススメ参考文献:はじめてのGAN(という題ではありますが、DCGANについての詳しい説明も載っています)

4. CoGAN (Coupled Generative Adversarial Networks)
- Coupled Generative Adversarial Networks
- コード
- ポイント:2つのGANを並列して使用した(最近はそんなにホットではないらしいです)
- オススメ参考文献:Agustinus Kristiadi's Blog

5. Pix2pix
- Image-to-Image Translation with Conditional Adversarial Networks
- コード
- ポイント:画像から画像への変換を高精度で行えるようになった
- 変換元の画像と変換先の画像が対になっている必要がある(Googleマップの同じ場所の地図と航空写真など)
- オススメ参考文献:pix2pixを理解したい

6. WGAN (Wasserstein Generative Adversarial Networks)
- Wasserstein GAN
- コード
- ポイント:以下の手法により学習が安定し、モード崩壊も回避
- 通常のGANに用いられている Jensen-Shannonダイバージェンス(勾配消失問題を引き起こす)の代わりに、Wasserstein距離を用いて損失関数を設計
- オススメ参考文献:Wasserstein GAN と Kantorovich-Rubinstein 双対性(Wasserstein距離について詳しく解説してくれています)
7. CycleGAN (Cycle Generative Adversarial Network)
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- コード
- ポイント:対となっていない2つの画像が訓練データとして与えられた際に、一方の画像からもう一方への変換が行えるようになった
- 「敵対性損失」(普通のGANで使われている損失関数)にプラスして「サイクル一貫性損失」を用いることで可能となった
-
- Pix2pixと「画像→画像変換」という点では似ているが、CycleGANではPix2pixと違って訓練データの画像群が対になっている必要がない!
- テクスチャや色の変換には強いが、構造的な変換(ex.犬→猫)は難しい
- オススメ参考文献:"GAN"の補足(鍵となるサイクル一貫性損失について解説してくれています)

できることのイメージはこんな感じです。(画像は論文を参照)
8. StackGAN (Stack Generative Adversarial Networks)
- StackGAN: Text to Photo-realistic Image Synthesis
with Stacked Generative Adversarial Networks - ポイント:テキスト表現のみを用いて高解像度の画像を生成できるようになった
- オススメ参考文献:【論文メモ:StackGAN】

論文参照。「この鳥は黒い翼をもち腹部は白いです」というテキストからこの画像が生成されます。
9. ProGAN (Progressive growing of Generative Adversarial Networks)
- Progressive Growing of GANs for Improved Quality, Stability, and Variation
- コード
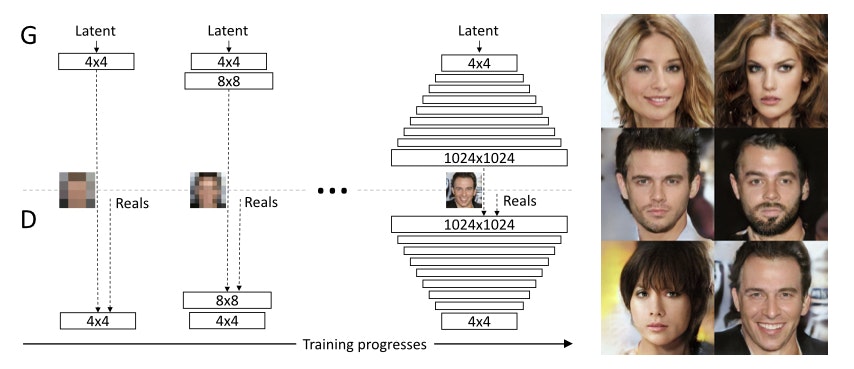
- ポイント:低解像度の画像から徐々に学習させていき、段階的に高解像度にすることに成功した
- オススメ参考文献:【Progressive Growing of GANs for Improved Quality, Stability, and Variation】を読んだのでまとめる
10. SAGAN (Self-Attention Generative Adversarial Networks)
- Self-Attention Generative Adversarial Networks
- コード
- ポイント:以下の手法を用いて生成画像の精度を向上させた
- Self Attentionを導入することで、画像全体の処理状態を考慮
- Spectral Normalizationを、DiscriminatorとGeneratorの双方に適用
- オススメ参考文献:SAGAN(Self Attention Generative Adversarial Network)のSelf Attention機構をざっくり理解した(その名の通り、全体像がつかみやすいです)
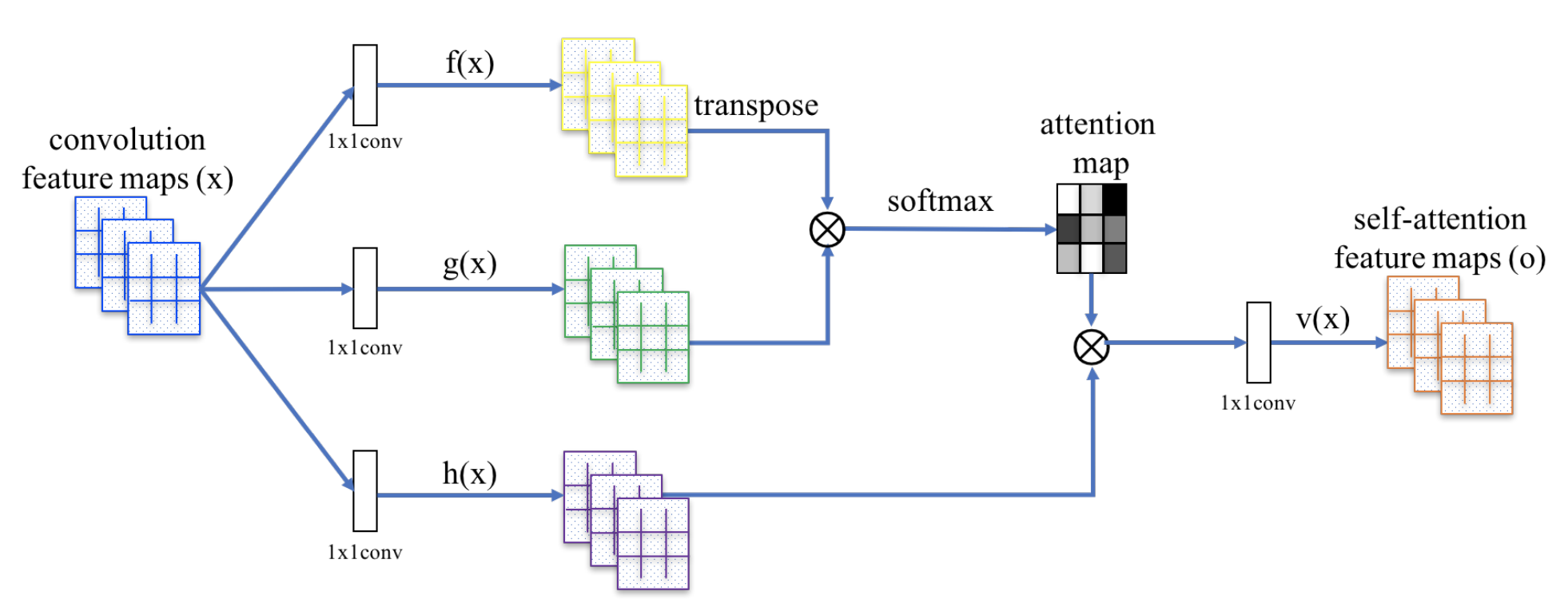
論文参照。Self Attention機構の構造はこんな感じです。
11. BigGAN (Big Generative Adversarial Networks)
- Large Scale GAN Training for High Fidelity Natural Image Synthesis
- コード
- ポイント:SAGANの改善版。Generatorに直行正則化を用いることで過学習を防ぎ、最大512×512ピクセルの高解像度画像を生成できるようになった
- オススメ参考文献:“Large Scale GAN Training for High Fidelity Natural Image Synthesis” -About BigGAN (日本語です)

論文中にあるBigGANで生成した画像です。ハイクオリティなのがわかりますね!
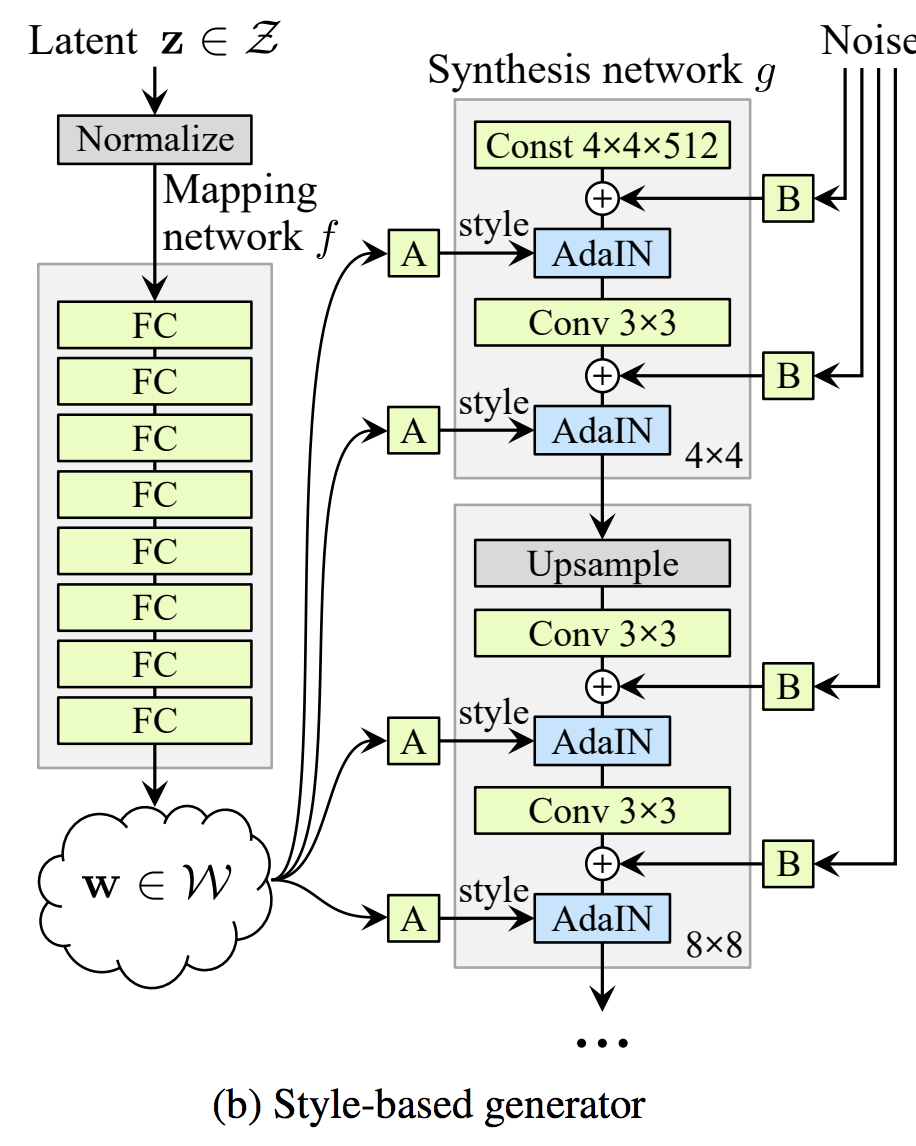
12. StyleGAN (Style-based Generative Adversarial Networks)
A Style-Based Generator Architecture for Generative Adversarial Networks- コード
- ポイント:スタイル変換を取り入れ新しいGeneratorを考案することで、1024×1024のサイズで高解像度の画像生成に成功した
- オススメ参考文献:
StyleGAN「写真が証拠になる時代は終わった。」
終わりに
最後まで読んでいただきありがとうございます。もっとGANについて細かいとこまで知りたい&英語でもokという方は、是非こちらのNIPS 2016 Tutorial: Generative Adversarial Networksを読んでみてください。
皆さんがGANについての全体像をイメージするのに役立てていれば幸いです。(訂正などあれば是非教えてください!)